Datenbank-Notfallwiederherstellung |. Ausführlicher Vergleich zwischen MySQL MGR und Alibaba Cloud PolarDB-X Paxos
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Open-Source-Ökosystem
Wie wir alle wissen, erreichen die primären und sekundären MySQL-Datenbanken (zwei Knoten) im Allgemeinen eine hohe Datenverfügbarkeit durch asynchrone Replikation und halbsynchrone Replikation (Semi-Sync). Bei der primären und sekundären Architektur treten nach dem HA-Wechsel schwerwiegende Probleme auf. Es besteht die Wahrscheinlichkeit einer Dateninkonsistenz (bezeichnet als RPO!=0).Solange die Geschäftsdaten von gewisser Bedeutung sind, sollten Sie daher kein Datenbankprodukt mit MySQL-Primär- und Sekundärarchitektur (zwei Knoten) wählen. Es wird empfohlen, eine Multi-Copy-Architektur mit RPO=0 zu wählen.
MySQL-Community zur Entwicklung der Multi-Copy-Technologie mit RPO=0:
- MySQL ist offiziell Open Source und hat die auf Gruppenreplikation basierende Hochverfügbarkeitslösung MySQL Group Replication (MGR) eingeführt. Das Paxos-Protokoll ist intern über XCOM gekapselt, um die Datenkonsistenz sicherzustellen.
- Ali Cloud PolarDB-X , abgeleitet aus der Geschäftspolitur und Verifizierung von Alibabas E-Commerce-Double-Eleven und mehreren Aktivitäten an verschiedenen Orten, wird es im Oktober 2021 im gesamten Kern als Open Source verfügbar sein und das MySQL-Open-Source-Ökosystem vollständig umfassen. PolarDB-X ist als zentralisierte und verteilte integrierte Datenbank positioniert. Sein Datenknoten Data Node (DN) übernimmt das selbst entwickelte X-Paxos-Protokoll und ist hochkompatibel mit MySQL 5.7/8.0. Es bietet nicht nur Hochverfügbarkeitsfunktionen auf finanzieller Ebene , aber auch Es verfügt über die Merkmale einer hoch skalierbaren Transaktions-Engine, einer flexiblen Betriebs- und Wartungswiederherstellung sowie einer kostengünstigen Datenspeicherung. Referenz: „PolarDB-X Open Source |. Drei Kopien von MySQL basierend auf Paxos》。
PolarDB-X Das Konzept der zentralisierten und verteilten Integration: Der Datenknoten-DN kann unabhängig als zentralisiertes Formular (Standardversion) verwendet werden, das vollständig mit dem eigenständigen Datenbankformular kompatibel ist. Wenn das Unternehmen so weit wächst, dass eine verteilte Erweiterung erforderlich ist, wird die Architektur vor Ort auf eine verteilte Form aktualisiert und die verteilten Komponenten werden nahtlos mit den ursprünglichen Datenknoten verbunden. Es ist keine Datenmigration oder Änderung auf der Anwendungsseite erforderlich , und Sie können die Benutzerfreundlichkeit und Skalierbarkeit genießen, die diese Formel und Architekturbeschreibung mit sich bringt:„Zentralisierte verteilte Integration“
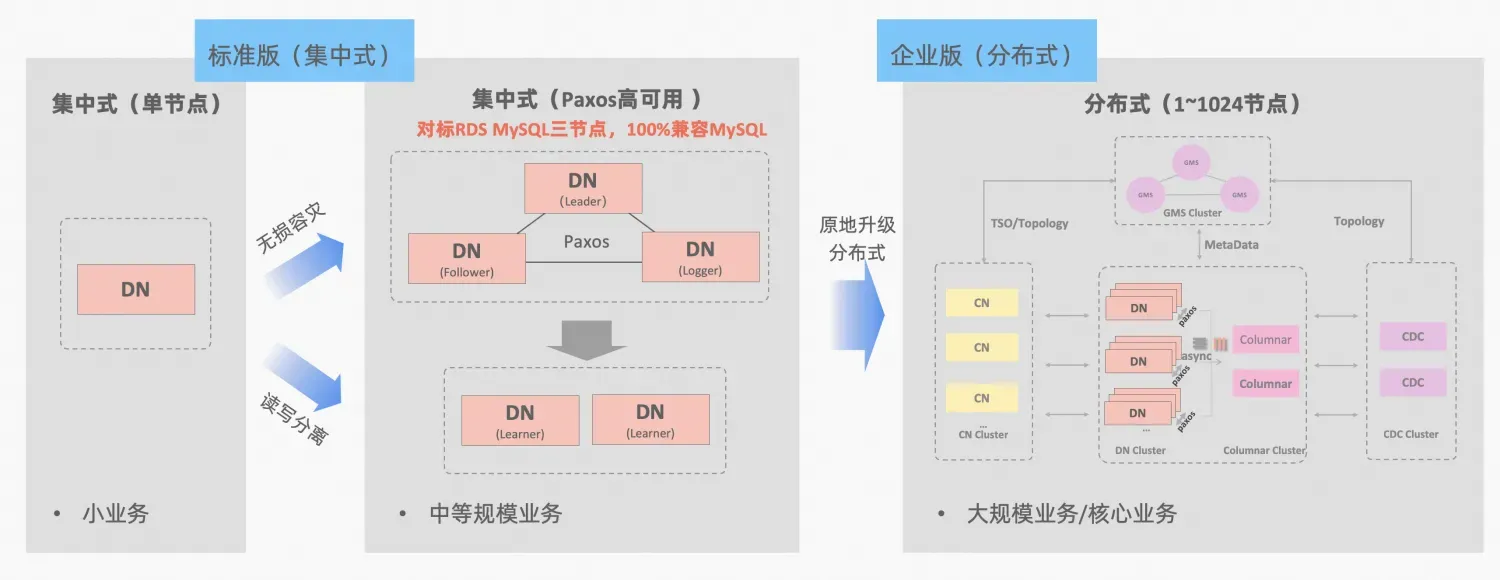
MySQLs MGR und PolarDB-Xs Standardversion DN nutzen beide das Paxos-Protokoll nach dem niedrigsten Prinzip. Was sind also die spezifischen Leistungen und Unterschiede bei der tatsächlichen Verwendung? In diesem Artikel werden die Aspekte des Architekturvergleichs, der Hauptunterschiede und des Testvergleichs näher erläutert.
MGR/DN-Abkürzungsbeschreibung: MGR stellt die technische Form von MySQL MGR dar, und DN stellt die technische Form von PolarDB-X Single DN Centralized (Standardversion) dar.
Kurz zusammengefasst
Die detaillierte Vergleichsanalyse ist relativ lang, daher können Sie zuerst die Zusammenfassung und das Fazit lesen. Wenn Sie interessiert sind, können Sie der Zusammenfassung folgen und in nachfolgenden Artikeln nach Hinweisen suchen.
MySQL MGR wird nicht für allgemeine Unternehmen und Firmen empfohlen, da es professionelles technisches Wissen und ein Betriebs- und Wartungsteam erfordert, um es gut zu nutzen. Dieser Artikel reproduziert auch drei „versteckte Fallstricke“ von MySQL MGR, die seit langem in der Branche kursieren :
- Dark Pit 1: MySQL MGR- und Zeigen Sie einen Parameter an und konfigurieren Sie ihn, um dies sicherzustellen. Derzeit kann das Design von MGR nicht sowohl Leistung als auch RPO erreichen.
- Fallstrick 2: Die Leistung von MySQL MGR ist schlecht, wenn es zu Netzwerkverzögerungen kommt. Der Artikel testete einen Vergleich von 4-Minuten-Netzwerkszenarien (einschließlich drei Computerräumen in derselben Stadt und drei Zentren an zwei Orten). Stadtleistungsparameter, es ist nur 1/5 davon in derselben Stadt, wenn die Datengarantie von RPO=0 aktiviert ist, wird die Leistung noch schlechter.Daher eignet sich MySQL MGR besser für die Verwendung im selben Computerraumszenario, ist jedoch nicht für die computerraumübergreifende Notfallwiederherstellung geeignet.
- Fallstrick 3: In der Multi-Copy-Architektur von MySQL MGR führt der Ausfall des Standby-Knotens dazu, dass der Datenverkehr des Master-Knoten-Leaders auf 0 sinkt, was nicht mit dem gesunden Menschenverstand vereinbar ist. Der Artikel konzentriert sich auf den Versuch, den Single-Leader-Modus von MGR (im Vergleich zur vorherigen Master-Slave-Replikatarchitektur) zu aktivieren und die beiden Aktionen Ausfallzeit und Wiederherstellung des Slave-Knotens zu simulieren Der Datenverkehr sank auf 0 (dauert etwa 10 Sekunden) und die allgemeine Bedienbarkeit und Wartbarkeit war relativ schlecht.Daher stellt MySQL MGR relativ hohe Anforderungen an den Betrieb und die Wartung des Hosts und erfordert ein professionelles DBA-Team.
Im Vergleich zu MySQL MGR weist PolarDB-X Paxos keine ähnlichen Nachteile wie MGR in Bezug auf Datenkonsistenz, computerraumübergreifende Notfallwiederherstellung sowie Knotenbetrieb und -wartung auf. Allerdings weist es auch einige kleinere Mängel und Vorteile bei der Notfallwiederherstellung auf:
- In einem einfachen Szenario desselben Computerraums sind die Leseleistung bei geringer Parallelität und die reine Schreibleistung bei hoher Parallelität geringfügig um etwa 5 % niedriger als bei MySQL MGR. Es werden mehrere Kopien gleichzeitig über das Netzwerk gesendet Es gibt Raum für weitere Leistungsoptimierungen.
- Vorteile: 100 % kompatibel mit den Funktionen von MySQL 5.7/8.0. Gleichzeitig wurden optimierte Optimierungen bei der Multi-Copy-Standby-Datenbankreplikation und den Failover-Pfaden vorgenommen. RTO für Hochverfügbarkeit <= 8 Sekunden -Minuten-Disaster-Recovery-Szenario in der Branche. Alle funktionieren gut und können Semi-Sync (Semi-Sync), MGR usw. ersetzen.
1. Architekturvergleich
Glossar
MGR/DN-Abkürzungsbeschreibung:
- MGR: Die technische Form von MySQL MGR, die Abkürzung für den nachfolgenden Inhalt: MGR
- DN: Alibaba Cloud PolarDB-X ist eine zentralisierte (Standardversion) technische Form. Der verteilte Datenknoten DN kann unabhängig als zentralisierte (Standardversion) Form verwendet werden. Der folgende Inhalt ist abgekürzt als: DN
MGR
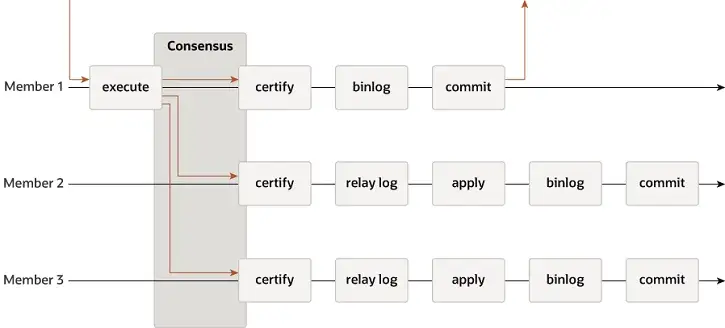
MGR unterstützt Single-Master- und Multi-Master-Modi und verwendet das Replikationssystem von MySQL vollständig wieder, einschließlich Event, Binlog & Relaylog, Apply, Binlog Apply Recovery und GTID. Der Hauptunterschied zu DN besteht darin, dass der Einstiegspunkt für die MGR-Transaktionsprotokollmehrheit, um einen Konsens zu erzielen, vor der Festschreibung der Hauptdatenbanktransaktion liegt.
-
- Bevor die Transaktion festgeschrieben wird, wird die Hook-Funktion before_commit group_replication_trans_before_commit aufgerufen, um in die Mehrheitsreplikation von MGR einzutreten.
- MGR verwendet das Paxos-Protokoll, um die auf THD zwischengespeicherten Binlog-Ereignisse mit allen Online-Knoten zu synchronisieren
- Nach Erhalt der Mehrheitsantwort stellt MGR fest, dass die Transaktion übermittelt werden kann
- THD tritt in den Transaktionsgruppenübermittlungsprozess ein und beginnt mit dem Schreiben der lokalen Binlog-Update-Redo-Antwort-Client-OK-Nachricht
-
- Die Paxos Engine von MGR hört weiterhin auf Protokollnachrichten vom Leader
- Nach einem vollständigen Paxos-Konsensprozess wird bestätigt, dass dieses (Batch-)Event eine Mehrheit im Cluster erreicht hat
- Schreiben Sie das empfangene Ereignis in das Relay-Protokoll, IO Thread Apply Relay Log
- Die Relay-Log-Anwendung durchläuft einen vollständigen Gruppenübermittlungsprozess und die Standby-Datenbank generiert schließlich ihre eigene Binlog-Datei.
