Recuperación ante desastres de bases de datos | Comparación en profundidad entre MySQL MGR y Alibaba Cloud PolarDB-X Paxos
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Ecosistema de código abierto
Como todos sabemos, las bases de datos primarias y secundarias de MySQL (dos nodos) generalmente logran una alta disponibilidad de datos mediante la replicación asíncrona y la replicación semisincrónica (Semi-Sync). Sin embargo, en escenarios anormales como fallas en la red de la sala de computadoras y cuelgues del host. Las arquitecturas primaria y secundaria encontrarán problemas graves después del cambio de HA. Habrá una probabilidad de inconsistencia de datos (denominada RPO! = 0).Por lo tanto, siempre que los datos comerciales sean de cierta importancia, no debe elegir un producto de base de datos con arquitectura primaria y secundaria MySQL (dos nodos). Se recomienda elegir una arquitectura de copia múltiple con RPO = 0.
Comunidad MySQL, sobre la evolución de la tecnología de copia múltiple con RPO=0:
- MySQL es oficialmente de código abierto y ha lanzado la solución de alta disponibilidad MySQL Group Replication (MGR) basada en replicación grupal. El protocolo Paxos está encapsulado internamente a través de XCOM para garantizar la coherencia de los datos.
- Nube de Ali PolarDB-X , derivado del pulido comercial y la verificación del comercio electrónico Double Eleven de Alibaba y la multiactividad en diferentes lugares, será de código abierto en todo el núcleo en octubre de 2021, adoptando completamente el ecosistema de código abierto MySQL. PolarDB-X se posiciona como una base de datos integrada centralizada y distribuida. Su nodo de datos Data Node (DN) adopta el protocolo X-Paxos de desarrollo propio y es altamente compatible con MySQL 5.7/8.0. No solo proporciona capacidades de alta disponibilidad a nivel financiero. , pero también tiene las características de un motor de transacciones altamente escalable, operación y mantenimiento flexibles, recuperación ante desastres y almacenamiento de datos de bajo costo.PolarDB-X Open Source | Tres copias de MySQL basadas en Paxos》。
PolarDB-X El concepto de integración centralizada y distribuida: el nodo de datos DN se puede utilizar de forma independiente como un formulario centralizado (versión estándar), que es totalmente compatible con el formulario de base de datos independiente. Cuando el negocio crece hasta el punto en que se requiere una expansión distribuida, la arquitectura se actualiza a una forma distribuida en el lugar y los componentes distribuidos se conectan perfectamente a los nodos de datos originales. No hay necesidad de migrar o modificar datos en el lado de la aplicación. Y podrá disfrutar de la usabilidad y escalabilidad que brinda esta fórmula, descripción de la arquitectura:"Integración distribuida centralizada"
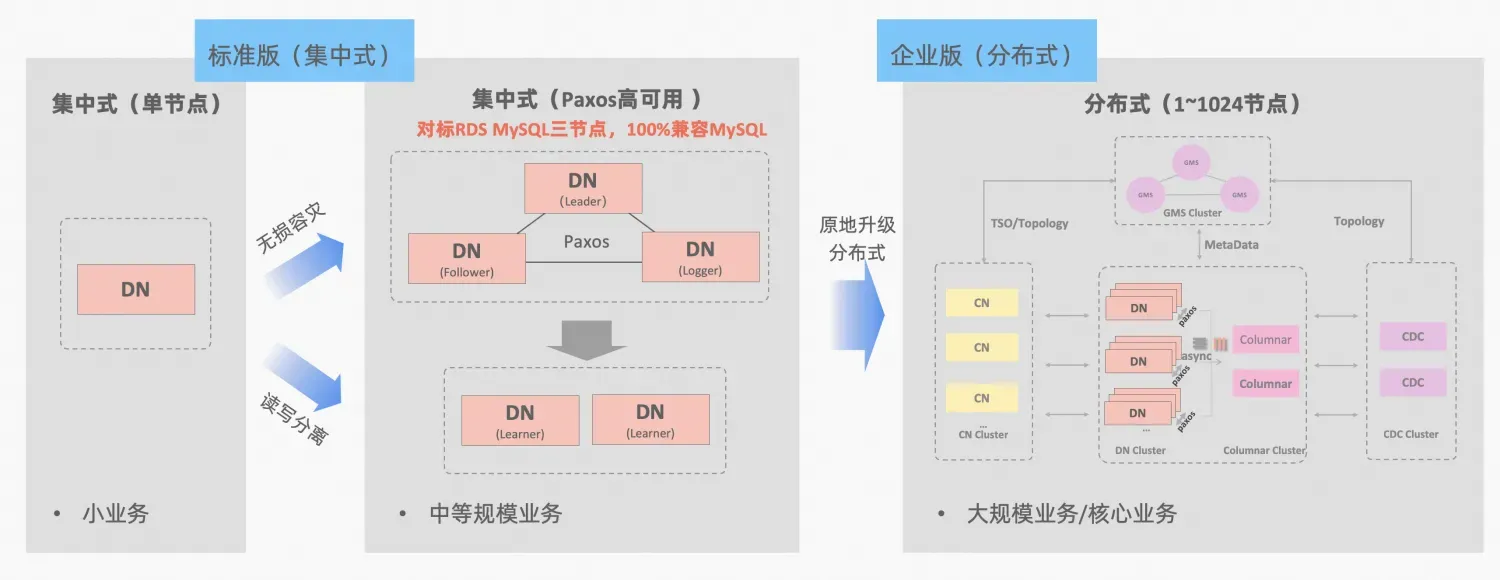
MGR de MySQL y DN de la versión estándar de PolarDB-X utilizan el protocolo Paxos desde el principio más bajo. Entonces, ¿cuáles son los rendimientos específicos y las diferencias en el uso real? Este artículo detalla los aspectos de la comparación de arquitecturas, las diferencias clave y la comparación de pruebas.
Descripción de la abreviatura de MGR/DN: MGR representa la forma técnica de MySQL MGR y DN representa la forma técnica de PolarDB-X single DN centralizado (versión estándar).
Resumen
El análisis comparativo detallado es relativamente largo, por lo que puede leer el resumen y la conclusión primero. Si está interesado, puede seguir el resumen y buscar pistas en artículos posteriores.
MySQL MGR no se recomienda para empresas y negocios en general porque requiere conocimientos técnicos profesionales y un equipo de operación y mantenimiento para usarlo bien. Este artículo también reproduce tres "errores ocultos" de MySQL MGR que han estado circulando en la industria durante mucho tiempo. :
- Dark Pit 1: los protocolos MySQL MGR y XCOM adoptan el modo de memoria completa. El valor predeterminado no cumple con la garantía de coherencia de datos de RPO = 0 (habrá un problema de datos faltantes en el caso de prueba más adelante en este artículo). muestre y configure un parámetro para garantizarlo. Actualmente El diseño de MGR no puede lograr tanto rendimiento como RPO.
- Error 2: el rendimiento de MySQL MGR es deficiente cuando hay retrasos en la red. El artículo probó una comparación de escenarios de red de 4 minutos (incluidas tres salas de computadoras en la misma ciudad y tres centros en dos lugares). parámetros de rendimiento de la ciudad, es solo 1/5 de eso en la misma ciudad, si la garantía de datos de RPO = 0 está activada, el rendimiento será aún peor.Por lo tanto, MySQL MGR es más adecuado para su uso en el mismo escenario de sala de computadoras, pero no es adecuado para la recuperación ante desastres entre salas de computadoras.
- Error 3: en la arquitectura de copias múltiples de MySQL MGR, la falla del nodo en espera hará que el tráfico del líder del nodo maestro caiga a 0, lo que no es consistente con el sentido común. El artículo se centra en intentar habilitar el modo líder único de MGR (en comparación con la arquitectura de réplica maestro-esclavo anterior de MySQL), simulando las dos acciones de tiempo de inactividad y recuperación de la réplica esclava. Las operaciones de operación y mantenimiento del nodo esclavo también causarán que el maestro. nodo (Líder) para aparecer El tráfico cayó a 0 (durando aproximadamente 10 segundos) y la operatividad y mantenibilidad generales fueron relativamente pobres.Por lo tanto, MySQL MGR tiene requisitos relativamente altos en cuanto a operación y mantenimiento del host y requiere un equipo de DBA profesional.
En comparación con MySQL MGR, PolarDB-X Paxos no tiene inconvenientes similares a MGR en términos de coherencia de datos, recuperación ante desastres entre salas de computadoras y operación y mantenimiento de nodos. Sin embargo, también tiene algunas desventajas y ventajas menores en la recuperación ante desastres:
- En un escenario simple en la misma sala de computadoras, el rendimiento de solo lectura con baja concurrencia y el rendimiento de escritura pura con alta concurrencia son ligeramente más bajos que MySQL MGR en aproximadamente un 5% y se envían varias copias a través de la red al mismo tiempo. hay margen para una mayor optimización del rendimiento.
- Ventajas: 100% compatible con las características de MySQL 5.7/8.0. Al mismo tiempo, se han realizado optimizaciones más optimizadas en la replicación de la base de datos en espera de múltiples copias y en las rutas de conmutación por error. RTO de conmutación de alta disponibilidad <= 8 segundos, un común 4. Escenario de recuperación ante desastres de minutos en la industria. Todos funcionan bien y pueden reemplazar la semisincronización (semisincronización), MGR, etc.
1. Comparación de arquitectura
Glosario
Descripción de la abreviatura de MGR/DN:
- MGR: la forma técnica de MySQL MGR, la abreviatura del contenido siguiente: MGR
- DN: Alibaba Cloud PolarDB-X es un formulario técnico centralizado (versión estándar). El nodo de datos distribuido DN se puede utilizar de forma independiente como un formulario centralizado (versión estándar). Es totalmente compatible con bases de datos independientes. como: DN
MONSEÑOR
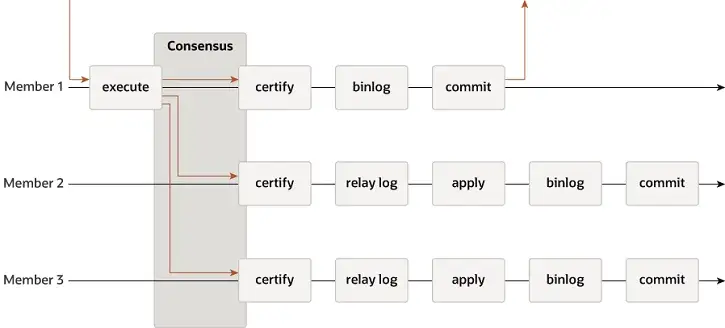
MGR admite modos de maestro único y multimaestro y reutiliza completamente el sistema de replicación de MySQL, incluidos Event, Binlog & Relaylog, Apply, Binlog Apply Recovery y GTID. La diferencia clave con DN es que el punto de entrada para que la mayoría del registro de transacciones de MGR alcance un consenso es antes de que se confirme la transacción de la base de datos principal.
-
- Antes de confirmar la transacción, se llama a la función de enlace before_commit group_replication_trans_before_commit para ingresar la replicación mayoritaria de MGR.
- MGR utiliza el protocolo Paxos para sincronizar los eventos Binlog almacenados en caché en THD con todos los nodos en línea
- Después de recibir la respuesta mayoritaria, MGR determina que la transacción puede presentarse
- THD ingresa al proceso de envío del grupo de transacciones y comienza a escribir la actualización local de Binlog Rehacer el mensaje OK del cliente de respuesta
-
- Paxos Engine de MGR continúa escuchando los mensajes de protocolo del Líder
- Después de un proceso de consenso completo de Paxos, se confirma que este evento (por lotes) ha alcanzado la mayoría en el clúster.
