2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Tämä artikkeli käyttää Alibaba Cloudin vektorinhakupalvelua (DashVector) yhdistettynä ONE-PEACE multimodaalinen malli , rakentaa reaaliaikaisia multimodaalisia hakuominaisuuksia "kuvien tekstihakulle". Kokonaisprosessi on seuraava: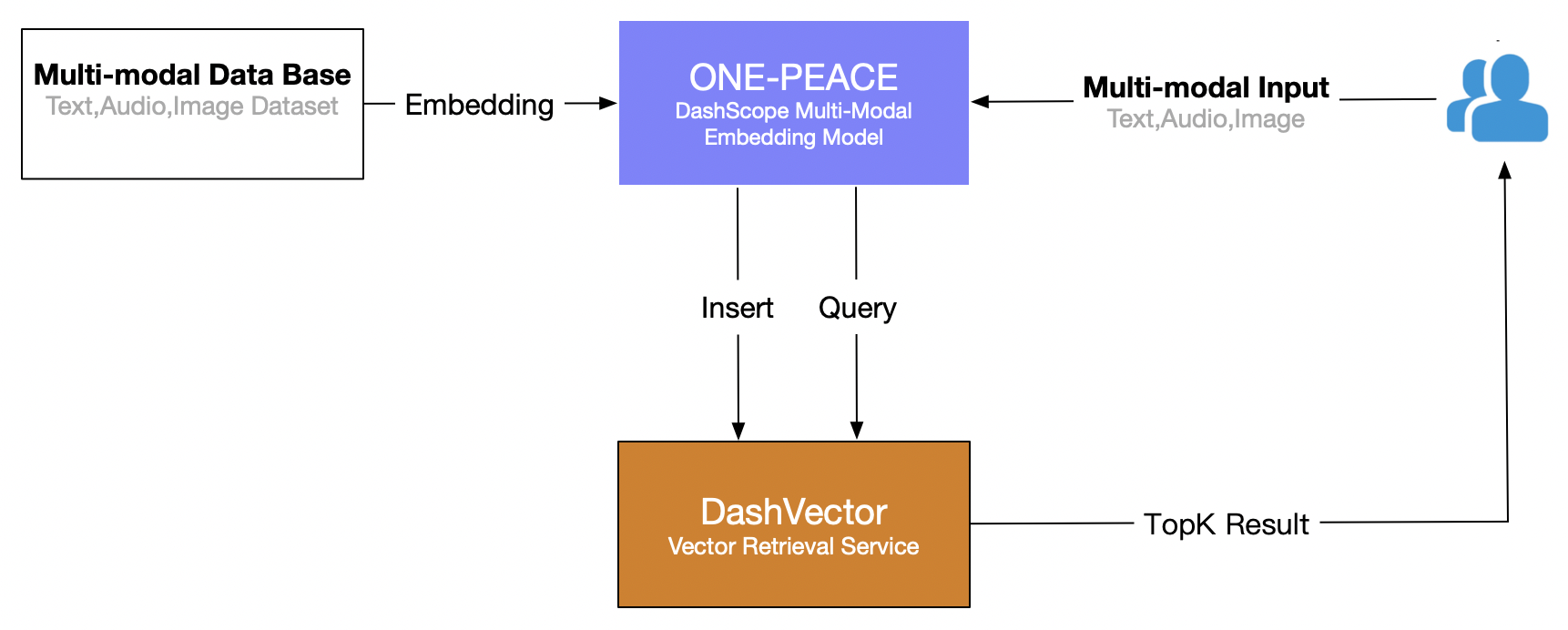
Edellytykset
- Avaa Lingji-mallipalvelu ja hanki API-KEY:Aktivoi DashScope ja luo API-Avain
- Avoin vektorin hakupalvelu: katsoTilaa palvelu。
- Luo vektorinhakupalvelu API-KEY: katsoAPI-KEY-hallinta。
Ympäristön valmistelu
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
tietojen valmistelu
havainnollistaa
Koska DashScopen ONE-PEACE-mallipalvelu tukee tällä hetkellä vain kuvan ja äänen syöttöä URL-osoitteiden muodossa, tietojoukko on ladattava etukäteen julkiseen verkkotallennustilaan (kuten oss/s3) ja hankittava vastaavan URL-osoiteluettelo. kuvia ja ääniä.