Der Grund, warum MGR den oben genannten Prozess übernimmt, liegt darin, dass sich MGR standardmäßig im Multi-Master-Modus befindet und jeder Knoten schreiben kann. Daher muss der Follower-Knoten in einer einzelnen Paxos-Gruppe das empfangene Protokoll zuerst in ein RelayLog konvertieren und dann kombinieren Mit der Schreibtransaktion, die es als Leiter zur Übermittlung erhält, wird die Binlog-Datei erstellt, um die endgültige Transaktion im zweistufigen Gruppenübermittlungsprozess zu übermitteln.
DN
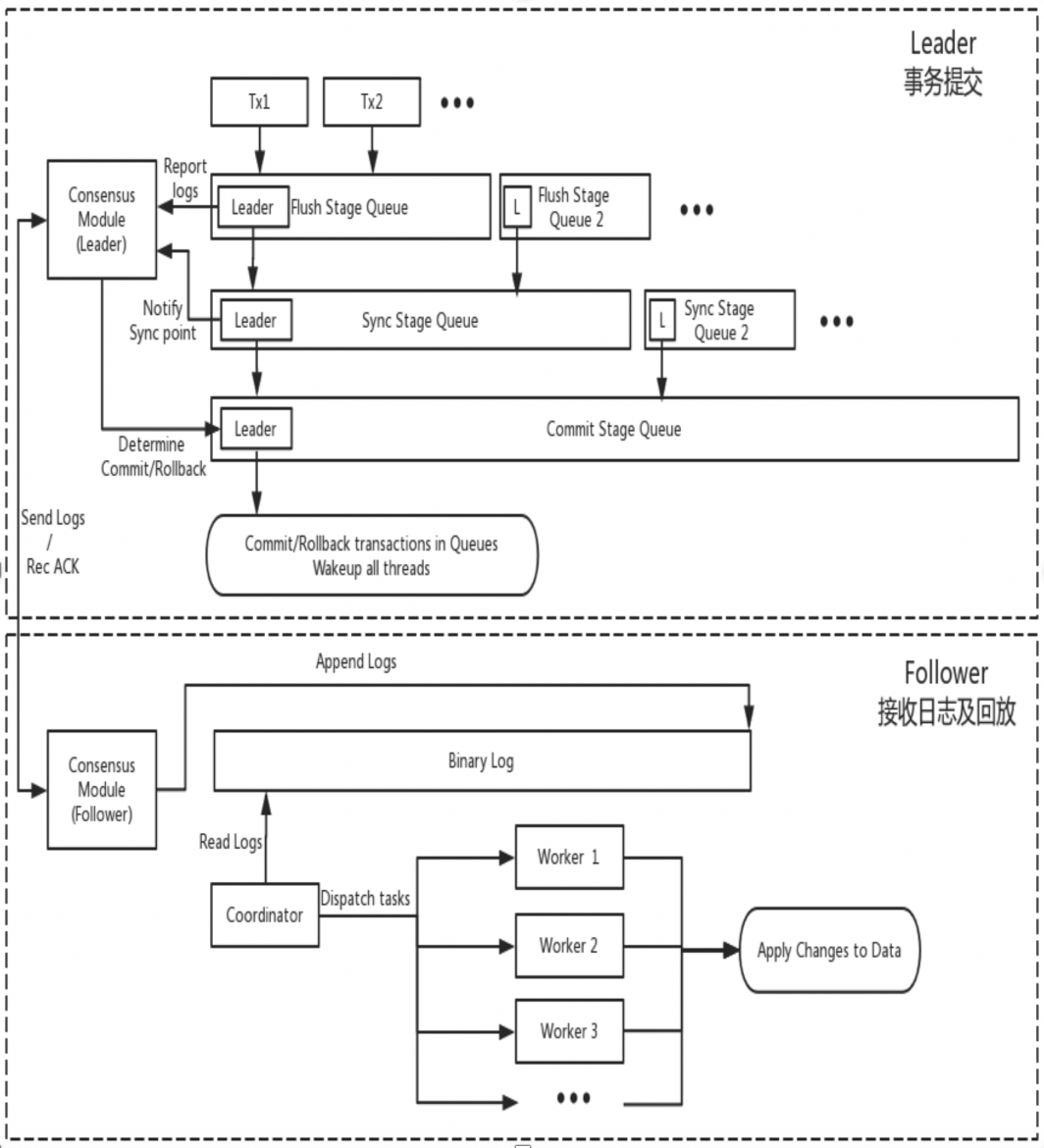
DN verwendet die grundlegende Datenstruktur und den Code auf Funktionsebene von MySQL wieder, integriert jedoch Protokollreplikation, Protokollverwaltung, Protokollwiedergabe und Absturzwiederherstellung eng mit dem X-Paxos-Protokoll, um einen eigenen Satz von Mehrheitsreplikations- und Statusmaschinenmechanismen zu bilden. Der Hauptunterschied zu MGR besteht darin, dass der Einstiegspunkt für die DN-Transaktionsprotokollmehrheit, um einen Konsens zu erzielen, während des Hauptübermittlungsprozesses der Datenbanktransaktion liegt.
-
- Geben Sie den Gruppenübermittlungsprozess der Transaktion ein. In der Flush-Phase der Gruppenübermittlung werden die Ereignisse auf jedem THD in die Binlog-Datei geschrieben und das Protokoll wird dann asynchron über X-Paxos an alle Follower gesendet.
- In der Synchronisierungsphase der Gruppenübermittlung wird zuerst das Binlog beibehalten und dann der X-Paxos-Persistenzspeicherort aktualisiert.
- In der Commit-Phase der Gruppenübermittlung müssen Sie zunächst darauf warten, dass X-Paxos die Mehrheitsantwort erhält, dann die Gruppe von Transaktionen übermitteln und schließlich mit einer OK-Nachricht vom Client antworten.
-
- X-Paxos wartet weiterhin auf Protokollnachrichten vom Leader
- Empfangen Sie ein (Gruppen-)Ereignis, schreiben Sie in das lokale Binlog und antworten Sie
- Die nächste Nachricht wird empfangen, die den Commit-Index der Position enthält, an der die Mehrheit erreicht wurde.
- Der SQL Apply-Thread wendet das empfangene Binlog-Protokoll weiterhin im Hintergrund an und wendet es höchstens auf die Mehrheitsposition an.
Der Grund für dieses Design ist, dass DN derzeit nur den Single-Master-Modus unterstützt, sodass das Protokoll auf der X-Paxos-Protokollebene das Relay-Protokoll selbst weglässt und den Dateninhalt seines persistenten Protokolls und des Leader-Protokolls weglässt sind gleich dem gleichen Preis.
2. Hauptunterschiede
2.1. Effizienz des Paxos-Protokolls

MGR
- Das Paxos-Protokoll von MGR basiert auf dem Mencius-Protokoll, das zur Multi-Paxos-Theorie gehört. Der Unterschied besteht darin, dass Mencius Optimierungsverbesserungen vorgenommen hat, um die Last des Masterknotens zu reduzieren und den Durchsatz zu erhöhen.
- Das Paxos-Protokoll von MGR wird von XCOM-Komponenten implementiert und unterstützt die Bereitstellung im Multi-Master- und Single-Master-Modus. Im Single-Master-Modus sendet das Binlog auf dem Leader-Knoten die Übertragung jedes Nachrichtenstapels (eine Transaktion). ein Standard-Multi-Paxos-Prozess.
- Um den Großteil einer Transaktion zu erfüllen, muss XCOM mindestens drei Nachrichteninteraktionen von Accept+AckAccept+Learn durchlaufen, d. h.Mindestens 1,5 RTT-Overhead.Es sind höchstens drei Nachrichteninteraktionen erforderlich: Prepare+AckPrepare+Accept+AckAccept+Learn.Das heißt insgesamt maximal 2,5 RTT-Overhead
- Da das Paxos-Protokoll mit hoher Kohäsion im XCOM-Modul abgeschlossen wird und das MySQL-Replikationssystem nicht kennt, muss der Leader warten, bis der gesamte Paxos-Prozess abgeschlossen ist, bevor er die Transaktion lokal festschreibt, einschließlich Binlog-Persistenz und Gruppenübermittlung.
- Nachdem der Follower die Mehrheitsübermittlung abgeschlossen hat, speichert er die Ereignisse asynchron im Relay-Protokoll, und dann übermitteln die SQL-Thread-Anwendung und -Gruppe das Produktions-Binlog.
- Da es sich bei dem von Paxos synchronisierten Protokoll um ein Binlog handelt, das vor Eintritt in den Gruppenübermittlungsprozess nicht sortiert wird, stimmt die Reihenfolge der Binlog-Ereignisse auf dem Leader möglicherweise nicht mit der Reihenfolge der Ereignisse im Relay-Protokoll auf dem Follower-Knoten überein.

DN
- Das Paxos-Protokoll von DN basiert auf dem Raft-Protokoll und gehört auch zur Multi-Paoxs-Theorie. Der Unterschied besteht darin, dass das Raft-Protokoll eine stärkere Führungsgarantie und technische Stabilitätsgarantie hat.
- Das Paxos-Protokoll von DN wird durch die X-Paoxs-Komponente vervollständigt. Im Single-Master-Modus sendet das Binlog atomar an den Follower-Knoten .
- Um den Großteil einer Transaktion abzuwickeln, muss X-Paoxs nur die beiden Nachrichteninteraktionen Append+AckAppend durchlaufen, und zwar nur1 RTT-Overhead
- Nachdem der Leader das Protokoll an den Follower gesendet hat, schreibt er die Transaktion fest, solange die Mehrheit zufrieden ist, ohne auf die Übertragung des Commit-Index in der zweiten Phase zu warten.
- Bevor der Follower die Mehrheitsübermittlung abschließen kann, müssen alle Transaktionsprotokolle beibehalten werden. Dies unterscheidet sich erheblich von MGRs XCOM, das diese nur im XCOM-Speicher empfangen muss.
- Der Commit-Index wird in nachfolgenden Nachrichten und Heartbeat-Nachrichten übertragen, und der Follower führt das Apply-Ereignis aus, nachdem der CommitIndex nach oben verschoben wurde.
- Der Binlog-Inhalt von Leader und Follower ist in derselben Reihenfolge, Raft-Protokolle weisen keine Lücken auf und der Batching/Pipeline-Mechanismus wird verwendet, um den Durchsatz der Protokollreplikation zu erhöhen.
- Im Vergleich zu MGR hat der Leader immer nur eine Roundtrip-Verzögerung, wenn eine Transaktion festgeschrieben wird., sehr wichtig für verzögerungsempfindliche verteilte Anwendungen
2.2. RPO
Theoretisch können sowohl Paxos als auch Raft die Datenkonsistenz sicherstellen und die Protokolle, die nach der Crash-Wiederherstellung eine Mehrheit erreicht haben, gehen nicht verloren, es gibt jedoch immer noch Unterschiede in bestimmten Projekten.
MGR
XCOM kapselt das Paxos-Protokoll vollständig und alle seine Protokolldaten werden zunächst im Speicher zwischengespeichert. Standardmäßig ist für Transaktionen, die eine Mehrheit erreichen, keine Protokollpersistenz erforderlich. Wenn die meisten Kuchen ausgefallen sind und der Leader ausfällt, entsteht ein ernstes Problem mit RPO != 0.Gehen Sie von einem Extremszenario aus:
- Der MGR-Cluster besteht aus drei Knoten ABC, von denen AB ein unabhängiger Computerraum in derselben Stadt und C ein stadtübergreifender Knoten ist. A ist der Leader-Knoten, BC der Follower-Knoten
- Initiieren Sie die Transaktion 001 auf dem Knoten Leader A. Wenn die Mehrheit über das Paxos-Protokoll erfüllt ist, kann die Transaktion als übermittelt betrachtet werden. Abschnitt AB bildete die Mehrheit, und Knoten C erhielt das Protokoll der Transaktion 001 aufgrund einer Verzögerung im stadtübergreifenden Netzwerk nicht.
- Im nächsten Moment übermittelt Leader A die Transaktion 001 und gibt Client Success zurück, was bedeutet, dass die Transaktion 001 an die Datenbank übermittelt wurde.
- Zu diesem Zeitpunkt befindet sich auf dem Follower von Knoten B das Protokoll der Transaktion 001 noch im XCOM-Cache und hatte noch keine Zeit, in das RelayLog geleert zu werden. Zu diesem Zeitpunkt hat der Follower von Knoten C die Transaktion 001 noch nicht empfangen Protokoll vom Leiter von Knoten A.
- Zu diesem Zeitpunkt ist Knoten AB ausgefallen, Knoten A fällt aus und kann für längere Zeit nicht wiederhergestellt werden, Knoten B startet neu und erholt sich schnell und Knoten BC stellen weiterhin Lese- und Schreibdienste bereit.
- Da das Transaktionsprotokoll 001 während der Ausfallzeit nicht im RelayLog von Knoten B gespeichert war und auch nicht von Knoten C empfangen wurde, hat der BC-Knoten zu diesem Zeitpunkt tatsächlich die Transaktion 001 verloren und kann sie nicht abrufen.
