
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Seperti yang kita ketahui bersama, database primer dan sekunder MySQL (dua node) umumnya mencapai ketersediaan data yang tinggi melalui replikasi asinkron dan replikasi semi-sinkron (Semi-Sync). arsitektur primer dan sekunder akan menghadapi masalah serius setelah peralihan HA. Akan ada kemungkinan ketidakkonsistenan data (disebut RPO!=0).Oleh karena itu, selama data bisnis sangat penting, Anda sebaiknya tidak memilih produk database dengan arsitektur primer dan sekunder MySQL (dua node). Disarankan untuk memilih arsitektur multi-salinan dengan RPO=0.
Komunitas MySQL, mengenai evolusi teknologi multi-copy dengan RPO=0:
PolarDB-X Konsep integrasi terpusat dan terdistribusi: node data DN dapat digunakan secara independen sebagai bentuk terpusat (versi standar), yang sepenuhnya kompatibel dengan bentuk database yang berdiri sendiri. Ketika bisnis tumbuh ke titik di mana perluasan terdistribusi diperlukan, arsitektur ditingkatkan ke bentuk terdistribusi, dan komponen terdistribusi terhubung dengan mulus ke node data asli. Tidak perlu migrasi atau modifikasi data di sisi aplikasi , dan Anda dapat menikmati distribusinya Kegunaan dan skalabilitas yang dibawa oleh rumus ini, deskripsi arsitektur:"Integrasi Terdistribusi Terpusat"
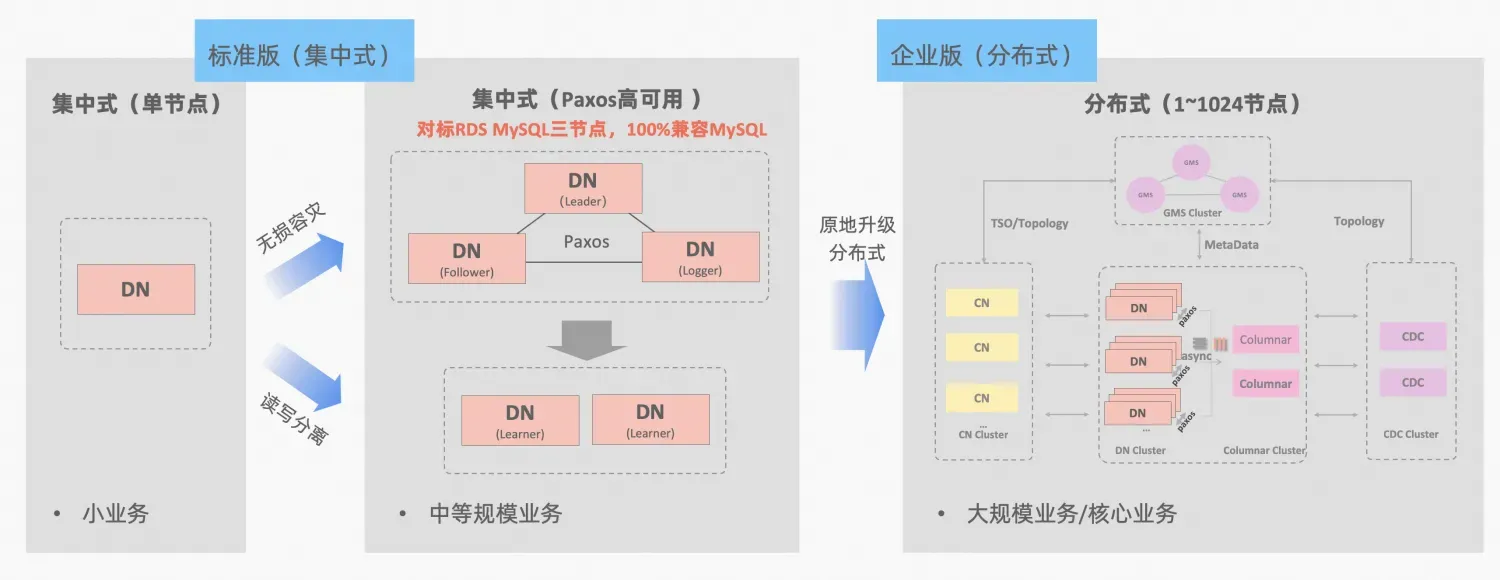
MGR MySQL dan DN versi standar PolarDB-X keduanya menggunakan protokol Paxos dari prinsip terendah. Jadi apa performa spesifik dan perbedaannya dalam penggunaan sebenarnya? Artikel ini menguraikan aspek perbandingan arsitektur, perbedaan utama, dan perbandingan pengujian.
Deskripsi singkatan MGR/DN: MGR mewakili bentuk teknis MySQL MGR, dan DN mewakili bentuk teknis PolarDB-X DN tunggal terpusat (versi standar).
Analisis komparatif secara detailnya relatif panjang, sehingga Anda bisa membaca ringkasan dan kesimpulannya terlebih dahulu. Jika tertarik, Anda bisa mengikuti ringkasannya dan mencari petunjuknya di artikel selanjutnya.
MySQL MGR tidak direkomendasikan untuk bisnis umum dan perusahaan karena memerlukan pengetahuan teknis profesional serta tim operasi dan pemeliharaan untuk menggunakannya dengan baik. Artikel ini juga mereproduksi tiga "perangkap tersembunyi" MySQL MGR yang telah lama beredar di industri :
Dibandingkan dengan MySQL MGR, PolarDB-X Paxos tidak memiliki kekurangan yang mirip dengan MGR dalam hal konsistensi data, pemulihan bencana lintas ruang komputer, serta pengoperasian dan pemeliharaan node. Namun, PolarDB-X juga memiliki beberapa kekurangan dan kelebihan kecil dalam pemulihan bencana:
Deskripsi singkatan MGR/DN:
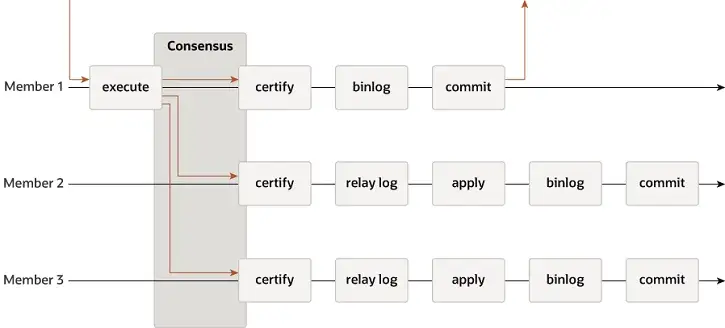
MGR mendukung mode master tunggal dan multi-master, dan sepenuhnya menggunakan kembali sistem replikasi MySQL, termasuk Event, Binlog & Relaylog, Apply, Binlog Apply Recovery, dan GTID. Perbedaan utama dari DN adalah bahwa titik masuk mayoritas log transaksi MGR untuk mencapai konsensus adalah sebelum transaksi database utama dilakukan.
