2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Cet article utilise le service de récupération de vecteurs d'Alibaba Cloud (DashVector), combiné à Modèle multimodal ONE-PEACE , construisez une capacité de récupération multimodale en temps réel de « recherche de texte pour des images ». Le processus global est le suivant :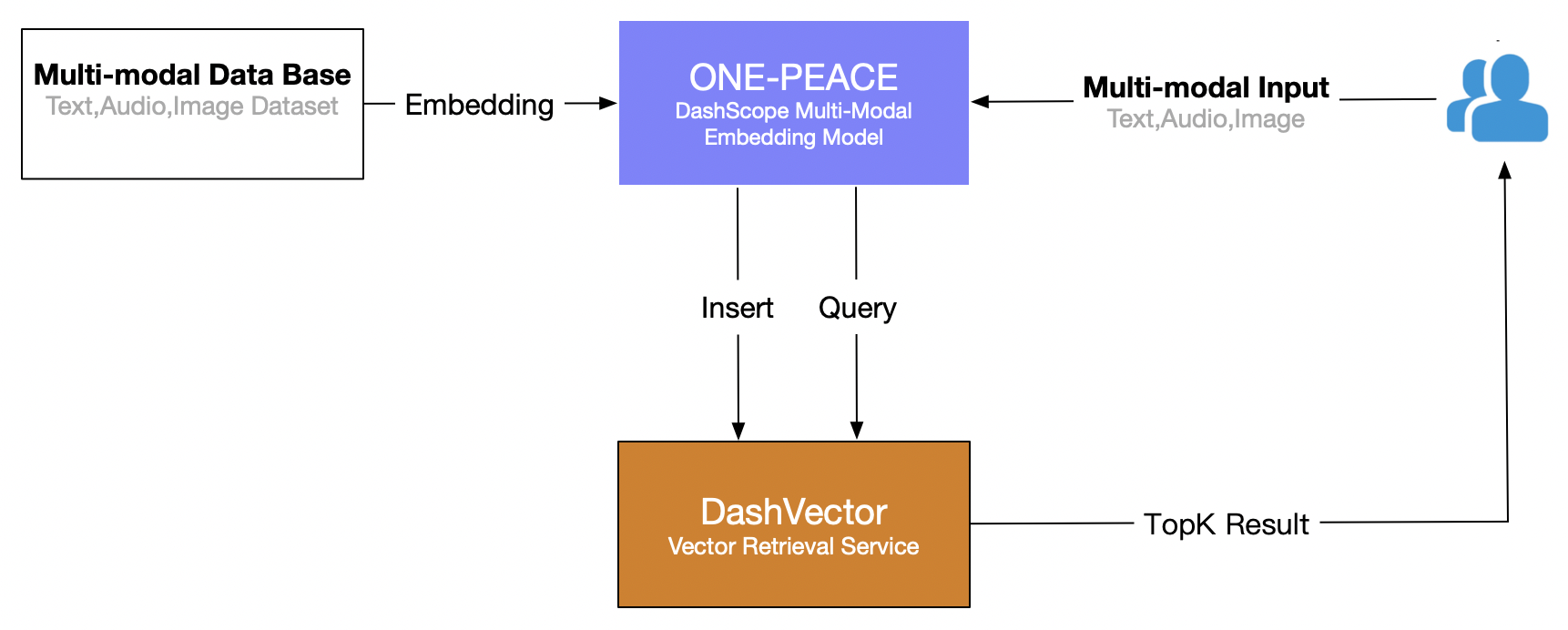
Conditions préalables
- Ouvrez le service de modèle Lingji et obtenez la clé API :Activez DashScope et créez une API-KEY
- Service ouvert de récupération de vecteurs : voirAbonnez-vous à un service。
- Créer un service de récupération de vecteurs API-KEY : voirGestion des API-KEY。
Préparation environnementale
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
préparation des données
illustrer
Étant donné que le service modèle ONE-PEACE de DashScope ne prend actuellement en charge que les entrées d'images et d'audio sous forme d'URL, il est nécessaire de télécharger l'ensemble de données sur un stockage de réseau public (tel que oss/s3) à l'avance et d'obtenir la liste d'adresses URL du correspondant. images et sons.
