Ανάκτηση βάσης δεδομένων καταστροφής | Σε βάθος σύγκριση μεταξύ MySQL MGR και Alibaba Cloud PolarDB-X Paxos.
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Οικοσύστημα ανοιχτού κώδικα
Όπως όλοι γνωρίζουμε, οι κύριες και δευτερεύουσες βάσεις δεδομένων της MySQL (δύο κόμβοι) γενικά επιτυγχάνουν υψηλή διαθεσιμότητα δεδομένων μέσω ασύγχρονης αναπαραγωγής και ημισύγχρονης αναπαραγωγής (Semi-Sync), ωστόσο, σε μη φυσιολογικά σενάρια, όπως αποτυχίες δικτύου υπολογιστών και διακοπή λειτουργίας κεντρικού υπολογιστή Οι πρωτογενείς και δευτερεύουσες αρχιτεκτονικές θα αντιμετωπίσουν σοβαρά προβλήματα μετά την εναλλαγή HA. Θα υπάρχει πιθανότητα ασυνέπειας δεδομένων (αναφέρεται ως RPO!=0).Επομένως, εάν τα επιχειρηματικά δεδομένα είναι κάποιας σημασίας, δεν θα πρέπει να επιλέξετε ένα προϊόν βάσης δεδομένων με κύρια και δευτερεύουσα αρχιτεκτονική (δύο κόμβους), συνιστάται να επιλέξετε μια αρχιτεκτονική πολλαπλών αντιγράφων με RPO=0.
Η κοινότητα της MySQL, σχετικά με την εξέλιξη της τεχνολογίας πολλαπλών αντιγράφων με RPO=0:
- Η MySQL είναι επίσημα ανοιχτού κώδικα και κυκλοφόρησε τη λύση υψηλής διαθεσιμότητας MySQL Group Replication (MGR) που βασίζεται στην ομαδική αναπαραγωγή Το πρωτόκολλο Paxos είναι εσωτερικά ενσωματωμένο μέσω του XCOM για να διασφαλίσει τη συνοχή των δεδομένων.
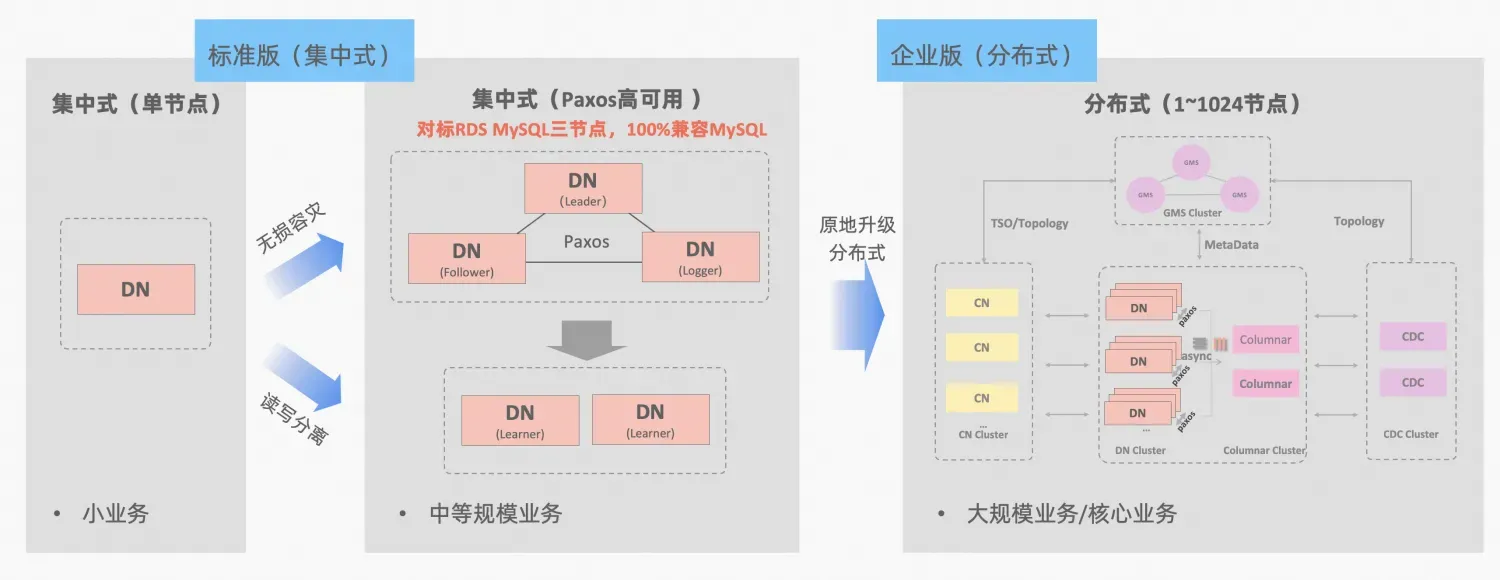
- Ali Cloud PolarDB-X , που προέρχεται από την επιχειρηματική στίλβωση και επαλήθευση του ηλεκτρονικού εμπορίου Double Eleven της Alibaba και την πολλαπλή δραστηριότητα σε διαφορετικά μέρη, θα είναι ανοιχτού κώδικα σε ολόκληρο τον πυρήνα τον Οκτώβριο του 2021, αγκαλιάζοντας πλήρως το οικοσύστημα ανοιχτού κώδικα MySQL. Το PolarDB-X είναι τοποθετημένο ως μια κεντρική και κατανεμημένη ολοκληρωμένη βάση δεδομένων , αλλά επίσης έχει τα χαρακτηριστικά του εξαιρετικά επεκτάσιμου κινητήρα συναλλαγών, της ευέλικτης λειτουργίας και συντήρησης ανάκτησης καταστροφών και χαμηλού κόστους αποθήκευσης δεδομένων: ".PolarDB-X Ανοιχτού Κώδικα |》。
PolarDB-X Η έννοια της κεντρικής και κατανεμημένης ολοκλήρωσης: ο κόμβος δεδομένων DN μπορεί να χρησιμοποιηθεί ανεξάρτητα ως κεντρική (τυπική έκδοση) φόρμα, η οποία είναι πλήρως συμβατή με τη φόρμα αυτόνομης βάσης δεδομένων. Όταν η επιχείρηση αναπτύσσεται στο σημείο όπου απαιτείται κατανεμημένη επέκταση, η αρχιτεκτονική αναβαθμίζεται σε μια κατανεμημένη μορφή και τα κατανεμημένα στοιχεία συνδέονται άψογα με τους αρχικούς κόμβους δεδομένων , και μπορείτε να απολαύσετε τη διανομή της χρηστικότητας και της επεκτασιμότητας που προσφέρει αυτός ο τύπος, περιγραφή αρχιτεκτονικής:"Κεντρική Κατανεμημένη Ενοποίηση"
Το MGR της MySQL και η τυπική έκδοση DN του PolarDB-X χρησιμοποιούν το πρωτόκολλο Paxos από τη χαμηλότερη αρχή, λοιπόν, ποιες είναι οι συγκεκριμένες επιδόσεις και οι διαφορές στην πραγματική χρήση; Αυτό το άρθρο αναλύει τις πτυχές της σύγκρισης αρχιτεκτονικής, τις βασικές διαφορές και τη σύγκριση δοκιμής.
Περιγραφή συντομογραφίας MGR/DN: Το MGR αντιπροσωπεύει την τεχνική μορφή του MySQL MGR και το DN αντιπροσωπεύει την τεχνική μορφή του PolarDB-X single DN κεντρικό (τυπική έκδοση).
TL;DR
Η λεπτομερής συγκριτική ανάλυση είναι σχετικά μεγάλη, επομένως μπορείτε να διαβάσετε πρώτα την περίληψη και το συμπέρασμα, εάν σας ενδιαφέρει, μπορείτε να ακολουθήσετε την περίληψη και να αναζητήσετε στοιχεία σε επόμενα άρθρα.
Το MySQL MGR δεν συνιστάται για γενικές επιχειρήσεις και εταιρείες επειδή απαιτεί επαγγελματικές τεχνικές γνώσεις και μια ομάδα λειτουργίας και συντήρησης για να το χρησιμοποιήσει καλά Αυτό το άρθρο αναπαράγει επίσης τρεις «κρυφές παγίδες» του MySQL MGR που κυκλοφορούν στον κλάδο εδώ και πολύ καιρό. :
- Dark Pit 1: Τα πρωτόκολλα MySQL MGR και XCOM υιοθετούν τη λειτουργία πλήρους μνήμης Προς το παρόν, η σχεδίαση του MGR δεν μπορεί να επιτύχει τόσο απόδοση όσο και RPO.
- Παγίδα 2: Η απόδοση του MySQL MGR είναι κακή όταν υπάρχει καθυστέρηση δικτύου. παραμέτρους απόδοσης πόλης, είναι μόνο το 1/5 της ίδιας πόλης, εάν η εγγύηση δεδομένων RPO=0 είναι ενεργοποιημένη, η απόδοση θα είναι ακόμη χειρότερη.Επομένως, το MySQL MGR είναι πιο κατάλληλο για χρήση στο ίδιο σενάριο αίθουσας υπολογιστών, αλλά δεν είναι κατάλληλο για ανάκτηση καταστροφής δωματίου μεταξύ υπολογιστών.
- Παγίδα 3: Στην αρχιτεκτονική πολλαπλών αντιγράφων του MySQL MGR, η αποτυχία του κόμβου αναμονής θα έχει ως αποτέλεσμα η κυκλοφορία του κύριου κόμβου Leader να πέσει στο 0, κάτι που δεν συνάδει με την κοινή λογική. Το άρθρο επικεντρώνεται στην προσπάθεια ενεργοποίησης της λειτουργίας single leader του MGR (σε σύγκριση με την προηγούμενη αρχιτεκτονική αντίγραφο master-slave της MySQL), προσομοιώνοντας τις δύο ενέργειες του χρόνου διακοπής λειτουργίας και της ανάκτησης του υποτελούς αντιγράφου Οι λειτουργίες λειτουργίας και συντήρησης του υποτελούς κόμβου προκαλούν επίσης τον κύριο κόμβος (Leader) για να εμφανιστεί Η κίνηση έπεσε στο 0 (διάρκεια περίπου 10 δευτερόλεπτα) και η συνολική λειτουργικότητα και δυνατότητα συντήρησης ήταν σχετικά κακή.Επομένως, το MySQL MGR έχει σχετικά υψηλές απαιτήσεις σχετικά με τη λειτουργία και τη συντήρηση του κεντρικού υπολογιστή και απαιτεί μια επαγγελματική ομάδα DBA.
Σε σύγκριση με το MySQL MGR, το PolarDB-X Paxos δεν έχει παγίδες παρόμοιες με το MGR όσον αφορά τη συνοχή των δεδομένων, την ανάκτηση δωματίου μεταξύ υπολογιστών και τη λειτουργία και τη συντήρηση κόμβων, ωστόσο, έχει επίσης κάποιες μικρές ελλείψεις και πλεονεκτήματα στην ανάκτηση καταστροφών.
- Σε ένα απλό σενάριο της ίδιας αίθουσας υπολογιστών, η απόδοση μόνο για ανάγνωση σε χαμηλή συγχρονισμό και η απόδοση καθαρής εγγραφής σε υψηλή ταυτόχρονη λειτουργία είναι ελαφρώς χαμηλότερη από την MySQL MGR κατά περίπου 5%. υπάρχει χώρος για περαιτέρω βελτιστοποίηση στην απόδοση.
- Πλεονεκτήματα: 100% συμβατό με τις δυνατότητες της MySQL 5.7/8.0. Ταυτόχρονα, έχουν γίνει πιο βελτιστοποιημένες βελτιστοποιήσεις στις διαδρομές αναμονής πολλαπλών αντιγράφων και εναλλαγής RTO με υψηλή διαθεσιμότητα <= 8 δευτερόλεπτα -σενάριο ανάκτησης λεπτών καταστροφών στον κλάδο Όλα έχουν καλή απόδοση και μπορούν να αντικαταστήσουν το semi-sync (semi-sync), το MGR κ.λπ.
1. Σύγκριση αρχιτεκτονικής
Γλωσσάριο
Περιγραφή συντομογραφίας MGR/DN:
- MGR: Η τεχνική μορφή του MySQL MGR, η συντομογραφία του επόμενου περιεχομένου: MGR
- DN: Το Alibaba Cloud PolarDB-X είναι μια κεντρική (τυπική έκδοση) τεχνική φόρμα ως: DN
MGR
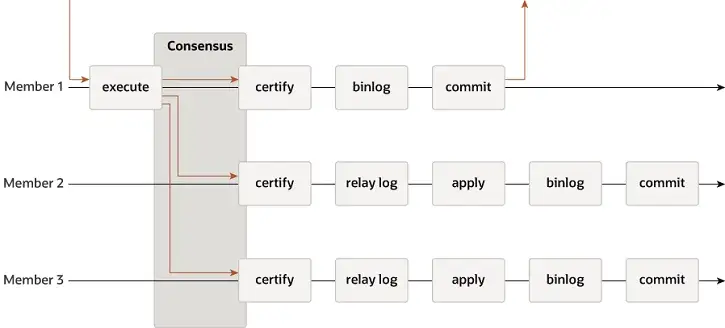
Το MGR υποστηρίζει λειτουργίες single-master και multi-master και επαναχρησιμοποιεί πλήρως το σύστημα αναπαραγωγής της MySQL, συμπεριλαμβανομένων των Event, Binlog & Relaylog, Apply, Binlog Apply Recovery και GTID. Η βασική διαφορά από το DN είναι ότι το σημείο εισόδου για την πλειοψηφία καταγραφής συναλλαγών MGR για την επίτευξη συναίνεσης είναι πριν από τη δέσμευση της κύριας συναλλαγής βάσης δεδομένων.
-
- Πριν από τη δέσμευση της συναλλαγής, η συνάρτηση πριν_επιτροπή hook group_replication_trans_before_commit καλείται να εισαγάγει την πλειοψηφική αναπαραγωγή του MGR.
- Το MGR χρησιμοποιεί το πρωτόκολλο Paxos για να συγχρονίσει τα συμβάντα Binlog που έχουν αποθηκευτεί προσωρινά στο THD σε όλους τους διαδικτυακούς κόμβους
- Αφού λάβει την απάντηση της πλειοψηφίας, η MGR καθορίζει ότι η συναλλαγή μπορεί να υποβληθεί
- Η THD εισέρχεται στη διαδικασία υποβολής της ομάδας συναλλαγών και ξεκινά τη σύνταξη τοπικής ενημέρωσης Binlog Επανάληψη απάντησης μηνύματος ΟΚ πελάτη
-
- Το Paxos Engine της MGR συνεχίζει να ακούει μηνύματα πρωτοκόλλου από τον Leader
- Μετά από μια πλήρη διαδικασία συναίνεσης των Παξών, επιβεβαιώνεται ότι αυτό το συμβάν (παρτίδα) έχει φτάσει στην πλειοψηφία στο σύμπλεγμα
- Γράψτε το ληφθέν συμβάν στο αρχείο καταγραφής αναμετάδοσης, IO Thread Εφαρμογή αρχείου καταγραφής αναμετάδοσης
- Η εφαρμογή Relay Log περνά από μια πλήρη διαδικασία ομαδικής υποβολής και η βάση δεδομένων αναμονής θα δημιουργήσει τελικά το δικό της αρχείο binlog.
Ο λόγος για τον οποίο το MGR υιοθετεί την παραπάνω διαδικασία είναι επειδή το MGR είναι από προεπιλογή σε λειτουργία multi-master και κάθε κόμβος μπορεί να γράψει, επομένως, ο κόμβος ακολούθου σε ένα μόνο Paxos Group πρέπει πρώτα να μετατρέψει το ληφθέν αρχείο καταγραφής σε RelayLog και μετά να συνδυάσει. με τη συναλλαγή εγγραφής που λαμβάνει ως ηγέτης για υποβολή , παράγεται το αρχείο Binlog για να υποβάλει την τελική συναλλαγή στη διαδικασία υποβολής ομάδας δύο σταδίων.
