
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Questo articolo utilizza il servizio di recupero vettoriale di Alibaba Cloud (DashVector), combinato con Modello multimodale ONE-PEACE , per creare capacità di recupero multimodale in tempo reale di "ricerca testuale di immagini". Il processo complessivo è il seguente: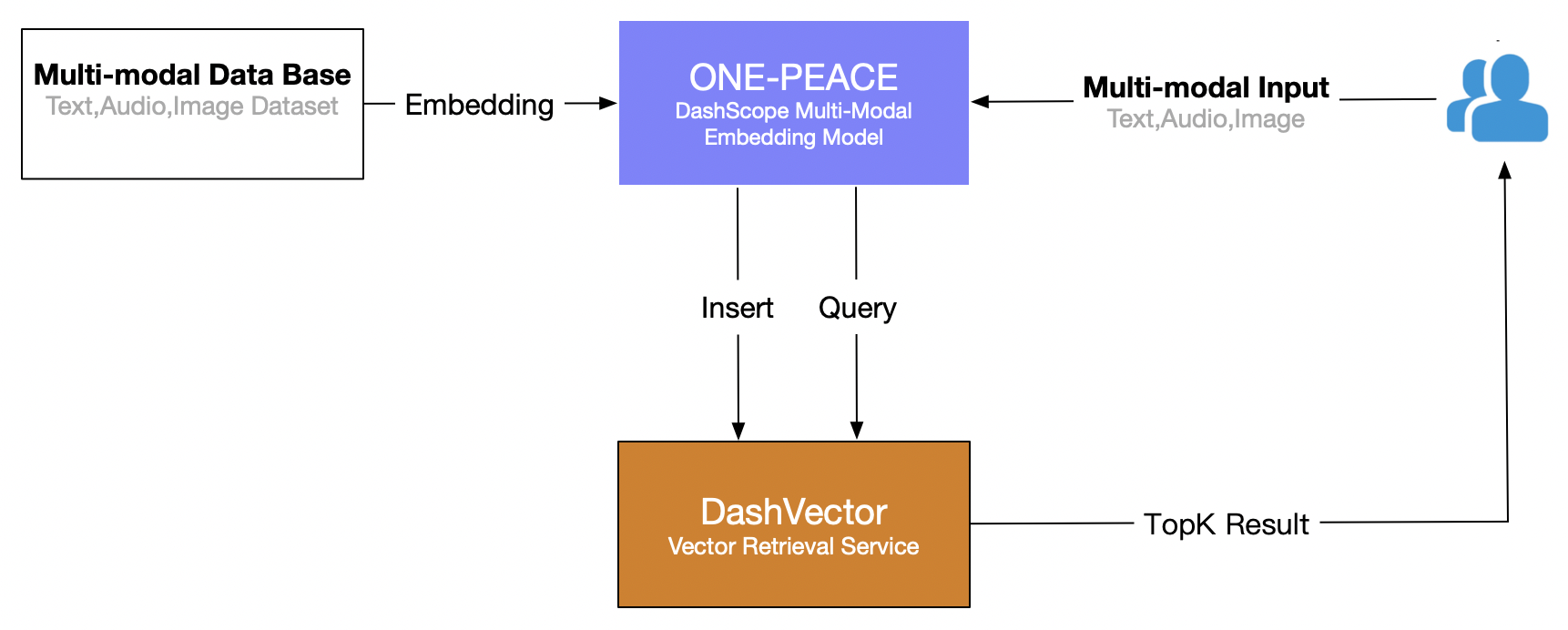
Prerequisiti
- Apri il servizio modello Lingji e ottieni API-KEY:Attiva DashScope e crea API-KEY
- Servizio di recupero vettoriale aperto: vedereAbbonarsi ad un servizio。
- Crea servizio di recupero vettoriale API-KEY: vediGestione API-KEY。
Preparazione ambientale
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
preparazione dei dati
illustrare
Poiché il servizio modello ONE-PEACE di DashScope attualmente supporta solo input di immagini e audio sotto forma di URL, è necessario caricare anticipatamente il set di dati nell'archivio di rete pubblica (come oss/s3) e ottenere l'elenco degli indirizzi URL del corrispondente immagini e audio.
