
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Como todos sabemos, os bancos de dados primários e secundários MySQL (dois nós) geralmente alcançam alta disponibilidade de dados por meio de replicação assíncrona e replicação semissíncrona (Semi-Sync). No entanto, em cenários anormais, como falhas de rede em salas de computadores e interrupções de host, o. arquiteturas primárias e secundárias encontrarão sérios problemas após a troca de HA. Haverá uma probabilidade de inconsistência de dados (referida como RPO!=0).Portanto, se os dados de negócios forem de certa importância, você não deve escolher um produto de banco de dados com arquitetura primária e secundária MySQL (dois nós. Recomenda-se escolher uma arquitetura multicópia com RPO = 0).
Comunidade MySQL, em relação à evolução da tecnologia multicópia com RPO=0:
PolarDB-X O conceito de integração centralizada e distribuída: o DN do nó de dados pode ser usado de forma independente como um formulário centralizado (versão padrão), que é totalmente compatível com o formulário de banco de dados independente. Quando o negócio cresce até o ponto em que a expansão distribuída é necessária, a arquitetura é atualizada para um formato distribuído e os componentes distribuídos são perfeitamente conectados aos nós de dados originais. Não há necessidade de migração ou modificação de dados no lado do aplicativo. , e você pode aproveitar a distribuição da usabilidade e escalabilidade trazidas por esta fórmula, descrição da arquitetura:"Integração Distribuída Centralizada"
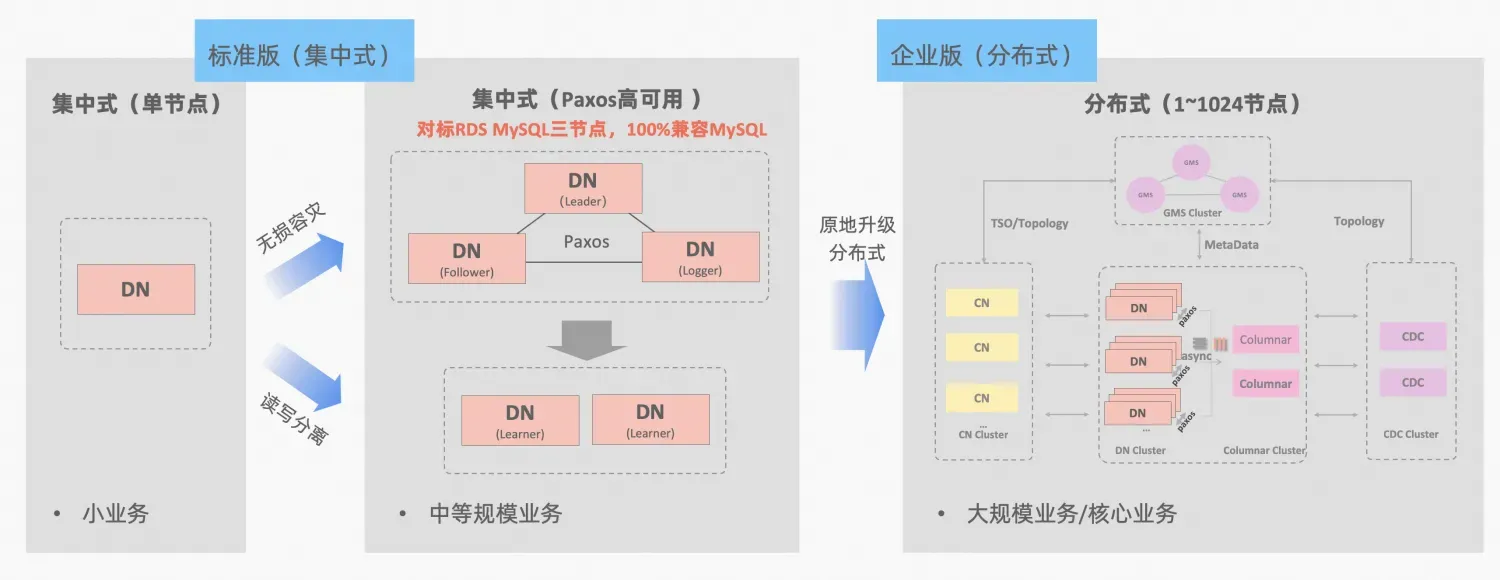
O MGR do MySQL e a versão padrão DN do PolarDB-X usam o protocolo Paxos do princípio mais baixo. Então, quais são os desempenhos específicos e as diferenças no uso real? Este artigo discorre sobre os aspectos de comparação de arquitetura, principais diferenças e comparação de testes.
Descrição da abreviatura MGR/DN: MGR representa a forma técnica do MySQL MGR e DN representa a forma técnica do PolarDB-X único DN centralizado (versão padrão).
A análise comparativa detalhada é relativamente longa, então você pode ler primeiro o resumo e a conclusão. Se estiver interessado, você pode acompanhar o resumo e procurar pistas nos artigos subsequentes.
O MySQL MGR não é recomendado para negócios e empresas em geral porque requer conhecimento técnico profissional e uma equipe de operação e manutenção para utilizá-lo bem. Este artigo também reproduz três "armadilhas ocultas" do MySQL MGR que circulam na indústria há muito tempo. :
Comparado ao MySQL MGR, o PolarDB-X Paxos não apresenta armadilhas semelhantes ao MGR em termos de consistência de dados, recuperação de desastres entre salas de computadores e operação e manutenção de nós. No entanto, também apresenta algumas pequenas deficiências e vantagens na recuperação de desastres:
Descrição da abreviatura MGR/DN:
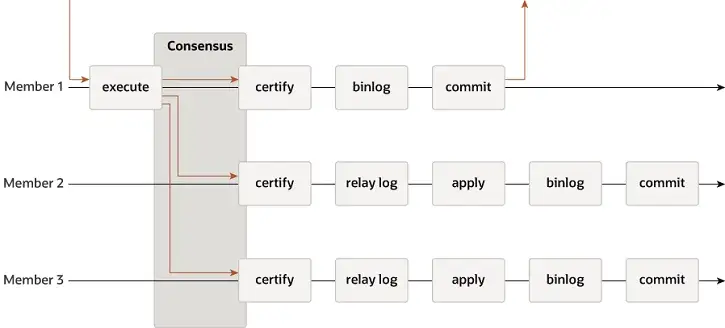
MGR suporta modos single-master e multi-master e reutiliza totalmente o sistema de replicação do MySQL, incluindo Event, Binlog & Relaylog, Apply, Binlog Apply Recovery e GTID. A principal diferença do DN é que o ponto de entrada para a maioria do log de transações do MGR chegar a um consenso é antes que a transação do banco de dados principal seja confirmada.