Alasan mengapa MGR mengadopsi proses di atas adalah karena MGR berada dalam mode multi-master secara default, dan setiap node dapat menulis. Oleh karena itu, node pengikut dalam satu Grup Paxos perlu mengubah log yang diterima menjadi RelayLog terlebih dahulu, lalu menggabungkannya. dengan transaksi tulis yang diterima sebagai pemimpin untuk diserahkan. , file Binlog diproduksi untuk mengirimkan transaksi terakhir dalam proses pengiriman grup dua tahap.
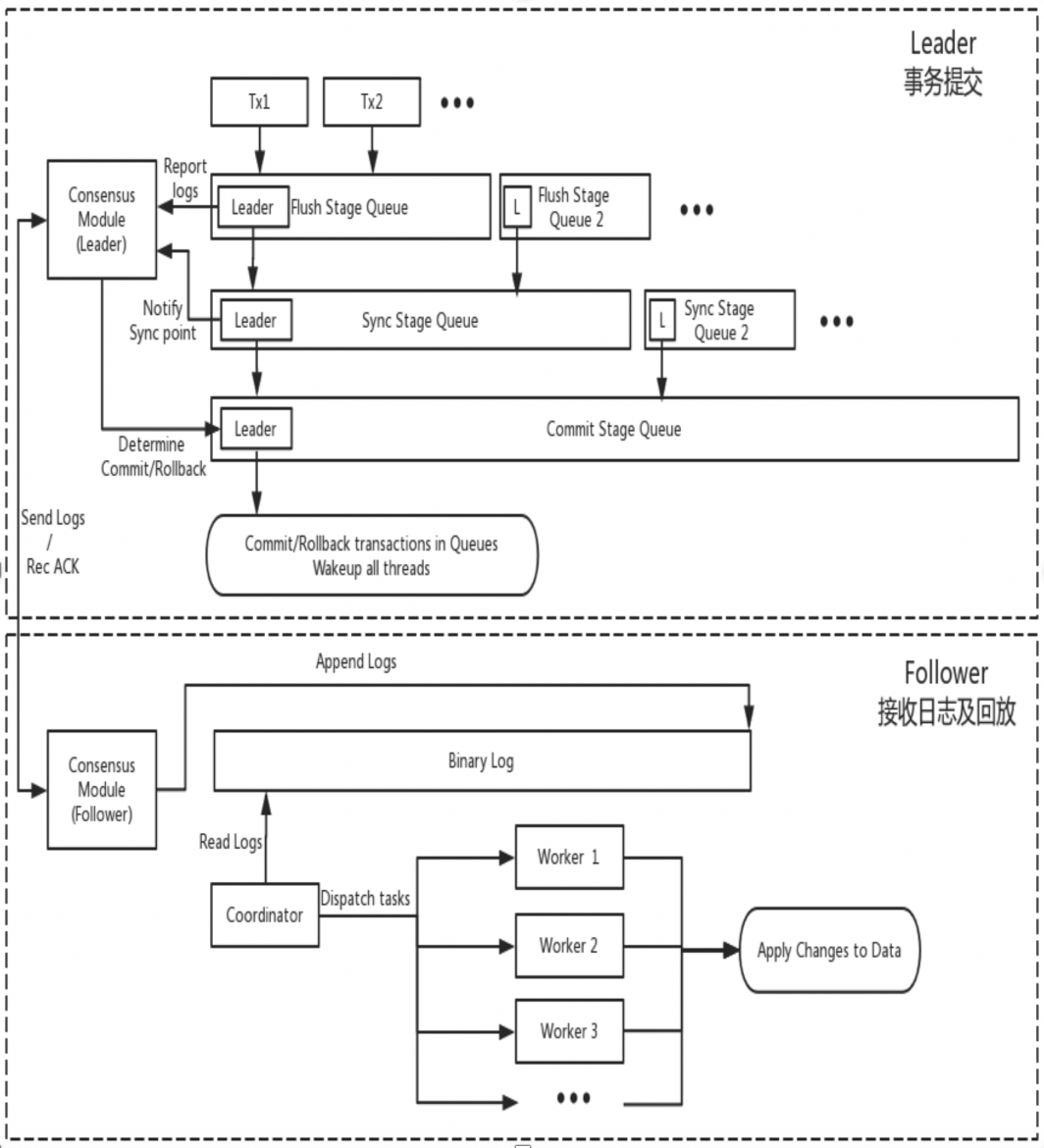
DN menggunakan kembali struktur data dasar dan kode tingkat fungsi MySQL, tetapi mengintegrasikan replikasi log, manajemen log, pemutaran log, dan pemulihan kerusakan dengan protokol X-Paxos untuk membentuk rangkaian replikasi mayoritas dan mekanisme mesin statusnya sendiri. Perbedaan utama dari MGR adalah bahwa titik masuk mayoritas log transaksi DN untuk mencapai konsensus adalah selama proses penyerahan transaksi database utama.
Alasan desain ini adalah DN saat ini hanya mendukung mode master tunggal, sehingga log pada tingkat protokol X-Paxos adalah Binlog itu sendiri. Follower juga menghilangkan Log Relai, dan konten data log persistennya serta log pemimpin sama dengan harga yang sama.

MGR

Tanggal
Secara teori, baik Paxos maupun Raft dapat memastikan konsistensi data dan log yang telah mencapai mayoritas setelah Crash Recovery tidak akan hilang, namun masih terdapat perbedaan dalam proyek tertentu.
MGR
XCOM sepenuhnya merangkum protokol Paxos, dan semua data protokolnya di-cache di memori terlebih dahulu. Secara default, transaksi yang mencapai mayoritas tidak memerlukan persistensi log. Jika sebagian besar pie gagal dan Pemimpin gagal, akan terjadi masalah serius yaitu RPO != 0.Asumsikan skenario ekstrem:
Berdasarkan parameter default komunitas, sebagian besar transaksi tidak memerlukan persistensi log dan tidak menjamin RPO=0. Hal ini dapat dianggap sebagai trade-off untuk kinerja dalam implementasi proyek XCOM. Untuk memastikan RPO=0 absolut, Anda perlu mengonfigurasi parameter group_replication_consistency yang mengontrol konsistensi baca dan tulis ke SETELAH. Namun, dalam kasus ini, selain overhead jaringan 1,5 RTT, transaksi akan memerlukan overhead log IO untuk mencapai mayoritas, dan kinerjanya akan sangat buruk.