Käytin Alibaba Cloudin OSS:ää kuvan tallentamiseen ja sain kuvan ulkopuolelta saatavilla olevan URL-osoitteen OSS-selainkäyttöliittymän kautta: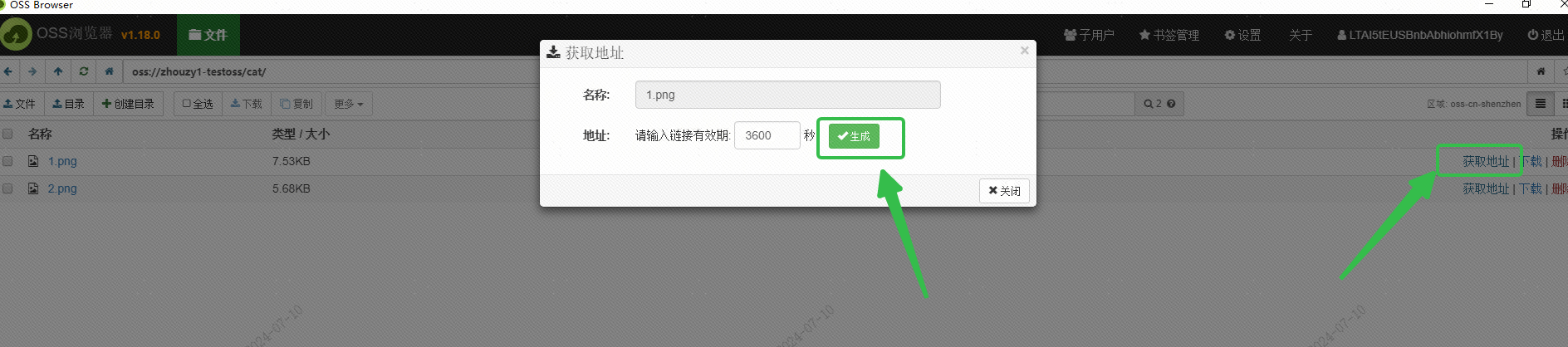
Tämän URL-osoitteen pitäisi saada myös käyttöliittymän kautta. Kiinnostuneet ystävät voivat yrittää hankkia sen erissä. Tallenna DashVector-vektoritietokantaan.
Kun olet saanut URL-osoitteen, kirjoita URL-osoite meidän imagenet1k-urls.txt tiedosto, koodimme lukee tiedoston myöhempää upottamista varten: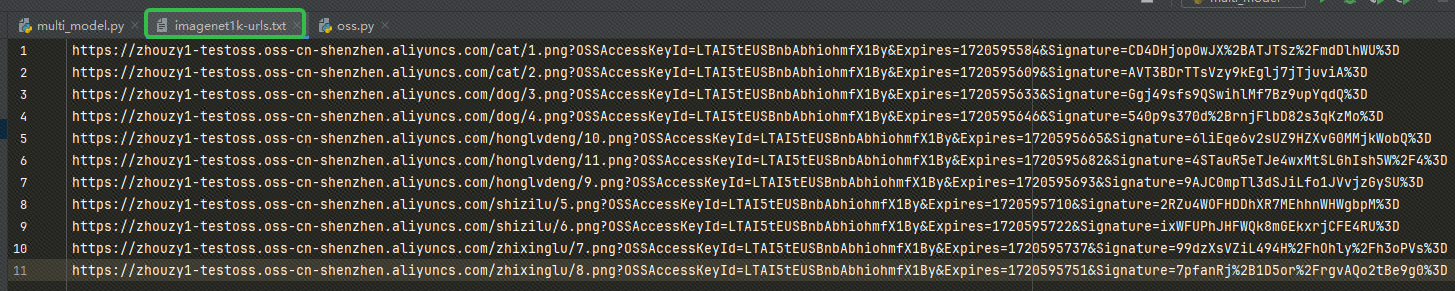