J'ai utilisé l'OSS d'Alibaba Cloud pour enregistrer l'image et j'ai obtenu l'URL accessible en externe de l'image via l'interface du navigateur OSS :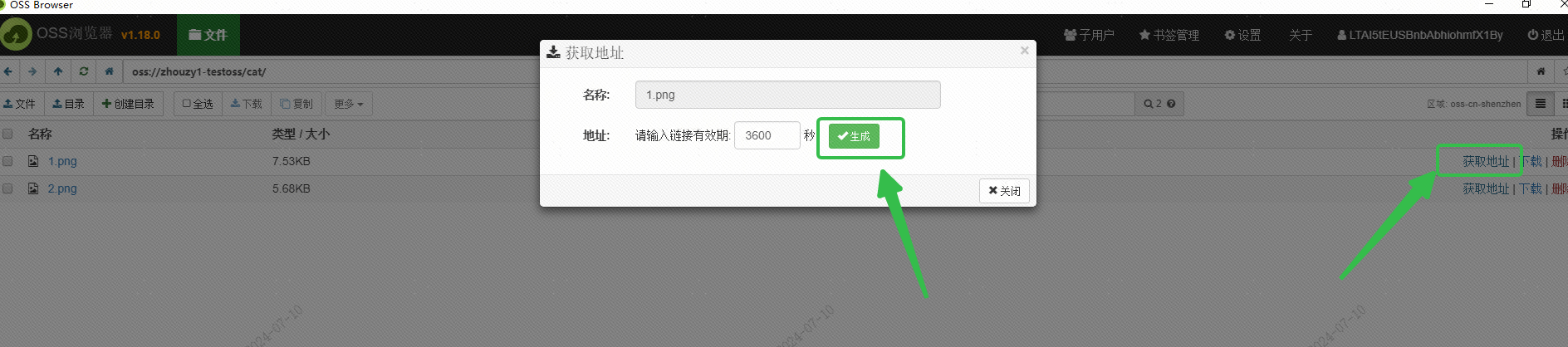
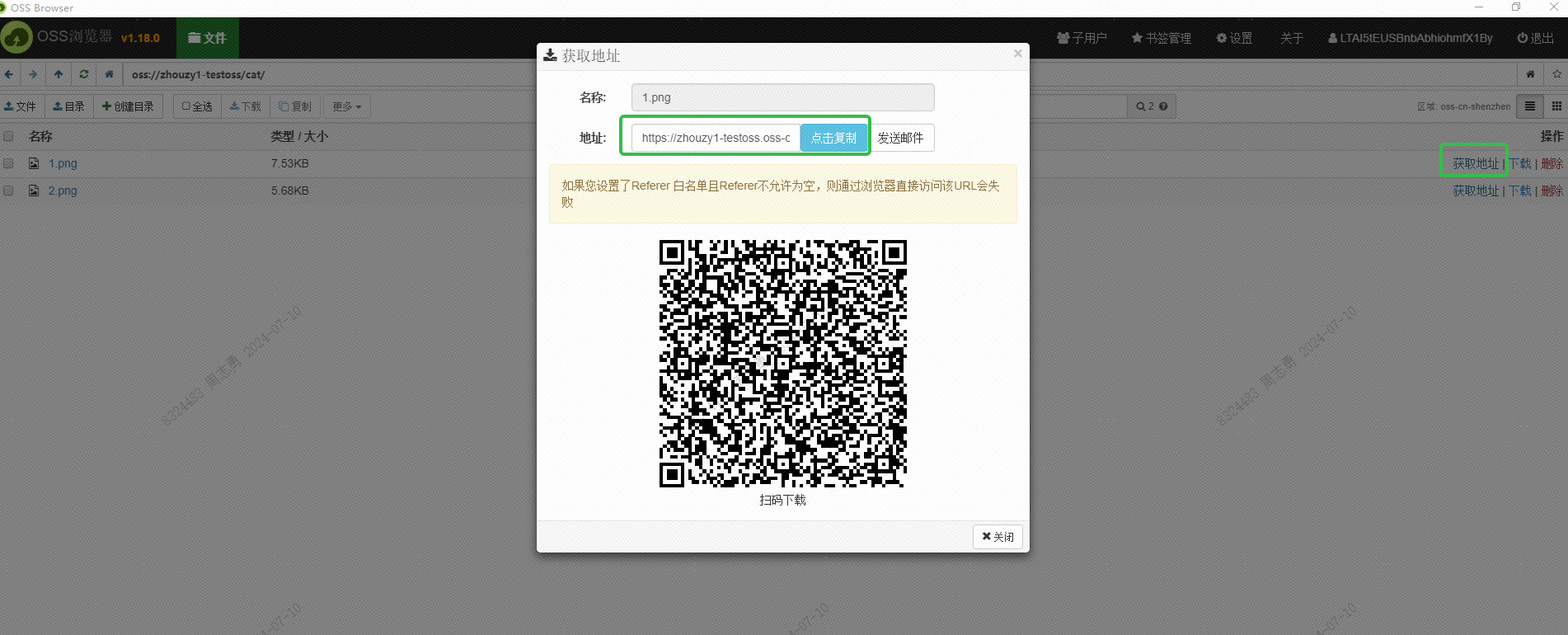
Cette URL doit également être obtenue via l'interface. Cela n'a pas encore été étudié. Les amis intéressés peuvent essayer de l'obtenir par lots via l'interface. Le but de l'obtention de cette URL est de permettre au service DashScope d'Alibaba Cloud de lire l'image pour l'intégration. Enregistrez dans la base de données vectorielles DashVector.