Tanggal
PolarDB-X DN menggunakan X-Paxos untuk mengimplementasikan protokol terdistribusi dan sangat terikat dengan proses Komitmen Grup MySQL. Saat transaksi dikirimkan, mayoritas diharuskan untuk mengonfirmasi penempatan dan persistensi sebelum pengiriman sebenarnya diizinkan. Sebagian besar penempatan disk di sini mengacu pada penempatan Binlog dari perpustakaan utama. Thread IO dari perpustakaan siaga menerima log dari perpustakaan utama dan menulisnya ke Binlognya sendiri untuk persistensi. Oleh karena itu, meskipun semua node gagal dalam skenario ekstrem, data tidak akan hilang dan RPO=0 dapat dijamin.
Waktu RTO terkait erat dengan waktu overhead dari cold restart sistem itu sendiri, yang tercermin dalam fungsi dasar spesifik:Mekanisme deteksi kesalahan->mekanisme pemulihan kerusakan->mekanisme pemilihan master->penimbangan log
MGR
Tanggal
MGR
Tanggal
Dalam mode master tunggal, XCOM MGR dan DN X-Paxos, mode pemimpin yang kuat, mengikuti prinsip dasar yang sama untuk memilih pemimpin - log yang telah disepakati oleh cluster tidak dapat dibatalkan. Namun jika menyangkut log yang tidak disepakati, terdapat perbedaan
MGR
Tanggal
Pemerataan log berarti ada penundaan replikasi log dalam log antara database primer dan sekunder, dan database sekunder perlu menyamakan log. Untuk node yang dimulai ulang dan dipulihkan, pemulihan biasanya dimulai dengan database siaga, dan penundaan replikasi log telah terjadi dibandingkan dengan database utama, dan log harus diambil dengan database utama. Untuk node yang secara fisik jauh dari Pemimpin, mencapai mayoritas biasanya tidak ada hubungannya dengan node tersebut selalu mengalami penundaan log replikasi dan selalu mengejar log. Situasi ini memerlukan penerapan teknik khusus untuk memastikan penyelesaian penundaan replikasi log secara tepat waktu.
MGR
Tanggal
Penundaan pemutaran basis data siaga adalah penundaan antara waktu penyelesaian transaksi yang sama di basis data utama dan waktu penerapan transaksi di basis data siaga. Yang diuji di sini adalah kinerja log aplikasi Terapkan basis data siaga. Hal ini mempengaruhi berapa lama waktu yang dibutuhkan database siaga untuk menyelesaikan aplikasi datanya dan menyediakan layanan baca dan tulis ketika terjadi pengecualian.
MGR
Tanggal
Transaksi besar tidak hanya mempengaruhi penyerahan transaksi biasa, tetapi juga mempengaruhi stabilitas seluruh protokol terdistribusi dalam sistem terdistribusi. Dalam kasus yang parah, transaksi besar akan menyebabkan seluruh cluster tidak tersedia untuk waktu yang lama.
MGR
Tanggal
MGR
Tanggal

| MGR | Tanggal | ||
| Efisiensi protokol | Waktu penyerahan transaksi | 1,5~2,5 RTT | 1 RTT |
| Kegigihan Mayoritas | Penghematan memori XCOM | Kegigihan binlog | |
| keandalan | RPO=0 | Tidak dijamin secara default | Dijamin sepenuhnya |
| Deteksi kesalahan | Semua node saling memeriksa, beban jaringan tinggi Siklus detak jantung tidak dapat disesuaikan | Node master secara berkala memeriksa node lainnya Parameter siklus detak jantung dapat disesuaikan | |
| Pemulihan Runtuh Mayoritas | intervensi manual | Pemulihan otomatis | |
| Pemulihan Kecelakaan Minoritas | Pemulihan otomatis dalam banyak kasus, intervensi manual dalam keadaan khusus | Pemulihan otomatis | |
| Pilih masternya | Bebas menentukan urutan pemilihan | Bebas menentukan urutan pemilihan | |
| Ikatan log | Log yang tertinggal tidak boleh melebihi cache XCOM 1GB | File BInlog tidak dihapus | |
| Penundaan pemutaran basis data siaga | Dua tahap + ganda satu, sangat lambat | Satu tahap + nol ganda, lebih cepat | |
| Bisnis besar | Batas defaultnya tidak lebih dari 143MB | Tidak ada batasan ukuran | |
| membentuk | Biaya ketersediaan tinggi | Tiga salinan berfungsi penuh, 3 salinan overhead penyimpanan data | Salinan log logger, 2 salinan penyimpanan data |
| simpul hanya-baca | Diimplementasikan dengan replikasi master-slave | Protokol ini dilengkapi dengan implementasi salinan read-only yang lebih ramping |
MGR diperkenalkan di MySQL 5.7.17, tetapi lebih banyak fitur terkait MGR hanya tersedia di MySQL 8.0, dan di MySQL 8.0.22 dan versi yang lebih baru, kinerja keseluruhan akan lebih stabil dan dapat diandalkan. Oleh karena itu, kami memilih versi terbaru 8.0.32 dari kedua belah pihak untuk pengujian perbandingan.
Mengingat terdapat perbedaan dalam lingkungan pengujian, metode kompilasi, metode penerapan, parameter operasi, dan metode pengujian selama pengujian komparatif PolarDB-X DN dan MySQL MGR, yang dapat menyebabkan data perbandingan pengujian tidak akurat, artikel ini akan fokus pada berbagai detail . Lanjutkan sebagai berikut:
| persiapan Ujian | PolarDB-X DN | MySQL MGR[1] |
| Lingkungan perangkat keras | Menggunakan mesin fisik yang sama dengan memori 96C 754GB dan disk SSD | |
| sistem operasi | Bahasa Indonesia:Linux 4.9.168-019.ali3000.alios7.x86_64 | |
| Versi kernel | Menggunakan baseline kernel berdasarkan komunitas versi 8.0.32 | |
| Metode kompilasi | Kompilasi dengan RelWithDebInfo yang sama | |
| Parameter operasi | Gunakan situs resmi PolarDB-X yang sama untuk menjual 32C128G dengan spesifikasi dan parameter yang sama | |
| Metode penerapan | Mode master tunggal | |
Catatan:
Pengujian kinerja adalah hal pertama yang diperhatikan semua orang saat memilih database. Di sini kami menggunakan alat sysbench resmi untuk membuat 16 tabel, masing-masing berisi 10 juta data, untuk melakukan pengujian kinerja dalam skenario OLTP, dan menguji serta membandingkan kinerja keduanya dalam kondisi konkurensi berbeda dalam skenario OLTP berbeda.Dengan mempertimbangkan berbagai situasi penerapan sebenarnya, kami menyimulasikan empat skenario penerapan berikut:
menjelaskan:
a. Pertimbangkan perbandingan horizontal kinerja empat skenario penerapan. Tiga pusat di dua tempat dan tiga pusat di tiga tempat semuanya mengadopsi mode penerapan 3 salinan.
b. Mengingat pembatasan ketat pada RPO=0 saat menggunakan produk database ketersediaan tinggi, MGR dikonfigurasi dengan RPO<>0 secara default. Di sini, kami akan terus menambahkan pengujian perbandingan antara MGR RPO<>0 dan RPO=0 di masing-masing produk skenario penerapan.
