Reprise après sinistre de base de données | Comparaison approfondie entre MySQL MGR et Alibaba Cloud PolarDB-X Paxos
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Écosystème open source
Comme nous le savons tous, les bases de données MySQL primaires et secondaires (deux nœuds) atteignent généralement une haute disponibilité des données grâce à la réplication asynchrone et à la réplication semi-synchrone (Semi-Sync). Cependant, dans des scénarios anormaux tels que des pannes de réseau de salle informatique et des blocages de l'hôte, le problème se produit. les architectures primaires et secondaires rencontreront de sérieux problèmes après la commutation HA. Il y aura une probabilité d'incohérence des données (appelée RPO ! = 0).Par conséquent, tant que les données métier ont une certaine importance, vous ne devez pas choisir un produit de base de données avec une architecture MySQL primaire et secondaire (deux nœuds). Il est recommandé de choisir une architecture multi-copies avec RPO=0.
Communauté MySQL, concernant l'évolution de la technologie multi-copie avec RPO=0 :
- MySQL est officiellement open source et a lancé la solution haute disponibilité MySQL Group Replication (MGR) basée sur la réplication de groupe. Le protocole Paxos est encapsulé en interne via XCOM pour garantir la cohérence des données.
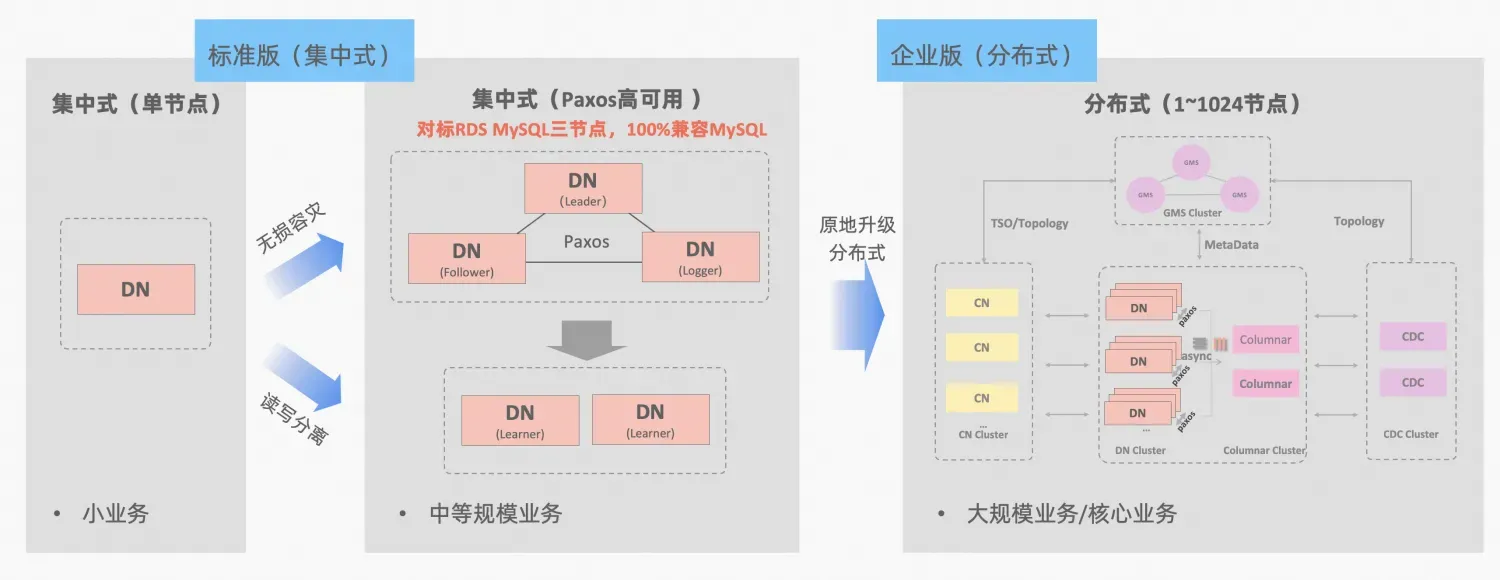
- Ali Nuage PolarDB-X , dérivé du peaufinage et de la vérification commerciaux du commerce électronique Double Eleven d'Alibaba et de la multiactivité dans différents endroits, il sera open source dans l'ensemble du noyau en octobre 2021, embrassant pleinement l'écosystème open source MySQL. PolarDB-X se positionne comme une base de données intégrée centralisée et distribuée. Son nœud de données Data Node (DN) adopte le protocole X-Paxos auto-développé et est hautement compatible avec MySQL 5.7/8.0. Il fournit non seulement des capacités de haute disponibilité au niveau financier. , mais il présente également les caractéristiques d'un moteur de transaction hautement évolutif, d'une reprise après sinistre flexible en matière d'exploitation et de maintenance et d'un stockage de données à faible coût. Référence : "PolarDB-X Open Source | Trois copies de MySQL basées sur Paxos》。
PolarDB-X Le concept d'intégration centralisée et distribuée : le nœud de données DN peut être utilisé indépendamment comme un formulaire centralisé (version standard), entièrement compatible avec le formulaire de base de données autonome. Lorsque l'entreprise se développe au point où une expansion distribuée est nécessaire, l'architecture est mise à niveau vers une forme distribuée en place et les composants distribués sont connectés de manière transparente aux nœuds de données d'origine. Il n'est pas nécessaire de migrer ou de modifier les données du côté des applications. , et vous pouvez profiter de la distribution. La convivialité et l'évolutivité apportées par cette formule, description de l'architecture :"Intégration distribuée centralisée"
Le MGR de MySQL et la version standard DN de PolarDB-X utilisent tous deux le protocole Paxos du principe le plus bas. Alors, quelles sont les performances spécifiques et les différences en utilisation réelle ? Cet article développe les aspects de la comparaison d'architecture, les principales différences et la comparaison de tests.
Description de l'abréviation MGR/DN : MGR représente la forme technique de MySQL MGR et DN représente la forme technique de PolarDB-X single DN centralisé (version standard).
TL;DR
L'analyse comparative détaillée est relativement longue, vous pouvez donc d'abord lire le résumé et la conclusion. Si vous êtes intéressé, vous pouvez suivre le résumé et rechercher des indices dans les articles suivants.
MySQL MGR n'est pas recommandé aux entreprises en général car il nécessite des connaissances techniques professionnelles et une équipe d'exploitation et de maintenance pour bien l'utiliser. Cet article reproduit également trois « pièges cachés » de MySQL MGR qui circulent dans l'industrie depuis longtemps. :
- Dark Pit 1 : les protocoles MySQL MGR et XCOM adoptent le mode mémoire complète. La valeur par défaut n'est pas de respecter la garantie de cohérence des données de RPO=0 (il y aura un problème de données manquantes dans le scénario de test plus loin dans cet article). afficher et configurer un paramètre pour le garantir. Actuellement, la conception de MGR ne peut pas atteindre à la fois les performances et le RPO.
- Piège 2 : les performances de MySQL MGR sont médiocres en cas de retard du réseau. L'article a testé une comparaison de scénarios de réseau de 4 minutes (y compris trois salles informatiques dans la même ville et trois centres à deux endroits). paramètres de performance de la ville, ce n'est que 1/5 de cela dans la même ville, si la garantie de données RPO=0 est activée, les performances seront encore pires.Par conséquent, MySQL MGR est plus adapté à une utilisation dans le même scénario de salle informatique, mais ne convient pas à la reprise après sinistre entre salles informatiques.
- Piège 3 : Dans l'architecture multi-copies de MySQL MGR, la panne du nœud de secours fera chuter le trafic du nœud maître Leader à 0, ce qui n'est pas conforme au bon sens. L'article se concentre sur la tentative d'activer le mode leader unique de MGR (par rapport à l'architecture de réplique maître-esclave précédente de MySQL), en simulant les deux actions de temps d'arrêt et de récupération de la réplique esclave. Les opérations d'exploitation et de maintenance du nœud esclave entraîneront également le maître. Le nœud (Leader) apparaît. Le trafic est tombé à 0 (durée d'environ 10 secondes) et l'opérabilité et la maintenabilité globales étaient relativement médiocres.Par conséquent, MySQL MGR a des exigences relativement élevées en matière d’exploitation et de maintenance de l’hôte et nécessite une équipe DBA professionnelle.
Par rapport à MySQL MGR, PolarDB-X Paxos ne présente pas de pièges similaires à MGR en termes de cohérence des données, de reprise après sinistre entre salles informatiques, ainsi que d'exploitation et de maintenance des nœuds. Cependant, il présente également quelques inconvénients et avantages mineurs en matière de reprise après sinistre :
- Dans un scénario simple de la même salle informatique, les performances en lecture seule sous faible concurrence et les performances d'écriture pure sous haute concurrence sont légèrement inférieures à celles de MySQL MGR d'environ 5 %. Plusieurs copies sont envoyées sur le réseau en même temps, et il est possible d’optimiser davantage les performances.
- Avantages : 100 % compatible avec les fonctionnalités de MySQL 5.7/8.0. Dans le même temps, des optimisations plus rationalisées ont été apportées aux chemins de réplication et de basculement de la base de données de secours multi-copies. RTO de commutation haute disponibilité <= 8 secondes, un temps commun de 4. Scénario de reprise après sinistre d'une minute dans l'industrie. Tous fonctionnent bien et peuvent remplacer la semi-synchronisation (semi-synchronisation), MGR, etc.
1. Comparaison des architectures
Glossaire
Description de l'abréviation MGR/DN :
- MGR : La forme technique de MySQL MGR, l'abréviation du contenu ultérieur : MGR
- DN : Alibaba Cloud PolarDB-X est un formulaire technique centralisé (version standard). Le DN du nœud de données distribué peut être utilisé indépendamment comme formulaire centralisé (version standard). Il est entièrement compatible avec les bases de données autonomes. comme : DN
MGR
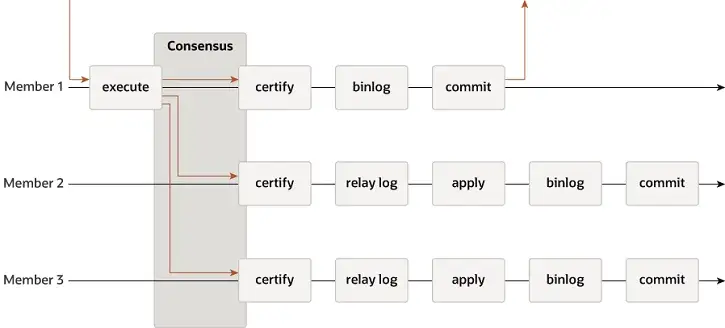
MGR prend en charge les modes mono-maître et multi-maître et réutilise entièrement le système de réplication de MySQL, notamment Event, Binlog & Relaylog, Apply, Binlog Apply Recovery et GTID. La principale différence avec DN est que le point d'entrée permettant à la majorité du journal de transactions MGR d'atteindre un consensus se situe avant la validation de la transaction de la base de données principale.
-
- Avant que la transaction ne soit validée, la fonction hook before_commit group_replication_trans_before_commit est appelée pour entrer dans la réplication majoritaire de MGR.
- MGR utilise le protocole Paxos pour synchroniser les événements Binlog mis en cache sur THD avec tous les nœuds en ligne
- Après avoir reçu la réponse majoritaire, MGR détermine que la transaction peut être soumise
- THD entre dans le processus de soumission du groupe de transactions et commence à écrire la mise à jour locale du Binlog Rétablir le message OK du client de réponse
-
- Le moteur Paxos de MGR continue d'écouter les messages de protocole du leader
- Après un processus de consensus Paxos complet, il est confirmé que cet événement (lot) a atteint la majorité dans le cluster.
