
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
우리 모두 알고 있듯이 MySQL 기본 및 보조 데이터베이스(2개 노드)는 일반적으로 비동기 복제 및 반동기 복제(Semi-Sync)를 통해 높은 데이터 가용성을 달성합니다. 그러나 컴퓨터실 네트워크 장애 및 호스트 중단과 같은 비정상적인 시나리오에서는 기본 및 보조 아키텍처는 HA 전환 후 심각한 문제에 직면하게 됩니다(RPO!=0이라고 함).따라서 비즈니스 데이터가 어느 정도 중요한 경우에는 MySQL 기본 및 보조 아키텍처(노드 2개)를 사용하는 데이터베이스 제품을 선택하지 않는 것이 좋습니다. RPO=0인 다중 복사 아키텍처를 선택하는 것이 좋습니다.
RPO=0을 사용한 다중 복사 기술의 발전에 관한 MySQL 커뮤니티:
폴라DB-X 중앙집중형 및 분산형 통합의 개념: 데이터 노드 DN은 독립형 데이터베이스 형식과 완벽하게 호환되는 중앙집중형(표준 버전) 형식으로 독립적으로 사용될 수 있습니다. 분산 확장이 필요할 정도로 비즈니스가 성장하면 아키텍처가 분산 형태로 업그레이드되고 분산 구성 요소가 원본 데이터 노드에 원활하게 연결됩니다. 애플리케이션 측에서 데이터 마이그레이션이나 수정이 필요하지 않습니다. , 이 공식, 아키텍처 설명이 제공하는 유용성과 확장성을 누릴 수 있습니다."중앙 집중식 분산 통합"
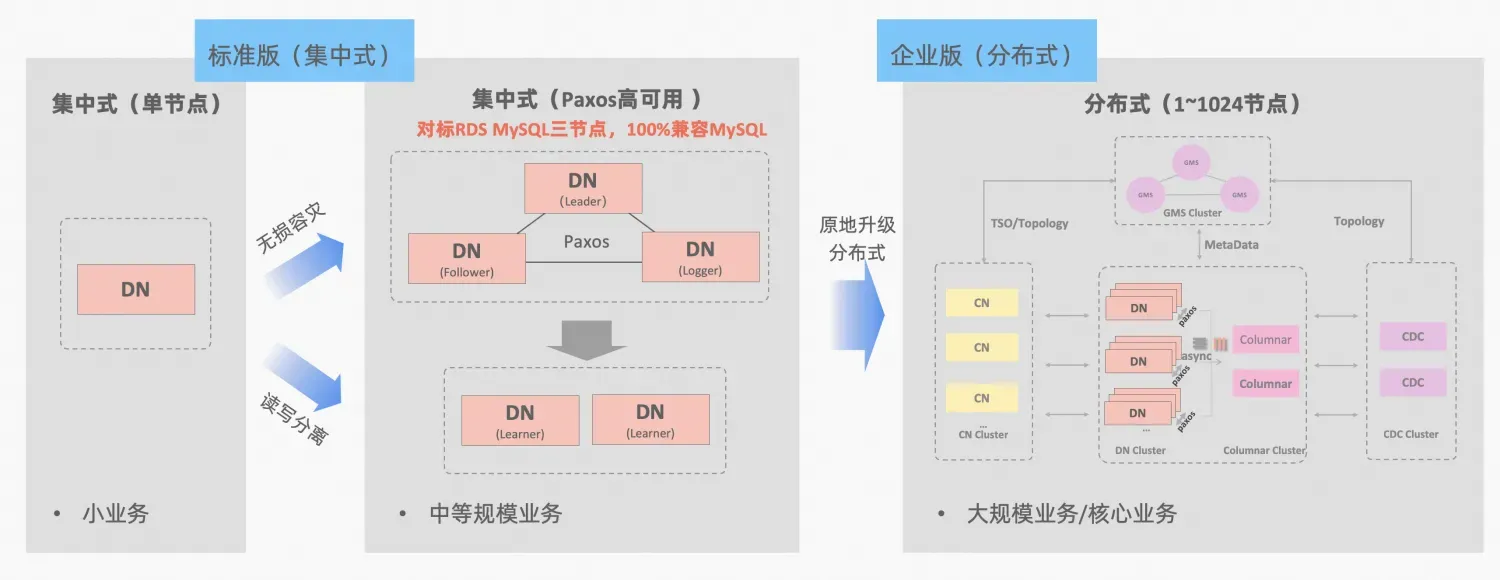
MySQL의 MGR과 PolarDB-X의 표준 버전 DN은 모두 가장 낮은 원칙의 Paxos 프로토콜을 사용합니다. 그렇다면 실제 사용 시 구체적인 성능과 차이점은 무엇입니까? 이 문서에서는 아키텍처 비교, 주요 차이점 및 테스트 비교 측면을 자세히 설명합니다.
MGR/DN 약어 설명: MGR은 MySQL MGR의 기술 형식을 나타내고, DN은 PolarDB-X 단일 DN 중앙 집중식(표준 버전)의 기술 형식을 나타냅니다.
자세한 비교분석은 비교적 길기 때문에 요약과 결론을 먼저 읽어보시고 관심이 있으신 분들은 요약을 따라가며 이어지는 글에서 단서를 찾아보시면 됩니다.
MySQL MGR을 잘 사용하려면 전문적인 기술 지식과 운영 및 유지 관리 팀이 필요하기 때문에 일반 비즈니스 및 기업에는 권장되지 않습니다. 또한 이 기사에서는 오랫동안 업계에 유통되어 온 MySQL MGR의 세 가지 "숨겨진 함정"을 재현합니다. :
MySQL MGR과 비교할 때 PolarDB-X Paxos는 데이터 일관성, 컴퓨터실 간 재해 복구, 노드 운영 및 유지 관리 측면에서 MGR과 유사한 함정이 없지만 재해 복구에는 몇 가지 사소한 단점과 장점도 있습니다.
MGR/DN 약어 설명:
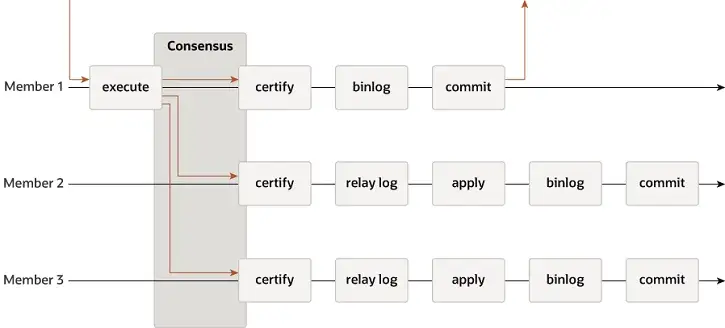
MGR은 단일 마스터 및 다중 마스터 모드를 지원하고 이벤트, Binlog 및 Relaylog, Apply, Binlog Apply Recovery 및 GTID를 포함한 MySQL의 복제 시스템을 완전히 재사용합니다. DN과의 주요 차이점은 MGR 트랜잭션 로그 대다수가 합의에 도달하기 위한 진입점이 기본 데이터베이스 트랜잭션이 커밋되기 전이라는 점입니다.