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_hanya_baca | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| Tanggal | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 melawan MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN melawan MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN melawan MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_baca_tulis | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| Tanggal | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 melawan MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN melawan MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN melawan MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_hanya_menulis | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| Tanggal | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 melawan MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN melawan MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN melawan MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
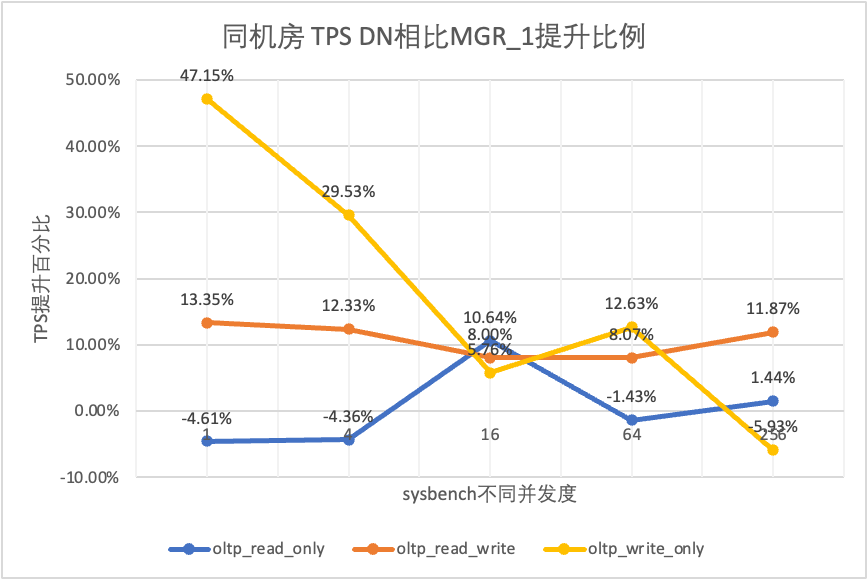
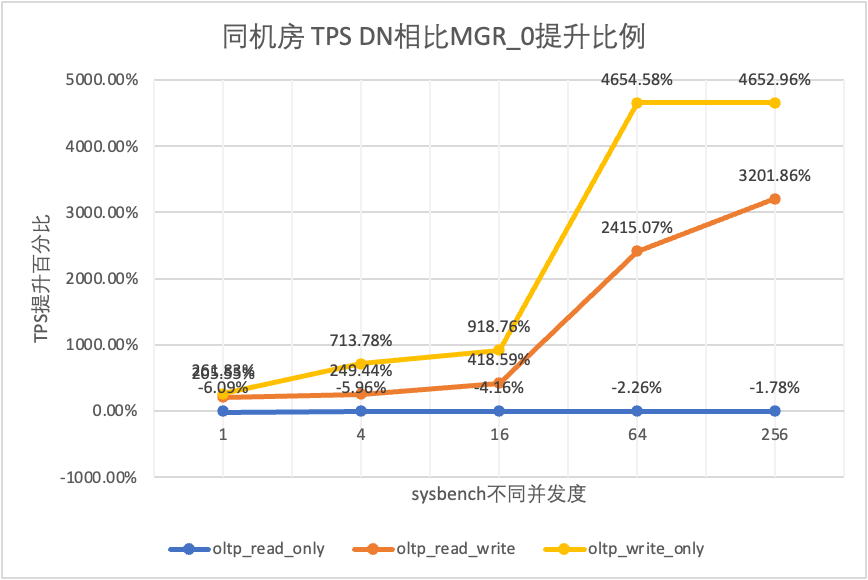
Hal ini terlihat dari hasil pengujian:
| Perbandingan TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_hanya_baca | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| Tanggal | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 melawan MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN melawan MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN melawan MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_baca_tulis | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| Tanggal | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 melawan MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN melawan MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN melawan MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_hanya_menulis | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| Tanggal | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 melawan MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN melawan MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN melawan MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Hal ini terlihat dari hasil pengujian:
| Perbandingan TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_hanya_baca | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| Tanggal | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 melawan MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN melawan MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN melawan MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_baca_tulis | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| Tanggal | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 melawan MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN melawan MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN melawan MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_hanya_menulis | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| Tanggal | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 melawan MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN melawan MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN melawan MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
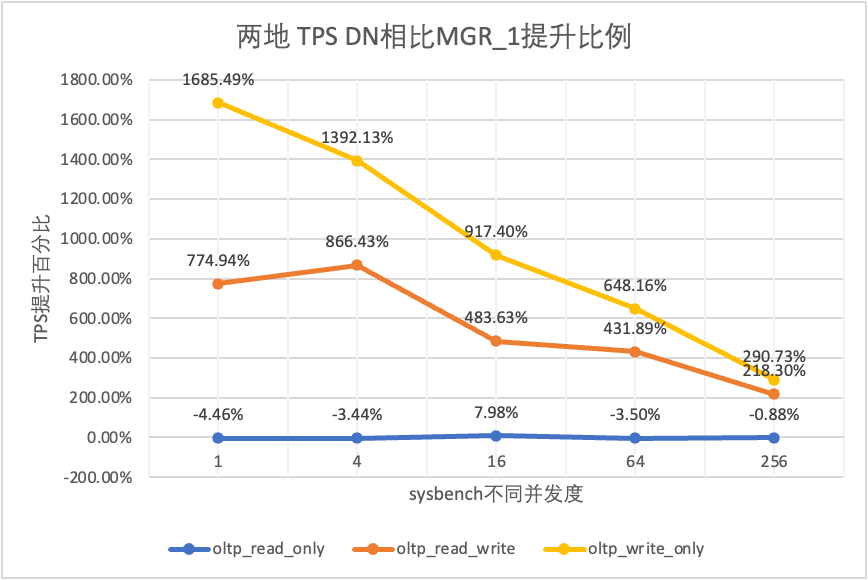
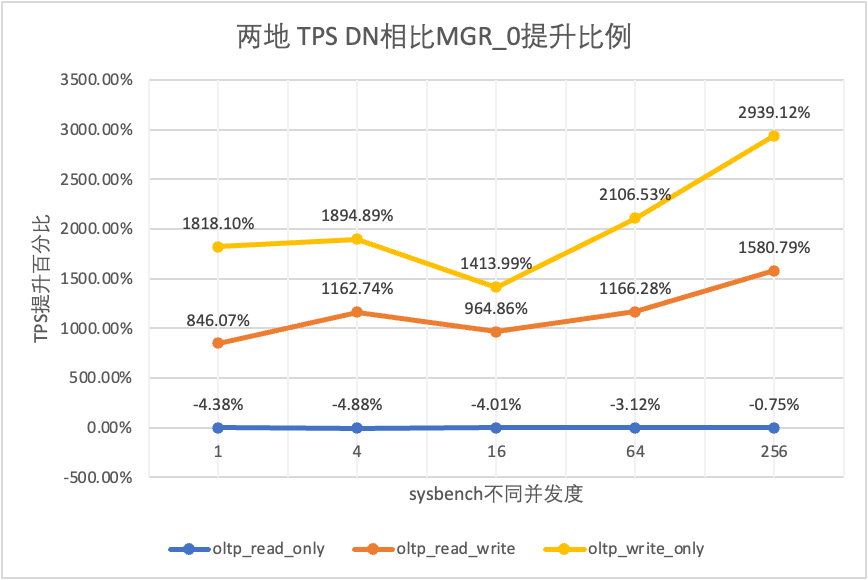
Hal ini terlihat dari hasil pengujian:
| Perbandingan TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_hanya_baca | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| Tanggal | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 melawan MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN melawan MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN melawan MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_baca_tulis | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| Tanggal | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 melawan MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN melawan MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN melawan MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_hanya_menulis | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| Tanggal | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 melawan MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN melawan MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN melawan MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
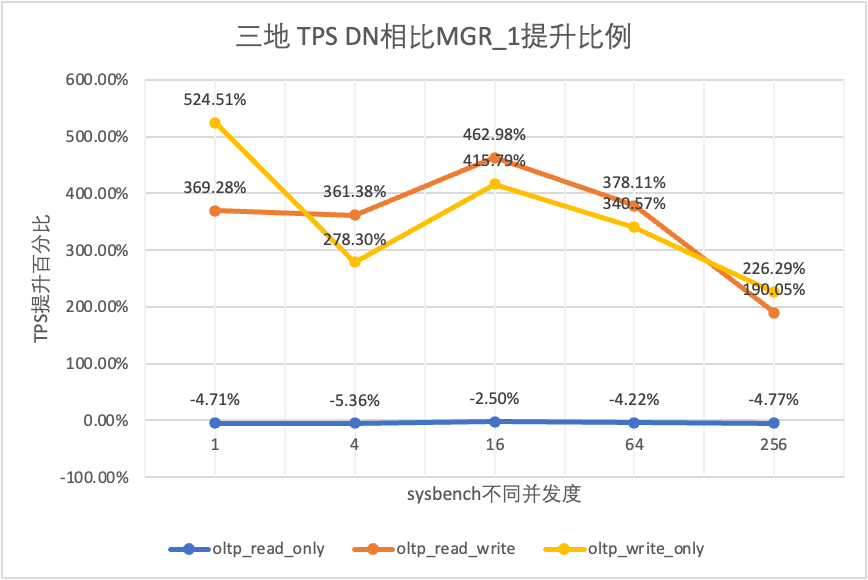
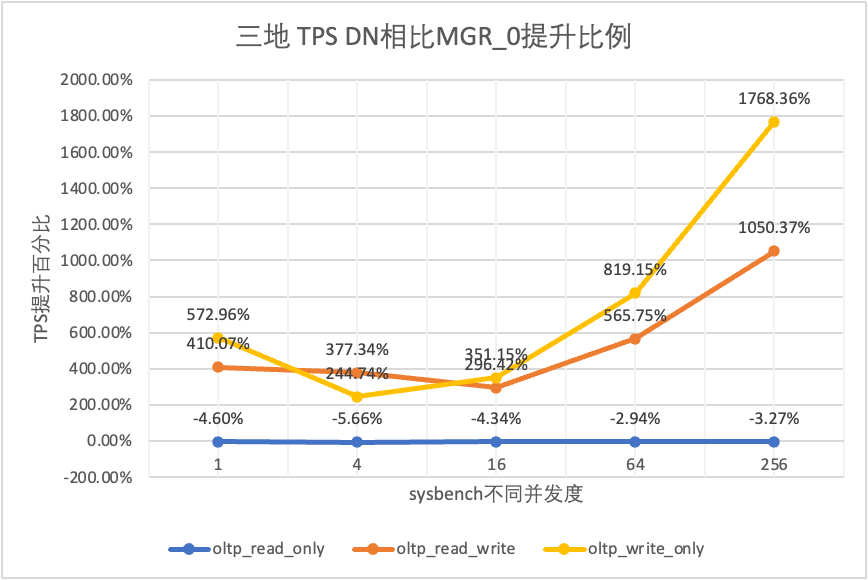
Hal ini terlihat dari hasil pengujian:
Untuk membandingkan dengan jelas perubahan kinerja dalam metode penerapan yang berbeda, kami memilih data TPS MGR dan DN dalam metode penerapan yang berbeda berdasarkan konkurensi skenario oltp_write_only 256 dalam pengujian di atas membandingkan data TPS dari metode penerapan yang berbeda. Rasio dibandingkan dengan data dasar untuk mengetahui perbedaan perubahan kinerja selama penerapan lintas kota