Koodi upotuksen suorittamiseksi on seuraava (lähetän täydellisen koodin ja hakemistorakenteen myöhemmin, vain upotettu koodi on lähetetty tähän):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHKuvan URL-osoite URL-osoitteessa ja suorita sitten DashScope-pyyntö kuvamme vektoroimiseksi ja tallentamiseksi.Suorituksen jälkeen voit läpäistäVektorihakupalvelukonsoli, tarkista vektoritiedot: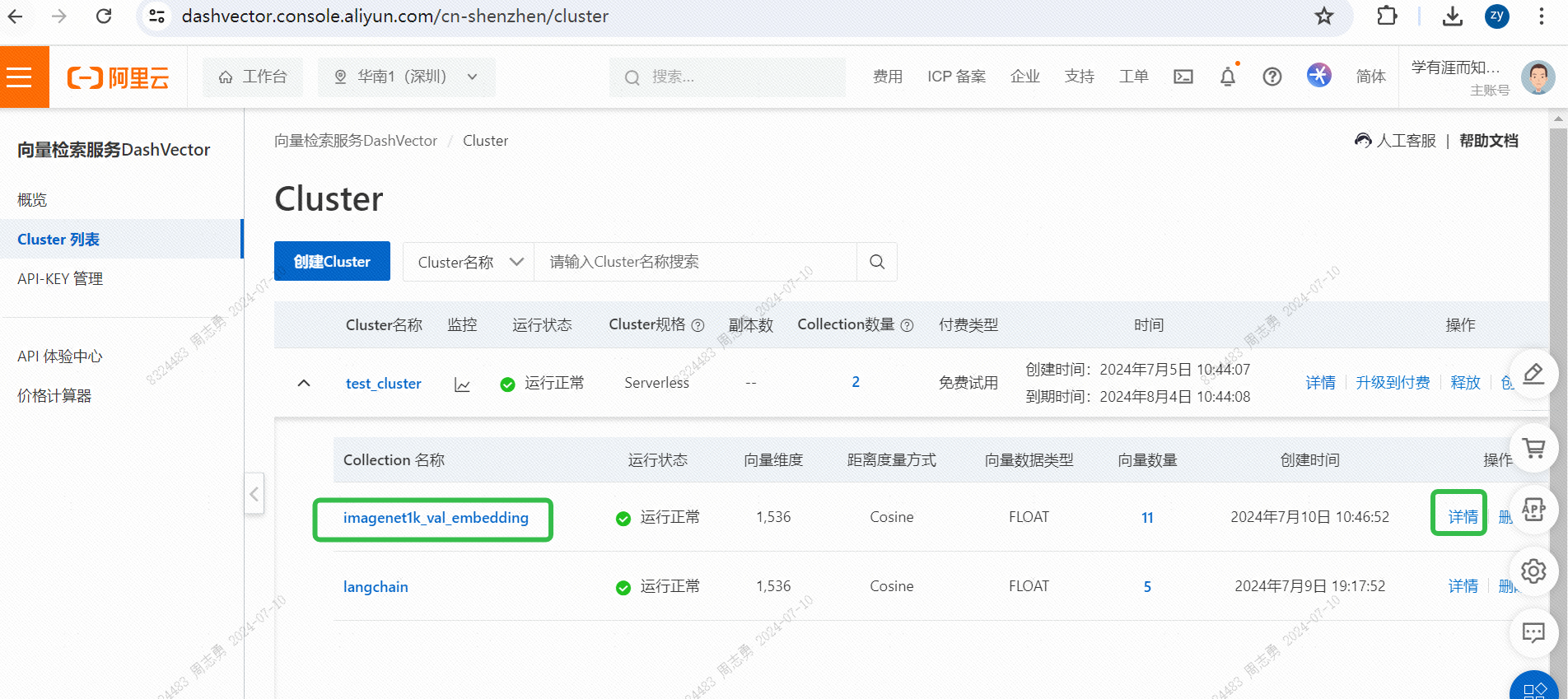
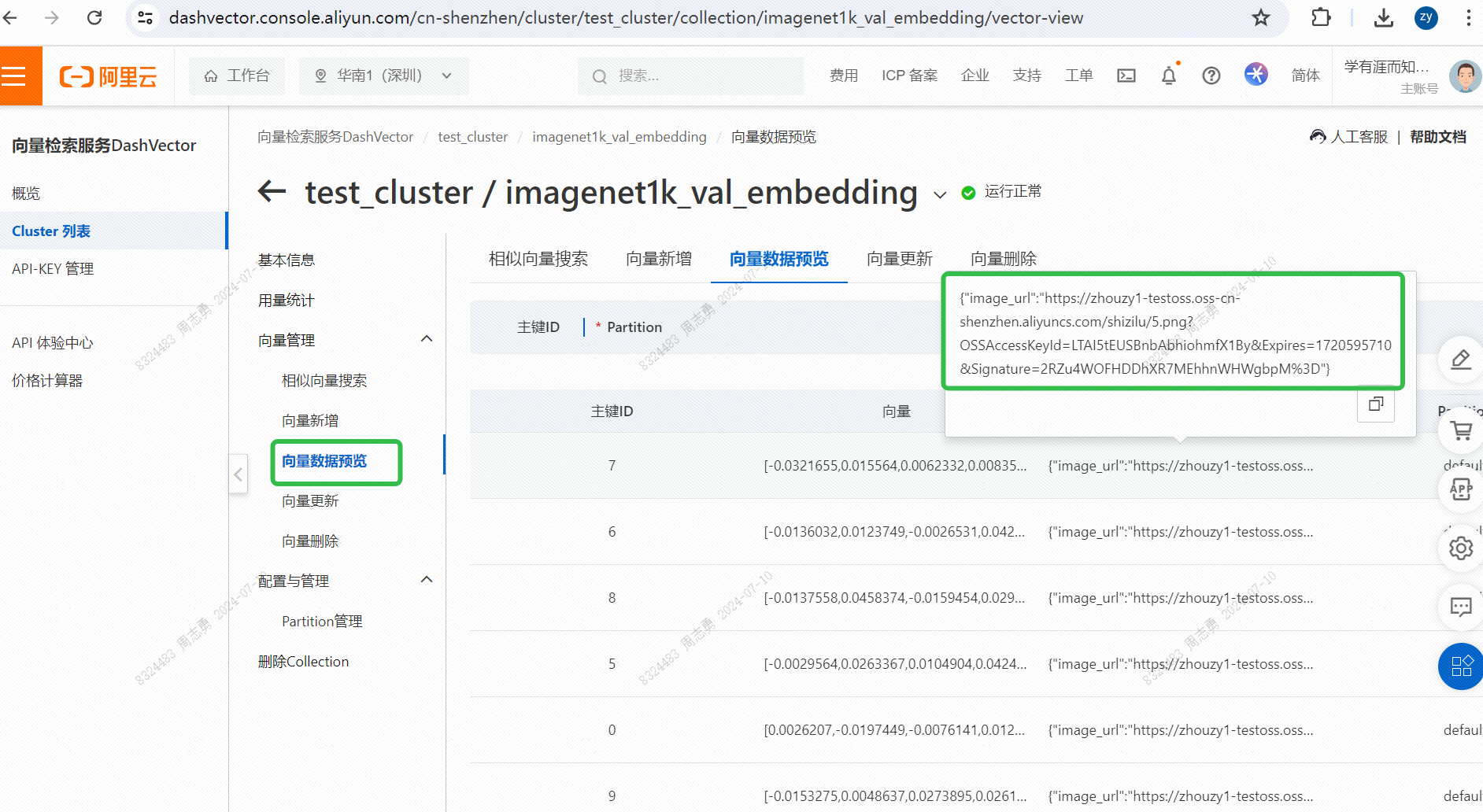