Après avoir obtenu l'URL, écrivez l'URL dans notre imagenet1k-urls.txt fichier, notre code lira le fichier pour l'intégrer plus tard :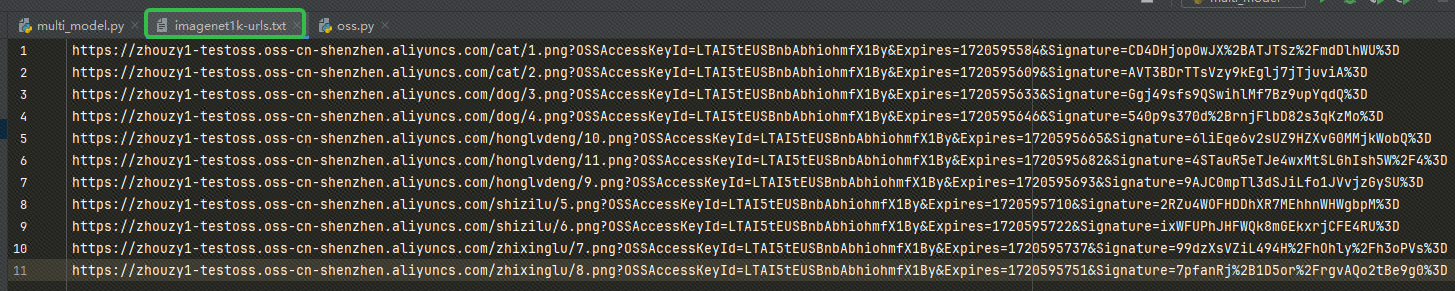
Le code pour exécuter l'intégration est le suivant (je publierai le code complet et la structure des répertoires plus tard, seul le code intégré est publié ici) :
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHL'URL de l'image dans l'URL, puis effectuez une requête DashScope pour vectoriser et stocker notre image.Après exécution, vous pouvez passerConsole de service de récupération de vecteurs, vérifiez les données vectorielles :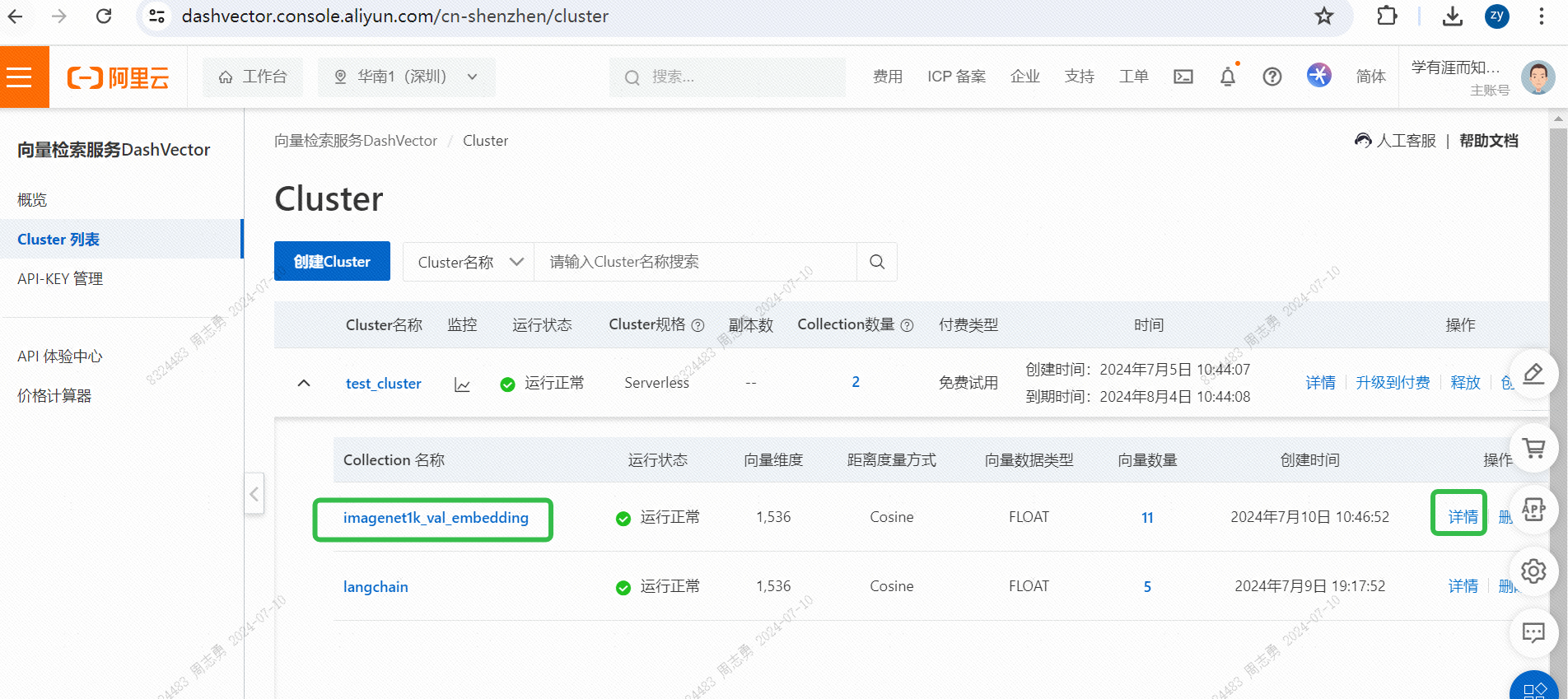
