2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Kuten me kaikki tiedämme, MySQL-ensisijainen ja toissijainen tietokanta (kaksi solmua) saavuttaa yleensä korkean tiedon saatavuuden asynkronisen replikoinnin ja puolisynkronisen replikoinnin (Semi-Sync) avulla ensisijaiset ja toissijaiset arkkitehtuurit kohtaavat vakavia ongelmia HA-vaihdon jälkeen. On todennäköistä, että tiedot ovat epäjohdonmukaisia (viitataan nimellä RPO! = 0).Siksi niin kauan kuin liiketoimintatiedot ovat tärkeitä, sinun ei pitäisi valita tietokantatuotetta, jossa on ensisijainen ja toissijainen MySQL-arkkitehtuuri (kaksi solmua. On suositeltavaa valita monikopioarkkitehtuuri, jossa RPO=0).
MySQL-yhteisö, koskien monikopiotekniikan kehitystä RPO=0:lla:
PolarDB-X Keskitetyn ja hajautetun integraation käsite: tietosolmua DN voidaan käyttää itsenäisesti keskitettynä (vakioversiona) lomakkeena, joka on täysin yhteensopiva erillisen tietokantalomakkeen kanssa. Kun liiketoiminta kasvaa siihen pisteeseen, että tarvitaan hajautettua laajennusta, arkkitehtuuri päivitetään hajautettuun muotoon ja hajautetut komponentit yhdistetään saumattomasti alkuperäisiin tietosolmuihin. Sovelluspuolella ei tarvitse siirtää tietoja tai muokata , ja voit nauttia tämän kaavan tuomasta käytettävyydestä ja skaalautumisesta, arkkitehtuurin kuvaus:"Keskitetty hajautettu integraatio"
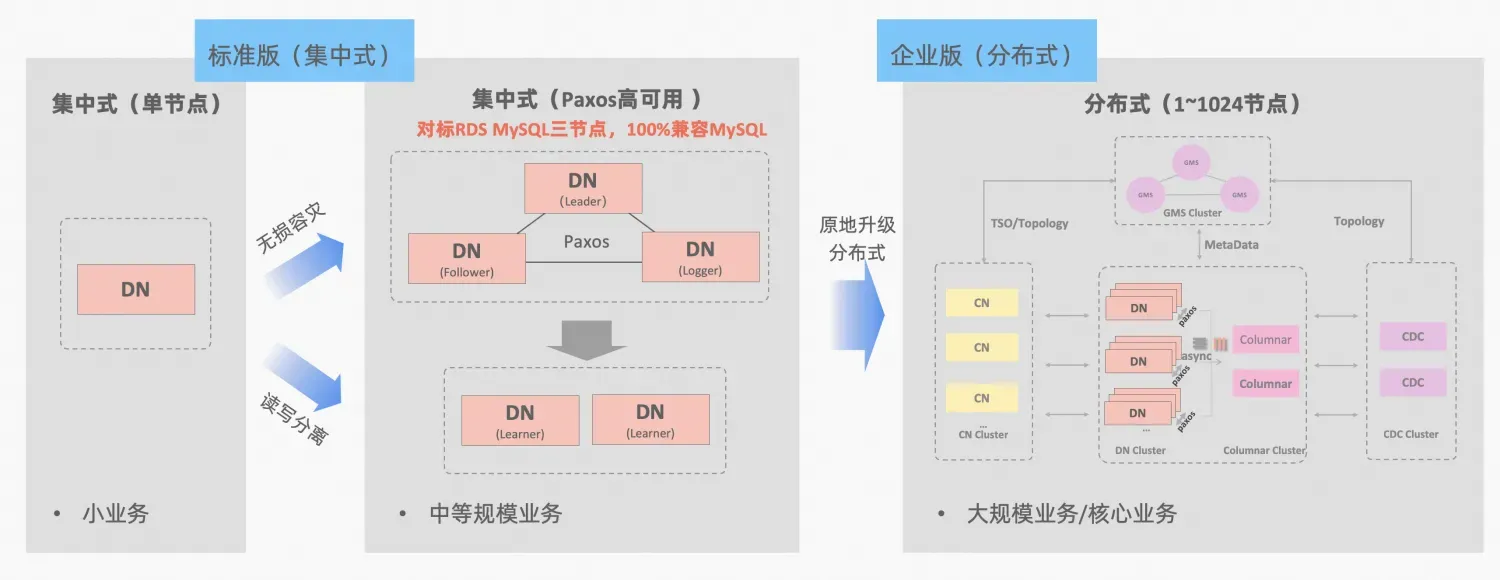
Sekä MySQL:n MGR että PolarDB-X:n standardiversio DN käyttävät Paxos-protokollaa alimmasta periaatteesta. Mitkä ovat siis erityiset suorituskyvyt ja erot todellisessa käytössä? Tässä artikkelissa käsitellään arkkitehtuurin vertailun näkökohtia, keskeisiä eroja ja testivertailua.
MGR/DN-lyhenteen kuvaus: MGR edustaa MySQL MGR:n teknistä muotoa ja DN edustaa PolarDB-X yksittäisen DN:n keskitettyä (vakioversio) teknistä muotoa.
Yksityiskohtainen vertaileva analyysi on suhteellisen pitkä, joten voit lukea yhteenvedon ja johtopäätöksen ensin.
MySQL MGR:ää ei suositella yleisille yrityksille ja yrityksille, koska se vaatii ammattimaista teknistä tietämystä sekä käyttö- ja huoltotiimiä. :
Verrattuna MySQL MGR:ään, PolarDB-X Paxosissa ei ole MGR:n kaltaisia sudenkuoppia tietojen johdonmukaisuuden, tietokoneiden välisen katastrofipalautuksen sekä solmun toiminnan ja ylläpidon suhteen. Sillä on kuitenkin myös joitain pieniä puutteita ja etuja katastrofipalautuksessa:
MGR/DN-lyhenteen kuvaus:
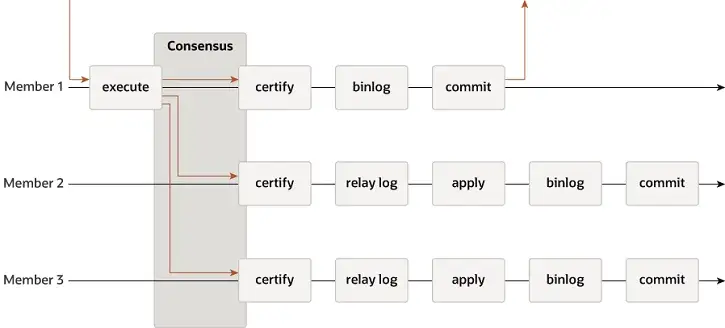
MGR tukee yhden isäntä- ja monen isännän tiloja ja käyttää täysin uudelleen MySQL:n replikointijärjestelmää, mukaan lukien Event, Binlog & Relaylog, Apply, Binlog Apply Recovery ja GTID. Keskeinen ero DN:stä on se, että MGR-tapahtumalokin enemmistö pääsee yhteisymmärrykseen ennen kuin päätietokantatapahtuma on sitoutunut.