| MGR_1 (256 bersamaan) | DN (256 bersamaan) | Keunggulan kinerja DN dibandingkan MGR | |
| Ruang komputer yang sama | 16092.02 | 15137.23 | -5.93% |
| Tiga pusat di kota yang sama | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Dua tempat dan tiga pusat | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Tiga tempat dan tiga pusat | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
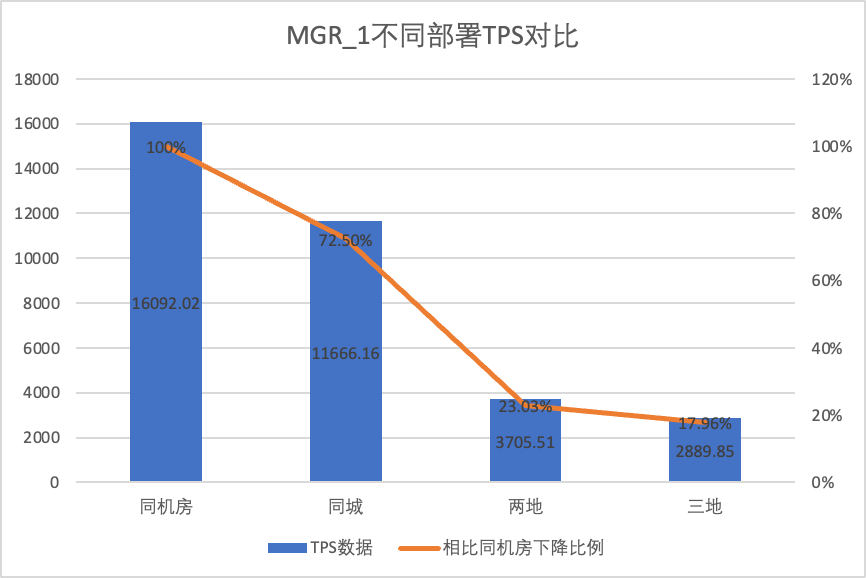
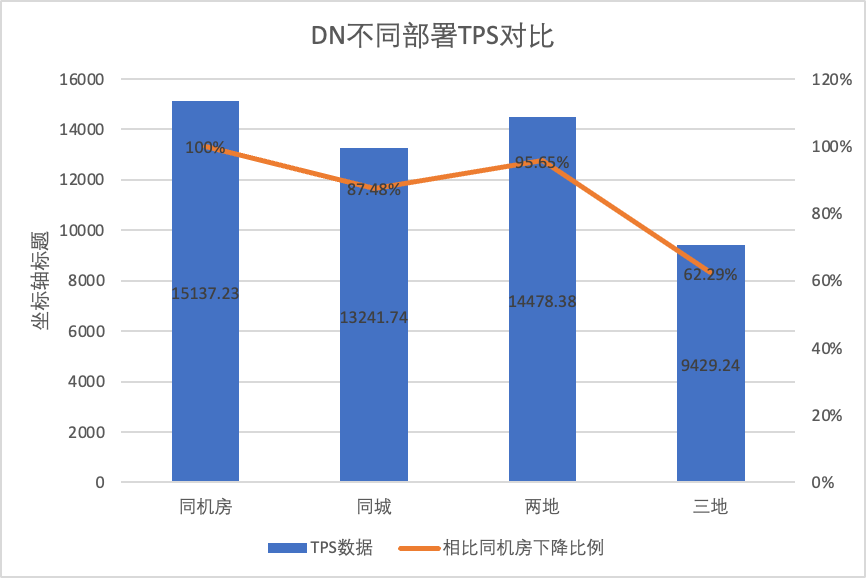
Hal ini terlihat dari hasil pengujian:
Dalam penggunaan sebenarnya, kita tidak hanya memperhatikan data performa saja, tetapi juga perlu memperhatikan jitter performa. Lagi pula, jika jitternya seperti roller coaster, pengalaman pengguna sebenarnya akan sangat buruk. Kami memantau dan menampilkan data keluaran TPS secara real-time. Mengingat alat sysbenc itu sendiri tidak mendukung data pemantauan keluaran jitter kinerja, kami menggunakan koefisien variasi matematis sebagai indikator perbandingan:
Mengambil 256 skenario oltp_read_write secara bersamaan sebagai contoh, kami menganalisis secara statistik TPS MGR_1 (RPO<>0) dan DN (RPO=0) di ruang komputer yang sama, tiga pusat di kota yang sama, tiga pusat di dua tempat, dan tiga pusat di tiga tempat. Grafik jitter sebenarnya adalah sebagai berikut, dan data indikator jitter sebenarnya untuk setiap skenario adalah sebagai berikut:
| CV | Ruang komputer yang sama | Tiga pusat di kota yang sama | Dua tempat dan tiga pusat | Tiga tempat dan tiga pusat |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| Tanggal | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
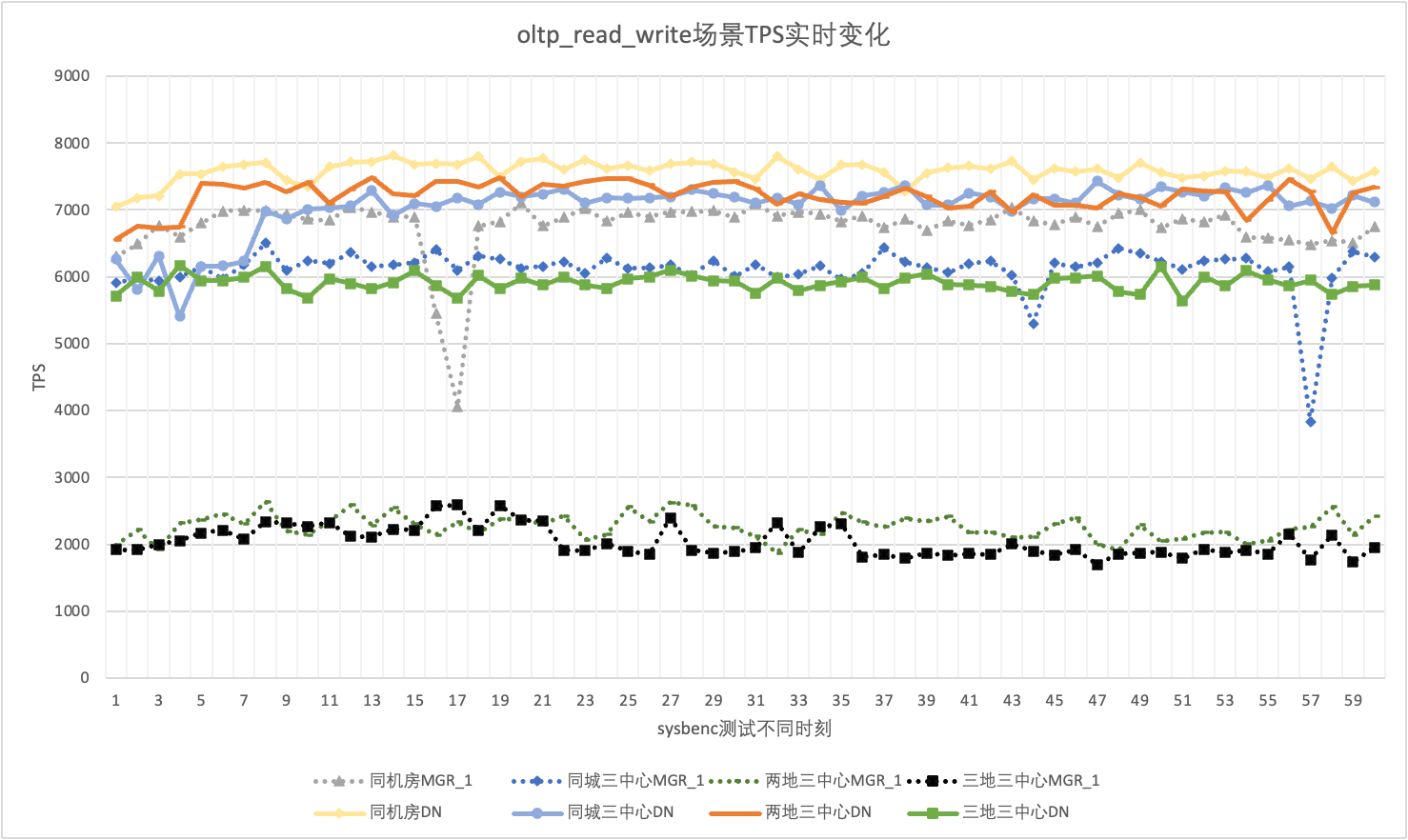
Hal ini terlihat dari hasil pengujian:
Fitur inti dari database terdistribusi adalah ketersediaan tinggi. Kegagalan node mana pun di cluster tidak akan mempengaruhi ketersediaan secara keseluruhan. Untuk bentuk penerapan tipikal 3 node dengan satu master dan dua cadangan yang diterapkan di ruang komputer yang sama, kami mencoba melakukan uji kegunaan dalam tiga skenario berikut:
Ketika tidak ada beban, matikan pemimpin dan pantau perubahan status setiap node di cluster dan apakah node tersebut dapat ditulis.