DN
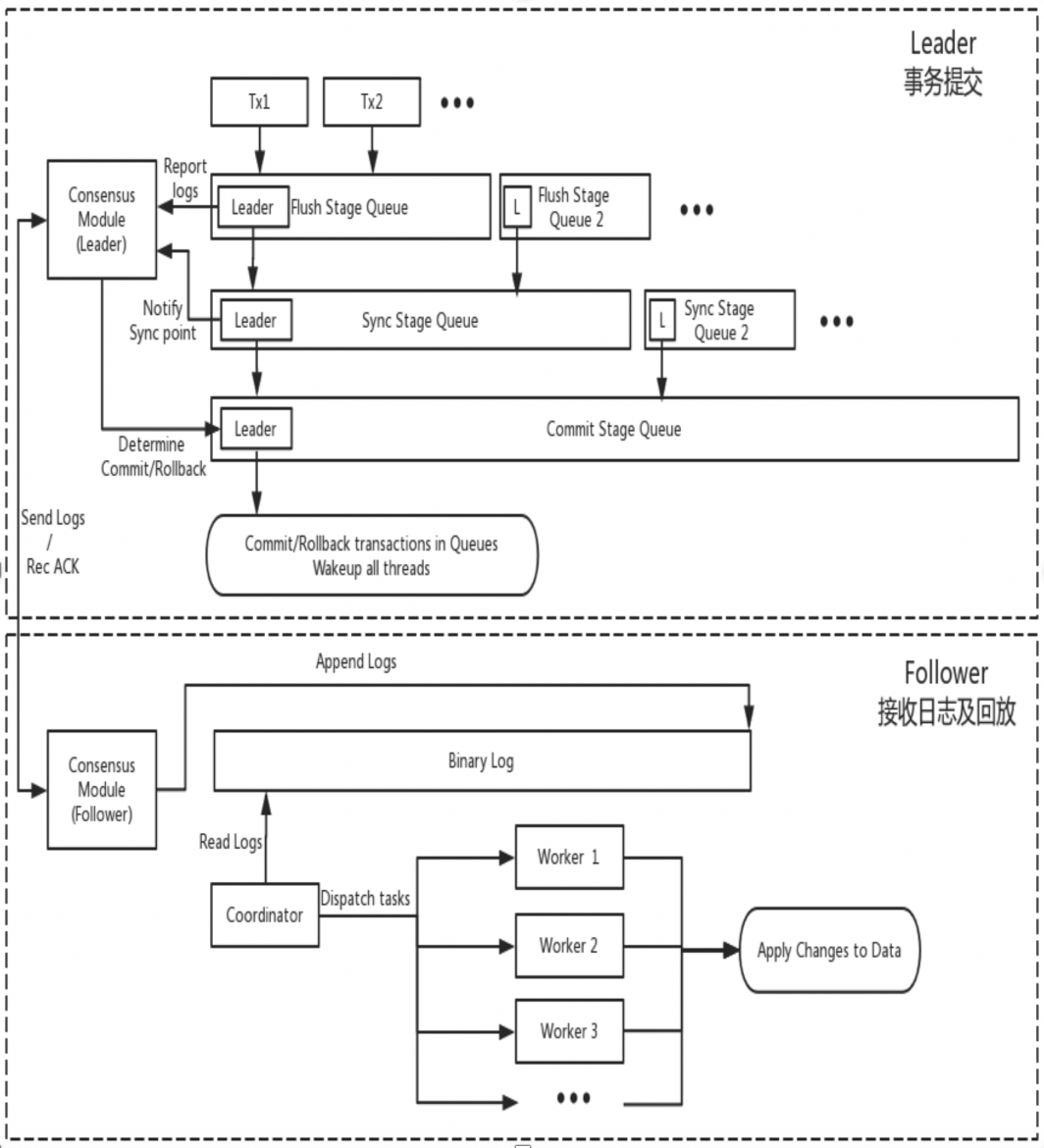
Το DN επαναχρησιμοποιεί τη βασική δομή δεδομένων και τον κώδικα σε επίπεδο λειτουργίας της MySQL, αλλά ενσωματώνει στενά την αναπαραγωγή αρχείων καταγραφής, τη διαχείριση αρχείων καταγραφής, την αναπαραγωγή αρχείων καταγραφής και την ανάκτηση σφαλμάτων με το πρωτόκολλο X-Paxos για να σχηματίσει το δικό του σύνολο πολλαπλών αντιγράφων και μηχανισμού κατάστασης. Η βασική διαφορά από το MGR είναι ότι το σημείο εισόδου για την πλειοψηφία καταγραφής συναλλαγών DN για την επίτευξη συναίνεσης είναι κατά τη διάρκεια της διαδικασίας υποβολής συναλλαγών της κύριας βάσης δεδομένων.
-
- Εισαγάγετε τη διαδικασία ομαδικής υποβολής της συναλλαγής Στη φάση Flush της ομαδικής υποβολής, τα συμβάντα σε κάθε THD εγγράφονται στο αρχείο Binlog και, στη συνέχεια, το αρχείο καταγραφής μεταδίδεται ασύγχρονα σε όλους τους ακόλουθους μέσω των X-Paxos.
- Στη φάση Συγχρονισμού της ομαδικής υποβολής, το Binlog διατηρείται πρώτα και, στη συνέχεια, ενημερώνεται η θέση επιμονής X-Paxos.
- Στη φάση δέσμευσης της ομαδικής υποβολής, πρέπει πρώτα να περιμένετε να λάβει η πλειοψηφία των X-Paxos απάντηση, στη συνέχεια να υποβάλετε την ομάδα συναλλαγών και, τέλος, να απαντήσετε με ένα μήνυμα ΟΚ από τον πελάτη.
-
- Οι X-Paxos συνεχίζουν να ακούν για μηνύματα πρωτοκόλλου από τον Leader
- Λάβετε μια (ομαδική) Συμβάντα, γράψτε στο τοπικό Binlog και απαντήστε
- Λαμβάνεται το επόμενο μήνυμα, το οποίο φέρει τον δείκτη Commit της θέσης όπου έχει επιτευχθεί η πλειοψηφία.
- Το νήμα Εφαρμογή SQL συνεχίζει να εφαρμόζει το ληφθέν αρχείο καταγραφής Binlog στο παρασκήνιο και το εφαρμόζει μόνο στη θέση πλειοψηφίας το πολύ.
Ο λόγος για αυτόν τον σχεδιασμό είναι ότι το DN υποστηρίζει επί του παρόντος μόνο λειτουργία single-master, επομένως το αρχείο καταγραφής σε επίπεδο πρωτοκόλλου X-Paxos είναι ο ίδιος ο ακόλουθος Binlog επίσης παραλείπει το αρχείο καταγραφής αναμετάδοσης και το περιεχόμενο δεδομένων του μόνιμου αρχείου καταγραφής του και το αρχείο καταγραφής του ηγέτη. ισούνται με την ίδια τιμή.
2. Βασικές διαφορές
2.1 Αποτελεσματικότητα πρωτοκόλλου Παξών

MGR
- Το πρωτόκολλο Paxos της MGR υλοποιείται με βάση το πρωτόκολλο Mencius, το οποίο ανήκει στη θεωρία Multi-Paxos. Η διαφορά είναι ότι η Mencius έχει κάνει βελτιώσεις βελτιστοποίησης στη μείωση του φορτίου του κύριου κόμβου και στην αύξηση της απόδοσης.
- Το πρωτόκολλο Paxos του MGR υλοποιείται από εξαρτήματα XCOM και υποστηρίζει την ανάπτυξη πολλαπλών βασικών και απλών κυρίων σε λειτουργία, το Binlog στο Leader εκπέμπει ατομικά στον κόμβο ακολούθου μια τυπική διαδικασία Multi-Paxos.
- Για να ικανοποιήσει το μεγαλύτερο μέρος μιας συναλλαγής, το XCOM πρέπει να περάσει από τουλάχιστον τρεις αλληλεπιδράσεις μηνυμάτων Accept+AckAccept+Learn, δηλαδήΤουλάχιστον 1,5 RTT γενικά.Απαιτεί το πολύ τρεις αλληλεπιδράσεις μηνυμάτων: Prepare+AckPrepare+Accept+AckAccept+Learn.Δηλαδή, το πολύ 2,5 RTT γενικά συνολικά
- Δεδομένου ότι το πρωτόκολλο Paxos ολοκληρώνεται με υψηλή συνοχή στη μονάδα XCOM και δεν γνωρίζει το σύστημα αναπαραγωγής MySQL, ο Leader πρέπει να περιμένει να ολοκληρωθεί η πλήρης διαδικασία Paxos πριν πραγματοποιήσει τη συναλλαγή τοπικά, συμπεριλαμβανομένης της εμμονής του Binlog και της ομαδικής υποβολής.
- Αφού ο ακόλουθος ολοκληρώσει την υποβολή της πλειοψηφίας, θα διατηρήσει ασύγχρονα τα συμβάντα στο αρχείο καταγραφής αναμετάδοσης και, στη συνέχεια, η εφαρμογή και η ομάδα SQL Thread θα υποβάλουν το Binlog παραγωγής.
- Δεδομένου ότι το αρχείο καταγραφής που συγχρονίζεται από τους Paxos είναι ένα Binlog που δεν ταξινομείται πριν εισέλθει στη διαδικασία υποβολής ομάδας, η σειρά των συμβάντων Binlog στο Leader ενδέχεται να μην είναι ίδια με τη σειρά των συμβάντων στο αρχείο καταγραφής αναμετάδοσης στον κόμβο ακόλουθο.

DN
- Το πρωτόκολλο Paxos της DN υλοποιείται με βάση το πρωτόκολλο Raft και επίσης ανήκει στη θεωρία Multi-Paoxs. Η διαφορά είναι ότι το πρωτόκολλο Raft έχει ισχυρότερη εγγύηση ηγεσίας και εγγύηση μηχανικής σταθερότητας.
- Το πρωτόκολλο Paxos του DN ολοκληρώνεται από το στοιχείο X-Paoxs. Η προεπιλογή είναι η λειτουργία single-master .
- Για να ικανοποιήσει το μεγαλύτερο μέρος μιας συναλλαγής, το X-Paoxs χρειάζεται μόνο να περάσει από τις δύο αλληλεπιδράσεις μηνυμάτων Append+AckAppend και μόνο1 RTT γενικά
- Αφού ο Leader στείλει το αρχείο καταγραφής στον ακόλουθο, εφόσον η πλειοψηφία είναι ικανοποιημένη, δεσμεύει τη συναλλαγή χωρίς να περιμένει τη μετάδοση του Commit Index στο δεύτερο στάδιο.
- Για να μπορέσει ο ακόλουθος να ολοκληρώσει την υποβολή της πλειοψηφίας, όλα τα αρχεία καταγραφής συναλλαγών πρέπει να διατηρηθούν. Αυτό διαφέρει σημαντικά από το MGR του XCOM.
- Το Commit Index μεταφέρεται σε επόμενα μηνύματα και μηνύματα καρδιακού παλμού και ο ακόλουθος εκτελεί το Apply Event αφού το CommitIndex προωθηθεί προς τα επάνω.
- Τα περιεχόμενα Binlog του Leader και του Follower είναι με την ίδια σειρά, τα αρχεία καταγραφής Raft δεν έχουν τρύπες και ο μηχανισμός Batching/Pipeline χρησιμοποιείται για την αύξηση της απόδοσης αναπαραγωγής αρχείων καταγραφής.
- Σε σύγκριση με το MGR, ο Leader έχει πάντα μόνο μία καθυστέρηση μετ' επιστροφής όταν δεσμεύεται μια συναλλαγή., πολύ κρίσιμο για κατανεμημένες εφαρμογές ευαίσθητες σε καθυστερήσεις
2.2. RPO
Θεωρητικά, τόσο το Paxos όσο και το Raft μπορούν να διασφαλίσουν τη συνέπεια των δεδομένων και τα αρχεία καταγραφής που έχουν φτάσει στην πλειοψηφία μετά το Crash Recovery δεν θα χαθούν, αλλά εξακολουθούν να υπάρχουν διαφορές σε συγκεκριμένα έργα.
MGR
Το XCOM ενσωματώνει πλήρως το πρωτόκολλο Paxos και όλα τα δεδομένα του πρωτοκόλλου του αποθηκεύονται πρώτα στην κρυφή μνήμη Από προεπιλογή, η συναλλαγή για να φτάσει στην πλειοψηφία δεν απαιτεί επιμονή στο αρχείο καταγραφής. Στην περίπτωση που οι περισσότερες πίτες είναι κάτω και το Leader αποτύχει, θα υπάρξει σοβαρό πρόβλημα RPO != 0.Ας υποθέσουμε ένα ακραίο σενάριο:
- Το σύμπλεγμα MGR αποτελείται από τρεις κόμβους ABC, από τους οποίους το AB είναι μια ανεξάρτητη αίθουσα υπολογιστών στην ίδια πόλη και ο C είναι ένας κόμβος μεταξύ πόλεων. Το A είναι Leader, το BC είναι κόμβος ακόλουθος
- Έναρξη συναλλαγής 001 στον κόμβο Leader A Το Leader A εκπέμπει το αρχείο καταγραφής της συναλλαγής 001 στον κόμβο BC Εάν η πλειοψηφία είναι ικανοποιημένη μέσω του πρωτοκόλλου Paxos. Το τμήμα AB αποτελούσε την πλειοψηφία και ο κόμβος C δεν έλαβε το αρχείο καταγραφής της συναλλαγής 001 λόγω καθυστέρησης του δικτύου μεταξύ πόλεων.
- Την επόμενη στιγμή, ο Leader A υποβάλλει τη συναλλαγή 001 και επιστρέφει την επιτυχία του πελάτη, πράγμα που σημαίνει ότι η συναλλαγή 001 έχει υποβληθεί στη βάση δεδομένων.
- Αυτή τη στιγμή, στον Ακόλουθο του κόμβου Β, το αρχείο καταγραφής της συναλλαγής 001 βρίσκεται ακόμα στη μνήμη cache του XCOM και δεν είχε χρόνο να ξεπλυθεί στο RelayLog αυτή τη στιγμή, ο ακόλουθος του κόμβου C εξακολουθεί να μην έχει λάβει τη συναλλαγή 001 αρχείο καταγραφής από τον αρχηγό του κόμβου Α.
- Αυτή τη στιγμή, ο κόμβος AB είναι εκτός λειτουργίας, ο κόμβος Α αποτυγχάνει και δεν μπορεί να ανακτηθεί για μεγάλο χρονικό διάστημα, ο κόμβος Β επανεκκινείται και ανακτά γρήγορα και οι κόμβοι BC συνεχίζουν να παρέχουν υπηρεσίες ανάγνωσης και εγγραφής.
- Δεδομένου ότι το αρχείο καταγραφής συναλλαγής 001 δεν παρέμεινε στο RelayLog του κόμβου Β κατά τη διάρκεια του χρόνου διακοπής λειτουργίας, ούτε ελήφθη από τον κόμβο C, επομένως αυτή τη στιγμή, ο κόμβος BC έχει πραγματικά χάσει τη συναλλαγή 001 και δεν μπορεί να την ανακτήσει.