Ho utilizzato l'OSS di Alibaba Cloud per salvare l'immagine e ho ottenuto l'URL dell'immagine accessibile esternamente tramite l'interfaccia del browser OSS: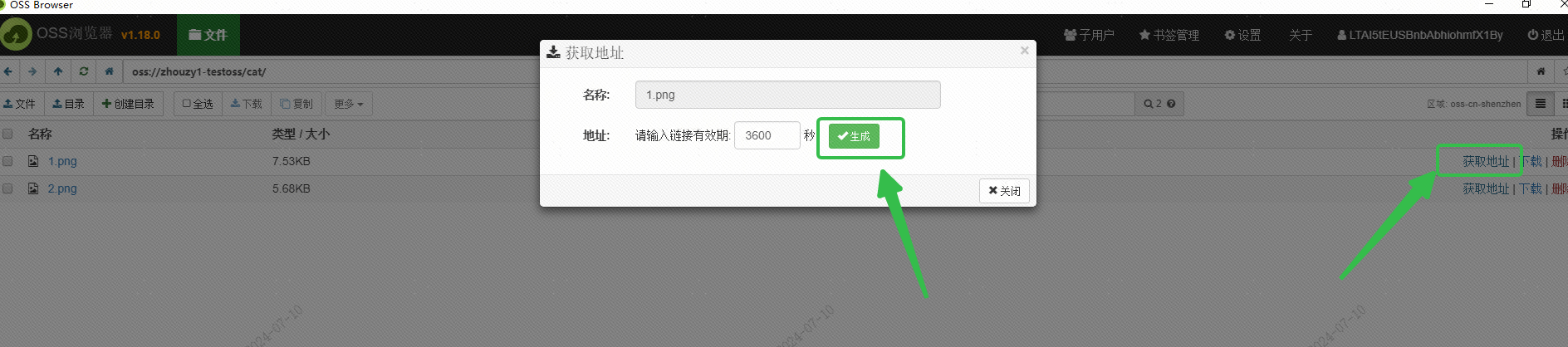
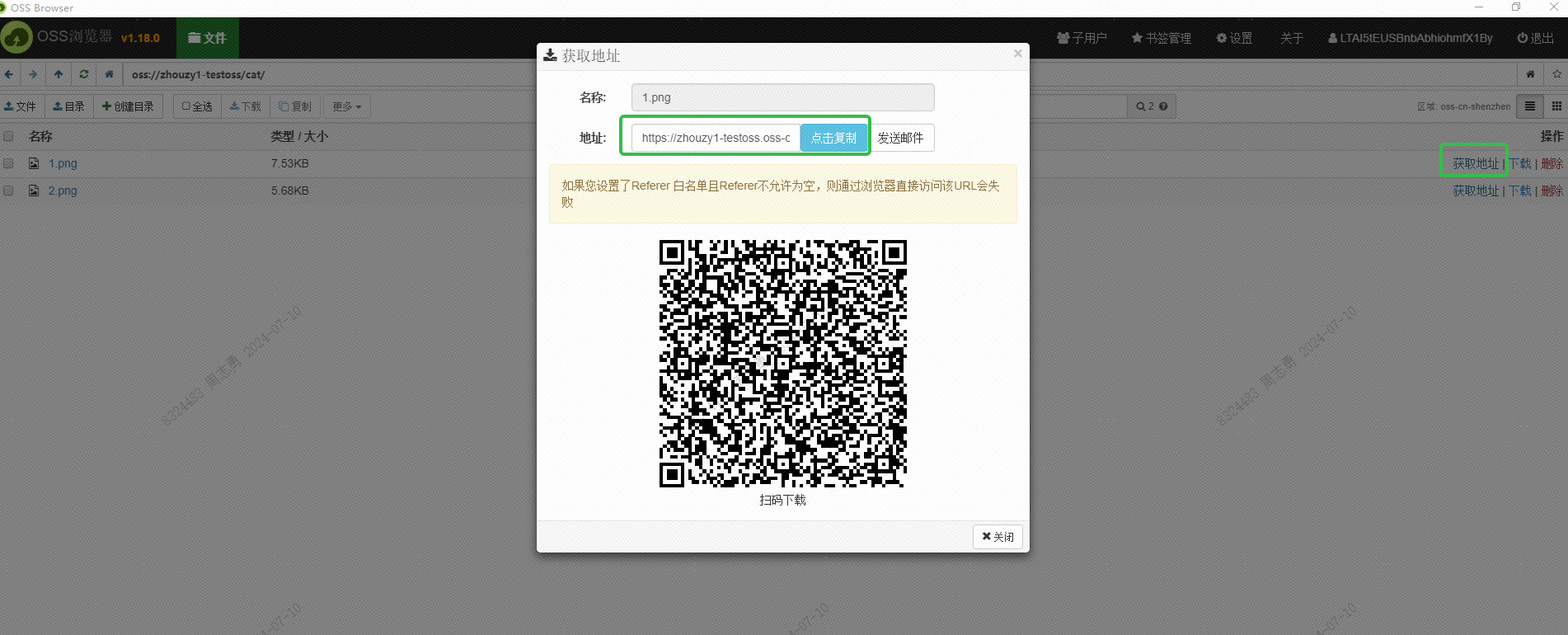
Questo URL dovrebbe essere ottenuto anche tramite l'interfaccia. Questo non è stato ancora studiato. Gli amici interessati possono provare a ottenerlo in batch tramite l'interfaccia. Lo scopo di ottenere questo URL è consentire al servizio DashScope di Alibaba Cloud di leggere l'immagine per l'incorporamento. Salva nel database vettoriale DashVector.