MGR이 위와 같은 프로세스를 채택하는 이유는 MGR이 기본적으로 다중 마스터 모드이고 각 노드가 쓰기가 가능하기 때문이다. 따라서 단일 Paxos 그룹의 Follower 노드는 수신된 로그를 먼저 RelayLog로 변환한 후 결합해야 한다. 제출할 리더로 받은 쓰기 트랜잭션과 함께 Binlog 파일이 생성되어 2단계 그룹 제출 프로세스에서 최종 트랜잭션을 제출합니다.
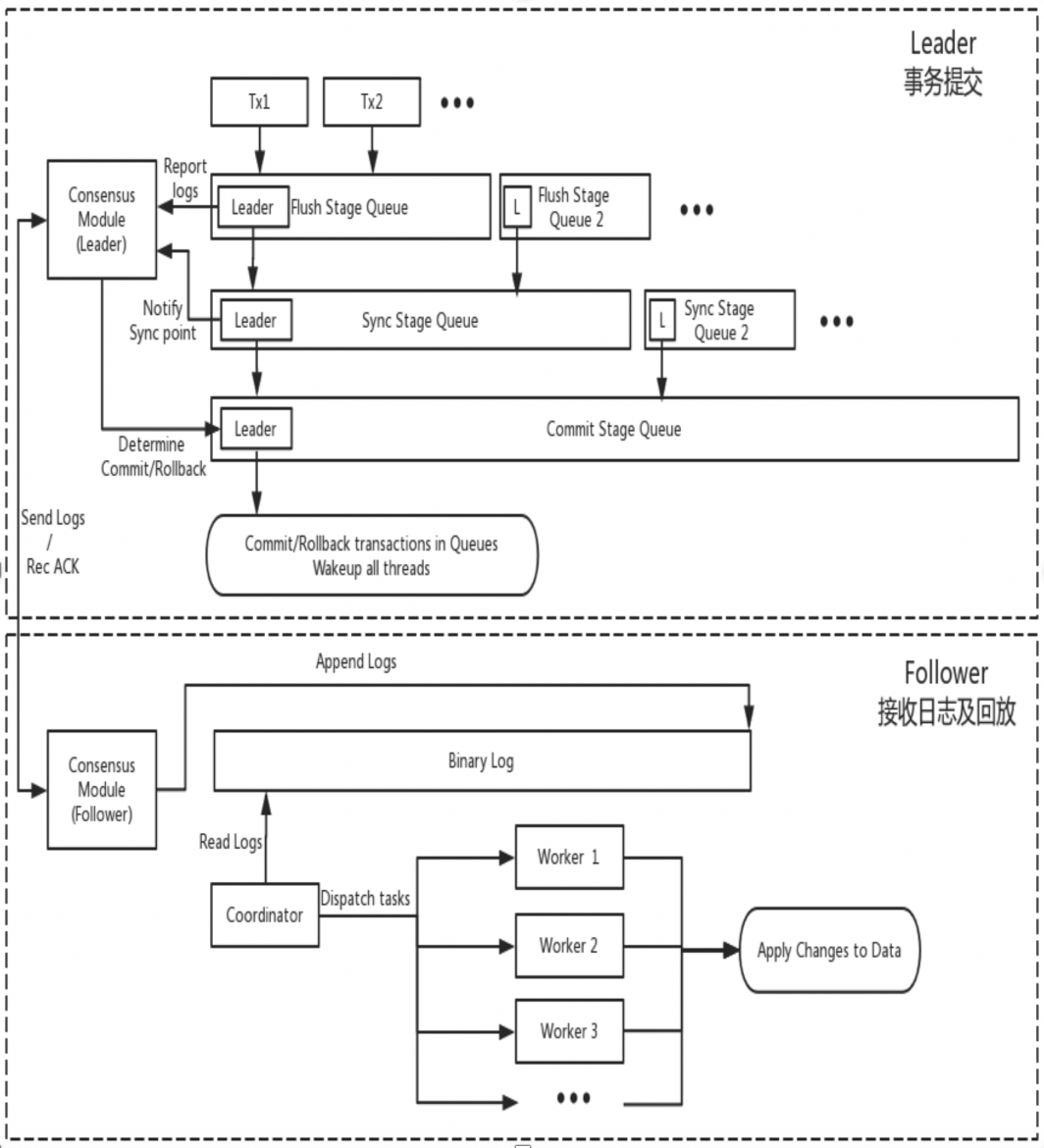
DN은 MySQL의 기본 데이터 구조와 기능 수준 코드를 재사용하지만 로그 복제, 로그 관리, 로그 재생 및 크래시 복구를 X-Paxos 프로토콜과 긴밀하게 통합하여 고유한 다수 복제 및 상태 머신 메커니즘 세트를 형성합니다. MGR과의 주요 차이점은 DN 트랜잭션 로그 대다수가 합의에 도달하기 위한 진입점이 기본 데이터베이스 트랜잭션 제출 프로세스 중에 있다는 것입니다.
이렇게 설계한 이유는 DN이 현재 단일 마스터 모드만 지원하므로 X-Paxos 프로토콜 수준의 로그는 Binlog 자체이기 때문입니다. Follower도 Relay Log와 영구 로그 및 리더 로그의 데이터 내용을 생략합니다. 가격은 동일합니다.

관리자

디엔에이
이론적으로는 Paxos와 Raft 모두 데이터 일관성을 보장할 수 있으며 Crash Recovery 이후 다수에 도달한 로그는 손실되지 않지만 특정 프로젝트에서는 여전히 차이가 있습니다.
관리자
XCOM은 Paxos 프로토콜을 완전히 캡슐화하며 모든 프로토콜 데이터는 먼저 메모리에 캐시됩니다. 기본적으로 다수에 도달하는 트랜잭션에는 로그 지속성이 필요하지 않습니다. 대부분의 파이가 다운되고 리더가 실패하는 경우 RPO != 0이라는 심각한 문제가 발생하게 됩니다.극단적인 시나리오를 가정해 보겠습니다.
커뮤니티의 기본 매개변수 하에서 대부분의 트랜잭션은 로그 지속성을 요구하지 않으며 RPO=0을 보장하지 않습니다. 이는 XCOM 프로젝트 구현 시 성능에 대한 절충으로 간주될 수 있습니다. 절대 RPO=0을 보장하려면 AFTER에 대한 읽기 및 쓰기 일관성을 제어하는 group_replication_consistency 매개변수를 구성해야 합니다. 그러나 이 경우 1.5 RTT 네트워크 오버헤드 외에도 트랜잭션에 과반수에 도달하려면 로그 IO 오버헤드가 필요합니다. 성능이 매우 저하됩니다.