- Écrivez l'événement reçu dans le journal de relais, le thread IO applique le journal de relais
- L'application Relay Log passe par un processus complet de soumission de groupe et la base de données de secours générera éventuellement son propre fichier binlog.
La raison pour laquelle MGR adopte le processus ci-dessus est que MGR est en mode multi-maître par défaut et que chaque nœud peut écrire. Par conséquent, le nœud suiveur d'un seul groupe Paxos doit d'abord convertir le journal reçu en RelayLog, puis le combiner. avec la transaction d'écriture qu'il reçoit en tant que leader à soumettre, le fichier Binlog est produit pour soumettre la transaction finale dans le processus de soumission de groupe en deux étapes.
DN
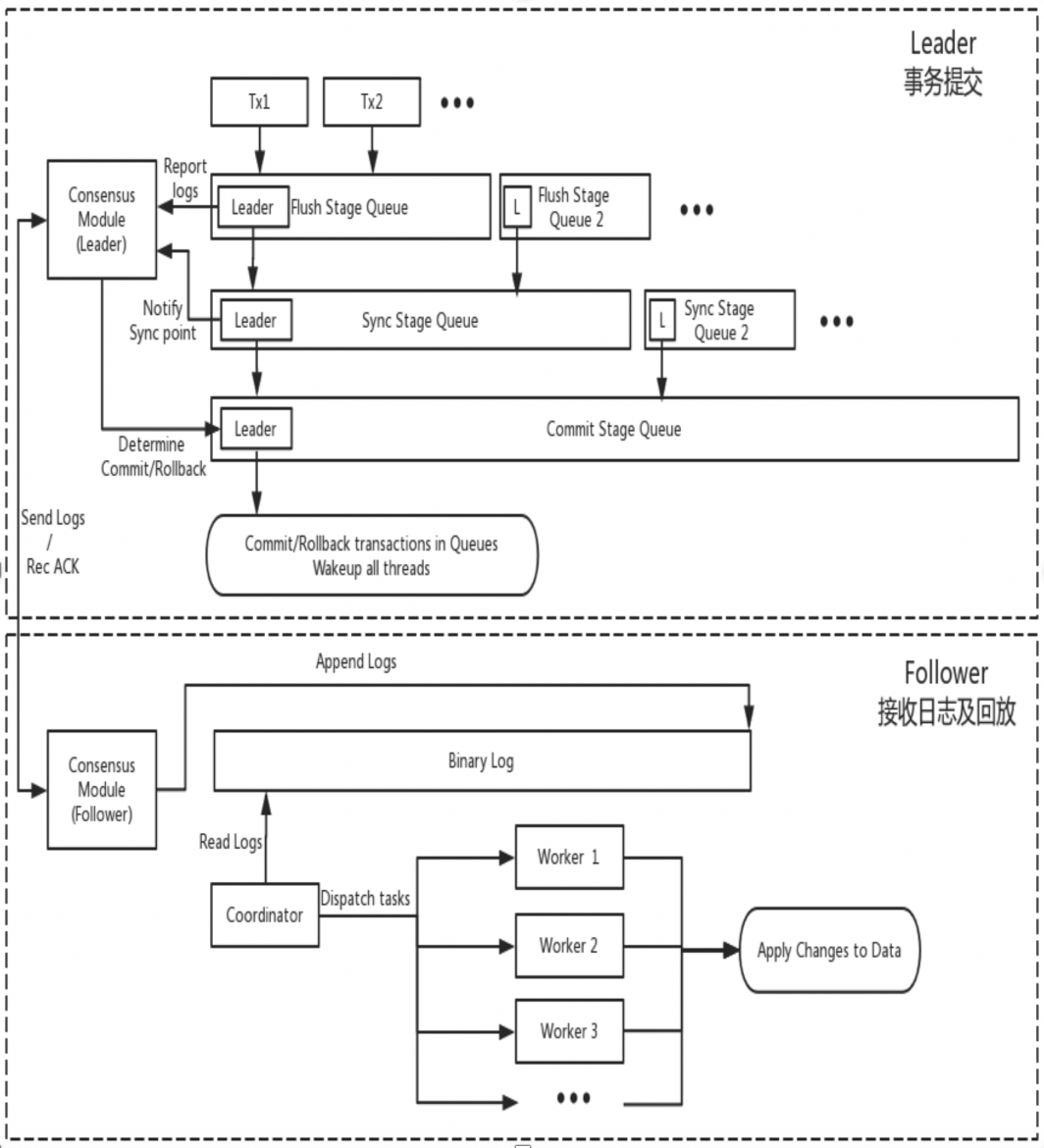
DN réutilise la structure de données de base et le code au niveau des fonctions de MySQL, mais intègre étroitement la réplication des journaux, la gestion des journaux, la lecture des journaux et la récupération après incident avec le protocole X-Paxos pour former son propre ensemble de mécanismes de réplication majoritaire et de machine d'état. La principale différence avec MGR est que le point d'entrée permettant à la majorité du journal de transactions DN d'atteindre un consensus se situe pendant le processus de soumission des transactions de la base de données principale.
-
- Entrez dans le processus de soumission de groupe de la transaction. Dans la phase Flush de la soumission de groupe, les événements sur chaque THD sont écrits dans le fichier Binlog, puis le journal est diffusé de manière asynchrone à tous les abonnés via X-Paxos.
- Dans la phase de synchronisation de la soumission de groupe, le Binlog est d'abord conservé, puis l'emplacement de persistance X-Paxos est mis à jour.
- Dans la phase de validation de la soumission de groupe, vous devez d'abord attendre que X-Paxos reçoive la réponse majoritaire, puis soumettre le groupe de transactions et enfin répondre avec un message OK du client.
-
- X-Paxos continue d'écouter les messages protocolaires du Leader
- Recevez un événement (de groupe), écrivez dans le Binlog local et répondez
- Le message suivant est reçu, qui porte l'index Commit de la position où la majorité a été atteinte.
- Le thread SQL Apply continue d'appliquer le journal Binlog reçu en arrière-plan et ne l'applique qu'à la position majoritaire au maximum.
La raison de cette conception est que DN ne prend actuellement en charge que le mode mono-maître, donc le journal au niveau du protocole X-Paxos est le Binlog Follower lui-même omet également le journal de relais, ainsi que le contenu des données de son journal persistant et du journal du leader. sont égaux au même prix.
2. Principales différences
2.1. Efficacité du protocole Paxos

MGR
- Le protocole Paxos de MGR est implémenté sur la base du protocole Mencius, qui appartient à la théorie Multi-Paxos. La différence est que Mencius a apporté des améliorations d'optimisation en réduisant la charge du nœud maître et en augmentant le débit.
- Le protocole Paxos de MGR est implémenté par les composants XCOM et prend en charge le déploiement en mode multi-maître et mono-maître, le Binlog sur le Leader diffuse atomiquement au nœud Follower la diffusion de chaque lot de messages (une transaction). un processus Multi-Paxos standard.
- Pour satisfaire la majorité d'une transaction, XCOM doit passer par au moins trois interactions de message Accept+AckAccept+Learn, c'est-à-dire :Au moins 1,5 RTT de surcharge.Il nécessite au plus trois interactions de message : Prepare+AckPrepare+Accept+AckAccept+Learn.Autrement dit, un maximum de 2,5 frais généraux RTT au total
- Étant donné que le protocole Paxos est complété avec une cohésion élevée dans le module XCOM et qu'il ne connaît pas le système de réplication MySQL, le leader doit attendre que le processus Paxos complet soit terminé avant de valider la transaction localement, y compris la persistance Binlog et la soumission de groupe.
- Une fois que le suiveur a terminé la soumission majoritaire, il conservera les événements de manière asynchrone dans le journal de relais, puis l'application et le groupe SQL Thread soumettront le Binlog de production.
- Étant donné que le journal synchronisé par Paxos est un Binlog qui n'est pas trié avant d'entrer dans le processus de soumission de groupe, l'ordre des événements Binlog sur le leader peut ne pas être le même que l'ordre des événements dans le journal de relais sur le nœud Follower.

DN
- Le protocole Paxos de DN est implémenté sur la base du protocole Raft et appartient également à la théorie Multi-Paoxs. La différence est que le protocole Raft a une garantie de leadership et une garantie de stabilité technique plus fortes.
- Le protocole Paxos de DN est complété par le composant X-Paoxs. La valeur par défaut est le mode mono-maître. En mode mono-maître, le Binlog sur le Leader diffuse atomiquement vers le nœud Follower. La diffusion de chaque lot de messages est un processus Raft standard. .
- Pour satisfaire la majorité d'une transaction, X-Paoxs n'a besoin que de passer par les deux interactions de message Append+AckAppend, et seulement1 frais généraux RTT
- Une fois que le leader a envoyé le journal au suiveur, tant que la majorité est satisfaite, il valide la transaction sans attendre la diffusion de l'index de validation dans la deuxième étape.
- Avant que Follower puisse terminer la soumission majoritaire, tous les journaux de transactions doivent être conservés. Ceci est très différent du XCOM de MGR. MGR n'a besoin que de les recevoir dans la mémoire XCOM.
- L'index de validation est intégré dans les messages suivants et les messages de battement de cœur, et le suiveur exécute l'événement Apply après que l'index de validation soit augmenté.
- Le contenu Binlog de Leader et Follower est dans le même ordre, les journaux Raft n'ont pas de trous et le mécanisme Batching/Pipeline est utilisé pour augmenter le débit de réplication des journaux.
- Par rapport à MGR, le Leader ne dispose toujours que d’un seul délai aller-retour lorsqu’une transaction est validée., très critique pour les applications distribuées sensibles aux délais
2.2. RPO
Théoriquement, Paxos et Raft peuvent garantir la cohérence des données et les journaux qui ont atteint la majorité après Crash Recovery ne seront pas perdus, mais il existe encore des différences selon les projets spécifiques.
MGR
XCOM encapsule complètement le protocole Paxos et toutes ses données de protocole sont d'abord mises en cache en mémoire. Par défaut, les transactions atteignant la majorité ne nécessitent pas de persistance du journal. Dans le cas où la plupart des tartes sont perdues et que le Leader échoue, il y aura un sérieux problème de RPO != 0.Supposons un scénario extrême :
- Le cluster MGR se compose de trois nœuds ABC, dont AB est une salle informatique indépendante dans la même ville et C est un nœud interurbain. A est le leader, BC est le nœud suiveur
- Initiez la transaction 001 sur le nœud Leader A. Leader A diffuse le journal de la transaction 001 au nœud BC Si la majorité est satisfaite via le protocole Paxos, la transaction peut être considérée comme soumise. La section AB constituait la majorité et le nœud C n'a pas reçu le journal de la transaction 001 en raison du retard du réseau interurbain.
- Au moment suivant, le leader A soumet la transaction 001 et renvoie le succès du client, ce qui signifie que la transaction 001 a été soumise à la base de données.
- A ce moment, sur le Follower du nœud B, le log de la transaction 001 est toujours dans le cache XCOM et n'a pas eu le temps d'être vidé vers le RelayLog ; à ce moment, le Follower du nœud C n'a toujours pas reçu la transaction 001 ; log du leader du nœud A.
- À ce stade, le nœud AB est en panne, le nœud A échoue et ne peut pas être récupéré pendant une longue période, le nœud B redémarre et récupère rapidement et les nœuds BC continuent de fournir des services de lecture et d'écriture.
- Étant donné que le journal de la transaction 001 n'a pas été conservé dans le RelayLog du nœud B pendant le temps d'arrêt et qu'il n'a pas été reçu par le nœud C, à ce moment-là, le nœud BC a en fait perdu la transaction 001 et ne peut pas la récupérer.