- Escriba el evento recibido en el registro de retransmisión, el subproceso IO aplique el registro de retransmisión
- La aplicación Relay Log pasa por un proceso completo de envío de grupo y la base de datos en espera eventualmente generará su propio archivo binlog.
La razón por la que MGR adopta el proceso anterior es porque MGR está en modo multimaestro de forma predeterminada y cada nodo puede escribir. Por lo tanto, el nodo seguidor en un único grupo Paxos primero debe convertir el registro recibido en un RelayLog y luego combinarlo. con la transacción de escritura que recibe como líder para enviar, se genera el archivo Binlog para enviar la transacción final en el proceso de envío grupal de dos etapas.
No.
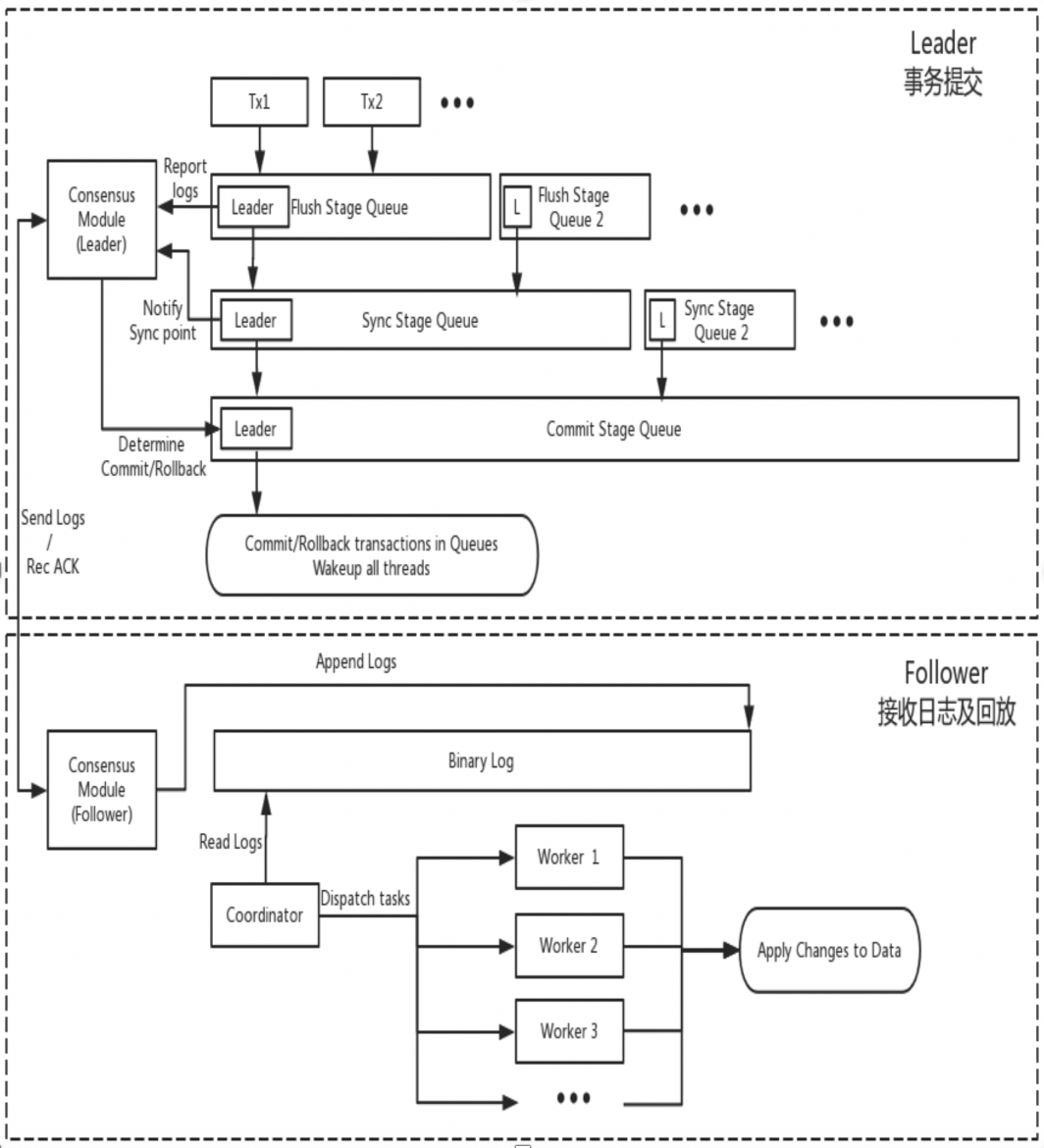
DN reutiliza la estructura de datos básica y el código de nivel de función de MySQL, pero integra estrechamente la replicación de registros, la administración de registros, la reproducción de registros y la recuperación de fallas con el protocolo X-Paxos para formar su propio conjunto de mecanismos de máquina de estado y replicación mayoritaria. La diferencia clave con MGR es que el punto de entrada para que la mayoría del registro de transacciones de DN llegue a un consenso es durante el proceso de envío de transacciones de la base de datos principal.
-
- Ingrese al proceso de envío grupal de la transacción. En la fase de descarga del envío grupal, los eventos en cada THD se escriben en el archivo Binlog y luego el registro se transmite de forma asincrónica a todos los seguidores a través de X-Paxos.
- En la fase de sincronización del envío del grupo, el Binlog persiste primero y luego se actualiza la ubicación de persistencia de X-Paxos.
- En la fase de confirmación del envío del grupo, primero debe esperar a que X-Paxos reciba la respuesta mayoritaria, luego enviar el grupo de transacciones y finalmente responder con un mensaje de aprobación del cliente.
-
- X-Paxos continúa escuchando mensajes de protocolo del Líder
- Reciba eventos (de grupo), escriba en el Binlog local y responda
- Se recibe el siguiente mensaje, que lleva el índice de compromiso de la posición donde se ha alcanzado la mayoría.
- El subproceso SQL Apply continúa aplicando el registro Binlog recibido en segundo plano y solo lo aplica a la posición mayoritaria como máximo.
La razón de este diseño es que DN actualmente solo admite el modo de maestro único, por lo que el registro en el nivel del protocolo X-Paxos es el propio Binlog Follower y omite el registro de retransmisión, y el contenido de datos de su registro persistente y el registro del líder. son iguales al mismo precio.
2. Diferencias clave
2.1. Eficiencia del protocolo Paxos

MONSEÑOR
- El protocolo Paxos de MGR se implementa en base al protocolo Mencius, que pertenece a la teoría Multi-Paxos. La diferencia es que Mencius ha realizado mejoras de optimización para reducir la carga del nodo maestro y aumentar el rendimiento.
- El protocolo Paxos de MGR es implementado por componentes XCOM y admite la implementación en modo multimaestro y maestro único. En el modo maestro único, Binlog en el líder transmite atómicamente al nodo seguidor La transmisión de cada lote de mensajes (una transacción). un proceso estándar de Multi-Paxos.
- Para satisfacer la mayor parte de una transacción, XCOM necesita pasar por al menos tres interacciones de mensajes de Aceptar+Aceptar+Aprender, es decir,Al menos 1,5 RTT por encima.Requiere como máximo tres interacciones de mensajes: Preparar+AckPrepare+Aceptar+AckAceptar+Aprender.Es decir, un máximo de 2,5 RTT de sobrecarga en total
- Dado que el protocolo Paxos se completa con alta cohesión en el módulo XCOM y no conoce el sistema de replicación MySQL, el líder debe esperar a que se complete el proceso completo de Paxos antes de confirmar la transacción localmente, incluida la persistencia de Binlog y el envío grupal.
- Después de que el seguidor complete el envío mayoritario, persistirá de forma asincrónica los eventos en el registro de retransmisión y luego la aplicación y el grupo de subprocesos SQL enviarán el Binlog de producción.
- Dado que el registro sincronizado por Paxos es un Binlog que no se ordena antes de ingresar al proceso de envío del grupo, el orden de los eventos de Binlog en el líder puede no ser el mismo que el orden de los eventos en el registro de retransmisión en el nodo seguidor.

No.
- El protocolo Paxos de DN se implementa en base al protocolo Raft y también pertenece a la teoría Multi-Paoxs. La diferencia es que el protocolo Raft tiene una garantía de liderazgo y una garantía de estabilidad de ingeniería más fuertes.
- El protocolo Paxos de DN se completa con el componente X-Paoxs. El modo predeterminado es el modo maestro único. En el modo maestro único, Binlog en el líder transmite atómicamente al nodo seguidor. La transmisión de cada lote de mensajes es un proceso estándar de Raft. .
- Para satisfacer la mayor parte de una transacción, X-Paoxs sólo necesita pasar por las dos interacciones de mensajes de Append+AckAppend, y sólo1 RTT por encima
- Después de que el líder envía el registro al seguidor, siempre que la mayoría esté satisfecha, confirma la transacción sin esperar a que se transmita el índice de confirmación en la segunda etapa.
- Antes de que el seguidor pueda completar el envío mayoritario, todos los registros de transacciones deben conservarse. Esto es significativamente diferente del XCOM de MGR. MGR solo necesita recibirlo en la memoria XCOM.
- El índice de confirmación se incluye en mensajes posteriores y mensajes de latido, y el seguidor realiza el evento de aplicación después de que se sube el índice de confirmación.
- El contenido de Binlog de Leader y Follower está en el mismo orden, los registros de Raft no tienen agujeros y el mecanismo de procesamiento por lotes/canalización se utiliza para aumentar el rendimiento de replicación de registros.
- En comparación con MGR, el líder siempre tiene solo un retraso de ida y vuelta cuando se confirma una transacción., muy crítico para aplicaciones distribuidas sensibles al retraso
2.2. RPO
En teoría, tanto Paxos como Raft pueden garantizar la coherencia de los datos y los registros que hayan alcanzado la mayoría después de Crash Recovery no se perderán, pero todavía existen diferencias en proyectos específicos.
MONSEÑOR
XCOM encapsula completamente el protocolo Paxos y todos los datos de su protocolo se almacenan primero en la memoria caché. De forma predeterminada, las transacciones que alcanzan la mayoría no requieren persistencia del registro. En el caso de que la mayoría de los pasteles estén caídos y el líder falle, habrá un problema grave de RPO! = 0.Supongamos un escenario extremo:
- El clúster MGR consta de tres nodos ABC, de los cuales AB es una sala de computadoras independiente en la misma ciudad y C es un nodo entre ciudades. A es líder, BC es nodo seguidor
- Inicie la transacción 001 en el nodo Líder A. El líder A transmite el registro de la transacción 001 al nodo BC. Si la mayoría está satisfecho a través del protocolo Paxos, la transacción se puede considerar enviada. La sección AB formó la mayoría y el nodo C no recibió el registro de la transacción 001 debido a un retraso en la red entre ciudades.
- En el momento siguiente, el Líder A envía la transacción 001 y devuelve el éxito del Cliente, lo que significa que la transacción 001 se ha enviado a la base de datos.
- En este momento, en el seguidor del nodo B, el registro de la transacción 001 todavía está en la caché de XCOM y no ha tenido tiempo de vaciarse en el RelayLog; en este momento, el seguidor del nodo C aún no ha recibido la transacción 001; registro del líder del nodo A.
- En este momento, el nodo AB está inactivo, el nodo A falla y no se puede recuperar durante mucho tiempo, el nodo B se reinicia y se recupera rápidamente y los nodos BC continúan brindando servicios de lectura y escritura.
- Dado que el registro de la transacción 001 no persistió en el RelayLog del nodo B durante el tiempo de inactividad, ni fue recibido por el nodo C, en este momento, el nodo BC en realidad perdió la transacción 001 y no puede recuperarla.