Pour récupérer les données d'une base de données vectorielles par texte, je saisiscatAprès avoir récupéré trois images (topk=3 défini dans notre code), vous pouvez vérifier l'effet. Deux sont des images de chats, mais une est une image de chien :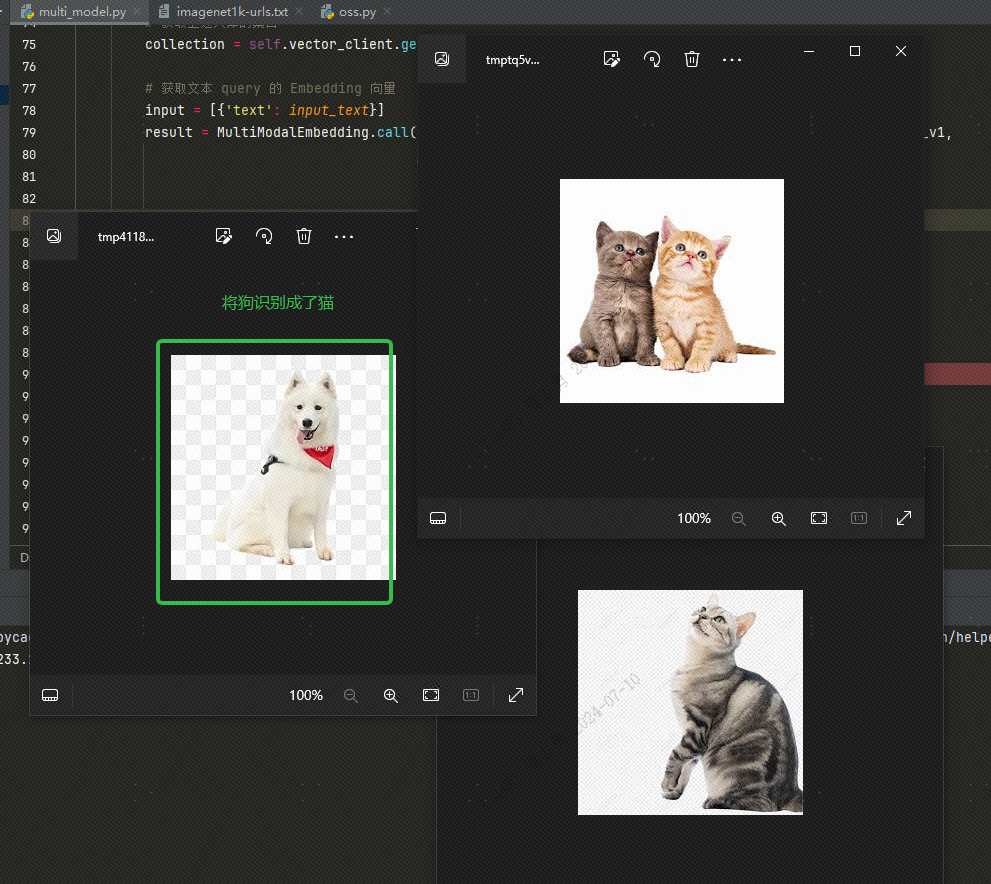
C'est parce qu'il existe des similitudes entre les chiens et les chats.topkRéglé sur 2, théoriquement le chien ne peut pas être détecté. Voyons l'effet, et bien sûr, il n'y a pas de chien :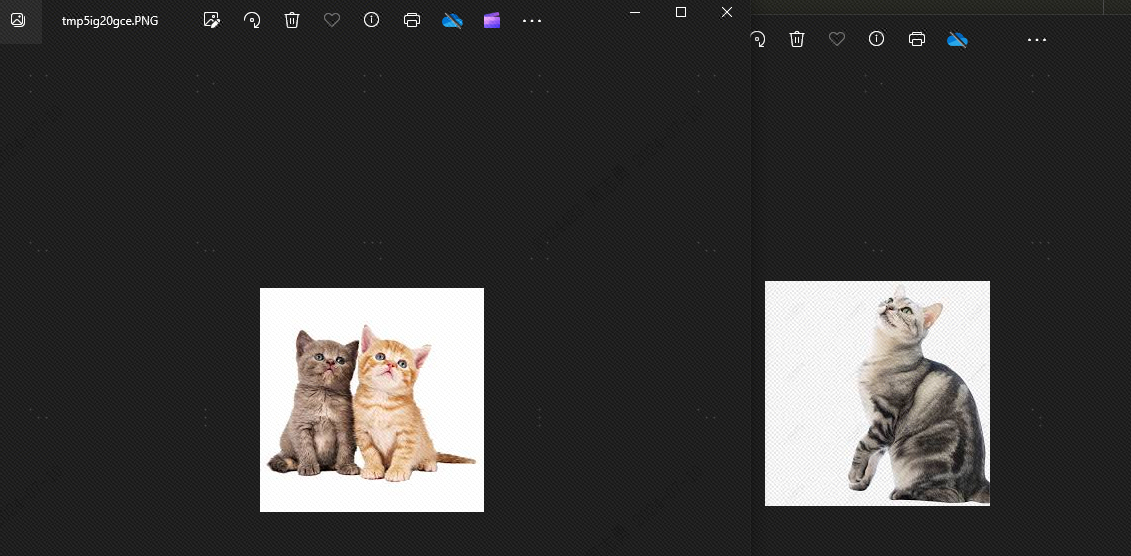
La raison pour laquelle les chiens apparaissent est que j'ai stocké 4 images d'animaux dans la bibliothèque vectorielle, 2 images de chats et 2 images de chiens. Si notre topk est défini sur 3, une image de chien supplémentaire sera détectée.
multi_model.pyLes fichiers sont les suivants :
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTLa structure du répertoire de code est la suivante : placez le fichier txt et le fichier py dans le même répertoire :
Informations Complémentaires
Utiliser des images locales: J'ai téléchargé l'image sur OSS. Vous pouvez également utiliser un fichier image local et remplacer le chemin du fichier dans txt par le chemin de l'image locale, comme suit :
Si nous utilisons des images locales, nous devons modifier le code ci-dessus et modifier le code suivant :
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