- Dans ce scénario où le parti majoritaire est en baisse, RPO!=0
Selon les paramètres par défaut de la communauté, la majorité des transactions ne nécessitent pas de persistance du journal et ne garantissent pas un RPO=0. Cela peut être considéré comme un compromis en termes de performances dans la mise en œuvre du projet XCOM. Pour garantir un RPO=0 absolu, vous devez configurer le paramètre group_replication_consistency qui contrôle la cohérence de lecture et d'écriture sur AFTER. Cependant, dans ce cas, en plus de la surcharge réseau de 1,5 RTT, la transaction nécessitera une surcharge d'E/S de journal pour atteindre la majorité. et la performance sera très mauvaise.
DN
PolarDB-X DN utilise X-Paxos pour implémenter un protocole distribué et est profondément lié au processus de validation de groupe de MySQL. Lorsqu'une transaction est soumise, la majorité est requise pour confirmer le placement et la persistance avant que la soumission réelle ne soit autorisée. La majeure partie de l'emplacement du disque fait ici référence à l'emplacement Binlog de la bibliothèque principale. Le thread IO de la bibliothèque de secours reçoit le journal de la bibliothèque principale et l'écrit dans son propre Binlog pour la persistance. Par conséquent, même si tous les nœuds échouent dans des scénarios extrêmes, les données ne seront pas perdues et le RPO=0 peut être garanti.
2.3. RTO
Le temps RTO est étroitement lié au temps nécessaire au redémarrage à froid du système lui-même, qui se reflète dans les fonctions de base spécifiques :Mécanisme de détection des défauts->mécanisme de récupération après incident->mécanisme de sélection du maître->équilibrage des journaux
2.3.1. Détection des défauts
MGR
- Chaque nœud envoie périodiquement des paquets de battement de cœur à d'autres nœuds pour vérifier si les autres nœuds sont sains. La période de battement de cœur est fixée à 1 s et ne peut pas être ajustée.
- Si le nœud actuel constate que les autres nœuds n'ont pas répondu après group_replication_member_expel_timeout (par défaut 5 s), il sera considéré comme un nœud défaillant et sera expulsé du cluster.
- Pour les exceptions telles qu'une interruption du réseau ou un redémarrage anormal, une fois le réseau restauré, un seul nœud défaillant tentera de rejoindre automatiquement le cluster, puis bloquera le journal.
DN
- Le nœud Leader envoie périodiquement des paquets de pulsation à d'autres nœuds pour vérifier si les autres nœuds sont sains. La période de pulsation est égale à 1/5 du délai d'expiration de l'élection. Le délai d'expiration des élections est contrôlé par le paramètre consensus_election_timeout. La valeur par défaut est de 5 s, donc la période de pulsation du nœud leader est par défaut de 1 s.
- Si le leader constate que d'autres nœuds sont hors ligne, il continuera à envoyer périodiquement des paquets de battements de cœur à tous les autres nœuds pour garantir que les autres nœuds puissent y accéder à temps après leur panne et leur récupération.Toutefois, le nœud Leader n'envoie plus de journaux de transactions au nœud hors ligne.
- Les nœuds non leaders n'envoient pas de paquets de détection de battement de cœur, mais si le nœud non leader constate qu'il n'a pas reçu le battement de cœur du nœud leader après consensus_election_timeout, une réélection sera déclenchée.
- Pour les exceptions telles qu'une interruption du réseau ou un redémarrage anormal, une fois le réseau restauré, le nœud défectueux rejoindra automatiquement le cluster.
- Par conséquent, en termes de détection des pannes, DN fournit davantage d'interfaces de configuration d'exploitation et de maintenance, et l'identification des pannes dans les scénarios de déploiement inter-villes sera plus précise.
2.3.2. Récupération après incident
MGR
-
- Le protocole Paxos implémenté par XCOM est en état de mémoire. L'obtention de la majorité ne nécessite pas de persistance. L'état du protocole est basé sur l'état de la mémoire du nœud majoritaire survivant.Si tous les nœuds raccrochent, le protocole ne peut pas être restauré. Une fois le cluster redémarré, une intervention manuelle est nécessaire pour le restaurer.
- Si un seul nœud tombe en panne et est récupéré, mais que le nœud Follower est en retard sur le nœud Leader avec plus de journaux de transactions et que les journaux de transactions mis en cache XCOM sur le Leader ont été effacés, la seule option consiste à utiliser le processus de récupération globale ou de clonage.
- La taille du cache XCOM est contrôlée par group_replication_message_cache_size, la valeur par défaut est 1 Go
- La récupération globale signifie que lorsqu'un nœud rejoint le cluster, il récupère les données en obtenant les journaux de transactions manquants requis (journal binaire) auprès d'autres nœuds.Ce processus repose sur au moins un nœud du cluster qui conserve tous les journaux de transactions requis.
- Clone s'appuie sur Clone Plugin, qui est utilisé pour la récupération lorsque la quantité de données est importante ou que de nombreux journaux sont manquants.Cela fonctionne en copiant un instantané de l'intégralité de la base de données sur le nœud en panne, suivi d'une synchronisation finale avec le dernier journal des transactions.
- Les processus de récupération globale et de clonage sont généralement automatisés, mais dans certains cas particuliers, tels que des problèmes de réseau ou le cache XCOM des deux autres nœuds a été vidé, une intervention manuelle est requise.
DN
-
- Le protocole X-Paxos utilise la persistance Binlog. Lors de la récupération après un crash, les transactions soumises seront d'abord entièrement restaurées. Pour les transactions en attente, vous devez attendre que la couche de protocole XPaxos parvienne à un accord pour déterminer la relation maître-sauvegarde avant de valider ou d'annuler la transaction. L'ensemble du processus est entièrement automatisé.Même si tous les nœuds sont en panne, le cluster peut automatiquement récupérer après le redémarrage.
- Pour les scénarios dans lesquels le nœud Follower est en retard par rapport au nœud Leader dans de nombreux journaux de transactions, tant que le fichier Binlog sur le Leader n'est pas supprimé, le nœud Follower rattrapera définitivement son retard.
- Par conséquent, en termes de récupération après incident, DN ne nécessite aucune intervention manuelle.
2.3.3. Choisir le dirigeant
En mode maître unique, XCOM de MGR et DN X-Paxos, un mode leader puissant, suivent le même principe de base pour la sélection du leader : les journaux convenus par le cluster ne peuvent pas être annulés. Mais lorsqu’il s’agit du constat de non-consensus, il existe des différences
MGR
- La sélection du leader concerne davantage le nœud qui servira ensuite de service Leader.Ce leader ne dispose pas nécessairement du dernier journal de consensus lorsqu'il est élu, il doit donc synchroniser les derniers journaux des autres nœuds du cluster et fournir des services de lecture et d'écriture une fois les journaux liés.
- L'avantage est que le choix du Leader lui-même est un produit stratégique, comme le poids et l'ordre. MGR contrôle le poids de chaque nœud via le paramètre group_replication_member_weight
- L'inconvénient est que le leader nouvellement élu lui-même peut avoir un retard de réplication important et doit continuer à rattraper le journal, ou peut avoir un retard d'application important et doit continuer à rattraper l'application de journal avant de pouvoir fournir des informations de lecture et de lecture. écrire des services.Cela se traduit par un temps RTO plus long
DN
- L'élection du leader est au sens du protocole. Quel que soit le nœud qui possède les journaux de tous les partis majoritaires du cluster, il peut être élu chef, ce nœud peut donc avoir été un suiveur ou un enregistreur auparavant.
- Le Logger ne peut pas fournir de services de lecture et d'écriture. Après avoir synchronisé les journaux avec d'autres nœuds, il abandonnera activement le rôle de Leader.
- Afin de garantir que le nœud désigné devient le leader, DN utilise la stratégie de pondération optimiste + la stratégie de pondération obligatoire pour limiter l'ordre de devenir le leader, et utilise le mécanisme de majorité stratégique pour garantir que le nouveau maître peut immédiatement fournir des lectures et des écritures. services sans délai.
- Par conséquent, en termes de sélection des leaders, DN prend non seulement en charge la même sélection stratégique que MGR, mais prend également en charge les stratégies de pondération obligatoires.
2.3.4. Correspondance des journaux
L'égalisation des journaux signifie qu'il existe un délai de réplication des journaux entre les bases de données principale et secondaire, et que la base de données secondaire doit égaliser les journaux. Pour les nœuds redémarrés et restaurés, la récupération est généralement démarrée avec la base de données de secours, et un retard de réplication des journaux s'est déjà produit par rapport à la base de données principale, et les journaux doivent être rattrapés par la base de données principale. Pour les nœuds physiquement éloignés du leader, atteindre la majorité n'a généralement rien à voir avec eux. Ils ont toujours un retard dans le journal de réplication et rattrapent toujours le journal. Ces situations nécessitent une mise en œuvre d’ingénierie spécifique pour garantir une résolution rapide des retards de réplication des journaux.
MGR
- Les journaux de transactions sont tous dans le cache XCOM, et le cache n'est que de 1 Go par défaut. Par conséquent, lorsqu'un nœud suiveur qui est loin en retard dans la réplication des journaux de demandes, il est facile de vider le cache.
- À ce stade, le suiveur en retard sera automatiquement expulsé du cluster, puis utilisera le processus de récupération globale ou de clonage mentionné ci-dessus pour la récupération après incident, puis rejoindra automatiquement le cluster après avoir rattrapé son retard.Si vous rencontrezPar exemple, des problèmes de réseau ou le cache XCOM des deux autres nœuds est effacé, auquel cas une intervention manuelle est nécessaire pour résoudre le problème.
- Pourquoi devons-nous d'abord expulser le cluster ? Parce que le nœud défectueux en mode multi-écriture affecte grandement les performances et que le cache du leader n'a aucun effet sur celui-ci. Il doit être ajouté après la connexion asynchrone.
- Pourquoi ne pouvons-nous pas lire directement le fichier Binlog local du Leader ? Parce que le protocole XCOM mentionné précédemment est en mémoire pleine et qu'il n'y a aucune information de protocole sur XCOM dans le Binlog et le journal de relais.
DN
- Les données sont toutes dans le fichier Binlog. Tant que le Binlog n'est pas nettoyé, il peut être envoyé à la demande et il n'y a aucune possibilité d'être expulsé du cluster.
- Afin de réduire la gigue des E/S provoquée par la lecture par la bibliothèque principale des anciens journaux de transactions à partir du fichier Binlog, DN donne la priorité à la lecture des journaux de transactions les plus récemment mis en cache à partir du cache FIFO. Le cache FIFO est contrôlé par le paramètre consensus_log_cache_size et par défaut. est 64M
- Si l'ancien journal des transactions dans le cache FIFO a été éliminé par le journal des transactions mis à jour, DN tentera de lire le journal des transactions précédemment mis en cache à partir du cache Prefetch. Le cache Prefetch est contrôlé par le paramètre consensus_prefetch_cache_size et la valeur par défaut est 64 Mo.
- S'il n'y a pas d'ancien journal de transactions requis dans le cache de prélecture, DN tentera de lancer une tâche d'E/S asynchrone, lira plusieurs journaux consécutifs avant et après le journal de transactions spécifié à partir du fichier Binlog par lots, les placera dans le cache de prélecture et attendra. pour la prochaine tentative de lecture de DN.
- Par conséquent, DN ne nécessite aucune intervention manuelle lorsqu’il s’agit d’équilibrer les journaux.
