
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Este artículo utiliza el servicio de recuperación de vectores de Alibaba Cloud (DashVector), combinado con Modelo multimodal UNA PAZ , cree una capacidad de recuperación multimodal en tiempo real de "búsqueda de texto para imágenes". El proceso general es el siguiente: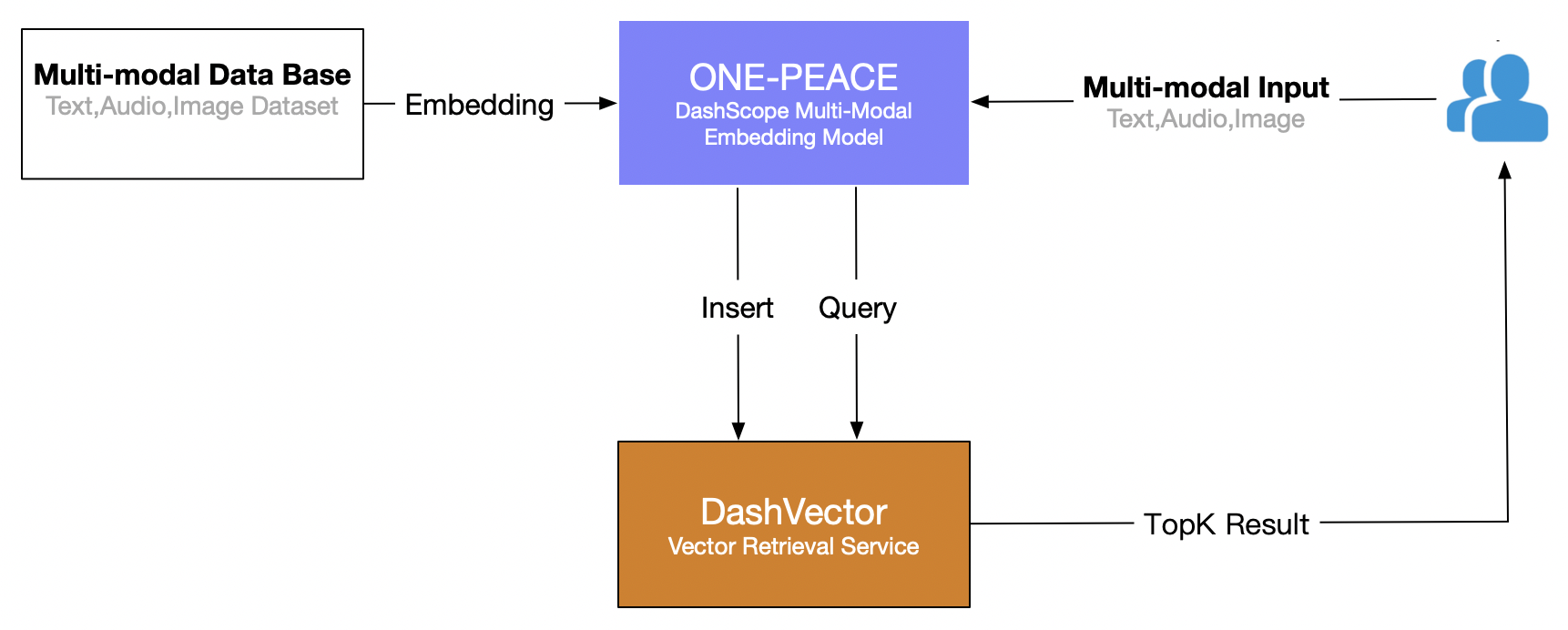
Requisitos previos
- Abra el servicio de modelo Lingji y obtenga API-KEY:Active DashScope y cree API-KEY
- Servicio abierto de recuperación de vectores: verSuscríbete a un servicio。
- Crear API-KEY del servicio de recuperación de vectores: verGestión de API-KEY。
Preparación ambiental
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
preparación de datos
ilustrar
Dado que el servicio modelo ONE-PEACE de DashScope actualmente solo admite la entrada de imágenes y audio en forma de URL, es necesario cargar el conjunto de datos en un almacenamiento de red público (como oss/s3) con anticipación y obtener la lista de direcciones URL del correspondiente. imágenes y audios.
