2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
अयं लेखः Alibaba Cloud इत्यस्य vector retrieval service (DashVector) इत्यस्य उपयोगं करोति, यत्... ONE-PEACE बहुविधप्रतिरूपम् , "चित्रेषु पाठसन्धानं" इत्यस्य वास्तविकसमयस्य बहुविध-पुनर्प्राप्तिक्षमतायाः निर्माणार्थम् । समग्रप्रक्रिया यथा भवति ।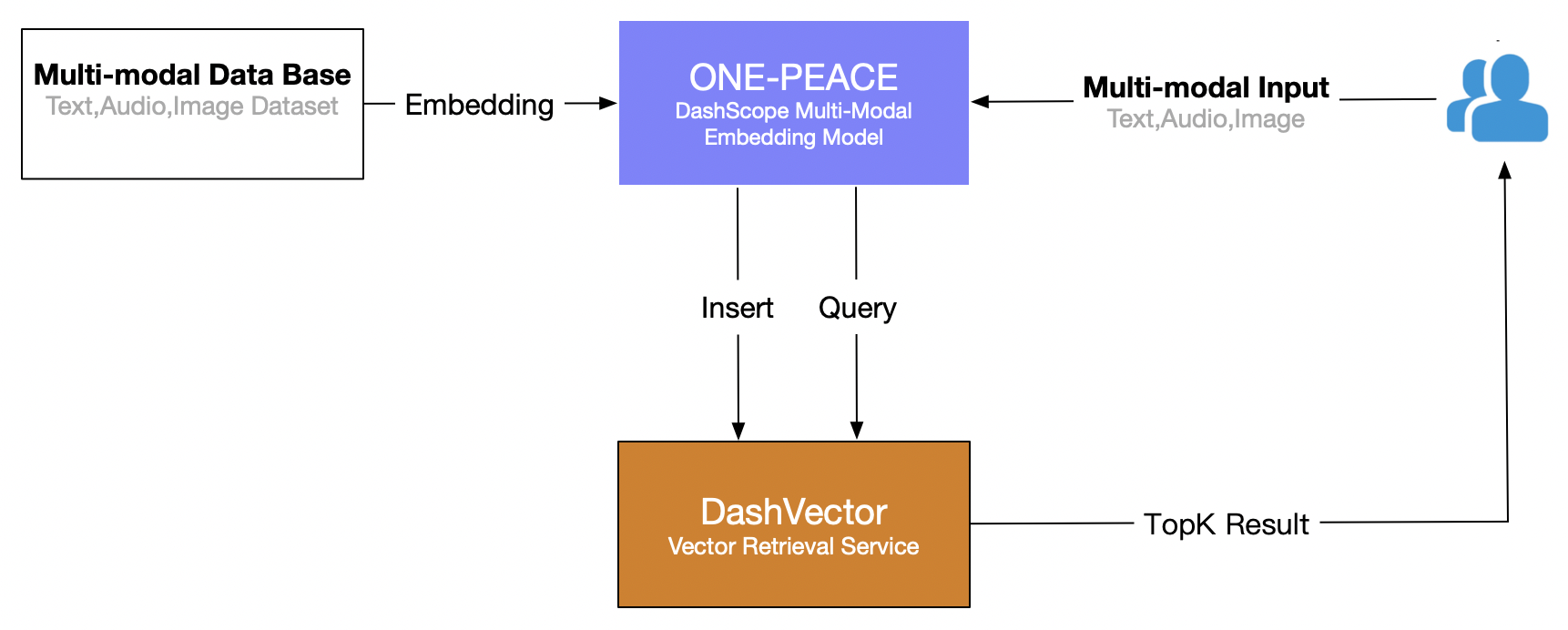
पूर्वापेक्षा
- Lingji model service उद्घाट्य API-KEY प्राप्तुम्:DashScope सक्रियं कृत्वा API-KEY रचयन्तु