2.4. Délai de lecture de la base de données en veille
Le délai de lecture de la base de données de secours est le délai entre le moment où la même transaction est terminée dans la base de données principale et le moment où la transaction est appliquée dans la base de données de secours. Ce qui est testé ici, ce sont les performances du journal d'application de la base de données de secours. Cela affecte le temps nécessaire à la base de données de secours pour terminer son application de données et fournir des services de lecture et d'écriture lorsqu'une exception se produit.
MGR
- La base de données de secours MGR reçoit le fichier RelayLog de la base de données principale Lors de l'application de l'application, elle doit relire le RelayLog, passer par un processus complet de soumission de groupe en deux étapes et produire les données et les fichiers Binlog correspondants.
- L'efficacité de l'application de transaction ici est la même que l'efficacité de la soumission des transactions sur la base de données principale. La configuration double-un par défaut (innodb_flush_log_at_trx_commit, sync_binlog) entraînera une surcharge de ressources similaire à celle de l'application de base de données de secours.
DN
- La base de données de sauvegarde DN reçoit le fichier Binlog de la base de données principale Lors de l'application, le Binlog doit être relu. Il lui suffit de passer par le processus de soumission de groupe en une étape et de produire les données correspondantes.
- Étant donné que DN prend en charge la récupération complète sur incident, l'application de base de données de secours n'a pas besoin d'activer innodb_flush_log_at_trx_commit=1, elle n'est donc pas réellement affectée par la configuration double-un.
- Par conséquent, en termes de délai de lecture de la base de données en veille, l'efficacité de la lecture de la base de données en veille DN sera bien supérieure à celle de MGR.
2.5. Impact des événements majeurs
Les transactions importantes affectent non seulement la soumission des transactions ordinaires, mais affectent également la stabilité de l'ensemble du protocole distribué dans un système distribué. Dans les cas graves, une transaction importante entraînera une indisponibilité prolongée de l'ensemble du cluster.
MGR
- MGR n'a aucune optimisation pour prendre en charge les transactions volumineuses. Il ajoute simplement le paramètre group_replication_transaction_size_limit pour contrôler la limite supérieure des transactions volumineuses. La valeur par défaut est de 143 Mo et le maximum est de 2 Go.
- Lorsque le journal des transactions dépasse la limite des transactions importantes, une erreur sera directement signalée et la transaction ne pourra pas être soumise.
DN
- Afin de résoudre le problème d'instabilité des systèmes distribués causé par des transactions volumineuses, DN adopte la solution de fractionnement des transactions volumineuses + fractionnement des objets volumineux pour résoudre le problème. DN divisera logiquement + physiquement le journal des transactions des transactions volumineuses. petits blocs, chaque petit bloc du journal des transactions utilise la garantie de validation Paxos complète
- Basé sur la solution de fractionnement des transactions volumineuses, DN n'impose aucune restriction sur la taille des transactions volumineuses. Les utilisateurs peuvent les utiliser à volonté et peuvent également garantir un RPO = 0.
- Pour des instructions détaillées, voir"Technologie de base du moteur de stockage PolarDB-X | Optimisation des transactions importantes"
- Par conséquent, DN peut gérer des affaires à grande échelle sans être affecté par des affaires à grande échelle.
2.6. Formulaire de déploiement
MGR
- MGR prend en charge les modes de déploiement mono-maître et multi-maître. En mode multi-maître, chaque nœud peut être lu et écrit. En mode mono-maître, la base de données principale peut être lue et écrite, et la base de données de secours ne peut être que lue. seulement.
- Le déploiement haute disponibilité MGR nécessite au moins trois déploiements de nœuds, c'est-à-dire au moins trois copies de données et de journaux. Le mode Logger n'est pas pris en charge.
- MGR ne prend pas en charge l'expansion des nœuds en lecture seule, mais il prend en charge la combinaison du mode de réplication MGR + maître-esclave pour obtenir une expansion de topologie similaire.
DN
- DN prend en charge le déploiement en mode maître unique. En mode maître unique, la base de données principale peut être lue et écrite, et la base de données de secours ne peut être qu'en lecture seule.
- Le déploiement haute disponibilité DN nécessite au moins trois nœuds, mais prend en charge le formulaire Logger de copie de journal, c'est-à-dire que Leader et Follower sont des copies complètes. Par rapport à Logger, il ne contient que des journaux et aucune donnée, et n'a pas le droit de l'être. élu. Dans ce cas, le déploiement haute disponibilité à trois nœuds ne nécessite que la surcharge de stockage de 2 copies de données + 3 copies de journaux, ce qui en fait un déploiement à faible coût.
- DN prend en charge le déploiement de nœuds en lecture seule et la copie en lecture seule du formulaire d'apprenant. Par rapport aux copies complètes, il n'a que des droits de vote. Grâce aux copies d'apprenant, la consommation d'abonnement en aval à la bibliothèque principale est réalisée.

2.7. Résumé des fonctionnalités
| | MGR | DN |
| Efficacité du protocole | Heure de soumission des transactions | 1,5 à 2,5 RTT | 1 RTT |
| | Persistance majoritaire | Sauvegarde de la mémoire XCOM | Persistance du journal binaire |
| fiabilité | RPO=0 | Non garanti par défaut | Entièrement garanti |
| | Détection de fautes | Tous les nœuds se vérifient mutuellement, la charge du réseau est élevée Le cycle de battement de coeur ne peut pas être ajusté | Le nœud maître vérifie périodiquement les autres nœuds Les paramètres du cycle de battement de coeur sont réglables |
| | Récupération de l’effondrement majoritaire | intervention manuelle | Récupération automatique |
| | Récupération après incident minoritaire | Récupération automatique dans la plupart des cas, intervention manuelle dans des circonstances particulières | Récupération automatique |
| | Choisissez le maître | Spécifiez librement l'ordre de sélection | Spécifiez librement l'ordre de sélection |
| Attache de bûche | Les journaux en retard ne peuvent pas dépasser 1 Go de cache XCOM | Les fichiers BInlog ne sont pas supprimés |
| Délai de lecture de la base de données en veille | Deux étapes + une double, très lente | Une étape + double zéro, plus rapide |
| Grosse affaire | La limite par défaut n'est pas supérieure à 143 Mo | Aucune limite de taille |
| formulaire | Coût de haute disponibilité | Trois copies entièrement fonctionnelles, 3 copies de surcharge de stockage de données | Copie du journal de l'enregistreur, 2 copies du stockage des données |
| nœud en lecture seule | Implémenté avec la réplication maître-esclave | Le protocole est livré avec une implémentation de copie en lecture seule plus allégée |
3. Comparaison des tests
MGR a été introduit dans MySQL 5.7.17, mais davantage de fonctionnalités liées à MGR ne sont disponibles que sur MySQL 8.0, et dans MySQL 8.0.22 et versions ultérieures, les performances globales seront plus stables et fiables. Par conséquent, nous avons sélectionné la dernière version 8.0.32 des deux parties pour des tests comparatifs.
Étant donné qu'il existe des différences dans les environnements de test, les méthodes de compilation, les méthodes de déploiement, les paramètres de fonctionnement et les méthodes de test lors des tests comparatifs de PolarDB-X DN et MySQL MGR, ce qui peut conduire à des données de comparaison de tests inexactes, cet article se concentrera sur divers détails. . Procédez comme suit:
| la préparation du test | Nom de domaine PolarDB-X | MySQL MGR[1] |
| Environnement matériel | Utiliser la même machine physique avec une mémoire 96C de 754 Go et un disque SSD |
| système opérateur | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| Version du noyau | Utilisation d'une base de référence du noyau basée sur la version communautaire 8.0.32 |
| Méthode de compilation | Compiler avec le même RelWithDebInfo |
| Paramètres de fonctionnement | Utilisez le même site officiel PolarDB-X pour vendre le 32C128G avec les mêmes spécifications et paramètres |
| Méthode de déploiement | Mode maître unique |
Note:
- MGR a le contrôle de flux activé par défaut, tandis que PolarDB-X DN a le contrôle de flux désactivé par défaut.Par conséquent, le group_replication_flow_control_mode de MGR est configuré séparément afin que les performances de MGR soient les meilleures.
- MGR a un goulot d'étranglement évident en matière de lecture pendant l'énumération, donc replication_optimize_for_static_plugin_config de MGR est configuré et activé séparément, afin que les performances en lecture seule de MGR soient les meilleures.
3.1. Performances
Les tests de performances sont la première chose à laquelle tout le monde prête attention lors de la sélection d’une base de données. Ici, nous utilisons l'outil officiel sysbench pour créer 16 tables, chacune contenant 10 millions de données, afin d'effectuer des tests de performances dans des scénarios OLTP, et de tester et comparer les performances des deux dans différentes conditions de concurrence dans différents scénarios OLTP.Compte tenu des différentes situations de déploiement réel, nous simulons respectivement les quatre scénarios de déploiement suivants :
- Trois nœuds sont déployés dans la même salle informatique. Il y a un délai réseau de 0,1 ms lorsque les machines se cinglent.
- Trois centres dans la même ville et trois salles informatiques dans la même région déploient trois nœuds. Il y a un délai réseau de 1 ms dans le ping entre les salles informatiques (par exemple : trois salles informatiques à Shanghai).
- Trois centres en deux endroits, trois nœuds déployés dans trois salles informatiques en deux endroits, ping réseau de 1 ms entre les salles informatiques d'une même ville, délai réseau de 30 ms entre la même ville et un autre endroit (par exemple : Shanghai/Shanghai/Shenzhen)
- Trois centres en trois endroits, trois nœuds déployés dans trois salles informatiques à trois endroits (par exemple : Shanghai/Hangzhou/Shenzhen), le délai de réseau entre Hangzhou et Shanghai est d'environ 5 ms, et la distance la plus éloignée de Hangzhou/Shanghai à Shenzhen est de 30 ms. .
illustrer:
a. Considérez la comparaison horizontale des performances de quatre scénarios de déploiement. Trois centres en deux endroits et trois centres en trois endroits adoptent tous le mode de déploiement de 3 copies. L'activité de production réelle peut être étendue au mode de déploiement de 5 copies.
b. Compte tenu des restrictions strictes sur RPO=0 lors de l'utilisation de produits de base de données à haute disponibilité, MGR est configuré avec RPO<>0 par défaut. Ici, nous continuerons à ajouter des tests comparatifs entre MGR RPO<>0 et RPO=0 dans chacun. scénario de déploiement.