디엔에이
PolarDB-X DN은 X-Paxos를 사용하여 분산 프로토콜을 구현하며 MySQL의 그룹 커밋 프로세스에 깊이 바인딩되어 있습니다. 트랜잭션이 제출되면 실제 제출이 허용되기 전에 대다수가 배치 및 지속성을 확인해야 합니다. 여기서 디스크 배치의 대부분은 기본 라이브러리의 Binlog 배치를 참조합니다. 대기 라이브러리의 IO 스레드는 기본 라이브러리의 로그를 수신하여 지속성을 위해 자체 Binlog에 씁니다. 따라서 극단적인 시나리오에서 모든 노드가 실패하더라도 데이터가 손실되지 않으며 RPO=0을 보장할 수 있습니다.
RTO 시간은 시스템 자체의 콜드 재시작 시간 오버헤드와 밀접하게 관련되어 있으며 이는 특정 기본 기능에 반영됩니다.오류 감지 메커니즘->충돌 복구 메커니즘->마스터 선택 메커니즘->로그 밸런싱
관리자
디엔에이
관리자
디엔에이
단일 마스터 모드에서 MGR의 XCOM과 강력한 리더 모드인 DN X-Paxos는 리더 선택에 대해 동일한 기본 원칙을 따릅니다. 즉, 클러스터에서 합의한 로그는 롤백할 수 없습니다. 하지만 합의되지 않은 로그의 경우에는 차이가 있습니다.
관리자
디엔에이
로그 평준화는 기본 데이터베이스와 보조 데이터베이스 간의 로그에 로그 복제 지연이 있으며, 보조 데이터베이스가 로그를 평준화해야 함을 의미합니다. 재시작 및 복구되는 노드의 경우 대개 스탠바이 데이터베이스를 이용하여 복구를 시작하는데, 메인 데이터베이스에 비해 이미 로그 복제 지연이 발생하여 메인 데이터베이스로 로그를 잡아야 한다. 리더로부터 물리적으로 멀리 떨어져 있는 노드의 경우 다수에 도달하는 것은 일반적으로 복제 로그 지연이 있으며 항상 로그를 따라잡습니다. 이러한 상황에서는 로그 복제 지연을 적시에 해결할 수 있도록 특정 엔지니어링 구현이 필요합니다.
관리자
디엔에이
대기 데이터베이스 재생 지연은 기본 데이터베이스에서 동일한 트랜잭션이 완료되는 시점과 대기 데이터베이스에서 해당 트랜잭션이 적용되는 시점 사이의 지연을 의미합니다. 여기서 테스트하는 것은 대기 데이터베이스 적용 애플리케이션 로그의 성능입니다. 이는 예외가 발생할 때 대기 데이터베이스가 데이터 애플리케이션을 완료하고 읽기 및 쓰기 서비스를 제공하는 데 걸리는 시간에 영향을 줍니다.
관리자
디엔에이
대규모 트랜잭션은 일반 트랜잭션의 제출에 영향을 미칠 뿐만 아니라 분산 시스템의 전체 분산 프로토콜의 안정성에도 영향을 미칩니다. 심각한 경우 대규모 트랜잭션으로 인해 전체 클러스터를 오랫동안 사용할 수 없게 됩니다.
관리자
디엔에이
관리자
디엔에이

| 관리자 | 디엔에이 | ||
| 프로토콜 효율성 | 거래 제출 시간 | 1.5~2.5 회 | 1RTT |
| 다수의 지속성 | XCOM 메모리 저장 | Binlog 지속성 | |
| 신뢰할 수 있음 | RPO=0 | 기본적으로 보장되지 않음 | 완전 보장 |
| 결함 감지 | 모든 노드가 서로를 확인하고 네트워크 부하가 높음 하트비트 주기를 조정할 수 없습니다. | 마스터 노드는 주기적으로 다른 노드를 확인합니다. 하트비트 주기 매개변수는 조정 가능합니다. | |
| 대다수 붕괴 복구 | 수동 개입 | 자동 복구 | |
| 소수 충돌 복구 | 대부분의 경우 자동 복구, 특수 상황에서는 수동 개입 | 자동 복구 | |
| 마스터를 선택하세요 | 선택 순서를 자유롭게 지정 | 선택 순서를 자유롭게 지정 | |
| 통나무 넥타이 | 지연 로그는 XCOM 1GB 캐시를 초과할 수 없습니다. | BInlog 파일은 삭제되지 않습니다 | |
| 대기 데이터베이스 재생 지연 | 2단계 + 1단계, 매우 느림 | 한 단계 + 더블 제로, 더 빨라짐 | |
| 대기업 | 기본 제한은 143MB 이하입니다. | 크기 제한 없음 | |
| 형태 | 고가용성 비용 | 완전한 기능을 갖춘 복사본 3개, 데이터 스토리지 오버헤드 복사본 3개 | 로거 로그 사본, 데이터 저장 사본 2개 |
| 읽기 전용 노드 | 마스터-슬레이브 복제로 구현됨 | 프로토콜은 Leaner 읽기 전용 복사 구현과 함께 제공됩니다. |
MGR은 MySQL 5.7.17에서 도입되었지만 더 많은 MGR 관련 기능은 MySQL 8.0에서만 사용할 수 있으며 MySQL 8.0.22 이상 버전에서는 전반적인 성능이 더욱 안정적이고 신뢰할 수 있습니다. 따라서 우리는 비교 테스트를 위해 양 당사자의 최신 버전 8.0.32를 선택했습니다.
PolarDB-X DN과 MySQL MGR의 비교 테스트 중 테스트 환경, 컴파일 방법, 배포 방법, 운영 매개 변수 및 테스트 방법에 차이가 있어 부정확한 테스트 비교 데이터가 발생할 수 있다는 점을 고려하여 이 기사에서는 다양한 세부 사항에 중점을 둘 것입니다. . 다음과 같이 진행하십시오.
| 시험 준비 | PolarDB-X DN | MySQL 관리자[1] |
| 하드웨어 환경 | 96C 754GB 메모리와 SSD 디스크를 갖춘 동일한 물리적 머신 사용 | |
| 운영 체제 | 리눅스 4.9.168-019.ali3000.alios7.x86_64 | |
| 커널 버전 | 커뮤니티 버전 8.0.32 기반 커널 기준 사용 | |
| 컴파일 방법 | 동일한 RelWithDebInfo로 컴파일 | |
| 작동 매개변수 | 동일한 PolarDB-X 공식 웹사이트를 사용하여 동일한 사양과 매개변수로 32C128G를 판매하세요. | |
| 배포 방법 | 단일 마스터 모드 | |
메모:
성능 테스트는 데이터베이스를 선택할 때 모두가 가장 먼저 주목하는 것입니다. 여기에서는 공식 sysbench 도구를 사용하여 각각 천만 개의 데이터가 포함된 16개의 테이블을 구축하여 OLTP 시나리오에서 성능 테스트를 수행하고 다양한 OLTP 시나리오의 서로 다른 동시성 조건에서 두 테이블의 성능을 테스트 및 비교합니다.실제 배포의 다양한 상황을 고려하여 다음 네 가지 배포 시나리오를 각각 시뮬레이션합니다.