- En este escenario donde el partido mayoritario está caído, RPO!=0
Según los parámetros predeterminados de la comunidad, la mayoría de las transacciones no requieren persistencia de registros y no garantizan RPO=0. Esto puede considerarse una compensación por el rendimiento en la implementación del proyecto XCOM. Para garantizar un RPO absoluto = 0, debe configurar el parámetro group_replication_consistency que controla la coherencia de lectura y escritura en DESPUÉS. Sin embargo, en este caso, además de la sobrecarga de la red 1,5 RTT, la transacción requerirá una sobrecarga de registro de E/S para alcanzar la mayoría. y el rendimiento será muy pobre.
No.
PolarDB-X DN utiliza X-Paxos para implementar un protocolo distribuido y está profundamente vinculado al proceso de confirmación de grupo de MySQL. Cuando se envía una transacción, se requiere que la mayoría confirme la ubicación y la persistencia antes de que se permita el envío real. La mayor parte de la ubicación del disco aquí se refiere a la ubicación Binlog de la biblioteca principal. El subproceso IO de la biblioteca en espera recibe el registro de la biblioteca principal y lo escribe en su propio Binlog para su persistencia. Por lo tanto, incluso si todos los nodos fallan en escenarios extremos, los datos no se perderán y se puede garantizar RPO=0.
2.3. RTO
El tiempo RTO está estrechamente relacionado con el tiempo de sobrecarga del reinicio en frío del propio sistema, lo que se refleja en las funciones básicas específicas:Mecanismo de detección de fallas->mecanismo de recuperación de fallas->mecanismo de selección maestra->equilibrio de registros
2.3.1. Detección de fallos
MONSEÑOR
- Cada nodo envía periódicamente paquetes de latidos a otros nodos para verificar si otros nodos están en buen estado. El período de latido se fija en 1 segundo y no se puede ajustar.
- Si el nodo actual descubre que otros nodos no han respondido después de group_replication_member_expel_timeout (5 segundos predeterminado), se considerará un nodo fallido y será expulsado del clúster.
- Para excepciones como interrupciones de la red o reinicios anormales, después de restaurar la red, un único nodo fallido intentará unirse automáticamente al clúster y luego bloquear el registro.
No.
- El nodo líder envía periódicamente paquetes de latidos a otros nodos para verificar si otros nodos están en buen estado. El período de latido es 1/5 del tiempo de espera de la elección. El tiempo de espera de la elección está controlado por el parámetro consenso_election_timeout. El valor predeterminado es 5 segundos, por lo que el período de latido del nodo líder es de 1 segundo.
- Si el líder descubre que otros nodos están fuera de línea, continuará enviando periódicamente paquetes de latidos a todos los demás nodos para garantizar que otros nodos puedan acceder a tiempo después de que fallen y se recuperen.Sin embargo, el nodo líder ya no envía registros de transacciones al nodo fuera de línea.
- Los nodos no líderes no envían paquetes de detección de latidos, pero si el nodo no líder descubre que no ha recibido el latido del nodo líder después del consenso_election_timeout, se activará una reelección.
- Para excepciones como interrupción de la red o reinicio anormal, después de restaurar la red, el nodo defectuoso se unirá automáticamente al clúster.
- Por lo tanto, en términos de detección de fallas, DN proporciona más interfaces de configuración de operación y mantenimiento, y la identificación de fallas en escenarios de implementación entre ciudades será más precisa.
2.3.2. Recuperación de fallos
MONSEÑOR
-
- El protocolo Paxos implementado por XCOM está en estado de memoria. El logro de la mayoría no requiere persistencia. El estado del protocolo se basa en el estado de la memoria del nodo mayoritario superviviente.Si todos los nodos cuelgan, el protocolo no se puede restaurar. Una vez reiniciado el clúster, se requiere intervención manual para restaurarlo.
- Si solo un nodo falla y se recupera, pero el nodo seguidor va por detrás del nodo líder con más registros de transacciones y los registros de transacciones almacenados en caché de XCOM en el líder se han borrado, la única opción es utilizar el proceso de recuperación global o clonación.
- El tamaño de la caché de XCOM está controlado por group_replication_message_cache_size, el valor predeterminado es 1 GB
- Recuperación global significa que cuando un nodo se reincorpora al clúster, recupera datos obteniendo los registros de transacciones faltantes necesarios (registro binario) de otros nodos.Este proceso depende de que al menos un nodo del clúster conserve todos los registros de transacciones necesarios.
- Clone se basa en el complemento Clone, que se utiliza para la recuperación cuando la cantidad de datos es grande o faltan muchos registros.Funciona copiando una instantánea de toda la base de datos en el nodo bloqueado, seguida de una sincronización final con el último registro de transacciones.
- Los procesos de Recuperación Global y Clonación suelen estar automatizados, pero en algunos casos especiales, como problemas de red o se ha borrado el caché XCOM de los otros dos nodos, se requiere intervención manual.
No.
-
- El protocolo X-Paxos utiliza la persistencia de Binlog. Cuando se recupera de una falla, las transacciones enviadas se restaurarán por completo primero. Para las transacciones pendientes, debe esperar a que la capa del protocolo XPaxos llegue a un acuerdo para determinar la relación maestro-respaldo antes de confirmar o revertir la transacción. Todo el proceso está totalmente automatizado.Incluso si todos los nodos están inactivos, el clúster puede recuperarse automáticamente después de reiniciarse.
- Para escenarios en los que el nodo Seguidor va por detrás del nodo Líder en muchos registros de transacciones, siempre que no se elimine el archivo Binlog en el Líder, el nodo Seguidor definitivamente se pondrá al día.
- Por lo tanto, en términos de recuperación de fallos, DN no requiere ninguna intervención manual.
2.3.3. Elegir al líder
En el modo de maestro único, XCOM y DN X-Paxos de MGR, un modo de líder fuerte, siguen el mismo principio básico para seleccionar el líder: los registros acordados por el clúster no se pueden revertir. Pero cuando se trata del registro de desacuerdo, existen diferencias
MONSEÑOR
- La selección del líder tiene más que ver con qué nodo servirá como servicio líder a continuación.Este líder no necesariamente tiene el registro de consenso más reciente cuando es elegido, por lo que necesita sincronizar los registros más recientes de otros nodos en el clúster y proporcionar servicios de lectura y escritura después de vincular los registros.
- La ventaja de esto es que la elección del Líder en sí es un producto estratégico, como el peso y el orden. MGR controla el peso de cada nodo a través del parámetro group_replication_member_weight
- La desventaja es que el líder recién elegido puede tener un gran retraso en la replicación y necesita continuar poniéndose al día con el registro, o puede tener un gran retraso en la aplicación y necesita continuar poniéndose al día con la aplicación de registro antes de que pueda proporcionar lectura y escribir servicios.Esto da como resultado un tiempo de RTO más largo.
No.
- La elección del líder se realiza en el sentido del protocolo. Cualquier nodo que tenga los registros de todos los partidos mayoritarios en el grupo puede ser elegido líder, por lo que este nodo puede haber sido un seguidor o un registrador antes.
- El registrador no puede proporcionar servicios de lectura y escritura. Después de sincronizar los registros con otros nodos, abandonará activamente el rol de líder.
- Para garantizar que el nodo designado se convierta en líder, DN utiliza la estrategia de peso optimista + la estrategia de peso obligatorio para limitar el orden de convertirse en líder, y utiliza el mecanismo de mayoría estratégica para garantizar que el nuevo maestro pueda proporcionar lectura y escritura de inmediato. servicios con cero retraso.
- Por lo tanto, en términos de selección de líderes, DN no solo admite la misma selección estratégica que MGR, sino que también admite estrategias de peso obligatorias.
2.3.4. Coincidencia de registros
La ecualización de registros significa que hay un retraso en la replicación de registros entre las bases de datos primaria y secundaria, y la base de datos secundaria necesita ecualizar los registros. Para los nodos que se reinician y restauran, la recuperación generalmente se inicia con la base de datos en espera y ya se ha producido un retraso en la replicación de registros en comparación con la base de datos principal, y los registros deben actualizarse con la base de datos principal. Para aquellos nodos que están físicamente lejos del líder, alcanzar la mayoría generalmente no tiene nada que ver con ellos. Siempre tienen un retraso en el registro de replicación y siempre están poniéndose al día con el registro. Estas situaciones requieren una implementación de ingeniería específica para garantizar la resolución oportuna de los retrasos en la replicación de registros.
MONSEÑOR
- Todos los registros de transacciones están en el caché de XCOM y el caché es solo de 1G de forma predeterminada. Por lo tanto, cuando un nodo seguidor que está muy atrasado en la replicación de registros de solicitudes, es fácil borrar el caché.
- En este momento, el seguidor rezagado será expulsado automáticamente del clúster y luego utilizará el proceso de recuperación global o clonación mencionado anteriormente para la recuperación de fallas y luego se unirá automáticamente al clúster después de ponerse al día.si te encuentrasPor ejemplo, problemas de red o se borra el caché XCOM de los otros dos nodos, en cuyo caso se requiere intervención manual para resolver el problema.
- ¿Por qué debemos expulsar el clúster primero? Porque el nodo defectuoso en modo de escritura múltiple afecta en gran medida el rendimiento y el caché del líder no tiene ningún efecto sobre él. Debe agregarse después de la conexión asincrónica.
- ¿Por qué no podemos leer directamente el archivo Binlog local del líder? Porque el protocolo XCOM mencionado anteriormente está en la memoria completa y no hay información de protocolo sobre XCOM en Binlog y Relay Log.
No.
- Todos los datos están en el archivo Binlog. Mientras el Binlog no se limpie, se pueden enviar a pedido y no hay posibilidad de ser expulsado del clúster.
- Para reducir la fluctuación de IO causada por la lectura de registros de transacciones antiguos del archivo Binlog por parte de la biblioteca principal, DN da prioridad a la lectura de los registros de transacciones almacenados en caché más recientes desde FIFO Cache. La caché FIFO está controlada por el parámetro consenso_log_cache_size y el valor predeterminado. es 64M
- Si el registro de transacciones actualizado ha eliminado el registro de transacciones antiguo en la caché FIFO, DN intentará leer el registro de transacciones previamente almacenado en caché desde la caché de captación previa. La caché de captación previa está controlada por el parámetro consenso_prefetch_cache_size y el valor predeterminado es 64M.
- Si no se requiere un registro de transacciones antiguo en Prefetch Cache, DN intentará iniciar una tarea de IO asincrónica, leerá varios registros consecutivos antes y después del registro de transacciones especificado del archivo Binlog en lotes, los colocará en Prefetch Cache y esperará. para el próximo reintento de lectura de DN.
- Por lo tanto, DN no requiere ninguna intervención manual cuando se trata de equilibrar registros.
2.4. Retraso en la reproducción de la base de datos en espera
El retraso de reproducción de la base de datos en espera es el retraso entre el momento en que se completa la misma transacción en la base de datos principal y el momento en que se aplica la transacción en la base de datos en espera. Lo que se prueba aquí es el rendimiento del registro de aplicación de aplicación de la base de datos en espera. Afecta el tiempo que tarda la base de datos en espera en completar su aplicación de datos y proporcionar servicios de lectura y escritura cuando se produce una excepción.
MONSEÑOR
- La base de datos en espera de MGR recibe el archivo RelayLog de la base de datos principal. Al aplicar la aplicación, necesita leer el RelayLog nuevamente, pasar por un proceso completo de envío grupal de dos etapas y producir los datos y archivos Binlog correspondientes.