A razão pela qual o MGR adota o processo acima é porque o MGR está no modo multimestre por padrão e cada nó pode escrever. Portanto, o nó seguidor em um único Grupo Paxos precisa primeiro converter o log recebido em RelayLog e depois combiná-lo. com a transação de gravação recebida como líder a ser enviada, o arquivo Binlog é produzido para enviar a transação final no processo de envio de grupo de dois estágios.
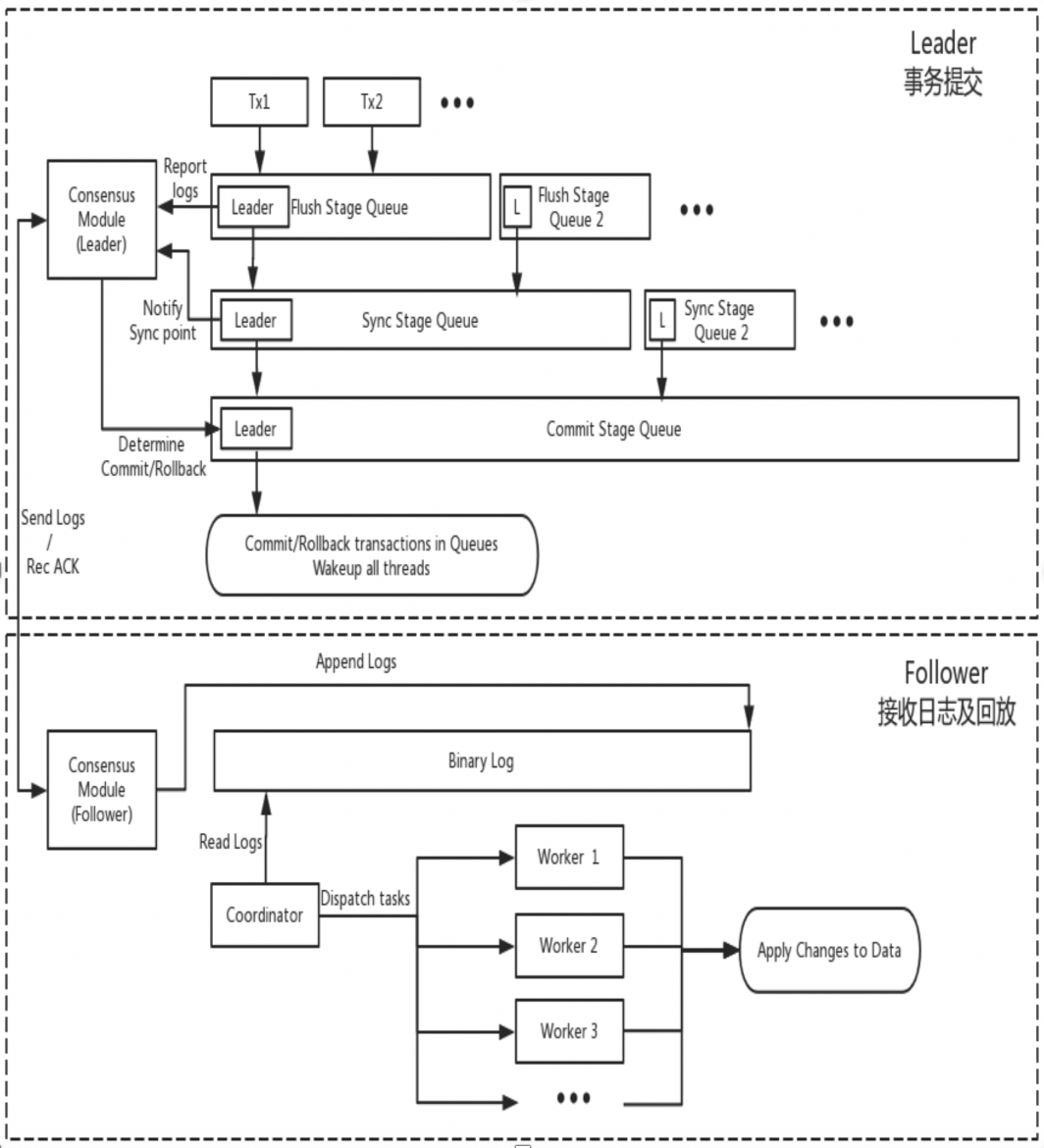
O DN reutiliza a estrutura de dados básica e o código de nível de função do MySQL, mas integra replicação de log, gerenciamento de log, reprodução de log e recuperação de falhas com o protocolo X-Paxos para formar seu próprio conjunto de replicação majoritária e mecanismo de máquina de status. A principal diferença do MGR é que o ponto de entrada para a maioria do log de transações do DN chegar a um consenso é durante o processo principal de envio de transações do banco de dados.
A razão para esse design é que o DN atualmente suporta apenas o modo mestre único, portanto, o log no nível do protocolo X-Paxos é o próprio Binlog que também omite o Relay Log e o conteúdo dos dados de seu log persistente e do log do líder. são iguais ao mesmo preço.

MGR

DN
Teoricamente, tanto Paxos quanto Raft podem garantir a consistência dos dados e os logs que atingiram a maioria após o Crash Recovery não serão perdidos, mas ainda existem diferenças em projetos específicos.
MGR
O XCOM encapsula completamente o protocolo Paxos e todos os seus dados de protocolo são armazenados em cache primeiro na memória. Por padrão, a maioria das transações não requer persistência de log. No caso em que a maioria das tortas cair e o Líder falhar, haverá um sério problema de RPO! = 0.Suponha um cenário extremo:
Sob os parâmetros padrão da comunidade, a maioria das transações não requer persistência de log e não garante RPO=0. Isto pode ser considerado uma compensação pelo desempenho na implementação do projeto XCOM. Para garantir RPO=0 absoluto, você precisa configurar o parâmetro group_replication_consistency que controla a consistência de leitura e gravação para AFTER. No entanto, neste caso, além da sobrecarga de rede RTT de 1,5, a transação exigirá uma sobrecarga de E/S de log para atingir a maioria. e o desempenho será muito ruim.