- In diesem Szenario, in dem die Mehrheitspartei am Boden liegt, ist RPO!=0
Gemäß den Standardparametern der Community erfordern die meisten Transaktionen keine Protokollpersistenz und garantieren keinen RPO=0. Dies kann als Kompromiss für die Leistung bei der Implementierung des XCOM-Projekts angesehen werden. Um den absoluten RPO=0 sicherzustellen, müssen Sie den Parameter „group_replication_consistency“ konfigurieren, der die Lese- und Schreibkonsistenz nach AFTER steuert. In diesem Fall erfordert die Transaktion jedoch zusätzlich zum 1,5-RTT-Netzwerk-Overhead einen Protokoll-E/A-Overhead, um die Mehrheit zu erreichen. und die Leistung wird sehr gering sein.
DN
PolarDB-X DN verwendet X-Paxos zur Implementierung eines verteilten Protokolls und ist eng an den Group-Commit-Prozess von MySQL gebunden. Bei der Übermittlung einer Transaktion ist die Mehrheit erforderlich, um die Platzierung und Persistenz zu bestätigen, bevor die tatsächliche Übermittlung zulässig ist. Der größte Teil der Festplattenplatzierung bezieht sich hier auf die Binlog-Platzierung der Hauptbibliothek. Der E/A-Thread der Standby-Bibliothek empfängt das Protokoll der Hauptbibliothek und schreibt es zur Persistenz in sein eigenes Binlog. Selbst wenn in Extremszenarien alle Knoten ausfallen, gehen daher keine Daten verloren und RPO=0 kann garantiert werden.
2.3. RTO
Die RTO-Zeit hängt eng mit dem Zeitaufwand für den Kaltstart des Systems selbst zusammen, der sich in den spezifischen Grundfunktionen widerspiegelt:Fehlererkennungsmechanismus -> Absturzwiederherstellungsmechanismus -> Master-Auswahlmechanismus -> Protokollausgleich
2.3.1. Fehlererkennung
MGR
- Jeder Knoten sendet regelmäßig Heartbeat-Pakete an andere Knoten, um zu überprüfen, ob andere Knoten fehlerfrei sind. Die Heartbeat-Periode ist auf 1 Sekunde festgelegt und kann nicht angepasst werden.
- Wenn der aktuelle Knoten feststellt, dass andere Knoten nach group_replication_member_expel_timeout (Standard 5 Sekunden) nicht geantwortet haben, wird er als ausgefallener Knoten betrachtet und aus dem Cluster ausgeschlossen.
- Bei Ausnahmen wie einer Netzwerkunterbrechung oder einem abnormalen Neustart versucht ein einzelner ausgefallener Knoten nach der Wiederherstellung des Netzwerks, automatisch dem Cluster beizutreten und blockiert dann das Protokoll.
DN
- Der Leader-Knoten sendet regelmäßig Heartbeat-Pakete an andere Knoten, um zu überprüfen, ob andere Knoten fehlerfrei sind. Die Heartbeat-Periode beträgt 1/5 des Wahl-Timeouts. Das Wahl-Timeout wird durch den Parameter „consens_election_timeout“ gesteuert. Der Standardwert beträgt 5 Sekunden, sodass die Heartbeat-Periode des Leader-Knotens standardmäßig 1 Sekunde beträgt.
- Wenn der Leader feststellt, dass andere Knoten offline sind, sendet er weiterhin regelmäßig Heartbeat-Pakete an alle anderen Knoten, um sicherzustellen, dass andere Knoten nach dem Absturz und der Wiederherstellung rechtzeitig darauf zugreifen können.Der Leader-Knoten sendet jedoch keine Transaktionsprotokolle mehr an den Offline-Knoten.
- Nicht-Leader-Knoten senden keine Heartbeat-Erkennungspakete, aber wenn der Nicht-Leader-Knoten feststellt, dass er den Heartbeat vom Leader-Knoten nach „consens_election_timeout“ nicht erhalten hat, wird eine Neuwahl ausgelöst.
- In Ausnahmefällen wie einer Netzwerkunterbrechung oder einem abnormalen Neustart tritt der fehlerhafte Knoten nach der Wiederherstellung des Netzwerks automatisch dem Cluster bei.
- Daher bietet DN im Hinblick auf die Fehlererkennung mehr Betriebs- und Wartungskonfigurationsschnittstellen, und die Identifizierung von Fehlern in stadtübergreifenden Bereitstellungsszenarien wird genauer.
2.3.2. Wiederherstellung nach einem Absturz
MGR
-
- Das von XCOM implementierte Paxos-Protokoll befindet sich im Speicherstatus. Das Erreichen der Mehrheit erfordert keine Persistenz. Der Protokollstatus basiert auf dem Speicherstatus des überlebenden Mehrheitsknotens.Wenn alle Knoten hängen bleiben, kann das Protokoll nicht wiederhergestellt werden. Nach dem Neustart des Clusters ist ein manueller Eingriff erforderlich.
- Wenn nur ein einzelner Knoten abstürzt und wiederhergestellt wird, der Follower-Knoten jedoch mit mehr Transaktionsprotokollen hinter dem Leader-Knoten zurückbleibt und die zwischengespeicherten XCOM-Transaktionsprotokolle auf dem Leader gelöscht wurden, besteht die einzige Option darin, den globalen Wiederherstellungs- oder Klonprozess zu verwenden.
- Die Größe des XCOM-Cache wird durch group_replication_message_cache_size gesteuert, der Standardwert ist 1 GB
- Globale Wiederherstellung bedeutet, dass ein Knoten, wenn er dem Cluster wieder beitritt, Daten wiederherstellt, indem er die erforderlichen fehlenden Transaktionsprotokolle (Binärprotokoll) von anderen Knoten erhält.Dieser Prozess erfordert, dass mindestens ein Knoten im Cluster alle erforderlichen Transaktionsprotokolle speichert
- Clone basiert auf dem Clone Plugin, das zur Wiederherstellung verwendet wird, wenn die Datenmenge groß ist oder viele Protokolle fehlen.Es funktioniert durch das Kopieren eines Snapshots der gesamten Datenbank auf den abgestürzten Knoten, gefolgt von einer abschließenden Synchronisierung mit dem neuesten Transaktionsprotokoll
- Die globalen Wiederherstellungs- und Klonprozesse sind normalerweise automatisiert, aber in einigen Sonderfällen, wie z. B. bei Netzwerkproblemen oder wenn der XCOM-Cache der anderen beiden Knoten geleert wurde, ist ein manueller Eingriff erforderlich.
DN
-
- Das X-Paxos-Protokoll verwendet die Binlog-Persistenz. Bei der Wiederherstellung nach einem Absturz werden übermittelte Transaktionen zunächst vollständig wiederhergestellt. Bei ausstehenden Transaktionen müssen Sie warten, bis die XPaxos-Protokollschicht eine Einigung erzielt hat, um die Master-Backup-Beziehung festzulegen, bevor Sie die Transaktion festschreiben oder rückgängig machen. Der gesamte Prozess ist vollständig automatisiert.Selbst wenn alle Knoten ausgefallen sind, kann der Cluster nach dem Neustart automatisch wiederhergestellt werden.
- In Szenarien, in denen der Follower-Knoten in vielen Transaktionsprotokollen hinter dem Leader-Knoten zurückbleibt, wird der Follower-Knoten definitiv aufholen, solange die Binlog-Datei auf dem Leader nicht gelöscht wird.
- Daher erfordert DN im Hinblick auf die Wiederherstellung nach einem Absturz überhaupt keinen manuellen Eingriff.
2.3.3. Auswahl des Leiters
Im Single-Master-Modus folgen MGRs XCOM und DN X-Paxos, ein starker Leader-Modus, demselben Grundprinzip für die Auswahl des Leaders – Protokolle, auf die sich der Cluster geeinigt hat, können nicht zurückgesetzt werden. Aber wenn es um das Unkonsensprotokoll geht, gibt es Unterschiede
MGR
- Bei der Leader-Auswahl geht es mehr darum, welcher Knoten als nächstes als Leader-Dienst fungiert.Dieser Anführer verfügt bei seiner Wahl nicht unbedingt über das neueste Konsensprotokoll, daher muss er die neuesten Protokolle von anderen Knoten im Cluster synchronisieren und nach dem Binden der Protokolle Lese- und Schreibdienste bereitstellen.
- Der Vorteil dabei ist, dass die Wahl des Leaders selbst ein strategisches Produkt ist, etwa Gewicht und Ordnung. MGR steuert die Gewichtung jedes Knotens über den Parameter „group_replication_member_weight“.
- Der Nachteil besteht darin, dass der neu gewählte Leader selbst möglicherweise eine große Replikationsverzögerung hat und weiterhin mit dem Protokoll aufholen muss, oder dass er möglicherweise eine große Anwendungsverzögerung hat und weiterhin mit der Protokollanwendung aufholen muss, bevor er Lese- und Lesevorgänge bereitstellen kann Schreibdienste.Dies führt zu einer längeren RTO-Zeit
DN
- Die Wahl des Anführers erfolgt im Sinne des Protokolls. Jeder Knoten, der über die Protokolle aller Mehrheitsparteien im Cluster verfügt, kann zum Anführer gewählt werden. Dieser Knoten kann also zuvor ein Anhänger oder ein Protokollierer gewesen sein.
- Der Logger kann keine Lese- und Schreibdienste bereitstellen, nachdem er die Protokolle mit anderen Knoten synchronisiert hat. Er gibt die Führungsrolle aktiv auf.
- Um sicherzustellen, dass der designierte Knoten zum Anführer wird, verwendet DN die optimistische Gewichtsstrategie + die obligatorische Gewichtsstrategie, um die Reihenfolge zu begrenzen, in der er zum Anführer wird, und verwendet den strategischen Mehrheitsmechanismus, um sicherzustellen, dass der neue Master sofort Lese- und Schreibvorgänge bereitstellen kann Dienste ohne Verzögerung.
- Daher unterstützt DN in Bezug auf die Auswahl von Führungskräften nicht nur die gleiche strategische Auswahl wie MGR, sondern unterstützt auch obligatorische Gewichtsstrategien.
2.3.4. Protokollabgleich
Protokollausgleich bedeutet, dass es bei den Protokollen zwischen der primären und sekundären Datenbank zu einer Protokollreplikationsverzögerung kommt und die sekundäre Datenbank die Protokolle ausgleichen muss. Bei Knoten, die neu gestartet und wiederhergestellt werden, wird die Wiederherstellung normalerweise mit der Standby-Datenbank gestartet. Im Vergleich zur Hauptdatenbank ist bereits eine Protokollreplikationsverzögerung aufgetreten, und die Protokolle müssen mit der Hauptdatenbank nachgeholt werden. Bei den Knoten, die physisch weit vom Leader entfernt sind, hat das Erreichen der Mehrheit normalerweise nichts damit zu tun. Sie haben immer eine Replikationsprotokollverzögerung und holen immer mit dem Protokoll auf. Diese Situationen erfordern eine spezifische technische Implementierung, um eine rechtzeitige Lösung von Verzögerungen bei der Protokollreplikation sicherzustellen.
MGR
- Die Transaktionsprotokolle befinden sich alle im XCOM-Cache, und der Cache ist standardmäßig nur 1 GB groß. Daher kann der Cache leicht geleert werden, wenn ein Follower-Knoten bei der Replikation von Anforderungsprotokollen weit zurückliegt.
- Zu diesem Zeitpunkt wird der verzögerte Follower automatisch aus dem Cluster geworfen und verwendet dann den oben erwähnten globalen Wiederherstellungs- oder Klonprozess für die Wiederherstellung nach einem Absturz und tritt dann automatisch dem Cluster bei, nachdem er aufgeholt hat.Wenn Sie stoßenBeispielsweise liegen Netzwerkprobleme vor oder der XCOM-Cache der beiden anderen Knoten wird geleert. In diesem Fall ist ein manueller Eingriff erforderlich, um das Problem zu beheben.
- Warum müssen wir den Cluster zuerst rausschmeißen? Weil der fehlerhafte Knoten im Multi-Write-Modus die Leistung stark beeinträchtigt und der Cache des Leaders keinen Einfluss darauf hat. Er muss nach der asynchronen Bindung hinzugefügt werden.
- Warum können wir die lokale Binlog-Datei des Leaders nicht direkt lesen? Da sich das zuvor erwähnte XCOM-Protokoll im vollen Speicher befindet und im Binlog- und Relay-Protokoll keine Protokollinformationen zu XCOM vorhanden sind.
DN
- Die Daten befinden sich alle in der Binlog-Datei. Solange das Binlog nicht bereinigt wird, kann es bei Bedarf gesendet werden und es besteht keine Möglichkeit, aus dem Cluster geworfen zu werden.