Utilicé el OSS de Alibaba Cloud para guardar la imagen y obtuve la URL de la imagen accesible externamente a través de la interfaz del navegador OSS: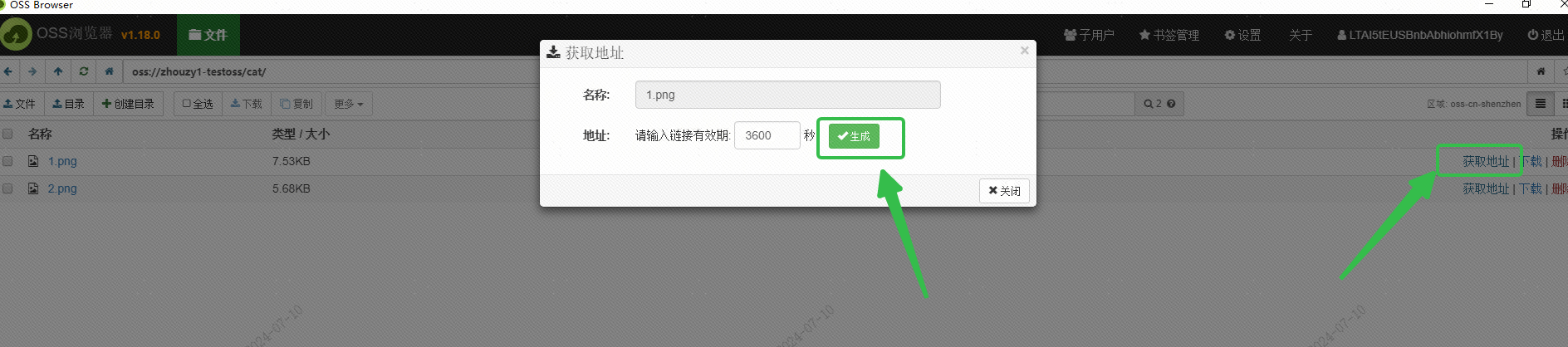
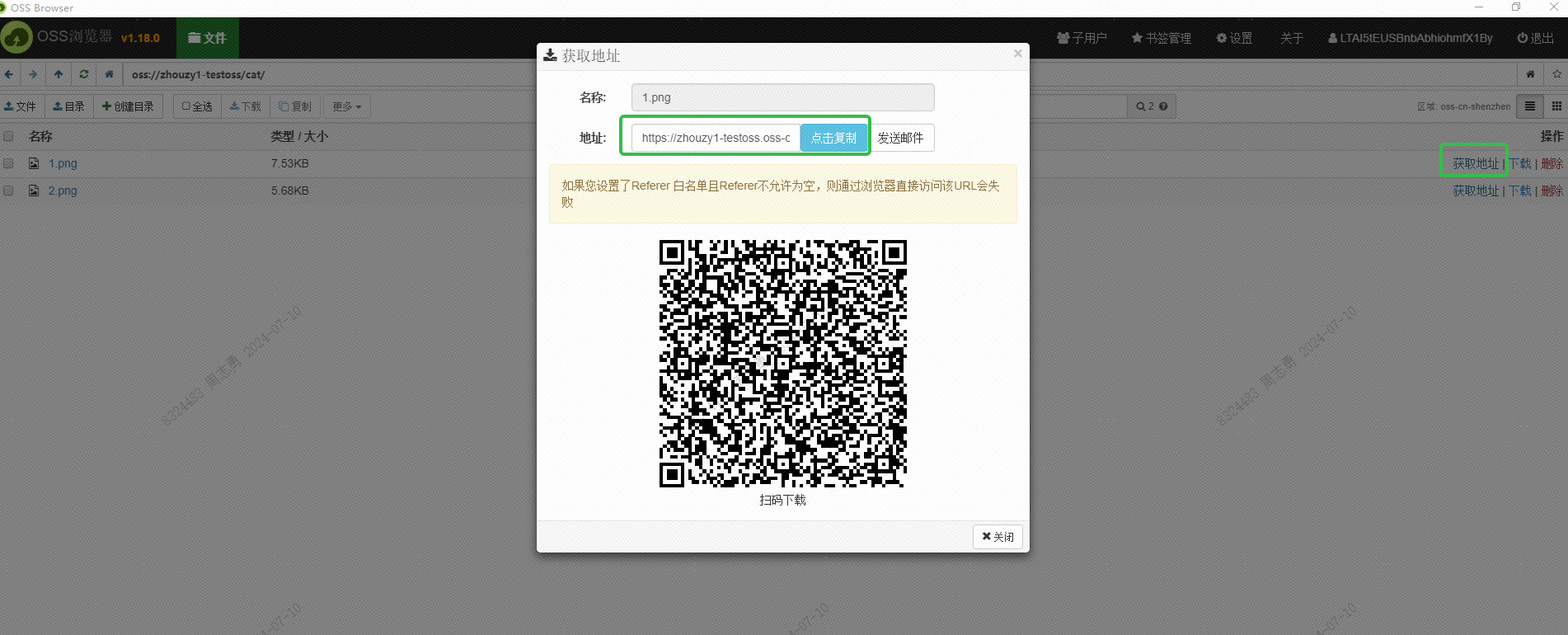
Esta URL también debe obtenerse a través de la interfaz. Esto aún no se ha estudiado. Los amigos interesados pueden intentar obtenerla en lotes a través de la interfaz. El propósito