Syy siihen, miksi MGR ottaa käyttöön yllä olevan prosessin, johtuu siitä, että MGR on oletuksena monipäätilassa ja jokainen solmu voi kirjoittaa. Siksi yhden Paxos-ryhmän seuraajasolmun on muunnettava vastaanotettu loki ensin RelayLogiksi ja sitten yhdistettävä. sen kirjoitustapahtuman kanssa, jonka se vastaanottaa lähettäjänä, tuotetaan Binlog-tiedosto, joka lähettää lopullisen tapahtuman kaksivaiheisessa ryhmälähetysprosessissa.
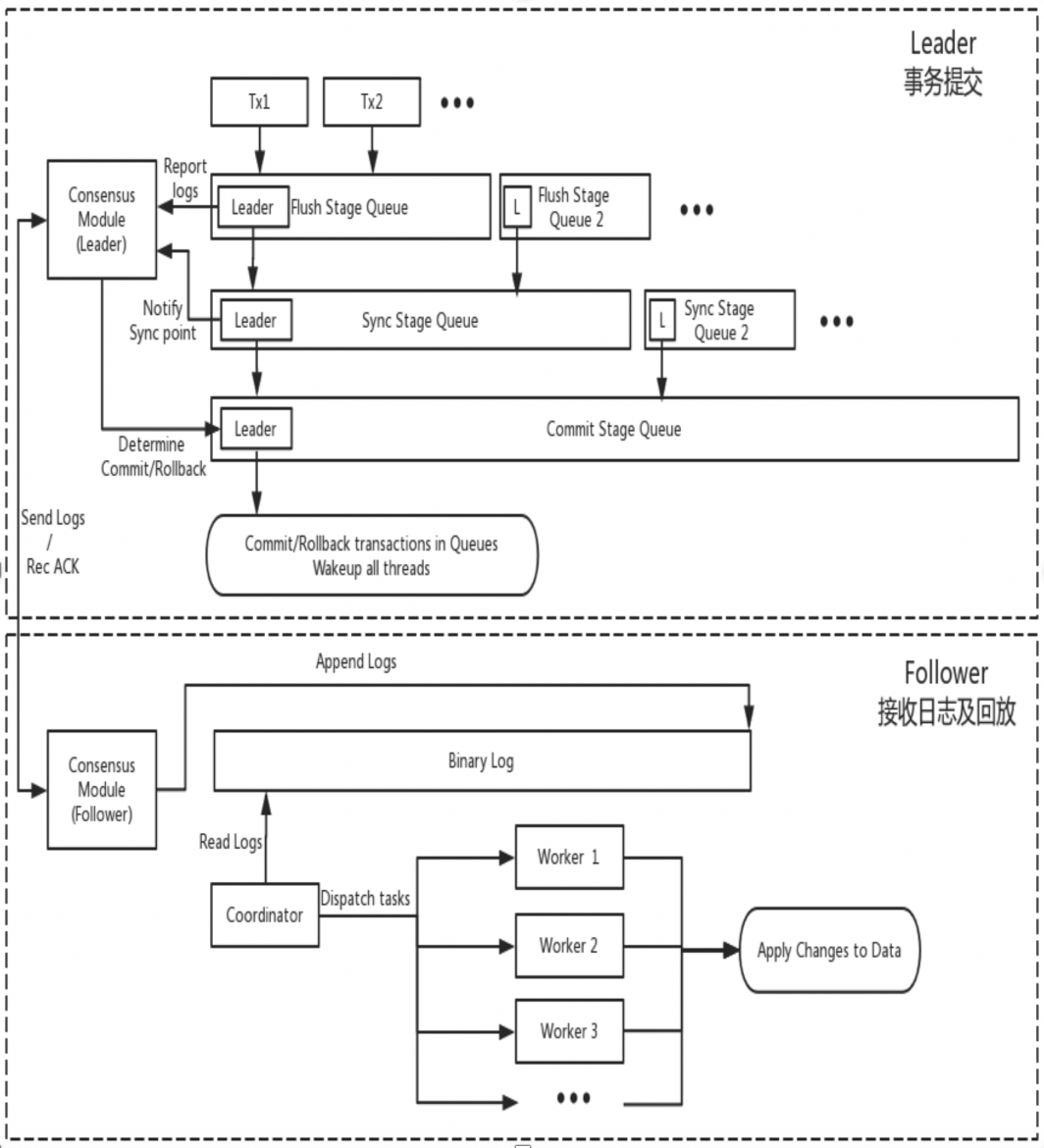
DN käyttää uudelleen MySQL:n perustietorakennetta ja toimintotason koodia, mutta integroi lokin replikoinnin, lokien hallinnan, lokien toiston ja kaatumispalautuksen tiiviisti X-Paxos-protokollan kanssa muodostaen oman joukon enemmistöreplikointia ja tilakonemekanismia. Keskeinen ero MGR:stä on se, että DN-tapahtumalokin enemmistö pääsee yhteisymmärrykseen päätietokantatapahtuman lähetysprosessin aikana.
Syynä tähän suunnitteluun on se, että DN tukee tällä hetkellä vain yhden pääkäyttäjän tilaa, joten X-Paxos-protokollan loki on itse Binlog-seuraaja, joka jättää pois myös välityslokin ja sen pysyvän lokin ja johtajan lokin ovat samat kuin Sama hinta.

MGR

DN
Teoriassa sekä Paxos että Raft voivat varmistaa tietojen johdonmukaisuuden ja kaatumispalautuksen jälkeen enemmistön saavuttaneet lokit eivät katoa, mutta yksittäisissä projekteissa on silti eroja.
MGR
XCOM kapseloi Paxos-protokollan kokonaan, ja kaikki sen protokollatiedot tallennetaan ensin välimuistiin. Oletuksena enemmistön saavuttaminen ei vaadi lokin pysyvyyttä. Siinä tapauksessa, että suurin osa piirakoista on alhaalla ja Leader epäonnistuu, syntyy vakava ongelma RPO != 0.Oletetaan äärimmäinen skenaario:
Yhteisön oletusparametreilla suurin osa tapahtumista ei vaadi lokin pysyvyyttä eikä takaa RPO=0:a Tätä voidaan pitää kompromissina XCOM-projektin toteutuksessa. Varmistaaksesi absoluuttisen RPO = 0, sinun on määritettävä parametri group_replication_consistency, joka ohjaa luku- ja kirjoitusyhteensopivuutta kohtaan AFTER. Tässä tapauksessa tapahtuma vaatii kuitenkin 1,5 RTT-verkon ylimääräisen lisäkulun saavuttaakseen suurimman osan. ja suorituskyky tulee olemaan erittäin huono.