- La eficiencia de la aplicación de transacciones aquí es la misma que la eficiencia del envío de transacciones en la base de datos principal. La configuración predeterminada de doble uno (innodb_flush_log_at_trx_commit, sync_binlog) hará que la misma sobrecarga de recursos de la aplicación de base de datos en espera sea grande.
No.
- La base de datos de respaldo de DN recibe el archivo Binlog de la base de datos principal. Al realizar la solicitud, el Binlog debe leerse nuevamente. Solo necesita pasar por el proceso de envío grupal de una etapa y generar los datos correspondientes.
- Dado que DN admite Crash Recover completo, la aplicación de base de datos en espera no necesita habilitar innodb_flush_log_at_trx_commit=1, por lo que en realidad no se ve afectada por la configuración doble uno.
- Por lo tanto, en términos de retraso en la reproducción de la base de datos en espera, la eficiencia de reproducción de la base de datos en espera de DN será mucho mayor que la de MGR.
2.5. Impacto de los grandes acontecimientos
Las transacciones grandes no solo afectan el envío de transacciones ordinarias, sino que también afectan la estabilidad de todo el protocolo distribuido en un sistema distribuido. En casos severos, una transacción grande hará que todo el clúster no esté disponible durante mucho tiempo.
MONSEÑOR
- MGR no tiene ninguna optimización para admitir transacciones grandes. Simplemente agrega el parámetro group_replication_transaction_size_limit para controlar el límite superior de transacciones grandes. El valor predeterminado es 143 M y el máximo es 2 GB.
- Cuando el registro de transacciones excede el límite de transacciones grandes, se informará un error directamente y la transacción no se podrá enviar.
No.
- Para resolver el problema de inestabilidad de los sistemas distribuidos causado por grandes transacciones, DN adopta la solución de división de transacciones grandes + división de objetos grandes para resolver el problema. DN dividirá el registro de transacciones de grandes transacciones lógicamente + físicamente. Bloques pequeños, cada bloque pequeño del registro de transacciones utiliza la garantía de compromiso completa de Paxos.
- Basado en la solución de dividir transacciones grandes, DN no impone ninguna restricción sobre el tamaño de las transacciones grandes. Los usuarios pueden usarlas a voluntad y también pueden garantizar RPO = 0.
- Para obtener instrucciones detalladas, consulte"Tecnología central del motor de almacenamiento PolarDB-X | Optimización de grandes transacciones"
- Por lo tanto, DN puede manejar asuntos a gran escala sin verse afectado por asuntos a gran escala.
2.6. Formulario de implementación
MONSEÑOR
- MGR admite modos de implementación de maestro único y maestro múltiple. En el modo maestro múltiple, cada nodo se puede leer y escribir. En el modo maestro único, la base de datos principal se puede leer y escribir, y la base de datos en espera solo se puede leer. solo.
- La implementación de alta disponibilidad de MGR requiere al menos tres implementaciones de nodos, es decir, no se admiten al menos tres copias de datos y registros.
- MGR no admite la expansión de nodos de solo lectura, pero admite la combinación del modo de replicación maestro-esclavo MGR + para lograr una expansión de topología similar.
No.
- DN admite la implementación del modo maestro único. En el modo maestro único, la base de datos principal se puede leer y escribir, y la base de datos en espera solo puede ser de solo lectura.
- La implementación de alta disponibilidad de DN requiere al menos tres nodos, pero admite la copia de registros en forma de Logger, es decir, Leader y Follower son copias con todas las funciones. En comparación con Logger, solo tiene registros y no tiene datos, y no tiene derecho a serlo. elegido. En este caso, la implementación de alta disponibilidad de tres nodos solo requiere la sobrecarga de almacenamiento de 2 copias de datos + 3 copias de registros, lo que la convierte en una implementación de bajo costo.
- DN admite la implementación de nodos de solo lectura y el formulario de aprendizaje de copia de solo lectura. En comparación con las copias con todas las funciones, solo no tiene derechos de voto. A través de las copias de aprendizaje, se realiza el consumo de suscripción posterior a la biblioteca principal.

2.7. Resumen de funciones
| | MONSEÑOR | No. |
| Eficiencia del protocolo | Tiempo de envío de la transacción | 1,5 ~ 2,5 tiempos de respuesta | 1 RTT |
| | Persistencia mayoritaria | guardado de memoria XCOM | persistencia de binlog |
| fiabilidad | OPR=0 | No garantizado por defecto | Totalmente garantizado |
| | Detección de fallas | Todos los nodos se controlan entre sí, la carga de la red es alta El ciclo de latidos no se puede ajustar | El nodo maestro comprueba periódicamente otros nodos Los parámetros del ciclo de latidos son ajustables. |
| | Recuperación del colapso de la mayoría | intervención manual | Recuperación automática |
| | Recuperación de caídas de minorías | Recuperación automática en la mayoría de los casos, intervención manual en circunstancias especiales. | Recuperación automática |
| | Elige el maestro | Especifique libremente el orden de selección | Especifique libremente el orden de selección |
| corbata de troncos | Los registros retrasados no pueden exceder el caché de 1 GB de XCOM | Los archivos BInlog no se eliminan |
| Retraso en la reproducción de la base de datos en espera | Dos etapas + doble, muy lenta | Una etapa + doble cero, más rápido |
| Grandes negocios | El límite predeterminado no es más de 143 MB. | Sin límite de tamaño |
| forma | Costo de alta disponibilidad | Tres copias completamente funcionales, 3 copias de sobrecarga de almacenamiento de datos | Copia del registro del registrador, 2 copias de almacenamiento de datos |
| nodo de solo lectura | Implementado con replicación maestro-esclavo. | El protocolo viene con una implementación de copia de solo lectura Leaner. |
3. Comparación de pruebas
MGR se introdujo en MySQL 5.7.17, pero más funciones relacionadas con MGR solo están disponibles en MySQL 8.0, y en MySQL 8.0.22 y versiones posteriores, el rendimiento general será más estable y confiable. Por lo tanto, seleccionamos la última versión 8.0.32 de ambas partes para realizar pruebas comparativas.
Teniendo en cuenta que existen diferencias en los entornos de prueba, métodos de compilación, métodos de implementación, parámetros operativos y métodos de prueba durante las pruebas comparativas de PolarDB-X DN y MySQL MGR, lo que puede generar datos de comparación de prueba inexactos, este artículo se centrará en varios detalles. . Proceder de la siguiente:
| examen de preparación | DN de PolarDB-X | Administrador de MySQL[1] |
| Entorno de hardware | Usando la misma máquina física con memoria 96C 754GB y disco SSD |
| Sistema operativo | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| Versión del núcleo | Usando una línea de base del kernel basada en la versión comunitaria 8.0.32 |
| Método de compilación | Compilar con el mismo RelWithDebInfo |
| Parámetros de operación | Utilice el mismo sitio web oficial de PolarDB-X para vender 32C128G con las mismas especificaciones y parámetros |
| Método de implementación | Modo maestro único |
Nota:
- MGR tiene el control de flujo habilitado de forma predeterminada, mientras que PolarDB-X DN tiene el control de flujo desactivado de forma predeterminada.Por lo tanto, group_replication_flow_control_mode de MGR se configura por separado para que el rendimiento de MGR sea el mejor.
- MGR tiene un cuello de botella de lectura obvio durante la enumeración, por lo que replication_optimize_for_static_plugin_config de MGR se configura y habilita por separado, de modo que el rendimiento de solo lectura de MGR será el mejor.
3.1. Rendimiento
Las pruebas de rendimiento son lo primero a lo que todos prestan atención al seleccionar una base de datos. Aquí utilizamos la herramienta oficial sysbench para crear 16 tablas, cada una con 10 millones de datos, para realizar pruebas de rendimiento en escenarios OLTP y probar y comparar el rendimiento de las dos en diferentes condiciones de concurrencia en diferentes escenarios OLTP.Teniendo en cuenta las diferentes situaciones de implementación real, simulamos los siguientes cuatro escenarios de implementación respectivamente:
- Se implementan tres nodos en la misma sala de computadoras. Hay un retraso de red de 0,1 ms cuando las máquinas hacen ping entre sí.
- Tres centros en la misma ciudad y tres salas de computadoras en la misma región implementan tres nodos. Hay un retraso de red de 1 ms en el ping entre las salas de computadoras (por ejemplo: tres salas de computadoras en Shanghai).
- Tres centros en dos lugares, tres nodos implementados en tres salas de computadoras en dos lugares, ping de red de 1 ms entre salas de computadoras en la misma ciudad, retraso de red de 30 ms entre la misma ciudad y otro lugar (por ejemplo: Shanghai/Shanghai/Shenzhen)
- Tres centros en tres lugares, tres nodos implementados en tres salas de computadoras en tres lugares (por ejemplo: Shanghai/Hangzhou/Shenzhen), el retraso de la red entre Hangzhou y Shanghai es de aproximadamente 5 ms, y la distancia más lejana de Hangzhou/Shanghai a Shenzhen es de 30 ms. .
ilustrar:
a. Considere la comparación horizontal del rendimiento de cuatro escenarios de implementación. Tres centros en dos lugares y tres centros en tres lugares adoptan el modo de implementación de 3 copias. El negocio de producción real se puede extender al modo de implementación de 5 copias.
b Teniendo en cuenta las restricciones estrictas sobre RPO=0 cuando se utilizan productos de bases de datos de alta disponibilidad, MGR está configurado con RPO<>0 de forma predeterminada. Aquí, continuaremos agregando pruebas comparativas entre MGR RPO<>0 y RPO=0 en cada uno. escenario de despliegue.