de obtener esta URL es permitir que el servicio DashScope de Alibaba Cloud lea la imagen para incrustarla. Guárdelo en la base de datos vectorial DashVector.
Después de obtener la URL, escríbala en nuestro imagenet1k-urls.txt archivo, nuestro código leerá el archivo para incrustarlo más tarde: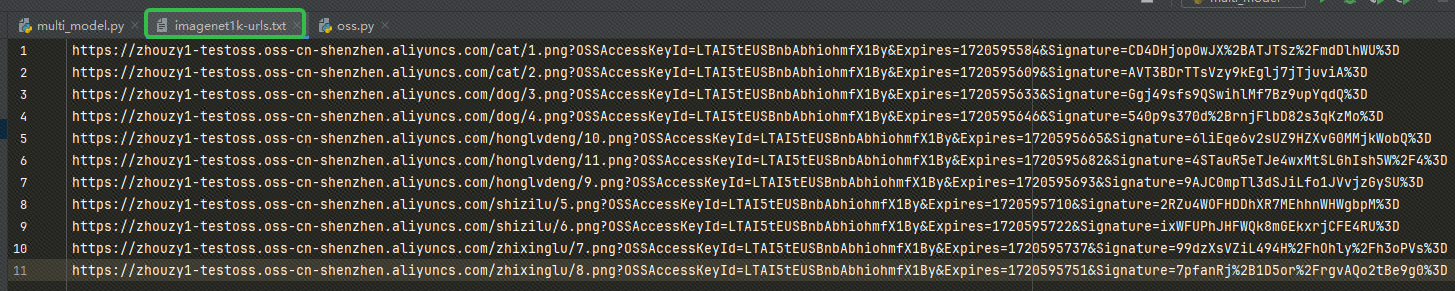
El código para ejecutar la incrustación es el siguiente (publicaré el