
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Artikel ini menggunakan layanan pengambilan vektor Alibaba Cloud (DashVector), dikombinasikan dengan Model multimodal SATU PERDAMAIAN , untuk membangun kemampuan pengambilan multi-modal waktu nyata dari "pencarian teks untuk gambar". Proses keseluruhannya adalah sebagai berikut: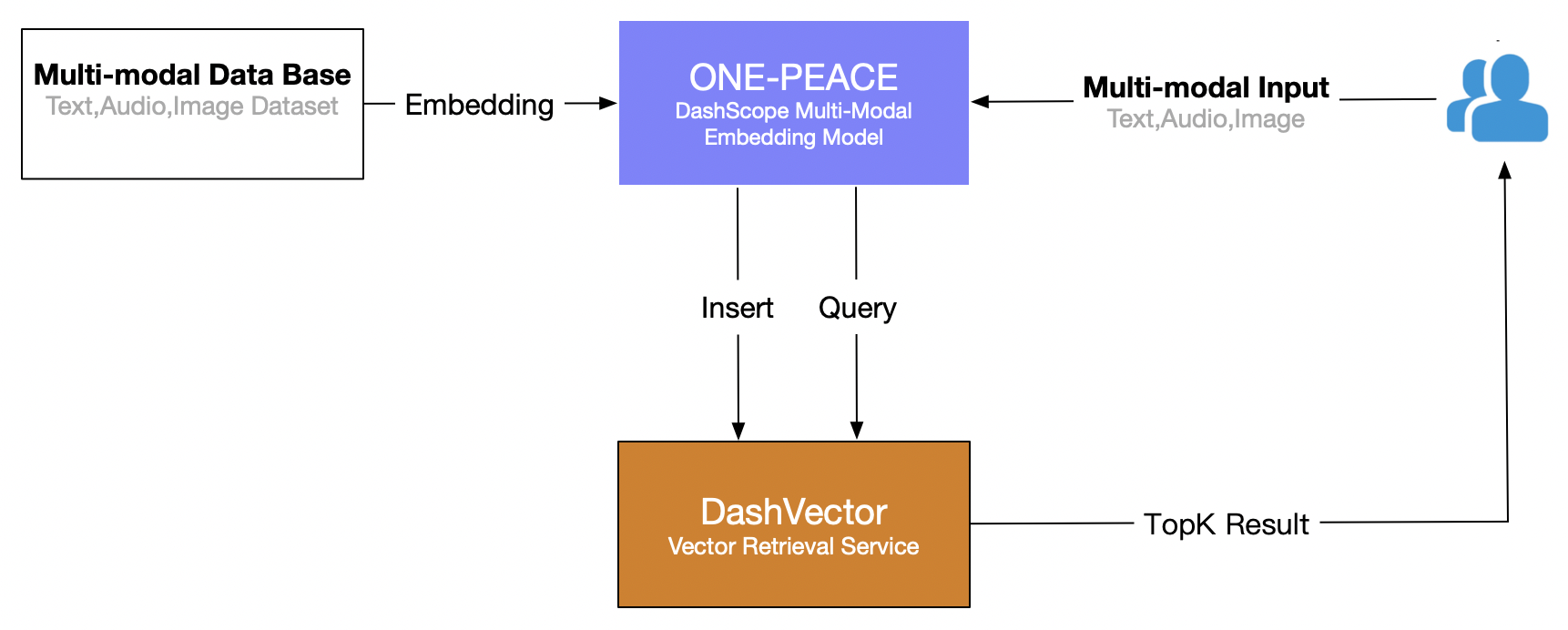
Prasyarat
- Buka layanan model Lingji dan dapatkan API-KEY:Aktifkan DashScope dan buat API-KEY
- Layanan pengambilan vektor terbuka: lihatBerlangganan ke suatu layanan。
- Buat layanan pengambilan vektor API-KEY: lihatManajemen API-KEY。
Persiapan lingkungan
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
persiapan data
menjelaskan
Karena layanan model ONE-PEACE DashScope saat ini hanya mendukung input gambar dan audio dalam bentuk URL, kumpulan data perlu diunggah ke penyimpanan jaringan publik (seperti oss/s3) terlebih dahulu dan dapatkan daftar alamat URL yang sesuai. gambar dan audio.