| MGR | Tanggal | |
| Mulai normal | 0 | 0 |
| membunuh pemimpin | 0 | 0 |
| Ditemukan waktu node yang tidak normal | 5 | 5 |
| Saatnya mengurangi 3 node menjadi 2 node | 23 | 8 |
| MGR | Tanggal | |
| Mulai normal | 0 | 0 |
| bunuh pemimpin, otomatis berhenti | 0 | 0 |
| Ditemukan waktu node yang tidak normal | 5 | 5 |
| Saatnya mengurangi 3 node menjadi 2 node | 23 | 8 |
| 2 node memulihkan waktu 3 node | 37 | 15 |

Dari hasil pengujian terlihat bahwa pada kondisi tanpa tekanan :
Gunakan sysbench untuk melakukan stress test secara bersamaan terhadap 16 thread dalam skenario oltp_read_write. Pada detik ke-10 pada gambar, matikan node siaga secara manual dan amati data TPS output real-time dari sysbench.
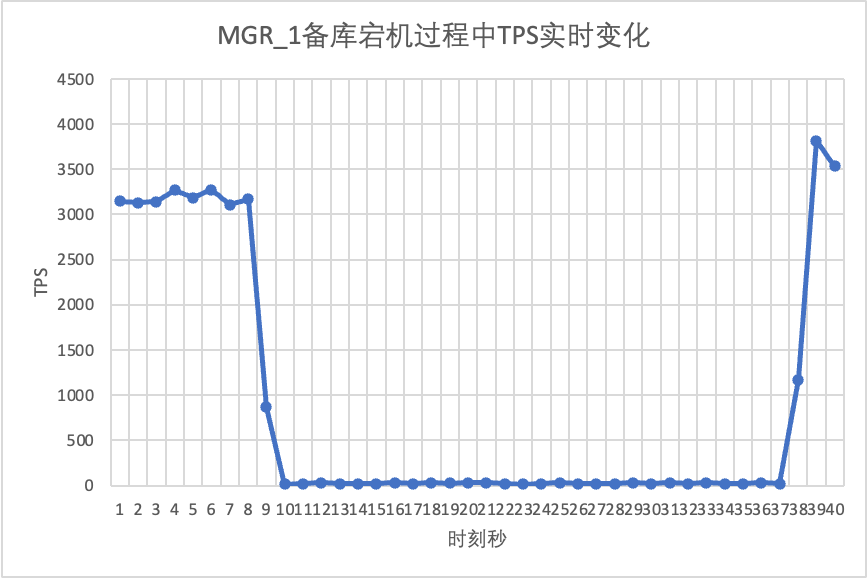


Dapat dilihat dari grafik hasil pengujian:
Melanjutkan pengujian, kami memulai ulang dan memulihkan database siaga dan mengamati perubahan pada data TPS dari database utama.
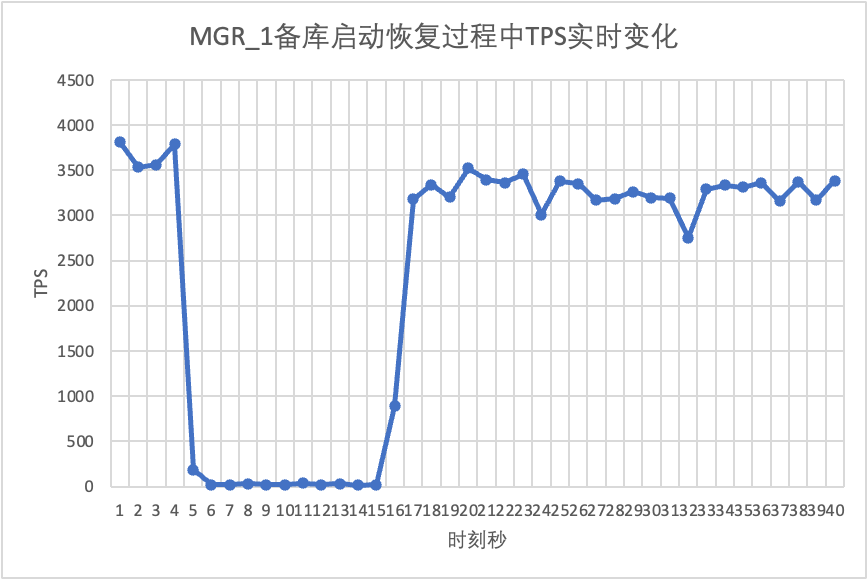
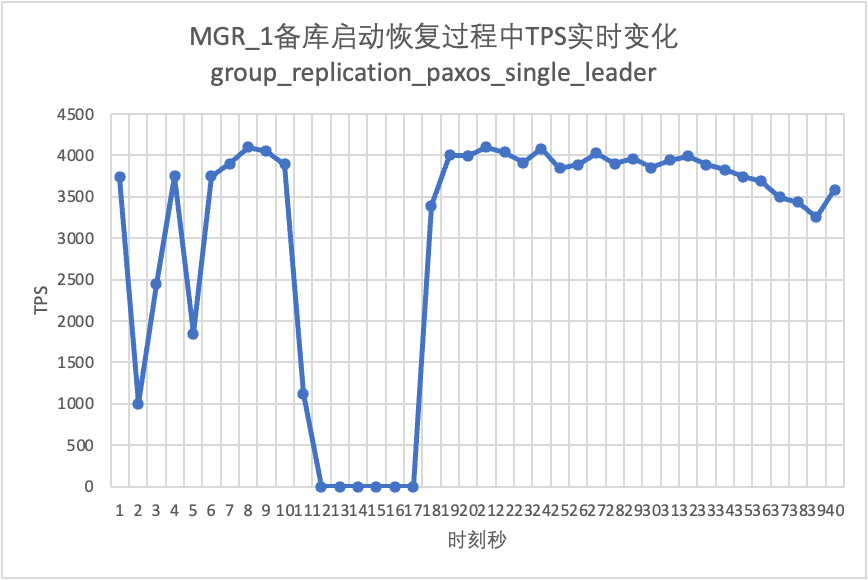
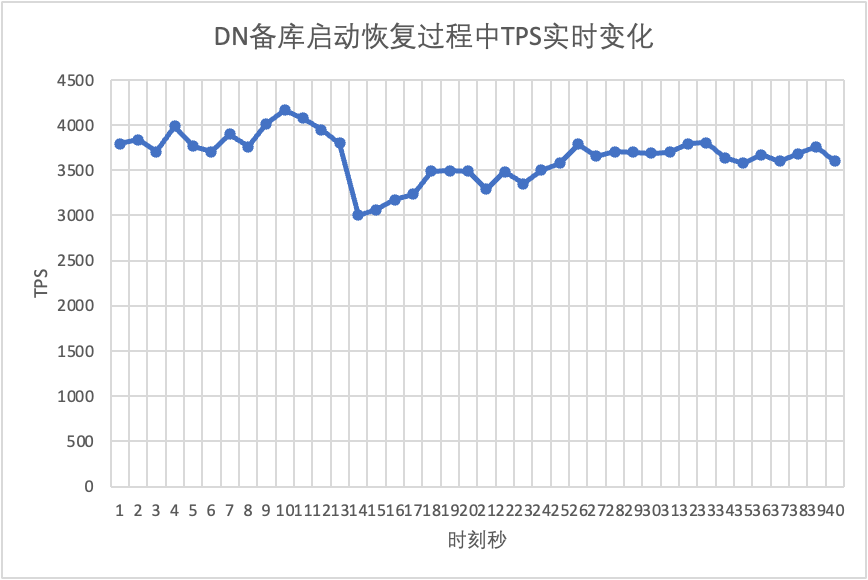
Dapat dilihat dari grafik hasil pengujian:
Untuk membangun skenario RPO<>0 kegagalan mayoritas MGR, kami menggunakan metode Kasus MTR milik komunitas untuk melakukan pengujian injeksi kesalahan pada MGR. Kasus yang dirancang adalah sebagai berikut:
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
Hasil kasus yang berjalan adalah sebagai berikut:
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
Perkiraan logika kasus yang mereproduksi angka yang hilang adalah sebagai berikut:
Berdasarkan kasus di atas, untuk MGR, ketika sebagian besar server mati dan database utama tidak tersedia, setelah database siaga dipulihkan, akan ada kehilangan data sebesar RPO<>0, dan catatan komit yang berhasil adalah awalnya dikembalikan ke klien hilang.
Untuk DN, pencapaian mayoritas mengharuskan log tetap berada di mayoritas, sehingga bahkan dalam skenario di atas, data tidak akan hilang dan RPO=0 dapat dijamin.
Dalam mode siaga aktif tradisional MySQL, basis data siaga umumnya berisi utas IO dan utas Terapkan. Setelah pengenalan protokol Paxos, utas IO menyinkronkan binlog dari basis data aktif dan siaga tergantung pada overhead Terapkan pemutaran database siaga, di sini kita menjadi penundaan pemutaran database siaga.
Kami menggunakan sysbench untuk menguji skenario oltp_write_only, dan menguji durasi penundaan dalam pemutaran database siaga di bawah 100 konkurensi dan jumlah kejadian yang berbeda.Waktu tunda pemutaran database siaga dapat ditentukan dengan memantau kolom APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP tabel performance_schema.replication_applier_status_by_worker untuk melihat apakah setiap pekerja bekerja secara real-time untuk menentukan apakah replikasi telah berakhir.

Dapat dilihat dari grafik hasil pengujian:
| MGR | Tanggal | ||
| pertunjukan | Baca transaksi | datar | datar |