설명하다:
a. 4개 배포 시나리오의 성능을 수평적으로 비교하면 2개 위치의 3개 센터는 모두 3개 복사본의 배포 모드를 채택합니다.
b. 고가용성 데이터베이스 제품 사용 시 RPO=0에 대한 엄격한 제한을 고려하여 MGR은 기본적으로 RPO<>0으로 구성됩니다. 여기서는 각 항목에서 MGR RPO<>0과 RPO=0 간의 비교 테스트를 계속 추가할 예정입니다. 배포 시나리오.
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_read_only | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| 디엔에이 | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 대 MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN 대 MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN 대 MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_읽기_쓰기 | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| 디엔에이 | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 대 MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN 대 MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN 대 MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_write_only | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| 디엔에이 | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 대 MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN 대 MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN 대 MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
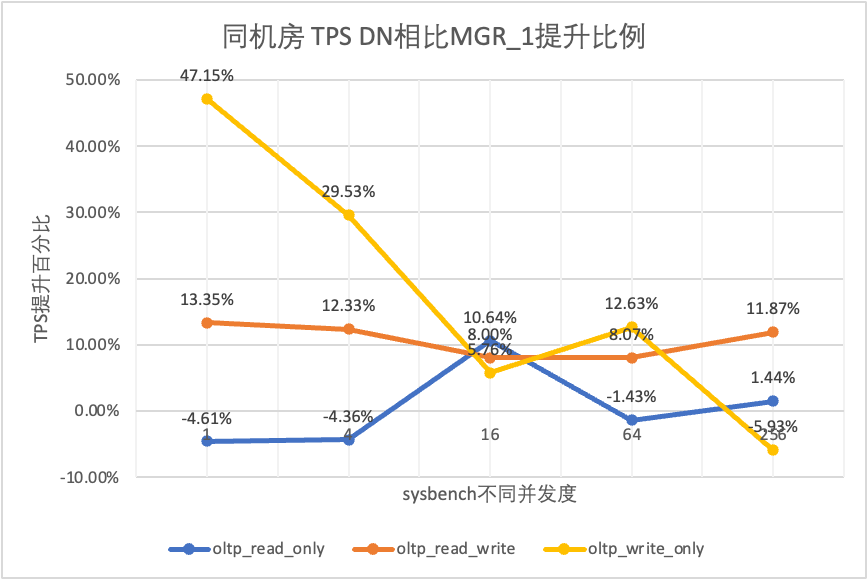
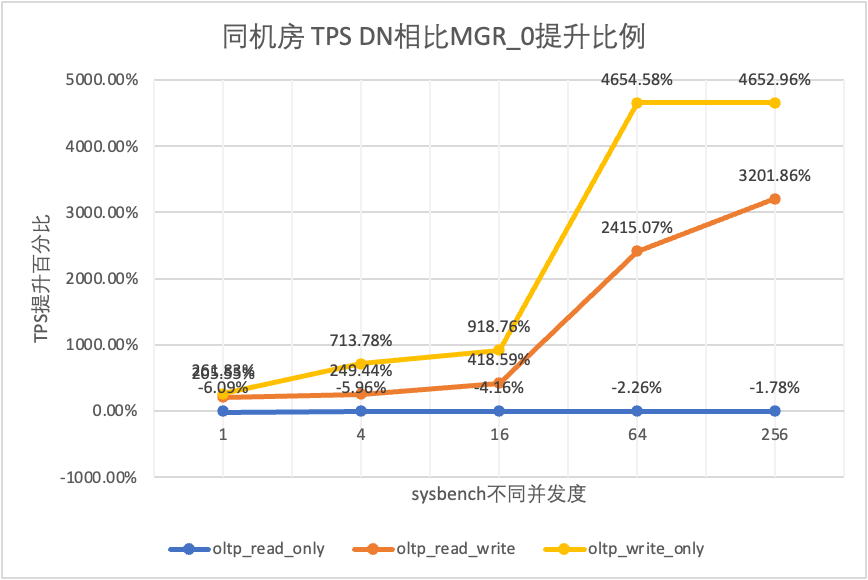
테스트 결과에서 볼 수 있습니다.
| TPS 비교 | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| 디엔에이 | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 대 MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN 대 MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN 대 MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_읽기_쓰기 | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| 디엔에이 | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 대 MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN 대 MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN 대 MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_write_only | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| 디엔에이 | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 대 MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN 대 MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN 대 MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


테스트 결과에서 볼 수 있습니다.
| TPS 비교 | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| 디엔에이 | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 대 MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN 대 MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN 대 MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_읽기_쓰기 | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| 디엔에이 | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 대 MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN 대 MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN 대 MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_write_only | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| 디엔에이 | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 대 MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN 대 MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN 대 MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
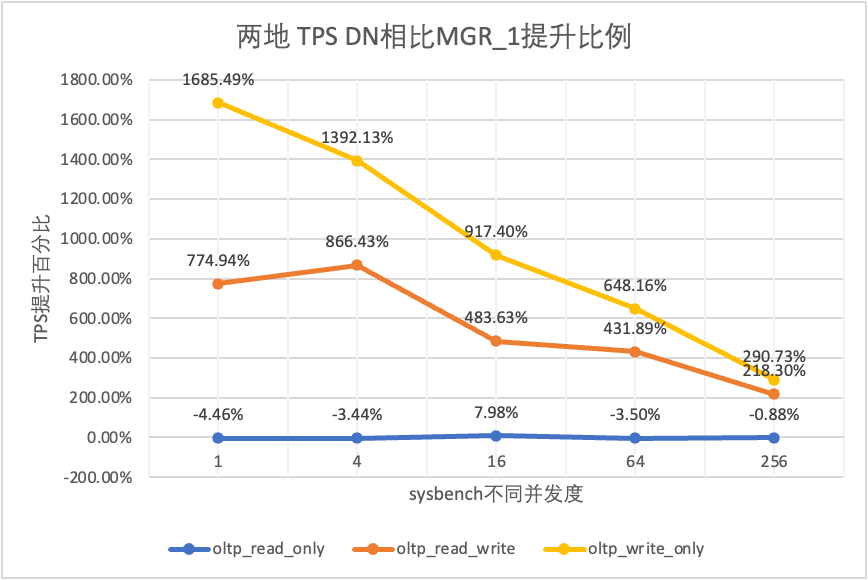
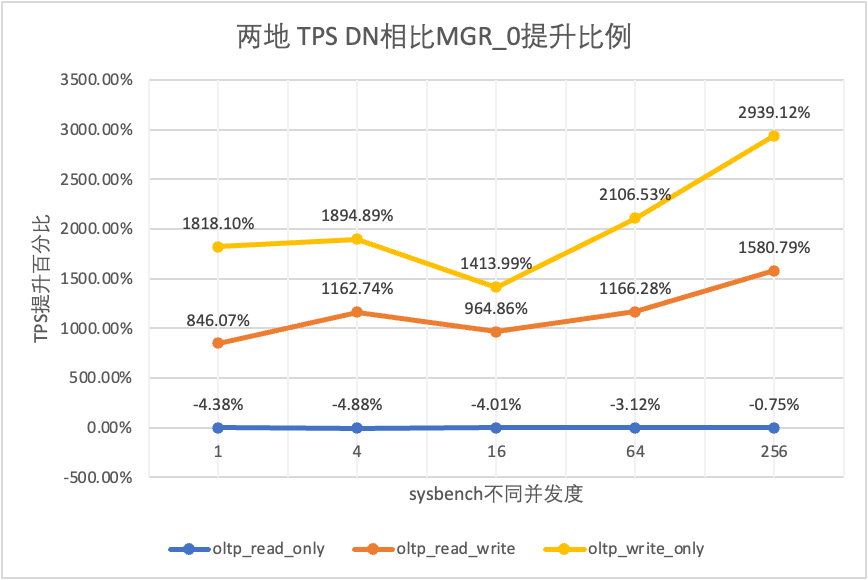
테스트 결과에서 볼 수 있습니다.