código completo y la estructura del directorio más adelante, aquí solo se publica el código incrustado):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHLa URL de la imagen en la URL y luego realiza una solicitud de DashScope para vectorizar y almacenar nuestra imagen.Después de la ejecución, puedes pasar.Consola de servicio de recuperación de vectores, verifique los datos del vector: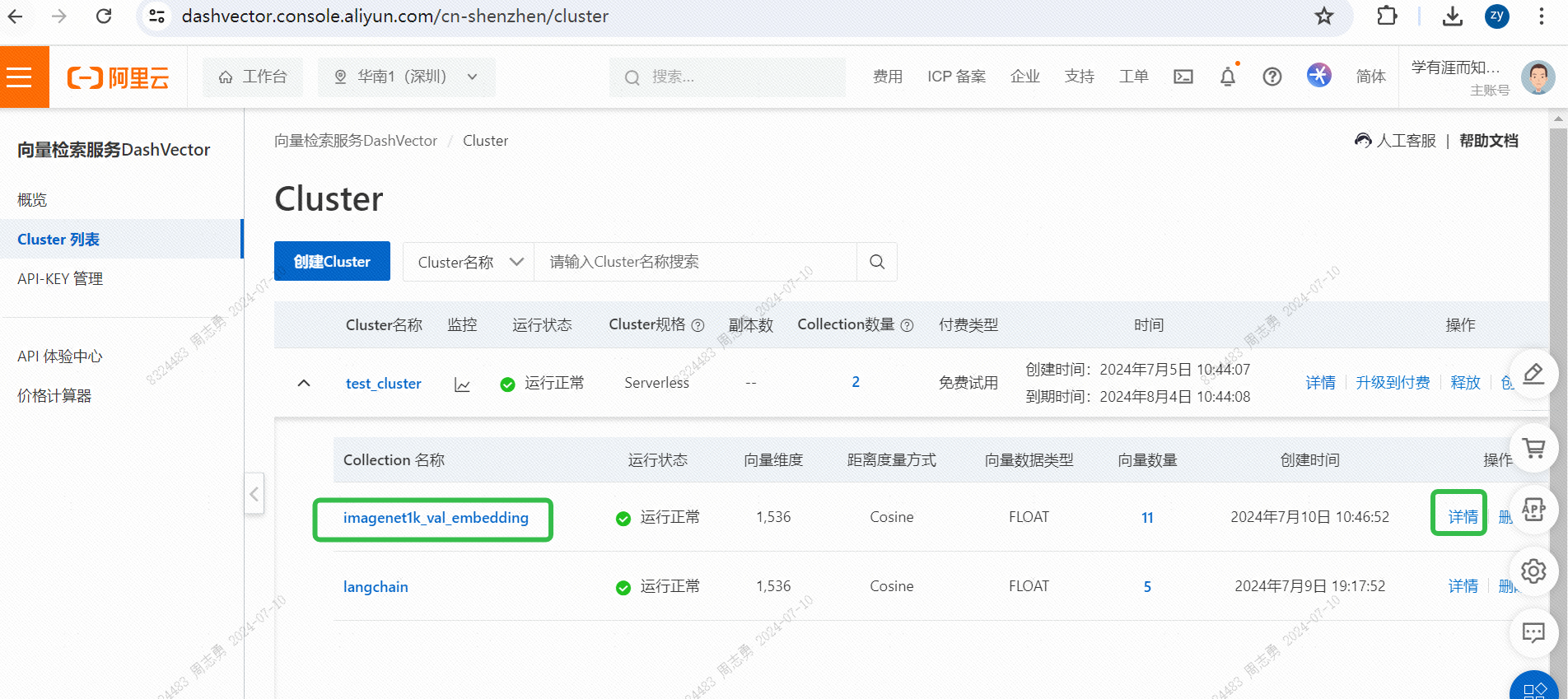