DN
PolarDB-X DN usa X-Paxos para implementar um protocolo distribuído e está profundamente vinculado ao processo de Group Commit do MySQL. Quando uma transação é enviada, a maioria é obrigada a confirmar o posicionamento e a persistência antes que o envio real seja permitido. A maior parte do posicionamento do disco aqui se refere ao posicionamento do Binlog da biblioteca principal. O thread IO da biblioteca standby recebe o log da biblioteca principal e o grava em seu próprio Binlog para persistência. Portanto, mesmo que todos os nós falhem em cenários extremos, os dados não serão perdidos e o RPO=0 poderá ser garantido.
O tempo RTO está intimamente relacionado ao tempo de sobrecarga de reinicialização a frio do próprio sistema, o que se reflete nas funções básicas específicas:Mecanismo de detecção de falhas-> mecanismo de recuperação de falhas-> mecanismo de seleção mestre-> balanceamento de log
MGR
DN
MGR
DN
No modo single-master, o XCOM e o DN X-Paxos do MGR, um modo líder forte, seguem o mesmo princípio básico para selecionar o líder – os logs que foram acordados pelo cluster não podem ser revertidos. Mas quando se trata do registro de não consenso, existem diferenças
MGR
DN
A equalização de log significa que há um atraso na replicação de log nos logs entre os bancos de dados primário e secundário, e o banco de dados secundário precisa equalizar os logs. Para nós que são reiniciados e restaurados, a recuperação geralmente é iniciada com o banco de dados de espera, e um atraso na replicação de log já ocorreu em comparação com o banco de dados principal, e os logs precisam ser atualizados com o banco de dados principal. Para aqueles nós que estão fisicamente distantes do Líder, atingir a maioria geralmente não tem nada a ver com eles. Eles sempre têm um atraso no log de replicação e estão constantemente atualizando o log. Essas situações exigem implementação de engenharia específica para garantir a resolução oportuna de atrasos na replicação de logs.
MGR
DN
O atraso de reprodução do banco de dados standby é o atraso entre o momento em que a mesma transação é concluída no banco de dados principal e o momento em que a transação é aplicada no banco de dados standby. O que é testado aqui é o desempenho do log do aplicativo Apply do banco de dados standby. Afeta quanto tempo leva para o banco de dados standby concluir seu aplicativo de dados e fornecer serviços de leitura e gravação quando ocorre uma exceção.
MGR
DN
Grandes transações não afetam apenas o envio de transações comuns, mas também afetam a estabilidade de todo o protocolo distribuído em um sistema distribuído. Em casos graves, uma grande transação fará com que todo o cluster fique indisponível por um longo período.
MGR
DN
MGR
DN

| MGR | DN | ||
| Eficiência do protocolo | Hora de envio da transação | 1,5~2,5 RTT | 1 RTT |
| Persistência da Maioria | Economia de memória XCOM | Persistência do log binário | |
| confiabilidade | RPO=0 | Não garantido por padrão | Totalmente garantido |
| Detecção de falha | Todos os nós verificam uns aos outros, a carga da rede é alta O ciclo de batimentos cardíacos não pode ser ajustado | O nó mestre verifica periodicamente outros nós Os parâmetros do ciclo de batimentos cardíacos são ajustáveis | |
| Recuperação de colapso majoritário | Intervenção manual | Recuperação automática | |
| Recuperação de acidentes minoritários | Recuperação automática na maioria dos casos, intervenção manual em circunstâncias especiais | Recuperação automática | |
| Escolha o mestre | Especifique livremente a ordem de seleção | Especifique livremente a ordem de seleção | |
| Gravata de toras | Os logs atrasados não podem exceder o cache de 1 GB do XCOM | Arquivos BInlog não são excluídos | |
| Atraso na reprodução do banco de dados em espera | Dois estágios + duplo, muito lento | Um estágio + duplo zero, mais rápido | |
| Grande negócio | O limite padrão não é superior a 143 MB | Sem limite de tamanho | |
| forma | Custo de alta disponibilidade | Três cópias totalmente funcionais, 3 cópias de sobrecarga de armazenamento de dados | Cópia de log do Logger, 2 cópias de armazenamento de dados |
| nó somente leitura | Implementado com replicação mestre-escravo | O protocolo vem com implementação de cópia somente leitura Leaner |
O MGR foi introduzido no MySQL 5.7.17, mas mais recursos relacionados ao MGR estão disponíveis apenas no MySQL 8.0, e no MySQL 8.0.22 e versões posteriores, o desempenho geral será mais estável e confiável. Portanto, selecionamos a versão mais recente 8.0.32 de ambas as partes para testes comparativos.
Considerando que existem diferenças nos ambientes de teste, métodos de compilação, métodos de implantação, parâmetros operacionais e métodos de teste durante o teste comparativo de PolarDB-X DN e MySQL MGR, o que pode levar a dados de comparação de teste imprecisos, este artigo se concentrará em vários detalhes . Proceda da seguinte forma:
| preparação para teste | PolarDB-X DN | Gerenciador do MySQL[1] |
| Ambiente de hardware | Usando a mesma máquina física com memória 96C de 754 GB e disco SSD | |
| sistema operacional | Linux 4.9.168-019.ali3000.alios7.x86_64 | |
| Versão do kernel | Usando uma linha de base do kernel baseada na versão 8.0.32 da comunidade | |
| Método de compilação | Compilar com o mesmo RelWithDebInfo | |
| Parâmetros operacionais | Use o mesmo site oficial do PolarDB-X para vender 32C128G com as mesmas especificações e parâmetros | |
| Método de implantação | Modo mestre único | |
Observação:
O teste de desempenho é a primeira coisa que todos prestam atenção ao selecionar um banco de dados. Aqui usamos a ferramenta oficial sysbench para construir 16 tabelas, cada uma com 10 milhões de dados, para realizar testes de desempenho em cenários OLTP e testar e comparar o desempenho dos dois sob diferentes condições de simultaneidade em diferentes cenários OLTP.Considerando as diferentes situações de implantação real, simulamos os quatro cenários de implantação a seguir, respectivamente:
ilustrar:
a. Considere a comparação horizontal do desempenho de quatro cenários de implantação. Três centros em dois locais e três centros em três locais adotam o modo de implantação de 3 cópias.
b. Considerando as restrições estritas de RPO=0 ao usar produtos de banco de dados de alta disponibilidade, o MGR é configurado com RPO<>0 por padrão. Aqui continuaremos a adicionar testes comparativos entre MGR RPO<>0 e RPO=0 em cada um. cenário de implantação.