| TPS 비교 | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| 디엔에이 | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 대 MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN 대 MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN 대 MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_읽기_쓰기 | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| 디엔에이 | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 대 MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN 대 MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN 대 MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_write_only | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| 디엔에이 | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 대 MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN 대 MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN 대 MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
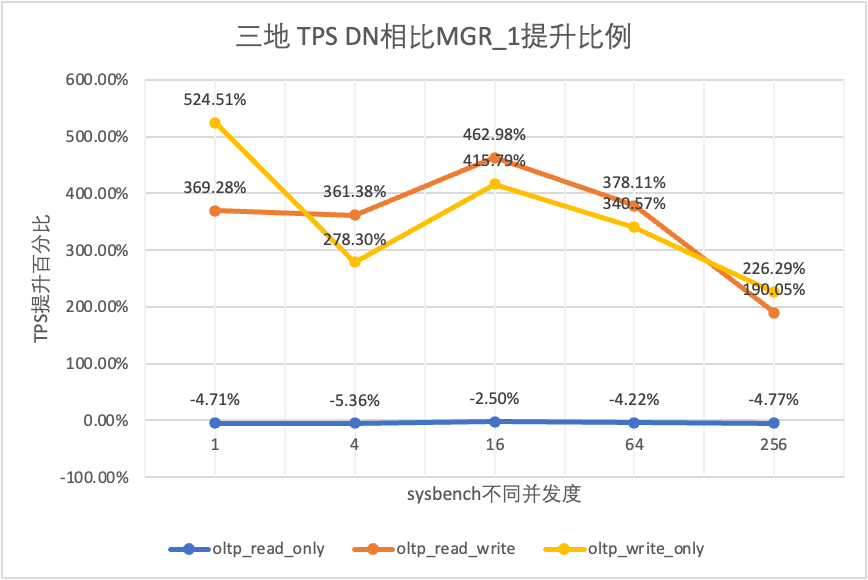
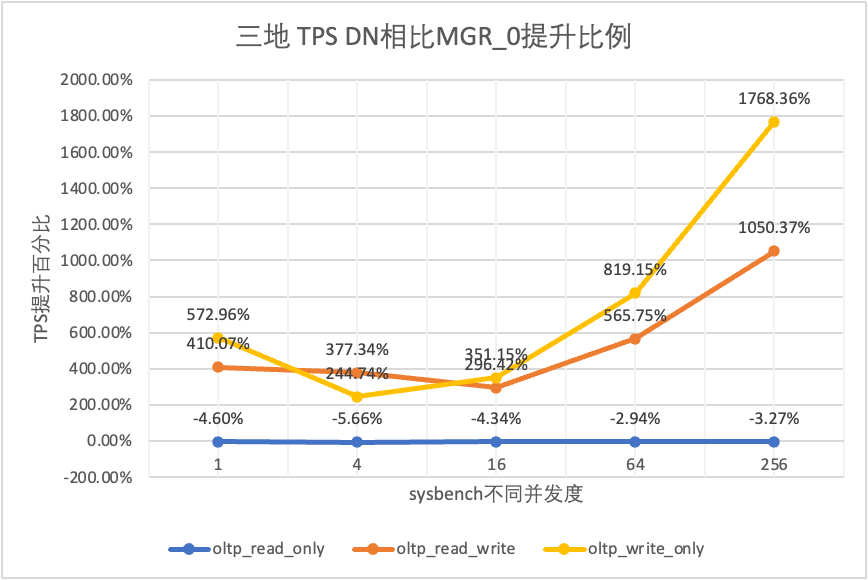
테스트 결과에서 볼 수 있습니다.
다양한 배포 방법에 따른 성능 변화를 명확하게 비교하기 위해 위 테스트에서 oltp_write_only 시나리오 256 동시성에서 다양한 배포 방법에 따른 MGR 및 DN의 TPS 데이터를 선택하여 컴퓨터실 테스트 데이터를 기준으로 계산했습니다. 도시 간 배포 중 성능 변화의 차이를 인식하기 위해 다양한 배포 방법의 TPS 데이터를 기준 대비 비율로 비교했습니다.