- MGR_0 representa datos para el caso de MGR RPO = 0
- MGR_1 representa datos para el caso de MGR RPO <> 0
- DN representa los datos para el caso de DN RPO = 0
3.1.1. Misma sala de informática
| | | 1 | 4 | 16 | 64 | 256 |
| oltp_solo_lectura | Monseñor_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| Monseñor_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 |
| No. | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 |
| MGR_0 frente a MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% |
| Comparación de DN y MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% |
| DN contra MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% |
| oltp_lectura_escritura | Monseñor_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| Monseñor_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 |
| No. | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 |
| MGR_0 frente a MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% |
| Comparación de DN y MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% |
| DN contra MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% |
| oltp_solo_escritura | Monseñor_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| Monseñor_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 |
| No. | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 |
| MGR_0 frente a MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% |
| Comparación de DN y MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% |
| DN contra MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
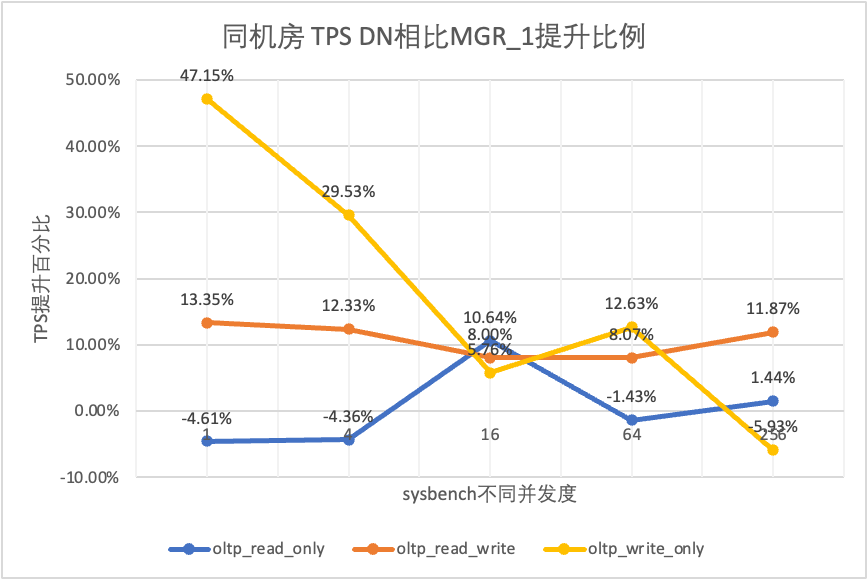
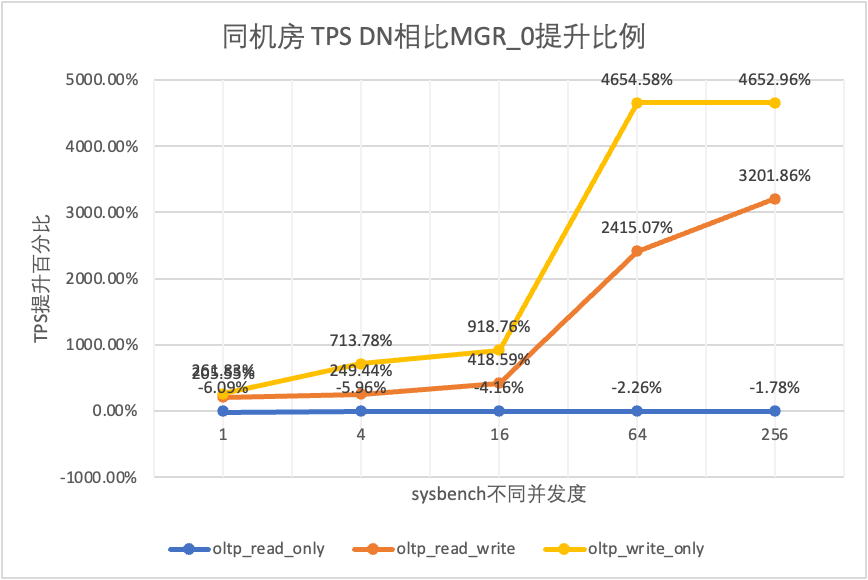
Se puede ver en los resultados de la prueba:
- En el escenario de solo lectura, ya sea comparando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la diferencia entre DN y MGR es estable entre -5% y 10%, lo que puede considerarse básicamente lo mismo. Si el RPO es igual a 0 no tiene ningún efecto en las transacciones de solo lectura
- En el escenario de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN (RPO = 0) mejora entre un 5% y un 47% en comparación con MGR_1 (RPO <>0), y la ventaja de rendimiento de DN es obvia cuando la concurrencia es baja y la ventaja cuando la concurrencia es alta Características no obvias. Esto se debe a que la eficiencia del protocolo de DN es mayor cuando la concurrencia es baja, pero los puntos críticos de rendimiento de DN y MGR en condiciones de alta concurrencia están todos en limpieza.
- Bajo la misma premisa de RPO = 0, en escenarios de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN mejora de 2 a 46 veces en comparación con MGR_0 y, a medida que aumenta la concurrencia, se mejora la ventaja de rendimiento de DN. No es de extrañar que MGR también abandone RPO=0 por motivos de rendimiento de forma predeterminada.
3.1.2. Tres centros en la misma ciudad
| Comparación de TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_solo_lectura | Monseñor_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| Monseñor_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 |
| No. | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 |
| MGR_0 frente a MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% |
| Comparación de DN y MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% |
| DN contra MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% |
| oltp_lectura_escritura | Monseñor_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| Monseñor_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 |
| No. | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 |
| MGR_0 frente a MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% |
| Comparación de DN y MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% |
| DN contra MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% |
| oltp_solo_escritura | Monseñor_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| Monseñor_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 |
| No. | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 |
| MGR_0 frente a MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% |
| Comparación de DN y MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% |
| DN contra MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Se puede ver en los resultados de la prueba:
- En el escenario de solo lectura, ya sea comparando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la diferencia entre DN y MGR es estable entre -7% y 5%, lo que puede considerarse básicamente lo mismo. Si el RPO es igual a 0 no tiene ningún efecto en las transacciones de solo lectura
- En un escenario de transacción mixta de lectura, escritura y solo escritura, el rendimiento de DN (RPO = 0) mejora entre un 30% y un 120% en comparación con MGR_1 (RPO <>0), y la ventaja de rendimiento de DN es obvia cuando hay concurrencia. es bajo y cuando la concurrencia es alta, el rendimiento es mejor. Funciones no obvias. Esto se debe a que la eficiencia del protocolo de DN es mayor cuando la concurrencia es baja, pero los puntos críticos de rendimiento de DN y MGR en condiciones de alta concurrencia están todos en limpieza.
- Bajo la misma premisa de RPO = 0, en escenarios de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN mejora de 1 a 14 veces en comparación con MGR_0 y, a medida que aumenta la concurrencia, se mejora la ventaja de rendimiento de DN. No es de extrañar que MGR también abandone RPO=0 por motivos de rendimiento de forma predeterminada.
3.1.3. Dos plazas y tres centros
| Comparación de TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_solo_lectura | Monseñor_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| Monseñor_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 |
| No. | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 |
| MGR_0 frente a MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% |
| Comparación de DN y MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% |
| DN contra MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% |
| oltp_lectura_escritura | Monseñor_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| Monseñor_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 |
| No. | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 |
| MGR_0 frente a MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% |
| Comparación de DN y MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% |
| DN contra MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% |
| oltp_solo_escritura | Monseñor_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| Monseñor_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 |
| No. | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 |
| MGR_0 frente a MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% |
| Comparación de DN y MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% |
| DN contra MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
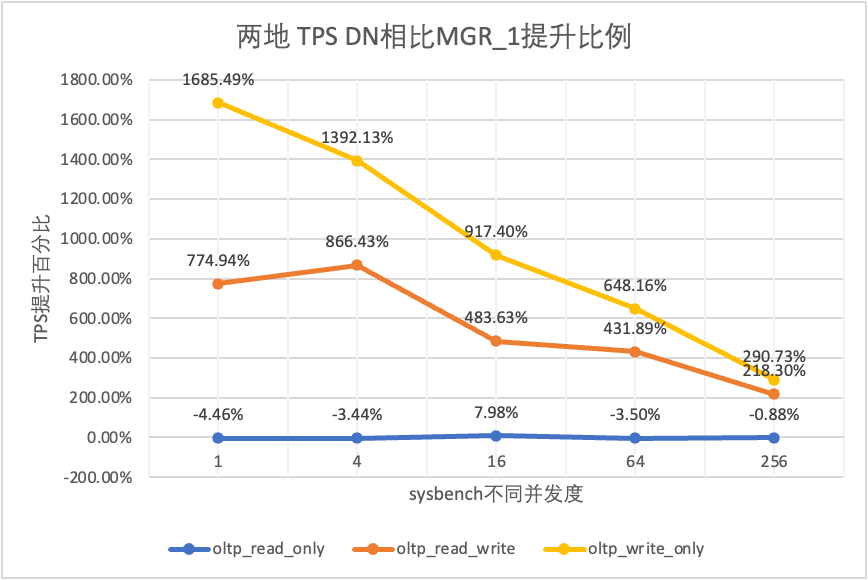
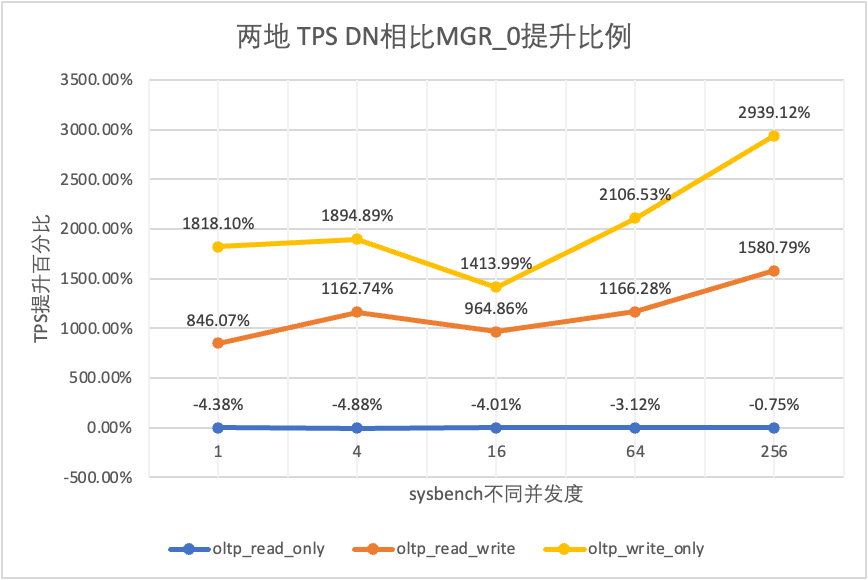
Se puede ver en los resultados de la prueba:
- En el escenario de solo lectura, ya sea comparando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la diferencia entre DN y MGR es estable entre -4% y 7%, lo que puede considerarse básicamente lo mismo. Si el RPO es igual a 0 no tiene ningún efecto en las transacciones de solo lectura
- En el escenario de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN (RPO = 0) mejora de 2 a 16 veces en comparación con MGR_1 (RPO <> 0), y la ventaja de rendimiento de DN es obvia cuando hay concurrencia. es bajo y la ventaja cuando la concurrencia es alta Características no obvias. Esto se debe a que la eficiencia del protocolo de DN es mayor cuando la concurrencia es baja, pero los puntos críticos de rendimiento de DN y MGR en condiciones de alta concurrencia están todos en limpieza.
- Bajo la misma premisa de RPO = 0, en escenarios de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN mejora de 8 a 29 veces en comparación con MGR_0 y, a medida que aumenta la concurrencia, se mejora la ventaja de rendimiento de DN. No es de extrañar que MGR también abandone RPO=0 por motivos de rendimiento de forma predeterminada.