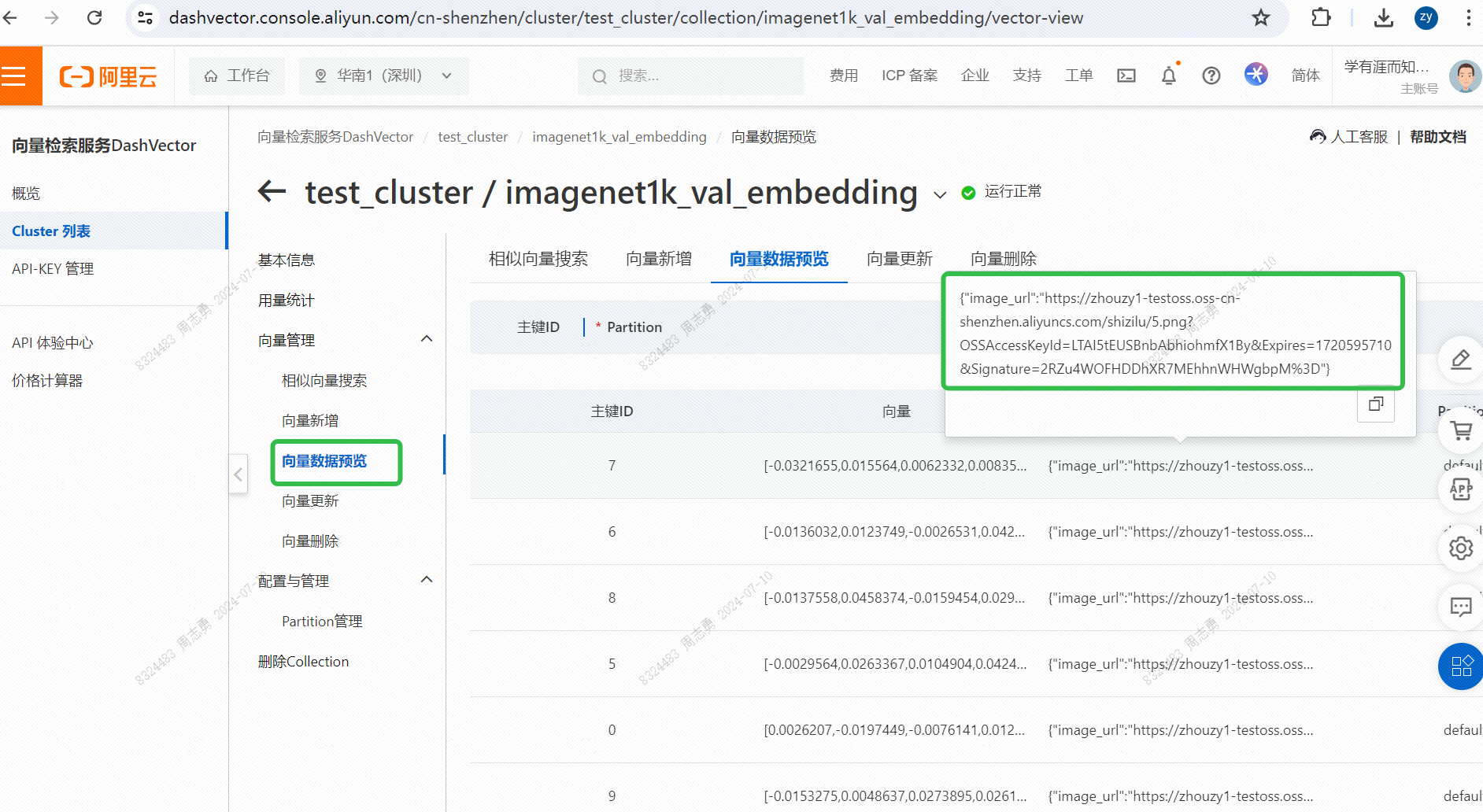
Para recuperar datos de una base de datos vectorial por texto, ingresocatDespués de recuperar tres imágenes (topk=3 establecido en nuestro código), puede verificar el efecto. Dos son imágenes de gatos, pero una es una imagen de un perro: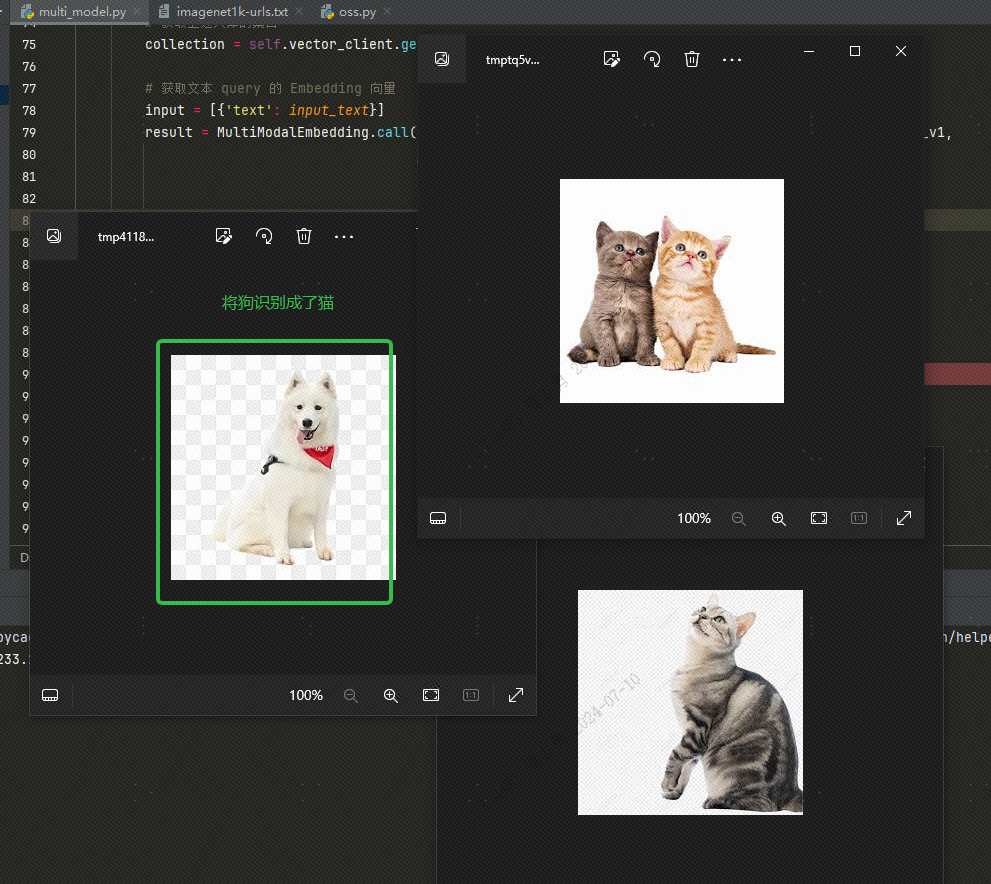
Esto se debe a que existen similitudes entre perros y gatos. A continuación