- सदिशपुनर्प्राप्तिसेवा उद्घाटयतु: पश्यन्तुकस्यापि सेवायाः सदस्यतां गृहाण。
- सदिशपुनर्प्राप्तिसेवा API-KEY रचयन्तु: पश्यन्तुएपिआइ-की प्रबन्धन。
पर्यावरणसज्जता
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
दत्तांशसज्जीकरणम्
दृष्टान्तरूपेण दर्शयतु
यतो हि DashScope इत्यस्य ONE-PEACE मॉडलसेवा वर्तमानकाले केवलं URL रूपेण चित्रं श्रव्यं च निवेशं समर्थयति, अतः पूर्वमेव सार्वजनिकजालभण्डारणस्थाने (यथा oss/s3) आँकडासमूहं अपलोड् कृत्वा तत्सम्बद्धस्य URL पतासूचीं प्राप्तुं आवश्यकम् अस्ति चित्राणि श्रव्याणि च।
मया चित्रं रक्षितुं Alibaba Cloud इत्यस्य OSS इत्यस्य उपयोगः कृतः, तथा च OSS Browser इत्यस्य अन्तरफलकस्य माध्यमेन चित्रस्य बाह्यरूपेण सुलभं URL प्राप्तम्: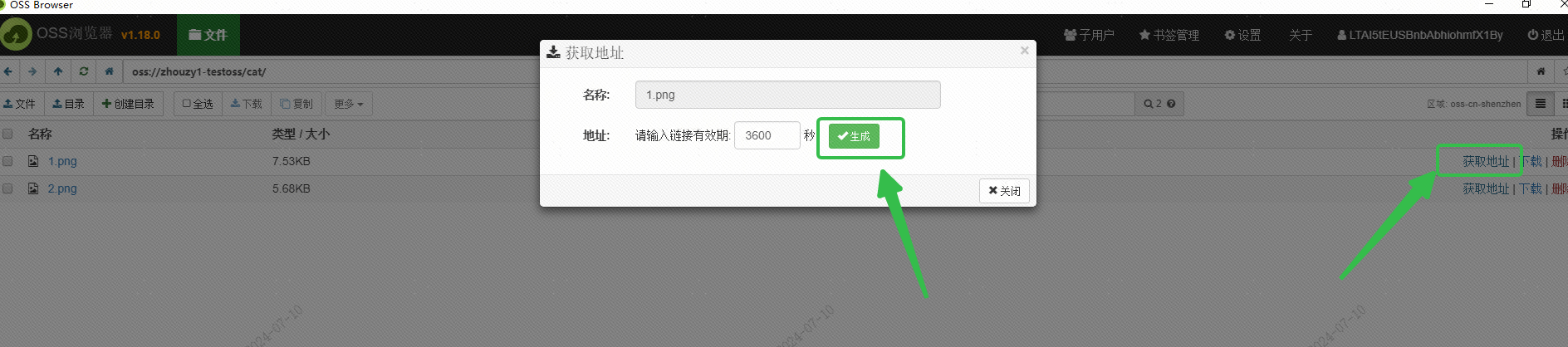
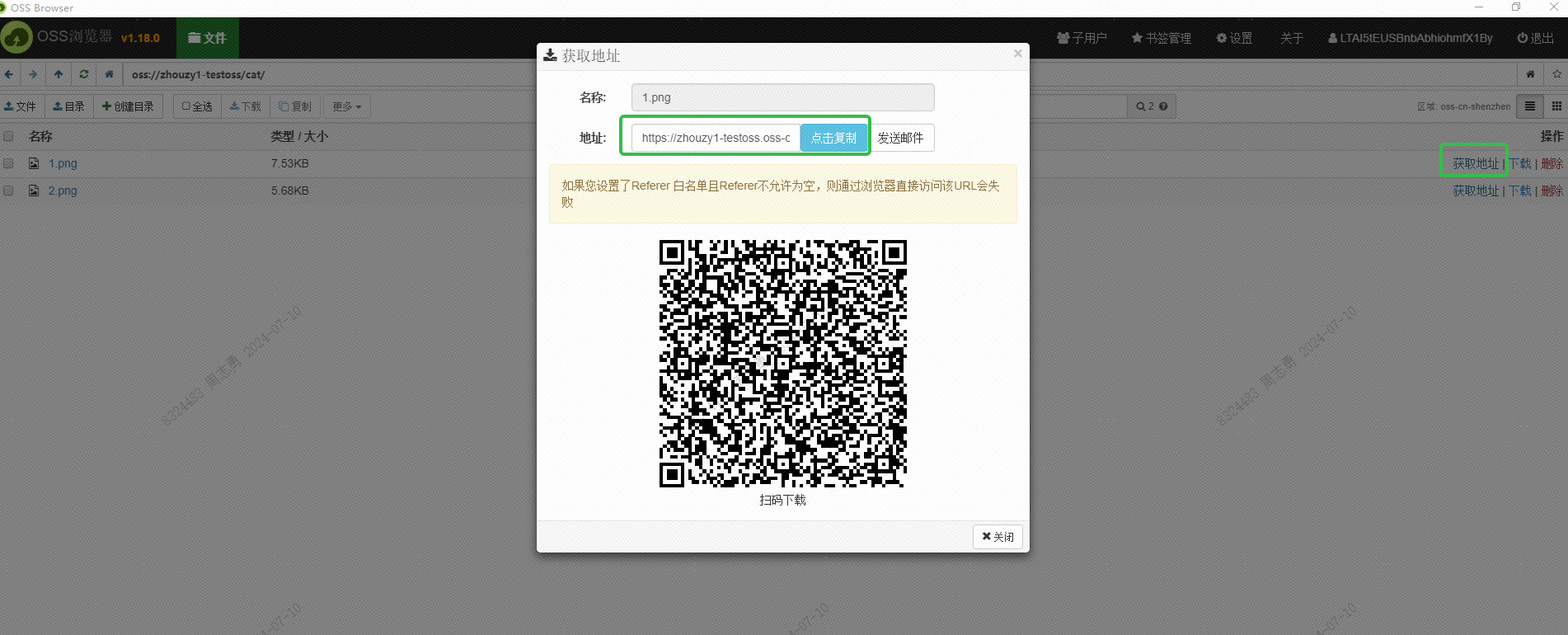
इदं URL इत्येतत् अन्तरफलकस्य माध्यमेन अपि प्राप्तव्यम् । DashVector सदिशदत्तांशकोशे रक्षन्तु ।
URL प्राप्त्वा URL अस्माकं मध्ये लिखन्तु imagenet1k-urls.txt file, अस्माकं कोडः पश्चात् एम्बेड् कर्तुं सञ्चिकां पठिष्यति: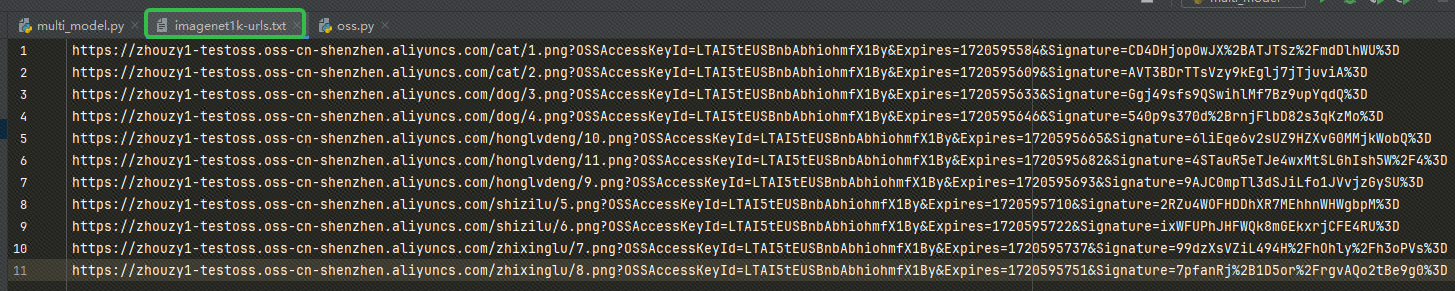