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_somente_leitura | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 vs MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN vs MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN vs MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_leitura_escrita | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 vs MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN vs MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN vs MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_somente_gravação | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 vs MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN vs MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN vs MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
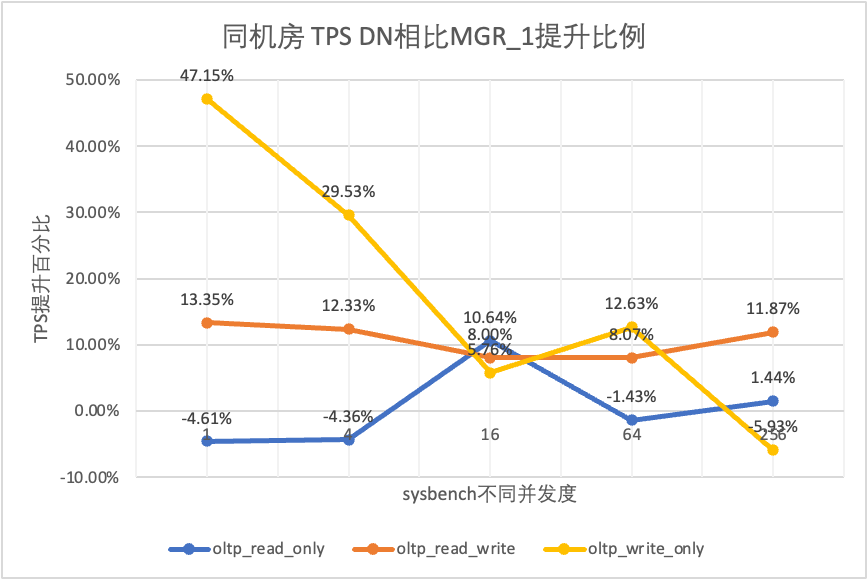
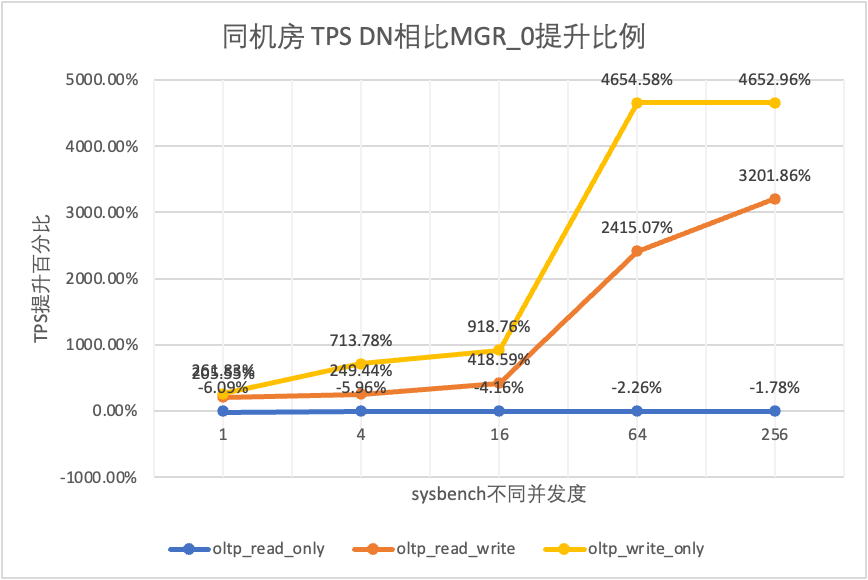
Isso pode ser visto nos resultados do teste:
| Comparação de TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_somente_leitura | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 vs MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN vs MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN vs MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_leitura_escrita | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 vs MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN vs MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN vs MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_somente_gravação | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 vs MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN vs MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN vs MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Isso pode ser visto nos resultados do teste:
| Comparação de TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_somente_leitura | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 vs MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN vs MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN vs MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_leitura_escrita | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 vs MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN vs MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN vs MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_somente_gravação | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 vs MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN vs MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN vs MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
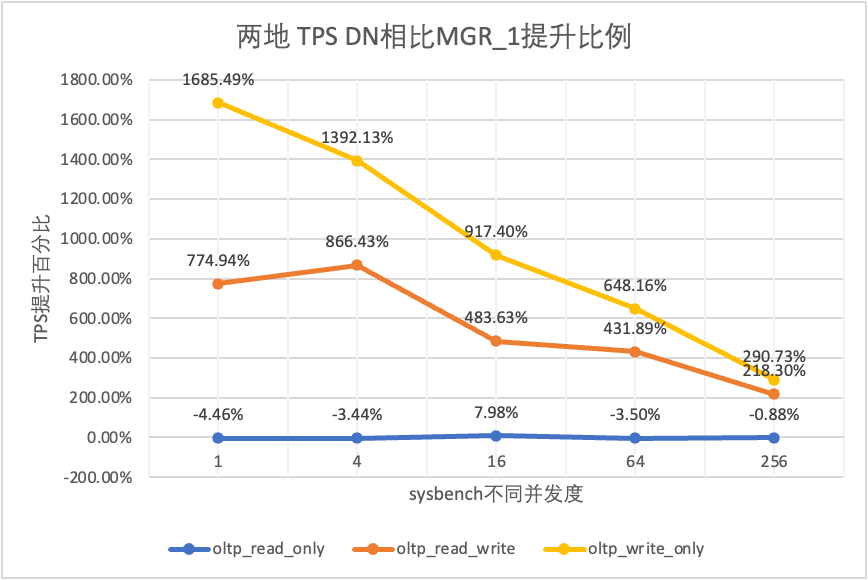
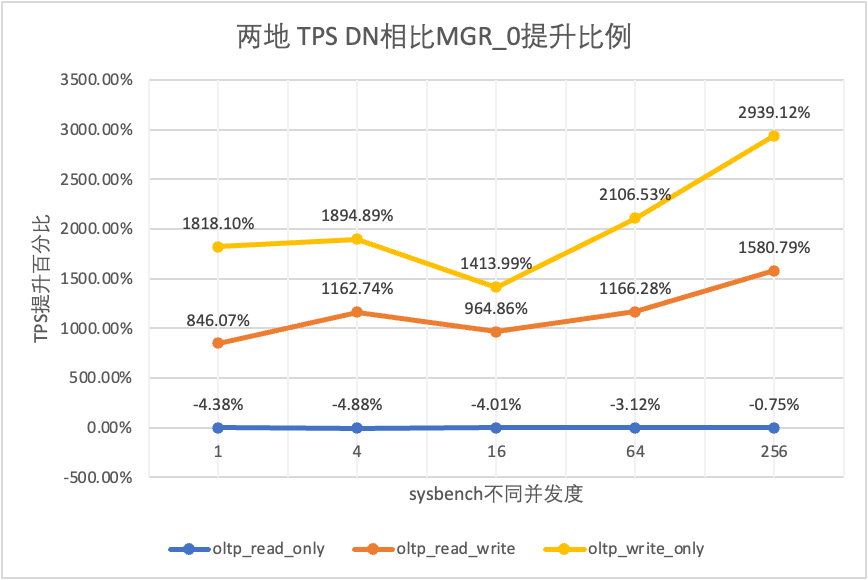
Isso pode ser visto nos resultados do teste:
| Comparação de TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_somente_leitura | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 vs MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN vs MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN vs MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_leitura_escrita | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 vs MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN vs MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN vs MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_somente_gravação | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 vs MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN vs MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN vs MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
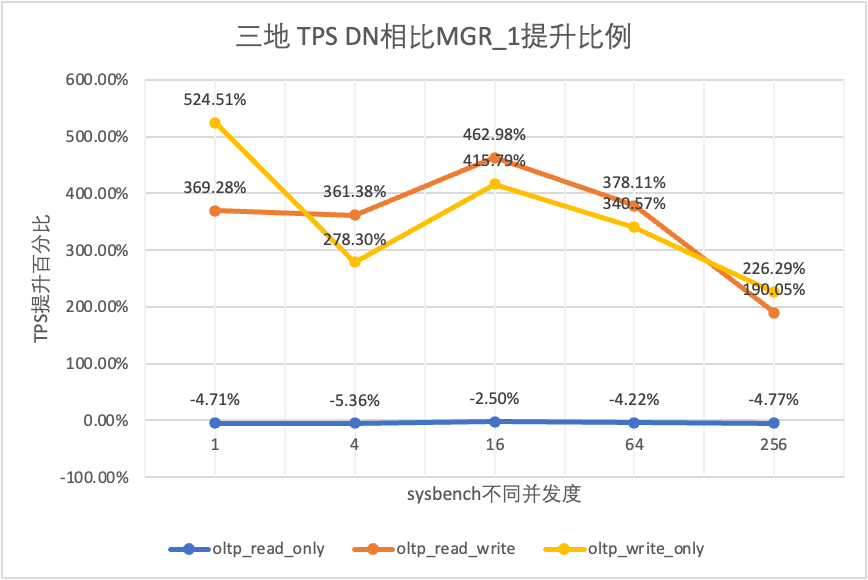
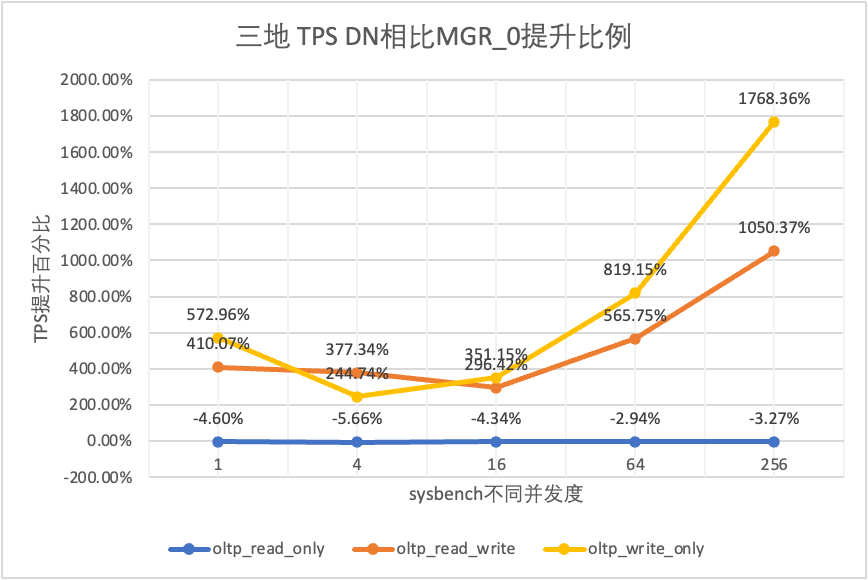
Isso pode ser visto nos resultados do teste:
Para comparar claramente as mudanças de desempenho sob diferentes métodos de implantação, selecionamos os dados TPS de MGR e DN sob diferentes métodos de implantação sob a simultaneidade do cenário 256 oltp_write_only no teste acima. Usando os dados de teste da sala de computadores como linha de base, calculamos e. comparou os dados TPS de diferentes métodos de implantação em comparação com a linha de base para perceber a diferença nas mudanças de desempenho durante a implantação entre cidades.
| MGR_1 (256 simultâneos) | DN (256 simultâneos) | Vantagens de desempenho do DN em comparação com o MGR | |
| Mesma sala de informática | 16092.02 | 15137.23 | -5.93% |
| Três centros na mesma cidade | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Dois lugares e três centros | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Três lugares e três centros | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
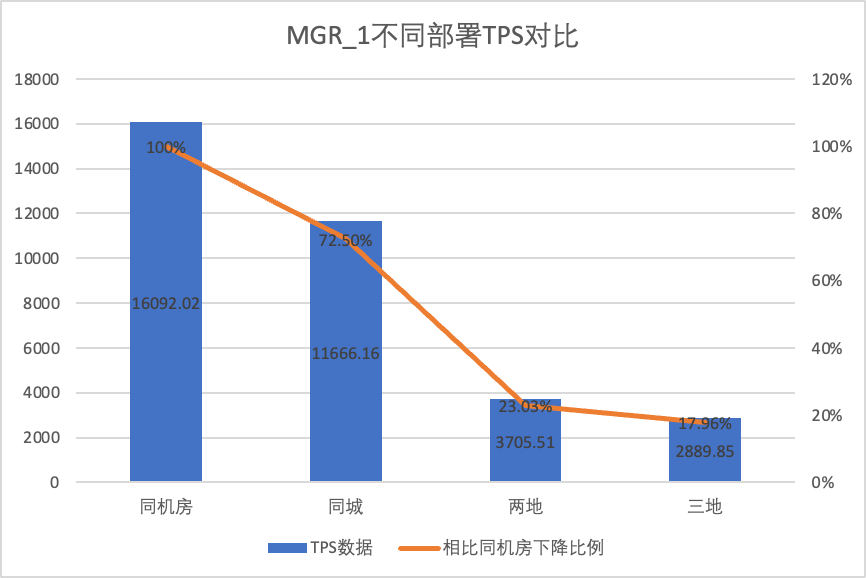
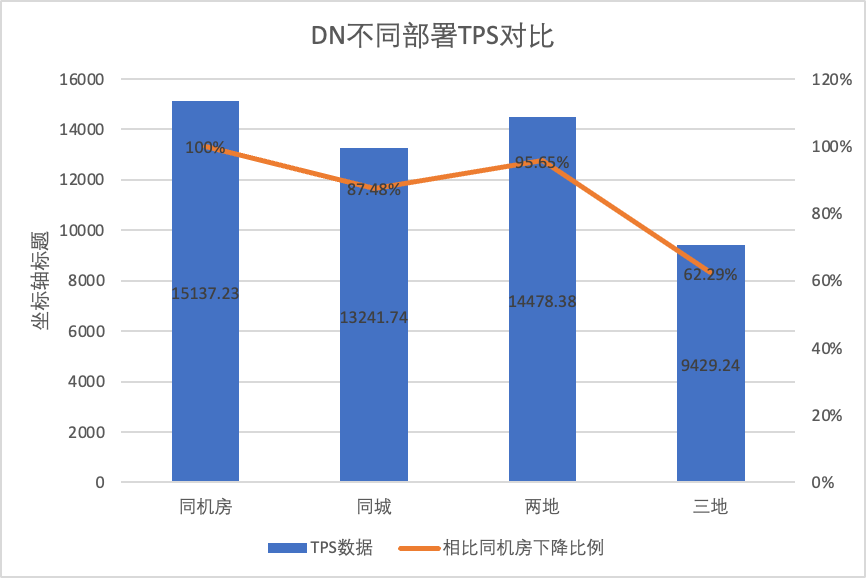
Isso pode ser visto nos resultados do teste:
No uso real, não prestamos atenção apenas aos dados de desempenho, mas também precisamos prestar atenção ao jitter de desempenho. Afinal, se o tremor for como uma montanha-russa, a experiência real do usuário será muito ruim. Monitoramos e exibimos dados de saída do TPS em tempo real. Considerando que a própria ferramenta sysbenc não suporta dados de monitoramento de saída de jitter de desempenho, usamos o coeficiente matemático de variação como indicador de comparação:
Tomando como exemplo o cenário oltp_read_write simultâneo de 256, analisamos estatisticamente o TPS de MGR_1 (RPO<>0) e DN (RPO=0) na mesma sala de informática, três centros na mesma cidade, três centros em dois locais, e três centros em três lugares. O gráfico de jitter real é o seguinte, e os dados reais do indicador de jitter para cada cenário são os seguintes:
| cv | Mesma sala de informática | Três centros na mesma cidade | Dois lugares e três centros | Três lugares e três centros |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
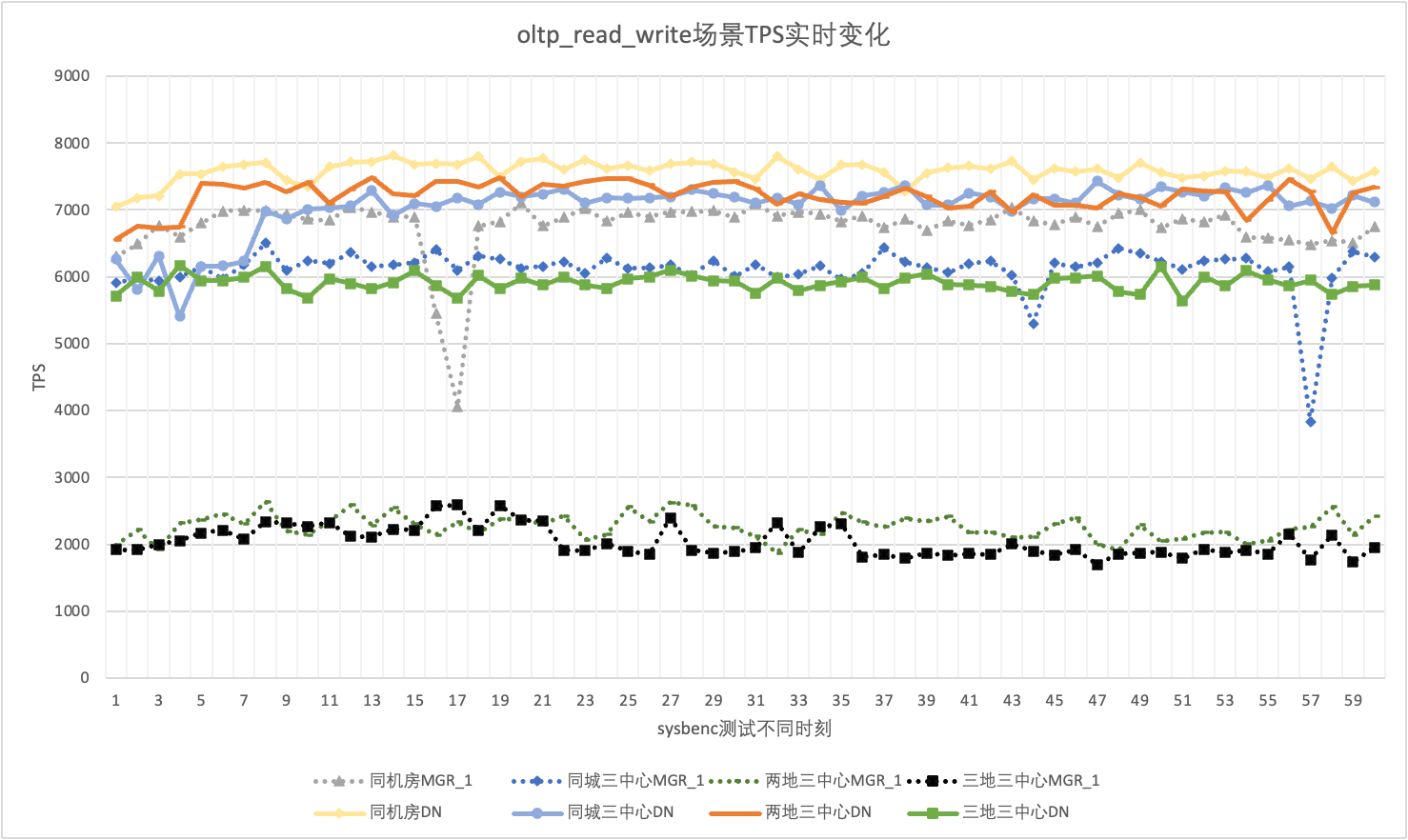
Isso pode ser visto nos resultados do teste:
O principal recurso de um banco de dados distribuído é a alta disponibilidade. A falha de qualquer nó no cluster não afetará a disponibilidade geral. Para a forma típica de implantação de 3 nós com um mestre e dois backups implantados na mesma sala de computadores, tentamos realizar testes de usabilidade nos três cenários a seguir:
Quando não há carga, mate o líder e monitore as mudanças de status de cada nó no cluster e se ele é gravável.
| MGR | DN | |
| Iniciando normalmente | 0 | 0 |
| matar líder | 0 | 0 |
| Tempo de nó anormal encontrado | 5 | 5 |
| É hora de reduzir 3 nós para 2 nós | 23 | 8 |
| MGR | DN | |
| Iniciando normalmente | 0 | 0 |
| mate o líder, puxe automaticamente para cima | 0 | 0 |
| Tempo de nó anormal encontrado | 5 | 5 |
| É hora de reduzir 3 nós para 2 nós | 23 | 8 |
| Restauração de 2 nós Tempo de 3 nós | 37 | 15 |

Pode-se observar pelos resultados dos testes que, sob nenhuma condição de pressão:
Use o sysbench para conduzir um teste de estresse simultâneo de 16 threads no cenário oltp_read_write No décimo segundo na figura, elimine manualmente um nó em espera e observe os dados TPS de saída em tempo real do sysbench.
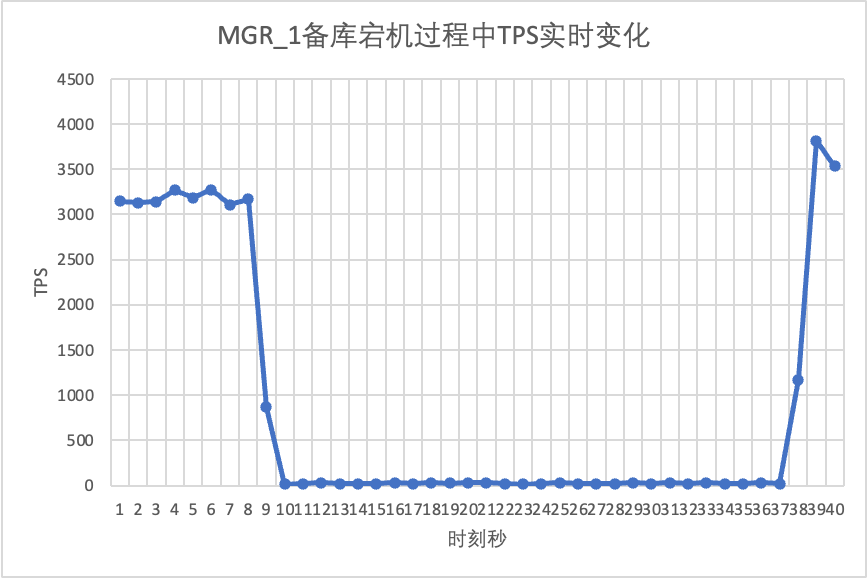


Isso pode ser visto no gráfico de resultados do teste:
Continuando o teste, reiniciamos e restauramos o banco de dados standby e observamos as alterações nos dados TPS do banco de dados principal.
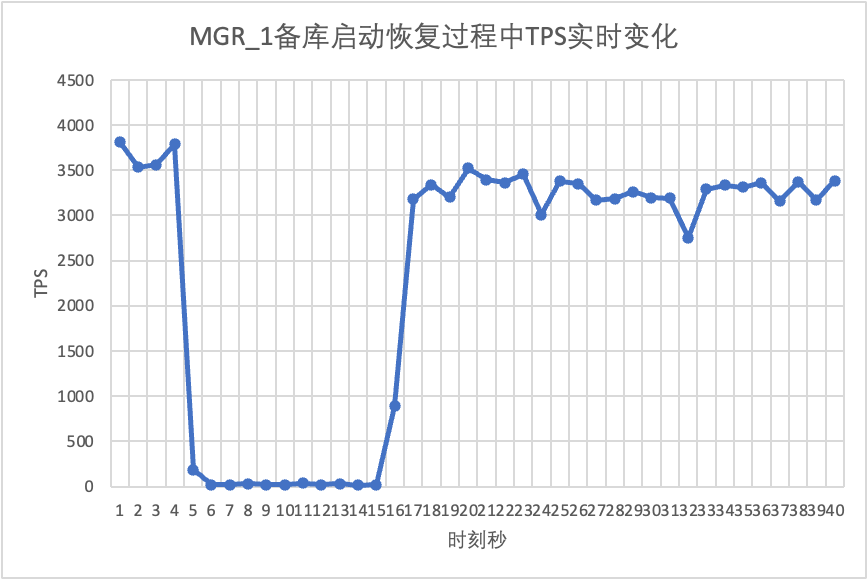
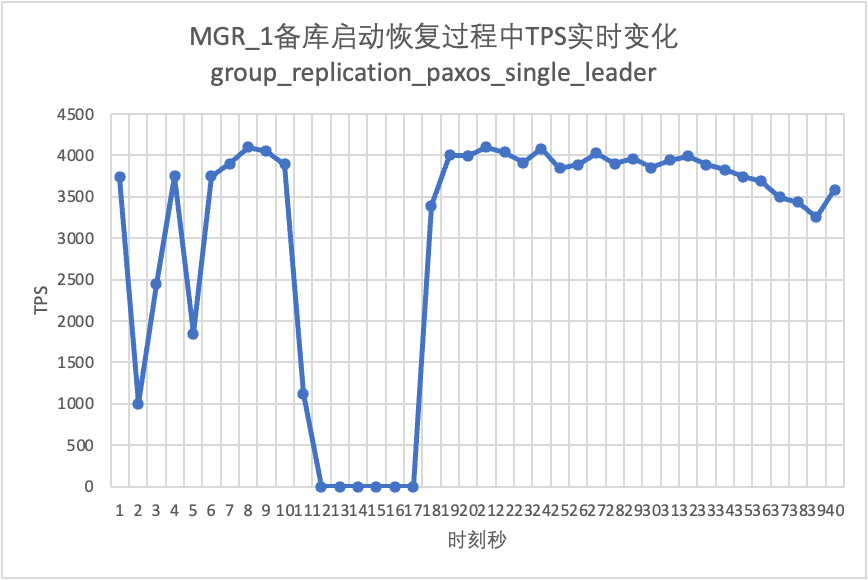
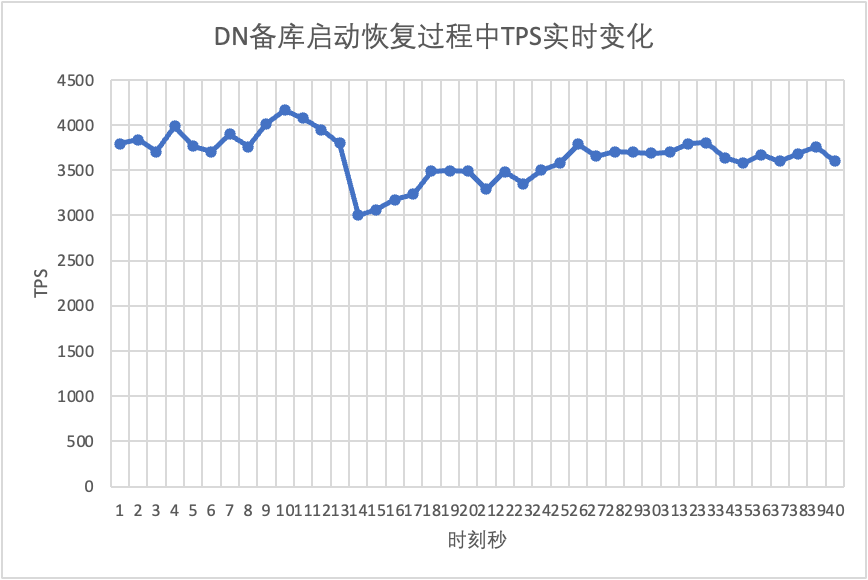
Isso pode ser visto no gráfico de resultados do teste:
Para construir o cenário RPO<>0 de falha majoritária do MGR, usamos o método MTR Case da própria comunidade para realizar testes de injeção de falhas no MGR.