DN
PolarDB-X DN käyttää X-Paxosta hajautetun protokollan toteuttamiseen ja on syvästi sidottu MySQL:n ryhmäsitoumusprosessiin. Suurin osa levyn sijoittelusta viittaa tässä pääkirjaston Binlog-sijoitteluun. Valmiustilassa olevan kirjaston IO-säie vastaanottaa pääkirjaston lokin ja kirjoittaa sen omaan Binlogiin pysyvyyttä varten. Siksi, vaikka kaikki solmut epäonnistuvat äärimmäisissä skenaarioissa, tietoja ei menetetä ja RPO=0 voidaan taata.
RTO-aika liittyy läheisesti itse järjestelmän kylmäkäynnistykseen kuluvaan aikaan, mikä näkyy erityisissä perustoiminnoissa:Vian havaitsemismekanismi -> kaatumispalautusmekanismi -> päävalintamekanismi -> lokin tasapainotus
MGR
DN
MGR
DN
Single-master-tilassa MGR:n XCOM ja DN X-Paxos, vahva johtajatila, noudattavat samaa perusperiaatetta johtajan valinnassa - klusterin sopimia lokeja ei voi peruuttaa. Mutta mitä tulee yksimielisyyteen, siinä on eroja
MGR
DN
Lokin tasaus tarkoittaa, että lokeissa on lokien replikointiviive ensisijaisen ja toissijaisen tietokannan välillä, ja toissijaisen tietokannan on tasattava lokit. Uudelleenkäynnistetyille ja palautetuille solmuille palautus aloitetaan yleensä valmiustilatietokannasta, ja lokin replikointiviive on jo tapahtunut päätietokantaan verrattuna, ja lokit on saatava päätietokantaan. Niille solmuille, jotka ovat fyysisesti kaukana Leaderista, enemmistön saavuttamisella ei yleensä ole mitään tekemistä niiden kanssa. Niillä on aina replikointilokin viive ja ne saavuttavat aina lokin. Nämä tilanteet edellyttävät erityistä suunnittelutoteutusta lokin replikointiviiveiden oikea-aikaisen ratkaisemisen varmistamiseksi.
MGR
DN
Valmiustilatietokannan toistoviive on viive ajankohdan välillä, jolloin sama tapahtuma suoritetaan päätietokannassa, ja aika, jolloin tapahtuma otetaan käyttöön valmiustilatietokannassa. Tässä testataan valmiustilatietokannan Apply-lokin suorituskyky. Se vaikuttaa siihen, kuinka kauan valmiustilassa oleva tietokanta suorittaa tietosovelluksensa ja tarjoaa luku- ja kirjoituspalveluita poikkeuksen sattuessa.
MGR
DN
Suuret tapahtumat eivät vaikuta vain tavallisten tapahtumien lähettämiseen, vaan vaikuttavat myös koko hajautetun protokollan vakauteen hajautetussa järjestelmässä.
MGR
DN
MGR
DN

| MGR | DN | ||
| Protokollan tehokkuus | Tapahtuman toimitusaika | 1,5-2,5 RTT | 1 RTT |
| Enemmistön pysyvyys | XCOM-muistin tallennus | Binlogin pysyvyys | |
| luotettavuus | RPO = 0 | Ei ole taattu oletuksena | Täysin taattu |
| Vian havaitseminen | Kaikki solmut tarkistavat toisensa, verkon kuormitus on korkea Sykejaksoa ei voi säätää | Pääsolmu tarkistaa säännöllisesti muut solmut Sykejakson parametrit ovat säädettävissä | |
| Enemmistön romahtaminen | manuaalinen interventio | Automaattinen palautus | |
| Minority Crash Recovery | Automaattinen palautus useimmissa tapauksissa, manuaalinen puuttuminen erityisissä olosuhteissa | Automaattinen palautus | |
| Valitse mestari | Määritä valintajärjestys vapaasti | Määritä valintajärjestys vapaasti | |
| Hirsisolmio | Viivästyneet lokit eivät voi ylittää XCOM 1 Gt:n välimuistia | BInlog-tiedostoja ei poisteta | |
| Valmiustilan tietokannan toistoviive | Kaksi vaihetta + tupla yksi, erittäin hidas | Yksi vaihe + tuplanolla, nopeammin | |
| Iso yritys | Oletusraja on enintään 143 Mt | Ei kokorajoitusta | |
| muodossa | Korkea saatavuuskustannukset | Täysin toimiva kolme kopiota, 3 kopiota tallennustilaa | Lokikopio, 2 kopiota tallennustilasta |
| vain luku -solmu | Toteutettu master-slave -replikaatiolla | Protokollassa on Leaner-vain luku -kopiototeutus |
MGR otettiin käyttöön MySQL 5.7.17:ssä, mutta enemmän MGR:ään liittyviä ominaisuuksia on saatavilla vain MySQL 8.0:ssa, ja MySQL 8.0.22:ssa ja uudemmissa versioissa yleinen suorituskyky on vakaampi ja luotettavampi. Siksi valitsimme molempien osapuolten uusimman version 8.0.32 vertailutestaukseen.
Ottaen huomioon, että PolarDB-X DN:n ja MySQL MGR:n vertailutestauksen aikana on eroja testiympäristöissä, käännösmenetelmissä, käyttöönottomenetelmissä, toimintaparametreissa ja testausmenetelmissä, mikä voi johtaa epätarkkoihin testivertailutietoihin, tässä artikkelissa keskitytään erilaisiin yksityiskohtiin. Toimi seuraavasti:
| testin valmistelu | PolarDB-X DN | MySQL MGR[1] |
| Laitteistoympäristö | Käytä samaa fyysistä konetta 96C 754GB muistilla ja SSD-levyllä | |
| käyttöjärjestelmä | Linux 4.9.168-019.ali3000.alios7.x86_64 | |
| Ytimen versio | Yhteisöversioon 8.0.32 perustuvan ytimen perustason käyttö | |
| Kokoonpanomenetelmä | Kääntää samalla RelWithDebInfolla | |
| Toimintaparametrit | Käytä samaa PolarDB-X:n virallista verkkosivustoa myydäksesi 32C128G:tä samoilla teknisillä ja parametreilla | |
| Käyttöönottomenetelmä | Yksi master -tila | |
Huomautus:
Suorituskykytestaus on ensimmäinen asia, johon jokainen kiinnittää huomiota tietokantaa valitessaan. Täällä käytämme virallista sysbench-työkalua rakentamaan 16 taulukkoa, joissa kussakin on 10 miljoonaa dataa, suorittamaan suorituskykytestauksia OLTP-skenaarioissa sekä testaamaan ja vertaamaan näiden kahden suorituskykyä eri samanaikaisissa olosuhteissa eri OLTP-skenaarioissa.Ottaen huomioon todellisen käyttöönoton eri tilanteet, simuloimme seuraavat neljä käyttöönottoskenaariota:
havainnollistaa:
a. Harkitse neljän käyttöönottoskenaarion suorituskyvyn horisontaalista vertailua. Kolme keskusa kahdessa paikassa ja kolme keskusa ottavat käyttöön 3 kopion käyttöönottotilan.
b. Ottaen huomioon tiukat rajoitukset RPO=0:lle käytettäessä korkean käytettävyyden tietokantatuotteita, MGR on määritetty oletuksena RPO<>0:lla. Tässä jatkamme vertailutestien lisäämistä MGR RPO<>0:n ja RPO=0:n välillä käyttöönoton skenaario.