| MGR_1(동시 256개) | DN(동시 256개) | MGR에 비해 DN의 성능 이점 | |
| 같은 컴퓨터실 | 16092.02 | 15137.23 | -5.93% |
| 같은 도시에 세 개의 센터가 있음 | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| 2개 장소와 3개 센터 | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| 3개 장소와 3개 센터 | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
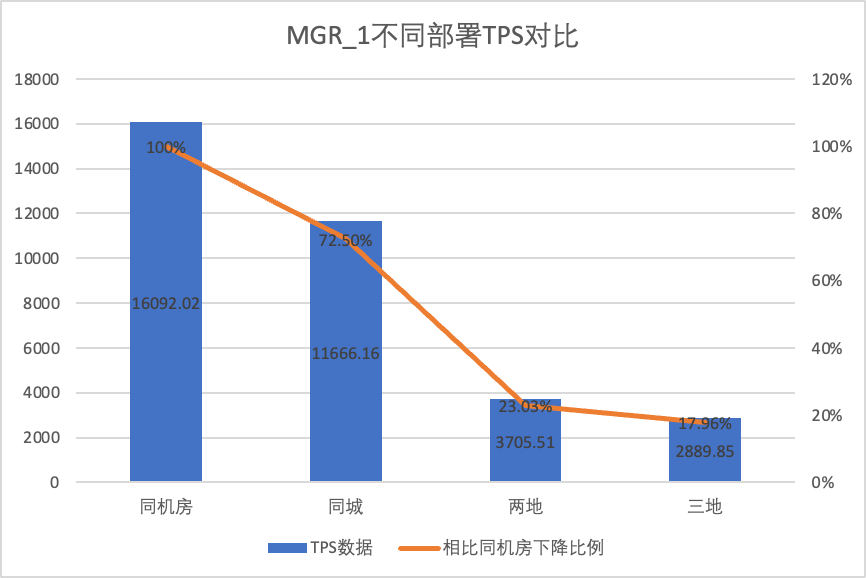
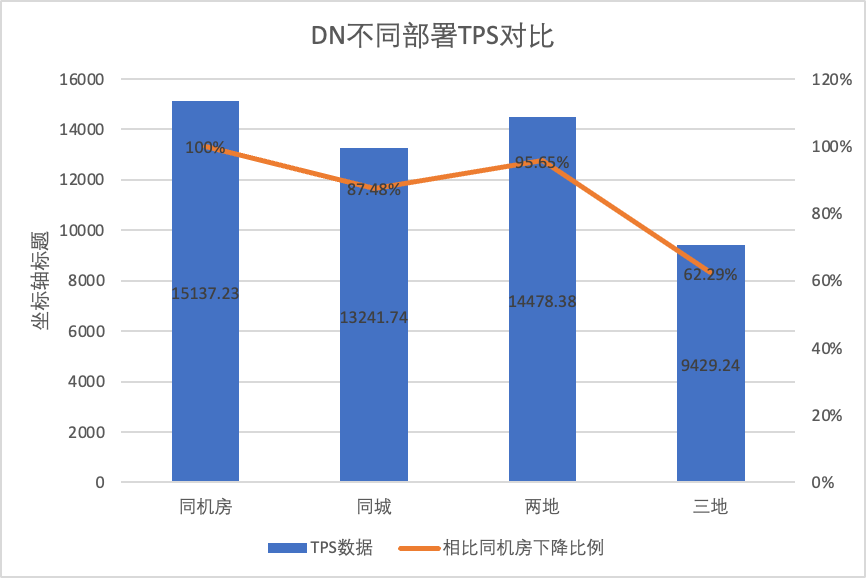
테스트 결과에서 볼 수 있습니다.
실제 사용에서는 성능 데이터뿐만 아니라 성능 지터에도 주의를 기울여야 합니다. 결국, 불안감이 롤러코스터와 같다면 실제 사용자 경험은 매우 좋지 않을 것입니다. TPS 실시간 출력 데이터를 모니터링하고 표시합니다. sysbenc 도구 자체가 성능 지터의 출력 모니터링 데이터를 지원하지 않는다는 점을 고려하여 수학적 변동 계수를 비교 지표로 사용합니다.
256개의 동시 oltp_read_write 시나리오를 예로 들어 동일한 전산실의 MGR_1(RPO<>0)과 DN(RPO=0)의 TPS, 동일한 도시의 3개 센터, 2개 장소의 3개 센터, 세 곳의 세 센터. 지터 상황. 실제 지터 그래프는 다음과 같으며, 각 시나리오별 실제 지터 지표 데이터는 다음과 같습니다.
| 이력서 | 같은 컴퓨터실 | 같은 도시에 세 개의 센터가 있음 | 2개 장소와 3개 센터 | 3개 장소와 3개 센터 |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| 디엔에이 | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
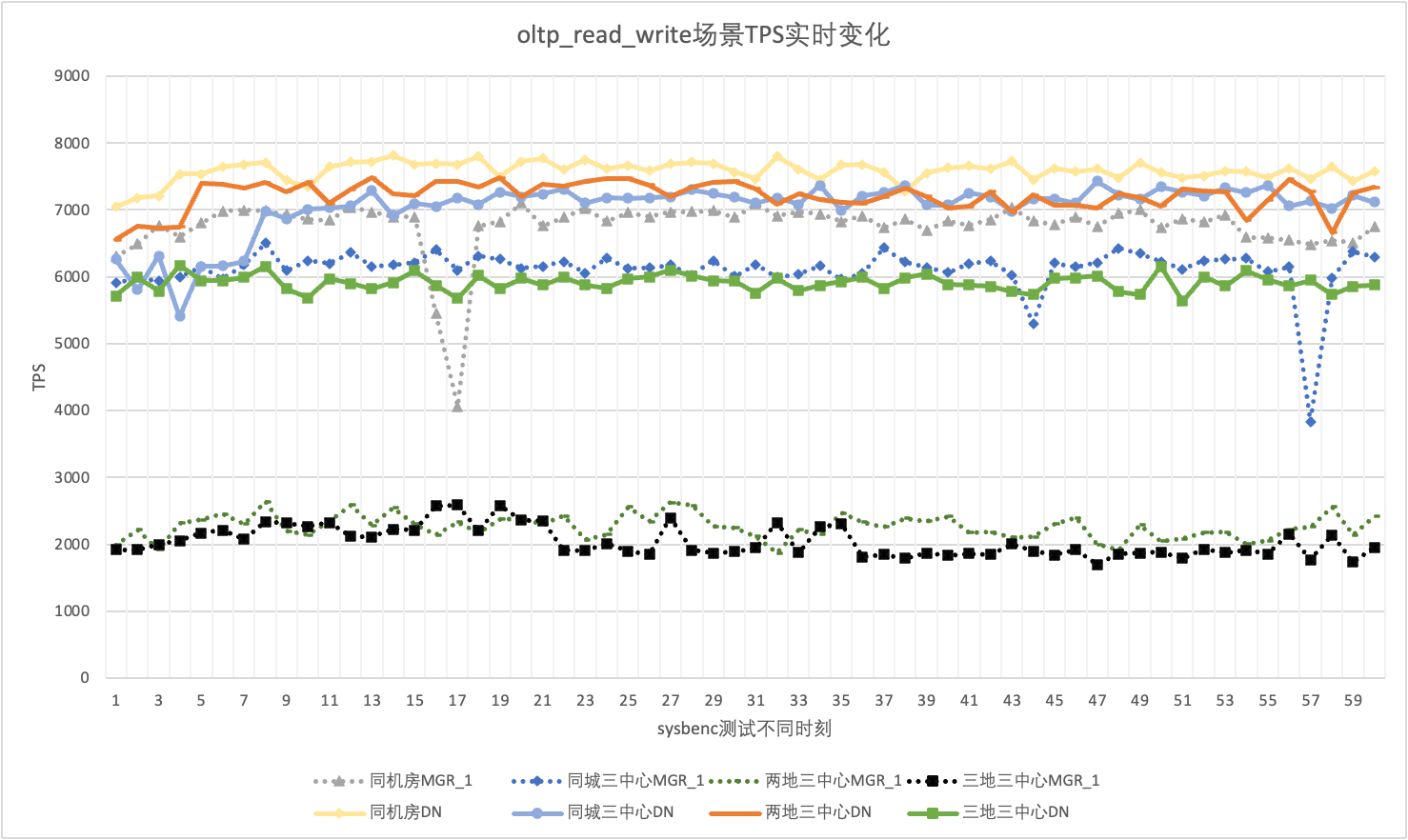
테스트 결과에서 볼 수 있습니다.