| menulis transaksi | Performanya tidak sebaik DN saat RPO<>0 Ketika RPO=0, kinerjanya jauh lebih rendah daripada DN Performa penerapan lintas kota turun drastis sebesar 27%~82% | Kinerja transaksi tulis jauh lebih tinggi daripada MGR Kinerja penerapan lintas kota menurun sebesar 4% hingga 37%. | |
| Naik opelet | Jitter kinerja parah, rentang jitter 6~10% | Relatif stabil di angka 3%, hanya setengah dari MGR | |
| RTO | Basis data utama sedang down | Kelainan ditemukan dalam 5 detik dan dikurangi menjadi dua node dalam 23 detik. | Kelainan ditemukan dalam 5 detik dan berkurang menjadi dua node dalam 8 detik. |
| Mulai ulang perpustakaan utama | Kelainan ditemukan dalam 5 detik, dan tiga node dipulihkan dalam 37 detik. | Kelainan terdeteksi dalam 5 detik, dan tiga node dipulihkan dalam 15 detik. | |
| Waktu henti basis data cadangan | Lalu lintas database utama turun menjadi 0 selama 20 detik. Hal ini dapat diatasi dengan mengaktifkan group_replication_paxos_single_leader secara eksplisit. | Ketersediaan database utama yang tinggi secara berkelanjutan | |
| Mulai ulang basis data siaga | Lalu lintas database utama turun menjadi 0 selama 10 detik. Mengaktifkan group_replication_paxos_single_leader secara eksplisit juga tidak berpengaruh. | Ketersediaan database utama yang tinggi secara berkelanjutan | |
| RPO | Pengulangan kasus | RPO<>0 ketika partai mayoritas turun Performance dan RPO=0 tidak dapat memiliki keduanya. | RPO = 0 |
| Penundaan basis data siaga | Waktu pemutaran basis data cadangan | Jeda antara aktif dan standby sangat besar. Performa dan latensi cadangan primer tidak dapat dicapai secara bersamaan. | Total waktu yang dihabiskan untuk pemutaran database siaga secara keseluruhan adalah 4% dari MGR, yaitu 25 kali lipat dari MGR. |
| parameter | parameter kunci |
| Konfigurasi default, tidak perlu profesional untuk menyesuaikan konfigurasi |
Setelah analisis teknis mendalam dan perbandingan kinerja,PolarDB-X Dengan protokol X-Paxos yang dikembangkan sendiri dan serangkaian desain yang dioptimalkan, DN telah menunjukkan banyak keunggulan dibandingkan MySQL MGR dalam hal kinerja, kebenaran, ketersediaan, dan overhead sumber daya. Namun, MGR juga menempati posisi penting dalam ekosistem MySQL , berbagai situasi seperti jitter pemadaman basis data siaga, fluktuasi kinerja pemulihan bencana ruang mesin lintas, dan stabilitas perlu dipertimbangkan. Oleh karena itu, jika Anda ingin memanfaatkan MGR dengan baik, Anda harus dilengkapi dengan tim teknis, operasi, dan pemeliharaan yang profesional mendukung.
Ketika dihadapkan dengan persyaratan skala besar, konkurensi tinggi, dan ketersediaan tinggi, mesin penyimpanan PolarDB-X memiliki keunggulan teknis yang unik dan kinerja yang sangat baik dibandingkan dengan MGR dalam skenario siap pakai.PolarDB-XTerpusat berbasis DN (versi standar) memiliki keseimbangan yang baik antara fungsi dan kinerja, menjadikannya solusi database yang sangat kompetitif.

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]