Saya menggunakan OSS Alibaba Cloud untuk menyimpan gambar, dan memperoleh URL gambar yang dapat diakses secara eksternal melalui antarmuka Browser OSS: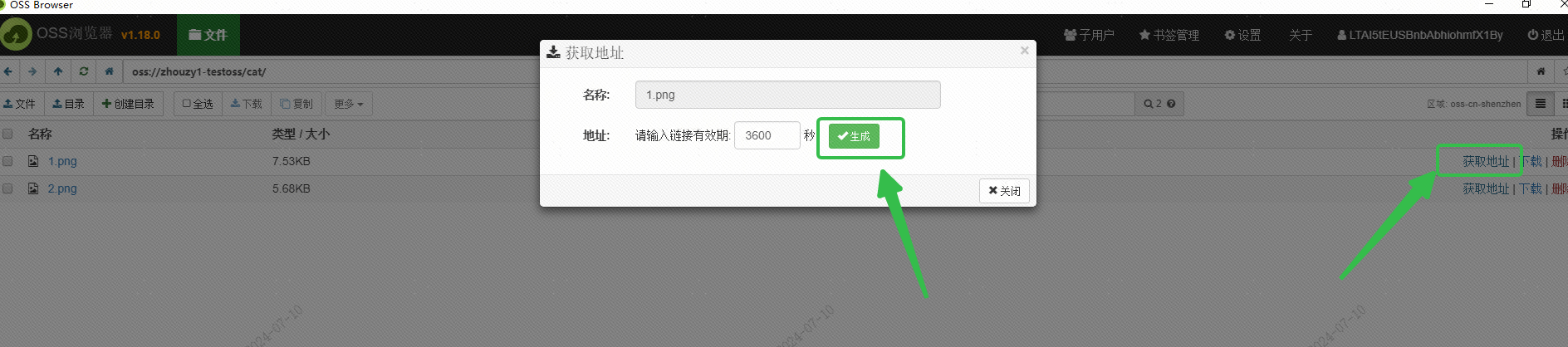
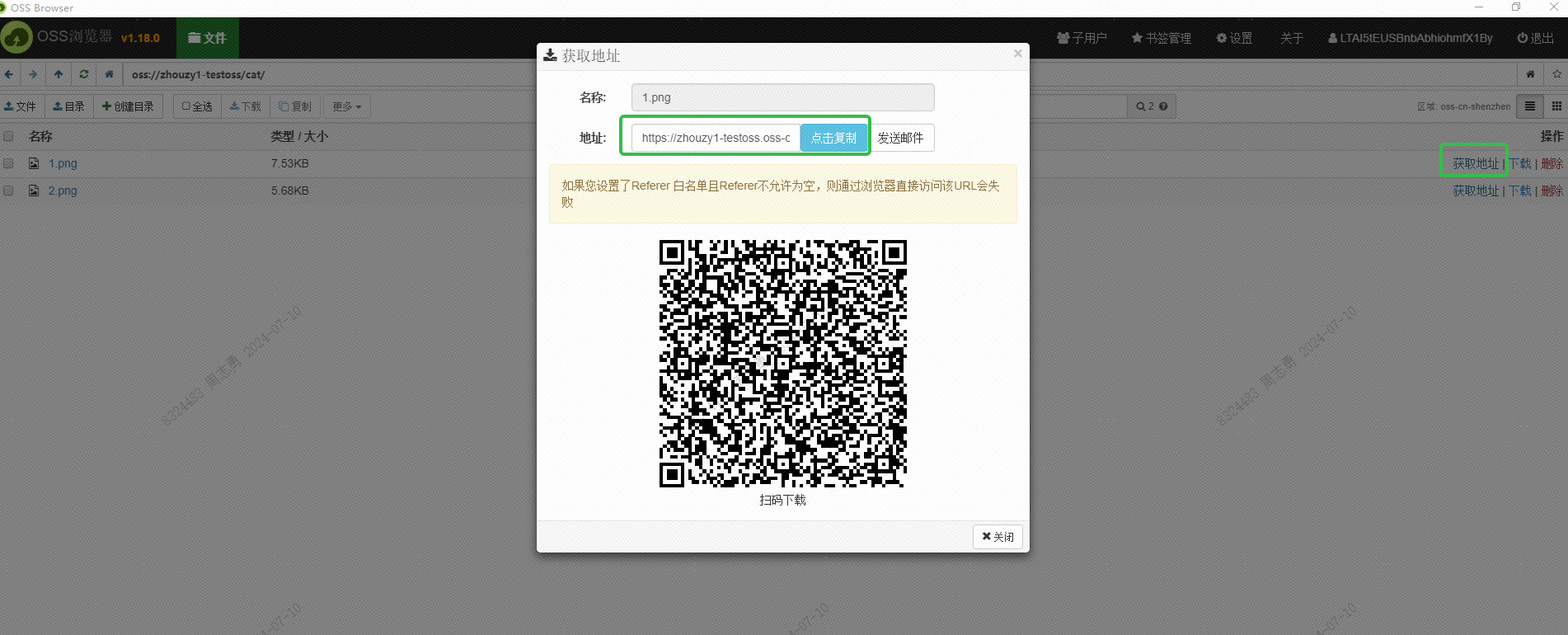
URL ini juga harus diperoleh melalui antarmuka. Ini belum dipelajari. Teman-teman yang tertarik dapat mencoba mendapatkannya secara bertahap melalui antarmuka. Tujuan mendapatkan URL ini adalah untuk memungkinkan layanan DashScope Alibaba Cloud membaca gambar untuk disematkan. Simpan ke database vektor DashVector.
Setelah mendapatkan URL, tuliskan URL tersebut ke milik kita imagenet1k-urls.txt file, kode kita akan membaca file untuk disematkan nanti: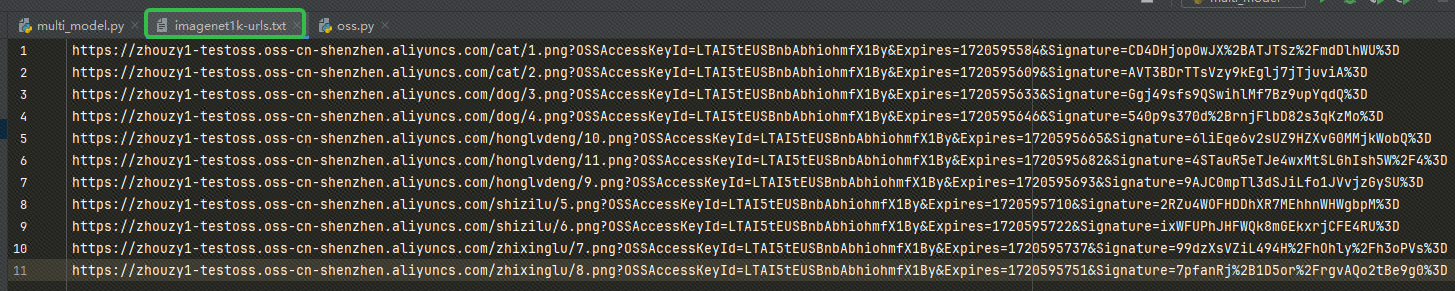
Kode untuk mengeksekusi embedding adalah sebagai berikut (kode lengkap dan struktur direktori akan saya posting nanti, hanya kode embedded yang diposting di sini):