분산 데이터베이스의 핵심 기능은 고가용성입니다. 클러스터의 모든 노드에 장애가 발생하더라도 전체 가용성에는 영향을 미치지 않습니다. 동일한 컴퓨터실에 하나의 마스터와 두 개의 백업이 배포된 3개 노드의 일반적인 배포 형태에 대해 다음 세 가지 시나리오에서 사용성 테스트를 수행하려고 했습니다.
부하가 없을 때 리더를 종료하고 클러스터 내 각 노드의 상태 변화와 쓰기 가능 여부를 모니터링합니다.
| 관리자 | 디엔에이 | |
| 정상적으로 시작 | 0 | 0 |
| 리더를 죽이다 | 0 | 0 |
| 비정상적인 노드 시간 발견 | 5 | 5 |
| 3개 노드를 2개 노드로 줄이는 데 걸리는 시간 | 23 | 8 |
| 관리자 | 디엔에이 | |
| 정상적으로 시작 | 0 | 0 |
| 리더를 죽이고 자동으로 끌어올림 | 0 | 0 |
| 비정상적인 노드 시간 발견 | 5 | 5 |
| 3개 노드를 2개 노드로 줄이는 데 걸리는 시간 | 23 | 8 |
| 2노드 복원 3노드 시간 | 37 | 15 |

압력이 없는 조건에서 테스트 결과를 보면 다음과 같습니다.
oltp_read_write 시나리오에서 sysbench를 사용하여 16개 스레드의 동시 스트레스 테스트를 수행합니다. 그림의 10초에서 대기 노드를 수동으로 종료하고 sysbench의 실시간 출력 TPS 데이터를 관찰합니다.
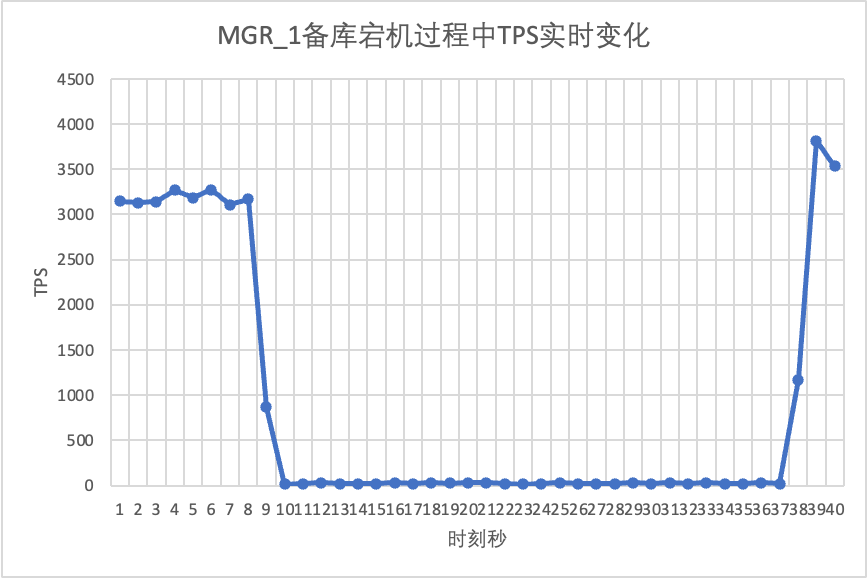


테스트 결과 차트에서 볼 수 있습니다.
테스트를 계속하여 대기 데이터베이스를 다시 시작 및 복원하고 기본 데이터베이스의 TPS 데이터 변경 사항을 관찰합니다.
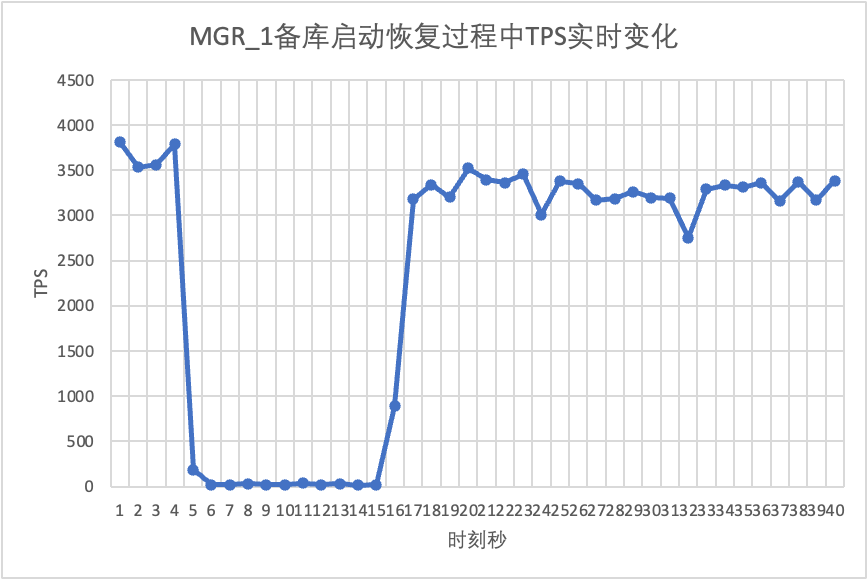
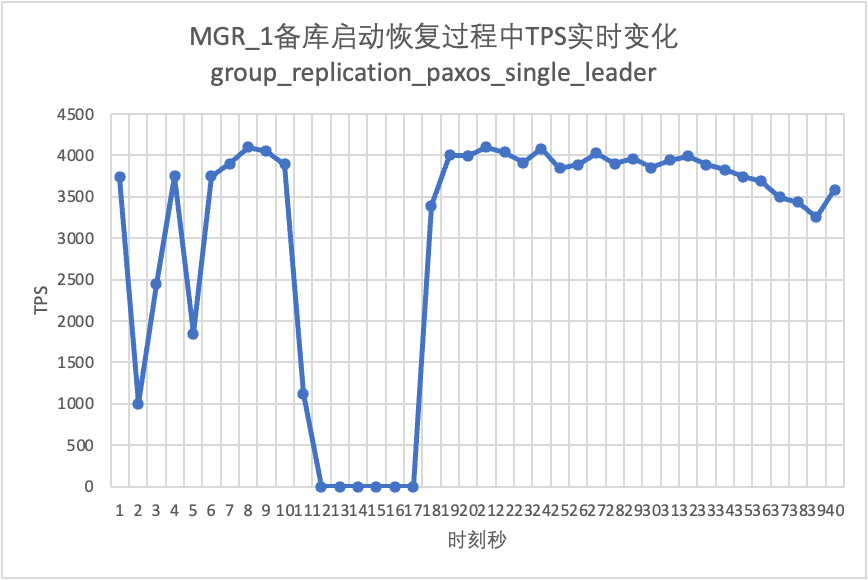
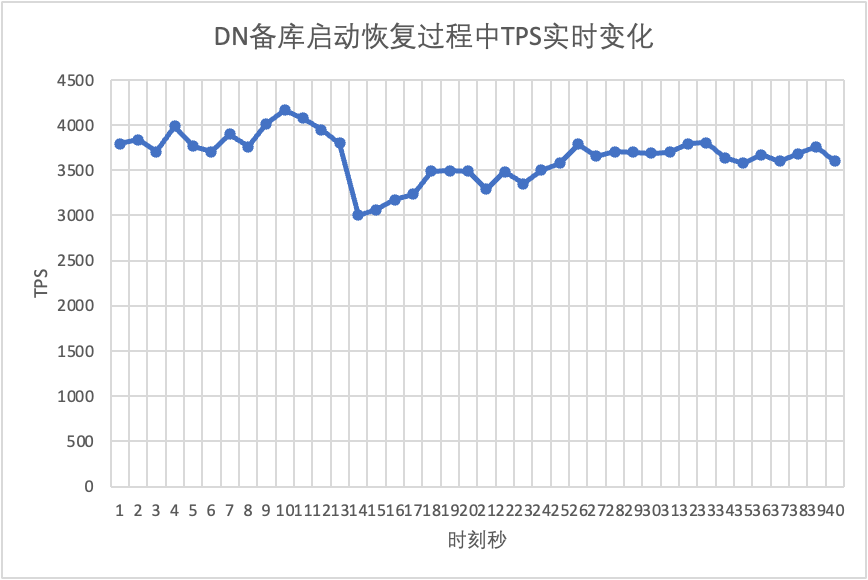
테스트 결과 차트에서 볼 수 있습니다.