Dopo aver ottenuto l'URL, scrivi l'URL nel nostro imagenet1k-urls.txt file, il nostro codice leggerà il file per incorporarlo successivamente: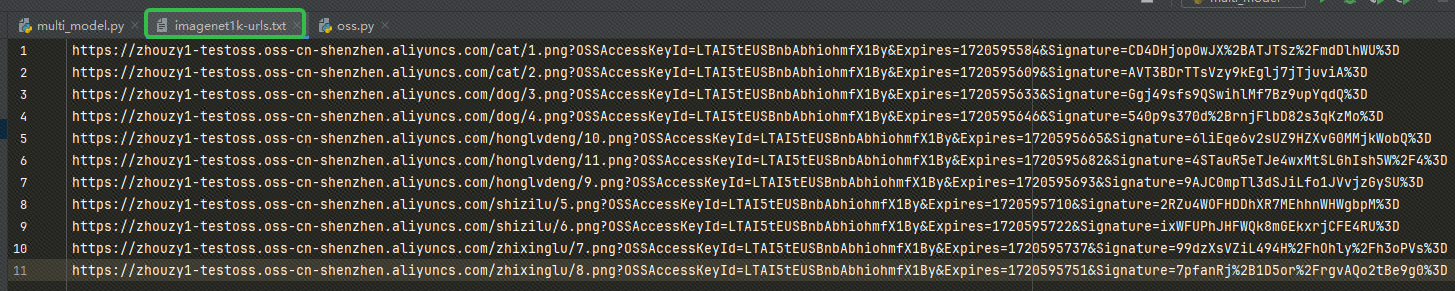
Il codice per eseguire l'incorporamento è il seguente (pubblicherò il codice completo e la struttura della directory in seguito, solo il codice incorporato è pubblicato qui):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHL'URL dell'immagine nell'URL, quindi