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
IMAGENET1K_URLS_FILE_PATHURL gambar di URL, lalu lakukan permintaan DashScope untuk membuat vektor dan menyimpan gambar kita.Setelah eksekusi, Anda bisa lulusKonsol layanan pengambilan vektor, periksa data vektor: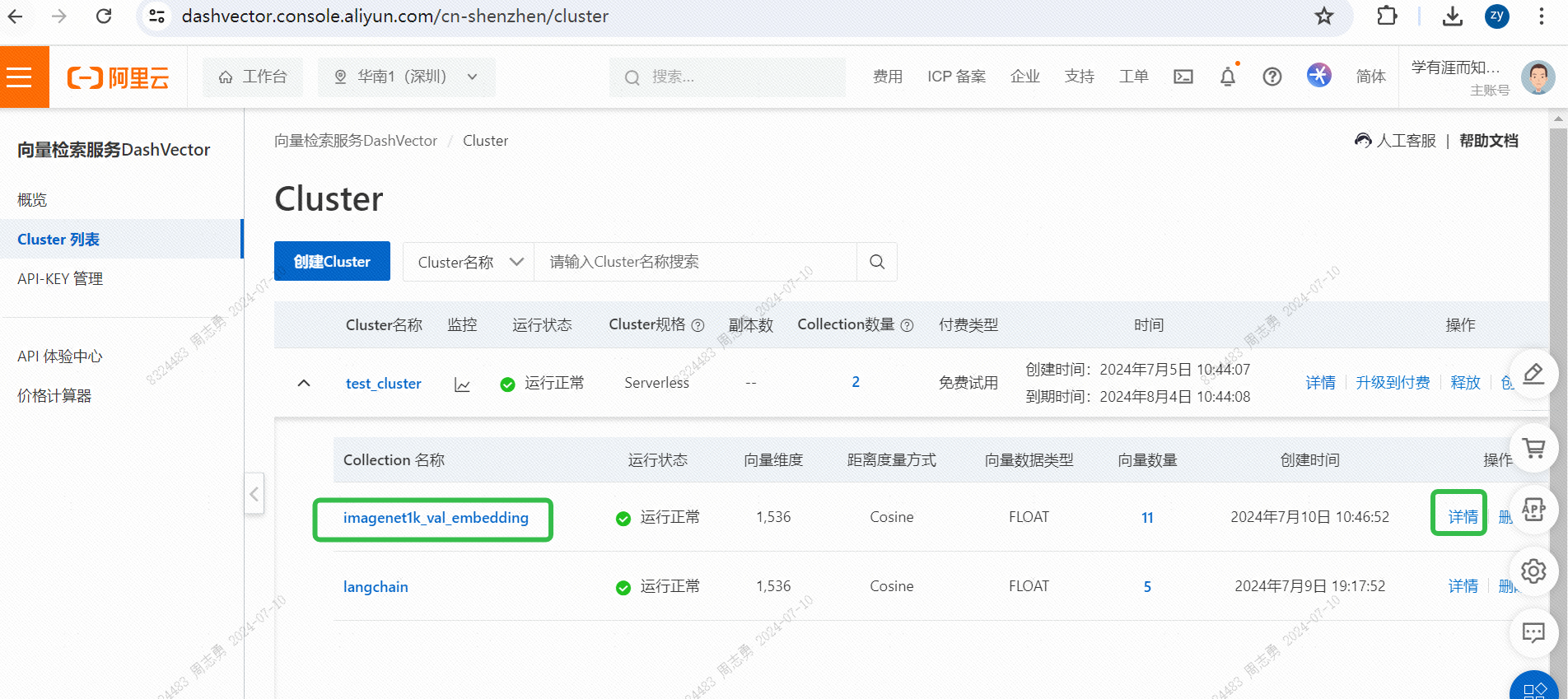
Untuk mengambil data dari database vektor melalui teks, saya entercatSetelah mengambil tiga gambar (topk=3 diatur dalam kode kami), Anda dapat memeriksa efeknya. Dua gambar adalah kucing, tetapi satu adalah gambar anjing: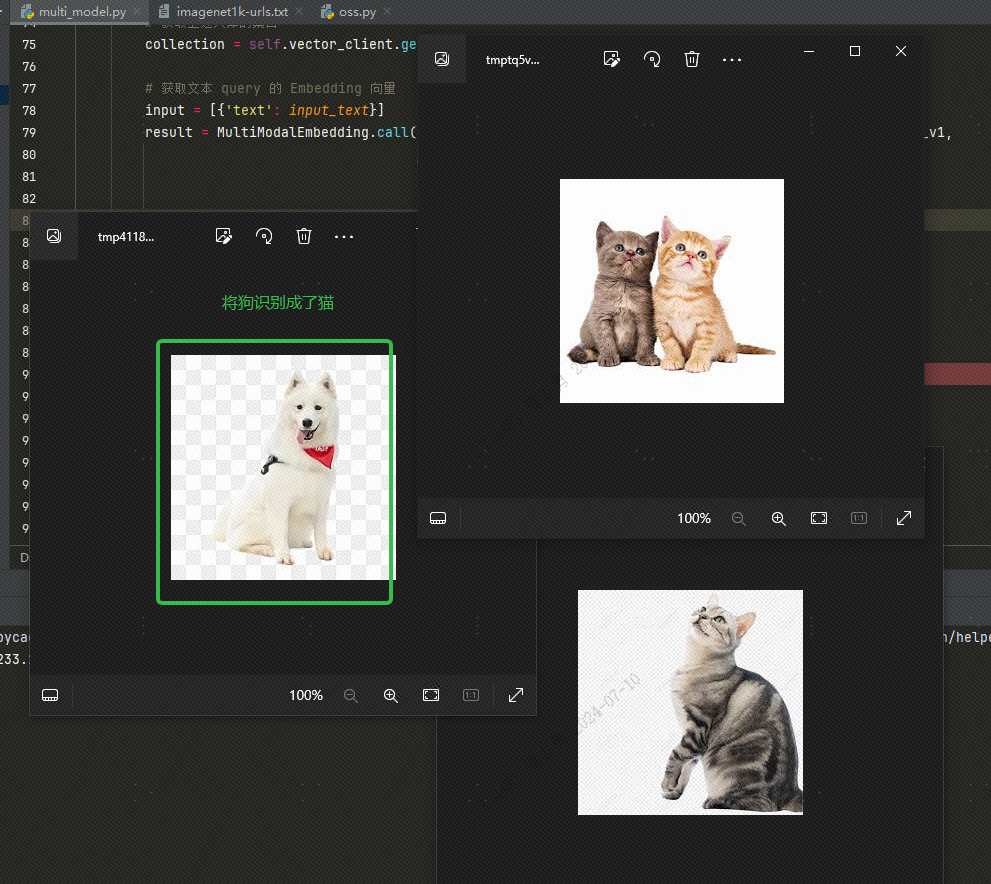
Ini karena ada kesamaan antara anjing dan kucingtopkSetel ke 2, secara teoritis anjing tidak dapat dideteksi. Mari kita lihat efeknya, dan benar saja, tidak ada anjing: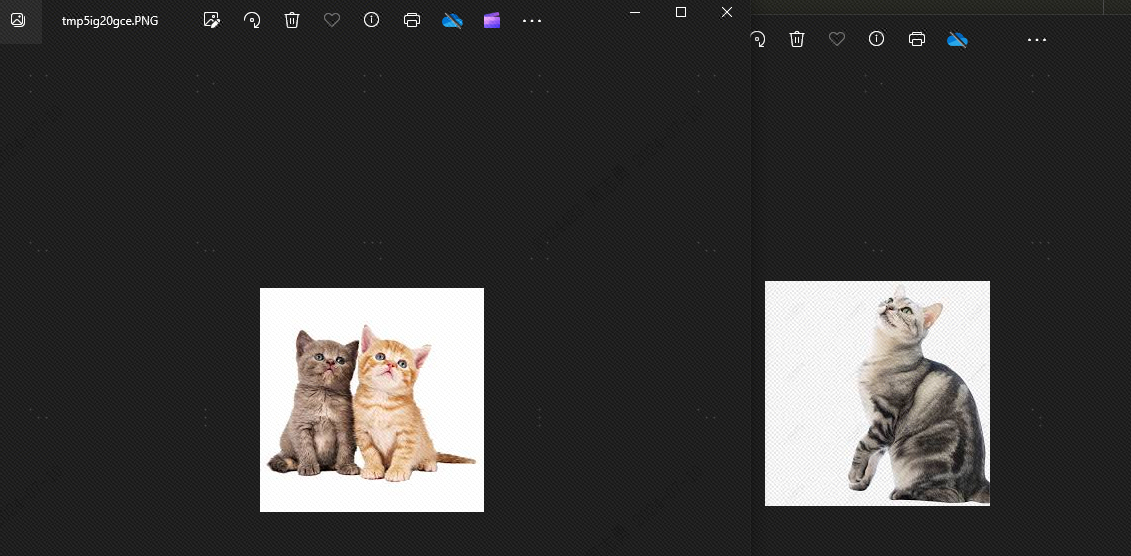
Alasan munculnya anjing karena saya sudah menyimpan 4 gambar binatang di perpustakaan vektor, 2 gambar kucing dan 2 gambar anjing. Jika topk kita diset ke 3, maka akan terdeteksi satu gambar anjing lagi.