- Um den E/A-Jitter zu reduzieren, der durch das Lesen alter Transaktionsprotokolle aus der Binlog-Datei durch die Hauptbibliothek verursacht wird, gibt DN dem Lesen der zuletzt zwischengespeicherten Transaktionsprotokolle aus dem FIFO-Cache Vorrang. Der FIFO-Cache wird durch den Parameter „consens_log_cache_size“ und die Standardeinstellung gesteuert ist 64M
- Wenn das alte Transaktionsprotokoll im FIFO-Cache durch das aktualisierte Transaktionsprotokoll entfernt wurde, versucht DN, das zuvor zwischengespeicherte Transaktionsprotokoll aus dem Prefetch-Cache zu lesen. Der Prefetch-Cache wird durch den Parameter „consens_prefetch_cache_size“ gesteuert und der Standardwert ist 64 MB
- Wenn im Prefetch-Cache kein erforderliches altes Transaktionsprotokoll vorhanden ist, versucht DN, eine asynchrone E/A-Aufgabe zu initiieren, mehrere aufeinanderfolgende Protokolle vor und nach dem angegebenen Transaktionsprotokoll stapelweise aus der Binlog-Datei zu lesen, sie im Prefetch-Cache abzulegen und zu warten für DNs nächsten Wiederholungsversuch
- Daher erfordert DN überhaupt keinen manuellen Eingriff, wenn es um den Protokollausgleich geht.
2.4. Wiedergabeverzögerung der Standby-Datenbank
Die Wiedergabeverzögerung der Standby-Datenbank ist die Verzögerung zwischen dem Zeitpunkt, zu dem dieselbe Transaktion in der Hauptdatenbank abgeschlossen wird, und dem Zeitpunkt, zu dem die Transaktion in der Standby-Datenbank angewendet wird. Hier wird die Leistung des Anwendungsprotokolls der Standby-Datenbank getestet. Sie beeinflusst, wie lange es dauert, bis die Standby-Datenbank ihre Datenanwendung abgeschlossen hat und Lese- und Schreibdienste bereitstellt, wenn eine Ausnahme auftritt.
MGR
- Die MGR-Standby-Datenbank empfängt die RelayLog-Datei von der Hauptdatenbank. Wenn die Anwendung angewendet wird, muss sie das RelayLog erneut lesen, einen vollständigen zweistufigen Gruppenübermittlungsprozess durchlaufen und die entsprechenden Daten- und Binlog-Dateien erstellen.
- Die Effizienz der Transaktionsanwendung ist hier dieselbe wie die Effizienz der Transaktionsübermittlung in der Hauptdatenbank. Die standardmäßige Double-One-Konfiguration (innodb_flush_log_at_trx_commit, sync_binlog) führt dazu, dass der Ressourcenaufwand der Standby-Datenbankanwendung groß ist.
DN
- Die DN-Sicherungsdatenbank empfängt die Binlog-Datei von der Hauptdatenbank. Bei der Anwendung muss das Binlog erneut gelesen werden. Es muss lediglich der einstufige Gruppenübermittlungsprozess durchlaufen und die entsprechenden Daten erstellt werden.
- Da DN die vollständige Wiederherstellung nach einem Absturz unterstützt, muss die Standby-Datenbankanwendung innodb_flush_log_at_trx_commit=1 nicht aktivieren, sodass sie von der Double-One-Konfiguration nicht tatsächlich betroffen ist.
- In Bezug auf die Wiedergabeverzögerung der Standby-Datenbank ist die Effizienz der DN-Standby-Datenbankwiedergabe daher viel höher als die von MGR.
2.5. Auswirkungen von Großveranstaltungen
Große Transaktionen wirken sich nicht nur auf die Übermittlung gewöhnlicher Transaktionen aus, sondern auch auf die Stabilität des gesamten verteilten Protokolls in einem verteilten System. In schweren Fällen führt eine große Transaktion dazu, dass der gesamte Cluster für längere Zeit nicht verfügbar ist.
MGR
- MGR bietet keine Optimierung für die Unterstützung großer Transaktionen. Es fügt lediglich den Parameter group_replication_transaction_size_limit hinzu, um die Obergrenze für große Transaktionen zu steuern.
- Wenn das Transaktionsprotokoll das große Transaktionslimit überschreitet, wird direkt ein Fehler gemeldet und die Transaktion kann nicht übermittelt werden.
DN
- Um das durch große Transaktionen verursachte Instabilitätsproblem zu lösen, übernimmt DN die Lösung der Aufteilung großer Transaktionen + Aufteilung großer Objekte, um das Problem zu lösen. DN teilt das Transaktionsprotokoll großer Transaktionen logisch + physisch auf Bei kleinen Blöcken nutzt jeder kleine Block des Transaktionsprotokolls die vollständige Paxos-Commit-Garantie
- Basierend auf der Lösung, große Transaktionen aufzuteilen, legt DN keine Beschränkungen hinsichtlich der Größe großer Transaktionen fest. Benutzer können sie nach Belieben verwenden und können auch RPO = 0 sicherstellen.
- Ausführliche Anweisungen finden Sie unter„PolarDB-X-Speicher-Engine-Kerntechnologie | Optimierung großer Transaktionen“
- Daher kann DN große Angelegenheiten abwickeln, ohne von großen Angelegenheiten betroffen zu sein.
2.6. Bereitstellungsformular
MGR
- MGR unterstützt Single-Master- und Multi-Master-Bereitstellungsmodi. Im Multi-Master-Modus kann jeder Knoten gelesen und geschrieben werden, und die Standby-Datenbank kann nur gelesen und geschrieben werden. nur.
- Für die MGR-Hochverfügbarkeitsbereitstellung sind mindestens drei Knotenbereitstellungen erforderlich, d. h. mindestens drei Kopien von Daten und Protokollen. Der Logger-Modus wird nicht unterstützt.
- MGR unterstützt nicht die Erweiterung schreibgeschützter Knoten, unterstützt jedoch die Kombination aus MGR + Master-Slave-Replikationsmodus, um eine ähnliche Topologieerweiterung zu erreichen.
DN
- DN unterstützt die Bereitstellung im Single-Master-Modus. Im Single-Master-Modus kann die Hauptdatenbank gelesen und geschrieben werden, während die Standby-Datenbank nur schreibgeschützt sein kann.
- Für die DN-Hochverfügbarkeitsbereitstellung sind mindestens drei Knoten erforderlich, die Logger-Form wird jedoch unterstützt, d gewählt. In diesem Fall erfordert die Hochverfügbarkeitsbereitstellung mit drei Knoten nur den Speicheraufwand von 2 Datenkopien + 3 Protokollkopien, was sie zu einer kostengünstigen Bereitstellung macht.
- DN unterstützt die schreibgeschützte Knotenbereitstellung und das schreibgeschützte Kopieren des Lernformulars. Im Vergleich zu Kopien mit vollem Funktionsumfang verfügt es nur über keine Stimmrechte. Durch Lernkopien wird der nachgelagerte Abonnementverbrauch für die Hauptbibliothek realisiert.

2.7. Funktionsübersicht
| | MGR | DN |
| Protokolleffizienz | Zeitpunkt der Transaktionseinreichung | 1,5 bis 2,5 RTT | 1 RTT |
| | Beharrlichkeit der Mehrheit | XCOM-Speicher sparen | Binlog-Persistenz |
| Zuverlässigkeit | RPO = 0 | Standardmäßig nicht garantiert | Völlig garantiert |
| | Fehlererkennung | Alle Knoten überprüfen sich gegenseitig, die Netzwerklast ist hoch Der Heartbeat-Zyklus kann nicht angepasst werden | Der Masterknoten überprüft regelmäßig andere Knoten Die Parameter des Heartbeat-Zyklus sind einstellbar |
| | Wiederherstellung nach Mehrheitskollaps | manuelle Eingriffe | Automatische Wiederherstellung |
| | Wiederherstellung nach einem Minority-Crash | Automatische Wiederherstellung in den meisten Fällen, manuelles Eingreifen in besonderen Fällen | Automatische Wiederherstellung |
| | Wählen Sie den Meister | Legen Sie die Reihenfolge der Auswahl frei fest | Legen Sie die Reihenfolge der Auswahl frei fest |
| Log-Krawatte | Verzögerungsprotokolle dürfen den XCOM-1-GB-Cache nicht überschreiten | BInlog-Dateien werden nicht gelöscht |
| Verzögerung bei der Wiedergabe der Standby-Datenbank | Zwei Etappen + doppelt eine, sehr langsam | Eine Stufe + Doppelnull, schneller |
| Großes Geschäft | Das Standardlimit beträgt nicht mehr als 143 MB | Keine Größenbeschränkung |
| bilden | Hohe Verfügbarkeitskosten | Voll funktionsfähig, drei Kopien, 3 Kopien Datenspeicheraufwand | Logger-Protokollkopie, 2 Kopien der Datenspeicherung |
| schreibgeschützter Knoten | Implementiert mit Master-Slave-Replikation | Das Protokoll verfügt über eine schlankere schreibgeschützte Kopierimplementierung |
3. Testvergleich
MGR wurde in MySQL 5.7.17 eingeführt, weitere MGR-bezogene Funktionen sind jedoch nur in MySQL 8.0 verfügbar, und in MySQL 8.0.22 und späteren Versionen wird die Gesamtleistung stabiler und zuverlässiger sein. Daher haben wir für Vergleichstests die neueste Version 8.0.32 beider Parteien ausgewählt.
Da es beim Vergleichstest von PolarDB-X DN und MySQL MGR Unterschiede in den Testumgebungen, Kompilierungsmethoden, Bereitstellungsmethoden, Betriebsparametern und Testmethoden gibt, die zu ungenauen Testvergleichsdaten führen können, konzentriert sich dieser Artikel auf verschiedene Details . Gehen Sie wie folgt vor:
| Test-Vorbereitungen | PolarDB-X DN | MySQL MGR[1] |
| Hardwareumgebung | Verwendung derselben physischen Maschine mit 96C 754 GB Speicher und SSD-Festplatte |
| Betriebssystem | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| Kernelversion | Verwendung einer Kernel-Baseline basierend auf Community-Version 8.0.32 |
| Kompilierungsmethode | Kompilieren Sie mit demselben RelWithDebInfo |
| Betriebsparameter | Verwenden Sie dieselbe offizielle Website von PolarDB-X, um 32C128G mit denselben Spezifikationen und Parametern zu verkaufen |
| Bereitstellungsmethode | Single-Master-Modus |
Notiz:
- Bei MGR ist die Flusskontrolle standardmäßig aktiviert, während bei PolarDB-X DN die Flusskontrolle standardmäßig deaktiviert ist.Daher wird der group_replication_flow_control_mode von MGR separat konfiguriert, damit die Leistung von MGR optimal ist.
- MGR weist während der Aufzählung einen offensichtlichen Leseengpass auf. Daher wird replication_optimize_for_static_plugin_config von MGR separat konfiguriert und aktiviert, sodass die schreibgeschützte Leistung von MGR am besten ist.
3.1. Leistung
Leistungstests sind das Erste, worauf jeder bei der Auswahl einer Datenbank achtet. Hier verwenden wir das offizielle Sysbench-Tool, um 16 Tabellen mit jeweils 10 Millionen Daten zu erstellen, um Leistungstests in OLTP-Szenarien durchzuführen und die Leistung der beiden unter verschiedenen Parallelitätsbedingungen in verschiedenen OLTP-Szenarien zu testen und zu vergleichen.Unter Berücksichtigung der unterschiedlichen Situationen des tatsächlichen Einsatzes simulieren wir jeweils die folgenden vier Einsatzszenarien:
- Drei Knoten werden im selben Computerraum bereitgestellt. Es gibt eine Netzwerkverzögerung von 0,1 ms, wenn die Maschinen sich gegenseitig anpingen.
- Drei Zentren in derselben Stadt und drei Computerräume in derselben Region stellen drei Knoten bereit. Es gibt eine Netzwerkverzögerung von 1 ms beim Ping zwischen den Computerräumen (Beispiel: drei Computerräume in Shanghai).
- Drei Zentren an zwei Orten, drei Knoten in drei Computerräumen an zwei Orten, 1 ms Netzwerk-Ping zwischen Computerräumen in derselben Stadt, 30 ms Netzwerkverzögerung zwischen derselben Stadt und einem anderen Ort (z. B. Shanghai/Shanghai/Shenzhen)
- Drei Zentren an drei Orten, drei Knoten in drei Computerräumen an drei Orten (z. B. Shanghai/Hangzhou/Shenzhen), die Netzwerkverzögerung zwischen Hangzhou und Shanghai beträgt etwa 5 ms und die weiteste Entfernung von Hangzhou/Shanghai nach Shenzhen beträgt 30 ms .
veranschaulichen:
a. Betrachten Sie den horizontalen Vergleich der Leistung von vier Bereitstellungsszenarien. Drei Zentren an zwei Standorten übernehmen alle den Bereitstellungsmodus mit 3 Kopien. Das reale Produktionsgeschäft kann auf den Bereitstellungsmodus mit 5 Kopien erweitert werden.
b. Unter Berücksichtigung der strengen Einschränkungen bei RPO=0 bei der Verwendung von Hochverfügbarkeits-Datenbankprodukten ist MGR standardmäßig mit RPO<>0 konfiguriert. Hier werden wir weiterhin Vergleichstests zwischen MGR RPO<>0 und RPO=0 hinzufügen Einsatzszenario.