esegui una richiesta DashScope per vettorizzare e archiviare la nostra immagine.Dopo l'esecuzione, puoi passareConsole del servizio di recupero vettori, controlla i dati del vettore: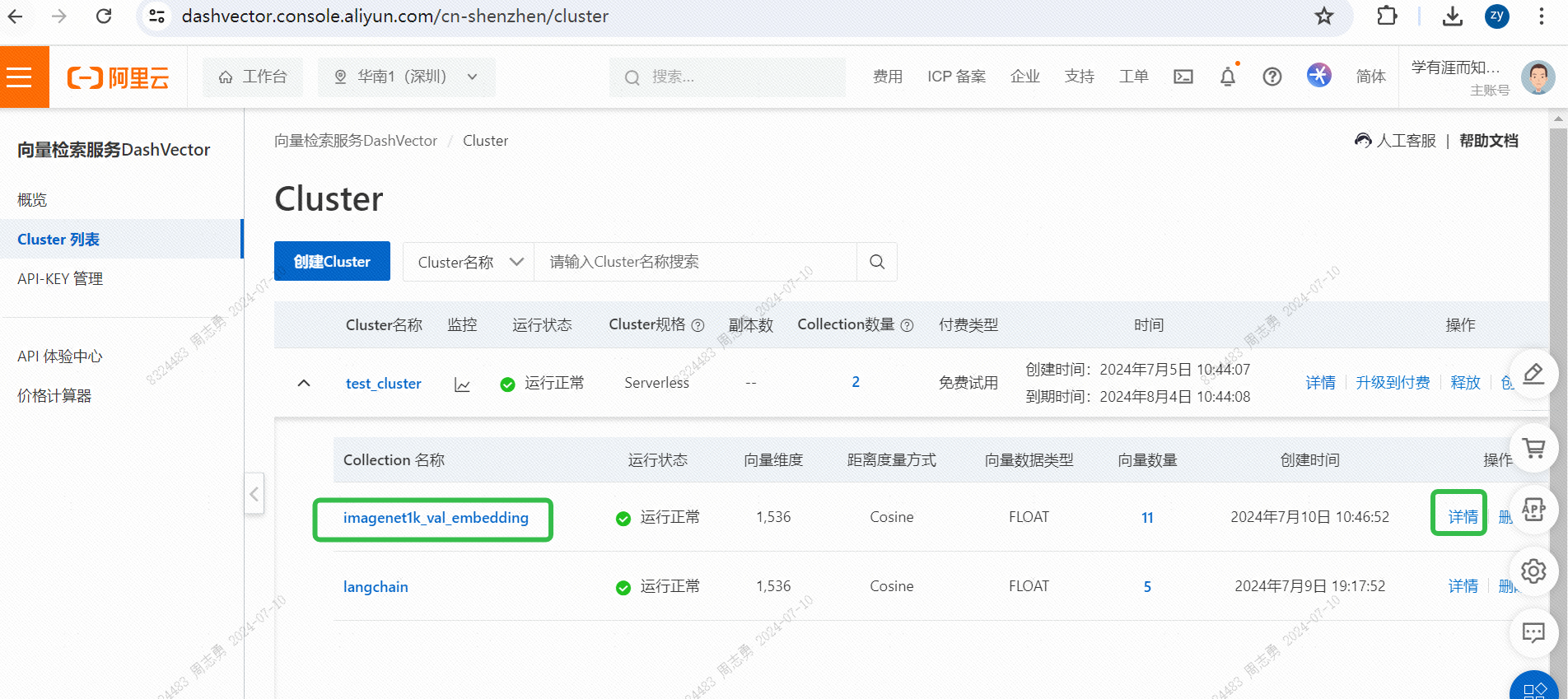
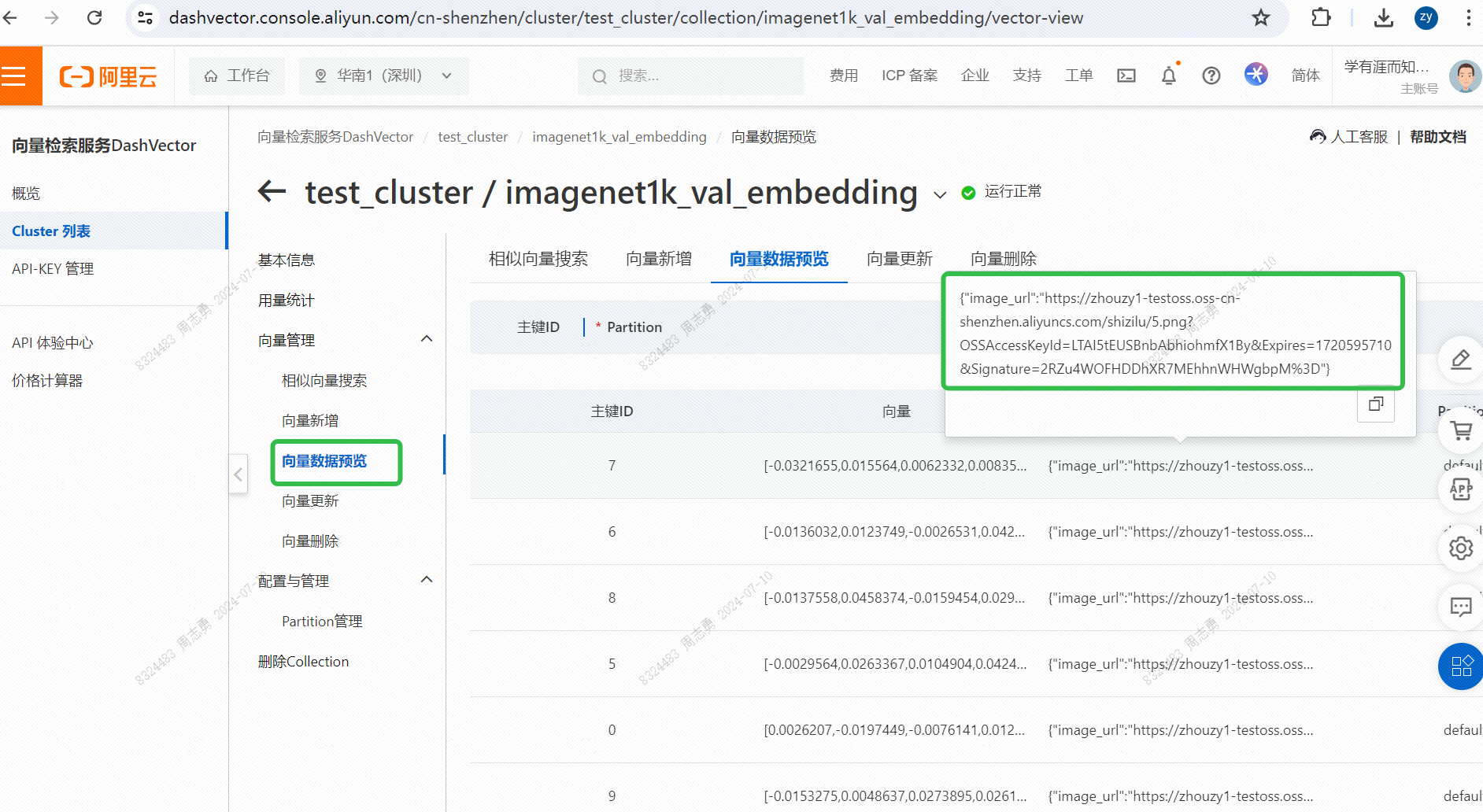
Per recuperare i dati da un database vettoriale tramite testo, inseriscocatDopo aver recuperato tre immagini (topk=3 impostate nel nostro codice), puoi verificare l'effetto. Due sono immagini di gatti, ma una è l'immagine di un cane: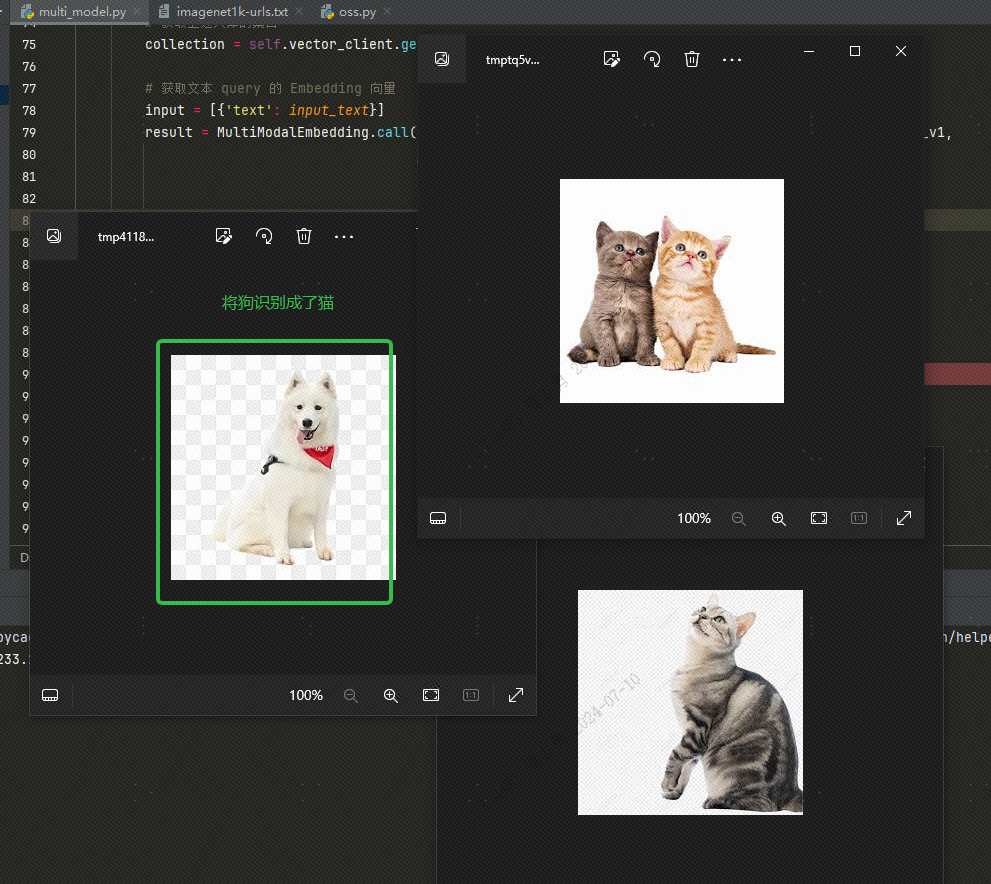