एम्बेडिंग् निष्पादयितुं कोडः निम्नलिखितरूपेण अस्ति (अहं सम्पूर्णं कोडं निर्देशिकासंरचनां च पश्चात् पोस्ट करिष्यामि, केवलं एम्बेडेड् कोडः एव अत्र पोस्ट् भवति):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHURL मध्ये चित्रस्य URL, ततः अस्माकं चित्रं वेक्टरीकृत्य संग्रहीतुं DashScope अनुरोधं कुर्वन्तु ।निष्पादनस्य अनन्तरं भवन्तः उत्तीर्णं कर्तुं शक्नुवन्तिसदिश पुनर्प्राप्ति सेवा कंसोल, सदिशदत्तांशं पश्यन्तु: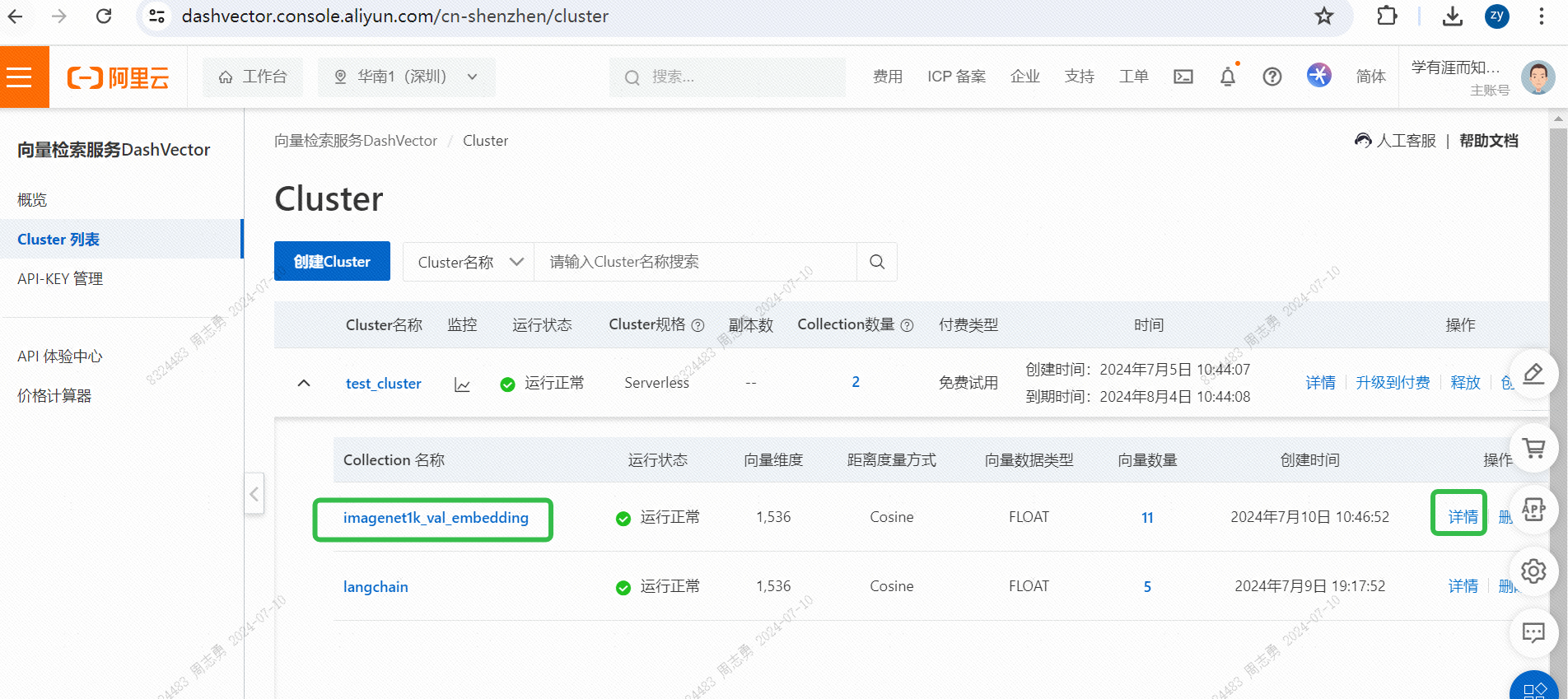
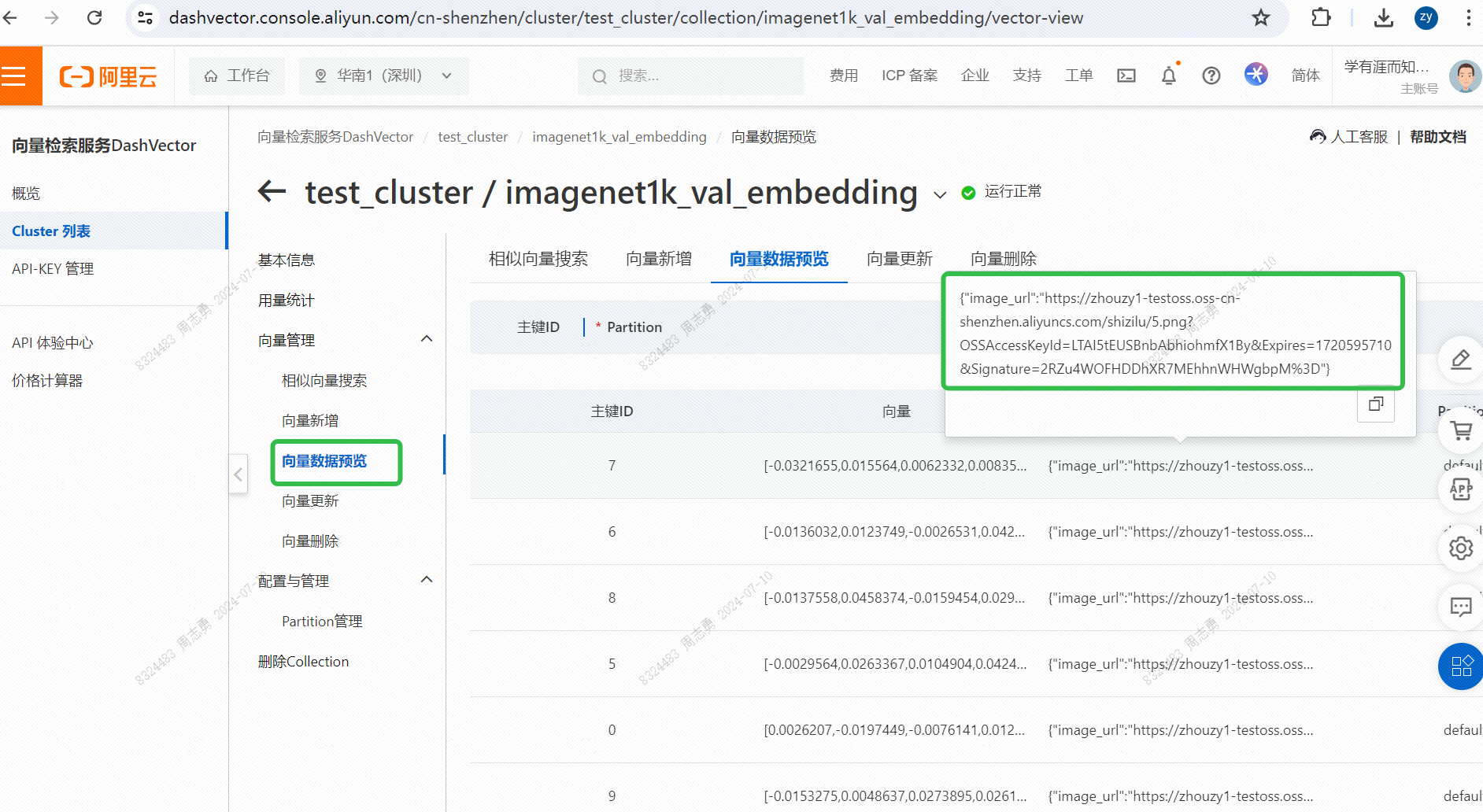