- MGR_0 représente les données pour le cas de MGR RPO = 0
- MGR_1 représente les données pour le cas de MGR RPO <> 0
- DN représente les données pour le cas de DN RPO = 0
3.1.1. Même salle informatique
| | | 1 | 4 | 16 | 64 | 256 |
| oltp_lecture_seule | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 |
| MGR_0 contre MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% |
| DN contre MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% |
| DN contre MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% |
| lecture_écriture_oltp | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 |
| MGR_0 contre MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% |
| DN contre MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% |
| DN contre MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% |
| oltp_write_only | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 |
| MGR_0 contre MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% |
| DN contre MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% |
| DN contre MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
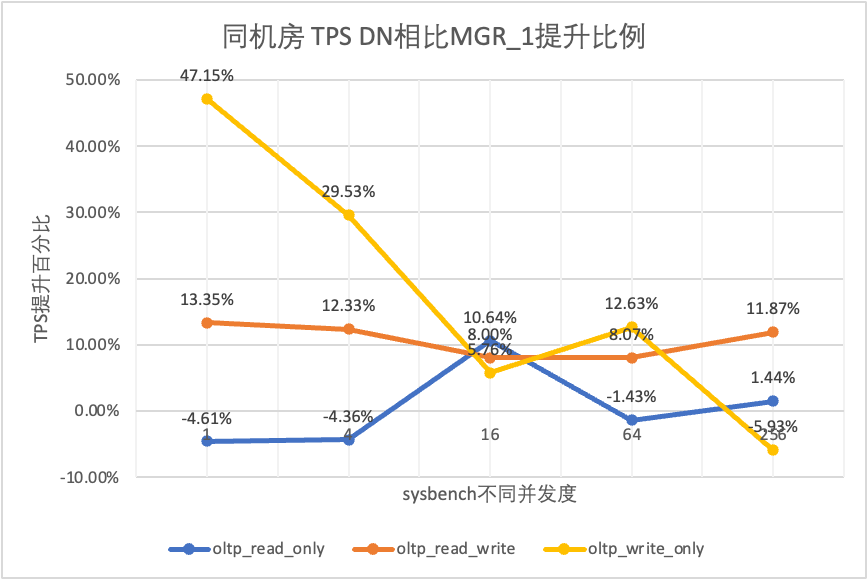
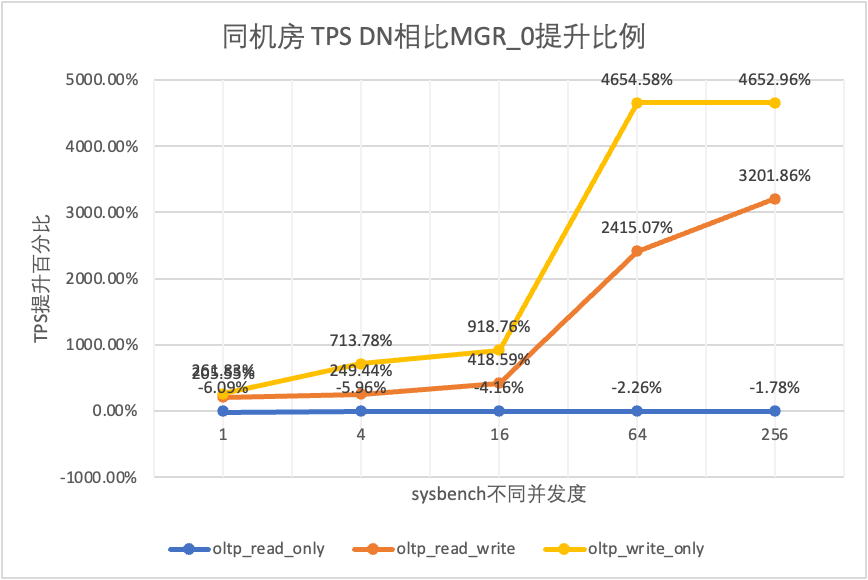
Il ressort des résultats des tests :
- Dans le scénario en lecture seule, que ce soit en comparant MGR_1 (RPO<>0) ou MGR_0 (RPO=0), la différence entre DN et MGR est stable entre -5 % et 10 %, ce qui peut être considéré comme fondamentalement la même. Que le RPO soit égal à 0 n'a aucun effet sur les transactions en lecture seule
- Dans le scénario de transaction mixte lecture-écriture et écriture seule, les performances de DN (RPO=0) sont améliorées de 5 % à 47 % par rapport à MGR_1 (RPO<>0), et l'avantage en termes de performances de DN est évident lorsque le la concurrence est faible et l'avantage lorsque la concurrence est élevée Caractéristiques peu évidentes. En effet, l'efficacité du protocole DN est plus élevée lorsque la concurrence est faible, mais les points chauds de performances de DN et MGR en cas de concurrence élevée sont tous en cours de nettoyage.
- Dans le même principe de RPO=0, dans des scénarios de transactions mixtes en lecture-écriture et en écriture seule, les performances de DN sont améliorées de 2 à 46 fois par rapport à MGR_0, et à mesure que la concurrence augmente, l'avantage en termes de performances de DN est amélioré. Pas étonnant que MGR abandonne également RPO=0 pour les performances par défaut.
3.1.2. Trois centres dans la même ville
| Comparaison TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_lecture_seule | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 |
| MGR_0 contre MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% |
| DN contre MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% |
| DN contre MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% |
| lecture_écriture_oltp | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 |
| MGR_0 contre MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% |
| DN contre MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% |
| DN contre MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% |
| oltp_write_only | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 |
| MGR_0 contre MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% |
| DN contre MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% |
| DN contre MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Il ressort des résultats des tests :
- Dans le scénario en lecture seule, que ce soit en comparant MGR_1 (RPO<>0) ou MGR_0 (RPO=0), la différence entre DN et MGR est stable entre -7 % et 5 %, ce qui peut être considéré comme fondamentalement la même. Que le RPO soit égal à 0 n'a aucun effet sur les transactions en lecture seule
- Dans un scénario de transaction mixte en lecture-écriture et en écriture seule, les performances de DN (RPO=0) sont améliorées de 30 % à 120 % par rapport à MGR_1 (RPO<>0), et l'avantage en termes de performances de DN est évident en cas de concurrence est faible, et lorsque la concurrence est élevée, les performances sont meilleures Caractéristiques peu évidentes. En effet, l'efficacité du protocole DN est plus élevée lorsque la concurrence est faible, mais les points chauds de performances de DN et MGR en cas de concurrence élevée sont tous en cours de nettoyage.
- Dans le même principe de RPO=0, dans des scénarios de transactions mixtes en lecture-écriture et en écriture seule, les performances de DN sont améliorées de 1 à 14 fois par rapport à MGR_0, et à mesure que la concurrence augmente, l'avantage en termes de performances de DN est amélioré. Pas étonnant que MGR abandonne également RPO=0 pour les performances par défaut.
3.1.3. Deux lieux et trois centres
| Comparaison TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_lecture_seule | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 |
| MGR_0 contre MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% |
| DN contre MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% |
| DN contre MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% |
| lecture_écriture_oltp | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 |
| MGR_0 contre MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% |
| DN contre MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% |
| DN contre MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% |
| oltp_write_only | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 |
| MGR_0 contre MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% |
| DN contre MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% |
| DN contre MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
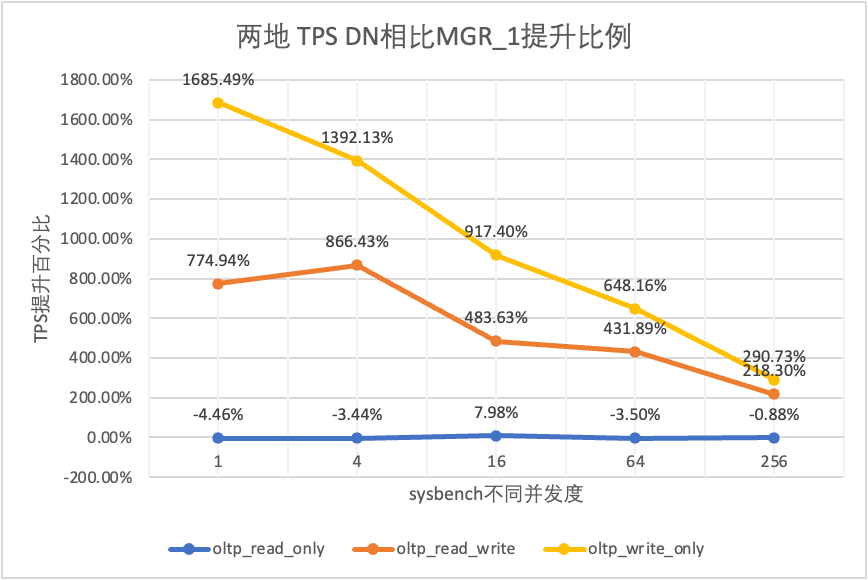
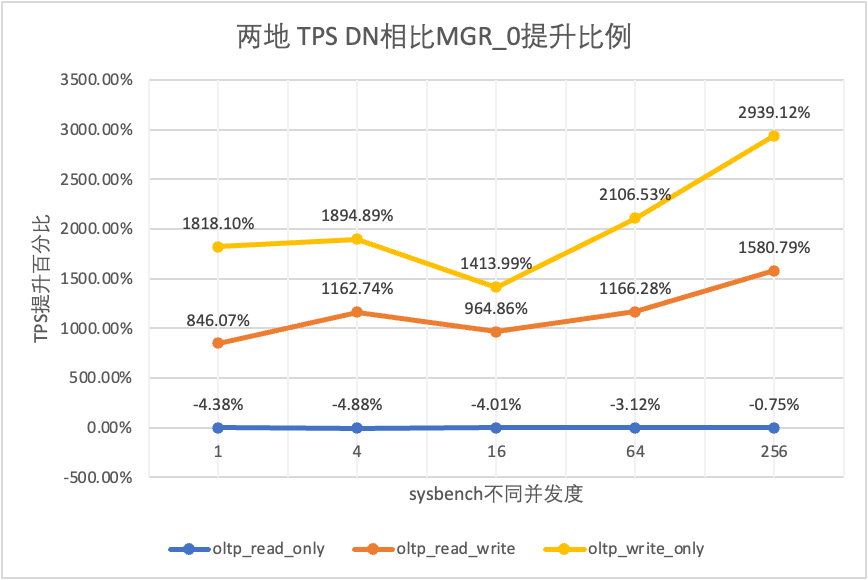
Il ressort des résultats des tests :
- Dans le scénario en lecture seule, que ce soit en comparant MGR_1 (RPO<>0) ou MGR_0 (RPO=0), la différence entre DN et MGR est stable entre -4 % et 7 %, ce qui peut être considéré comme fondamentalement la même. Que le RPO soit égal à 0 n'a aucun effet sur les transactions en lecture seule
- Dans le scénario de transaction mixte en lecture-écriture et en écriture seule, les performances de DN (RPO=0) sont améliorées de 2 à 16 fois par rapport à MGR_1 (RPO<>0), et l'avantage en termes de performances de DN est évident en cas de concurrence est faible, et l'avantage lorsque la concurrence est élevée Caractéristiques peu évidentes. En effet, l'efficacité du protocole DN est plus élevée lorsque la concurrence est faible, mais les points chauds de performances de DN et MGR en cas de concurrence élevée sont tous en cours de nettoyage.
- Dans le même principe de RPO=0, dans des scénarios de transactions mixtes en lecture-écriture et en écriture seule, les performances de DN sont améliorées de 8 à 29 fois par rapport à MGR_0, et à mesure que la concurrence augmente, l'avantage en termes de performances de DN est amélioré. Pas étonnant que MGR abandonne également RPO=0 pour les performances par défaut.