3.1.4. Tres plazas y tres centros
| Comparación de TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_solo_lectura | Monseñor_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| Monseñor_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 |
| No. | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 |
| MGR_0 frente a MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% |
| Comparación de DN y MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% |
| DN contra MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% |
| oltp_lectura_escritura | Monseñor_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| Monseñor_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 |
| No. | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 |
| MGR_0 frente a MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% |
| Comparación de DN y MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% |
| DN contra MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% |
| oltp_solo_escritura | Monseñor_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| Monseñor_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 |
| No. | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 |
| MGR_0 frente a MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% |
| Comparación de DN y MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% |
| DN contra MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
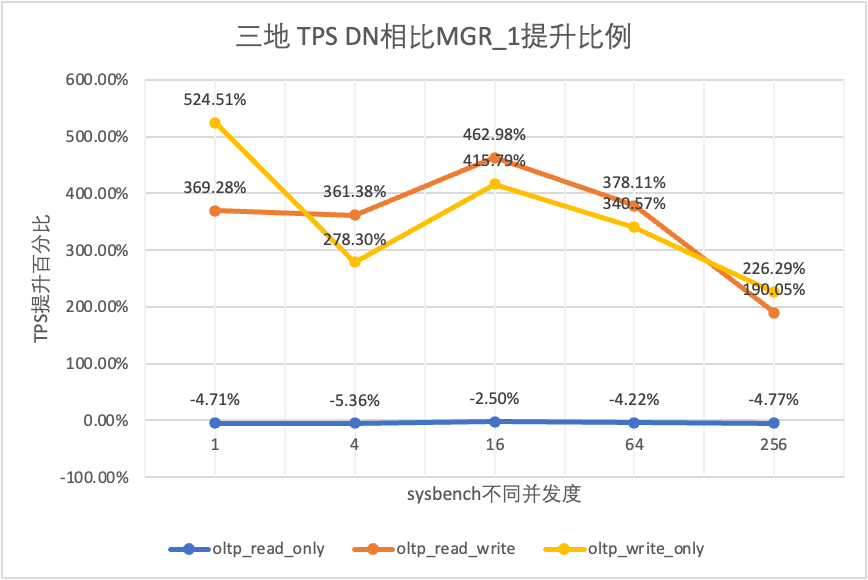
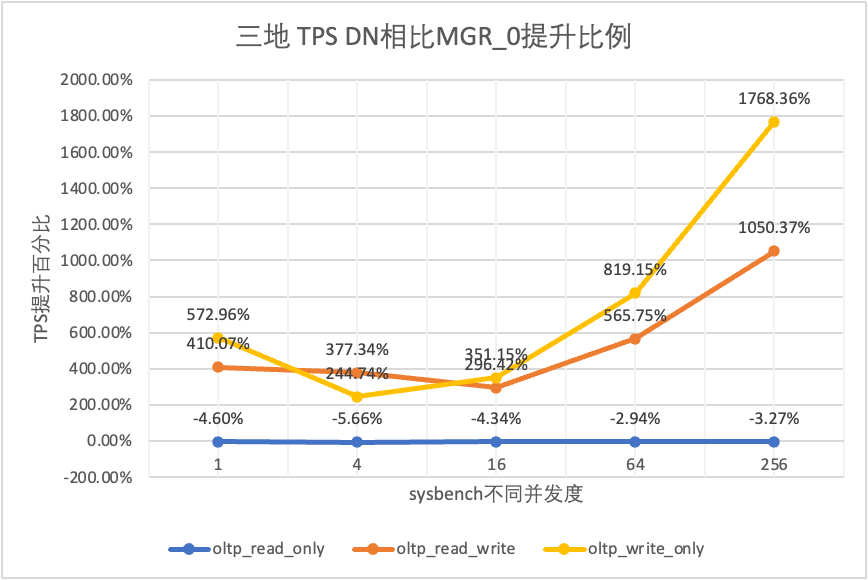
Se puede ver en los resultados de la prueba:
- En el escenario de solo lectura, ya sea comparando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la diferencia entre DN y MGR es estable entre -5% y 0%, lo que puede considerarse básicamente lo mismo. Si el RPO es igual a 0 no tiene ningún efecto en las transacciones de solo lectura
- En el escenario de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN (RPO = 0) mejora de 2 a 5 veces en comparación con MGR_1 (RPO <> 0), y la ventaja de rendimiento de DN es obvia cuando hay concurrencia. es bajo y la ventaja cuando la concurrencia es alta Características no obvias. Esto se debe a que la eficiencia del protocolo de DN es mayor cuando la concurrencia es baja, pero los puntos críticos de rendimiento de DN y MGR en condiciones de alta concurrencia están todos en limpieza.
- Bajo la misma premisa de RPO = 0, en escenarios de transacciones mixtas de lectura, escritura y solo escritura, el rendimiento de DN mejora de 2 a 17 veces en comparación con MGR_0 y, a medida que aumenta la concurrencia, se mejora la ventaja de rendimiento de DN. No es de extrañar que MGR también abandone RPO=0 por motivos de rendimiento de forma predeterminada.
3.1.5. Comparación de implementación
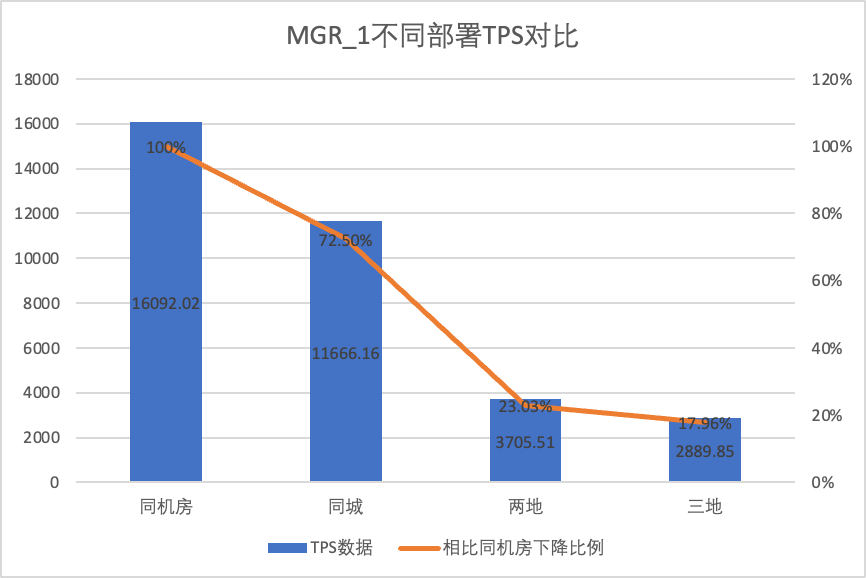
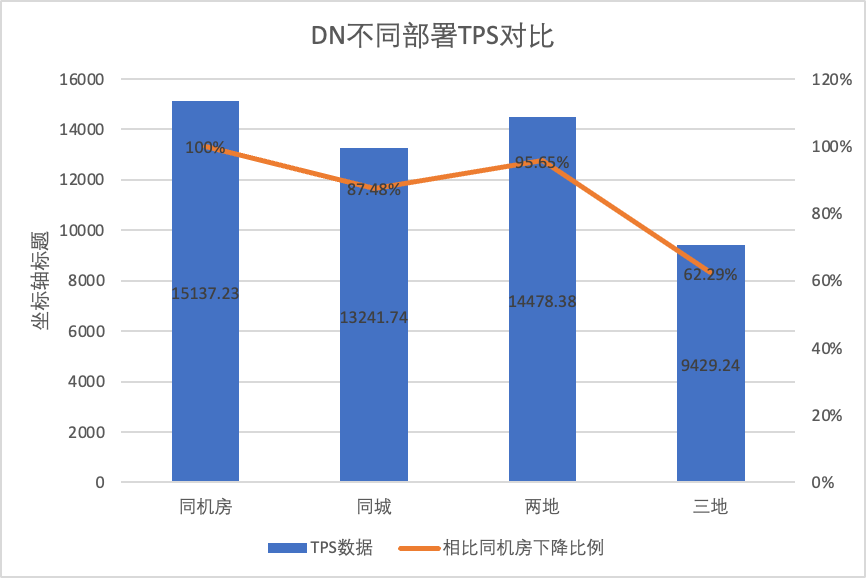
Para comparar claramente los cambios de rendimiento bajo diferentes métodos de implementación, seleccionamos los datos TPS de MGR y DN bajo diferentes métodos de implementación bajo el escenario oltp_write_only 256 concurrente en la prueba anterior. Utilizando los datos de prueba de la sala de computadoras como línea de base, calculamos y comparó los datos de TPS de diferentes métodos de implementación con la línea de base para percibir la diferencia en los cambios de rendimiento durante la implementación entre ciudades.
| | MGR_1 (256 simultáneos) | DN (256 simultáneos) | Ventajas de rendimiento de DN en comparación con MGR |
| Misma sala de ordenadores | 16092.02 | 15137.23 | -5.93% |
| Tres centros en la misma ciudad | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Dos plazas y tres centros | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Tres plazas y tres centros | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
Se puede ver en los resultados de la prueba:
- Con la expansión del método de implementación, el TPS de MGR_1 (RPO <>0) disminuyó significativamente en comparación con la implementación en la misma sala de computadoras, y el rendimiento de la implementación entre salas de computadoras en la misma ciudad disminuyó en un 27,5%. del despliegue entre ciudades (tres centros en dos lugares, tres centros en tres lugares) Una disminución del 77% al 82%, que se debe al aumento en el despliegue de RT entre ciudades.
- DN (RTO = 0) es relativamente estable en comparación con la implementación en la misma sala de computadoras, el rendimiento de la implementación de salas de computadoras cruzadas en la misma ciudad y la implementación de tres centros en dos lugares cayó entre un 4% y un 12%. El rendimiento del despliegue de tres centros en tres lugares cayó un 37% en condiciones de alta latencia de la red. Esto también se debe al mayor despliegue de RT en las ciudades.Sin embargo, gracias al mecanismo Batch&Pipeline de DN, el impacto entre ciudades se puede resolver aumentando la concurrencia. Por ejemplo, bajo la arquitectura de tres lugares y tres centros, con> = 512 concurrencia, el rendimiento del rendimiento en la misma ciudad y dos. Los lugares y tres centros se pueden alinear básicamente.
- Se puede ver que la implementación entre ciudades tiene un gran impacto en MGR_1 (RPO <>0)
3.1.6. Fluctuación del rendimiento
En el uso real, no solo prestamos atención a los datos de rendimiento, sino que también debemos prestar atención a la fluctuación del rendimiento. Después de todo, si la inquietud es como una montaña rusa, la experiencia real del usuario será muy pobre. Monitoreamos y mostramos datos de salida de TPS en tiempo real. Teniendo en cuenta que la herramienta sysbenc en sí no admite datos de monitoreo de salida de fluctuación de rendimiento, utilizamos el coeficiente de variación matemático como indicador de comparación:
- Coeficiente de variación (CV): el coeficiente de variación es la desviación estándar dividida por la media. Generalmente se usa para comparar las fluctuaciones de diferentes conjuntos de datos, especialmente cuando las diferencias de medias son grandes. Cuanto mayor sea el CV, mayor será la fluctuación de los datos en relación con la media.