पाठेन सदिशदत्तांशकोशात् दत्तांशं प्राप्तुं अहं प्रविशामिcatत्रीणि चित्राणि (अस्माकं कोड् मध्ये topk=3 सेट्) प्राप्त्वा, भवान् प्रभावं परीक्षितुं शक्नोति द्वे बिडालस्य चित्रम्, परन्तु एकं श्वः चित्रम् अस्ति: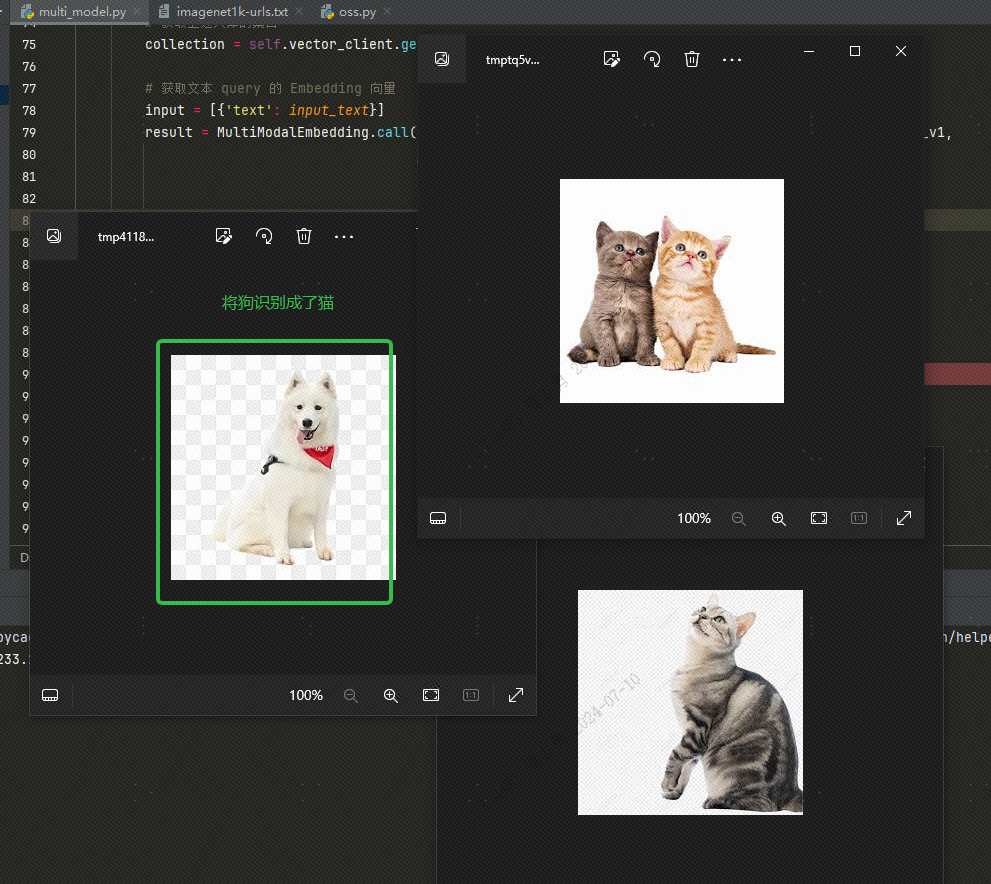
यतो हि श्वबिडालयोः साम्यम् अस्ति तदनन्तरं वयं करिष्यामःtopk2 इति सेट् कृत्वा, सैद्धान्तिकरूपेण श्वः ज्ञातुं न शक्यते, प्रभावं पश्यामः, तथा च निश्चितरूपेण, श्वः नास्ति: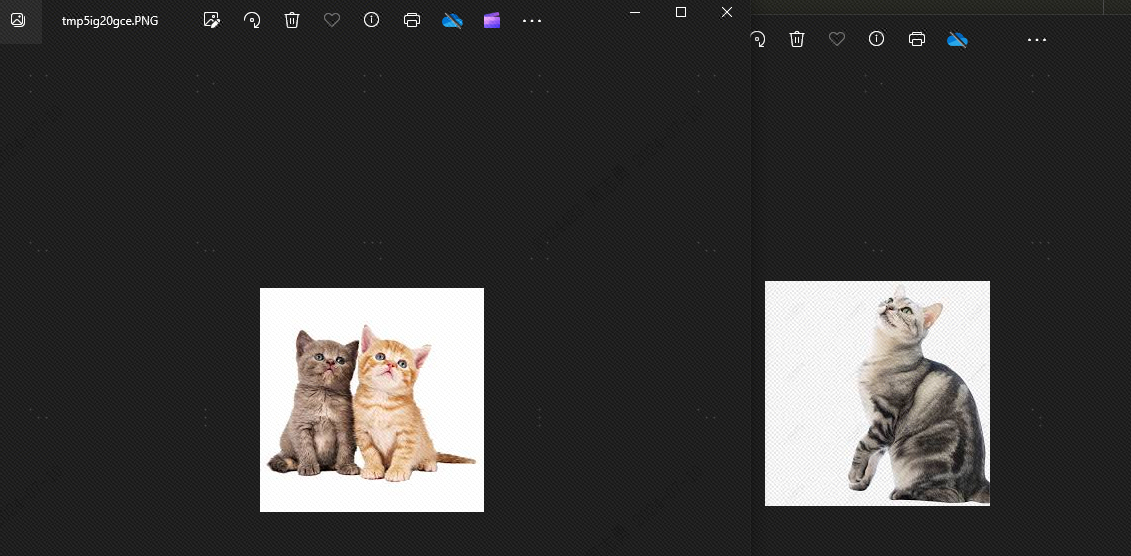