multi_model.pyFile-file tersebut adalah sebagai berikut:
import os
import dashscope
from dashvector import Client, Doc, DashVectorException
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
class DashVectorMultiModel:
def __init__(self):
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
os.environ["DASHVECTOR_ENDPOINT"] = ""
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
# 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到
# 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。
# 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下
self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
self.vector_client = self.init_vector_client()
self.vector_collection_name = 'imagenet1k_val_embedding'
def init_vector_client(self):
return Client(
api_key=os.environ["DASHVECTOR_API_KEY"],
endpoint=os.environ["DASHVECTOR_ENDPOINT"]
)
def index_image(self):
# 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维
collection = self.vector_client.get(self.vector_collection_name)
if not collection:
rsp = self.vector_client.create(self.vector_collection_name, 1536)
collection = self.vector_client.get(self.vector_collection_name)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector
with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
def show_image(self, image_list):
for img in image_list:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
def text_search(self, input_text):
# 获取上述入库的集合
collection = self.vector_client.get('imagenet1k_val_embedding')
# 获取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
api_key=os.environ["DASHSCOPE_API_KEY"],
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=2)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
a = DashVectorMultiModel()
# 执行 embedding 操作
a.index_image()
# 文本检索
text_query = "Traffic light"
a.show_image(a.text_search(text_query))
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINTStruktur direktori kodenya adalah sebagai berikut. Tempatkan file txt dan file py di direktori yang sama:
Informasi tambahan
Gunakan gambar lokal: Saya mengunggah gambar ke OSS. Anda juga dapat menggunakan file gambar lokal dan mengganti jalur file di txt dengan jalur gambar lokal, sebagai berikut:
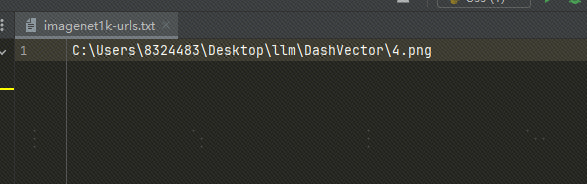
Jika kita menggunakan gambar lokal, kita harus memodifikasi kode di atas dan kode di bawah ini:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码
img = Image.open(img_url)

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. "Saya telah memberikan banyak kontribusi di bidang dokumentasi pengembang stasiun sumber terbuka untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]