veremos.topkSi se establece en 2, en teoría no se puede detectar el perro. Veamos el efecto y, efectivamente, no hay ningún perro: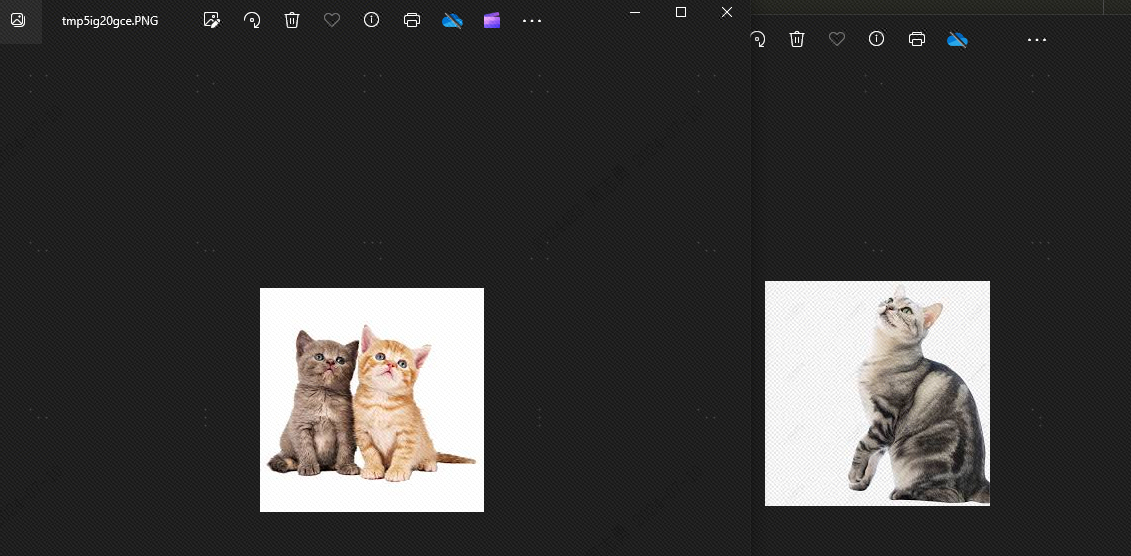
La razón por la que aparecen perros es porque he almacenado 4 imágenes de animales en la biblioteca de vectores, 2 imágenes de gatos y 2 imágenes de perros. Si nuestro topk está configurado en 3, se detectará una imagen de perro más.