- Σε αυτό το σενάριο όπου το κόμμα της πλειοψηφίας είναι κάτω, RPO!=0
Σύμφωνα με τις προεπιλεγμένες παραμέτρους της κοινότητας, η πλειονότητα των συναλλαγών δεν απαιτεί επιμονή στο αρχείο καταγραφής και δεν εγγυάται RPO=0 Αυτό μπορεί να θεωρηθεί ως συμβιβασμός για την απόδοση στην υλοποίηση του έργου XCOM. Για να διασφαλίσετε το απόλυτο RPO=0, πρέπει να διαμορφώσετε την παράμετρο group_replication_consistency που ελέγχει τη συνοχή ανάγνωσης και εγγραφής σε AFTER, ωστόσο, σε αυτήν την περίπτωση, εκτός από την επιβάρυνση δικτύου 1,5 RTT, η συναλλαγή θα απαιτήσει μια επιβάρυνση καταγραφής IO για να φτάσει στην πλειοψηφία. και η απόδοση θα είναι πολύ κακή.
DN
Το PolarDB-X DN χρησιμοποιεί το X-Paxos για να εφαρμόσει ένα κατανεμημένο πρωτόκολλο και είναι βαθιά συνδεδεμένο με τη διαδικασία ομαδικής δέσμευσης της MySQL Όταν υποβάλλεται μια συναλλαγή, απαιτείται η πλειοψηφία να επιβεβαιώσει την τοποθέτηση και την επιμονή πριν επιτραπεί η πραγματική υποβολή. Το μεγαλύτερο μέρος της τοποθέτησης δίσκου εδώ αναφέρεται στην τοποθέτηση Binlog της κύριας βιβλιοθήκης Το νήμα IO της βιβλιοθήκης αναμονής λαμβάνει το αρχείο καταγραφής της κύριας βιβλιοθήκης και το γράφει στο δικό του Binlog για επιμονή. Επομένως, ακόμη και αν όλοι οι κόμβοι αποτύχουν σε ακραία σενάρια, τα δεδομένα δεν θα χαθούν και το RPO=0 μπορεί να είναι εγγυημένο.
2.3. RTO
Ο χρόνος RTO είναι στενά συνδεδεμένος με το χρόνο της κρύας επανεκκίνησης του ίδιου του συστήματος, το οποίο αντικατοπτρίζεται στις συγκεκριμένες βασικές λειτουργίες:Μηχανισμός ανίχνευσης σφαλμάτων->μηχανισμός ανάκτησης σφαλμάτων->μηχανισμός κύριας επιλογής->εξισορρόπηση αρχείων καταγραφής
2.3.1 Ανίχνευση σφαλμάτων
MGR
- Κάθε κόμβος στέλνει περιοδικά πακέτα καρδιακών παλμών σε άλλους κόμβους για να ελέγχει εάν οι άλλοι κόμβοι είναι υγιείς.
- Εάν ο τρέχων κόμβος διαπιστώσει ότι άλλοι κόμβοι δεν έχουν ανταποκριθεί μετά το group_replication_member_expel_timeout (προεπιλογή 5s), θα θεωρηθεί ως αποτυχημένος κόμβος και θα αποβληθεί από το σύμπλεγμα.
- Για εξαιρέσεις όπως διακοπή δικτύου ή μη κανονική επανεκκίνηση, μετά την αποκατάσταση του δικτύου, ένας μεμονωμένος αποτυχημένος κόμβος θα προσπαθήσει να ενταχθεί αυτόματα στο σύμπλεγμα και στη συνέχεια να συνδέσει το αρχείο καταγραφής.
DN
- Ο κόμβος Leader στέλνει περιοδικά πακέτα καρδιακού παλμού σε άλλους κόμβους για να ελέγχει εάν οι άλλοι κόμβοι είναι υγιείς. Το χρονικό όριο εκλογών ελέγχεται από την παράμετρο consensus_election_timeout Η προεπιλογή είναι 5s, επομένως η περίοδος παλμών του αρχηγού είναι προεπιλεγμένη σε 1s.
- Εάν το Leader διαπιστώσει ότι άλλοι κόμβοι είναι εκτός σύνδεσης, θα συνεχίσει να στέλνει περιοδικά πακέτα καρδιακών παλμών σε όλους τους άλλους κόμβους για να διασφαλίσει ότι οι άλλοι κόμβοι μπορούν να έχουν πρόσβαση εγκαίρως μετά τη συντριβή και την ανάκτηση.Ωστόσο, ο κόμβος Leader δεν στέλνει πλέον αρχεία καταγραφής συναλλαγών στον κόμβο εκτός σύνδεσης.
- Οι μη αρχηγοί κόμβοι δεν στέλνουν πακέτα ανίχνευσης καρδιακού παλμού, αλλά εάν ο κόμβος που δεν είναι ηγέτης διαπιστώσει ότι δεν έχει λάβει τον καρδιακό παλμό από τον κόμβο αρχηγού μετά το consensus_election_timeout, θα ενεργοποιηθεί μια επανεκλογή.
- Για εξαιρέσεις όπως διακοπή δικτύου ή μη κανονική επανεκκίνηση, μετά την αποκατάσταση του δικτύου, ο ελαττωματικός κόμβος θα ενταχθεί αυτόματα στο σύμπλεγμα.
- Ως εκ τούτου, όσον αφορά τον εντοπισμό σφαλμάτων, το DN παρέχει περισσότερες διεπαφές διαμόρφωσης λειτουργίας και συντήρησης και ο εντοπισμός σφαλμάτων σε σενάρια ανάπτυξης μεταξύ πόλεων θα είναι πιο ακριβής.
2.3.2 Ανάκτηση συντριβής
MGR
-
- Το πρωτόκολλο Paxos που υλοποιείται από το XCOM είναι σε κατάσταση μνήμης.Εάν κλείσουν όλοι οι κόμβοι, το πρωτόκολλο δεν μπορεί να αποκατασταθεί Μετά την επανεκκίνηση του συμπλέγματος, απαιτείται μη αυτόματη παρέμβαση για την επαναφορά του.
- Εάν μόνο ένας μεμονωμένος κόμβος διακοπεί και ανακτηθεί, αλλά ο κόμβος Follower υστερεί σε σχέση με τον κόμβο Leader με περισσότερα αρχεία καταγραφής συναλλαγών και τα αρχεία καταγραφής συναλλαγών που έχουν αποθηκευτεί στην κρυφή μνήμη XCOM στο Leader έχουν διαγραφεί, η μόνη επιλογή είναι να χρησιμοποιήσετε τη διαδικασία Global Recovery ή Clone.
- Το μέγεθος της κρυφής μνήμης XCOM ελέγχεται από το group_replication_message_cache_size, η προεπιλογή είναι 1 GB
- Καθολική ανάκτηση σημαίνει ότι όταν ένας κόμβος επανέρχεται στο σύμπλεγμα, ανακτά δεδομένα λαμβάνοντας τα απαιτούμενα αρχεία καταγραφής συναλλαγών που λείπουν (Binary Log) από άλλους κόμβους.Αυτή η διαδικασία βασίζεται σε τουλάχιστον έναν κόμβο στο σύμπλεγμα που διατηρεί όλα τα απαιτούμενα αρχεία καταγραφής συναλλαγών
- Το Clone βασίζεται στο Clone Plugin, το οποίο χρησιμοποιείται για ανάκτηση όταν ο όγκος των δεδομένων είναι μεγάλος ή λείπουν πολλά αρχεία καταγραφής.Λειτουργεί αντιγράφοντας ένα στιγμιότυπο ολόκληρης της βάσης δεδομένων στον κόμβο που έχει συντριβεί, ακολουθούμενο από έναν τελικό συγχρονισμό με το πιο πρόσφατο αρχείο καταγραφής συναλλαγών
- Οι διαδικασίες Global Recovery και Clone είναι συνήθως αυτοματοποιημένες, αλλά σε ορισμένες ειδικές περιπτώσεις, όπως προβλήματα δικτύου ή έχει εκκαθαριστεί η μνήμη cache XCOM των άλλων δύο κόμβων, απαιτείται μη αυτόματη παρέμβαση.
DN
-
- Το πρωτόκολλο X-Paxos χρησιμοποιεί την επιμονή Binlog Κατά την ανάκτηση από ένα crash, οι υποβληθείσες συναλλαγές θα αποκατασταθούν πλήρως πρώτα. Για συναλλαγές σε εκκρεμότητα, πρέπει να περιμένετε μέχρι το επίπεδο πρωτοκόλλου XPaxos να καταλήξει σε συμφωνία για τον προσδιορισμό της σχέσης master-slave πριν πραγματοποιήσετε ή επαναφέρετε τη συναλλαγή. Η όλη διαδικασία είναι πλήρως αυτοματοποιημένη.Ακόμα κι αν όλοι οι κόμβοι είναι εκτός λειτουργίας, το σύμπλεγμα μπορεί να ανακτήσει αυτόματα μετά την επανεκκίνηση.
- Για σενάρια όπου ο κόμβος ακόλουθος υστερεί σε σχέση με τον κόμβο Leader σε πολλά αρχεία καταγραφής συναλλαγών, εφόσον το αρχείο Binlog στο Leader δεν έχει διαγραφεί, ο κόμβος ακολούθου σίγουρα θα καλυφθεί.
- Επομένως, όσον αφορά την ανάκτηση σύγκρουσης, το DN δεν απαιτεί καθόλου χειροκίνητη παρέμβαση.
2.3.3 Επιλογή του ηγέτη
Στη λειτουργία single-master, τα XCOM και DN X-Paxos της MGR, μια ισχυρή λειτουργία leader, ακολουθούν την ίδια βασική αρχή για την επιλογή του leader - τα αρχεία καταγραφής που έχουν συμφωνηθεί από το σύμπλεγμα δεν μπορούν να επαναφερθούν. Αλλά όταν πρόκειται για το αρχείο καταγραφής χωρίς συναίνεση, υπάρχουν διαφορές
MGR
- Η επιλογή Leader αφορά περισσότερο ποιος κόμβος θα χρησιμεύσει ως υπηρεσία Leader στη συνέχεια.Αυτό το Leader δεν έχει απαραίτητα το πιο πρόσφατο αρχείο καταγραφής συναίνεσης όταν εκλέγεται, επομένως πρέπει να συγχρονίσει τα πιο πρόσφατα αρχεία καταγραφής από άλλους κόμβους του συμπλέγματος και να παρέχει υπηρεσίες ανάγνωσης και εγγραφής μετά τη σύνδεση των αρχείων καταγραφής.
- Το πλεονέκτημα αυτού είναι ότι η επιλογή του ίδιου του Leader είναι ένα στρατηγικό προϊόν, όπως το βάρος και η τάξη. Το MGR ελέγχει το βάρος κάθε κόμβου μέσω της παραμέτρου group_replication_member_weight
- Το μειονέκτημα είναι ότι ο ίδιος ο νεοεκλεγείς Leader μπορεί να έχει μεγάλη καθυστέρηση αναπαραγωγής και πρέπει να συνεχίσει να προλαβαίνει το αρχείο καταγραφής ή μπορεί να έχει μεγάλη καθυστέρηση εφαρμογής και πρέπει να συνεχίσει να προλαβαίνει την εφαρμογή καταγραφής για να μπορέσει να παρέχει ανάγνωση και ανάγνωση και γράψτε υπηρεσίες.Αυτό έχει ως αποτέλεσμα μεγαλύτερο χρόνο RTO
DN
- Η εκλογή αρχηγού είναι με την έννοια του πρωτοκόλλου Όποιος κόμβος έχει τα αρχεία καταγραφής όλων των κομμάτων της πλειοψηφίας στο σύμπλεγμα μπορεί να εκλεγεί ως αρχηγός, επομένως αυτός ο κόμβος μπορεί να ήταν ακόλουθος ή καταγραφέας.
- Το Logger δεν μπορεί να παρέχει υπηρεσίες ανάγνωσης και γραφής Αφού συγχρονίσει τα αρχεία καταγραφής με άλλους κόμβους, θα εγκαταλείψει ενεργά τον ρόλο του Leader.
- Προκειμένου να διασφαλιστεί ότι ο καθορισμένος κόμβος θα γίνει ο ηγέτης, ο DN χρησιμοποιεί τη στρατηγική αισιόδοξου βάρους + την υποχρεωτική στρατηγική βάρους για να περιορίσει τη σειρά του να γίνει ηγέτης και χρησιμοποιεί τον μηχανισμό στρατηγικής πλειοψηφίας για να διασφαλίσει ότι ο νέος κύριος μπορεί να παρέχει αμέσως ανάγνωση και εγγραφή υπηρεσίες με μηδενική καθυστέρηση.
- Επομένως, όσον αφορά την επιλογή ηγέτη, το DN όχι μόνο υποστηρίζει την ίδια στρατηγική επιλογή με το MGR, αλλά υποστηρίζει επίσης υποχρεωτικές στρατηγικές βάρους.
2.3.4 Αντιστοίχιση ημερολογίου
Η εξισορρόπηση αρχείων καταγραφής σημαίνει ότι υπάρχει καθυστέρηση αναπαραγωγής αρχείων καταγραφής μεταξύ της κύριας και της δευτερεύουσας βάσης δεδομένων και η δευτερεύουσα βάση δεδομένων πρέπει να εξισώσει τα αρχεία καταγραφής. Για κόμβους που επανεκκινούνται και αποκαθίστανται, η ανάκτηση ξεκινά συνήθως με τη βάση δεδομένων αναμονής και έχει ήδη σημειωθεί καθυστέρηση αναπαραγωγής αρχείων καταγραφής σε σύγκριση με την κύρια βάση δεδομένων και τα αρχεία καταγραφής πρέπει να εντοπίζονται στην κύρια βάση δεδομένων. Για εκείνους τους κόμβους που είναι φυσικά μακριά από το Leader, το να φτάσουν στην πλειοψηφία τους συνήθως δεν έχει καμία σχέση με αυτούς. Αυτές οι καταστάσεις απαιτούν συγκεκριμένη εφαρμογή μηχανικής για να διασφαλιστεί η έγκαιρη επίλυση των καθυστερήσεων αναπαραγωγής αρχείων καταγραφής.
MGR
- Τα αρχεία καταγραφής συναλλαγών βρίσκονται όλα στην κρυφή μνήμη XCOM και η κρυφή μνήμη είναι μόνο 1G από προεπιλογή. Επομένως, όταν ένας κόμβος ακολούθου είναι πολύ πίσω στην αναπαραγωγή αιτημάτων, είναι εύκολο να διαγραφεί η κρυφή μνήμη.
- Αυτή τη στιγμή, ο οπαδός που καθυστερεί θα αποβληθεί αυτόματα από το σύμπλεγμα και, στη συνέχεια, θα χρησιμοποιήσει τη διαδικασία Global Recovery ή Clone που αναφέρεται παραπάνω για την ανάκτηση σφαλμάτων και, στη συνέχεια, θα ενταχθεί αυτόματα στο σύμπλεγμα αφού καλυφθεί.Αν συναντήσετεΓια παράδειγμα, διαγράφονται προβλήματα δικτύου ή η μνήμη cache XCOM των άλλων δύο κόμβων, οπότε απαιτείται μη αυτόματη παρέμβαση για την επίλυση του προβλήματος.
- Γιατί πρέπει πρώτα να αποκλείσουμε το σύμπλεγμα επειδή ο ελαττωματικός κόμβος σε λειτουργία πολλαπλής εγγραφής επηρεάζει πολύ την απόδοση και η κρυφή μνήμη του Leader δεν έχει καμία επίδραση σε αυτόν.
- Γιατί δεν μπορούμε να διαβάσουμε απευθείας το τοπικό αρχείο Binlog του Leader Επειδή το πρωτόκολλο XCOM που αναφέρθηκε προηγουμένως είναι σε πλήρη μνήμη και δεν υπάρχουν πληροφορίες πρωτοκόλλου για το XCOM στο αρχείο καταγραφής Binlog και αναμετάδοσης;
DN
- Τα δεδομένα βρίσκονται όλα στο αρχείο Binlog Εφόσον το Binlog δεν έχει καθαριστεί, μπορεί να σταλεί κατά παραγγελία και δεν υπάρχει πιθανότητα να απομακρυνθεί από το σύμπλεγμα.