- MGR_0 stellt Daten für den Fall MGR RPO = 0 dar
- MGR_1 stellt Daten für den Fall dar, dass MGR RPO <> 0 ist
- DN stellt die Daten für den Fall DN RPO = 0 dar
3.1.1. Gleicher Computerraum
| | | 1 | 4 | 16 | 64 | 256 |
| oltp_schreibgeschützt | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 |
| MGR_0 im Vergleich zu MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% |
| DN vs. MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% |
| DN vs. MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% |
| oltp_lesen_schreiben | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 |
| MGR_0 im Vergleich zu MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% |
| DN vs. MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% |
| DN vs. MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% |
| oltp_write_only | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 |
| MGR_0 im Vergleich zu MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% |
| DN vs. MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% |
| DN vs. MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
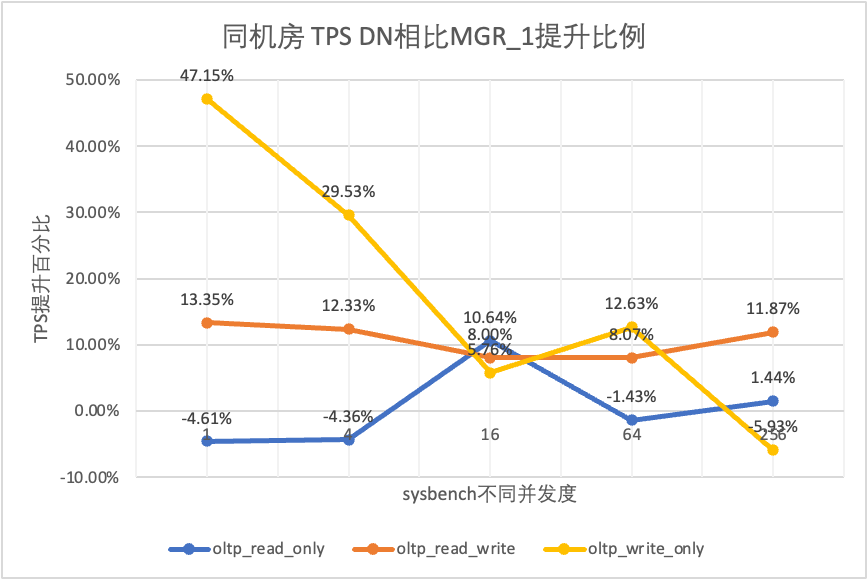
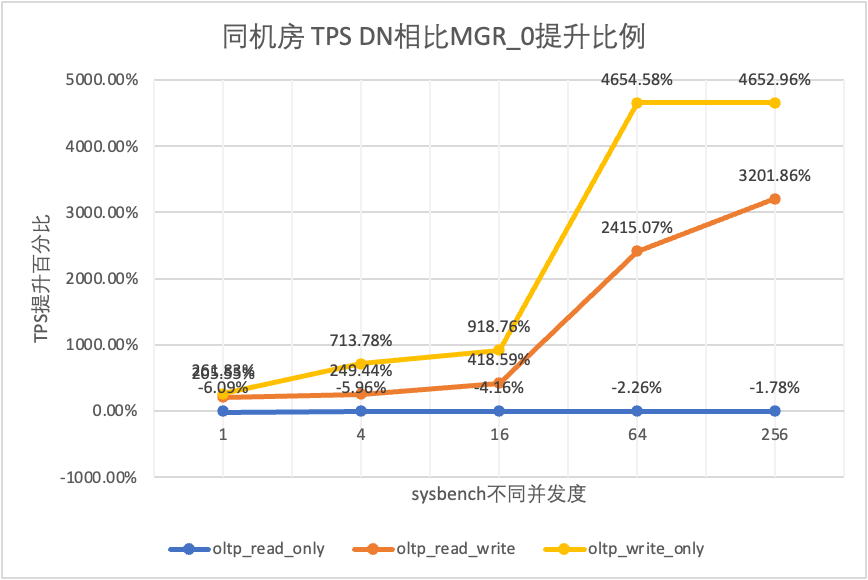
Aus den Testergebnissen geht hervor:
- Im schreibgeschützten Szenario liegt der Unterschied zwischen DN und MGR unabhängig davon, ob MGR_1 (RPO<>0) oder MGR_0 (RPO=0) verglichen wird, zwischen -5 % und 10 %, was grundsätzlich als gleich angesehen werden kann. Ob RPO gleich 0 ist, hat keine Auswirkung auf schreibgeschützte Transaktionen
- Im gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenario wird die Leistung von DN (RPO=0) im Vergleich zu MGR_1 (RPO<>0) um 5 % bis 47 % verbessert, und der Leistungsvorteil von DN ist offensichtlich, wenn die Die Parallelität ist gering und der Vorteil, wenn die Parallelität hoch ist, ist nicht offensichtlich. Dies liegt daran, dass die Protokolleffizienz von DN bei geringer Parallelität höher ist, die Leistungs-Hotspots von DN und MGR bei hoher Parallelität jedoch alle in der Bereinigung liegen.
- Unter der gleichen Prämisse von RPO=0 wird die Leistung von DN in gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenarien im Vergleich zu MGR_0 um das Zweifache bis 46-fache verbessert, und mit zunehmender Parallelität wird der Leistungsvorteil von DN erhöht. Kein Wunder, dass MGR aus Leistungsgründen standardmäßig auch auf RPO=0 verzichtet.
3.1.2. Drei Zentren in derselben Stadt
| TPS-Vergleich | | 1 | 4 | 16 | 64 | 256 |
| oltp_schreibgeschützt | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 |
| MGR_0 im Vergleich zu MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% |
| DN vs. MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% |
| DN vs. MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% |
| oltp_lesen_schreiben | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 |
| MGR_0 im Vergleich zu MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% |
| DN vs. MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% |
| DN vs. MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% |
| oltp_write_only | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 |
| MGR_0 im Vergleich zu MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% |
| DN vs. MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% |
| DN vs. MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Aus den Testergebnissen geht hervor:
- Im schreibgeschützten Szenario liegt der Unterschied zwischen DN und MGR unabhängig davon, ob MGR_1 (RPO<>0) oder MGR_0 (RPO=0) verglichen wird, zwischen -7 % und 5 %, was grundsätzlich als gleich angesehen werden kann. Ob RPO gleich 0 ist, hat keine Auswirkung auf schreibgeschützte Transaktionen
- In einem gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenario wird die Leistung von DN (RPO=0) im Vergleich zu MGR_1 (RPO<>0) um 30 bis 120 % verbessert, und der Leistungsvorteil von DN ist bei Parallelität offensichtlich ist niedrig, und wenn die Parallelität hoch ist, ist die Leistung besser. Nicht offensichtliche Funktionen. Dies liegt daran, dass die Protokolleffizienz von DN bei geringer Parallelität höher ist, die Leistungs-Hotspots von DN und MGR bei hoher Parallelität jedoch alle in der Bereinigung liegen.
- Unter der gleichen Prämisse von RPO=0 wird in gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenarien die Leistung von DN im Vergleich zu MGR_0 um das 1- bis 14-fache verbessert, und mit zunehmender Parallelität wird der Leistungsvorteil von DN erhöht. Kein Wunder, dass MGR aus Leistungsgründen standardmäßig auch auf RPO=0 verzichtet.
3.1.3. Zwei Orte und drei Zentren
| TPS-Vergleich | | 1 | 4 | 16 | 64 | 256 |
| oltp_schreibgeschützt | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 |
| MGR_0 im Vergleich zu MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% |
| DN vs. MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% |
| DN vs. MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% |
| oltp_lesen_schreiben | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 |
| MGR_0 im Vergleich zu MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% |
| DN vs. MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% |
| DN vs. MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% |
| oltp_write_only | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 |
| MGR_0 im Vergleich zu MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% |
| DN vs. MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% |
| DN vs. MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
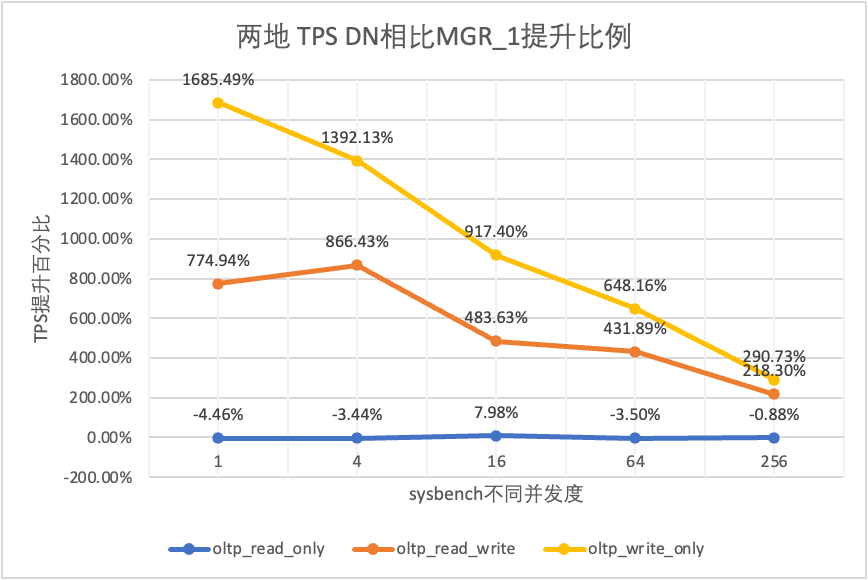
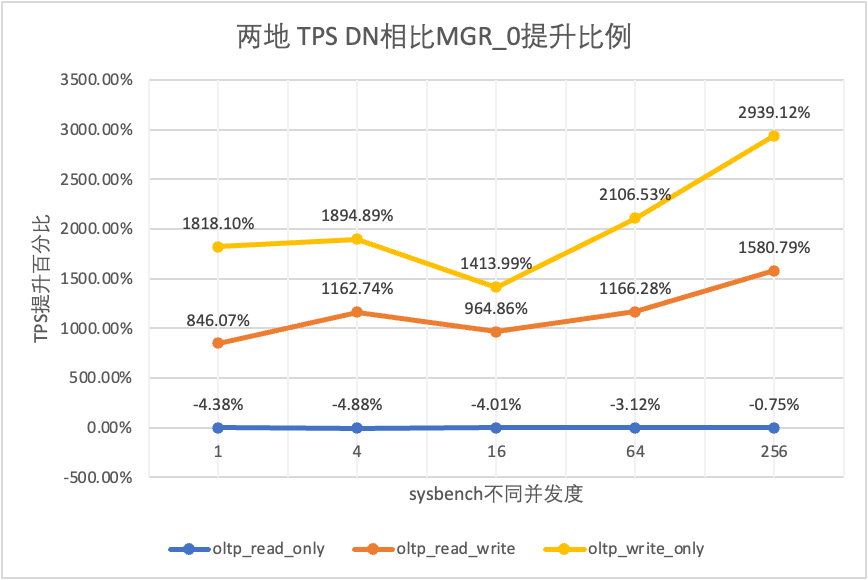
Aus den Testergebnissen geht hervor:
- Im schreibgeschützten Szenario liegt der Unterschied zwischen DN und MGR unabhängig davon, ob MGR_1 (RPO<>0) oder MGR_0 (RPO=0) verglichen wird, stabil zwischen -4 % und 7 %, was grundsätzlich als gleich angesehen werden kann. Ob RPO gleich 0 ist, hat keine Auswirkung auf schreibgeschützte Transaktionen
- Im gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenario wird die Leistung von DN (RPO=0) im Vergleich zu MGR_1 (RPO<>0) um das Zweifache bis 16-fache verbessert, und der Leistungsvorteil von DN ist bei Parallelität offensichtlich ist niedrig und der Vorteil, wenn die Parallelität hoch ist. Nicht offensichtliche Funktionen. Dies liegt daran, dass die Protokolleffizienz von DN bei geringer Parallelität höher ist, die Leistungs-Hotspots von DN und MGR bei hoher Parallelität jedoch alle in der Bereinigung liegen.
- Unter der gleichen Prämisse von RPO=0 wird die Leistung von DN in gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenarien im Vergleich zu MGR_0 um das 8- bis 29-fache verbessert, und mit zunehmender Parallelität erhöht sich der Leistungsvorteil von DN. Kein Wunder, dass MGR aus Leistungsgründen standardmäßig auch auf RPO=0 verzichtet.