Questo perché ci sono somiglianze tra cani e gatti. Successivamente lo faremotopkImpostato su 2, teoricamente il cane non può essere rilevato. Vediamo l'effetto e, come previsto, non c'è nessun cane: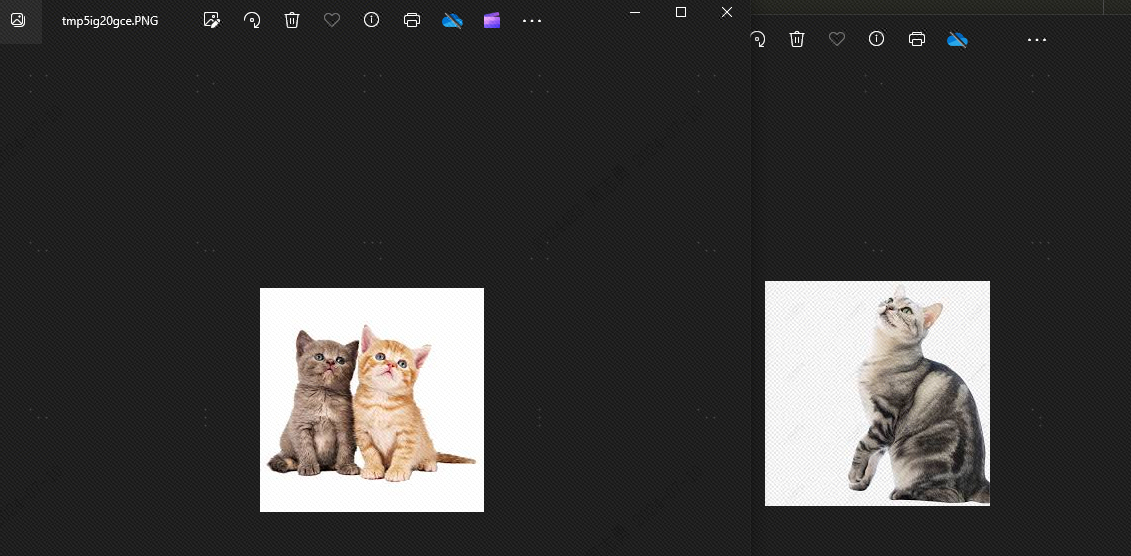
Il motivo per cui compaiono i cani è perché ho memorizzato 4 immagini di animali nella libreria vettoriale, 2 immagini di gatti e 2 immagini di cani. Se il nostro topk è impostato su 3, verrà rilevata un'altra immagine di cane.
multi_model.pyI file sono i seguenti:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTLa struttura della directory del codice è la seguente. Posiziona il file txt e il file py nella stessa directory:
Informazioni aggiuntive
Usa immagini locali: Ho caricato l'immagine su OSS Puoi anche utilizzare un file immagine locale e sostituire il percorso del file in txt con il percorso dell'immagine locale, come segue:
Se utilizziamo immagini locali, dobbiamo modificare il codice sopra e il codice sotto:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]