- Προκειμένου να μειωθεί το jitter IO που προκαλείται από την κύρια βιβλιοθήκη που διαβάζει παλιά αρχεία καταγραφής συναλλαγών από το αρχείο Binlog, η DN δίνει προτεραιότητα στην ανάγνωση των πιο πρόσφατα αποθηκευμένων αρχείων καταγραφής συναλλαγών από την προσωρινή μνήμη FIFO Η προσωρινή μνήμη FIFO ελέγχεται από την παράμετρο consensus_log_cache_size είναι 64 εκ
- Εάν το παλιό αρχείο καταγραφής συναλλαγών στην προσωρινή μνήμη FIFO έχει εξαλειφθεί από το ενημερωμένο αρχείο καταγραφής συναλλαγών, η DN θα προσπαθήσει να διαβάσει το αρχείο καταγραφής συναλλαγών που αποθηκεύτηκε προηγουμένως από την προσωρινή μνήμη Prefetch Η προσωρινή μνήμη Prefetch ελέγχεται από την παράμετρο consensus_prefetch_cache_size και η προεπιλογή είναι 64M.
- Εάν δεν υπάρχει απαιτούμενο παλιό αρχείο καταγραφής συναλλαγών στην προσωρινή μνήμη Prefetch, η DN θα προσπαθήσει να ξεκινήσει μια ασύγχρονη εργασία IO, θα διαβάσει πολλά διαδοχικά αρχεία καταγραφής πριν και μετά το καθορισμένο αρχείο καταγραφής συναλλαγών από το αρχείο Binlog σε παρτίδες, θα τα τοποθετήσει στην προσωρινή μνήμη Prefetch και θα περιμένει για την επόμενη επανάληψη ανάγνωσης του DN
- Επομένως, το DN δεν απαιτεί καθόλου χειροκίνητη παρέμβαση όταν πρόκειται για εξισορρόπηση αρχείων καταγραφής.
2.4 Καθυστέρηση αναπαραγωγής βάσης δεδομένων σε αναμονή
Η καθυστέρηση αναπαραγωγής βάσης δεδομένων αναμονής είναι η καθυστέρηση μεταξύ του χρόνου ολοκλήρωσης της ίδιας συναλλαγής στην κύρια βάση δεδομένων και της ώρας εφαρμογής της συναλλαγής στη βάση δεδομένων αναμονής Αυτό που ελέγχεται εδώ είναι η απόδοση της βάσης δεδομένων αναμονής Εφαρμογή αρχείου καταγραφής εφαρμογής. Επηρεάζει τον χρόνο που χρειάζεται η βάση δεδομένων αναμονής για να ολοκληρώσει την εφαρμογή δεδομένων της και να παρέχει υπηρεσίες ανάγνωσης και εγγραφής όταν προκύπτει εξαίρεση.
MGR
- Η βάση δεδομένων αναμονής MGR λαμβάνει το αρχείο RelayLog από την κύρια βάση δεδομένων Κατά την εφαρμογή της εφαρμογής, πρέπει να διαβάσετε ξανά το RelayLog και να περάσετε από μια πλήρη διαδικασία υποβολής ομάδων δύο σταδίων για την παραγωγή των αντίστοιχων δεδομένων και των αρχείων Binlog.
- Η αποτελεσματικότητα της εφαρμογής συναλλαγής εδώ είναι η ίδια με την απόδοση υποβολής συναλλαγών στην κύρια βάση δεδομένων Η προεπιλεγμένη διαμόρφωση διπλού ενός (innodb_flush_log_at_trx_commit, sync_binlog) θα προκαλέσει την ίδια επιβάρυνση πόρων της εφαρμογής βάσης δεδομένων αναμονής.
DN
- Η βάση δεδομένων αντιγράφων ασφαλείας DN λαμβάνει το αρχείο Binlog από την κύρια βάση δεδομένων, το Binlog πρέπει να διαβαστεί ξανά.
- Δεδομένου ότι το DN υποστηρίζει πλήρη Ανάκτηση Crash, η εφαρμογή βάσης δεδομένων αναμονής δεν χρειάζεται να ενεργοποιήσει το innodb_flush_log_at_trx_commit=1, επομένως δεν επηρεάζεται στην πραγματικότητα από τη διαμόρφωση του double-one.
- Επομένως, όσον αφορά την καθυστέρηση αναπαραγωγής βάσης δεδομένων σε αναμονή, η απόδοση αναπαραγωγής βάσης δεδομένων αναμονής DN θα είναι πολύ μεγαλύτερη από το MGR.
2.5 Επιπτώσεις σημαντικών γεγονότων
Οι μεγάλες συναλλαγές δεν επηρεάζουν μόνο την υποβολή των συνηθισμένων συναλλαγών, αλλά επηρεάζουν επίσης τη σταθερότητα ολόκληρου του κατανεμημένου πρωτοκόλλου σε ένα κατανεμημένο σύστημα.
MGR
- Το MGR δεν έχει καμία βελτιστοποίηση για την υποστήριξη μεγάλων συναλλαγών Απλώς προσθέτει την παράμετρο group_replication_transaction_size_limit για τον έλεγχο του ανώτατου ορίου των μεγάλων συναλλαγών.
- Όταν το αρχείο καταγραφής συναλλαγών υπερβαίνει το μεγάλο όριο συναλλαγών, θα αναφέρεται απευθείας ένα σφάλμα και η συναλλαγή δεν μπορεί να υποβληθεί.
DN
- Προκειμένου να λυθεί το πρόβλημα αστάθειας των κατανεμημένων συστημάτων που προκαλούνται από μεγάλες συναλλαγές, το DN υιοθετεί τη λύση του διαχωρισμού μεγάλων συναλλαγών + διαχωρισμού μεγάλων αντικειμένων για να λύσει το πρόβλημα λογικά + το αρχείο καταγραφής συναλλαγών μικρά μπλοκ, κάθε μικρό μπλοκ του αρχείου καταγραφής συναλλαγών χρησιμοποιεί την πλήρη εγγύηση δέσμευσης Paxos
- Με βάση τη λύση του διαχωρισμού μεγάλων συναλλαγών, η DN δεν επιβάλλει περιορισμούς στο μέγεθος των μεγάλων συναλλαγών Οι χρήστες μπορούν να τις χρησιμοποιήσουν κατά βούληση και μπορούν επίσης να εξασφαλίσουν RPO=0.
- Για λεπτομερείς οδηγίες, βλ"PolarDB-X Storage Engine Core Technology | Βελτιστοποίηση μεγάλων συναλλαγών"
- Επομένως, η DN μπορεί να χειριστεί υποθέσεις μεγάλης κλίμακας χωρίς να επηρεάζεται από υποθέσεις μεγάλης κλίμακας.
2.6 Έντυπο ανάπτυξης
MGR
- Το MGR υποστηρίζει λειτουργίες ανάπτυξης ενός κύριου και πολλαπλού κύριου Στη λειτουργία πολλαπλών βασικών στοιχείων, κάθε κόμβος μπορεί να διαβαστεί και να γραφτεί σε λειτουργία απλής κύριας βάσης, και η βάση δεδομένων αναμονής μπορεί να διαβαστεί μόνο. μόνο.
- Η ανάπτυξη MGR υψηλής διαθεσιμότητας απαιτεί τουλάχιστον τρεις αναπτύξεις κόμβων, δηλαδή, δεν υποστηρίζονται τουλάχιστον τρία αντίγραφα δεδομένων και αρχείων καταγραφής.
- Το MGR δεν υποστηρίζει την επέκταση κόμβων μόνο για ανάγνωση, αλλά υποστηρίζει τον συνδυασμό λειτουργίας αναπαραγωγής MGR + master-slave για την επίτευξη παρόμοιας επέκτασης τοπολογίας.
DN
- Το DN υποστηρίζει την ανάπτυξη μιας κύριας λειτουργίας Στη λειτουργία απλής κύριας, η κύρια βάση δεδομένων μπορεί να διαβαστεί και να γραφτεί και η βάση δεδομένων αναμονής μπορεί να είναι μόνο για ανάγνωση.
- Η ανάπτυξη υψηλής διαθεσιμότητας DN απαιτεί τουλάχιστον τρεις κόμβους, αλλά υποστηρίζει τη φόρμα καταγραφής αντιγραφής καταγραφής, δηλαδή, το Leader και το Follower είναι αντίγραφα με πλήρεις δυνατότητες, σε σύγκριση με το Logger, έχει μόνο αρχεία καταγραφής και χωρίς δεδομένα και δεν έχει το δικαίωμα να είναι εκλεγμένος. Σε αυτήν την περίπτωση, η ανάπτυξη υψηλής διαθεσιμότητας τριών κόμβων απαιτεί μόνο την επιβάρυνση αποθήκευσης 2 αντιγράφων δεδομένων + 3 αντιγράφων αρχείων καταγραφής, καθιστώντας την ανάπτυξη χαμηλού κόστους.
- Το DN υποστηρίζει την ανάπτυξη κόμβου μόνο για ανάγνωση και τη φόρμα εκμάθησης αντιγράφων μόνο για ανάγνωση Σε σύγκριση με τα πλήρη αντίγραφα, δεν έχει μόνο δικαιώματα ψήφου μέσω των αντιγράφων εκμάθησης, η κατανάλωση συνδρομής στην κύρια βιβλιοθήκη.

2.7 Περίληψη χαρακτηριστικών
| | MGR | DN |
| Αποτελεσματικότητα πρωτοκόλλου | Χρόνος υποβολής συναλλαγής | 1,5~2,5 RTT | 1 RTT |
| | Επιμονή της πλειοψηφίας | Αποθήκευση μνήμης XCOM | Επιμονή Binlog |
| αξιοπιστία | RPO=0 | Δεν είναι εγγυημένο από προεπιλογή | Πλήρως εγγυημένο |
| | Ανίχνευση βλαβών | Όλοι οι κόμβοι ελέγχουν ο ένας τον άλλον, το φόρτο δικτύου είναι υψηλό Ο κύκλος του καρδιακού παλμού δεν μπορεί να ρυθμιστεί | Ο κύριος κόμβος ελέγχει περιοδικά άλλους κόμβους Οι παράμετροι του κύκλου καρδιακών παλμών είναι ρυθμιζόμενες |
| | Ανάκτηση κατάρρευσης πλειοψηφίας | χειρωνακτική παρέμβαση | Αυτόματη ανάκτηση |
| | Ανάκτηση μειονοτήτων | Αυτόματη ανάκτηση στις περισσότερες περιπτώσεις, χειρωνακτική επέμβαση σε ειδικές περιπτώσεις | Αυτόματη ανάκτηση |
| | Επιλέξτε τον κύριο | Καθορίστε ελεύθερα τη σειρά επιλογής | Καθορίστε ελεύθερα τη σειρά επιλογής |
| κούτσουρο γραβάτα | Τα αρχεία καταγραφής με καθυστέρηση δεν μπορούν να υπερβαίνουν τη μνήμη cache XCOM 1 GB | Τα αρχεία BInlog δεν διαγράφονται |
| Καθυστέρηση αναπαραγωγής βάσης δεδομένων σε κατάσταση αναμονής | Δύο στάδια + διπλό ένα, πολύ αργό | Ένα στάδιο + διπλό μηδέν, πιο γρήγορα |
| Μεγάλη δουλειά | Το προεπιλεγμένο όριο δεν είναι μεγαλύτερο από 143 MB | Χωρίς όριο μεγέθους |
| μορφή | Υψηλό κόστος διαθεσιμότητας | Πλήρως λειτουργικά τρία αντίγραφα, 3 αντίγραφα γενικής χρήσης αποθήκευσης δεδομένων | Αντιγραφή αρχείου καταγραφής, 2 αντίγραφα αποθήκευσης δεδομένων |
| κόμβος μόνο για ανάγνωση | Υλοποιήθηκε με αντιγραφή master-slave | Το πρωτόκολλο συνοδεύεται από εφαρμογή αντιγραφής Leaner μόνο για ανάγνωση |
3. Σύγκριση δοκιμής
Το MGR εισήχθη στην MySQL 5.7.17, αλλά περισσότερες δυνατότητες που σχετίζονται με το MGR είναι διαθέσιμες μόνο στο MySQL 8.0 και σε MySQL 8.0.22 και νεότερες εκδόσεις, η συνολική απόδοση θα είναι πιο σταθερή και αξιόπιστη. Επομένως, επιλέξαμε την πιο πρόσφατη έκδοση 8.0.32 και των δύο μερών για συγκριτική δοκιμή.
Λαμβάνοντας υπόψη ότι υπάρχουν διαφορές στα περιβάλλοντα δοκιμών, τις μεθόδους μεταγλώττισης, τις μεθόδους ανάπτυξης, τις παραμέτρους λειτουργίας και τις μεθόδους δοκιμής κατά τη συγκριτική δοκιμή των PolarDB-X DN και MySQL MGR, οι οποίες μπορεί να οδηγήσουν σε ανακριβή δεδομένα σύγκρισης δοκιμών, αυτό το άρθρο θα επικεντρωθεί σε διάφορες λεπτομέρειες Προχωρήστε ως εξής:
| προετοιμασία δοκιμής | PolarDB-X DN | MySQL MGR[1] |
| Περιβάλλον υλικού | Χρησιμοποιώντας το ίδιο φυσικό μηχάνημα με μνήμη 96C 754 GB και δίσκο SSD |
| λειτουργικό σύστημα | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| Έκδοση πυρήνα | Χρήση βασικής γραμμής πυρήνα που βασίζεται στην έκδοση κοινότητας 8.0.32 |
| Μέθοδος μεταγλώττισης | Μεταγλώττιση με το ίδιο RelWithDebInfo |
| Παράμετροι λειτουργίας | Χρησιμοποιήστε τον ίδιο επίσημο ιστότοπο PolarDB-X για να πουλήσετε το 32C128G με τις ίδιες προδιαγραφές και παραμέτρους |
| Μέθοδος ανάπτυξης | Ενιαία κύρια λειτουργία |
Σημείωση:
- Το MGR έχει ενεργοποιημένο τον έλεγχο ροής από προεπιλογή, ενώ το PolarDB-X DN έχει απενεργοποιημένο τον έλεγχο ροής από προεπιλογή.Επομένως, η λειτουργία group_replication_flow_control_mode του MGR έχει ρυθμιστεί ξεχωριστά έτσι ώστε η απόδοση του MGR να είναι η καλύτερη.
- Το MGR έχει ένα προφανές σημείο συμφόρησης ανάγνωσης κατά την απαρίθμηση, επομένως το replication_optimize_for_static_plugin_config του MGR έχει ρυθμιστεί και ενεργοποιηθεί ξεχωριστά, έτσι ώστε η απόδοση μόνο για ανάγνωση του MGR να είναι η καλύτερη.
3.1 Απόδοση
Ο έλεγχος απόδοσης είναι το πρώτο πράγμα στο οποίο προσέχουν όλοι όταν επιλέγουν μια βάση δεδομένων. Εδώ χρησιμοποιούμε το επίσημο εργαλείο sysbench για να δημιουργήσουμε 16 πίνακες, ο καθένας με 10 εκατομμύρια δεδομένα, για να εκτελέσουμε δοκιμές απόδοσης σε σενάρια OLTP και να ελέγξουμε και να συγκρίνουμε την απόδοση των δύο υπό διαφορετικές συνθήκες ταυτόχρονης χρήσης σε διαφορετικά σενάρια OLTP.Λαμβάνοντας υπόψη τις διαφορετικές καταστάσεις της πραγματικής ανάπτυξης, προσομοιώνουμε τα ακόλουθα τέσσερα σενάρια ανάπτυξης αντίστοιχα:
- Τρεις κόμβοι αναπτύσσονται στην ίδια αίθουσα υπολογιστών Υπάρχει μια καθυστέρηση δικτύου 0,1 ms όταν τα μηχανήματα κάνουν ping μεταξύ τους.