MGR 다수 실패 RPO<>0 시나리오를 구성하기 위해 커뮤니티 자체의 MTR Case 방법을 사용하여 MGR에 대한 결함 주입 테스트를 수행합니다.
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
사례 실행 결과는 다음과 같습니다.
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
누락된 숫자를 재현하는 사건의 대략적인 논리는 다음과 같습니다.
위의 경우에 따르면, MGR의 경우 대부분의 서버가 다운되어 메인 데이터베이스를 사용할 수 없는 경우, 스탠바이 데이터베이스를 복원한 후 RPO<>0의 데이터 손실이 발생하며 성공적인 커밋 기록이 남게 됩니다. 원래 클라이언트에 반환된 내용은 손실됩니다.
DN의 경우 다수를 달성하려면 로그가 다수 유지되어야 하므로 위의 시나리오에서도 데이터가 손실되지 않고 RPO=0이 보장될 수 있습니다.
MySQL의 기존 활성-대기 모드에서 대기 데이터베이스에는 일반적으로 IO 스레드와 Apply 스레드가 포함됩니다. Paxos 프로토콜이 도입된 후 IO 스레드는 주로 대기 데이터베이스의 복제 지연을 동기화합니다. 대기 데이터베이스의 재생 적용 오버헤드에 따라 달라지며 여기서는 대기 데이터베이스 재생 지연이 됩니다.
우리는 sysbench를 사용하여 oltp_write_only 시나리오를 테스트하고 100개의 동시성 및 다양한 이벤트 수에서 대기 데이터베이스 재생의 지연 기간을 테스트합니다.대기 데이터베이스 재생 지연 시간은 Performance_schema.replication_applier_status_by_worker 테이블의 APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP 열을 모니터링하여 각 작업자가 실시간으로 작업 중인지 확인하여 복제가 종료되었는지 확인하면 확인할 수 있습니다.

테스트 결과 차트에서 볼 수 있습니다.
| 관리자 | 디엔에이 | ||
| 성능 | 거래 읽기 | 평평한 | 평평한 |
| 거래 쓰기 | RPO<>0일 때 성능은 DN만큼 좋지 않습니다. RPO=0이면 성능이 DN보다 훨씬 떨어집니다. 도시 간 배포 성능이 27%~82% 심각하게 감소했습니다. | 쓰기 트랜잭션 성능은 MGR보다 훨씬 높습니다. 도시 간 배포 성능이 4%에서 37%로 감소합니다. | |
| 지터 | 성능 지터가 심하고 지터 범위는 6~10%입니다. | MGR의 절반에 불과한 3%로 비교적 안정적입니다. | |
| RTO | 기본 데이터베이스가 다운되었습니다 | 5초 만에 이상 징후가 발견됐고, 23초 만에 노드 2개로 줄었다. | 5초 만에 이상현상이 발견됐고, 8초 만에 노드 2개로 줄어들었다. |
| 기본 라이브러리 다시 시작 | 5초 만에 이상 징후가 발견됐고, 37초 만에 3개 노드가 복구됐다. | 5초 안에 이상을 감지하고, 15초 안에 3개의 노드를 복구합니다. | |
| 백업 데이터베이스 가동 중지 시간 | 메인 데이터베이스의 트래픽이 20초 동안 0으로 떨어졌습니다. group_replication_paxos_single_leader를 명시적으로 켜면 이 문제를 완화할 수 있습니다. | 기본 데이터베이스의 지속적인 고가용성 | |
| 대기 데이터베이스 재시작 | 메인 데이터베이스의 트래픽이 10초 동안 0으로 떨어졌습니다. group_replication_paxos_single_leader를 명시적으로 켜는 것도 효과가 없습니다. | 기본 데이터베이스의 지속적인 고가용성 | |
| RPO | 사례 재발 | 다수당이 무너지면 RPO<>0 성능과 RPO=0은 둘 다 가질 수 없습니다. | RPO = 0 |
| 대기 데이터베이스 지연 | 백업 데이터베이스 재생 시간 | 활성과 대기 사이의 지연이 매우 깁니다. 성능과 기본 백업 지연 시간은 동시에 달성할 수 없습니다. | 전체 대기 데이터베이스 재생에 소요된 총 시간은 MGR의 4%이며 이는 MGR의 25배입니다. |
| 매개변수 | 주요 매개변수 |
| 기본 구성으로 전문가가 구성을 사용자 정의할 필요가 없습니다. |
심층적인 기술적 분석과 성능 비교를 거쳐,폴라DB-X 자체 개발한 X-Paxos 프로토콜과 일련의 최적화된 설계를 통해 DN은 성능, 정확성, 가용성 및 리소스 오버헤드 측면에서 MySQL MGR에 비해 많은 이점을 입증했습니다. 그러나 MGR은 MySQL 생태계에서도 중요한 위치를 차지하고 있습니다. , 대기 데이터베이스 중단 지터, 기계실 간 재해 복구 성능 변동, 안정성 등 다양한 상황을 고려해야 합니다. 따라서 MGR을 효과적으로 활용하려면 전문적인 기술 및 운영 및 유지 관리 팀을 갖추고 있어야 합니다. 지원하다.
대규모, 높은 동시성 및 고가용성 요구 사항에 직면했을 때 PolarDB-X 스토리지 엔진은 기본 시나리오에서 MGR과 비교할 때 고유한 기술적 이점과 탁월한 성능을 제공합니다.폴라DB-XDN 기반 중앙집중형(표준 버전)은 기능과 성능의 균형이 잘 잡혀 있어 경쟁력이 매우 높은 데이터베이스 솔루션입니다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com