multi_model.pyLos archivos son los siguientes:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTLa estructura del directorio del código es la siguiente. Coloque el archivo txt y el archivo py en el mismo directorio: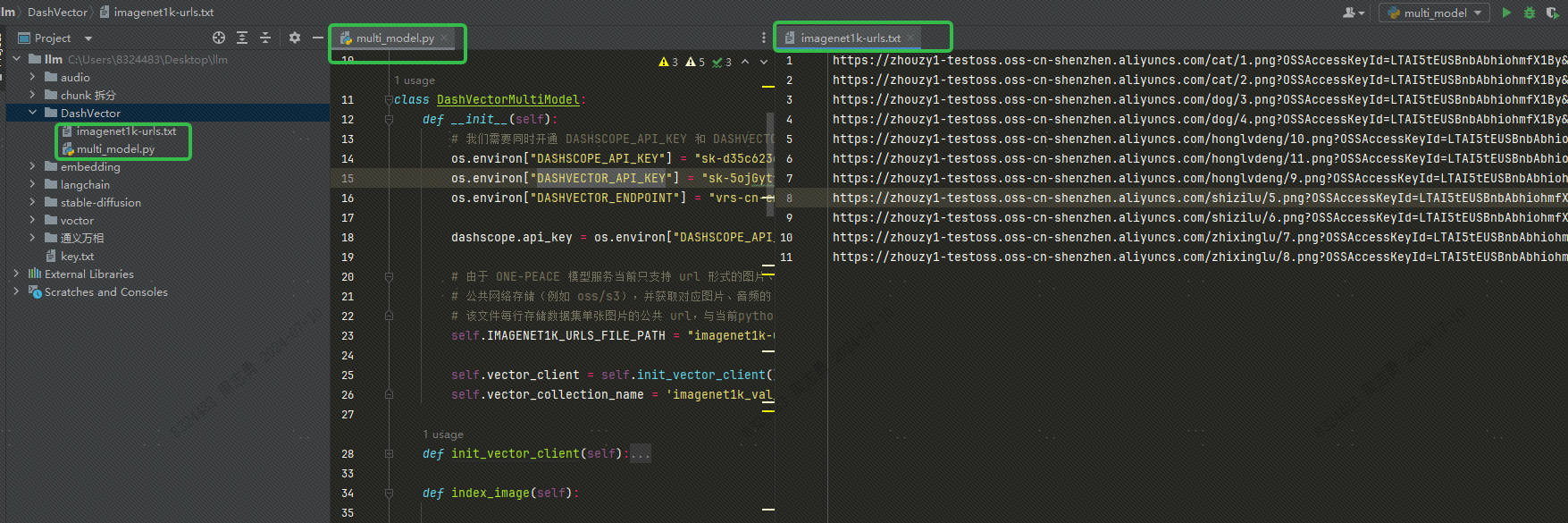
Información adicional
Utilice imágenes locales: Subí la imagen a OSS. También puedes usar un archivo de imagen local y reemplazar la ruta del archivo en txt con la ruta de la imagen local, de la siguiente manera:
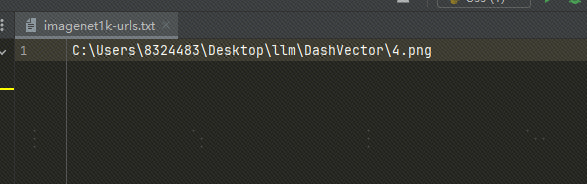
Si usamos imágenes locales, tenemos que modificar el código anterior y modificar el siguiente código:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]