- Τρία κέντρα στην ίδια πόλη και τρεις αίθουσες υπολογιστών στην ίδια περιοχή αναπτύσσουν τρεις κόμβους Υπάρχει μια καθυστέρηση δικτύου 1ms στο ping μεταξύ των αιθουσών υπολογιστών (για παράδειγμα: τρεις αίθουσες υπολογιστών στη Σαγκάη).
- Τρία κέντρα σε δύο μέρη, τρεις κόμβοι που αναπτύσσονται σε τρεις αίθουσες υπολογιστών σε δύο μέρη, ping δικτύου 1ms μεταξύ αιθουσών υπολογιστών στην ίδια πόλη, καθυστέρηση δικτύου 30ms μεταξύ της ίδιας πόλης και ενός άλλου μέρους (για παράδειγμα: Σαγκάη/Σανγκάη/Σενζέν)
- Τρία κέντρα σε τρία μέρη, τρεις κόμβοι που αναπτύσσονται σε τρεις αίθουσες υπολογιστών σε τρία μέρη (για παράδειγμα: Σαγκάη/Χανγκζού/Σενζέν), η καθυστέρηση δικτύου μεταξύ Χανγκζού και Σαγκάη είναι περίπου 5 ms και η πιο απομακρυσμένη απόσταση από το Χανγκζού/Σανγκάη στο Σενζέν είναι 30 ms .
εικονογραφώ:
Ας εξετάσουμε την οριζόντια σύγκριση της απόδοσης τεσσάρων σεναρίων ανάπτυξης και τρία κέντρα σε τρία σημεία.
β) Λαμβάνοντας υπόψη τους αυστηρούς περιορισμούς στο RPO=0 κατά τη χρήση προϊόντων βάσης δεδομένων υψηλής διαθεσιμότητας, το MGR έχει ρυθμιστεί με RPO<>0 από προεπιλογή, θα συνεχίσουμε να προσθέτουμε συγκριτικά τεστ μεταξύ MGR RPO<>0 και RPO=0 σενάριο ανάπτυξης.
- Το MGR_0 αντιπροσωπεύει δεδομένα για την περίπτωση του MGR RPO = 0
- Το MGR_1 αντιπροσωπεύει δεδομένα για την περίπτωση του MGR RPO <> 0
- Το DN αντιπροσωπεύει τα δεδομένα για την περίπτωση του DN RPO = 0
3.1.1 Ίδιο δωμάτιο υπολογιστών
| | | 1 | 4 | 16 | 64 | 256 |
| oltp_read_only | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 |
| MGR_0 έναντι MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% |
| DN εναντίον MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% |
| DN έναντι MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% |
| oltp_read_write | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 |
| MGR_0 έναντι MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% |
| DN εναντίον MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% |
| DN έναντι MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% |
| oltp_write_only | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 |
| MGR_0 έναντι MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% |
| DN εναντίον MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% |
| DN έναντι MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
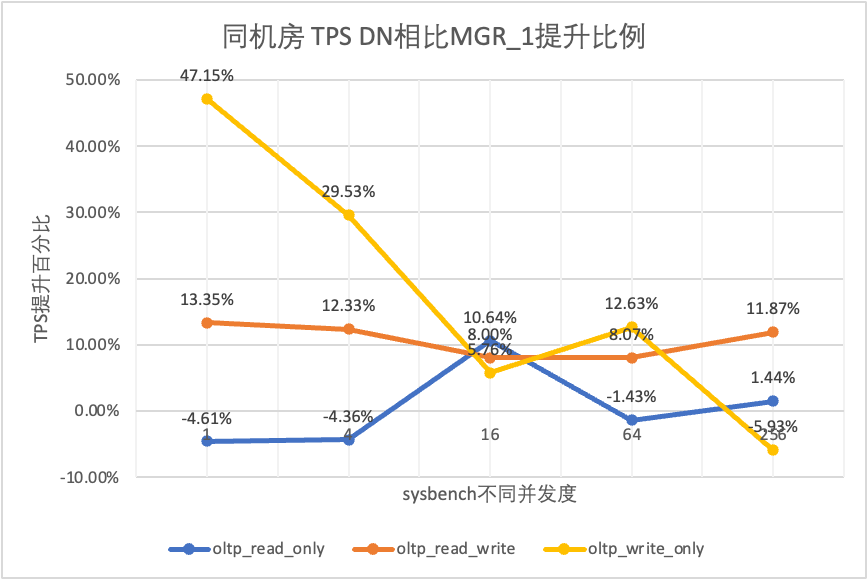
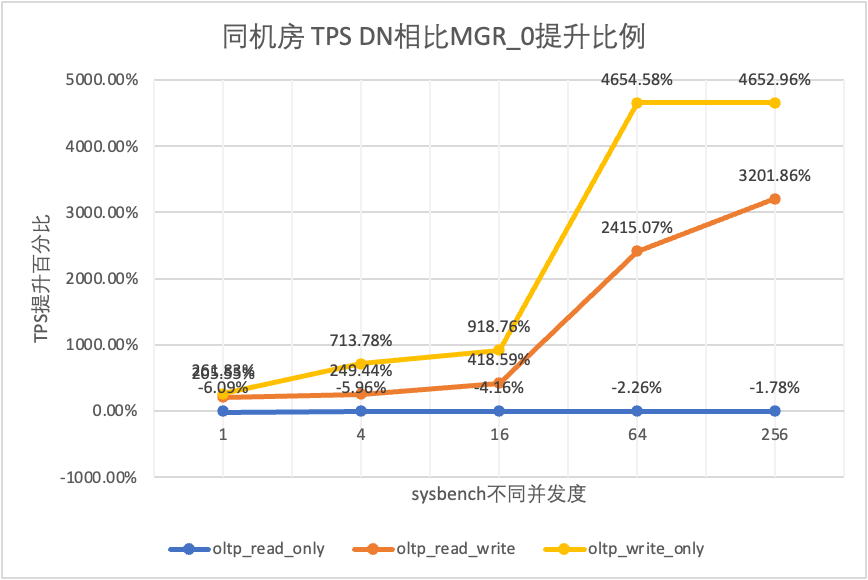
Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Στο σενάριο μόνο για ανάγνωση, είτε συγκρίνετε το MGR_1 (RPO<>0) είτε το MGR_0 (RPO=0), η διαφορά μεταξύ DN και MGR είναι σταθερή μεταξύ -5% και 10%, το οποίο μπορεί να θεωρηθεί ότι είναι βασικά το ίδιο. Το αν το RPO είναι ίσο με 0 δεν έχει καμία επίδραση στις συναλλαγές μόνο για ανάγνωση
- Στο μεικτό σενάριο συναλλαγής ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN (RPO=0) βελτιώνεται κατά 5% έως 47% σε σύγκριση με το MGR_1 (RPO<>0) και το πλεονέκτημα απόδοσης του DN είναι προφανές όταν ο συγχρονισμός είναι χαμηλός και το πλεονέκτημα όταν ο συγχρονισμός είναι υψηλός Αφανείς λειτουργίες. Αυτό οφείλεται στο γεγονός ότι η αποτελεσματικότητα του πρωτοκόλλου του DN είναι υψηλότερη όταν η συγχρονισμός είναι χαμηλή, αλλά τα hotspot απόδοσης των DN και MGR υπό υψηλή ταυτόχρονη λειτουργία βρίσκονται όλα στον καθαρισμό.
- Κάτω από την ίδια προϋπόθεση του RPO=0, σε μικτά σενάρια συναλλαγών ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN βελτιώνεται κατά 2 φορές έως 46 φορές σε σύγκριση με το MGR_0, και καθώς αυξάνεται η ταυτόχρονη λειτουργία, το πλεονέκτημα απόδοσης του DN ενισχύεται. Δεν είναι περίεργο που το MGR εγκαταλείπει επίσης το RPO=0 για απόδοση από προεπιλογή.
3.1.2 Τρία κέντρα στην ίδια πόλη
| Σύγκριση TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_read_only | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 |
| MGR_0 έναντι MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% |
| DN εναντίον MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% |
| DN έναντι MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% |
| oltp_read_write | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 |
| MGR_0 έναντι MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% |
| DN εναντίον MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% |
| DN έναντι MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% |
| oltp_write_only | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 |
| MGR_0 έναντι MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% |
| DN εναντίον MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% |
| DN έναντι MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Στο σενάριο μόνο για ανάγνωση, είτε συγκρίνετε το MGR_1 (RPO<>0) είτε το MGR_0 (RPO=0), η διαφορά μεταξύ DN και MGR είναι σταθερή μεταξύ -7% και 5%, το οποίο μπορεί να θεωρηθεί ότι είναι βασικά το ίδιο. Το αν το RPO είναι ίσο με 0 δεν έχει καμία επίδραση στις συναλλαγές μόνο για ανάγνωση
- Στο μεικτό σενάριο συναλλαγής ανάγνωσης-εγγραφής και μόνο εγγραφής, η απόδοση του DN (RPO=0) βελτιώνεται κατά 30% έως 120% σε σύγκριση με το MGR_1 (RPO<>0) και το πλεονέκτημα απόδοσης του DN είναι προφανές όταν υπάρχει ταυτόχρονη είναι χαμηλή, και το πλεονέκτημα όταν ο συγχρονισμός είναι υψηλός Αφανείς λειτουργίες. Αυτό οφείλεται στο γεγονός ότι η αποτελεσματικότητα του πρωτοκόλλου του DN είναι υψηλότερη όταν η συγχρονισμός είναι χαμηλή, αλλά τα hotspot απόδοσης των DN και MGR υπό υψηλή ταυτόχρονη λειτουργία βρίσκονται όλα στον καθαρισμό.
- Υπό την ίδια προϋπόθεση του RPO=0, σε μικτά σενάρια συναλλαγών ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN βελτιώνεται κατά 1 έως 14 φορές σε σύγκριση με το MGR_0 και καθώς αυξάνεται η ταυτόχρονη λειτουργία, το πλεονέκτημα απόδοσης του DN ενισχύεται. Δεν είναι περίεργο που το MGR εγκαταλείπει επίσης το RPO=0 για απόδοση από προεπιλογή.
3.1.3 Δύο θέσεις και τρία κέντρα
| Σύγκριση TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_read_only | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 |
| MGR_0 έναντι MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% |
| DN εναντίον MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% |
| DN έναντι MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% |
| oltp_read_write | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 |
| MGR_0 έναντι MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% |
| DN εναντίον MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% |
| DN έναντι MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% |
| oltp_write_only | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 |
| MGR_0 έναντι MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% |
| DN εναντίον MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% |
| DN έναντι MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
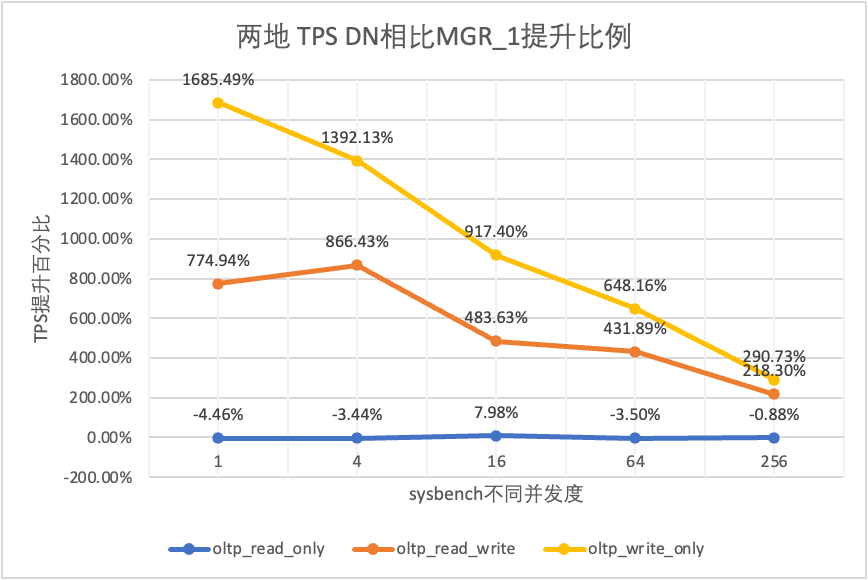
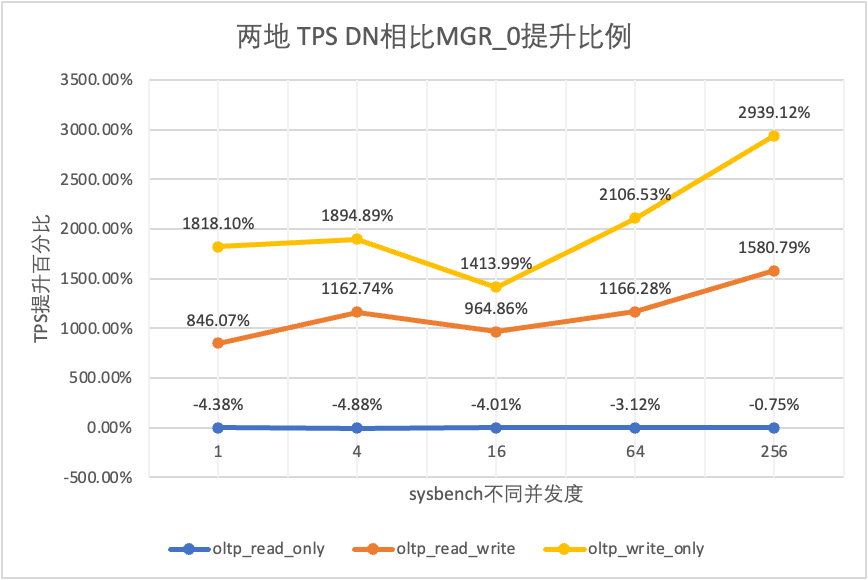
Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Στο σενάριο μόνο για ανάγνωση, είτε συγκρίνετε το MGR_1 (RPO<>0) είτε το MGR_0 (RPO=0), η διαφορά μεταξύ DN και MGR είναι σταθερή μεταξύ -4% και 7%, το οποίο μπορεί να θεωρηθεί ότι είναι βασικά το ίδιο. Το αν το RPO είναι ίσο με 0 δεν έχει καμία επίδραση στις συναλλαγές μόνο για ανάγνωση
- Στο μεικτό σενάριο συναλλαγής ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN (RPO=0) βελτιώνεται κατά 2 έως 16 φορές σε σύγκριση με το MGR_1 (RPO<>0) και το πλεονέκτημα απόδοσης του DN είναι προφανές όταν η ταυτόχρονη είναι χαμηλή, και το πλεονέκτημα όταν ο συγχρονισμός είναι υψηλός Αφανείς λειτουργίες. Αυτό οφείλεται στο γεγονός ότι η αποτελεσματικότητα του πρωτοκόλλου του DN είναι υψηλότερη όταν η συγχρονισμός είναι χαμηλή, αλλά τα hotspot απόδοσης των DN και MGR υπό υψηλή ταυτόχρονη λειτουργία βρίσκονται όλα στον καθαρισμό.
- Κάτω από την ίδια προϋπόθεση του RPO=0, σε μικτά σενάρια συναλλαγών ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN βελτιώνεται κατά 8 φορές έως 29 φορές σε σύγκριση με το MGR_0 και καθώς αυξάνεται η ταυτόχρονη λειτουργία, το πλεονέκτημα απόδοσης του DN ενισχύεται. Δεν είναι περίεργο που το MGR εγκαταλείπει επίσης το RPO=0 για απόδοση από προεπιλογή.
3.1.4 Τρεις θέσεις και τρία κέντρα
| Σύγκριση TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_read_only | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 |
| MGR_0 έναντι MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% |
| DN εναντίον MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% |
| DN έναντι MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% |
| oltp_read_write | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 |
| MGR_0 έναντι MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% |
| DN εναντίον MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% |
| DN έναντι MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% |
| oltp_write_only | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 |
| MGR_0 έναντι MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% |
| DN εναντίον MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% |
| DN έναντι MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
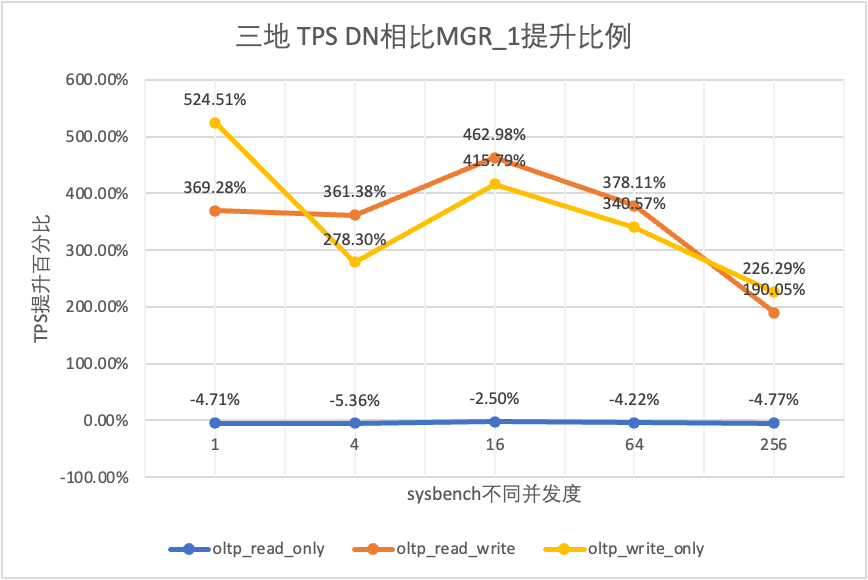
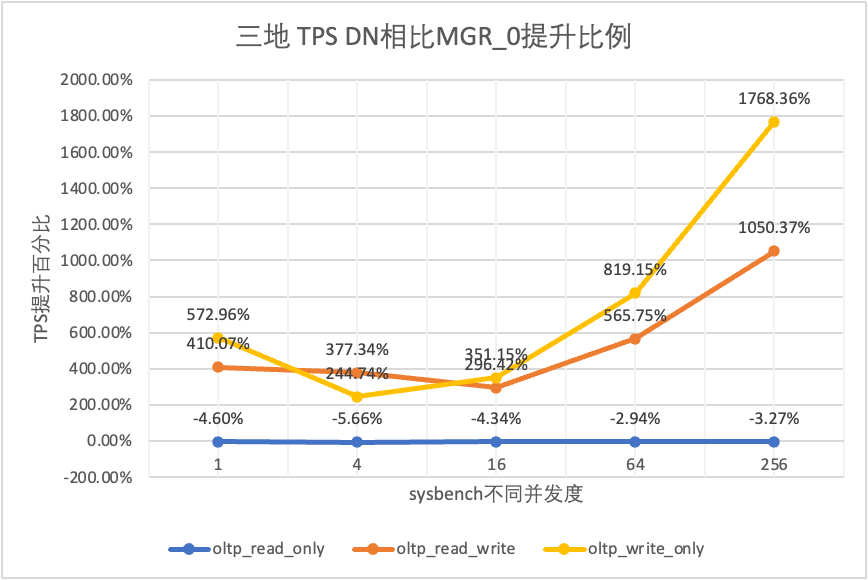
Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Στο σενάριο μόνο για ανάγνωση, είτε συγκρίνετε το MGR_1 (RPO<>0) είτε το MGR_0 (RPO=0), η διαφορά μεταξύ DN και MGR είναι σταθερή μεταξύ -5% και 0%, το οποίο μπορεί να θεωρηθεί ότι είναι βασικά το ίδιο. Το αν το RPO είναι ίσο με 0 δεν έχει καμία επίδραση στις συναλλαγές μόνο για ανάγνωση
- Στο μεικτό σενάριο συναλλαγών ανάγνωσης-εγγραφής και μόνο εγγραφής, η απόδοση του DN (RPO=0) βελτιώνεται κατά 2 έως 5 φορές σε σύγκριση με το MGR_1 (RPO<>0) και το πλεονέκτημα απόδοσης του DN είναι προφανές όταν ο συγχρονισμός είναι χαμηλά, και το πλεονέκτημα είναι καλύτερο όταν ο συγχρονισμός είναι υψηλός. Αυτό οφείλεται στο γεγονός ότι η αποτελεσματικότητα του πρωτοκόλλου του DN είναι υψηλότερη όταν η συγχρονισμός είναι χαμηλή, αλλά τα hotspot απόδοσης των DN και MGR υπό υψηλή ταυτόχρονη λειτουργία βρίσκονται όλα στον καθαρισμό.
- Κάτω από την ίδια προϋπόθεση του RPO=0, σε μικτά σενάρια συναλλαγών ανάγνωσης-εγγραφής και εγγραφής μόνο, η απόδοση του DN βελτιώνεται κατά 2 φορές έως 17 φορές σε σύγκριση με το MGR_0 και καθώς αυξάνεται η ταυτόχρονη λειτουργία, το πλεονέκτημα απόδοσης του DN ενισχύεται. Δεν είναι περίεργο που το MGR εγκαταλείπει επίσης το RPO=0 για απόδοση από προεπιλογή.
3.1.5 Σύγκριση ανάπτυξης
Προκειμένου να συγκρίνουμε με σαφήνεια τις αλλαγές απόδοσης σε διαφορετικές μεθόδους ανάπτυξης, επιλέξαμε τα δεδομένα TPS του MGR και του DN υπό διαφορετικές μεθόδους ανάπτυξης στο σενάριο oltp_write_only 256 στην παραπάνω δοκιμή Χρησιμοποιώντας τα δεδομένα δοκιμής αίθουσας υπολογιστών ως βάση, υπολογίσαμε και Σύγκρινε τα δεδομένα TPS των διαφορετικών μεθόδων ανάπτυξης σε σύγκριση με τη γραμμή βάσης για να αντιληφθούν τη διαφορά στις αλλαγές απόδοσης κατά τη διάρκεια της ανάπτυξης μεταξύ πόλεων
| | MGR_1 (256 ταυτόχρονα) | DN (256 ταυτόχρονα) | Πλεονεκτήματα απόδοσης του DN σε σύγκριση με το MGR |
| Η ίδια αίθουσα υπολογιστών | 16092.02 | 15137.23 | -5.93% |
| Τρία κέντρα στην ίδια πόλη | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Δύο θέσεις και τρία κέντρα | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Τρεις θέσεις και τρία κέντρα | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
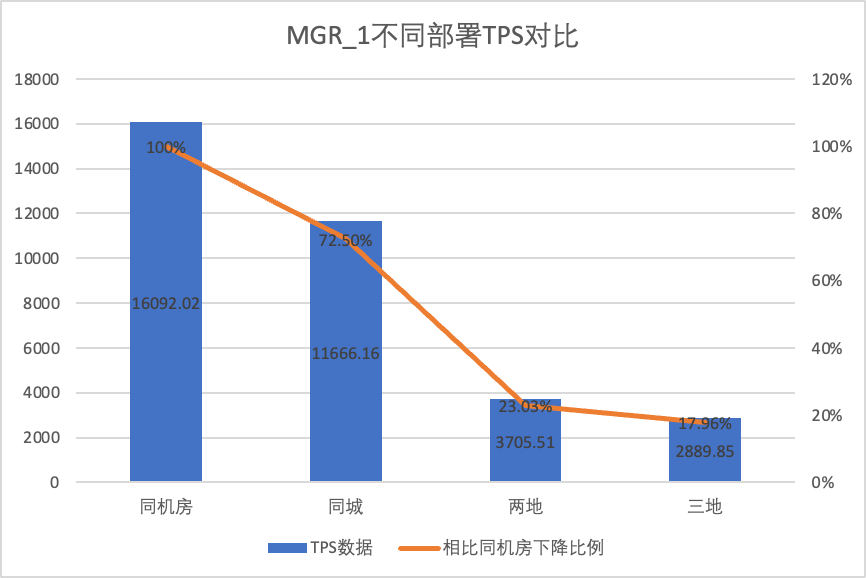
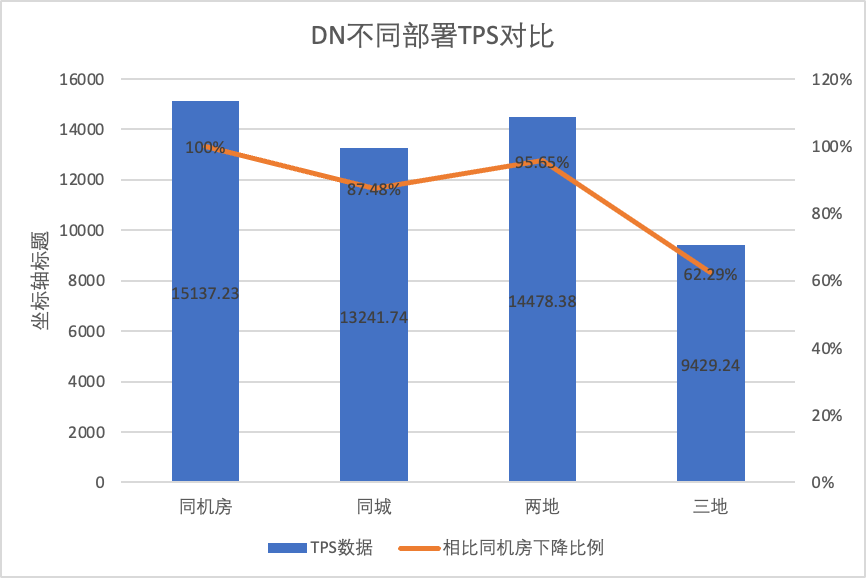
Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Με την επέκταση της μεθόδου ανάπτυξης, το TPS του MGR_1 (RPO<>0) μειώθηκε σημαντικά Σε σύγκριση με την ανάπτυξη στην ίδια αίθουσα υπολογιστών, η απόδοση της ανάπτυξης δωματίου μεταξύ υπολογιστών στην ίδια πόλη μειώθηκε κατά 27,5%. ανάπτυξης μεταξύ πόλεων (τρία κέντρα σε δύο μέρη, τρία κέντρα σε τρία σημεία) ανάπτυξη Μείωση 77%~82%, η οποία οφείλεται στην αύξηση της ανάπτυξης RT μεταξύ πόλεων.
- Το DN (RTO=0) είναι σχετικά σταθερό Σε σύγκριση με την ανάπτυξη στην ίδια αίθουσα υπολογιστών, η απόδοση της ανάπτυξης αιθουσών μεταξύ υπολογιστών στην ίδια πόλη και η ανάπτυξη τριών κέντρων σε δύο μέρη μειώθηκε κατά 4% σε 12%. Η απόδοση της εγκατάστασης τριών κέντρων σε τρία μέρη μειώθηκε κατά 37% υπό υψηλή καθυστέρηση δικτύου.Ωστόσο, χάρη στον μηχανισμό Batch&Pipeline της DN, ο αντίκτυπος της διασταύρωσης πόλεων μπορεί να λυθεί αυξάνοντας τη συγχρονικότητα, για παράδειγμα, με την αρχιτεκτονική τριών θέσεων και τριών κέντρων, με >=512 ταυτόχρονη, την απόδοση απόδοσης στην ίδια πόλη και δύο. μέρη και τρία κέντρα μπορούν βασικά να ευθυγραμμιστούν.
- Μπορεί να φανεί ότι η ανάπτυξη μεταξύ πόλεων έχει μεγάλο αντίκτυπο στο MGR_1 (RPO<>0)
3.1.6 Απόδοση Jitter
Στην πραγματική χρήση, όχι μόνο δίνουμε προσοχή στα δεδομένα απόδοσης, αλλά πρέπει επίσης να δίνουμε προσοχή στο jitter απόδοσης. Σε τελική ανάλυση, αν το jitter μοιάζει με τρενάκι λούνα παρκ, η πραγματική εμπειρία χρήστη θα είναι πολύ κακή. Παρακολουθούμε και εμφανίζουμε δεδομένα εξόδου TPS σε πραγματικό χρόνο Λαμβάνοντας υπόψη ότι το ίδιο το εργαλείο sysbenc δεν υποστηρίζει δεδομένα παρακολούθησης απόδοσης, χρησιμοποιούμε τον μαθηματικό συντελεστή διακύμανσης ως δείκτη σύγκρισης:
- Συντελεστής διακύμανσης (CV): Ο συντελεστής διακύμανσης είναι η τυπική απόκλιση διαιρούμενη με τον μέσο όρο. Συνήθως χρησιμοποιείται για τη σύγκριση των διακυμάνσεων διαφορετικών συνόλων δεδομένων, ειδικά όταν οι μέσες διαφορές είναι μεγάλες. Όσο μεγαλύτερο είναι το βιογραφικό, τόσο μεγαλύτερη είναι η διακύμανση των δεδομένων σε σχέση με τον μέσο όρο.