श्वानानां दृश्यमानस्य कारणं अस्ति यत् मया सदिशपुस्तकालये ४ पशुचित्रं, २ बिडालचित्रं २ श्वापदचित्रं च संगृहीतम् यदि अस्माकं topk ३ इति सेट् भवति तर्हि एकं अधिकं श्वापदचित्रं ज्ञास्यति।
multi_model.pyसञ्चिकाः निम्नलिखितरूपेण सन्ति ।
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTकोड निर्देशिका संरचना निम्नलिखितरूपेण अस्ति txt सञ्चिकां py सञ्चिकां च एकस्मिन् निर्देशिकायां स्थापयन्तु ।
अतिरिक्त सूचना
स्थानीयप्रतिमानां उपयोगं कुर्वन्तु: मया चित्रं OSS मध्ये अपलोड् कृतम् भवान् स्थानीयप्रतिबिम्बसञ्चिकां अपि उपयोक्तुं शक्नोति तथा च txt मध्ये सञ्चिकामार्गं स्थानीयप्रतिबिम्बमार्गेण प्रतिस्थापयितुं शक्नोति, यथा:
यदि वयं स्थानीयचित्रस्य उपयोगं कुर्मः तर्हि उपरि कोडं अधोलिखितं च कोडं परिवर्तयितव्यम् :
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

सः ३० वर्षाणाम् अनुसरणं प्रौयोगिक कौलिका समुह, सलग, जावा, जावास्च, php, css समुच्चय भाषा सुनाधारी, ph, css समुच्चय संस्कृत भाषा सुनावं, सरोकार विद्वान विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग