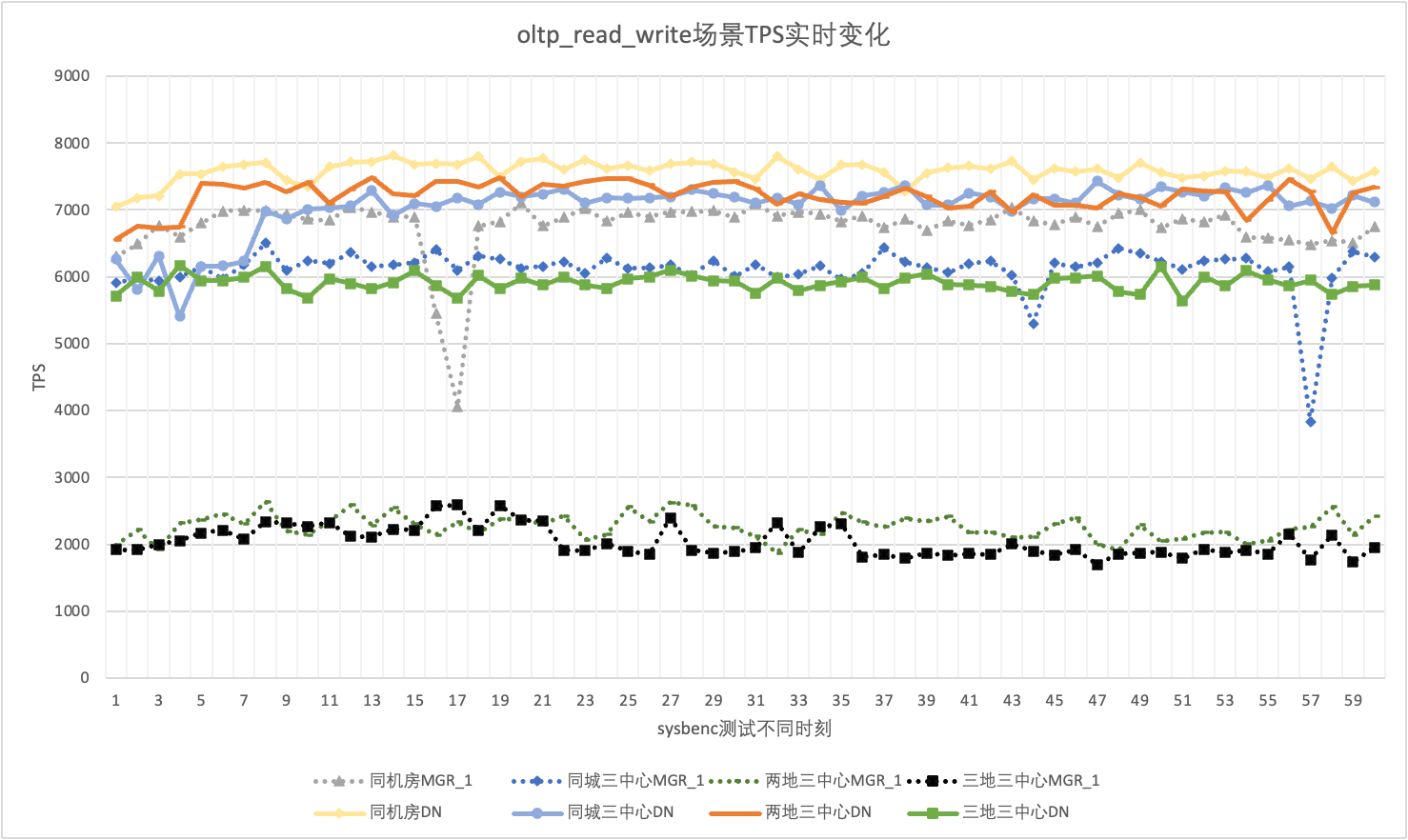
Tomando como ejemplo el escenario de 256 oltp_read_write concurrentes, analizamos estadísticamente el TPS de MGR_1 (RPO <> 0) y DN (RPO = 0) en la misma sala de computadoras, tres centros en la misma ciudad, tres centros en dos lugares y Tres centros en tres lugares. Situación de inquietud. El gráfico de fluctuación real es el siguiente y los datos reales del indicador de fluctuación para cada escenario son los siguientes:
| CV | Misma sala de ordenadores | Tres centros en la misma ciudad | Dos plazas y tres centros | Tres plazas y tres centros |
| Monseñor_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| No. | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
Se puede ver en los resultados de la prueba:
- El TPS de MGR está en un estado inestable en el escenario oltp_read_write y de repente cae bruscamente sin ningún motivo. Este fenómeno se ha encontrado en múltiples pruebas en múltiples escenarios de implementación. En comparación, DN es muy estable.
- Calculando el coeficiente de variación CV, el CV de MGR es muy grande, del 6% al 10%, e incluso alcanza el valor máximo del 10% cuando el retraso en la misma sala de ordenadores es mínimo, mientras que el CV de DN es relativamente estable, del 2% al 4. %, y el rendimiento de DN es más estable que el de MGR. Sex es básicamente el doble.
- Se puede ver que la fluctuación de rendimiento de MGR_1 (RPO <>0) es relativamente grande
3.2. RTO
La característica principal de una base de datos distribuida es la alta disponibilidad. La falla de cualquier nodo en el clúster no afectará la disponibilidad general. Para la forma de implementación típica de 3 nodos con un maestro y dos respaldos implementados en la misma sala de computadoras, intentamos realizar pruebas de usabilidad en los siguientes tres escenarios:
- Interrumpa la base de datos principal, luego reiníciela y observe el tiempo de RTO para que el clúster restablezca la disponibilidad durante el proceso.
- Interrumpa cualquier base de datos en espera y luego reiníciela para observar el rendimiento de disponibilidad de la base de datos primaria durante el proceso.
3.2.1. Tiempo de inactividad de la base de datos principal + reinicio.
Cuando no haya carga, elimine al líder y supervise los cambios de estado de cada nodo en el clúster y si se puede escribir.
| | MONSEÑOR | No. |
| Comenzando normalmente | 0 | 0 |
| matar al líder | 0 | 0 |
| Tiempo de nodo anormal encontrado | 5 | 5 |
| Es hora de reducir 3 nodos a 2 nodos | 23 | 8 |
| | MONSEÑOR | No. |
| Comenzando normalmente | 0 | 0 |
| matar al líder, levantarse automáticamente | 0 | 0 |
| Tiempo de nodo anormal encontrado | 5 | 5 |
| Es hora de reducir 3 nodos a 2 nodos | 23 | 8 |
| Restauración de 2 nodos Tiempo de 3 nodos | 37 | 15 |

Se puede ver en los resultados de la prueba que bajo condiciones sin presión:
- El RTO de DN es de 8 a 15 segundos, se necesitan 8 segundos para reducirlo a 2 nodos y 15 segundos para restaurar 3 nodos;
- El RTO de MGR es de 23 a 37 segundos. Se necesitan 23 segundos para bajar a 2 nodos y 37 segundos para restaurar 3 nodos.
- El rendimiento de RTO DN es en general mejor que MGR
3.2.2. Tiempo de inactividad de la base de datos en espera + reinicio.
Utilice sysbench para realizar una prueba de esfuerzo concurrente de 16 subprocesos en el escenario oltp_read_write. En el décimo segundo de la figura, elimine manualmente un nodo en espera y observe los datos TPS de salida en tiempo real de sysbench.
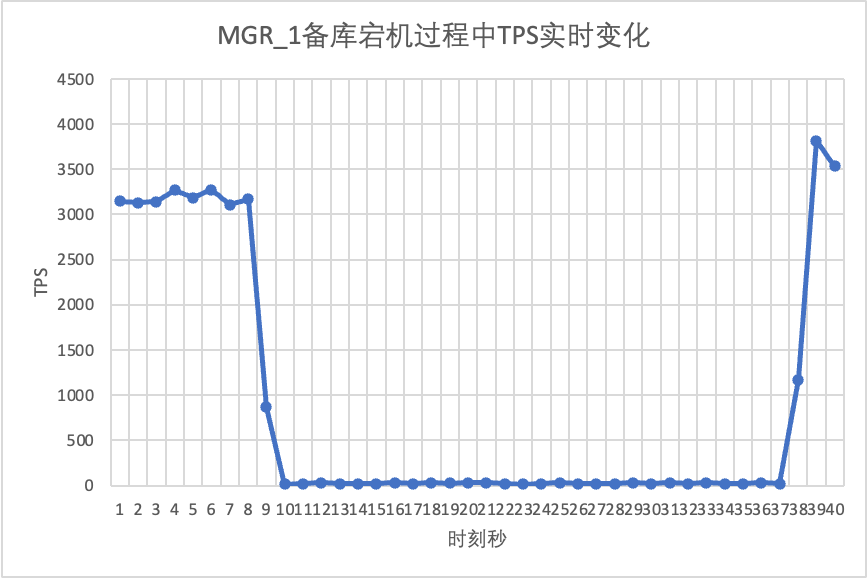


Se puede ver en el cuadro de resultados de la prueba:
- Después de que se interrumpió la base de datos en espera, el TPS de la base de datos principal de MGR disminuyó significativamente y duró unos 20 segundos antes de volver a los niveles normales. Según el análisis de registros, aquí hay dos procesos: detectar que el nodo defectuoso se ha vuelto inalcanzable y expulsar el nodo defectuoso del clúster MGR. Esta prueba confirmó una falla que ha estado circulando en la comunidad MGR durante mucho tiempo. Incluso si solo 1 nodo entre 3 no está disponible,Todo el grupo experimentó graves nerviosismo durante un período de tiempo y dejó de estar disponible.
- Para resolver el problema de que MGR de un solo maestro tenga una falla de un solo nodo y toda la instancia no esté disponible, la comunidad introdujo la función de líder único de MGR paxos desde 8.0.27 para resolver el problema, pero está desactivada de manera predeterminada. Aquí activamos group_replication_paxos_single_leader y continuamos verificando. Después de interrumpir la base de datos en espera esta vez, el rendimiento de la base de datos principal permanece estable y ha mejorado ligeramente. El motivo debería estar relacionado con la reducción de la carga de la red.
- Para DN, después de que se interrumpió la base de datos en espera, el TPS de la base de datos principal aumentó inmediatamente en aproximadamente un 20% y luego permaneció estable y el clúster siempre estuvo disponible.Esto es lo opuesto a MGR. La razón es que después de interrumpir una base de datos en espera, la base de datos principal solo necesita enviar registros a la base de datos en espera restante cada vez, y el proceso de envío y recepción de paquetes de red es más eficiente.
Continuando con la prueba, reiniciamos y restauramos la base de datos en espera y observamos los cambios en los datos TPS de la base de datos principal.
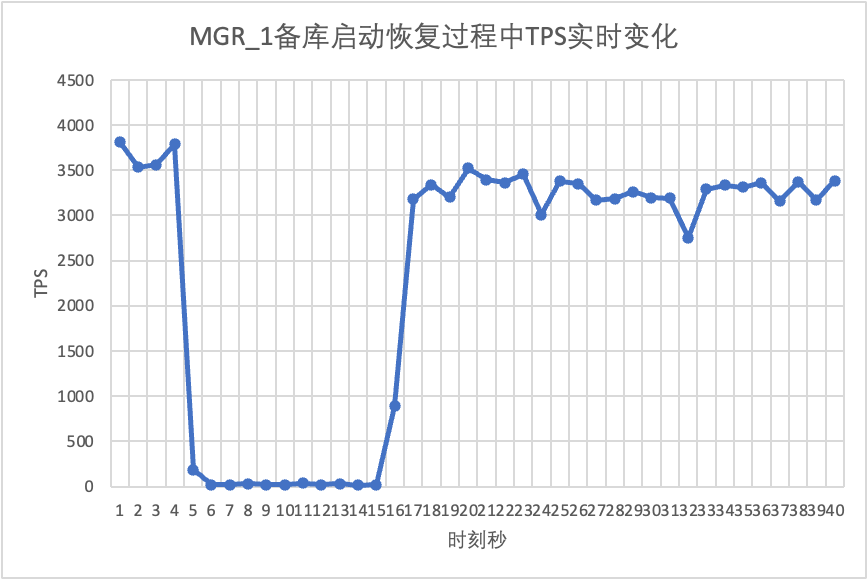
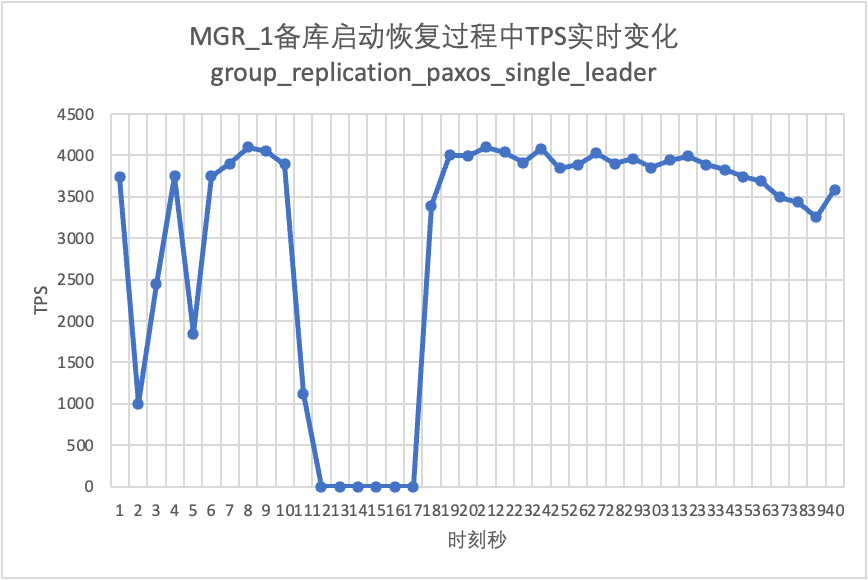
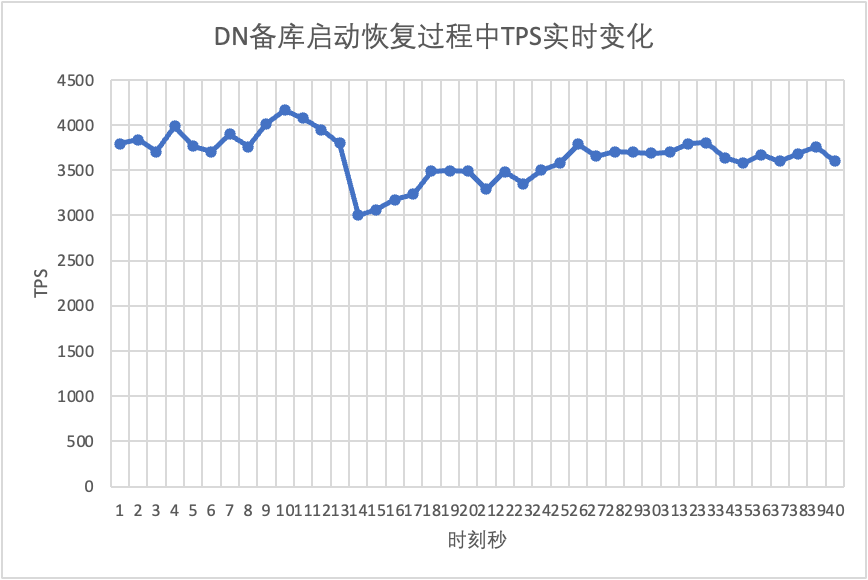
Se puede ver en el cuadro de resultados de la prueba:
- MGR se recuperó de 2 nodos a 3 nodos en 5 segundos.Pero también existe una situación en la que la biblioteca principal no está disponible, lo que dura unos 12 segundos.Aunque el nodo en espera finalmente se unió al clúster, el estado MEMBER_STATE siempre ha sido RECUPERANDO, lo que indica que se están buscando datos en este momento.
- En el escenario después de habilitar group_replication_paxos_single_leader, el reinicio de la base de datos en espera también se verifica. Como resultado, MGR se recupera de 2 nodos a 3 nodos en 10 segundos.Pero todavía hubo un tiempo no disponible que duró unos 7 segundos.Parece que este parámetro no puede resolver completamente el problema de que el MGR de un solo maestro tenga una falla en un solo nodo y toda la instancia no esté disponible.
- Para DN, la base de datos en espera se recupera de 2 a 3 nodos en 10 segundos y la base de datos principal permanece disponible. Aquí habrá fluctuaciones a corto plazo en TPS. Esto se debe a que el retraso en la replicación de registros de la base de datos en espera reiniciada está retrasado y los registros retrasados deben extraerse de la base de datos principal. base de datos principal Después de la revisión del registro, el rendimiento general será estable.
3.3. RPO
Para construir el escenario de falla mayoritaria de MGR RPO <> 0, utilizamos el método de caso MTR propio de la comunidad para realizar pruebas de inyección de fallas en MGR. El caso diseñado es el siguiente:
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo ############################################################
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record

loose-group_replication_member_weight=100
loose-group_replication_member_weight=90
loose-group_replication_member_weight=80
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socket
Los resultados de la ejecución del caso son los siguientes:
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
include/start_and_bootstrap_group_replication.inc
include/start_group_replication.inc
include/start_group_replication.inc
############################################################
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
INSERT INTO t1 VALUES(2);
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
La lógica aproximada de un caso que reproduce números faltantes es la siguiente:
- MGR consta de 3 nodos en modo maestro único, Servidor 1/2/3, donde el Servidor 1 es la base de datos principal e inicializa 1 registro c1=1
- El servidor 2/3 de inyección de fallas se bloqueará al escribir el registro de retransmisión
- Se conectó al nodo del Servidor 1, escribió el registro de c1 = 2 y la confirmación de la transacción también fue exitosa.
- Luego, el servidor simulado 1 falla de manera anormal (falla de la máquina, no se puede restaurar y no se puede acceder a él). En este momento, el servidor 2/3 queda como mayoría.
- Reinicie el Servidor 2/3 normalmente (recuperación rápida), pero el Servidor 2/3 no puede restaurar el clúster a un estado utilizable.
- Conéctese al nodo del Servidor 2/3 y consulte los registros de la base de datos. Solo se ve el registro de c1=1 (el Servidor 2/3 ha perdido c1=2).
Según el caso anterior, para MGR, cuando la mayoría de los servidores están inactivos y la base de datos principal no está disponible, después de restaurar la base de datos en espera, habrá una pérdida de datos de RPO<>0 y el registro de confirmación exitosa que fue originalmente devuelto al cliente se pierde.
Para DN, lograr la mayoría requiere que los registros persistan en la mayoría, por lo que incluso en el escenario anterior, los datos no se perderán y se puede garantizar RPO=0.
3.4. Retraso en la reproducción de la base de datos en espera
En el modo tradicional activo-en espera de MySQL, la base de datos en espera generalmente contiene subprocesos IO y subprocesos de aplicación. Después de la introducción del protocolo Paxos, el subproceso IO sincroniza el binlog de las bases de datos activas y en espera principalmente. Depende de la sobrecarga de Aplicar la reproducción de la base de datos en espera. Aquí nos convertimos en el retraso de reproducción de la base de datos en espera.
Usamos sysbench para probar el escenario oltp_write_only y probar la duración del retraso en la reproducción de la base de datos en espera con 100 concurrencias y un número diferente de eventos.El tiempo de retraso de reproducción de la base de datos en espera se puede determinar monitoreando la columna APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP de la tabla performance_schema.replication_applier_status_by_worker para ver si cada trabajador está trabajando en tiempo real para determinar si la replicación ha finalizado.

Se puede ver en el cuadro de resultados de la prueba:
- Con la misma cantidad de datos escritos, el tiempo de finalización de la reproducción de todos los registros de la base de datos en espera de DN es mucho mejor que el consumo de tiempo de MGR, que es solo del 3% al 4% del de MGR. Esto es fundamental para la puntualidad del cambio activo/en espera.
- A medida que aumenta el número de escrituras, la ventaja de latencia de reproducción de la base de datos en espera de DN sobre MGR continúa manteniéndose y es muy estable.
- Al analizar los motivos del retraso en la reproducción de la base de datos en espera, la estrategia de reproducción de la base de datos en espera de MGR adopta group_replication_consistency con el valor predeterminado de EVENTUAL, es decir, las transacciones RO y RW no esperan la aplicación de transacciones anteriores antes de la ejecución. Esto puede garantizar el máximo rendimiento de escritura de la base de datos principal, pero el retraso de la base de datos en espera será relativamente grande (al sacrificar el retraso de la base de datos en espera y RPO = 0 a cambio de la escritura de alto rendimiento de la base de datos principal, active la función de limitación actual de MGR puede equilibrar el rendimiento y la base de datos en espera se retrasa, pero el rendimiento de la base de datos principal se verá comprometido)
3.5. Resumen de la prueba
| | MONSEÑOR | No. |
| actuación | Leer transacción | departamento | departamento |
| escribir transacción | El rendimiento no es tan bueno como el de DN cuando RPO <> 0 Cuando RPO = 0, el rendimiento es muy inferior al de DN El rendimiento de la implementación entre ciudades cayó seriamente entre un 27% y un 82% | El rendimiento de las transacciones de escritura es mucho mayor que el de MGR El rendimiento de la implementación entre ciudades disminuye entre un 4% y un 37%. |
| Estar nervioso | La fluctuación del rendimiento es grave, el rango de fluctuación es del 6 al 10 % | Relativamente estable en 3%, sólo la mitad de MGR |
| RTO | La base de datos principal está caída | La anomalía se descubrió en 5 segundos y se redujo a dos nodos en 23 segundos. | La anomalía se descubrió en 5 segundos y se redujo a dos nodos en 8 segundos. |
| Reiniciar la biblioteca principal | Se descubrió una anomalía en 5 segundos y se restauraron tres nodos en 37 segundos. | Se detecta una anomalía en 5 segundos y se restauran tres nodos en 15 segundos. |
| Tiempo de inactividad de la base de datos de respaldo | El tráfico de la base de datos principal cayó a 0 durante 20 segundos. Se puede aliviar activando explícitamente group_replication_paxos_single_leader. | Alta disponibilidad continua de la base de datos principal. |
| Reinicio de la base de datos en espera | El tráfico de la base de datos principal cayó a 0 durante 10 segundos. Activar explícitamente group_replication_paxos_single_leader tampoco tiene ningún efecto. | Alta disponibilidad continua de la base de datos principal. |
| OPR | Recurrencia del caso | RPO<>0 cuando el partido mayoritario cae Performance y RPO=0 no pueden tener ambos. | OPR = 0 |
| Retraso de la base de datos en espera | Tiempo de reproducción de la base de datos de respaldo | El retraso entre activo y en espera es muy grande. El rendimiento y la latencia de la copia de seguridad primaria no se pueden lograr al mismo tiempo. | El tiempo total dedicado a la reproducción general de la base de datos en espera es el 4% de MGR, que es 25 veces mayor que el de MGR. |
| parámetro | parámetro clave |
- El control de flujo group_replication_flow_control_mode está habilitado de forma predeterminada y debe configurarse para desactivarlo y mejorar el rendimiento.
- replication_optimize_for_static_plugin_config La optimización del complemento estático está desactivada de forma predeterminada y debe activarse para mejorar el rendimiento.
- group_replication_paxos_single_leader está desactivado de forma predeterminada y debe activarse para mejorar la estabilidad de la base de datos principal cuando la base de datos en espera está inactiva.
- group_replication_consistency está desactivado de forma predeterminada y no garantiza RPO=0. Si se requiere RPO=0, es necesario configurar DESPUÉS.
- El límite_tamaño_de_transacción_de_replicación_de_grupo predeterminado es 143 M, que debe aumentarse cuando se encuentran transacciones grandes.
- binlog_transaction_dependency_tracking tiene como valor predeterminado COMMIT_ORDER. Es necesario ajustar MGR a WRITESET para mejorar el rendimiento de reproducción de la base de datos en espera.
| Configuración predeterminada, no es necesario que los profesionales personalicen la configuración |
4. Resumen
Después de un análisis técnico en profundidad y una comparación de rendimiento,PolarDB-X Con su protocolo X-Paxos de desarrollo propio y una serie de diseños optimizados, DN ha demostrado muchas ventajas sobre MySQL MGR en términos de rendimiento, corrección, disponibilidad y sobrecarga de recursos. Sin embargo, MGR también ocupa una posición importante en el ecosistema MySQL. , se deben considerar diversas situaciones, como la fluctuación de la interrupción de la base de datos en espera, las fluctuaciones del rendimiento de la recuperación ante desastres entre salas de máquinas y la estabilidad. Por lo tanto, si desea hacer un buen uso de MGR, debe estar equipado con un equipo técnico y de operación y mantenimiento profesional. apoyo.
Cuando se enfrenta a requisitos de gran escala, alta concurrencia y alta disponibilidad, el motor de almacenamiento PolarDB-X tiene ventajas técnicas únicas y un rendimiento excelente en comparación con MGR en escenarios listos para usar.PolarDB-XLa centralizada basada en DN (versión estándar) tiene un buen equilibrio entre funciones y rendimiento, lo que la convierte en una solución de base de datos altamente competitiva.