3.1.4. Trois lieux et trois centres
| Comparaison TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_lecture_seule | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 |
| MGR_0 contre MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% |
| DN contre MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% |
| DN contre MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% |
| lecture_écriture_oltp | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 |
| MGR_0 contre MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% |
| DN contre MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% |
| DN contre MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% |
| oltp_write_only | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 |
| MGR_0 contre MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% |
| DN contre MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% |
| DN contre MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
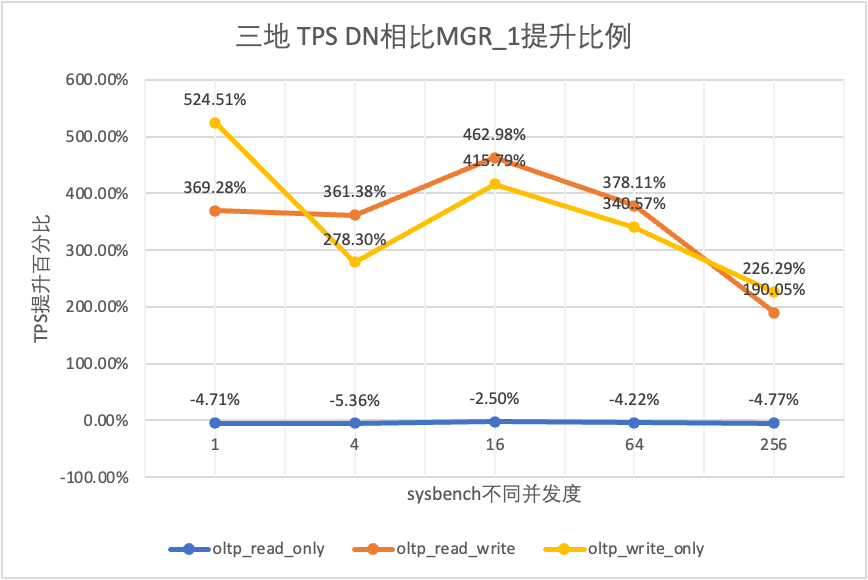
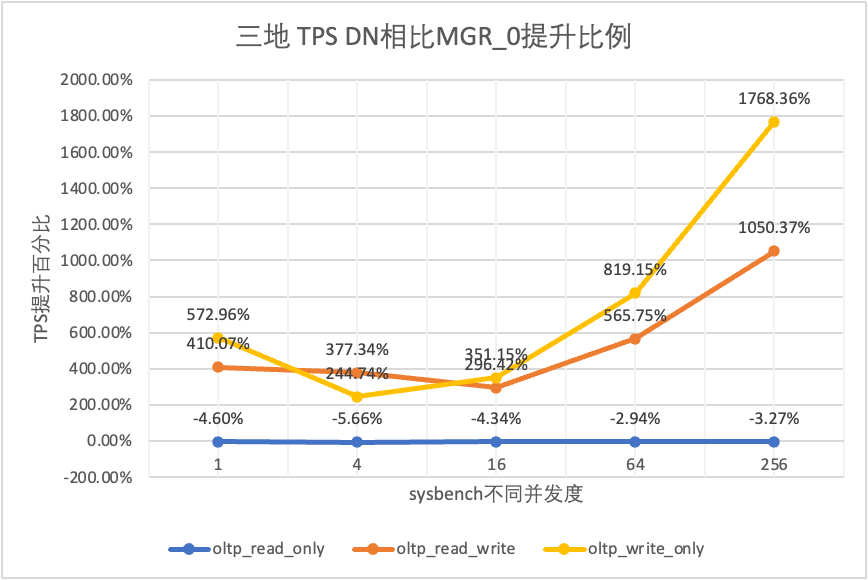
Il ressort des résultats des tests :
- Dans le scénario en lecture seule, que ce soit en comparant MGR_1 (RPO<>0) ou MGR_0 (RPO=0), la différence entre DN et MGR est stable entre -5 % et 0 %, ce qui peut être considéré comme fondamentalement la même. Que le RPO soit égal à 0 n'a aucun effet sur les transactions en lecture seule
- Dans le scénario de transaction mixte en lecture-écriture et en écriture seule, les performances de DN (RPO=0) sont améliorées de 2 à 5 fois par rapport à MGR_1 (RPO<>0), et l'avantage en termes de performances de DN est évident en cas de concurrence est faible, et l'avantage lorsque la concurrence est élevée Caractéristiques peu évidentes. En effet, l'efficacité du protocole DN est plus élevée lorsque la concurrence est faible, mais les points chauds de performances de DN et MGR en cas de concurrence élevée sont tous en cours de nettoyage.
- Dans le même principe de RPO=0, dans des scénarios de transactions mixtes en lecture-écriture et en écriture seule, les performances de DN sont améliorées de 2 à 17 fois par rapport à MGR_0, et à mesure que la concurrence augmente, l'avantage en termes de performances de DN est amélioré. Pas étonnant que MGR abandonne également RPO=0 pour les performances par défaut.
3.1.5. Comparaison de déploiement
Afin de comparer clairement les changements de performances sous différentes méthodes de déploiement, nous avons sélectionné les données TPS de MGR et DN sous différentes méthodes de déploiement dans le cadre de la concurrence du scénario oltp_write_only 256 dans le test ci-dessus en utilisant les données de test de la salle informatique comme référence, nous avons calculé et. a comparé les données TPS de différentes méthodes de déploiement par rapport à la référence pour percevoir la différence dans les changements de performances lors du déploiement inter-villes.
| | MGR_1 (256 simultanés) | DN (256 simultanés) | Avantages en termes de performances du DN par rapport au MGR |
| Même salle informatique | 16092.02 | 15137.23 | -5.93% |
| Trois centres dans la même ville | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Deux lieux et trois centres | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Trois lieux et trois centres | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
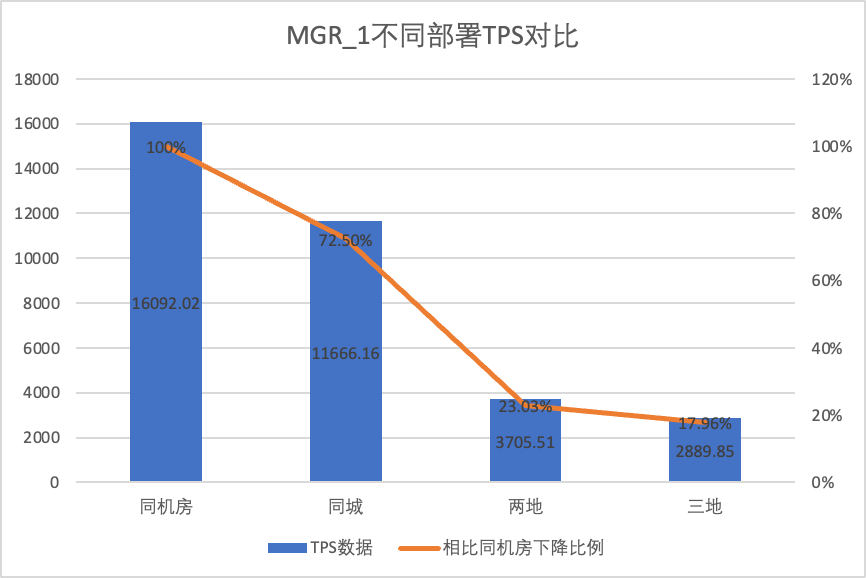
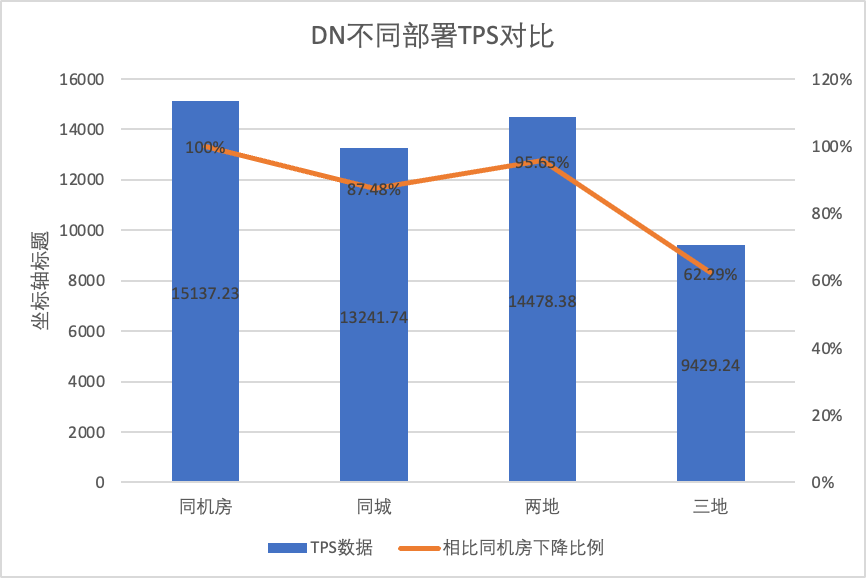
Il ressort des résultats des tests :
- Avec l'expansion de la méthode de déploiement, le TPS de MGR_1 (RPO<>0) a considérablement diminué par rapport au déploiement dans la même salle informatique, les performances du déploiement entre salles informatiques dans la même ville ont chuté de 27,5 %. du déploiement interurbain (trois centres en deux lieux, trois centres en trois lieux) Une diminution de 77 % ~ 82 %, qui est due à l'augmentation du déploiement interurbain de RT.
- Le DN (RTO=0) est relativement stable Par rapport au déploiement dans la même salle informatique, les performances du déploiement de salles cross-informatiques dans la même ville et du déploiement de trois centres en deux lieux ont chuté de 4 % à 12 %. Les performances du déploiement de trois centres sur trois lieux ont chuté de 37 % en raison d'une latence élevée du réseau. Cela est également dû au déploiement accru de RT dans les villes.Cependant, grâce au mécanisme Batch&Pipeline de DN, l'impact de l'inter-ville peut être résolu en augmentant la concurrence. Par exemple, dans le cadre de l'architecture à trois places et à trois centres, avec une concurrence >=512, le débit de performance dans la même ville et deux. les lieux et trois centres peuvent être fondamentalement alignés.
- On peut voir que le déploiement inter-villes a un grand impact sur MGR_1 (RPO<>0)
3.1.6. Gigue des performances
En utilisation réelle, nous prêtons non seulement attention aux données de performances, mais devons également prêter attention à la gigue des performances. Après tout, si la gigue ressemble à des montagnes russes, l’expérience utilisateur réelle sera très mauvaise. Nous surveillons et affichons les données de sortie TPS en temps réel Étant donné que l'outil sysbenc lui-même ne prend pas en charge les données de surveillance de sortie de la gigue des performances, nous utilisons le coefficient mathématique de variation comme indicateur de comparaison :
- Coefficient de variation (CV) : Le coefficient de variation est l'écart type divisé par la moyenne. Il est généralement utilisé pour comparer les fluctuations de différents ensembles de données, en particulier lorsque les différences moyennes sont importantes. Plus le CV est grand, plus la fluctuation des données par rapport à la moyenne est grande.