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
Os resultados da execução do caso são os seguintes:
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
A lógica aproximada de um caso que reproduz números faltantes é a seguinte:
De acordo com o caso acima, para MGR, quando a maioria dos servidores estiver inoperante e o banco de dados principal indisponível, e após a restauração do banco de dados standby, haverá perda de dados de RPO<>0, e o registro de commit bem-sucedido que foi originalmente devolvido ao cliente é perdido.
Para DN, o alcance da maioria requer que os logs sejam persistidos na maioria, portanto, mesmo no cenário acima, os dados não serão perdidos e o RPO=0 poderá ser garantido.
No modo de espera ativo tradicional do MySQL, o banco de dados de espera geralmente contém threads de IO e threads de aplicação. Após a introdução do protocolo Paxos, o thread de IO sincroniza o log binário dos bancos de dados ativos e de espera principalmente. depende da sobrecarga da reprodução do Apply do banco de dados de espera, aqui nos tornamos o atraso de reprodução do banco de dados de espera.
Usamos o sysbench para testar o cenário oltp_write_only e testar a duração do atraso na reprodução do banco de dados standby em 100 simultaneidades e diferentes números de eventos.O tempo de atraso de reprodução do banco de dados de espera pode ser determinado monitorando a coluna APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP da tabela performance_schema.replication_applier_status_by_worker para ver se cada trabalhador está trabalhando em tempo real para determinar se a replicação foi finalizada.

Isso pode ser visto no gráfico de resultados do teste:
| MGR | DN | ||
| desempenho | Ler transação | plano | plano |
| escrever transação | O desempenho não é tão bom quanto DN quando RPO<>0 Quando RPO=0, o desempenho é muito inferior ao DN O desempenho da implantação entre cidades caiu seriamente de 27% a 82% | O desempenho da transação de gravação é muito superior ao MGR O desempenho da implantação entre cidades diminui de 4% a 37%. | |
| Tremor | O jitter de desempenho é severo, a faixa de jitter é de 6 a 10% | Relativamente estável em 3%, apenas metade do MGR | |
| RTO | O banco de dados principal está inativo | A anormalidade foi descoberta em 5s e reduzida para dois nós em 23s. | A anormalidade foi descoberta em 5s e reduzida para dois nós em 8s. |
| Reinicie a biblioteca principal | Uma anormalidade foi descoberta em 5 segundos e três nós foram restaurados em 37 segundos. | Uma anormalidade é detectada em 5 segundos e três nós são restaurados em 15 segundos. | |
| Tempo de inatividade do banco de dados de backup | O tráfego do banco de dados principal caiu para 0 por 20 segundos. Isso pode ser aliviado ativando explicitamente group_replication_paxos_single_leader. | Alta disponibilidade contínua do banco de dados principal | |
| Reinicialização do banco de dados em espera | O tráfego do banco de dados principal caiu para 0 por 10 segundos. Ativar explicitamente group_replication_paxos_single_leader também não tem efeito. | Alta disponibilidade contínua do banco de dados principal | |
| RPO | Recorrência de caso | RPO<>0 quando o partido majoritário cai Desempenho e RPO=0 não podem ter ambos. | RPO = 0 |
| Atraso do banco de dados em espera | Tempo de reprodução do banco de dados de backup | O atraso entre ativo e standby é muito grande. O desempenho e a latência do backup primário não podem ser alcançados ao mesmo tempo. | O tempo total gasto na reprodução geral do banco de dados em espera é de 4% do MGR, o que é 25 vezes maior que o do MGR. |
| parâmetro | parâmetro chave |
| Configuração padrão, não há necessidade de profissionais personalizarem a configuração |
Após análise técnica aprofundada e comparação de desempenho,PolarDB-X Com seu protocolo X-Paxos autodesenvolvido e uma série de designs otimizados, o DN demonstrou muitas vantagens sobre o MySQL MGR em termos de desempenho, correção, disponibilidade e sobrecarga de recursos. No entanto, o MGR também ocupa uma posição importante no ecossistema MySQL. , várias situações, como jitter de interrupção do banco de dados em espera, flutuações de desempenho de recuperação de desastres entre salas de máquinas e estabilidade, precisam ser consideradas. Portanto, se você deseja fazer bom uso do MGR, deve estar equipado com uma equipe técnica e de operação e manutenção profissional. apoiar.
Quando confrontado com requisitos de grande escala, alta simultaneidade e alta disponibilidade, o mecanismo de armazenamento PolarDB-X tem vantagens técnicas exclusivas e excelente desempenho em comparação com o MGR em cenários prontos para uso.PolarDB-XO centralizado baseado em DN (versão padrão) possui um bom equilíbrio entre funções e desempenho, tornando-o uma solução de banco de dados altamente competitiva.

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]