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_read_only | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 vs. MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN vs MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN vs MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_read_write | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 vs. MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN vs MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN vs MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_write_only | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 vs. MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN vs MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN vs MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
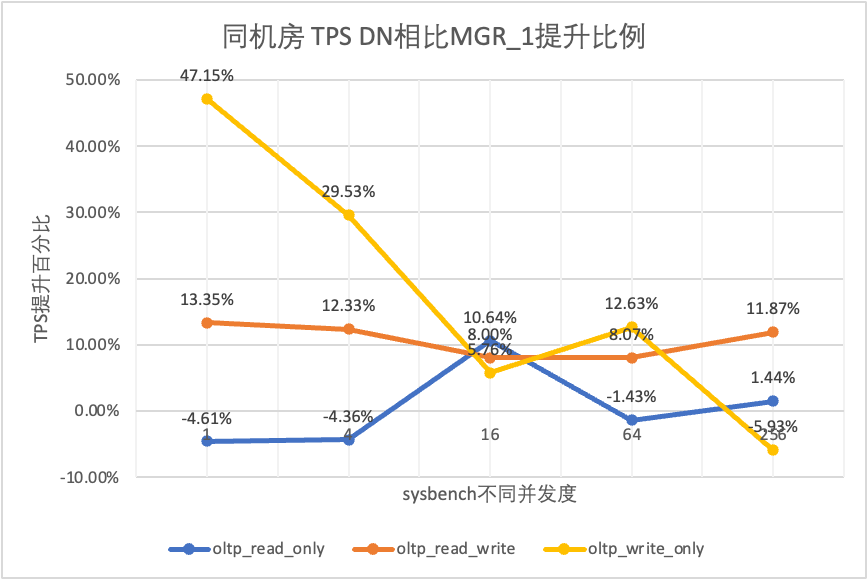
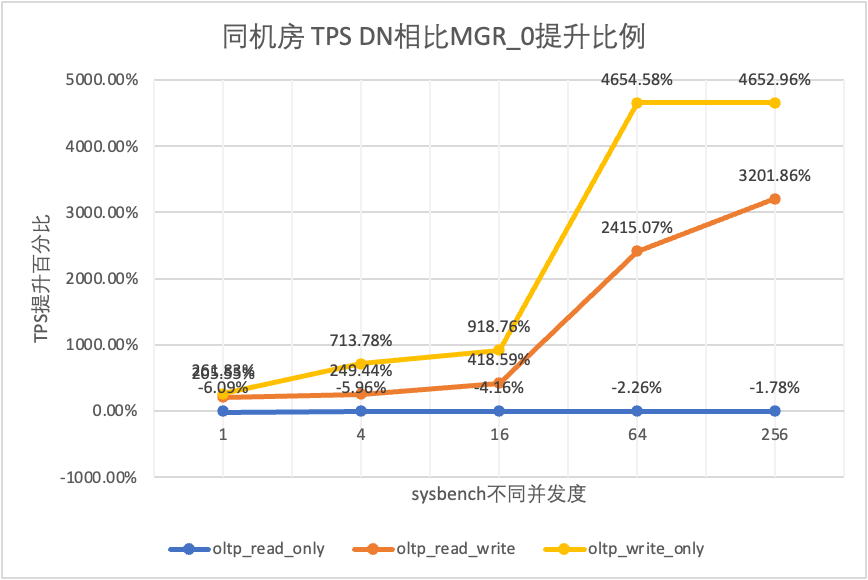
Se näkyy testituloksista:
| TPS vertailu | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 vs. MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN vs MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN vs MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_read_write | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 vs. MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN vs MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN vs MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_write_only | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 vs. MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN vs MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN vs MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Se näkyy testituloksista:
| TPS vertailu | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 vs. MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN vs MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN vs MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_read_write | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 vs. MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN vs MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN vs MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_write_only | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 vs. MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN vs MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN vs MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
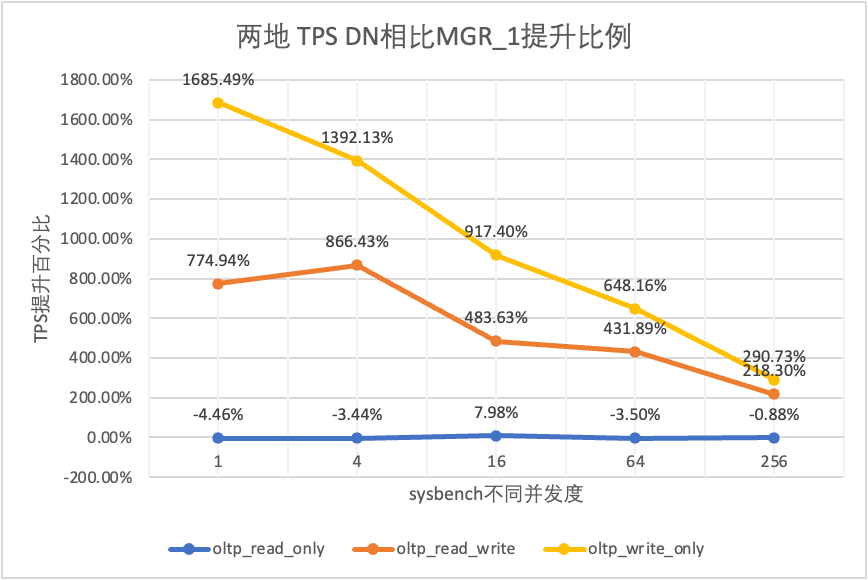
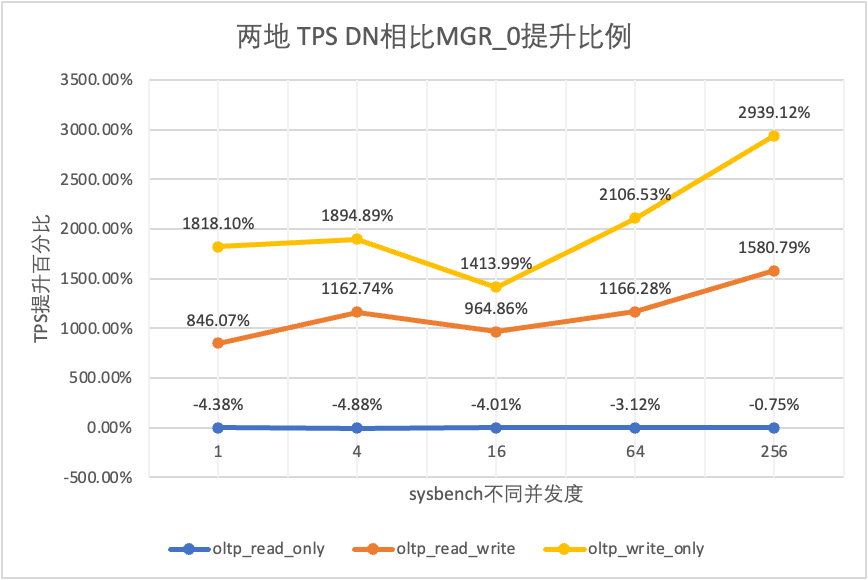
Se näkyy testituloksista:
| TPS vertailu | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 vs. MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN vs MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN vs MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_read_write | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 vs. MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN vs MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN vs MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_write_only | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 vs. MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN vs MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN vs MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
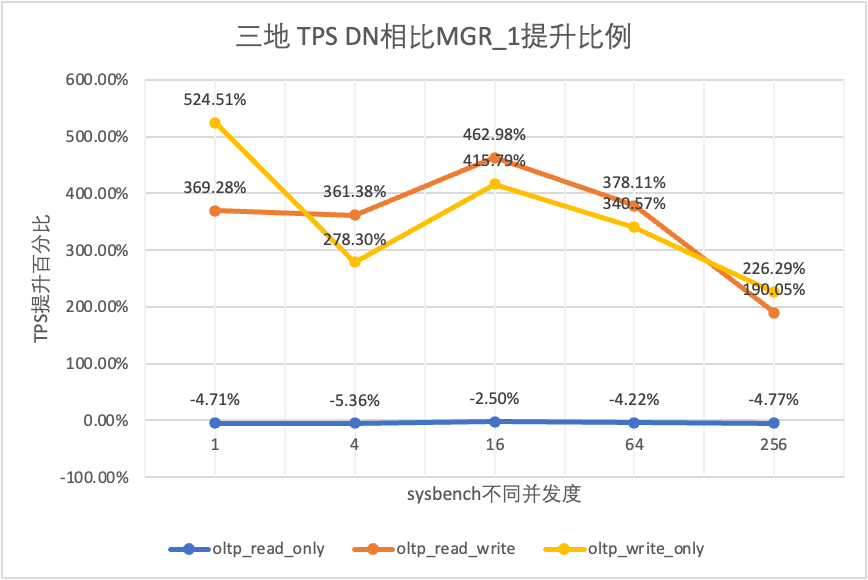
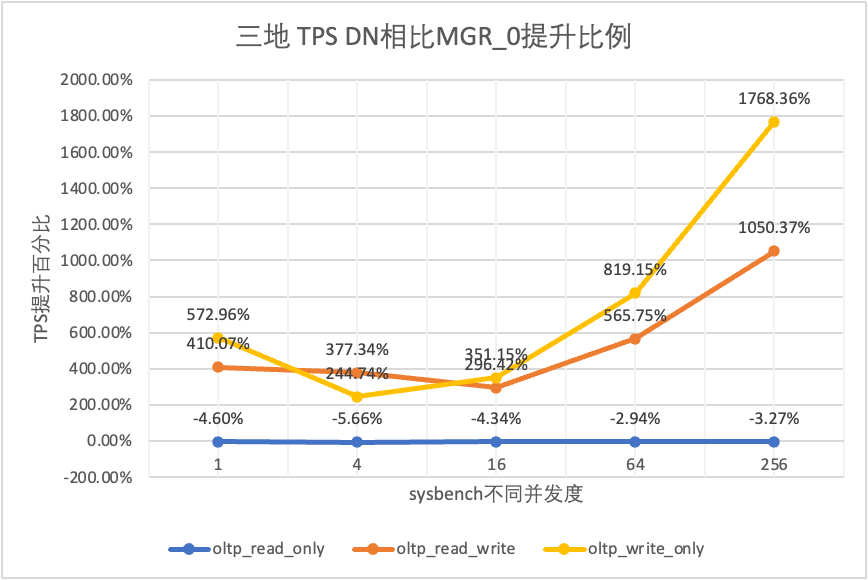
Se näkyy testituloksista:
Vertaaksemme selkeästi suorituskyvyn muutoksia eri käyttöönottomenetelmissä, valitsimme yllä olevassa testissä MGR:n ja DN:n TPS-tiedot eri käyttöönottomenetelmien oltp_write_only 256 -skenaariossa vertaili eri käyttöönottomenetelmien TPS-tietoja perusarvoon havaitakseen eron suorituskyvyn muutoksissa kaupunkien välisen käyttöönoton aikana
| MGR_1 (256 samanaikaista) | DN (256 samanaikaisesti) | DN:n suorituskykyedut MGR:ään verrattuna | |
| Sama tietokonehuone | 16092.02 | 15137.23 | -5.93% |