3.1.4. Drei Orte und drei Zentren
| TPS-Vergleich | | 1 | 4 | 16 | 64 | 256 |
| oltp_schreibgeschützt | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 |
| MGR_0 im Vergleich zu MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% |
| DN vs. MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% |
| DN vs. MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% |
| oltp_lesen_schreiben | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 |
| MGR_0 im Vergleich zu MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% |
| DN vs. MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% |
| DN vs. MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% |
| oltp_write_only | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 |
| MGR_0 im Vergleich zu MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% |
| DN vs. MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% |
| DN vs. MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
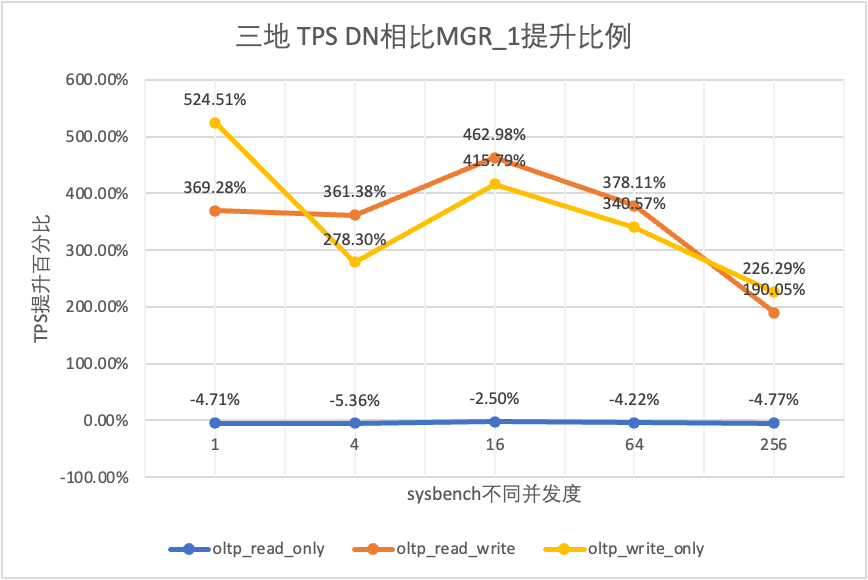
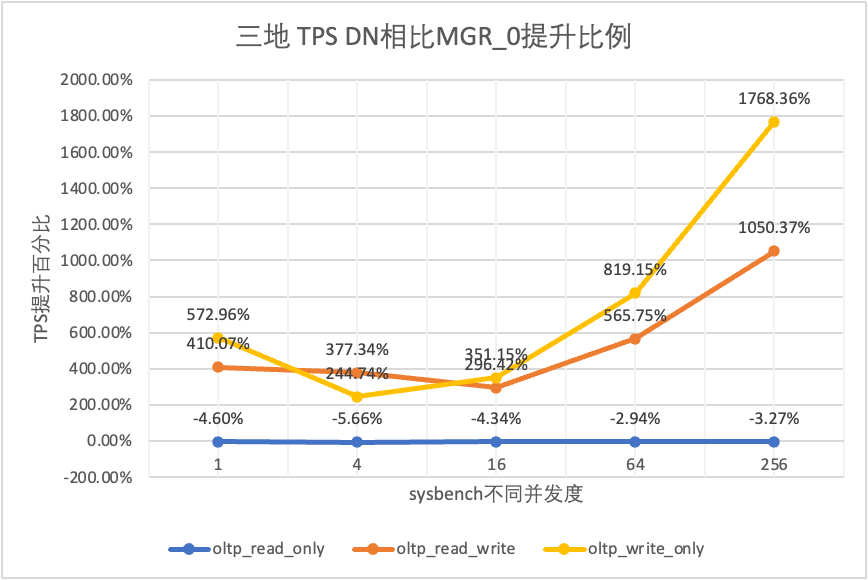
Aus den Testergebnissen geht hervor:
- Im schreibgeschützten Szenario liegt der Unterschied zwischen DN und MGR unabhängig davon, ob MGR_1 (RPO<>0) oder MGR_0 (RPO=0) verglichen wird, stabil zwischen -5 % und 0 %, was grundsätzlich als gleich angesehen werden kann. Ob RPO gleich 0 ist, hat keine Auswirkung auf schreibgeschützte Transaktionen
- Im gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenario wird die Leistung von DN (RPO=0) im Vergleich zu MGR_1 (RPO<>0) um das Zwei- bis Fünffache verbessert, und der Leistungsvorteil von DN ist bei Parallelität offensichtlich ist niedrig und der Vorteil, wenn die Parallelität hoch ist. Nicht offensichtliche Funktionen. Dies liegt daran, dass die Protokolleffizienz von DN bei geringer Parallelität höher ist, die Leistungs-Hotspots von DN und MGR bei hoher Parallelität jedoch alle in der Bereinigung liegen.
- Unter der gleichen Prämisse von RPO=0 wird die Leistung von DN in gemischten Lese-/Schreib- und Nur-Schreib-Transaktionsszenarien im Vergleich zu MGR_0 um das Zweifache bis 17-fache verbessert, und mit zunehmender Parallelität wird der Leistungsvorteil von DN erhöht. Kein Wunder, dass MGR aus Leistungsgründen standardmäßig auch auf RPO=0 verzichtet.
3.1.5. Bereitstellungsvergleich
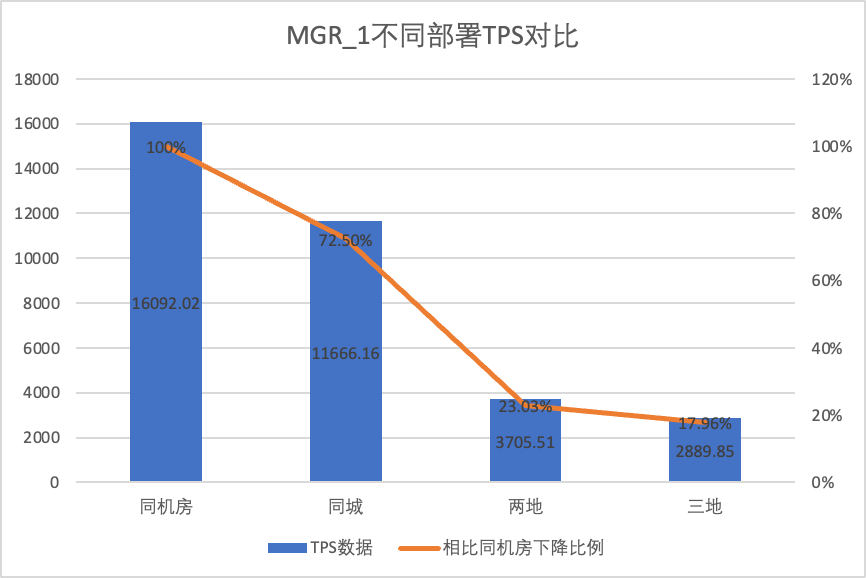
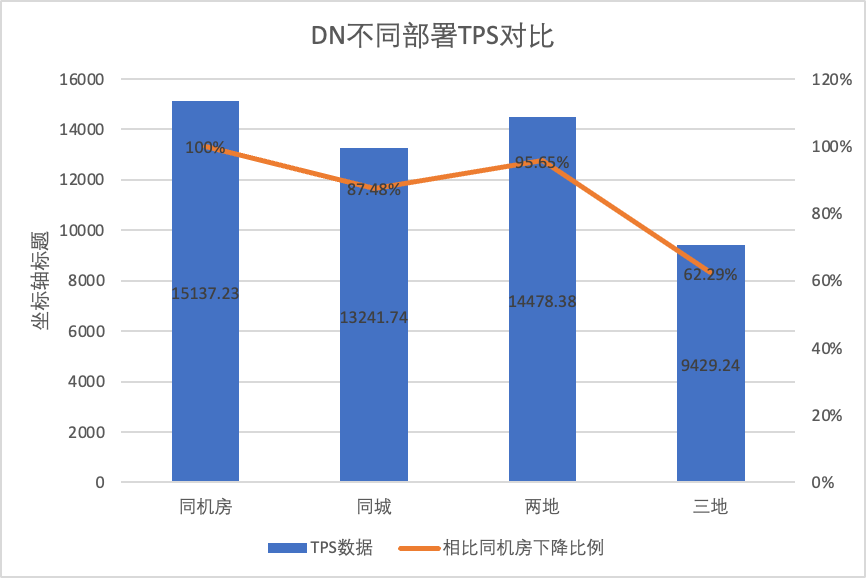
Um die Leistungsänderungen unter verschiedenen Bereitstellungsmethoden klar zu vergleichen, haben wir im obigen Test die TPS-Daten von MGR und DN unter verschiedenen Bereitstellungsmethoden unter dem oltp_write_only-Szenario 256 ausgewählt. Unter Verwendung der Computerraum-Testdaten als Basis haben wir berechnet und Verglich die TPS-Daten verschiedener Bereitstellungsmethoden mit der Basislinie, um den Unterschied in den Leistungsänderungen während der stadtübergreifenden Bereitstellung zu erkennen
| | MGR_1 (256 gleichzeitig) | DN (256 gleichzeitig) | Leistungsvorteile von DN im Vergleich zu MGR |
| Gleicher Computerraum | 16092.02 | 15137.23 | -5.93% |
| Drei Zentren in derselben Stadt | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Zwei Orte und drei Zentren | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Drei Orte und drei Zentren | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
Aus den Testergebnissen geht hervor:
- Mit der Erweiterung der Bereitstellungsmethode sank die TPS von MGR_1 (RPO<>0) im Vergleich zur Bereitstellung im gleichen Computerraum um 27,5 % des stadtübergreifenden Einsatzes (drei Zentren an zwei Orten, drei Zentren an drei Orten) Ein Rückgang um 77 % bis 82 %, was auf die Zunahme des stadtübergreifenden Einsatzes von RT zurückzuführen ist.
- DN (RTO=0) ist relativ stabil, verglichen mit der Bereitstellung im gleichen Computerraum, die Leistung der Bereitstellung von computerübergreifenden Räumen in derselben Stadt und der Bereitstellung von drei Zentren an zwei Orten sank um 4 % bis 12 %. Die Leistung des Einsatzes von drei Zentren an drei Orten sank bei hoher Netzwerklatenz um 37 %. Dies ist auch auf den verstärkten Einsatz von RT in allen Städten zurückzuführen.Dank des Batch&Pipeline-Mechanismus von DN können die Auswirkungen der stadtübergreifenden Parallelität jedoch gelöst werden. Beispielsweise kann bei der Drei-Ort- und Drei-Zentren-Architektur mit >=512 Parallelität der Leistungsdurchsatz in derselben Stadt und zwei erhöht werden Orte und drei Zentren können grundsätzlich aneinandergereiht werden.
- Es ist ersichtlich, dass der stadtübergreifende Einsatz einen großen Einfluss auf MGR_1 (RPO<>0) hat.
3.1.6. Leistungsjitter
Bei der tatsächlichen Verwendung achten wir nicht nur auf Leistungsdaten, sondern müssen auch auf Leistungsjitter achten. Denn wenn der Jitter einer Achterbahnfahrt gleicht, wird die tatsächliche Benutzererfahrung sehr schlecht sein. Wir überwachen und zeigen TPS-Echtzeit-Ausgabedaten an. Da das Sysbenc-Tool selbst keine Ausgabeüberwachungsdaten für Leistungsjitter unterstützt, verwenden wir den mathematischen Variationskoeffizienten als Vergleichsindikator:
- Variationskoeffizient (CV): Der Variationskoeffizient ist die Standardabweichung dividiert durch den Mittelwert. Er wird normalerweise verwendet, um die Schwankungen verschiedener Datensätze zu vergleichen, insbesondere wenn die Mittelwertunterschiede groß sind. Je größer der CV, desto größer ist die Schwankung der Daten relativ zum Mittelwert.