En prenant comme exemple le scénario oltp_read_write 256 concurrents, nous analysons statistiquement le TPS de MGR_1 (RPO<>0) et DN (RPO=0) dans la même salle informatique, trois centres dans la même ville, trois centres à deux endroits, et trois centres à trois endroits. Le graphique de gigue réel est le suivant et les données réelles de l'indicateur de gigue pour chaque scénario sont les suivantes :
| CV | Même salle informatique | Trois centres dans la même ville | Deux lieux et trois centres | Trois lieux et trois centres |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
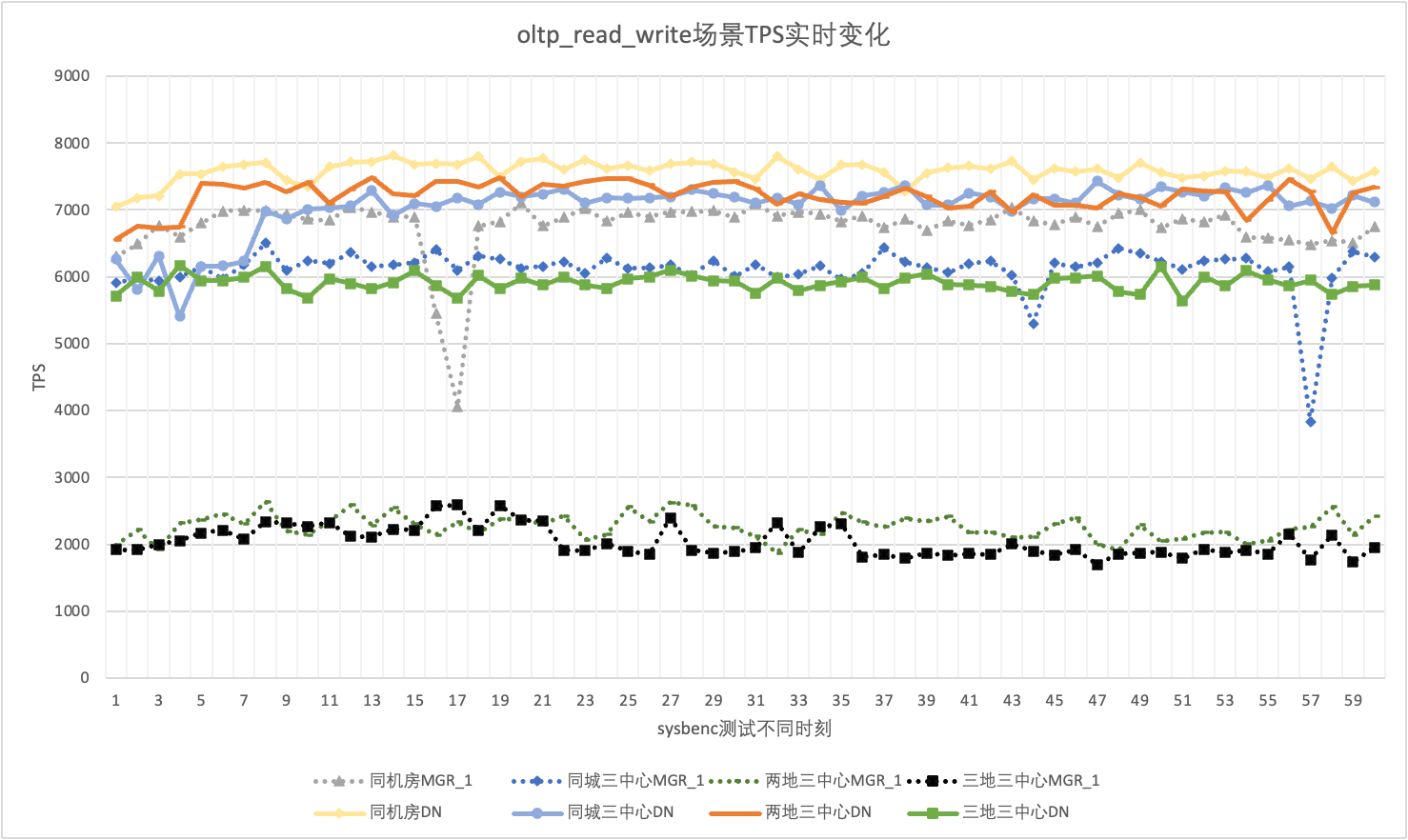
Il ressort des résultats des tests :
- Le TPS de MGR est dans un état instable dans le scénario oltp_read_write, et il chute soudainement sans raison. Ce phénomène a été constaté dans plusieurs tests dans plusieurs scénarios de déploiement. En comparaison, DN est très stable.
- En calculant le coefficient de variation CV, le CV de MGR est très grand, 6% à 10%, et atteint même la valeur maximale de 10% lorsque le retard dans la même salle informatique est minime, tandis que le CV de DN est relativement stable, 2% à 4 %, et les performances de DN sont plus stables que celles de MGR. Le sexe est fondamentalement deux fois plus élevé.
- On peut voir que la gigue des performances de MGR_1 (RPO<>0) est relativement importante
3.2. RTO
La fonctionnalité principale d'une base de données distribuée est la haute disponibilité. La défaillance d'un nœud du cluster n'affectera pas la disponibilité globale. Pour la forme de déploiement typique de 3 nœuds avec un maître et deux sauvegardes déployés dans la même salle informatique, nous avons essayé d'effectuer des tests d'utilisabilité dans les trois scénarios suivants :
- Interrompez la base de données principale, puis redémarrez-la et observez le temps RTO du cluster pour restaurer la disponibilité pendant le processus.
- Interrompez toute base de données de secours, puis redémarrez-la pour observer les performances de disponibilité de la base de données principale pendant le processus.
3.2.1. Temps d'arrêt de la base de données principale + redémarrage
Lorsqu'il n'y a pas de charge, tuez le leader et surveillez les changements d'état de chaque nœud du cluster et s'il est accessible en écriture.
| | MGR | DN |
| Démarrant normalement | 0 | 0 |
| tuer le chef | 0 | 0 |
| Temps de nœud anormal trouvé | 5 | 5 |
| Il est temps de réduire 3 nœuds à 2 nœuds | 23 | 8 |
| | MGR | DN |
| Démarrant normalement | 0 | 0 |
| tuer le chef, s'arrêter automatiquement | 0 | 0 |
| Temps de nœud anormal trouvé | 5 | 5 |
| Il est temps de réduire 3 nœuds à 2 nœuds | 23 | 8 |
| Restauration à 2 nœuds Temps à 3 nœuds | 37 | 15 |

Il ressort des résultats des tests que, sans conditions de pression :
- Le RTO du DN est de 8 à 15 s, il faut 8 s pour réduire à 2 nœuds et 15 s pour restaurer 3 nœuds ;
- Le RTO de MGR est de 23 à 37 secondes. Il faut 23 secondes pour rétrograder à 2 nœuds et 37 secondes pour restaurer 3 nœuds.
- Les performances RTO du DN sont globalement meilleures que celles du MGR
3.2.2. Temps d'arrêt de la base de données en veille + redémarrage.
Utilisez sysbench pour effectuer un test de contrainte simultané de 16 threads dans le scénario oltp_read_write À la 10e seconde de la figure, supprimez manuellement un nœud de secours et observez les données TPS de sortie en temps réel de sysbench.
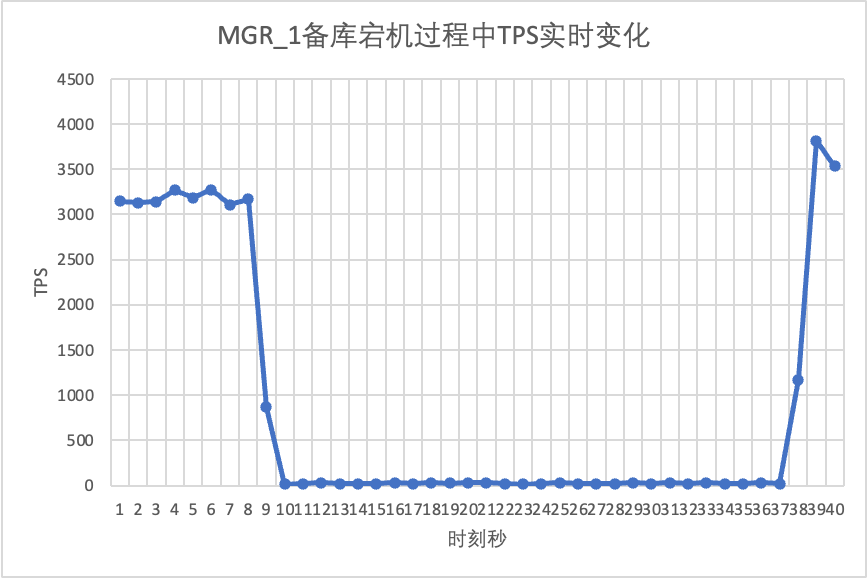


On peut le voir sur le tableau des résultats du test :
- Après l'interruption de la base de données de secours, le TPS de la base de données principale de MGR a chuté de manière significative et a duré environ 20 secondes avant de revenir à des niveaux normaux. Selon l'analyse des journaux, il existe deux processus : détecter que le nœud défectueux est devenu inaccessible et expulser le nœud défectueux du cluster MGR. Ce test a confirmé une faille qui circulait depuis longtemps dans la communauté MGR. Même si seulement 1 nœud parmi 3 nœuds est indisponible,L'ensemble du cluster a connu de fortes perturbations pendant un certain temps et est devenu indisponible.
- Pour résoudre le problème de la défaillance d'un seul nœud de MGR à maître unique et de l'indisponibilité de l'instance entière, la communauté a introduit la fonction MGR paxos single leader à partir de la version 8.0.27 pour résoudre le problème, mais elle est désactivée par défaut. Ici, nous activons group_replication_paxos_single_leader et continuons à vérifier. Après avoir interrompu la base de données de secours cette fois, les performances de la base de données principale restent stables et se sont légèrement améliorées. La raison devrait être liée à la réduction de la charge du réseau.
- Pour DN, après l'interruption de la base de données de secours, le TPS de la base de données principale a immédiatement augmenté d'environ 20 %, puis est resté stable et le cluster était toujours disponible.C'est le contraire de MGR. La raison en est qu'après avoir interrompu une base de données de secours, la base de données principale n'a besoin que d'envoyer des journaux à la base de données de secours restante à chaque fois, et le processus d'envoi et de réception des paquets réseau est plus efficace.
Poursuivant le test, nous redémarrons et restaurons la base de données de secours et observons les modifications des données TPS de la base de données principale.
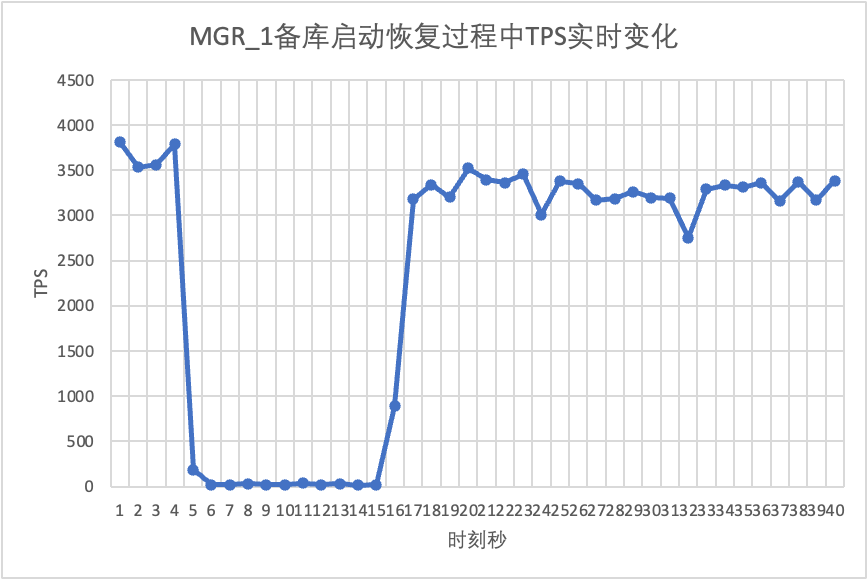
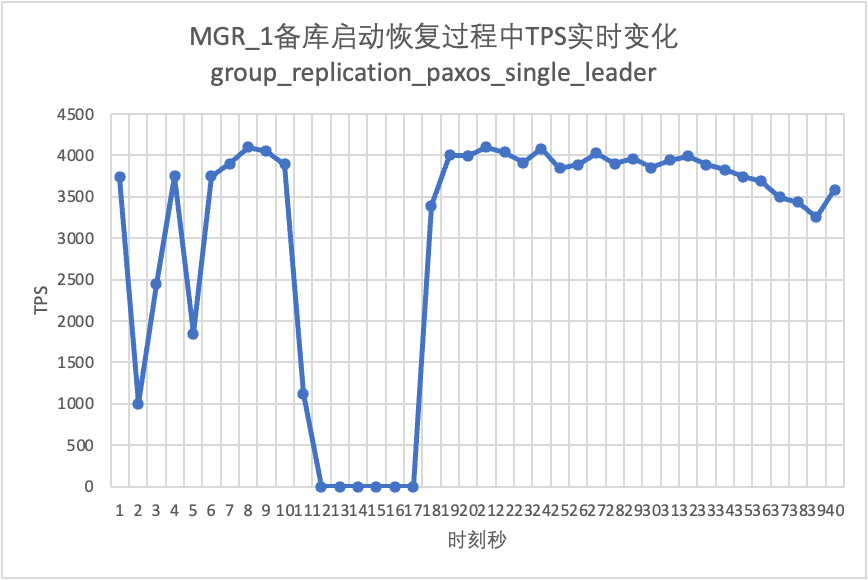
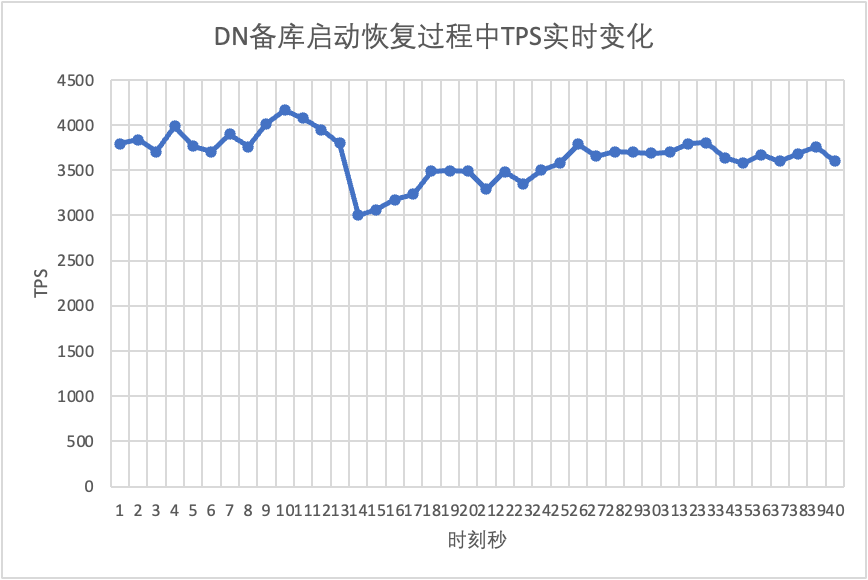
On peut le voir sur le tableau des résultats du test :
- MGR est passé de 2 nœuds à 3 nœuds en 5 secondes.Mais il existe également une situation où la bibliothèque principale est indisponible, qui dure environ 12 secondes.Bien que le nœud de secours ait finalement rejoint le cluster, l'état MEMBER_STATE a toujours été RECOVERING, indiquant que les données sont actuellement recherchées.
- Dans le scénario après l'activation de group_replication_paxos_single_leader, le redémarrage de la base de données de secours est également vérifié. Par conséquent, MGR récupère de 2 nœuds à 3 nœuds en 10 secondes.Mais il restait encore un temps d'indisponibilité d'environ 7 secondes.Il semble que ce paramètre ne puisse pas résoudre complètement le problème de la défaillance d'un seul nœud du MGR à maître unique et de l'indisponibilité de l'instance entière.
- Pour DN, la base de données de secours récupère de 2 nœuds à 3 nœuds en 10 secondes et la base de données principale reste disponible. Il y aura ici des fluctuations à court terme du TPS, car le délai de réplication des journaux de la base de données de secours redémarrée est en retard et les journaux en retard doivent être extraits de la base de données principale. Par conséquent, il y aura un léger impact sur la base de données principale. base de données principale. Après l'examen du journal, les performances globales seront stables.
3.3. RPO
Afin de construire le scénario RPO<>0 d'échec majoritaire de MGR, nous utilisons la propre méthode de cas MTR de la communauté pour effectuer des tests d'injection de fautes sur MGR. Le cas conçu est le suivant :
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo ############################################################
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record

loose-group_replication_member_weight=100
loose-group_replication_member_weight=90
loose-group_replication_member_weight=80
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socket
Les résultats de l'exécution du cas sont les suivants :
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
include/start_and_bootstrap_group_replication.inc
include/start_group_replication.inc
include/start_group_replication.inc
############################################################
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
INSERT INTO t1 VALUES(2);
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
La logique approximative d'un cas qui reproduit des nombres manquants est la suivante :
- MGR se compose de 3 nœuds en mode maître unique, Serveur 1/2/3, où le Serveur 1 est la base de données principale et initialise 1 enregistrement c1=1
- Le serveur d'injection de pannes 2/3 se bloquera lors de l'écriture du journal de relais
- Connecté au nœud du serveur 1, a écrit l'enregistrement c1=2 et la validation de la transaction a également renvoyé un succès.
- Ensuite, le serveur simulé 1 plante anormalement (panne de la machine, impossible à restaurer et inaccessible). À ce stade, le serveur 2/3 constitue la majorité.
- Redémarrez le serveur 2/3 normalement (récupération rapide), mais le serveur 2/3 ne peut pas restaurer le cluster dans un état utilisable.
- Connectez-vous au nœud du serveur 2/3 et interrogez les enregistrements de la base de données. Seul l'enregistrement de c1=1 est visible (le serveur 2/3 a perdu c1=2).
Selon le cas ci-dessus, pour MGR, lorsque la majorité des serveurs sont en panne et que la base de données principale est indisponible, une fois la base de données de secours restaurée, il y aura une perte de données de RPO<>0 et l'enregistrement de la validation réussie qui a été initialement retourné au client est perdu.
Pour DN, l'obtention de la majorité nécessite que les journaux soient conservés dans la majorité, donc même dans le scénario ci-dessus, les données ne seront pas perdues et le RPO=0 peut être garanti.
3.4. Délai de lecture de la base de données en veille
Dans le mode actif-veille traditionnel de MySQL, la base de données en veille contient généralement des threads IO et des threads Apply. Après l'introduction du protocole Paxos, le thread IO synchronise principalement le journal binaire des bases de données actives et en veille. dépend de la surcharge de l'application de lecture de la base de données en veille, nous devenons ici le délai de lecture de la base de données en veille.
Nous utilisons sysbench pour tester le scénario oltp_write_only et tester la durée du délai de lecture de la base de données en veille sous 100 simultanéités et un nombre différent d'événements.Le délai de lecture de la base de données de secours peut être déterminé en surveillant la colonne APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP de la table performance_schema.replication_applier_status_by_worker pour voir si chaque travailleur travaille en temps réel afin de déterminer si la réplication est terminée.

On peut le voir sur le tableau des résultats du test :
- Avec la même quantité de données écrites, le temps d'exécution de la lecture de tous les journaux de la base de données de secours de DN est bien meilleur que celui de MGR, la consommation de temps de DN n'est que de 3 à 4 % de celle de MGR. Ceci est essentiel à la rapidité du basculement actif/veille.
- À mesure que le nombre d'écritures augmente, l'avantage de latence de lecture de la base de données de secours de DN par rapport à MGR continue d'être maintenu et est très stable.
- En analysant les raisons du retard de lecture de la base de données de secours, la stratégie de lecture de la base de données de secours de MGR adopte group_replication_consistency avec la valeur par défaut de EVENTUAL, c'est-à-dire que les transactions RO et RW n'attendent pas l'application des transactions précédentes avant d'être exécutées. Cela peut garantir les performances d'écriture maximales de la base de données principale, mais le délai de la base de données de secours sera relativement important (en sacrifiant le délai de la base de données de secours et le RPO = 0 en échange d'une écriture haute performance de la base de données principale, en activant la fonction de limitation de courant de MGR peut équilibrer les performances et la base de données de secours est retardée, mais les performances de la base de données principale seront compromises)
3.5. Résumé des tests
| | MGR | DN |
| performance | Lire la transaction | plat | plat |
| écrire une transaction | Les performances ne sont pas aussi bonnes que DN lorsque RPO<>0 Lorsque RPO=0, les performances sont bien inférieures à DN Les performances de déploiement interurbain ont considérablement chuté de 27 % à 82 % | Les performances des transactions d'écriture sont bien supérieures à celles de MGR Les performances de déploiement inter-villes diminuent de 4 % à 37 %. |
| Gigue | La gigue des performances est sévère, la plage de gigue est de 6 à 10 % | Relativement stable à 3 %, seulement la moitié du MGR |
| RTO | La base de données principale est en panne | L'anomalie a été découverte en 5 secondes et réduite à deux nœuds en 23 secondes. | L'anomalie a été découverte en 5 secondes et réduite à deux nœuds en 8 secondes. |
| Redémarrez la bibliothèque principale | Une anomalie a été découverte en 5 secondes et trois nœuds ont été restaurés en 37 secondes. | Une anomalie est détectée en 5 secondes, et trois nœuds sont restaurés en 15 secondes. |
| Temps d'arrêt de la base de données de sauvegarde | Le trafic de la base de données principale est tombé à 0 pendant 20 secondes. Cela peut être atténué en activant explicitement group_replication_paxos_single_leader. | Haute disponibilité continue de la base de données principale |
| Redémarrage de la base de données en veille | Le trafic de la base de données principale est tombé à 0 pendant 10 secondes. L'activation explicite de group_replication_paxos_single_leader n'a également aucun effet. | Haute disponibilité continue de la base de données principale |
| RPO | Récidive du cas | RPO<>0 lorsque le parti majoritaire tombe Performance et RPO=0 ne peuvent pas avoir les deux. | RPO = 0 |
| Délai de base de données en veille | Temps de lecture de la base de données de sauvegarde | Le délai entre l'activité et la veille est très important. Les performances et la latence de la sauvegarde principale ne peuvent pas être obtenues en même temps. | Le temps total consacré à la lecture globale de la base de données en veille est de 4 % du MGR, soit 25 fois celui du MGR. |
| paramètre | paramètre clé |
- Le contrôle de flux group_replication_flow_control_mode est activé par défaut et doit être configuré pour le désactiver afin d'améliorer les performances.
- L'optimisation du plug-in statique replication_optimize_for_static_plugin_config est désactivée par défaut et doit être activée pour améliorer les performances.
- group_replication_paxos_single_leader est désactivé par défaut et doit être activé pour améliorer la stabilité de la base de données principale lorsque la base de données de secours est en panne.
- group_replication_consistency est désactivé par défaut et ne garantit pas RPO=0. Si RPO=0 est requis, AFTER doit être configuré.
- La valeur par défaut group_replication_transaction_size_limit est de 143 M, ce qui doit être augmenté en cas de transactions volumineuses.
- binlog_transaction_dependency_tracking est par défaut COMMIT_ORDER et doit être ajusté à WRITESET pour améliorer les performances de lecture de la base de données en veille.
| Configuration par défaut, pas besoin de professionnels pour personnaliser la configuration |
4. Résumé
Après une analyse technique approfondie et une comparaison des performances,PolarDB-X Avec son protocole X-Paxos auto-développé et une série de conceptions optimisées, DN a démontré de nombreux avantages par rapport à MySQL MGR en termes de performances, d'exactitude, de disponibilité et de surcharge de ressources. Cependant, MGR occupe également une position importante dans l'écosystème MySQL. , diverses situations telles que la gigue de panne de base de données en veille, les fluctuations des performances de récupération après sinistre entre les salles de machines et la stabilité doivent être prises en compte. Par conséquent, si vous souhaitez faire bon usage de MGR, vous devez être équipé d'une équipe technique, d'exploitation et de maintenance professionnelle. soutien.
Face à des exigences à grande échelle, de haute concurrence et de haute disponibilité, le moteur de stockage PolarDB-X présente des avantages techniques uniques et d'excellentes performances par rapport à MGR dans des scénarios prêts à l'emploi.PolarDB-XLa version centralisée basée sur DN (version standard) présente un bon équilibre entre fonctions et performances, ce qui en fait une solution de base de données très compétitive.