| Kolme keskustaa samassa kaupungissa | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Kaksi paikkaa ja kolme keskustaa | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Kolme paikkaa ja kolme keskustaa | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
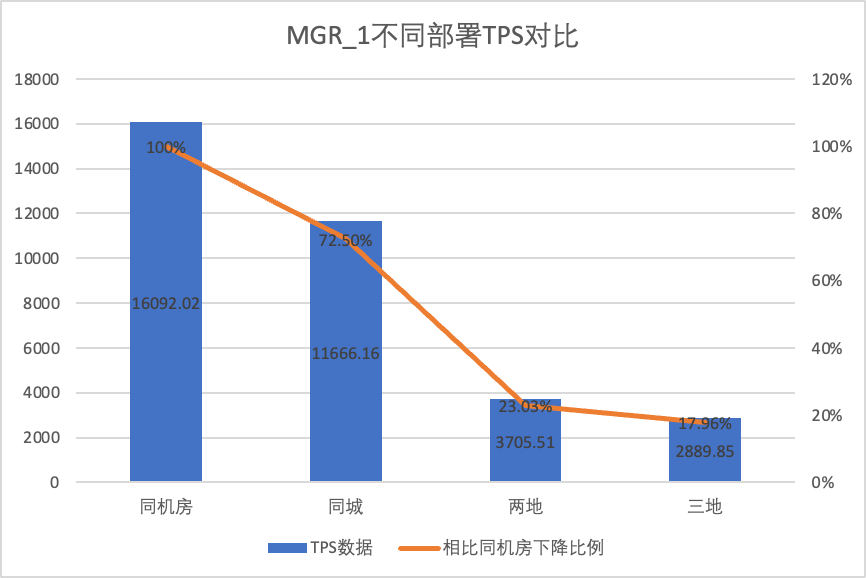
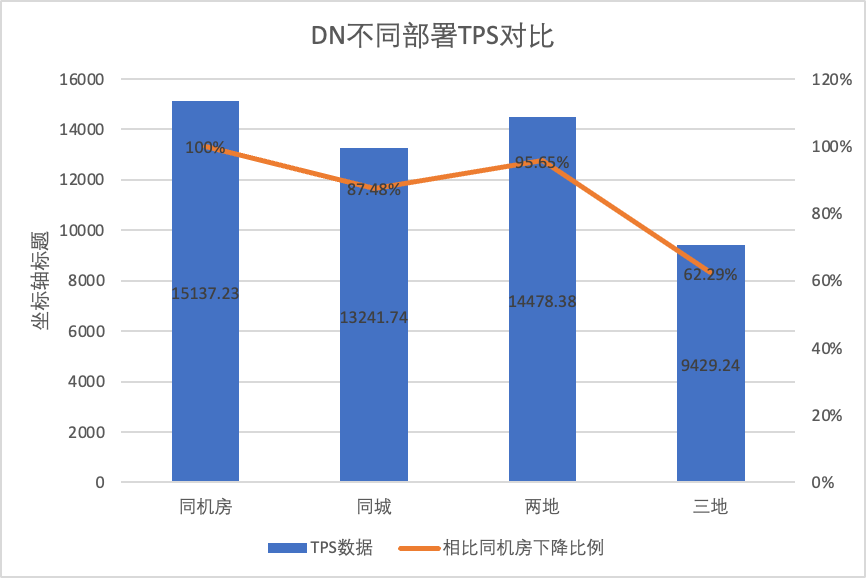
Se näkyy testituloksista:
Varsinaisessa käytössä emme kiinnitä huomiota vain suorituskykytietoihin, vaan meidän on kiinnitettävä huomiota myös suorituskyvyn tärinään. Loppujen lopuksi, jos värinä on kuin vuoristorata, todellinen käyttökokemus on erittäin huono. Tarkkailemme ja näytämme TPS:n reaaliaikaisia lähtötietoja Koska sysbenc-työkalu ei itse tue suorituskyvyn värinän tulosseurantatietoja, käytämme matemaattista variaatiokerrointa vertailuindikaattorina:
Ottamalla 256 samanaikaisen oltp_read_write -skenaarion esimerkkinä analysoimme tilastollisesti MGR_1 (RPO<>0) ja DN (RPO=0) TPS:t samassa tietokonehuoneessa, kolmessa keskustassa samassa kaupungissa, kolmessa keskustassa kahdessa paikassa ja kolme keskustaa kolmessa paikassa. Varsinainen värinäkaavio on seuraava, ja kunkin skenaarion varsinaiset värinäindikaattoritiedot ovat seuraavat:
| CV | Sama tietokonehuone | Kolme keskustaa samassa kaupungissa | Kaksi paikkaa ja kolme keskustaa | Kolme paikkaa ja kolme keskustaa |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
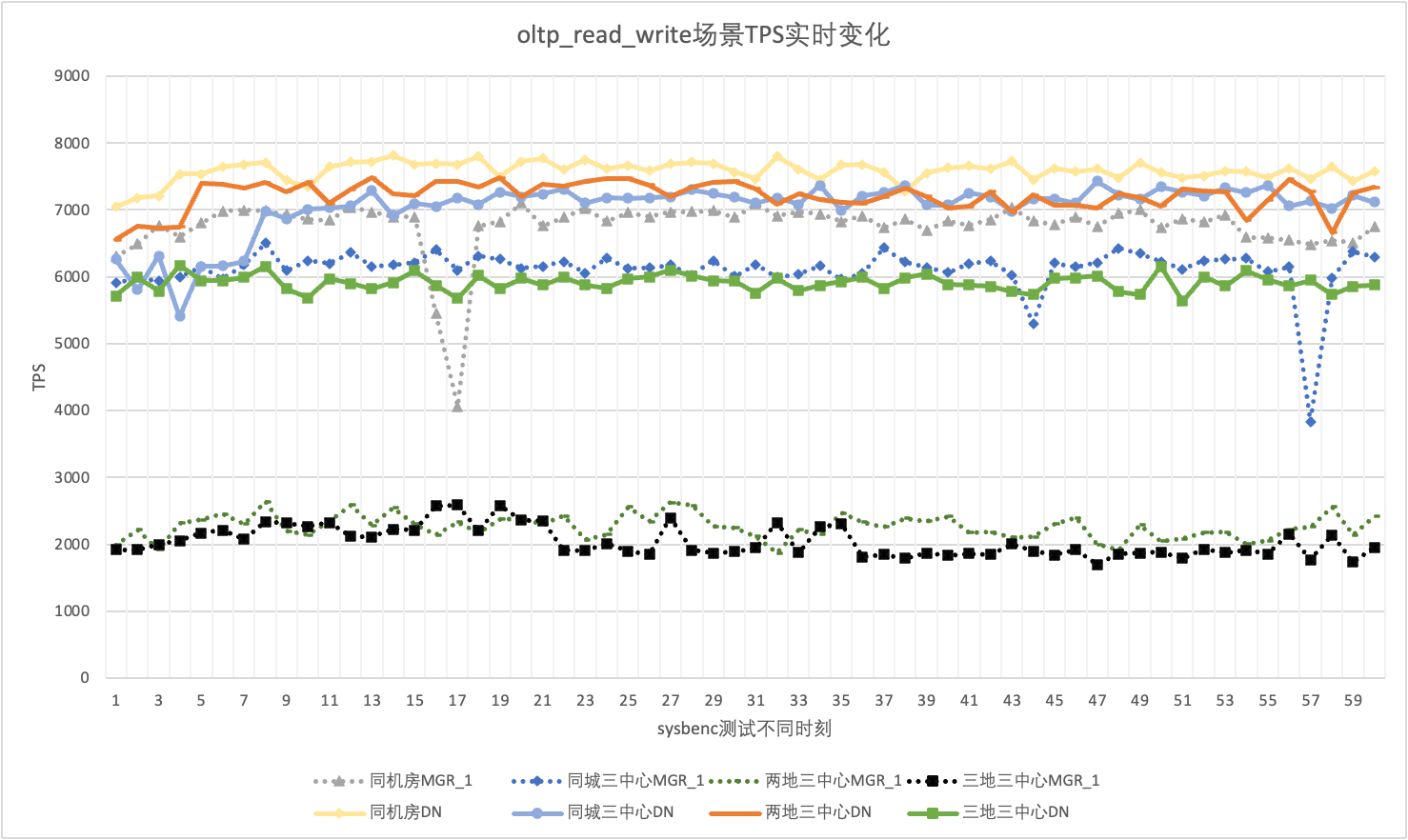
Se näkyy testituloksista:
Hajautetun tietokannan ydinominaisuus on korkea käytettävyys. Klusterin minkään solmun vika ei vaikuta yleiseen saatavuuteen. Tyypillisessä käyttöönottomuodossa, jossa on kolme solmua, joissa on yksi isäntä ja kaksi varmuuskopiota samassa tietokonehuoneessa, yritimme suorittaa käytettävyystestejä seuraavissa kolmessa skenaariossa:
Kun kuormaa ei ole, lopeta johtaja ja seuraa klusterin jokaisen solmun tilamuutoksia ja sitä, onko se kirjoitettava.
| MGR | DN | |
| Aloittaa normaalisti | 0 | 0 |
| tappaa johtaja | 0 | 0 |
| Epänormaali solmuaika löydetty | 5 | 5 |
| Aika vähentää 3 solmua 2 solmuun | 23 | 8 |
| MGR | DN | |
| Aloittaa normaalisti | 0 | 0 |
| tappaa johtaja, vetää automaattisesti ylös | 0 | 0 |
| Epänormaali solmuaika löydetty | 5 | 5 |
| Aika vähentää 3 solmua 2 solmuun | 23 | 8 |
| 2 solmun palautus 3 solmun aika | 37 | 15 |

Testituloksista voidaan nähdä, että ilman paineita:
Käytä sysbenchiä suorittaaksesi samanaikaisen 16 säikeen stressitestin oltp_read_write-skenaariossa. Tapa kuvan 10. sekunti manuaalisesti valmiustilasolmu ja tarkkaile sysbenchin reaaliaikaisia TPS-tietoja.
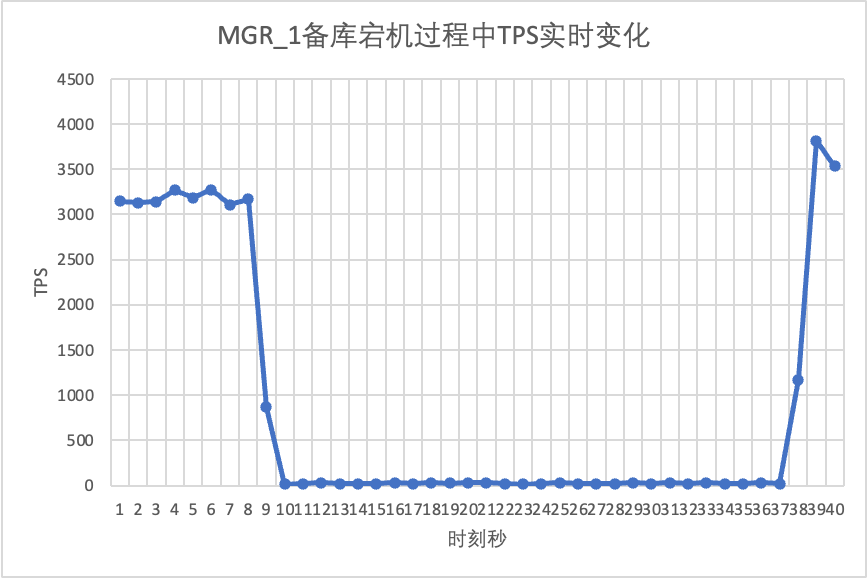


Se näkyy testitulostaulukosta:
Jatkamme testiä, käynnistämme uudelleen ja palautamme valmiustilatietokannan ja tarkkailemme muutoksia päätietokannan TPS-tiedoissa.
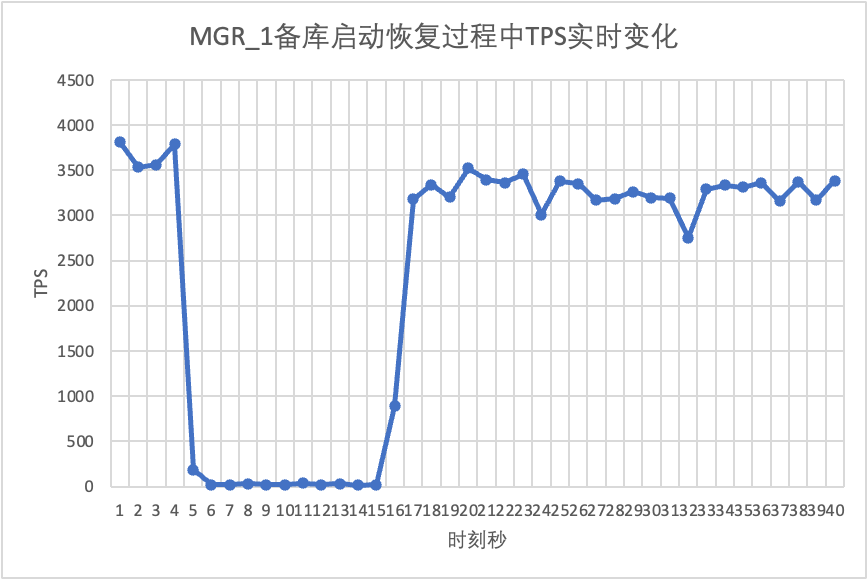
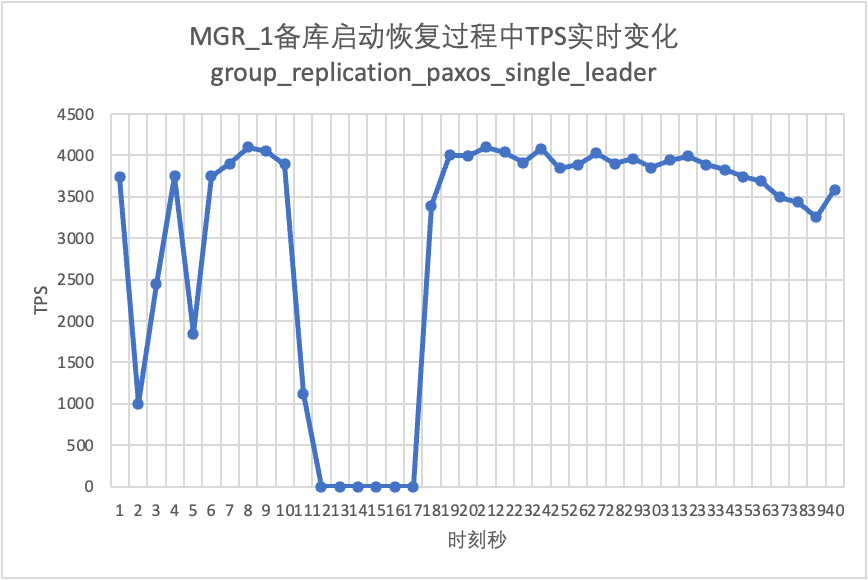
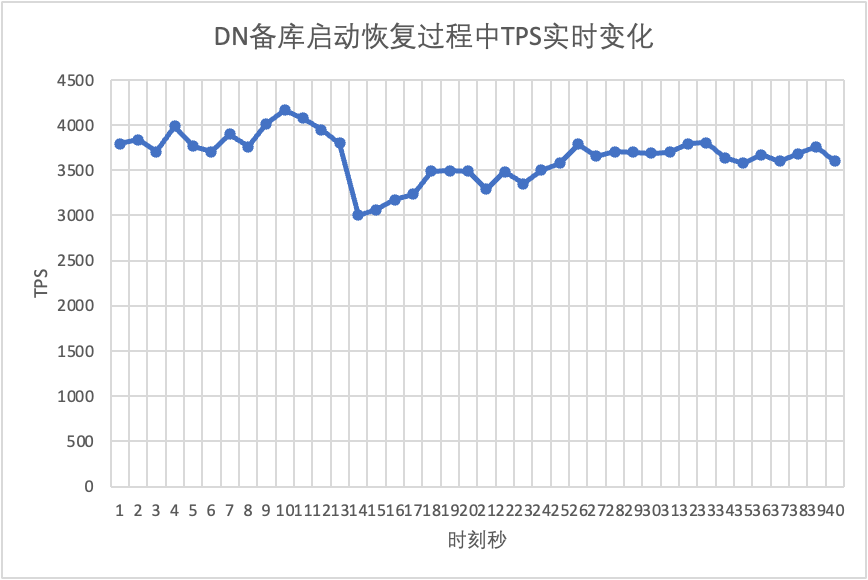
Se näkyy testitulostaulukosta:
MGR-enemmistövika RPO<>0 -skenaarion rakentamiseksi käytämme yhteisön omaa MTR Case -menetelmää virheen injektiotestien suorittamiseen MGR:ssä. Suunniteltu tapaus on seuraava:
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
Asian käsittelyn tulokset ovat seuraavat:
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
Puuttuvat numerot toistavan tapauksen likimääräinen logiikka on seuraava:
Yllä olevan tapauksen mukaan MGR:n tapauksessa, kun suurin osa palvelimista on poissa käytöstä ja päätietokanta ei ole käytettävissä, valmiustilan tietokanta on palautettu, tiedot menetetään RPO<>0 ja onnistuneen toimituksen tietue. alun perin palautettu asiakkaalle on kadonnut.
DN:lle enemmistön saavuttaminen edellyttää, että lokit säilyvät enemmistössä, joten edes yllä olevassa skenaariossa tietoja ei menetetä ja RPO=0 voidaan taata.
Perinteisessä MySQL:n aktiivisessa valmiustilassa valmiustilatietokanta sisältää yleensä IO-säikeitä ja Apply-säikeitä Paxos-protokollan käyttöönoton jälkeen IO-säie synkronoi pääasiassa valmiustilatietokannan replikointiviiveen riippuu valmiustilatietokannan Apply playbackin kulusta, tässä meistä tulee valmiustilatietokannan toistoviive.
Testaamme sysbenchin avulla oltp_write_only-skenaariota ja valmiustilatietokannan toiston viiveen kestoa alle 100 samanaikaisuuden ja erilaisten tapahtumien lukumäärän.Valmiustilatietokannan toiston viiveaika voidaan määrittää tarkkailemalla performance_schema.replication_applier_status_by_worker-taulukon APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP-saraketta nähdäkseen, työskentelevätkö jokainen työntekijä reaaliajassa, jotta voidaan määrittää, onko toisinnus päättynyt.

Se näkyy testitulostaulukosta:
| MGR | DN | ||
| esitys | Lue kauppa | tasainen | tasainen |
| kirjoittaa kauppa | Suorituskyky ei ole yhtä hyvä kuin DN, kun RPO<>0 Kun RPO = 0, suorituskyky on paljon huonompi kuin DN Kaupunkien välisen käyttöönoton suorituskyky heikkeni vakavasti 27–82 % | Kirjoitustapahtuman suorituskyky on paljon korkeampi kuin MGR Kaupunkien välisen käyttöönoton suorituskyky laskee 4 %:lla 37 %:iin. | |
| Jitter | Suorituskyvyn värinää on voimakasta, tärinän vaihteluväli on 6–10 % | Suhteellisen vakaa 3 %:ssa, vain puolet MGR:stä | |
| RTO | Päätietokanta on poissa käytöstä | Poikkeavuus havaittiin 5 sekunnissa ja väheni kahteen solmuun 23 sekunnissa. | Poikkeavuus havaittiin 5 sekunnissa ja väheni kahteen solmuun 8 sekunnissa. |
| Käynnistä pääkirjasto uudelleen | Poikkeavuus havaittiin 5 sekunnissa, ja kolme solmua palautettiin 37 sekunnissa. | Poikkeavuus havaitaan 5 sekunnissa ja kolme solmua palautuu 15 sekunnissa. | |
| Varmuuskopioi tietokannan seisokki | Päätietokannan liikenne putosi nollaan 20 sekunniksi. Sitä voidaan lievittää ottamalla käyttöön ryhmä_replication_paxos_single_leader. | Päätietokannan jatkuva korkea saatavuus | |
| Valmiustilassa tietokanta käynnistyy uudelleen | Päätietokannan liikenne putosi nollaan 10 sekunniksi. Group_replication_paxos_single_leader-toiminnon eksplisiittisellä käyttöönotolla ei myöskään ole vaikutusta. | Päätietokannan jatkuva korkea saatavuus | |
| RPO | Tapauksen toistuminen | RPO<>0, kun enemmistöpuolue kaatuu Suorituskyky ja RPO=0 eivät voi sisältää molempia. | RPO = 0 |
| Valmiustilan tietokannan viive | Varmuuskopioi tietokannan toistoaika | Viive aktiivisen ja valmiustilan välillä on erittäin suuri. Suorituskykyä ja ensisijaisen varmuuskopion viivettä ei voida saavuttaa samanaikaisesti. | Valmiustilatietokannan toistoon käytetty kokonaisaika on 4 % MGR:stä, mikä on 25 kertaa MGR:ää. |
| parametri | avainparametri |
| Oletuskokoonpano, ammattilaisten ei tarvitse mukauttaa kokoonpanoa |
Perusteellisen teknisen analyysin ja suorituskyvyn vertailun jälkeenPolarDB-X Itse kehittämällä X-Paxos-protokollalla ja useilla optimoiduilla malleilla DN on osoittanut monia etuja MySQL MGR:ään verrattuna suorituskyvyn, oikeellisuuden, käytettävyyden ja resurssien suhteen. MGR on kuitenkin myös tärkeässä asemassa MySQL-ekosysteemissä , on otettava huomioon erilaiset tilanteet, kuten valmiustilan tietokannan katkokset, konehuoneiden väliset katastrofipalautussuorituskyvyn vaihtelut ja vakaus. Siksi, jos haluat hyödyntää MGR:ää hyvin, sinun on oltava varustettu ammattitaitoisella teknisellä sekä käyttö- ja huoltotiimällä tuki.
Kun PolarDB-X-tallennusmoottorilla on suuria, korkean samanaikaisuuden ja korkean käytettävyyden vaatimuksia, sillä on ainutlaatuisia teknisiä etuja ja erinomainen suorituskyky MGR:ään verrattuna.PolarDB-XDN-pohjaisessa keskitetyssä (vakioversiossa) on hyvä tasapaino toimintojen ja suorituskyvyn välillä, mikä tekee siitä erittäin kilpailukykyisen tietokantaratkaisun.

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten