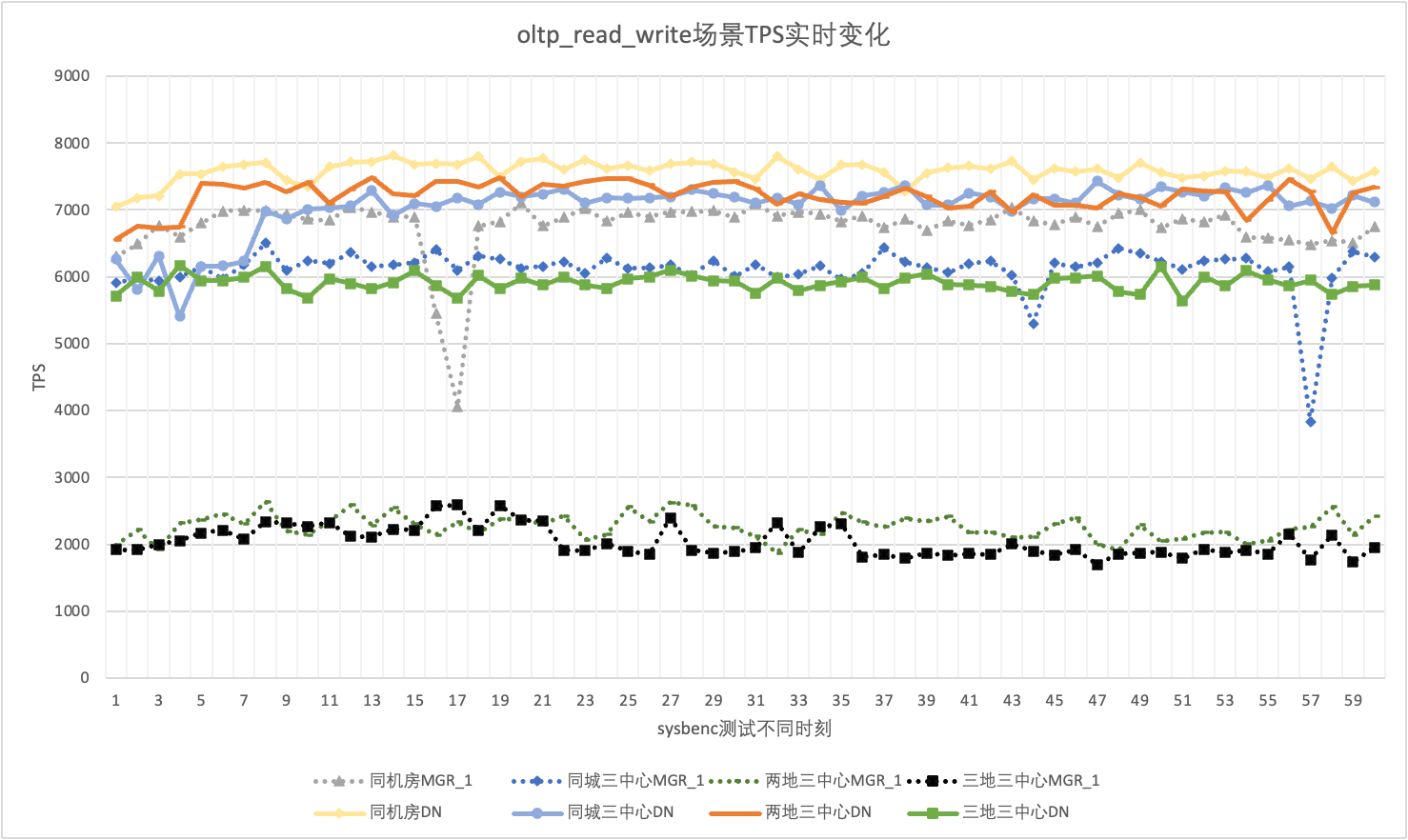
Am Beispiel des 256 gleichzeitigen oltp_read_write-Szenarios analysieren wir statistisch die TPS von MGR_1 (RPO<>0) und DN (RPO=0) im selben Computerraum, drei Zentren in derselben Stadt, drei Zentren an zwei Orten usw drei Zentren an drei Orten. Das tatsächliche Jitter-Diagramm sieht wie folgt aus, und die tatsächlichen Jitter-Indikatordaten für jedes Szenario lauten wie folgt:
| Lebenslauf | Gleicher Computerraum | Drei Zentren in derselben Stadt | Zwei Orte und drei Zentren | Drei Orte und drei Zentren |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
Aus den Testergebnissen geht hervor:
- Das TPS von MGR befindet sich im oltp_read_write-Szenario in einem instabilen Zustand und fällt plötzlich ohne Grund stark ab. Dieses Phänomen wurde in mehreren Tests in mehreren Bereitstellungsszenarien festgestellt. Im Vergleich dazu ist DN sehr stabil.
- Bei der Berechnung des Variationskoeffizienten CV ist der CV von MGR sehr groß, 6 % bis 10 %, und erreicht sogar den Maximalwert von 10 %, wenn die Verzögerung im selben Computerraum minimal ist, während der CV von DN relativ stabil ist, 2 % bis 4 %, und die Leistung von DN ist stabiler als die von MGR. Sex ist grundsätzlich doppelt so hoch
- Es ist ersichtlich, dass der Leistungsjitter von MGR_1 (RPO<>0) relativ groß ist
3.2. RTO
Das Kernmerkmal einer verteilten Datenbank ist die hohe Verfügbarkeit. Der Ausfall eines Knotens im Cluster hat keinen Einfluss auf die Gesamtverfügbarkeit. Für die typische Bereitstellungsform von 3 Knoten mit einem Master und zwei Backups, die im selben Computerraum bereitgestellt werden, haben wir versucht, Benutzerfreundlichkeitstests in den folgenden drei Szenarien durchzuführen:
- Unterbrechen Sie die Hauptdatenbank, starten Sie sie dann neu und beobachten Sie die RTO-Zeit, die der Cluster benötigt, um die Verfügbarkeit während des Prozesses wiederherzustellen.
- Unterbrechen Sie jede Standby-Datenbank und starten Sie sie dann neu, um die Verfügbarkeitsleistung der Primärdatenbank während des Prozesses zu beobachten.
3.2.1. Ausfallzeit der Hauptdatenbank + Neustart
Wenn keine Last vorhanden ist, töten Sie den Anführer und überwachen Sie die Statusänderungen jedes Knotens im Cluster und ob er beschreibbar ist.
| | MGR | DN |
| Startet normal | 0 | 0 |
| Anführer töten | 0 | 0 |
| Ungewöhnliche Knotenzeit gefunden | 5 | 5 |
| Zeit, 3 Knoten auf 2 Knoten zu reduzieren | 23 | 8 |
| | MGR | DN |
| Startet normal | 0 | 0 |
| Anführer töten, automatisch hochziehen | 0 | 0 |
| Ungewöhnliche Knotenzeit gefunden | 5 | 5 |
| Zeit, 3 Knoten auf 2 Knoten zu reduzieren | 23 | 8 |
| 2-Knoten-Wiederherstellungszeit, 3-Knoten-Zeit | 37 | 15 |

Aus den Testergebnissen geht hervor, dass unter drucklosen Bedingungen:
- Die RTO von DN beträgt 8–15 Sekunden, die Reduzierung auf 2 Knoten dauert 8 Sekunden und die Wiederherstellung von 3 Knoten dauert 15 Sekunden.
- Die RTO von MGR beträgt 23–37 Sekunden. Das Downgrade auf 2 Knoten dauert 23 Sekunden und die Wiederherstellung von 3 Knoten.
- Die RTO-Leistung DN ist insgesamt besser als MGR
3.2.2. Ausfallzeit der Standby-Datenbank + Neustart
Verwenden Sie Sysbench, um einen gleichzeitigen Stresstest von 16 Threads im oltp_read_write-Szenario durchzuführen. Beenden Sie in der 10. Sekunde in der Abbildung manuell einen Standby-Knoten und beobachten Sie die Echtzeit-TPS-Ausgabedaten von Sysbench.
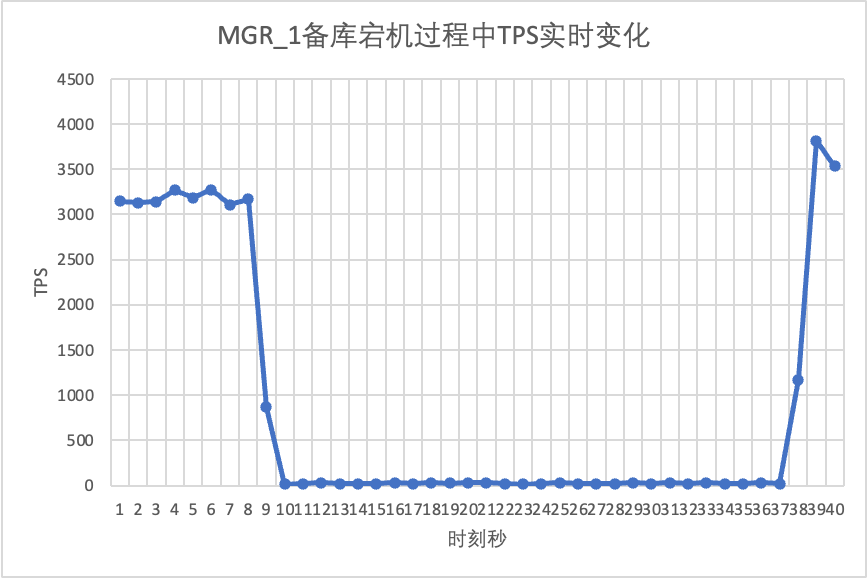


Aus der Testergebnistabelle geht hervor:
- Nachdem die Standby-Datenbank unterbrochen wurde, fiel der TPS der Hauptdatenbank von MGR deutlich ab und es dauerte etwa 20 Sekunden, bevor er wieder auf den Normalwert zurückkehrte. Laut Protokollanalyse gibt es hier zwei Prozesse: Erkennen, dass der fehlerhafte Knoten nicht mehr erreichbar ist, und Herauswerfen des fehlerhaften Knotens aus dem MGR-Cluster. Dieser Test bestätigte einen Fehler, der seit langem in der MGR-Community kursiert. Auch wenn nur einer von drei Knoten nicht verfügbar ist.Der gesamte Cluster erlebte eine Zeit lang starke Schwankungen und war nicht mehr verfügbar.
- Um das Problem zu lösen, dass beim Single-Master-MGR ein einzelner Knoten ausfällt und die gesamte Instanz nicht verfügbar ist, hat die Community ab 8.0.27 die MGR-Paxos-Single-Leader-Funktion eingeführt, um das Problem zu lösen, die jedoch standardmäßig deaktiviert ist. Hier aktivieren wir group_replication_paxos_single_leader und fahren mit der Überprüfung fort. Nach der Unterbrechung der Standby-Datenbank bleibt die Leistung der Hauptdatenbank stabil und hat sich leicht verbessert. Der Grund sollte mit der Reduzierung der Netzwerklast zusammenhängen.
- Für DN stieg der TPS der Hauptdatenbank nach der Unterbrechung der Standby-Datenbank sofort um etwa 20 %, blieb dann stabil und der Cluster war immer verfügbar.Dies ist das Gegenteil von MGR. Der Grund dafür ist, dass die Hauptdatenbank nach der Unterbrechung einer Standby-Datenbank jedes Mal nur Protokolle an die verbleibende Standby-Datenbank senden muss und der Sende- und Empfangsprozess von Netzwerkpaketen effizienter ist.
Wir setzen den Test fort, starten die Standby-Datenbank neu und stellen sie wieder her und beobachten die Änderungen in den TPS-Daten der Hauptdatenbank.
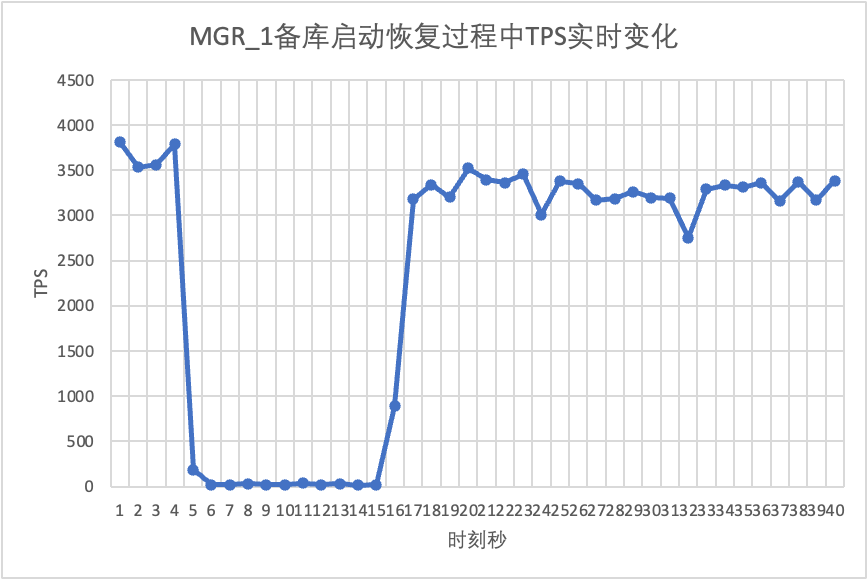
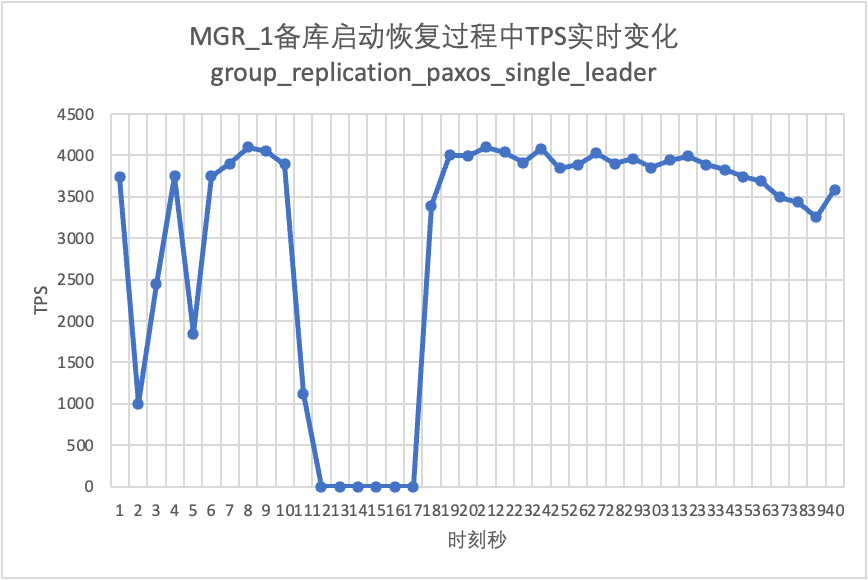
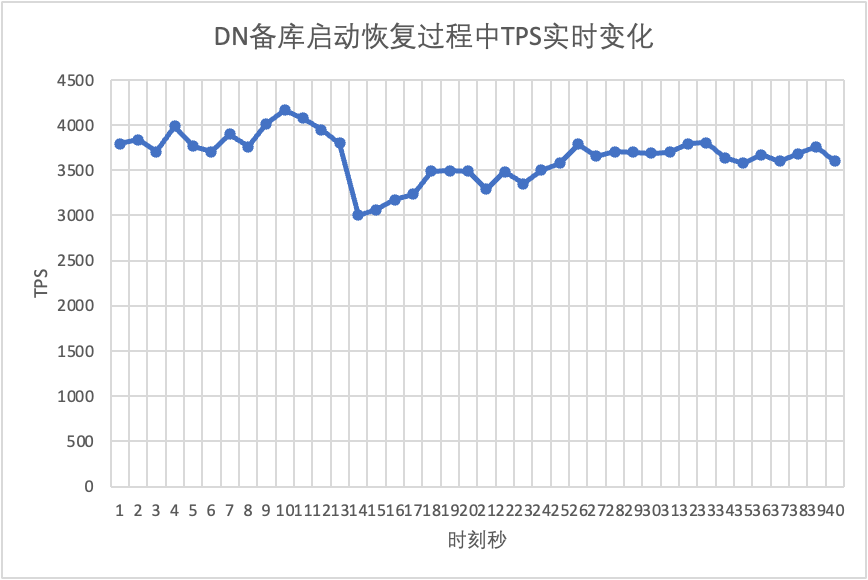
Aus der Testergebnistabelle geht hervor:
- MGR erholte sich in 5 Sekunden von 2 Knoten auf 3 Knoten.Es gibt jedoch auch Situationen, in denen die Hauptbibliothek nicht verfügbar ist, was etwa 12 Sekunden dauert.Obwohl der Standby-Knoten schließlich dem Cluster beigetreten ist, war der MEMBER_STATE-Status immer RECOVERING, was darauf hinweist, dass zu diesem Zeitpunkt Daten verfolgt werden.
- In dem Szenario wird nach der Aktivierung von „group_replication_paxos_single_leader“ auch der Neustart der Standby-Datenbank überprüft. Dadurch wird MGR in 10 Sekunden von 2 Knoten auf 3 Knoten wiederhergestellt.Aber es gab immer noch eine nicht verfügbare Zeit von etwa 7 Sekunden.Es scheint, dass dieser Parameter das Problem nicht vollständig lösen kann, dass beim Single-Master-MGR ein einzelner Knoten ausfällt und die gesamte Instanz nicht verfügbar ist.
- Bei DN wird die Standby-Datenbank in 10 Sekunden von 2 Knoten auf 3 Knoten wiederhergestellt, und die Primärdatenbank bleibt verfügbar. Hier kommt es zu kurzfristigen Schwankungen im TPS. Dies liegt daran, dass die Protokollreplikationsverzögerung der neu gestarteten Standby-Datenbank zurückbleibt und die verzögerten Protokolle aus der Hauptdatenbank abgerufen werden müssen Nach der Protokollüberprüfung ist die Gesamtleistung stabil.
3.3. RPO
Um das MGR-Mehrheitsausfall-RPO<>0-Szenario zu konstruieren, verwenden wir die Community-eigene MTR-Case-Methode, um Fehlerinjektionstests für MGR durchzuführen. Der entworfene Fall ist wie folgt:
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo ############################################################
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record

loose-group_replication_member_weight=100
loose-group_replication_member_weight=90
loose-group_replication_member_weight=80
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socket
Die Ergebnisse der Fallbearbeitung lauten wie folgt:
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
include/start_and_bootstrap_group_replication.inc
include/start_group_replication.inc
include/start_group_replication.inc
############################################################
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
INSERT INTO t1 VALUES(2);
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
Die ungefähre Logik eines Falls, der fehlende Zahlen reproduziert, ist wie folgt:
- MGR besteht aus 3 Knoten im Single-Master-Modus, Server 1/2/3, wobei Server 1 die Hauptdatenbank ist und 1 Datensatz c1=1 initialisiert
- Fault-Injection-Server 2/3 bleibt beim Schreiben des Relay-Protokolls hängen
- Mit dem Server 1-Knoten verbunden, den Datensatz von c1=2 geschrieben und die Transaktionsübergabe hat ebenfalls einen Erfolg zurückgegeben.
- Dann stürzt der Scheinserver1 ungewöhnlich ab (Maschinenfehler, kann nicht wiederhergestellt werden und es kann nicht auf Server 2/3 zugegriffen werden).
- Starten Sie Server 2/3 normal neu (schnelle Wiederherstellung), aber Server 2/3 kann den Cluster nicht in einen verwendbaren Zustand zurückversetzen.
- Stellen Sie eine Verbindung zum Server 2/3-Knoten her und fragen Sie die Datenbankdatensätze ab. Es wird nur der Datensatz von c1=1 angezeigt (Server 2/3 hat c1=2 verloren).
Gemäß dem obigen Fall kommt es bei MGR, wenn die meisten Server ausgefallen sind und die Hauptdatenbank nicht verfügbar ist, nach der Wiederherstellung der Standby-Datenbank zu einem Datenverlust von RPO<>0 und der Aufzeichnung eines erfolgreichen Commits Ursprünglich an den Kunden zurückgegebene Dokumente gehen verloren.
Für DN erfordert das Erreichen der Mehrheit, dass die Protokolle in der Mehrheit bestehen bleiben, sodass auch im obigen Szenario keine Daten verloren gehen und RPO = 0 garantiert werden kann.
3.4. Wiedergabeverzögerung der Standby-Datenbank
Im herkömmlichen Aktiv-Standby-Modus von MySQL enthält die Standby-Datenbank im Allgemeinen IO-Threads und Apply-Threads. Nach der Einführung des Paxos-Protokolls synchronisiert der IO-Thread hauptsächlich das Binlog der aktiven und Standby-Datenbank Hängt vom Overhead der Wiedergabe der Standby-Datenbank ab. Hier werden wir zur Wiedergabeverzögerung der Standby-Datenbank.
Wir verwenden Sysbench, um das oltp_write_only-Szenario zu testen und die Dauer der Verzögerung bei der Wiedergabe der Standby-Datenbank bei 100 Parallelität und unterschiedlicher Anzahl von Ereignissen zu testen.Die Verzögerungszeit für die Wiedergabe der Standby-Datenbank kann ermittelt werden, indem die Spalte APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP der Tabelle performance_schema.replication_applier_status_by_worker überwacht wird, um festzustellen, ob jeder Worker in Echtzeit arbeitet, um festzustellen, ob die Replikation beendet wurde.

Aus der Testergebnistabelle geht hervor:
- Bei gleicher Menge geschriebener Daten ist die Abschlusszeit der Standby-Datenbankwiedergabe aller Protokolle weitaus kürzer als die von MGR. Der Zeitverbrauch von DN beträgt nur 3 % bis 4 % der Zeit von MGR. Dies ist entscheidend für die Pünktlichkeit der Aktiv-/Standby-Umschaltung.
- Wenn die Anzahl der Schreibvorgänge zunimmt, bleibt der Vorteil der Standby-Datenbank-Wiedergabelatenz von DN gegenüber MGR weiterhin erhalten und ist sehr stabil.
- Bei der Analyse der Gründe für die Verzögerung der Wiedergabe der Standby-Datenbank übernimmt die Wiedergabestrategie der Standby-Datenbank von MGR die Gruppenreplikationskonsistenz mit dem Standardwert EVENTUAL, d. h. RO- und RW-Transaktionen warten vor der Ausführung nicht auf die Anwendung vorheriger Transaktionen. Dadurch kann die maximale Schreibleistung der Hauptdatenbank sichergestellt werden, die Verzögerung der Standby-Datenbank ist jedoch relativ groß (indem die Verzögerung der Standby-Datenbank und RPO = 0 geopfert werden, um Hochleistungsschreiben in der Hauptdatenbank zu ermöglichen und die Strombegrenzungsfunktion zu aktivieren). von MGR kann die Leistung ausgleichen und die Standby-Datenbank wird verzögert, aber die Leistung der Hauptdatenbank wird beeinträchtigt)
3.5. Testzusammenfassung
| | MGR | DN |
| Leistung | Transaktion lesen | Wohnung | Wohnung |
| Transaktion schreiben | Die Leistung ist nicht so gut wie bei DN, wenn RPO<>0 Bei RPO=0 ist die Leistung deutlich schlechter als bei DN Die Leistung bei der städteübergreifenden Bereitstellung sank erheblich um 27 % bis 82 %. | Die Leistung von Schreibtransaktionen ist viel höher als bei MGR Die stadtübergreifende Bereitstellungsleistung sinkt um 4 % auf 37 %. |
| Nervosität | Der Leistungs-Jitter ist schwerwiegend, der Jitter-Bereich beträgt 6–10 %. | Relativ stabil bei 3 %, nur die Hälfte des MGR |
| RTO | Die Hauptdatenbank ist ausgefallen | Die Anomalie wurde in 5 Sekunden entdeckt und in 23 Sekunden auf zwei Knoten reduziert. | Die Anomalie wurde in 5 Sekunden entdeckt und in 8 Sekunden auf zwei Knoten reduziert. |
| Starten Sie die Hauptbibliothek neu | Innerhalb von 5 Sekunden wurde eine Anomalie entdeckt und in 37 Sekunden wurden drei Knoten wiederhergestellt. | Eine Anomalie wird innerhalb von 5 Sekunden erkannt und drei Knoten werden in 15 Sekunden wiederhergestellt. |
| Ausfallzeit der Sicherungsdatenbank | Der Datenverkehr der Hauptdatenbank fiel für 20 Sekunden auf 0. Dies kann durch explizites Aktivieren von group_replication_paxos_single_leader gemildert werden. | Kontinuierliche Hochverfügbarkeit der Hauptdatenbank |
| Neustart der Standby-Datenbank | Der Datenverkehr der Hauptdatenbank fiel für 10 Sekunden auf 0. Das explizite Einschalten von group_replication_paxos_single_leader hat ebenfalls keine Auswirkung. | Kontinuierliche Hochverfügbarkeit der Hauptdatenbank |
| RPO | Fallwiederholung | RPO<>0, wenn die Mehrheitspartei untergeht Leistung und RPO=0 können nicht beides haben. | RPO = 0 |
| Verzögerung der Standby-Datenbank | Wiedergabezeit der Sicherungsdatenbank | Die Verzögerung zwischen Aktiv und Standby ist sehr groß. Leistung und primäre Backup-Latenz können nicht gleichzeitig erreicht werden. | Die Gesamtzeit, die für die Wiedergabe der gesamten Standby-Datenbank aufgewendet wird, beträgt 4 % der MGR, was dem 25-fachen der MGR entspricht. |
| Parameter | Schlüsselparameter |
- Die Flusskontrolle „group_replication_flow_control_mode“ ist standardmäßig aktiviert und muss so konfiguriert werden, dass sie deaktiviert wird, um die Leistung zu verbessern.
- Die statische Plug-in-Optimierung replication_optimize_for_static_plugin_config ist standardmäßig deaktiviert und muss zur Verbesserung der Leistung aktiviert werden
- group_replication_paxos_single_leader ist standardmäßig deaktiviert und muss aktiviert werden, um die Stabilität der Hauptdatenbank zu verbessern, wenn die Standby-Datenbank ausfällt.
- group_replication_consistency ist standardmäßig deaktiviert und garantiert nicht RPO=0. Wenn RPO=0 erforderlich ist, muss AFTER konfiguriert werden.
- Das Standard-group_replication_transaction_size_limit beträgt 143 MB und muss bei großen Transaktionen erhöht werden.
- binlog_transaction_dependency_tracking ist standardmäßig COMMIT_ORDER und muss auf WRITESET angepasst werden, um die Leistung der Standby-Datenbankwiedergabe zu verbessern.
| Standardkonfiguration, keine Notwendigkeit für Fachleute, die Konfiguration anzupassen |
4. Zusammenfassung
Nach eingehender technischer Analyse und LeistungsvergleichPolarDB-X Mit seinem selbst entwickelten X-Paxos-Protokoll und einer Reihe optimierter Designs hat DN viele Vorteile gegenüber MySQL MGR in Bezug auf Leistung, Korrektheit, Verfügbarkeit und Ressourcenaufwand gezeigt. Allerdings nimmt MGR auch eine wichtige Position im MySQL-Ökosystem ein Wenn Sie MGR optimal nutzen möchten, müssen Sie daher über ein professionelles Technik-, Betriebs- und Wartungsteam verfügen Unterstützung.
Bei großen Anforderungen mit hoher Parallelität und hoher Verfügbarkeit bietet die PolarDB-X-Speicher-Engine im Vergleich zu MGR einzigartige technische Vorteile und eine hervorragende Leistung.PolarDB-XDie DN-basierte Zentralversion (Standardversion) bietet ein gutes Gleichgewicht zwischen Funktionen und Leistung und ist somit eine äußerst wettbewerbsfähige Datenbanklösung.