Λαμβάνοντας ως παράδειγμα το 256 ταυτόχρονο σενάριο oltp_read_write, αναλύουμε στατιστικά το TPS του MGR_1 (RPO<>0) και του DN (RPO=0) στον ίδιο χώρο υπολογιστών, τρία κέντρα στην ίδια πόλη, τρία κέντρα σε δύο μέρη και τρία κέντρα σε τρία σημεία. Το πραγματικό γράφημα jitter είναι το ακόλουθο και τα πραγματικά δεδομένα ένδειξης jitter για κάθε σενάριο είναι τα εξής:
| βιογραφικό | Η ίδια αίθουσα υπολογιστών | Τρία κέντρα στην ίδια πόλη | Δύο θέσεις και τρία κέντρα | Τρεις θέσεις και τρία κέντρα |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
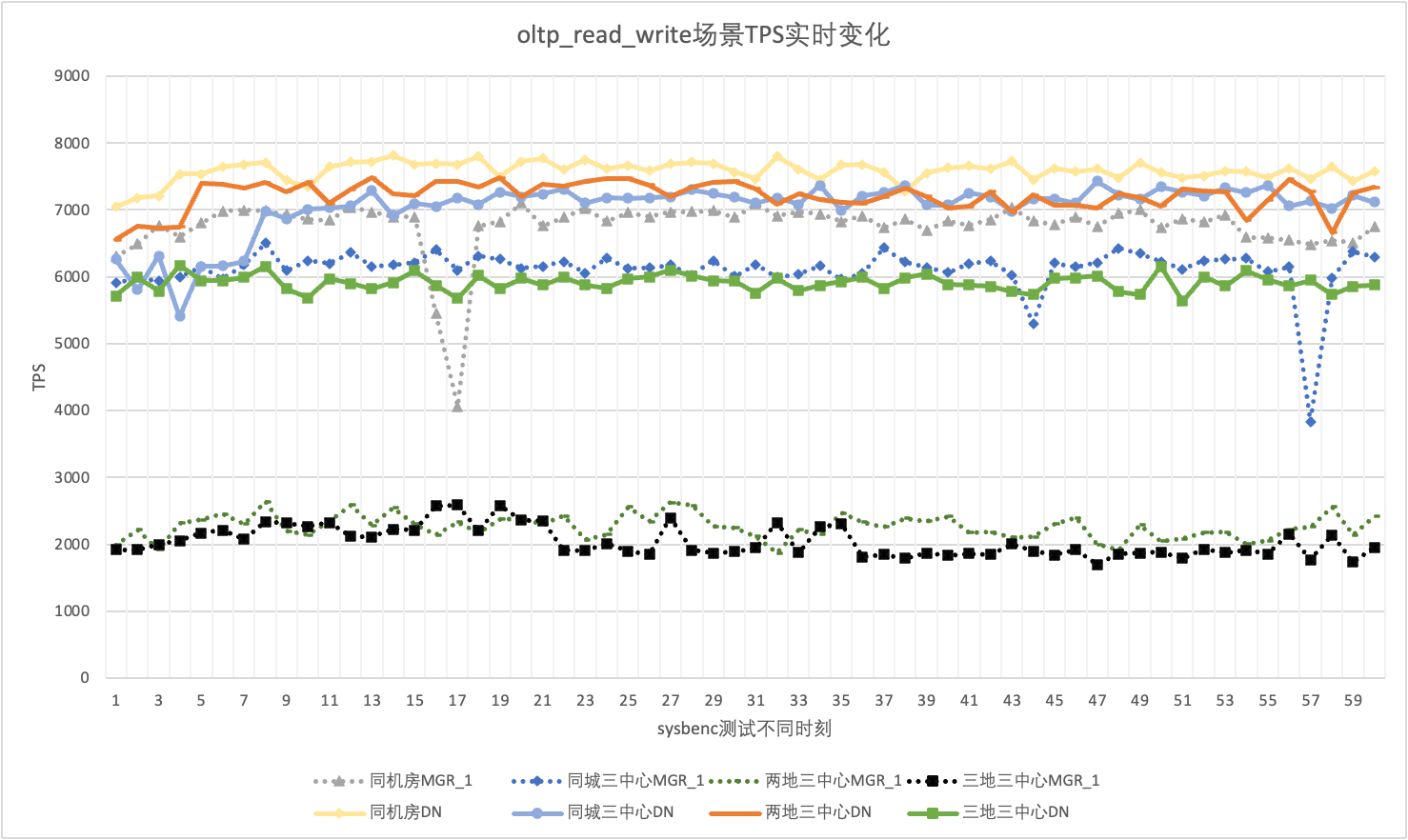
Μπορεί να φανεί από τα αποτελέσματα των δοκιμών:
- Το TPS του MGR βρίσκεται σε ασταθή κατάσταση στο σενάριο oltp_read_write και πέφτει απότομα χωρίς λόγο. Αυτό το φαινόμενο έχει βρεθεί σε πολλαπλές δοκιμές σε πολλαπλά σενάρια ανάπτυξης. Συγκριτικά, το DN είναι πολύ σταθερό.
- Υπολογίζοντας τον συντελεστή διακύμανσης CV, το βιογραφικό του MGR είναι πολύ μεγάλο, 6% έως 10%, και φτάνει ακόμη και τη μέγιστη τιμή του 10% όταν η καθυστέρηση στην ίδια αίθουσα υπολογιστών είναι ελάχιστη, ενώ το CV του DN είναι σχετικά σταθερό, 2% έως 4 % και η απόδοση του DN είναι πιο σταθερή από το MGR Το σεξ είναι βασικά διπλάσιο
- Μπορεί να φανεί ότι το jitter απόδοσης του MGR_1 (RPO<>0) είναι σχετικά μεγάλο
3.2. RTO
Το βασικό χαρακτηριστικό μιας κατανεμημένης βάσης δεδομένων είναι η υψηλή διαθεσιμότητα Η αποτυχία οποιουδήποτε κόμβου στο σύμπλεγμα δεν θα επηρεάσει τη συνολική διαθεσιμότητα. Για την τυπική φόρμα ανάπτυξης 3 κόμβων με έναν κύριο και δύο αντίγραφα ασφαλείας που αναπτύσσονται στον ίδιο χώρο υπολογιστών, προσπαθήσαμε να πραγματοποιήσουμε δοκιμές χρηστικότητας στα ακόλουθα τρία σενάρια:
- Διακόψτε την κύρια βάση δεδομένων, στη συνέχεια επανεκκινήστε την και παρατηρήστε τον χρόνο RTO για την επαναφορά της διαθεσιμότητας του συμπλέγματος κατά τη διάρκεια της διαδικασίας.
- Διακόψτε οποιαδήποτε βάση δεδομένων σε κατάσταση αναμονής και, στη συνέχεια, επανεκκινήστε την για να παρατηρήσετε την απόδοση διαθεσιμότητας της κύριας βάσης δεδομένων κατά τη διάρκεια της διαδικασίας.
3.2.1 Διακοπή λειτουργίας της κύριας βάσης δεδομένων + επανεκκίνηση
Όταν δεν υπάρχει φόρτωση, σκοτώστε τον ηγέτη και παρακολουθήστε τις αλλαγές κατάστασης κάθε κόμβου στο σύμπλεγμα και εάν είναι εγγράψιμος.
| | MGR | DN |
| Ξεκινώντας κανονικά | 0 | 0 |
| σκοτώσει τον αρχηγό | 0 | 0 |
| Βρέθηκε μη φυσιολογικός χρόνος κόμβου | 5 | 5 |
| Ώρα να μειωθούν 3 κόμβοι σε 2 κόμβοι | 23 | 8 |
| | MGR | DN |
| Ξεκινώντας κανονικά | 0 | 0 |
| σκοτώστε τον αρχηγό, τραβήξτε αυτόματα προς τα πάνω | 0 | 0 |
| Βρέθηκε μη φυσιολογικός χρόνος κόμβου | 5 | 5 |
| Ώρα να μειωθούν 3 κόμβοι σε 2 κόμβοι | 23 | 8 |
| 2 κόμβος επαναφορά 3 κόμβος χρόνος | 37 | 15 |

Μπορεί να φανεί από τα αποτελέσματα των δοκιμών ότι κάτω από συνθήκες πίεσης:
- Το RTO του DN είναι 8-15 δευτερόλεπτα, χρειάζονται 8 δευτερόλεπτα για να μειωθεί σε 2 κόμβους και 15 δευτερόλεπτα για να επαναφέρετε 3 κόμβους.
- Το RTO του MGR είναι 23-37s Χρειάζονται 23s για να υποβαθμιστείτε σε 2 κόμβους και 37s για να επαναφέρετε 3 κόμβους.
- Το DN απόδοσης RTO είναι συνολικά καλύτερο από το MGR
3.2.2 Διακοπή λειτουργίας βάσης δεδομένων αναμονής + επανεκκίνηση
Χρησιμοποιήστε το sysbench για να πραγματοποιήσετε μια ταυτόχρονη δοκιμή πίεσης 16 νημάτων στο σενάριο oltp_read_write Στο 10ο δευτερόλεπτο του σχήματος, σκοτώστε έναν κόμβο αναμονής και παρατηρήστε τα δεδομένα TPS εξόδου σε πραγματικό χρόνο.
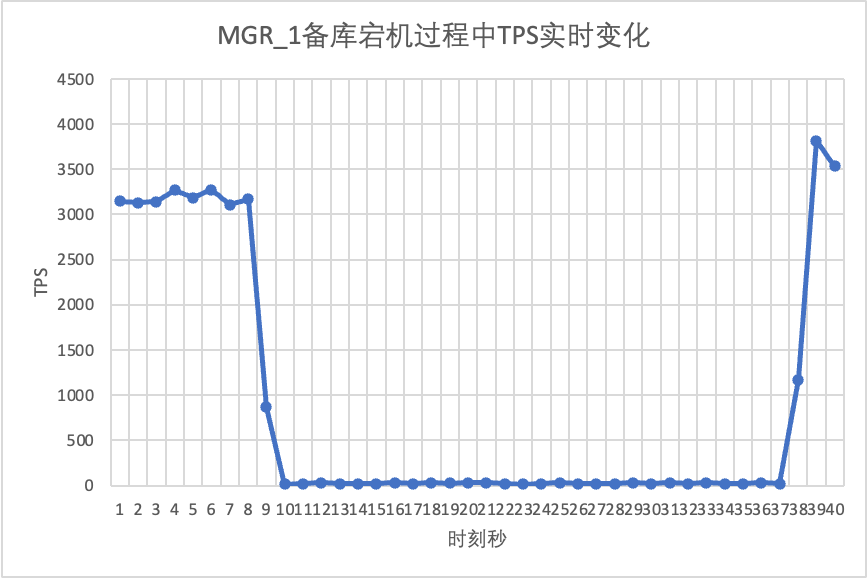


Μπορεί να φανεί από το διάγραμμα αποτελεσμάτων δοκιμής:
- Μετά τη διακοπή της βάσης δεδομένων αναμονής, η κύρια βάση δεδομένων TPS της MGR μειώθηκε σημαντικά και διήρκεσε περίπου 20 δευτερόλεπτα πριν επιστρέψει στα κανονικά επίπεδα. Σύμφωνα με την ανάλυση καταγραφής, υπάρχουν δύο διαδικασίες εδώ: η ανίχνευση ότι ο ελαττωματικός κόμβος έχει καταστεί μη προσβάσιμος και η εκτόξευση του ελαττωματικού κόμβου από το σύμπλεγμα MGR. Αυτή η δοκιμή επιβεβαίωσε ένα ελάττωμα που κυκλοφορεί στην κοινότητα MGR για μεγάλο χρονικό διάστημα, ακόμα κι αν μόνο 1 κόμβος μεταξύ 3 κόμβων δεν είναι διαθέσιμος.Ολόκληρο το σύμπλεγμα παρουσίασε σοβαρές ταραχές για ένα χρονικό διάστημα και έγινε μη διαθέσιμο.
- Για να λύσει το πρόβλημα του single-master MGR που έχει αποτυχία ενός κόμβου και δεν είναι διαθέσιμο ολόκληρο το στιγμιότυπο, η κοινότητα εισήγαγε τη λειτουργία MGR paxos single leader από την 8.0.27 για να λύσει το πρόβλημα, αλλά είναι απενεργοποιημένη από προεπιλογή. Εδώ ενεργοποιούμε το group_replication_paxos_single_leader και συνεχίζουμε την επαλήθευση Μετά τη διακοπή της βάσης δεδομένων αναμονής αυτή τη φορά, η απόδοση της κύριας βάσης δεδομένων παραμένει σταθερή και έχει βελτιωθεί ελαφρώς.
- Για το DN, μετά τη διακοπή της βάσης δεδομένων αναμονής, το TPS της κύριας βάσης δεδομένων αυξήθηκε αμέσως κατά περίπου 20%, και στη συνέχεια παρέμεινε σταθερό και το σύμπλεγμα ήταν πάντα διαθέσιμο.Αυτό είναι το αντίθετο του MGR Ο λόγος είναι ότι μετά τη διακοπή μιας βάσης δεδομένων αναμονής, η κύρια βάση δεδομένων χρειάζεται μόνο να στέλνει αρχεία καταγραφής στην υπόλοιπη βάση δεδομένων αναμονής κάθε φορά και η διαδικασία αποστολής και λήψης πακέτων δικτύου είναι πιο αποτελεσματική.
Συνεχίζοντας τη δοκιμή, κάνουμε επανεκκίνηση και επαναφορά της βάσης δεδομένων αναμονής και παρατηρούμε τις αλλαγές στα δεδομένα TPS της κύριας βάσης δεδομένων.
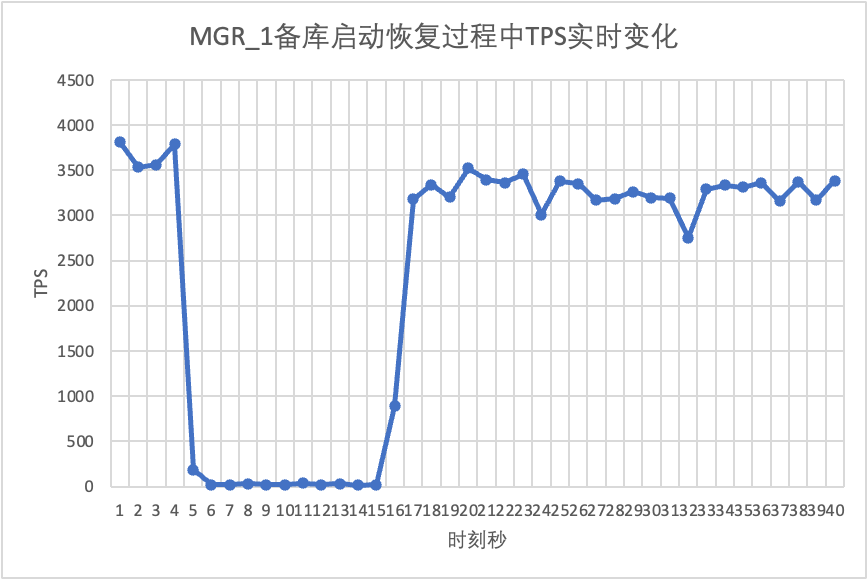
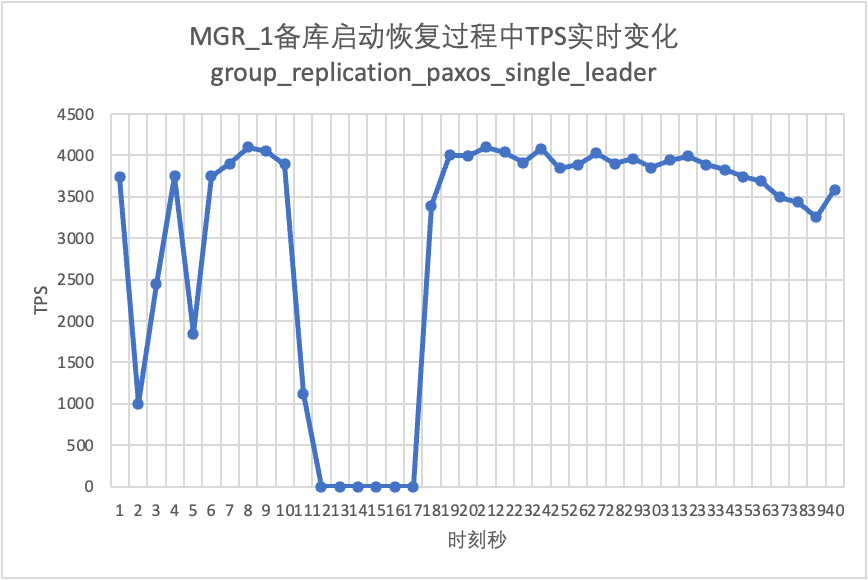
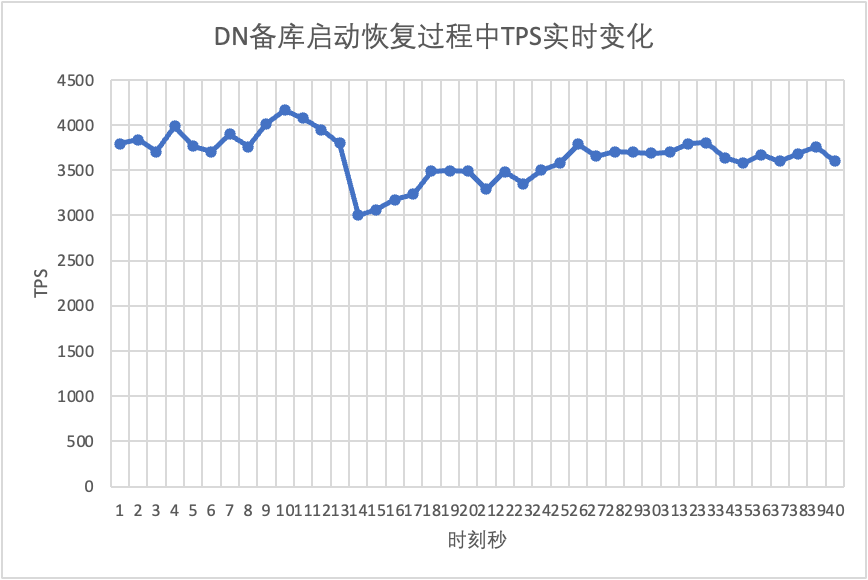
Μπορεί να φανεί από το διάγραμμα αποτελεσμάτων δοκιμής:
- Το MGR ανακτήθηκε από 2 κόμβους σε 3 κόμβους σε 5 δευτερόλεπτα.Αλλά υπάρχει επίσης μια κατάσταση όπου η κύρια βιβλιοθήκη δεν είναι διαθέσιμη, η οποία διαρκεί περίπου 12 δευτερόλεπτα.Παρόλο που ο κόμβος αναμονής εντάχθηκε τελικά στο σύμπλεγμα, η κατάσταση MEMBER_STATE ανέκαθεν ΑΝΑΚΤΗΣΕΙ, υποδεικνύοντας ότι αυτή τη στιγμή γίνεται αναζήτηση δεδομένων.
- Στο σενάριο μετά την ενεργοποίηση του group_replication_paxos_single_leader, επαληθεύεται επίσης η επανεκκίνηση της βάσης δεδομένων σε κατάσταση αναμονής. Ως αποτέλεσμα, το MGR ανακτά από 2 κόμβους σε 3 κόμβους σε 10 δευτερόλεπτα.Υπήρχε όμως ακόμα ένας μη διαθέσιμος χρόνος που διήρκησε περίπου 7 δευτερόλεπτα.Φαίνεται ότι αυτή η παράμετρος δεν μπορεί να λύσει πλήρως το πρόβλημα του single-master MGR που έχει αποτυχία μεμονωμένου κόμβου και ολόκληρη η παρουσία δεν είναι διαθέσιμη.
- Για το DN, η βάση δεδομένων αναμονής ανακτά από 2 κόμβους σε 3 κόμβους σε 10 δευτερόλεπτα και η κύρια βάση δεδομένων παραμένει διαθέσιμη. Θα υπάρξουν βραχυπρόθεσμες διακυμάνσεις στο TPS κύρια βάση δεδομένων Μετά την ανασκόπηση του αρχείου καταγραφής, η συνολική απόδοση θα είναι σταθερή.
3.3. RPO
Προκειμένου να κατασκευάσουμε το σενάριο της πλειοψηφίας αποτυχίας MGR RPO<>0, χρησιμοποιούμε τη μέθοδο MTR Case της κοινότητας για να εκτελέσουμε δοκιμή έγχυσης σφάλματος στο MGR Η σχεδιασμένη περίπτωση είναι η εξής:
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo ############################################################
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record

loose-group_replication_member_weight=100
loose-group_replication_member_weight=90
loose-group_replication_member_weight=80
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socket
Τα αποτελέσματα του case running είναι τα εξής:
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
include/start_and_bootstrap_group_replication.inc
include/start_group_replication.inc
include/start_group_replication.inc
############################################################
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
INSERT INTO t1 VALUES(2);
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
Η κατά προσέγγιση λογική μιας περίπτωσης που αναπαράγει αριθμούς που λείπουν είναι η εξής:
- Το MGR αποτελείται από 3 κόμβους σε λειτουργία single-master, Server 1/2/3, όπου ο διακομιστής 1 είναι η κύρια βάση δεδομένων και αρχικοποιεί 1 εγγραφή c1=1
- Fault injection Server 2/3 θα κολλήσει όταν γράφετε το αρχείο καταγραφής αναμετάδοσης
- Συνδέθηκε στον κόμβο Server 1, έγραψε την εγγραφή c1=2 και η δέσμευση συναλλαγής επέστρεψε επίσης επιτυχής.
- Στη συνέχεια, ο Mock server1 κολλάει ασυνήθιστα (αποτυχία μηχανήματος, δεν μπορεί να αποκατασταθεί και δεν είναι δυνατή η πρόσβαση σε αυτόν αυτήν τη στιγμή, ο διακομιστής 2/3 παραμένει για να σχηματίσει πλειοψηφία).
- Κάντε επανεκκίνηση του διακομιστή 2/3 κανονικά (γρήγορη ανάκτηση), αλλά ο διακομιστής 2/3 δεν μπορεί να επαναφέρει το σύμπλεγμα σε κατάσταση χρήσης.
- Συνδεθείτε στον κόμβο Server 2/3 και υποβάλετε ερώτημα στις εγγραφές της βάσης δεδομένων Μόνο η εγγραφή του c1=1 (ο διακομιστής 2/3 έχει χάσει c1=2).
Σύμφωνα με την παραπάνω περίπτωση, για το MGR, όταν η πλειονότητα των διακομιστών είναι εκτός λειτουργίας και η κύρια βάση δεδομένων δεν είναι διαθέσιμη, αφού αποκατασταθεί η βάση δεδομένων αναμονής, θα υπάρξει απώλεια δεδομένων RPO<>0 και το αρχείο επιτυχούς δέσμευσης που ήταν που επιστράφηκε αρχικά στον πελάτη χάνεται.
Για το DN, η επίτευξη της πλειοψηφίας απαιτεί τα αρχεία καταγραφής να διατηρούνται στην πλειοψηφία τους, επομένως ακόμη και στο παραπάνω σενάριο, τα δεδομένα δεν θα χαθούν και το RPO=0 μπορεί να είναι εγγυημένο.
3.4 Καθυστέρηση αναπαραγωγής βάσης δεδομένων σε αναμονή
Στην παραδοσιακή λειτουργία αναμονής της MySQL, η βάση δεδομένων αναμονής περιλαμβάνει γενικά νήματα IO και νήματα Εφαρμογή Μετά την εισαγωγή του πρωτοκόλλου Paxos, το νήμα IO συγχρονίζει το binlog της βάσης δεδομένων ενεργού και αναμονής εξαρτάται από την επιβάρυνση της Εφαρμογής αναπαραγωγής της βάσης δεδομένων αναμονής, εδώ γινόμαστε η καθυστέρηση αναπαραγωγής της βάσης δεδομένων αναμονής.
Χρησιμοποιούμε το sysbench για να δοκιμάσουμε το σενάριο oltp_write_only και να ελέγξουμε τη διάρκεια της καθυστέρησης στην αναπαραγωγή της βάσης δεδομένων αναμονής κάτω από 100 ταυτότητες και διαφορετικό αριθμό συμβάντων.Ο χρόνος καθυστέρησης αναπαραγωγής της βάσης δεδομένων αναμονής μπορεί να προσδιοριστεί παρακολουθώντας τη στήλη APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP του πίνακα performance_schema.replication_applier_status_by_worker για να δείτε εάν κάθε εργαζόμενος εργάζεται σε πραγματικό χρόνο για να προσδιορίσει εάν η αναπαραγωγή έχει τελειώσει.

Μπορεί να φανεί από το διάγραμμα αποτελεσμάτων δοκιμής:
- Κάτω από τον ίδιο όγκο γραπτών δεδομένων, ο χρόνος ολοκλήρωσης της αναπαραγωγής βάσης δεδομένων αναμονής όλων των αρχείων καταγραφής είναι πολύ καλύτερος από εκείνον της κατανάλωσης χρόνου του DN είναι μόνο 3% έως 4% του MGR. Αυτό είναι κρίσιμο για την επικαιρότητα της εναλλαγής ενεργού/αναμονής.
- Καθώς ο αριθμός των εγγραφών αυξάνεται, το πλεονέκτημα καθυστέρησης αναπαραγωγής βάσης δεδομένων αναμονής της DN έναντι του MGR συνεχίζει να διατηρείται και είναι πολύ σταθερό.
- Αναλύοντας τους λόγους για την καθυστέρηση αναπαραγωγής της βάσης δεδομένων αναμονής, η στρατηγική αναπαραγωγής βάσης δεδομένων αναμονής της MGR υιοθετεί τη συνοχή group_replication_consistency με την προεπιλεγμένη τιμή του EVENTUAL, δηλαδή οι συναλλαγές RO και RW δεν περιμένουν την εφαρμογή των προηγούμενων συναλλαγών πριν από την εκτέλεση. Αυτό μπορεί να εξασφαλίσει τη μέγιστη απόδοση εγγραφής της κύριας βάσης δεδομένων, αλλά η καθυστέρηση της βάσης δεδομένων αναμονής θα είναι σχετικά μεγάλη (θυσιάζοντας την καθυστέρηση βάσης δεδομένων αναμονής και RPO=0 σε αντάλλαγμα για εγγραφή υψηλής απόδοσης της κύριας βάσης δεδομένων, ενεργοποιώντας την τρέχουσα περιοριστική λειτουργία του MGR μπορεί να εξισορροπήσει την απόδοση και Η βάση δεδομένων αναμονής έχει καθυστερήσει, αλλά η απόδοση της κύριας βάσης δεδομένων θα διακυβευτεί)
3.5 Περίληψη δοκιμής
| | MGR | DN |
| εκτέλεση | Διαβάστε τη συναλλαγή | διαμέρισμα | διαμέρισμα |
| εγγραφή συναλλαγής | Η απόδοση δεν είναι τόσο καλή όσο το DN όταν το RPO<>0 Όταν RPO=0, η απόδοση είναι πολύ κατώτερη από το DN Η απόδοση της ανάπτυξης μεταξύ πόλεων μειώθηκε σοβαρά κατά 27%~82% | Η απόδοση της συναλλαγής εγγραφής είναι πολύ υψηλότερη από το MGR Η απόδοση ανάπτυξης μεταξύ πόλεων μειώνεται κατά 4% σε 37%. |
| Jitter | Το jitter απόδοσης είναι σοβαρό, το εύρος jitter είναι 6~10% | Σχετικά σταθερό στο 3%, μόνο το ήμισυ της MGR |
| RTO | Η κύρια βάση δεδομένων είναι εκτός λειτουργίας | Η ανωμαλία ανακαλύφθηκε σε 5 δευτερόλεπτα και μειώθηκε σε δύο κόμβους σε 23 δευτερόλεπτα. | Η ανωμαλία ανακαλύφθηκε σε 5s και μειώθηκε σε δύο κόμβους σε 8s. |
| Επανεκκινήστε την κύρια βιβλιοθήκη | Μια ανωμαλία ανακαλύφθηκε σε 5 δευτερόλεπτα και τρεις κόμβοι αποκαταστάθηκαν σε 37 δευτερόλεπτα. | Μια ανωμαλία ανιχνεύεται σε 5 δευτερόλεπτα και τρεις κόμβοι αποκαθίστανται σε 15 δευτερόλεπτα. |
| Διακοπή λειτουργίας της βάσης δεδομένων αντιγράφων ασφαλείας | Η κίνηση της κύριας βάσης δεδομένων έπεσε στο 0 για 20 δευτερόλεπτα. Μπορεί να μετριαστεί ενεργοποιώντας ρητά το group_replication_paxos_single_leader. | Συνεχής υψηλή διαθεσιμότητα της κύριας βάσης δεδομένων |
| Επανεκκίνηση βάσης δεδομένων σε κατάσταση αναμονής | Η κίνηση της κύριας βάσης δεδομένων έπεσε στο 0 για 10 δευτερόλεπτα. Η ρητή ενεργοποίηση του group_replication_paxos_single_leader επίσης δεν έχει κανένα αποτέλεσμα. | Συνεχής υψηλή διαθεσιμότητα της κύριας βάσης δεδομένων |
| RPO | Υποτροπή περιστατικού | RPO<>0 όταν το κόμμα της πλειοψηφίας πέφτει Το Performance και το RPO=0 δεν μπορούν να έχουν και τα δύο. | RPO = 0 |
| Καθυστέρηση βάσης δεδομένων αναμονής | Χρόνος αναπαραγωγής της βάσης δεδομένων αντιγράφων ασφαλείας | Οι καθυστερήσεις κύριας και εφεδρικής είναι πολύ μεγάλες. Η απόδοση και ο λανθάνουσα καθυστέρηση του κύριου αντιγράφου ασφαλείας δεν μπορούν να επιτευχθούν ταυτόχρονα. | Ο συνολικός χρόνος που δαπανάται για τη συνολική αναπαραγωγή βάσης δεδομένων σε κατάσταση αναμονής είναι 4% του MGR, δηλαδή 25 φορές μεγαλύτερος από αυτόν του MGR. |
| παράμετρος | βασική παράμετρος |
- Ο έλεγχος ροής group_replication_flow_control_mode είναι ενεργοποιημένος από προεπιλογή και πρέπει να ρυθμιστεί ώστε να απενεργοποιείται για βελτίωση της απόδοσης.
- replication_optimize_for_static_plugin_config Η στατική βελτιστοποίηση προσθηκών είναι απενεργοποιημένη από προεπιλογή και πρέπει να ενεργοποιηθεί για βελτίωση της απόδοσης
- Το group_replication_paxos_single_leader είναι απενεργοποιημένο από προεπιλογή και πρέπει να ενεργοποιηθεί για να βελτιωθεί η σταθερότητα της κύριας βάσης δεδομένων όταν η βάση δεδομένων αναμονής είναι απενεργοποιημένη.
- Το group_replication_consistency είναι απενεργοποιημένο από προεπιλογή και δεν εγγυάται RPO=0 Εάν απαιτείται RPO=0, το AFTER πρέπει να διαμορφωθεί.
- Το προεπιλεγμένο group_replication_transaction_size_limit είναι 143 εκατομμύρια, το οποίο πρέπει να αυξηθεί όταν αντιμετωπίζετε μεγάλες συναλλαγές.
- Το binlog_transaction_dependency_tracking είναι προεπιλεγμένο σε COMMIT_ORDER πρέπει να προσαρμοστεί σε WRITESET για να βελτιωθεί η απόδοση της αναπαραγωγής βάσης δεδομένων σε κατάσταση αναμονής.
| Προεπιλεγμένη διαμόρφωση, δεν χρειάζεται οι επαγγελματίες να προσαρμόσουν τη διαμόρφωση |
4. Περίληψη
Μετά από εις βάθος τεχνική ανάλυση και σύγκριση απόδοσης,PolarDB-X Με το πρωτόκολλο X-Paxos που έχει αναπτύξει μόνος του και μια σειρά βελτιστοποιημένων σχεδίων, η DN έχει επιδείξει πολλά πλεονεκτήματα σε σχέση με το MySQL MGR όσον αφορά την απόδοση, την ορθότητα, τη διαθεσιμότητα και τα γενικά έξοδα πόρων , πρέπει να ληφθούν υπόψη διάφορες καταστάσεις όπως το jitter διακοπής της βάσης δεδομένων αναμονής, οι διακυμάνσεις της απόδοσης ανάκτησης καταστροφών μεταξύ μηχανημάτων και η σταθερότητα, επομένως, εάν θέλετε να χρησιμοποιήσετε σωστά το MGR, πρέπει να είστε εξοπλισμένοι με επαγγελματική ομάδα τεχνικής και λειτουργίας και συντήρησης υποστήριξη.
Όταν αντιμετωπίζετε απαιτήσεις μεγάλης κλίμακας, υψηλής συγχρονισμού και υψηλής διαθεσιμότητας, ο κινητήρας αποθήκευσης PolarDB-X έχει μοναδικά τεχνικά πλεονεκτήματα και εξαιρετική απόδοση σε σύγκριση με το MGR σε εξωγενή σενάρια.PolarDB-XΗ κεντρική έκδοση που βασίζεται σε DN (τυπική έκδοση) έχει μια καλή ισορροπία μεταξύ λειτουργιών και απόδοσης, καθιστώντας την μια εξαιρετικά ανταγωνιστική λύση βάσης δεδομένων.