Jos haluat hakea tietoja vektoritietokannasta tekstin avulla, syötäncatKun olet hakenut kolme kuvaa (koodissamme asetettu topk=3), voit tarkistaa tehosteen kaksi kissoista, mutta yksi on koiran kuva: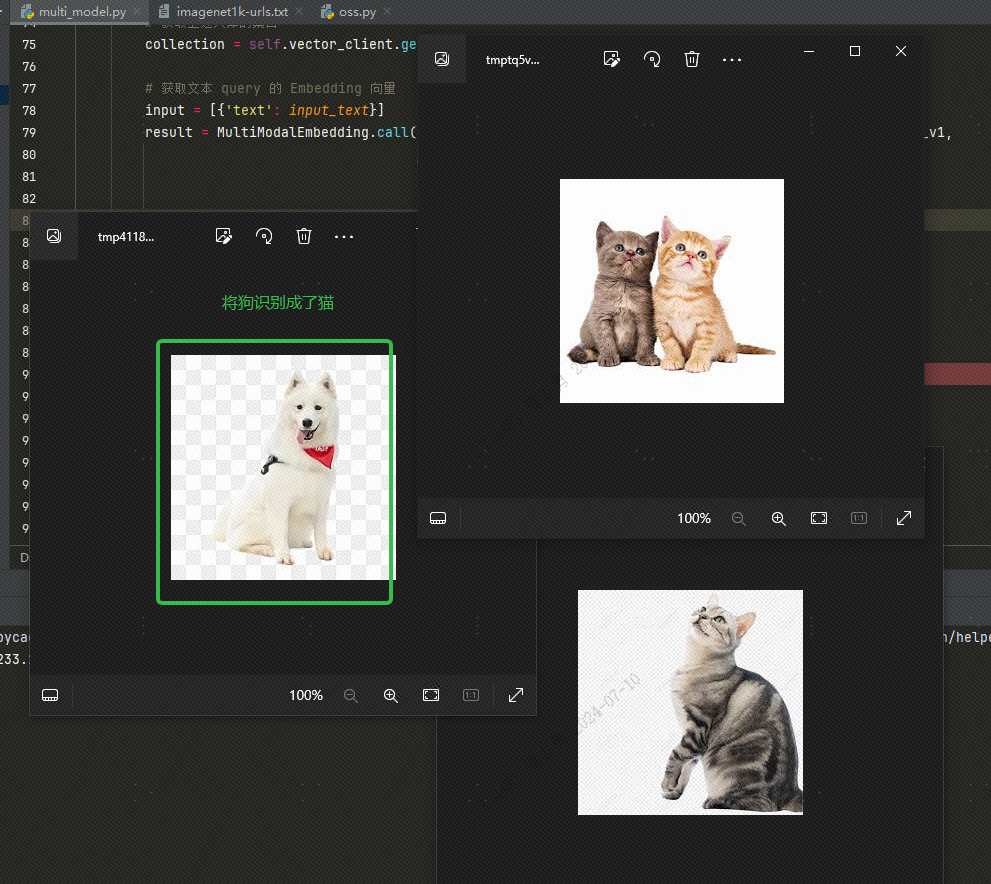
Tämä johtuu siitä, että koirien ja kissojen välillä on yhtäläisyyksiätopkAseta arvoon 2, teoriassa koiraa ei voida havaita. Katsotaanpa vaikutusta, ja totta kai koiraa ei ole: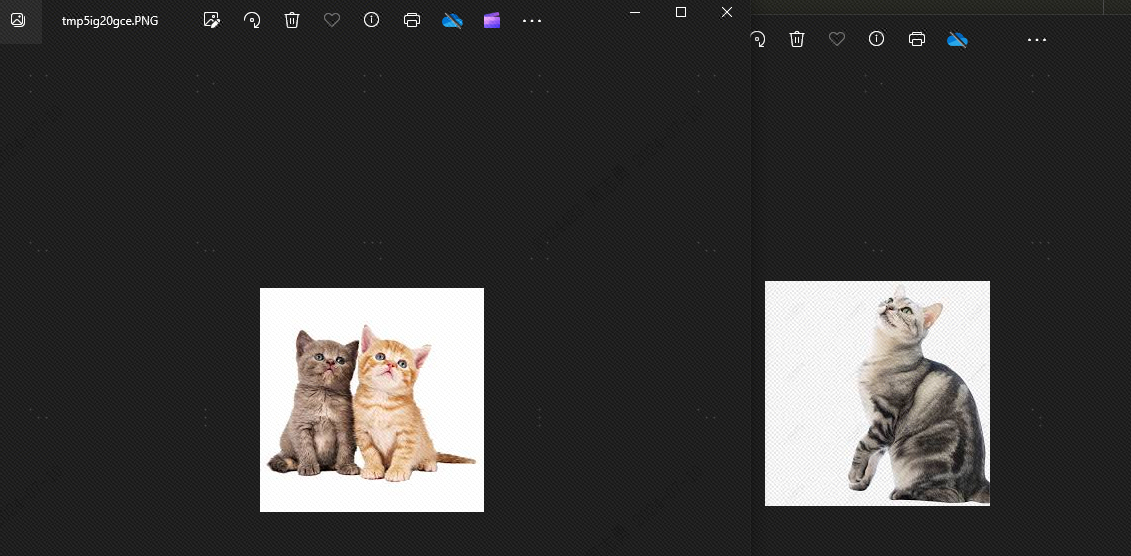
Syy siihen, miksi koirat ilmestyvät, johtuu siitä, että olen tallentanut 4 eläinkuvaa vektorikirjastoon, 2 kissakuvaa ja 2 koirakuvaa.
multi_model.pyTiedostot ovat seuraavat:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTKoodihakemistorakenne on seuraava. Aseta txt-tiedosto ja py-tiedosto samaan hakemistoon:
Lisäinformaatio
Käytä paikallisia kuvia: Lähetin kuvan OSS:ään. Voit myös käyttää paikallista kuvatiedostoa ja korvata txt-tiedoston polun paikallisella kuvapolulla seuraavasti:
Jos käytämme paikallisia kuvia, meidän on muutettava yllä olevaa koodia ja alla olevaa koodia:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten

