Ripristino di emergenza del database |. Confronto approfondito tra MySQL MGR e Alibaba Cloud PolarDB-X Paxos
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Ecosistema open source
Come tutti sappiamo, i database primari e secondari MySQL (due nodi) generalmente raggiungono un'elevata disponibilità dei dati attraverso la replica asincrona e la replica semi-sincrona (Semi-Sync). Tuttavia, in scenari anomali come guasti della rete della sala computer e blocchi dell'host, il le architetture primarie e secondarie incontreranno seri problemi dopo il passaggio ad alta disponibilità. Ci sarà una probabilità di incoerenza dei dati (denominata RPO!=0).Pertanto, se i dati aziendali sono di una certa importanza, non è consigliabile scegliere un prodotto database con architettura primaria e secondaria MySQL (due nodi). Si consiglia di scegliere un'architettura multicopia con RPO=0.
Comunità MySQL, riguardo l'evoluzione della tecnologia multi-copia con RPO=0:
- MySQL è ufficialmente open source e ha lanciato la soluzione ad alta disponibilità MySQL Group Replication (MGR) basata sulla replica di gruppo. Il protocollo Paxos è incapsulato internamente tramite XCOM per garantire la coerenza dei dati.
- Ali Nuvola PolarDB-X , derivato dal perfezionamento e dalla verifica del business dell'e-commerce Double Eleven di Alibaba e dalla multi-attività in diversi luoghi, sarà open source nell'intero nucleo nell'ottobre 2021, abbracciando pienamente l'ecosistema open source MySQL. PolarDB-X è posizionato come database integrato centralizzato e distribuito. Il suo nodo dati Data Node (DN) adotta il protocollo X-Paxos sviluppato internamente ed è altamente compatibile con MySQL 5.7/8.0. Non solo fornisce funzionalità di alta disponibilità a livello finanziario , ma ha anche le caratteristiche di un motore di transazione altamente scalabile, di un funzionamento flessibile e di un ripristino di emergenza di manutenzione, nonché di un'archiviazione dei dati a basso costo. Riferimento: ".PolarDB-X Open Source |. Tre copie di MySQL basate su Paxos》。
PolarDB-X Il concetto di integrazione centralizzata e distribuita: il DN del nodo dati può essere utilizzato in modo indipendente come modulo centralizzato (versione standard), che è completamente compatibile con il modulo di database autonomo. Quando l'azienda cresce al punto da richiedere un'espansione distribuita, l'architettura viene aggiornata a una forma distribuita e i componenti distribuiti sono perfettamente connessi ai nodi di dati originali. Non è necessaria la migrazione o la modifica dei dati sul lato dell'applicazione e puoi goderti la distribuzione dell'usabilità e della scalabilità offerte da questa formula, descrizione dell'architettura:"Integrazione distribuita centralizzata"
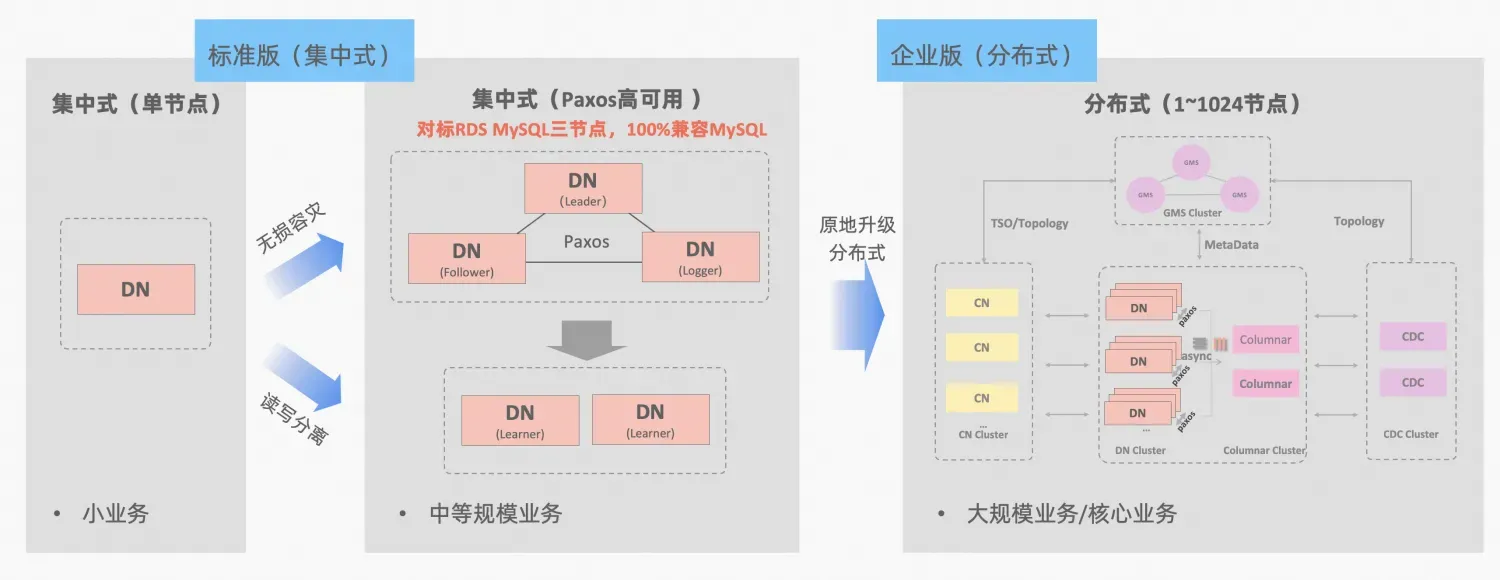
MGR di MySQL e la versione standard DN di PolarDB-X utilizzano entrambi il protocollo Paxos dal principio più basso. Quindi quali sono le prestazioni specifiche e le differenze nell'uso effettivo? Questo articolo approfondisce gli aspetti del confronto dell'architettura, delle differenze principali e del confronto dei test.
Descrizione abbreviazione MGR/DN: MGR rappresenta la forma tecnica di MySQL MGR e DN rappresenta la forma tecnica di PolarDB-X singolo DN centralizzato (versione standard).
In breve
L'analisi comparativa dettagliata è relativamente lunga, quindi puoi leggere prima il riassunto e la conclusione. Se sei interessato, puoi seguire il riassunto e cercare indizi negli articoli successivi.
MySQL MGR non è consigliato per aziende e aziende in generale perché richiede conoscenze tecniche professionali e un team operativo e di manutenzione per utilizzarlo bene. Questo articolo riproduce anche tre "insidie nascoste" di MySQL MGR che circolano nel settore da molto tempo. :
- Dark Pit 1: i protocolli MySQL MGR e XCOM adottano la modalità di memoria completa L'impostazione predefinita non è quella di soddisfare la garanzia di coerenza dei dati di RPO=0 (si verificherà un problema di dati mancanti nel caso di test più avanti in questo articolo). visualizzare e configurare un parametro per garantirlo Attualmente il design di MGR non può raggiungere sia prestazioni che RPO.
- Trappola 2: le prestazioni di MySQL MGR sono scarse in caso di ritardo della rete L'articolo ha testato un confronto di scenari di rete di 4 minuti (incluse tre sale computer nella stessa città e tre centri in due luoghi). parametri di prestazione della città, è solo 1/5 di quello della stessa città, se la garanzia dei dati di RPO=0 è attivata, la prestazione sarà ancora peggiore.Pertanto, MySQL MGR è più adatto all'uso nello stesso scenario di sala computer, ma non è adatto per il ripristino di emergenza tra sale computer.
- Trappola 3: Nell'architettura multi-copia di MySQL MGR, il guasto del nodo standby farà sì che il traffico del nodo master Leader scenda a 0, il che non è coerente con il buon senso. L'articolo si concentra sul tentativo di abilitare la modalità single leader di MGR (rispetto alla precedente architettura di replica master-slave di MySQL), simulando le due azioni di inattività e ripristino della replica slave. Le operazioni di funzionamento e manutenzione del nodo slave causeranno anche il master nodo (Leader) per apparire. Il traffico è sceso a 0 (della durata di circa 10 secondi) e l'operabilità e la manutenibilità complessive erano relativamente scarse.Pertanto, MySQL MGR ha requisiti relativamente elevati in termini di funzionamento e manutenzione dell'host e richiede un team DBA professionale.
Rispetto a MySQL MGR, PolarDB-X Paxos non presenta inconvenienti simili a MGR in termini di coerenza dei dati, ripristino di emergenza tra sale computer e funzionamento e manutenzione dei nodi. Tuttavia, presenta anche alcuni piccoli difetti e vantaggi nel ripristino di emergenza:
- In uno scenario semplice della stessa sala computer, le prestazioni di sola lettura in condizioni di bassa concorrenza e le prestazioni di scrittura pura in condizioni di concorrenza elevata sono leggermente inferiori a quelle di MySQL MGR di circa il 5%. c'è spazio per un'ulteriore ottimizzazione delle prestazioni.
- Vantaggi: compatibile al 100% con le funzionalità di MySQL 5.7/8.0 Allo stesso tempo, sono state apportate ottimizzazioni più snelle alla replica del database in standby multi-copia e ai percorsi di failover ad alta disponibilità RTO <= 8 secondi, un comune 4 Scenario di ripristino di emergenza in pochi minuti nel settore. Tutti funzionano bene e possono sostituire semi-sync (semi-sync), MGR, ecc.
1. Confronto tra architetture
Glossario
Descrizione abbreviazione MGR/DN:
- MGR: La forma tecnica di MySQL MGR, l'abbreviazione del contenuto successivo: MGR
- DN: Alibaba Cloud PolarDB-X è un modulo tecnico centralizzato (versione standard). Il DN del nodo dati distribuito può essere utilizzato in modo indipendente come modulo centralizzato (versione standard). È completamente compatibile con i database autonomi come: DN
Direttore Generale
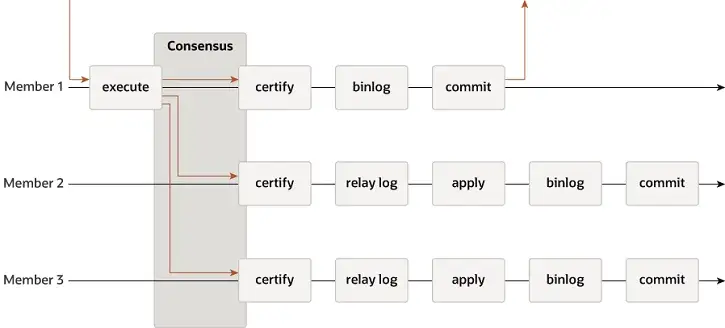
MGR supporta le modalità single-master e multi-master e riutilizza completamente il sistema di replica di MySQL, inclusi Event, Binlog e Relaylog, Apply, Binlog Apply Recovery e GTID. La differenza fondamentale rispetto al DN è che il punto di ingresso affinché la maggioranza del log delle transazioni MGR raggiunga il consenso è prima che venga eseguita la transazione del database principale.
-
- Prima che venga eseguito il commit della transazione, viene richiamata la funzione hook before_commit group_replication_trans_before_commit per immettere la replica maggioritaria di MGR.
- MGR utilizza il protocollo Paxos per sincronizzare gli eventi Binlog memorizzati nella cache di THD su tutti i nodi online
- Dopo aver ricevuto la risposta della maggioranza, MGR stabilisce che la transazione può essere presentata
- THD entra nel processo di invio del gruppo di transazioni e inizia a scrivere il messaggio OK del client di risposta Redo per l'aggiornamento del Binlog locale
-
- Il Paxos Engine di MGR continua ad ascoltare i messaggi di protocollo del Leader
- Dopo un completo processo di consenso a Paxos, si conferma che questo evento (batch) ha raggiunto la maggioranza nel cluster
- Scrive l'evento ricevuto nel registro di inoltro, thread di IO Applica registro di inoltro
- L'applicazione Relay Log passa attraverso un processo completo di invio di gruppo e il database in standby alla fine genererà il proprio file binlog.
Il motivo per cui MGR adotta il processo di cui sopra è perché MGR è in modalità multi-master per impostazione predefinita e ciascun nodo può scrivere. Pertanto, il nodo follower in un singolo gruppo Paxos deve prima convertire il registro ricevuto in RelayLog e quindi combinarlo con la transazione di scrittura che riceve come leader da inviare, viene prodotto il file Binlog per inviare la transazione finale nel processo di invio del gruppo in due fasi.
D.N.
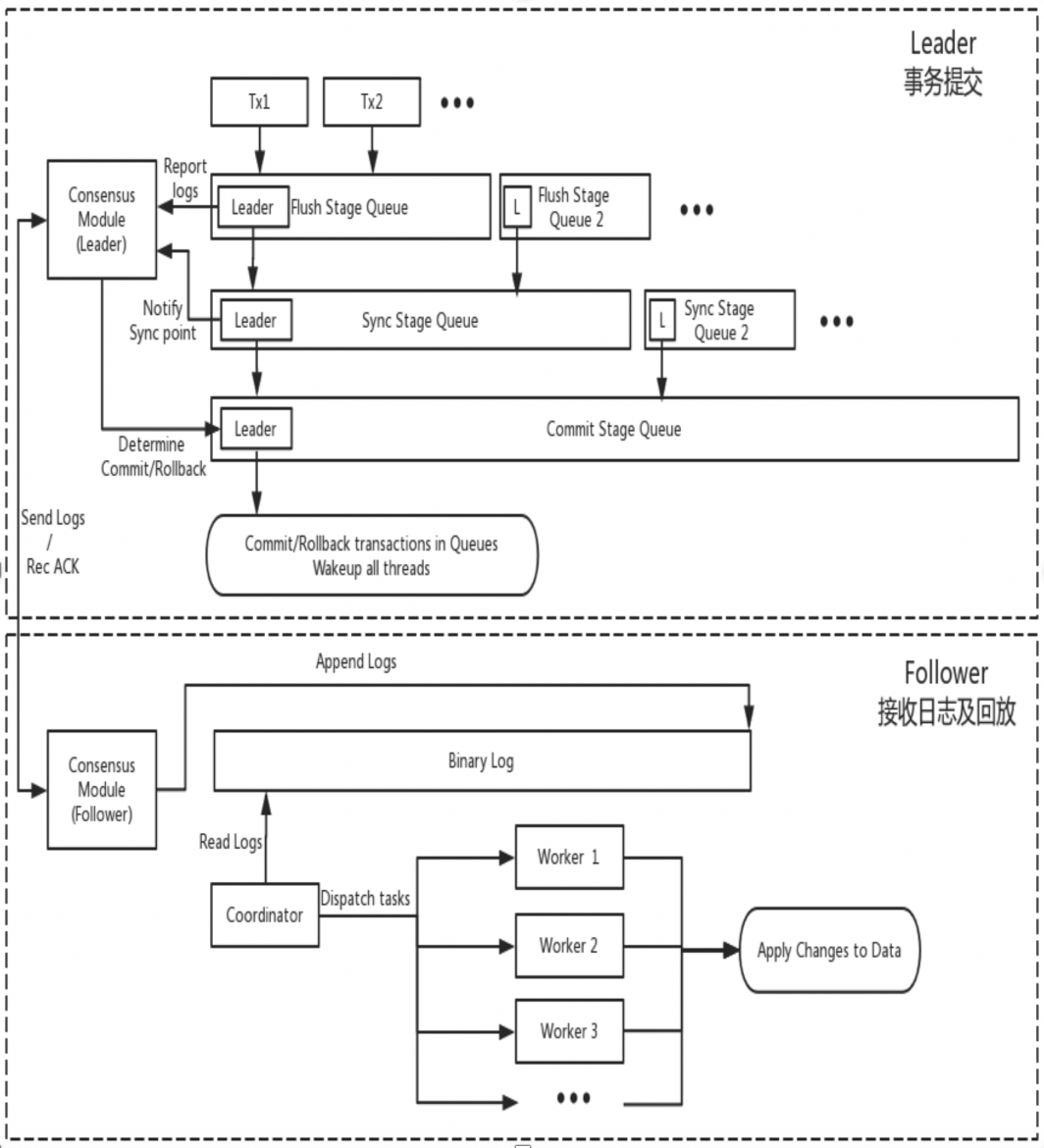
DN riutilizza la struttura dei dati di base di MySQL e il codice a livello di funzione, ma integra strettamente la replica dei log, la gestione dei log, la riproduzione dei log e il ripristino da crash con il protocollo X-Paxos per formare il proprio set di meccanismi di replica maggioritaria e macchina di stato. La differenza fondamentale rispetto a MGR è che il punto di ingresso affinché la maggioranza dei log delle transazioni DN raggiunga il consenso è durante il processo di invio delle transazioni del database principale.
-
- Immettere il processo di invio del gruppo della transazione Nella fase Flush dell'invio del gruppo, gli eventi su ciascun THD vengono scritti nel file Binlog, quindi il registro viene trasmesso in modo asincrono a tutti i follower tramite X-Paxos.
- Nella fase di sincronizzazione dell'invio del gruppo, il Binlog viene prima reso permanente, quindi viene aggiornata la posizione di persistenza di X-Paxos.
- Nella fase di Commit dell'invio del gruppo, è necessario prima attendere che X-Paxos riceva la risposta della maggioranza, quindi inviare il gruppo di transazioni e infine rispondere con un messaggio di OK da parte del client.
-
- X-Paxos continua ad ascoltare i messaggi di protocollo del Leader
- Ricevi un (gruppo) Eventi, scrivi sul Binlog locale e rispondi
- Viene ricevuto il messaggio successivo che riporta l'indice di Commit della posizione in cui è stata raggiunta la maggioranza.
- Il thread SQL Apply continua ad applicare il log Binlog ricevuto in background e lo applica al massimo solo alla posizione di maggioranza.
Il motivo di questa progettazione è che DN attualmente supporta solo la modalità single-master, quindi il registro a livello di protocollo X-Paxos è il Binlog stesso che omette anche il registro di inoltro e il contenuto dei dati del suo registro persistente e del registro del leader sono uguali allo stesso prezzo.
2. Differenze chiave
2.1. Efficienza del protocollo Paxos

Direttore Generale
- Il protocollo Paxos di MGR è implementato sulla base del protocollo Mencius, che appartiene alla teoria Multi-Paxos. La differenza è che Mencius ha apportato miglioramenti di ottimizzazione riducendo il carico del nodo master e aumentando il throughput.
- Il protocollo Paxos di MGR è implementato dai componenti XCOM e supporta la distribuzione in modalità multi-master e single-master. In modalità single-master, il Binlog sul Leader trasmette atomicamente al nodo Follower un processo Multi-Paxos standard.
- Per soddisfare la maggior parte di una transazione, XCOM deve passare attraverso almeno tre interazioni di messaggi di Accept+AckAccept+Learn, ovvero,Almeno 1,5 RTT in testa.Richiede al massimo tre interazioni del messaggio: Prepara+AckPrepare+Accetta+AckAccetta+Apprendi.Cioè, un massimo di 2,5 RTT in totale
- Poiché il protocollo Paxos è completato con elevata coesione nel modulo XCOM e non è a conoscenza del sistema di replica MySQL, il Leader deve attendere il completamento dell'intero processo Paxos prima di effettuare il commit della transazione localmente, inclusa la persistenza Binlog e l'invio del gruppo.
- Dopo che il Follower ha completato l'invio della maggioranza, persisterà in modo asincrono gli eventi nel registro di inoltro, quindi l'applicazione e il gruppo del thread SQL invieranno il Binlog di produzione.
- Poiché il log sincronizzato da Paxos è un Binlog che non viene ordinato prima di entrare nel processo di invio del gruppo, l'ordine degli eventi Binlog sul Leader potrebbe non essere lo stesso dell'ordine degli eventi nel Relay Log sul nodo Follower.

D.N.
- Il protocollo Paxos di DN è implementato sulla base del protocollo Raft e appartiene anche alla teoria Multi-Paoxs. La differenza è che il protocollo Raft ha una garanzia di leadership e una garanzia di stabilità ingegneristica più forti.
- Il protocollo Paxos di DN è completato dal componente X-Paoxs L'impostazione predefinita è la modalità single-master, il Binlog sul Leader trasmette atomicamente al nodo Follower. La trasmissione di ciascun batch di messaggi è un processo Raft standard .
- Per soddisfare la maggior parte di una transazione, X-Paoxs deve solo eseguire le due interazioni del messaggio Append+AckAppend e solo1 RTT in testa
- Dopo che il Leader ha inviato il log al Follower, purché la maggioranza sia soddisfatta, conferma la transazione senza attendere la trasmissione dell'indice di commit nella seconda fase.
- Prima che il follower possa completare l'invio della maggioranza, tutti i log delle transazioni devono essere persistenti. Questo è significativamente diverso da XCOM di MGR che deve solo riceverli nella memoria XCOM.
- L'indice di commit viene riportato nei messaggi successivi e nei messaggi heartbeat e il follower esegue l'evento di applicazione dopo che il CommitIndex è stato inviato.
- I contenuti Binlog di Leader e Follower sono nello stesso ordine, i log Raft non hanno buchi e il meccanismo Batching/Pipeline viene utilizzato per aumentare la velocità effettiva della replica dei log.
- Rispetto a MGR, il Leader ha sempre solo un ritardo di andata e ritorno quando viene impegnata una transazione., molto critico per le applicazioni distribuite sensibili al ritardo
2.2. L'RPO
In teoria, sia Paxos che Raft possono garantire la coerenza dei dati e i log che hanno raggiunto la maggioranza dopo Crash Recovery non andranno persi, ma ci sono ancora differenze nei progetti specifici.
Direttore Generale
XCOM incapsula completamente il protocollo Paxos e tutti i dati del protocollo vengono prima memorizzati nella cache. Per impostazione predefinita, la maggior parte delle transazioni non richiede la persistenza del registro. Nel caso in cui la maggior parte delle torte fallisca e il Leader fallisca, si verificherà un serio problema di RPO != 0.Ipotizziamo uno scenario estremo:
- Il cluster MGR è composto da tre nodi ABC, di cui AB è una sala computer indipendente nella stessa città e C è un nodo interurbano. A è il nodo Leader, BC è il nodo Follower
- Avvia la transazione 001 sul nodo Leader A. Il leader A trasmette il registro della transazione 001 al nodo BC Se la maggioranza è soddisfatta tramite il protocollo Paxos, la transazione può essere considerata inviata. La sezione AB formava la maggioranza e il nodo C non ha ricevuto il registro della transazione 001 a causa del ritardo della rete cittadina.
- Nel momento successivo, il Leader A invia la transazione 001 e restituisce il successo del cliente, il che significa che la transazione 001 è stata inviata al database.
- In questo momento, sul Follower del nodo B, il log della transazione 001 è ancora nella cache XCOM e non ha avuto il tempo di essere scaricato su RelayLog in questo momento, il Follower del nodo C non ha ancora ricevuto la transazione 001; log dal leader del nodo A.
- In questo momento, il nodo AB è inattivo, il nodo A si guasta e non può essere ripristinato per molto tempo, il nodo B si riavvia e si ripristina rapidamente e i nodi BC continuano a fornire servizi di lettura e scrittura.
- Poiché il registro della transazione 001 non è stato persistente nel RelayLog del nodo B durante il tempo di inattività, né è stato ricevuto dal nodo C, quindi in questo momento il nodo BC ha effettivamente perso la transazione 001 e non può recuperarla.
- In questo scenario in cui il partito di maggioranza è in ribasso, RPO!=0
Secondo i parametri predefiniti della comunità, la maggior parte delle transazioni non richiede la persistenza del registro e non garantisce RPO=0. Questo può essere considerato un compromesso per le prestazioni nell'implementazione del progetto XCOM. Per garantire un RPO assoluto = 0, è necessario configurare il parametro group_replication_consistency che controlla la coerenza di lettura e scrittura su AFTER. Tuttavia, in questo caso, oltre a 1,5 RTT di sovraccarico di rete, la transazione richiederà un sovraccarico di I/O di registro per raggiungere la maggioranza. e la prestazione sarà molto scarsa.
D.N.
PolarDB-X DN utilizza X-Paxos per implementare un protocollo distribuito ed è profondamente legato al processo Group Commit di MySQL Quando viene inviata una transazione, è necessaria la maggioranza per confermare il posizionamento e la persistenza prima che venga consentito l'effettivo invio. La maggior parte del posizionamento del disco qui si riferisce al posizionamento del Binlog della libreria principale. Il thread IO della libreria in standby riceve il log della libreria principale e lo scrive nel proprio Binlog per la persistenza. Pertanto, anche se tutti i nodi falliscono in scenari estremi, i dati non andranno persi e sarà possibile garantire RPO=0.
2.3. RTO
Il tempo RTO è strettamente correlato al tempo di sovraccarico del riavvio a freddo del sistema stesso, che si riflette nelle specifiche funzioni di base:Meccanismo di rilevamento guasti->meccanismo di ripristino da crash->meccanismo di selezione principale->bilanciamento registro
2.3.1. Rilevamento guasti
Direttore Generale
- Ogni nodo invia periodicamente pacchetti heartbeat ad altri nodi per verificare se gli altri nodi sono integri. Il periodo heartbeat è fisso su 1 e non può essere modificato.
- Se il nodo corrente rileva che altri nodi non hanno risposto dopo group_replication_member_expel_timeout (default 5s), verrà considerato un nodo non riuscito e verrà espulso dal cluster.
- Per eccezioni quali interruzione della rete o riavvio anomalo, dopo il ripristino della rete, un singolo nodo guasto tenterà di unirsi automaticamente al cluster e quindi di legare il registro.
D.N.
- Il nodo Leader invia periodicamente pacchetti heartbeat ad altri nodi per verificare se gli altri nodi sono integri. Il periodo di heartbeat è 1/5 del timeout elettorale. Il timeout dell'elezione è controllato dal parametro consensus_election_timeout. Il valore predefinito è 5 s, quindi il periodo di heartbeat del nodo leader è predefinito su 1 s.
- Se il Leader rileva che altri nodi sono offline, continuerà a inviare periodicamente pacchetti heartbeat a tutti gli altri nodi per garantire che gli altri nodi possano accedere in tempo dopo l'arresto anomalo e il ripristino.Tuttavia, il nodo Leader non invia più i registri delle transazioni al nodo offline.
- I nodi non leader non inviano pacchetti di rilevamento dell'heartbeat, ma se il nodo non leader rileva di non aver ricevuto l'heartbeat dal nodo leader dopo consensus_election_timeout, verrà attivata una rielezione.
- Per eccezioni quali interruzione della rete o riavvio anomalo, dopo il ripristino della rete, il nodo difettoso si unirà automaticamente al cluster.
- Pertanto, in termini di rilevamento dei guasti, DN fornisce più interfacce di configurazione per il funzionamento e la manutenzione e l'identificazione dei guasti negli scenari di distribuzione in città sarà più accurata.
2.3.2. Recupero da incidente
Direttore Generale
-
- Il protocollo Paxos implementato da XCOM è in stato di memoria. Il raggiungimento della maggioranza non richiede persistenza. Lo stato del protocollo si basa sullo stato di memoria del nodo maggioritario sopravvissuto.Se tutti i nodi si riagganciano, il protocollo non può essere ripristinato. Dopo il riavvio del cluster, è necessario un intervento manuale per ripristinarlo.
- Se solo un singolo nodo si arresta in modo anomalo e viene ripristinato, ma il nodo Follower è in ritardo rispetto al nodo Leader con più log delle transazioni e i log delle transazioni memorizzati nella cache XCOM sul Leader sono stati cancellati, l'unica opzione è utilizzare il processo di ripristino globale o clonazione.
- La dimensione della cache XCOM è controllata da group_replication_message_cache_size, il valore predefinito è 1 GB
- Recupero globale significa che quando un nodo si ricongiunge al cluster, recupera i dati ottenendo i log delle transazioni mancanti richiesti (log binario) da altri nodi.Questo processo si basa su almeno un nodo nel cluster che conserva tutti i log delle transazioni richiesti
- Clone si basa sul plugin Clone, che viene utilizzato per il ripristino quando la quantità di dati è grande o mancano molti registri.Funziona copiando un'istantanea dell'intero database sul nodo in crash, seguita da una sincronizzazione finale con l'ultimo registro delle transazioni
- I processi Global Recovery e Clone sono solitamente automatizzati, ma in alcuni casi particolari, come problemi di rete o la cache XCOM degli altri due nodi è stata svuotata, è necessario un intervento manuale.
D.N.
-
- Il protocollo X-Paxos utilizza la persistenza Binlog Durante il ripristino da un arresto anomalo, le transazioni inviate verranno prima completamente ripristinate. Per le transazioni in sospeso, è necessario attendere che il livello del protocollo XPaxos raggiunga un accordo per determinare la relazione master-backup prima di confermare o ripristinare la transazione. L'intero processo è completamente automatizzato.Anche se tutti i nodi sono inattivi, il cluster può ripristinarsi automaticamente dopo il riavvio.
- Per gli scenari in cui il nodo Follower resta indietro rispetto al nodo Leader in molti log delle transazioni, finché il file Binlog sul Leader non viene eliminato, il nodo Follower riuscirà sicuramente a recuperare il ritardo.
- Pertanto, in termini di ripristino da un arresto anomalo del sistema, DN non richiede alcun intervento manuale.
2.3.3. Scelta del leader
In modalità single-master, XCOM e DN X-Paxos di MGR, una modalità leader forte, seguono lo stesso principio di base per la selezione del leader: i log concordati dal cluster non possono essere ripristinati. Ma quando si tratta del registro dei nonconsensi, ci sono delle differenze
Direttore Generale
- La selezione del leader riguarda più quale nodo fungerà successivamente da servizio Leader.Questo leader non dispone necessariamente del registro di consenso più recente quando viene eletto, quindi deve sincronizzare i registri più recenti da altri nodi nel cluster e fornire servizi di lettura e scrittura dopo che i registri sono stati collegati.
- Il vantaggio di ciò è che la scelta del Leader stesso è un prodotto strategico, come peso e ordine. MGR controlla il peso di ciascun nodo tramite il parametro group_replication_member_weight
- Lo svantaggio è che lo stesso Leader neoeletto potrebbe avere un ampio ritardo di replica e dover continuare a recuperare il ritardo, oppure il ritardo dell'applicazione potrebbe essere elevato e deve continuare a recuperare il ritardo con l'applicazione di registro prima che possa fornire servizi di lettura e scrivere servizi.Ciò si traduce in un tempo RTO più lungo
D.N.
- L'elezione del leader avviene nel senso del protocollo. Qualunque nodo abbia i log di tutti i partiti di maggioranza nel cluster può essere eletto leader, quindi questo nodo potrebbe essere stato prima un follower o un logger.
- Il Logger non può fornire servizi di lettura e scrittura Dopo aver sincronizzato i log con altri nodi, rinuncerà attivamente al ruolo di Leader.
- Per garantire che il nodo designato diventi leader, DN utilizza una strategia di ponderazione ottimistica + una strategia di ponderazione obbligatoria per limitare l'ordine in cui diventa leader e utilizza un meccanismo di maggioranza strategica per garantire che il nuovo master possa immediatamente fornire operazioni di lettura e scrittura servizi con ritardo zero.
- Pertanto, in termini di selezione del leader, DN non solo supporta la stessa selezione strategica di MGR, ma supporta anche strategie di peso obbligatorie.
2.3.4. Corrispondenza dei registri
L'equalizzazione dei log significa che è presente un ritardo nella replica dei log tra il database primario e quello secondario e che il database secondario deve equalizzare i log. Per i nodi riavviati e ripristinati, il ripristino in genere viene avviato con il database in standby e si è già verificato un ritardo nella replica del log rispetto al database principale ed è necessario che i log vengano aggiornati con il database principale. Per quei nodi che sono fisicamente lontani dal Leader, raggiungere la maggioranza di solito non ha nulla a che fare con loro. Hanno sempre un ritardo nel log di replica e sono costantemente al passo con il log. Queste situazioni richiedono un'implementazione tecnica specifica per garantire la risoluzione tempestiva dei ritardi nella replica dei log.
Direttore Generale
- I log delle transazioni sono tutti nella cache XCOM e la cache è solo 1G per impostazione predefinita. Pertanto, quando un nodo follower che è molto indietro nella replica delle richieste registra, è facile che la cache venga svuotata.
- A questo punto, il follower in ritardo verrà automaticamente espulso dal cluster, quindi utilizzerà il processo di ripristino globale o clonazione menzionato sopra per il ripristino da arresto anomalo, quindi si unirà automaticamente al cluster dopo aver recuperato il ritardo.Se incontriAd esempio, si verificano problemi di rete o viene cancellata la cache XCOM degli altri due nodi, nel qual caso è necessario un intervento manuale per risolvere il problema.
- Perché dobbiamo prima eliminare il cluster? Perché il nodo difettoso in modalità multiscrittura influisce notevolmente sulle prestazioni e la cache del leader non ha alcun effetto su di esso. Deve essere aggiunta dopo il collegamento asincrono.
- Perché non possiamo leggere direttamente il file Binlog locale del Leader perché il protocollo XCOM menzionato in precedenza è in memoria piena e non sono presenti informazioni sul protocollo su XCOM nel Binlog e nel Relay Log.
D.N.
- I dati sono tutti nel file Binlog Finché il Binlog non viene pulito, può essere inviato su richiesta e non c'è alcuna possibilità di essere espulso dal cluster.
- Per ridurre il jitter di I/O causato dalla libreria principale che legge i vecchi log delle transazioni dal file Binlog, DN dà la priorità alla lettura dei log delle transazioni memorizzati nella cache più recentemente dalla cache FIFO. La cache FIFO è controllata dal parametro consensus_log_cache_size e dal valore predefinito è 64M
- Se il vecchio registro delle transazioni nella cache FIFO è stato eliminato dal registro delle transazioni aggiornato, DN tenterà di leggere il registro delle transazioni precedentemente memorizzato nella cache dalla cache di prefetch. La cache di prefetch è controllata dal parametro consensus_prefetch_cache_size e il valore predefinito è 64M.
- Se non è richiesto un vecchio registro delle transazioni nella cache di precaricamento, DN proverà ad avviare un'attività IO asincrona, leggerà diversi registri consecutivi prima e dopo il registro delle transazioni specificato dal file Binlog in batch, li inserirà nella cache di precaricamento e attenderà per il prossimo tentativo di lettura di DN Scegli
- Pertanto, DN non richiede alcun intervento manuale quando si tratta di bilanciare i log.
2.4. Ritardo di riproduzione del database in standby
Il ritardo di riproduzione del database in standby è il ritardo tra il momento in cui la stessa transazione viene completata nel database principale e il momento in cui la transazione viene applicata nel database in standby. Ciò che viene testato qui è la prestazione del registro dell'applicazione del database in standby. Influisce sul tempo impiegato dal database in standby per completare l'applicazione dei dati e fornire servizi di lettura e scrittura quando si verifica un'eccezione.
Direttore Generale
- Il database in standby MGR riceve il file RelayLog dal database principale Quando applica l'applicazione, deve leggere nuovamente RelayLog, passare attraverso un processo completo di invio di gruppo in due fasi e produrre i dati e i file Binlog corrispondenti.
- L'efficienza dell'applicazione della transazione qui è la stessa dell'efficienza dell'invio della transazione sul database principale. La configurazione doppia predefinita (innodb_flush_log_at_trx_commit, sync_binlog) causerà un sovraccarico delle stesse risorse dell'applicazione del database in standby.
D.N.
- Il database di backup DN riceve il file Binlog dal database principale Quando si applica, il Binlog deve essere letto nuovamente. È sufficiente passare attraverso il processo di invio del gruppo in una fase e produrre i dati corrispondenti.
- Poiché DN supporta il Crash Recover completo, non è necessario che l'applicazione del database in standby abiliti innodb_flush_log_at_trx_commit=1, quindi non è effettivamente influenzata dalla configurazione double-one.
- Pertanto, in termini di ritardo di riproduzione del database in standby, l'efficienza di riproduzione del database in standby DN sarà molto maggiore di MGR.
2.5. Impatto dei grandi eventi
Le transazioni di grandi dimensioni non influenzano solo l'invio delle transazioni ordinarie, ma influenzano anche la stabilità dell'intero protocollo distribuito in un sistema distribuito. Nei casi più gravi, una transazione di grandi dimensioni renderà l'intero cluster non disponibile per un lungo periodo.
Direttore Generale
- MGR non dispone di alcuna ottimizzazione per supportare transazioni di grandi dimensioni. Aggiunge semplicemente il parametro group_replication_transaction_size_limit per controllare il limite superiore delle transazioni di grandi dimensioni. Il valore predefinito è 143 MB e il massimo è 2 GB.
- Quando il registro delle transazioni supera il limite di transazioni di grandi dimensioni, verrà segnalato direttamente un errore e la transazione non potrà essere inviata.
D.N.
- Per risolvere il problema di instabilità dei sistemi distribuiti causato da transazioni di grandi dimensioni, DN adotta la soluzione di suddivisione di transazioni di grandi dimensioni + suddivisione di oggetti di grandi dimensioni per risolvere il problema. DN dividerà il registro delle transazioni di grandi dimensioni in modo logico e fisico piccoli blocchi, ogni piccolo blocco del registro delle transazioni utilizza la garanzia di commit Paxos completa
- Basandosi sulla soluzione di frazionamento delle transazioni di grandi dimensioni, DN non impone alcuna restrizione sulla dimensione delle transazioni di grandi dimensioni. Gli utenti possono utilizzarle a piacimento e possono anche garantire RPO=0.
- Per istruzioni dettagliate, vedere"Tecnologia di base del motore di archiviazione PolarDB-X | Ottimizzazione di transazioni di grandi dimensioni"
- Pertanto, DN può gestire affari su larga scala senza essere influenzato da affari su larga scala.
2.6 Modulo di distribuzione
Direttore Generale
- MGR supporta le modalità di distribuzione a master singolo e multimaster. In modalità multimaster, ciascun nodo può essere letto e scritto. In modalità a master singolo, il database principale può essere letto e scritto e il database di standby può essere solo letto. soltanto.
- La distribuzione a disponibilità elevata MGR richiede almeno tre distribuzioni di nodi, ovvero almeno tre copie di dati e registri La modalità di registrazione della copia del registro non è supportata.
- MGR non supporta l'espansione dei nodi di sola lettura, ma supporta la combinazione di MGR + modalità di replica master-slave per ottenere un'espansione della topologia simile.
D.N.
- DN supporta la distribuzione in modalità master singolo. In modalità master singolo, il database principale può essere letto e scritto e il database di standby può essere solo di sola lettura.
- La distribuzione ad alta disponibilità DN richiede almeno tre nodi, ma supporta il modulo Logger per la copia del registro, ovvero Leader e Follower sono copie complete. Rispetto a Logger, contiene solo registri e nessun dato e non ha il diritto di esserlo eletto. In questo caso, la distribuzione ad alta disponibilità a tre nodi richiede solo il sovraccarico di archiviazione di 2 copie di dati + 3 copie di log, rendendola una distribuzione a basso costo.
- DN supporta la distribuzione del nodo di sola lettura e la copia di sola lettura del modulo Learner. Rispetto alle copie con funzionalità complete, solo la copia Learner consente la sottoscrizione a valle e il consumo della libreria principale.

2.7. Riepilogo delle funzionalità
| | Direttore Generale | D.N. |
| Efficienza del protocollo | Orario di invio della transazione | 1,5~2,5 RTT | 1 RTT |
| | Persistenza della maggioranza | Salvataggio della memoria XCOM | Persistenza del binlog |
| affidabilità | RPO=0 | Non garantito per impostazione predefinita | Completamente garantito |
| | Rilevamento guasti | Tutti i nodi si controllano a vicenda, il carico della rete è elevato Il ciclo del battito cardiaco non può essere regolato | Il nodo master controlla periodicamente gli altri nodi I parametri del ciclo di battito cardiaco sono regolabili |
| | Recupero dal collasso della maggioranza | intervento manuale | Recupero automatico |
| | Recupero da incidente di minoranza | Ripristino automatico nella maggior parte dei casi, intervento manuale in circostanze particolari | Recupero automatico |
| | Scegli il maestro | Specificare liberamente l'ordine di selezione | Specificare liberamente l'ordine di selezione |
| Legatura del tronco | I log in ritardo non possono superare 1 GB di cache XCOM | I file BInlog non vengono eliminati |
| Ritardo di riproduzione del database in standby | Due palchi + uno doppio, molto lento | Uno stadio + doppio zero, più veloce |
| Grande affare | Il limite predefinito non è superiore a 143 MB | Nessun limite di dimensioni |
| modulo | Costo di disponibilità elevata | Tre copie perfettamente funzionanti, 3 copie di sovraccarico di archiviazione dei dati | Copia del registro del logger, 2 copie dell'archiviazione dei dati |
| nodo di sola lettura | Implementato con replica master-slave | Il protocollo viene fornito con un'implementazione della copia di sola lettura più snella |
3. Confronto dei test
MGR è stato introdotto in MySQL 5.7.17, ma più funzionalità correlate a MGR sono disponibili solo su MySQL 8.0 e in MySQL 8.0.22 e versioni successive le prestazioni complessive saranno più stabili e affidabili. Pertanto, abbiamo selezionato l'ultima versione 8.0.32 di entrambe le parti per i test comparativi.
Considerando che esistono differenze negli ambienti di test, nei metodi di compilazione, nei metodi di distribuzione, nei parametri operativi e nei metodi di test durante i test comparativi di PolarDB-X DN e MySQL MGR, che potrebbero portare a dati di confronto dei test imprecisi, questo articolo si concentrerà su vari dettagli . Procedi come segue:
| preparazione al test | DN PolarDB-X | Gestione MySQL[1] |
| Ambiente hardware | Utilizzando la stessa macchina fisica con memoria 96C da 754 GB e disco SSD |
| sistema operativo | Linux 4.9.168-019.ali3000.alios7.x86_64 |
| Versione del kernel | Utilizzando una linea di base del kernel basata sulla versione 8.0.32 della community |
| Metodo di compilazione | Compilare con lo stesso RelWithDebInfo |
| Parametri operativi | Utilizza lo stesso sito Web ufficiale PolarDB-X per vendere 32C128G con le stesse specifiche e parametri |
| Metodo di distribuzione | Modalità master singolo |
Nota:
- Per MGR il controllo del flusso è abilitato per impostazione predefinita, mentre per PolarDB-X DN il controllo del flusso è disattivato per impostazione predefinita.Pertanto, group_replication_flow_control_mode di MGR è configurato separatamente in modo che le prestazioni di MGR siano le migliori.
- MGR presenta un evidente collo di bottiglia nella lettura durante l'enumerazione, quindi replication_optimize_for_static_plugin_config di MGR è configurato e abilitato separatamente, in modo che le prestazioni di sola lettura di MGR siano le migliori.
3.1
Il test delle prestazioni è la prima cosa a cui tutti prestano attenzione quando si seleziona un database. Qui utilizziamo lo strumento ufficiale sysbench per creare 16 tabelle, ciascuna con 10 milioni di dati, per eseguire test delle prestazioni in scenari OLTP e testare e confrontare le prestazioni dei due in diverse condizioni di concorrenza in diversi scenari OLTP.Considerando le diverse situazioni di implementazione effettiva, simuliamo rispettivamente i seguenti quattro scenari di implementazione:
- Tre nodi sono distribuiti nella stessa sala computer. Si verifica un ritardo di rete di 0,1 ms quando le macchine si eseguono il ping tra loro.
- Tre centri nella stessa città e tre sale computer nella stessa regione distribuiscono tre nodi. C'è un ritardo di rete di 1 ms nel ping tra le sale computer (ad esempio: tre sale computer a Shanghai).
- Tre centri in due luoghi, tre nodi distribuiti in tre sale computer in due luoghi, ping di rete di 1 ms tra sale computer nella stessa città, ritardo di rete di 30 ms tra la stessa città e un altro luogo (ad esempio: Shanghai/Shanghai/Shenzhen)
- Tre centri in tre luoghi, tre nodi distribuiti in tre sale computer in tre luoghi (ad esempio: Shanghai/Hangzhou/Shenzhen), il ritardo della rete tra Hangzhou e Shanghai è di circa 5 ms e la distanza più lontana da Hangzhou/Shanghai a Shenzhen è di 30 ms .
illustrare:
a. Considerare il confronto orizzontale delle prestazioni di quattro scenari di distribuzione. Tre centri in due luoghi e tre centri in tre luoghi adottano tutti la modalità di distribuzione di 3 copie. L'attività di produzione reale può essere estesa alla modalità di distribuzione di 5 copie.
b. Considerando le rigide restrizioni su RPO=0 quando si utilizzano prodotti di database ad alta disponibilità, MGR è configurato con RPO<>0 per impostazione predefinita. Qui continueremo ad aggiungere test comparativi tra MGR RPO<>0 e RPO=0 in ciascuno scenario di distribuzione.
- MGR_0 rappresenta i dati per il caso di MGR RPO = 0
- MGR_1 rappresenta i dati per il caso di MGR RPO <> 0
- DN rappresenta i dati per il caso di DN RPO = 0
3.1.1. Stessa sala computer
| | | 1 | 4 | 16 | 64 | 256 |
| oltp_sola_lettura | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| MGR_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 |
| D.N. | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 |
| MGR_0 contro MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% |
| DN contro MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% |
| DN contro MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% |
| oltp_lettura_scrittura | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| MGR_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 |
| D.N. | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 |
| MGR_0 contro MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% |
| DN contro MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% |
| DN contro MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% |
| oltp_scrivere_solo | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| MGR_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 |
| D.N. | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 |
| MGR_0 contro MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% |
| DN contro MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% |
| DN contro MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
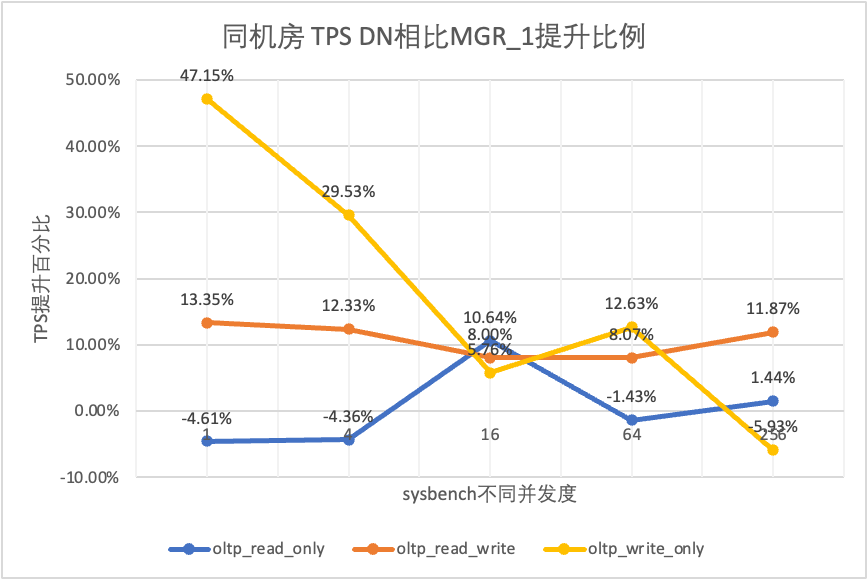
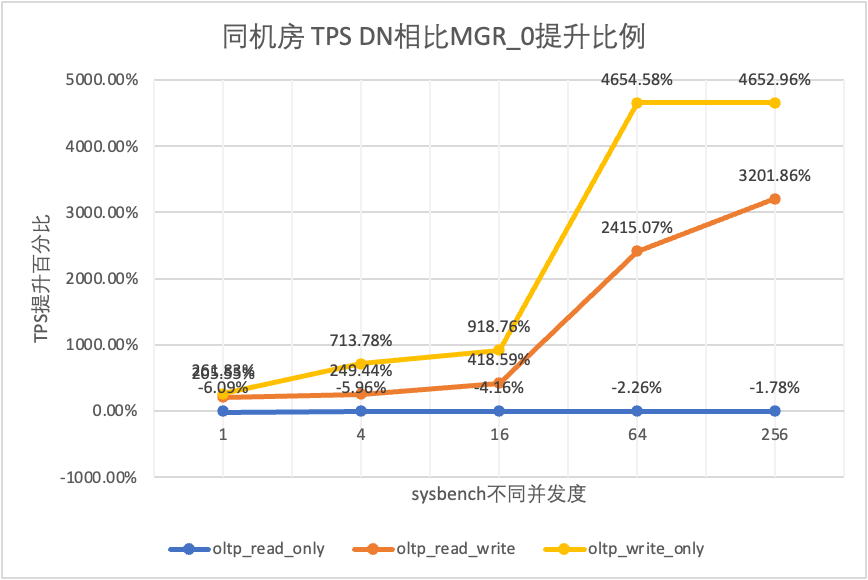
Dai risultati del test si può vedere:
- Nello scenario di sola lettura, confrontando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la differenza tra DN e MGR è stabile tra -5% e 10%, che può essere considerata sostanzialmente la stessa. Il fatto che RPO sia uguale a 0 non ha alcun effetto sulle transazioni di sola lettura
- Nello scenario di transazione mista di lettura-scrittura e sola scrittura, le prestazioni di DN (RPO=0) sono migliorate dal 5% al 47% rispetto a MGR_1 (RPO<>0) e il vantaggio prestazionale di DN è evidente quando il la concorrenza è bassa e il vantaggio quando la concorrenza è elevata Caratteristiche non ovvie. Questo perché l'efficienza del protocollo di DN è maggiore quando la concorrenza è bassa, ma i punti caldi delle prestazioni di DN e MGR in caso di concorrenza elevata sono tutti in fase di pulizia.
- Con la stessa premessa di RPO=0, negli scenari di transazioni miste di lettura-scrittura e di sola scrittura, le prestazioni di DN migliorano da 2 a 46 volte rispetto a MGR_0 e, con l'aumento della concorrenza, il vantaggio prestazionale di DN aumenta. Non c'è da stupirsi che anche MGR abbandoni RPO=0 per le prestazioni per impostazione predefinita.
3.1.2. Tre centri nella stessa città
| Confronto TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_sola_lettura | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| MGR_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 |
| D.N. | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 |
| MGR_0 contro MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% |
| DN contro MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% |
| DN contro MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% |
| oltp_lettura_scrittura | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| MGR_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 |
| D.N. | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 |
| MGR_0 contro MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% |
| DN contro MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% |
| DN contro MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% |
| oltp_scrivere_solo | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| MGR_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 |
| D.N. | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 |
| MGR_0 contro MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% |
| DN contro MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% |
| DN contro MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Dai risultati del test si può vedere:
- Nello scenario di sola lettura, confrontando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la differenza tra DN e MGR è stabile tra -7% e 5%, che può essere considerata sostanzialmente la stessa. Il fatto che RPO sia uguale a 0 non ha alcun effetto sulle transazioni di sola lettura
- In uno scenario di transazione mista di lettura-scrittura e sola scrittura, le prestazioni di DN (RPO=0) sono migliorate dal 30% al 120% rispetto a MGR_1 (RPO<>0) e il vantaggio prestazionale di DN è evidente quando la concorrenza è basso e quando la concorrenza è elevata, le prestazioni sono migliori Funzionalità non ovvie. Questo perché l'efficienza del protocollo di DN è maggiore quando la concorrenza è bassa, ma i punti caldi delle prestazioni di DN e MGR in caso di concorrenza elevata sono tutti in fase di pulizia.
- Con la stessa premessa di RPO=0, negli scenari di transazioni miste di lettura-scrittura e di sola scrittura, le prestazioni di DN migliorano da 1 a 14 volte rispetto a MGR_0 e, con l'aumento della concorrenza, il vantaggio prestazionale di DN aumenta. Non c'è da stupirsi che anche MGR abbandoni RPO=0 per le prestazioni per impostazione predefinita.
3.1.3. Due luoghi e tre centri
| Confronto TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_sola_lettura | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| MGR_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 |
| D.N. | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 |
| MGR_0 contro MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% |
| DN contro MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% |
| DN contro MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% |
| oltp_lettura_scrittura | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| MGR_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 |
| D.N. | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 |
| MGR_0 contro MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% |
| DN contro MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% |
| DN contro MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% |
| oltp_scrivere_solo | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| MGR_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 |
| D.N. | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 |
| MGR_0 contro MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% |
| DN contro MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% |
| DN contro MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
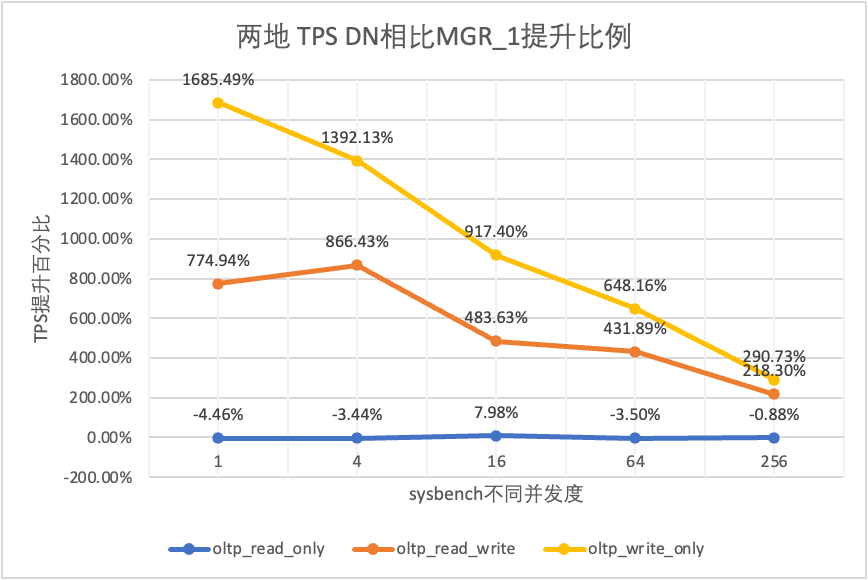
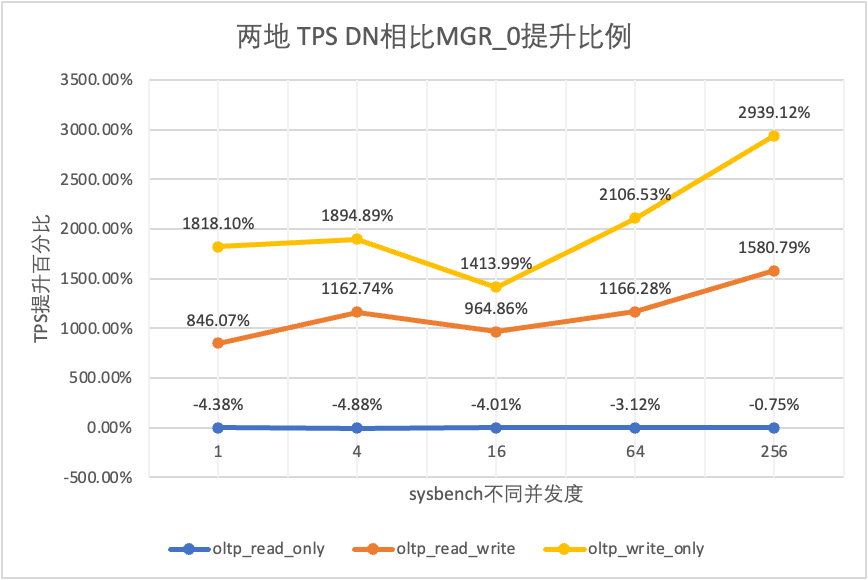
Dai risultati del test si può vedere:
- Nello scenario di sola lettura, confrontando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la differenza tra DN e MGR è stabile tra -4% e 7%, che può essere considerata sostanzialmente la stessa. Il fatto che RPO sia uguale a 0 non ha alcun effetto sulle transazioni di sola lettura
- Nello scenario di transazione mista di lettura-scrittura e sola scrittura, le prestazioni di DN (RPO=0) sono migliorate da 2 a 16 volte rispetto a MGR_1 (RPO<>0) e il vantaggio prestazionale di DN è evidente quando la concorrenza è basso e il vantaggio quando la concorrenza è elevata Caratteristiche non ovvie. Questo perché l'efficienza del protocollo di DN è maggiore quando la concorrenza è bassa, ma i punti caldi delle prestazioni di DN e MGR in caso di concorrenza elevata sono tutti in fase di pulizia.
- Con la stessa premessa di RPO=0, negli scenari di transazioni miste di lettura-scrittura e di sola scrittura, le prestazioni di DN migliorano da 8 a 29 volte rispetto a MGR_0 e, con l'aumento della concorrenza, il vantaggio prestazionale di DN aumenta. Non c'è da stupirsi che anche MGR abbandoni RPO=0 per le prestazioni per impostazione predefinita.
3.1.4. Tre luoghi e tre centri
| Confronto TPS | | 1 | 4 | 16 | 64 | 256 |
| oltp_sola_lettura | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| MGR_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 |
| D.N. | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 |
| MGR_0 contro MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% |
| DN contro MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% |
| DN contro MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% |
| oltp_lettura_scrittura | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| MGR_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 |
| D.N. | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 |
| MGR_0 contro MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% |
| DN contro MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% |
| DN contro MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% |
| oltp_scrivere_solo | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| MGR_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 |
| D.N. | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 |
| MGR_0 contro MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% |
| DN contro MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% |
| DN contro MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
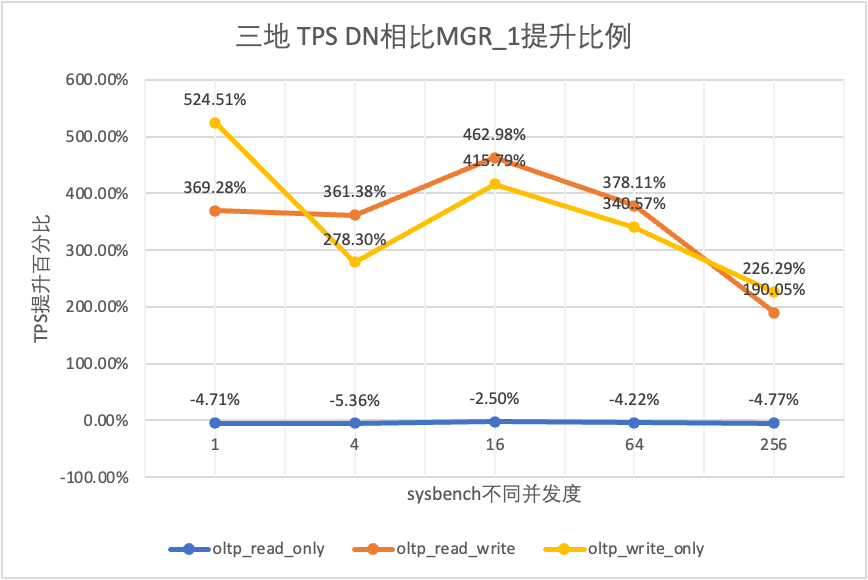
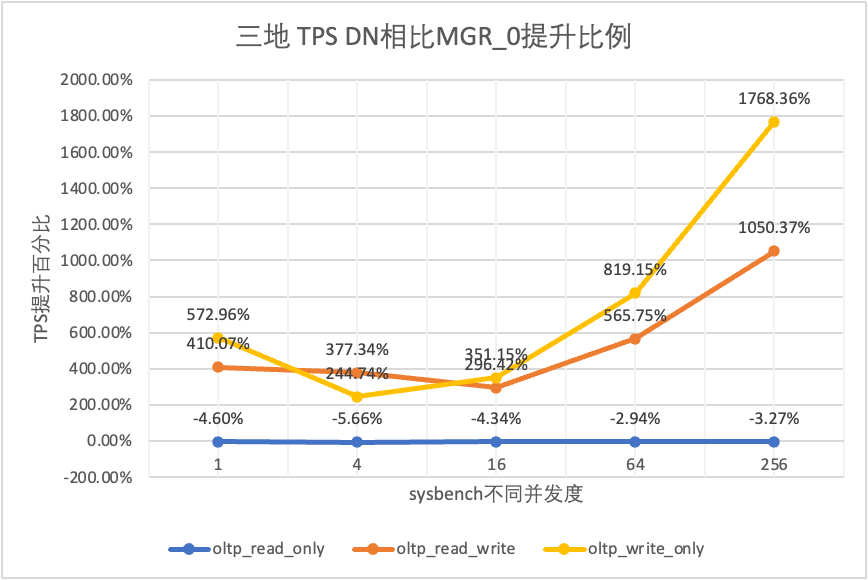
Dai risultati del test si può vedere:
- Nello scenario di sola lettura, confrontando MGR_1 (RPO<>0) o MGR_0 (RPO=0), la differenza tra DN e MGR è stabile tra -5% e 0%, che può essere considerata sostanzialmente la stessa. Il fatto che RPO sia uguale a 0 non ha alcun effetto sulle transazioni di sola lettura
- Nello scenario di transazione mista di lettura-scrittura e sola scrittura, le prestazioni di DN (RPO=0) sono migliorate da 2 a 5 volte rispetto a MGR_1 (RPO<>0) e il vantaggio prestazionale di DN è evidente quando la concorrenza è basso e il vantaggio in caso di concorrenza è elevato Caratteristiche non ovvie. Questo perché l'efficienza del protocollo di DN è maggiore quando la concorrenza è bassa, ma i punti caldi delle prestazioni di DN e MGR in caso di concorrenza elevata sono tutti in fase di pulizia.
- Con la stessa premessa di RPO=0, negli scenari di transazioni miste di lettura-scrittura e di sola scrittura, le prestazioni di DN migliorano da 2 a 17 volte rispetto a MGR_0 e, con l'aumento della concorrenza, il vantaggio prestazionale di DN aumenta. Non c'è da stupirsi che anche MGR abbandoni RPO=0 per le prestazioni per impostazione predefinita.
3.1.5. Confronto della distribuzione
Per confrontare chiaramente le modifiche delle prestazioni con diversi metodi di distribuzione, abbiamo selezionato i dati TPS di MGR e DN con diversi metodi di distribuzione nella concorrenza dello scenario 256 oltp_write_only nel test precedente Utilizzando i dati dei test della sala computer come base, abbiamo calcolato e confrontato i dati TPS di diversi metodi di distribuzione Rapporto rispetto alla linea di base per percepire la differenza nei cambiamenti di prestazioni durante la distribuzione in più città
| | MGR_1 (256 simultanei) | DN (256 simultanei) | Vantaggi prestazionali di DN rispetto a MGR |
| Stessa aula informatica | 16092.02 | 15137.23 | -5.93% |
| Tre centri nella stessa città | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Due luoghi e tre centri | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Tre luoghi e tre centri | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
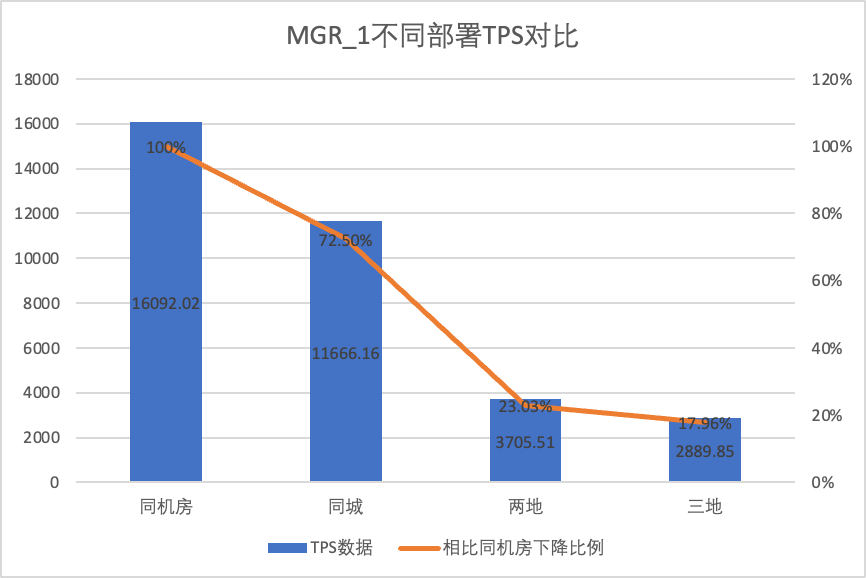
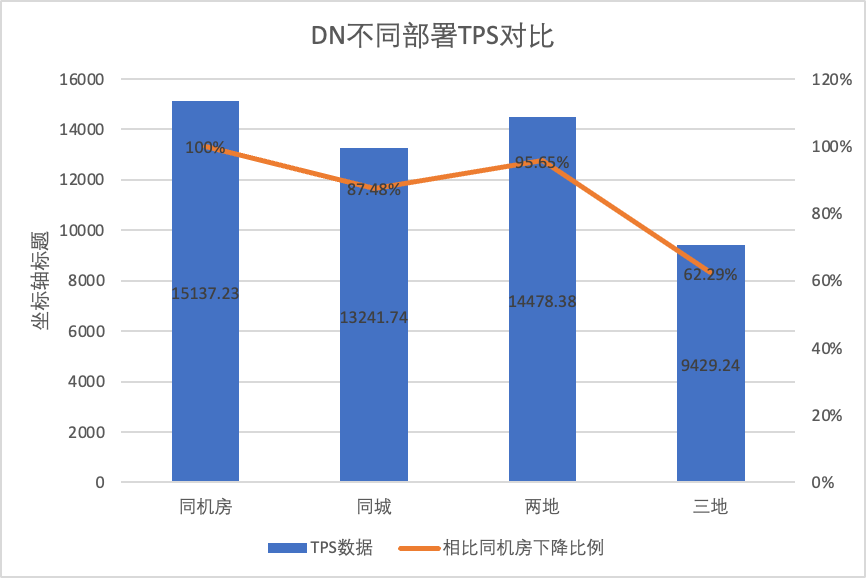
Dai risultati del test si può vedere:
- Con l'espansione del metodo di distribuzione, il TPS di MGR_1 (RPO<>0) è diminuito in modo significativo. Rispetto all'implementazione nella stessa sala computer, le prestazioni dell'implementazione su più sale computer nella stessa città sono diminuite del 27,5%. di diffusione della RT nelle città (tre centri in due luoghi, tre centri in tre luoghi) Una diminuzione del 77%~82%, dovuta all'aumento della diffusione della RT nelle città.
- DN (RTO=0) è relativamente stabile Rispetto all'implementazione nella stessa sala computer, la prestazione dell'implementazione di sale cross-computer nella stessa città e dell'implementazione di tre centri in due luoghi è diminuita dal 4% al 12%. Le prestazioni dell’implementazione di tre centri in tre luoghi sono diminuite del 37% in caso di elevata latenza della rete. Ciò è dovuto anche alla maggiore implementazione della RT nelle città.Tuttavia, grazie al meccanismo Batch&Pipeline di DN, l'impatto tra città può essere risolto aumentando la concorrenza. Ad esempio, con l'architettura a tre luoghi e tre centri, con >= 512 concomitanza, il throughput delle prestazioni nella stessa città e due. luoghi e tre centri possono essere sostanzialmente allineati.
- Si può vedere che l'implementazione in tutta la città ha un grande impatto su MGR_1 (RPO<>0)
3.1.6. Jitter delle prestazioni
Nell'uso reale, non prestiamo attenzione solo ai dati sulle prestazioni, ma dobbiamo prestare attenzione anche al jitter delle prestazioni. Dopotutto, se il jitter è come le montagne russe, l'effettiva esperienza dell'utente sarà molto scarsa. Monitoriamo e visualizziamo i dati di output del TPS in tempo reale Considerando che lo strumento sysbenc stesso non supporta i dati di monitoraggio dell'output del jitter delle prestazioni, utilizziamo il coefficiente matematico di variazione come indicatore di confronto:
- Coefficiente di variazione (CV): il coefficiente di variazione è la deviazione standard divisa per la media. Viene spesso utilizzato per confrontare le fluttuazioni di diversi set di dati, soprattutto quando le differenze medie sono grandi. Maggiore è il CV, maggiore è la fluttuazione dei dati rispetto alla media.
Prendendo come esempio lo scenario simultaneo di 256 oltp_read_write, analizziamo statisticamente il TPS di MGR_1 (RPO<>0) e DN (RPO=0) nella stessa sala computer, tre centri nella stessa città, tre centri in due luoghi e tre centri in tre posti situazione di Jitter. Il grafico del jitter effettivo è il seguente e i dati dell'indicatore di jitter effettivo per ciascuno scenario sono i seguenti:
| CV | Stessa aula informatica | Tre centri nella stessa città | Due luoghi e tre centri | Tre luoghi e tre centri |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| D.N. | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
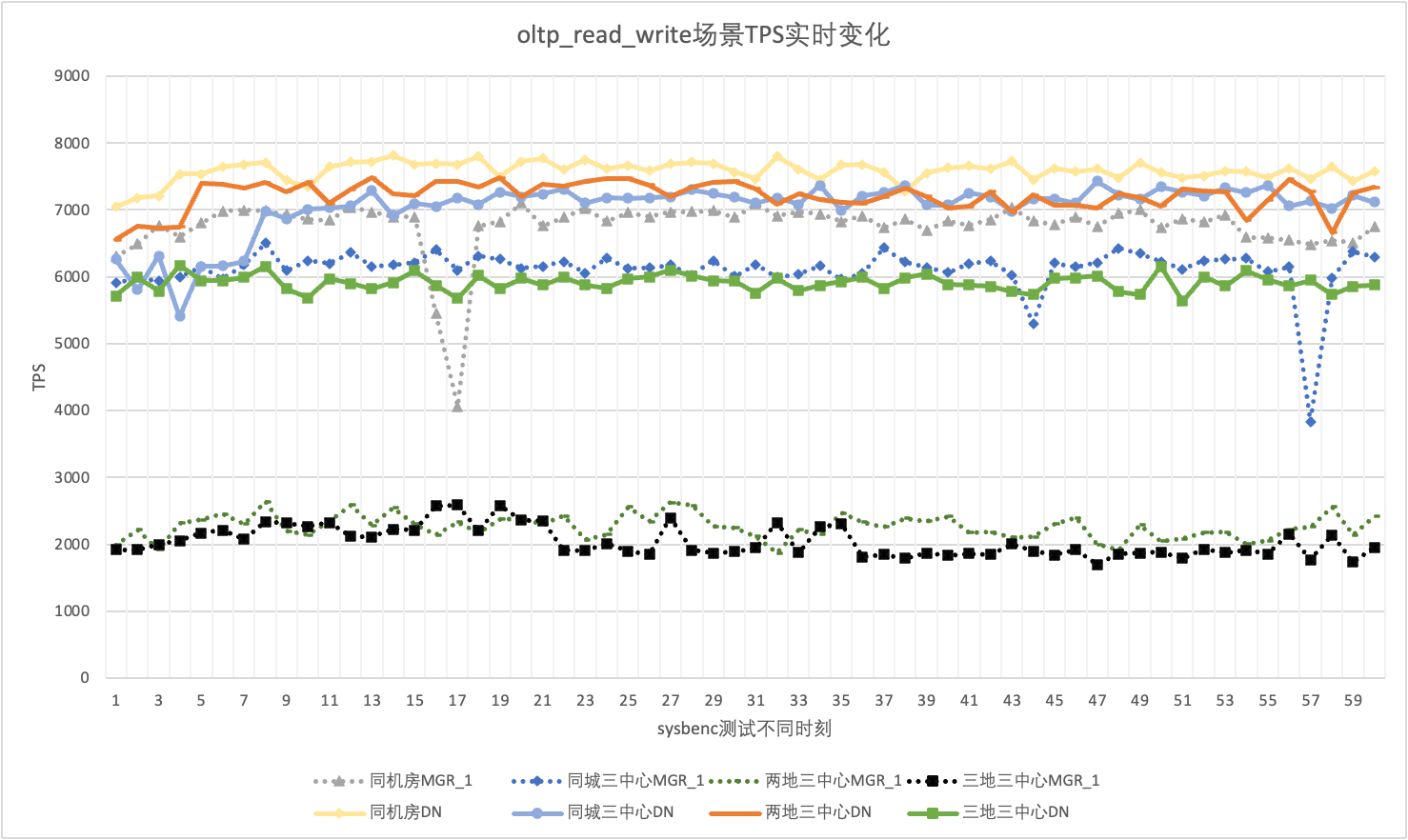
Dai risultati del test si può vedere:
- Il TPS di MGR è in uno stato instabile nello scenario oltp_read_write e diminuisce improvvisamente senza motivo. Questo fenomeno è stato riscontrato in più test in più scenari di distribuzione. In confronto, DN è molto stabile.
- Calcolando il coefficiente di variazione CV, il CV di MGR è molto ampio, dal 6% al 10%, e raggiunge anche il valore massimo del 10% quando il ritardo nella stessa sala computer è minimo, mentre il CV di DN è relativamente stabile, dal 2% al 4 %, e la performance di DN è più stabile di quella di MGR Sex è sostanzialmente due volte più alta
- Si può vedere che il jitter prestazionale di MGR_1 (RPO<>0) è relativamente elevato
3.2. RTO
La caratteristica principale di un database distribuito è l'elevata disponibilità. Il guasto di qualsiasi nodo nel cluster non influirà sulla disponibilità complessiva. Per la tipica forma di distribuzione di 3 nodi con un master e due backup distribuiti nella stessa sala computer, abbiamo provato a condurre test di usabilità nei seguenti tre scenari:
- Interrompere il database principale, quindi riavviarlo e osservare il tempo RTO affinché il cluster ripristini la disponibilità durante il processo.
- Interrompere qualsiasi database in standby e quindi riavviarlo per osservare le prestazioni di disponibilità del database primario durante il processo.
3.2.1. Tempo di inattività del database principale + riavvio
Quando non c'è carico, uccidi il leader e monitora i cambiamenti di stato di ciascun nodo nel cluster e se è scrivibile.
| | Direttore Generale | D.N. |
| Inizio normalmente | 0 | 0 |
| uccidere il leader | 0 | 0 |
| Rilevato tempo del nodo anomalo | 5 | 5 |
| È ora di ridurre 3 nodi a 2 nodi | 23 | 8 |
| | Direttore Generale | D.N. |
| Inizio normalmente | 0 | 0 |
| uccidi il leader, tirati su automaticamente | 0 | 0 |
| Rilevato tempo del nodo anomalo | 5 | 5 |
| È ora di ridurre 3 nodi a 2 nodi | 23 | 8 |
| Ripristino su 2 nodi Tempo su 3 nodi | 37 | 15 |

Dai risultati del test si può vedere che in assenza di pressione:
- L'RTO di DN è 8-15 secondi, sono necessari 8 secondi per ridurre a 2 nodi e 15 secondi per ripristinare 3 nodi;
- L'RTO di MGR è 23-37 secondi. Sono necessari 23 secondi per eseguire il downgrade a 2 nodi e 37 secondi per ripristinare 3 nodi.
- Prestazioni RTO DN è complessivamente migliore di MGR
3.2.2. Tempo di inattività del database in standby + riavvio
Utilizzare sysbench per condurre uno stress test simultaneo di 16 thread nello scenario oltp_read_write Al decimo secondo nella figura, uccidere manualmente un nodo di standby e osservare i dati TPS di output in tempo reale di sysbench.
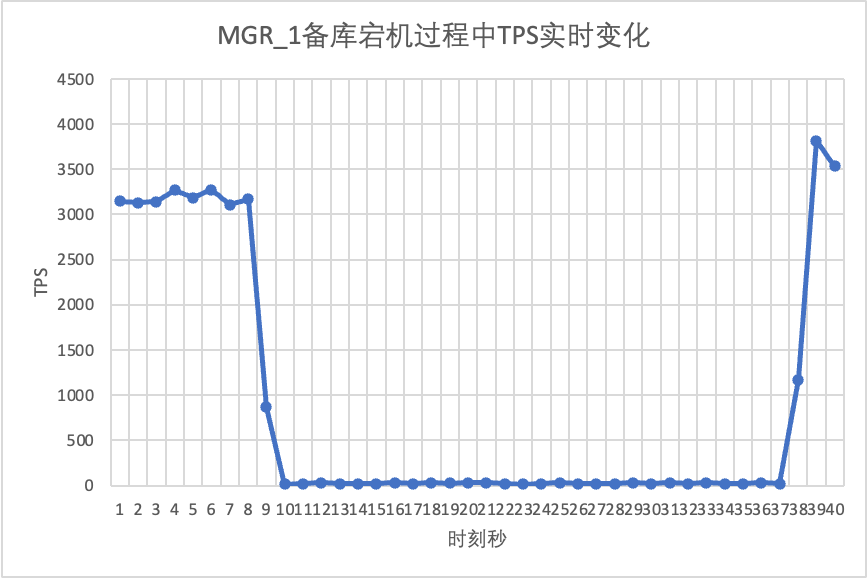


Si può vedere dalla tabella dei risultati del test:
- Dopo che il database in standby è stato interrotto, il TPS del database principale di MGR è diminuito in modo significativo ed è durato circa 20 secondi prima di tornare ai livelli normali. Secondo l'analisi dei log, ci sono due processi qui: il rilevamento che il nodo difettoso è diventato irraggiungibile e l'espulsione del nodo difettoso dal cluster MGR. Questo test ha confermato un difetto che circolava da molto tempo nella comunità MGR. Anche se solo 1 nodo su 3 non è disponibile,L'intero cluster ha sperimentato forti nervosismi per un periodo di tempo ed è diventato non disponibile.
- Per risolvere il problema dell'MGR a master singolo che presenta un guasto a un singolo nodo e l'intera istanza non è disponibile, la comunità ha introdotto la funzione MGR paxos single leader nella versione 8.0.27 per risolvere il problema, ma è disattivata per impostazione predefinita. Qui attiviamo group_replication_paxos_single_leader e continuiamo a verificare Dopo aver interrotto questa volta il database in standby, le prestazioni del database principale rimangono stabili e leggermente migliorate. Il motivo dovrebbe essere legato alla riduzione del carico di rete.
- Per DN, dopo l'interruzione del database in standby, il TPS del database principale è aumentato immediatamente di circa il 20%, per poi rimanere stabile e il cluster era sempre disponibile.Questo è l'opposto di MGR. Il motivo è che dopo aver interrotto un database in standby, il database principale deve inviare ogni volta solo i registri al database in standby rimanente. Il processo di invio e ricezione dei pacchetti di rete è più efficiente.
Continuando il test, riavviamo e ripristiniamo il database in standby e osserviamo le modifiche nei dati TPS del database principale.
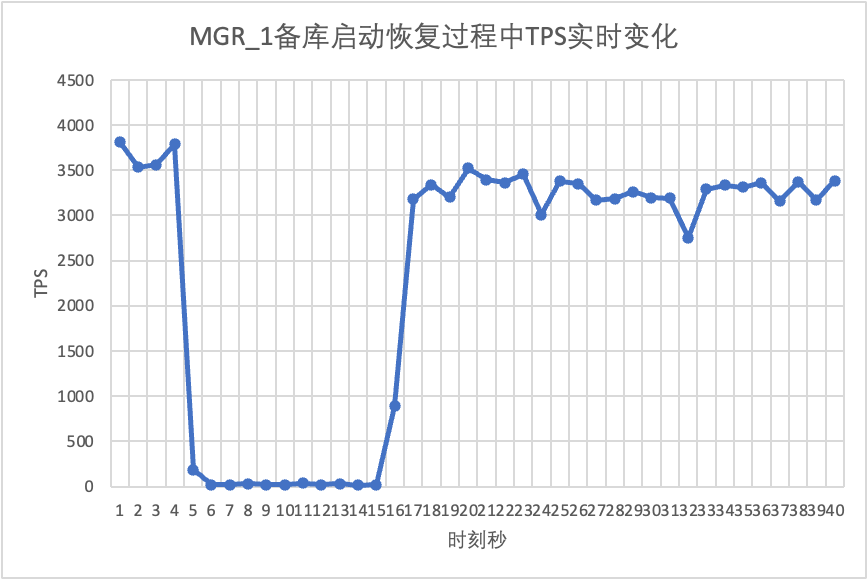
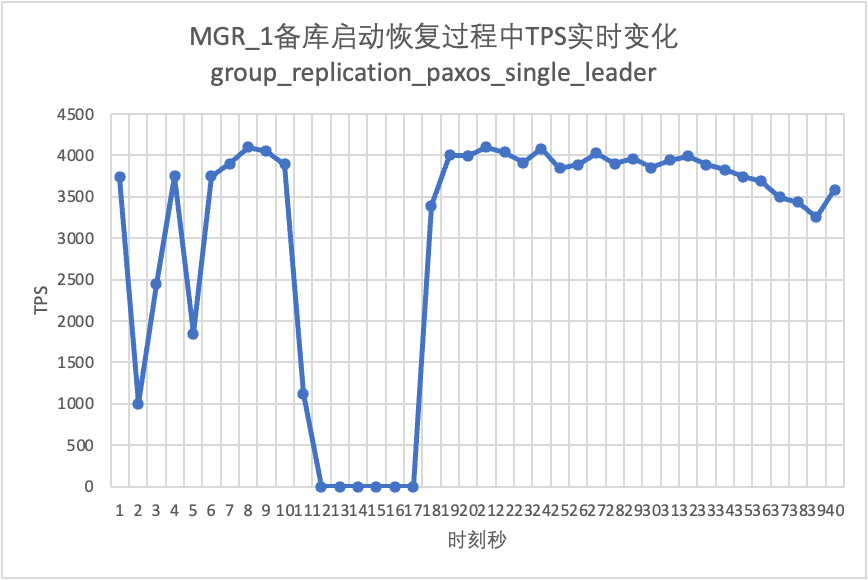
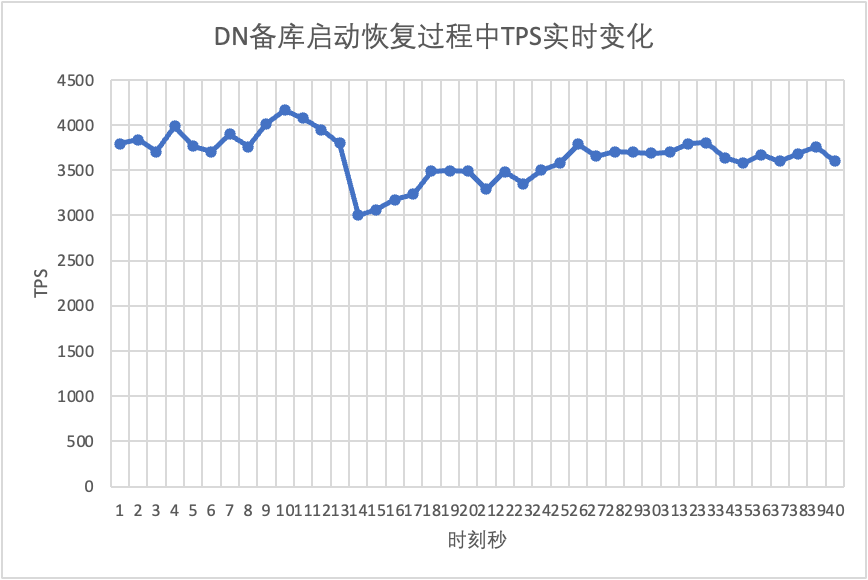
Si può vedere dalla tabella dei risultati del test:
- MGR ha recuperato da 2 nodi a 3 nodi in 5 secondi.Ma c'è anche una situazione in cui la libreria principale non è disponibile, il che dura circa 12 secondi.Sebbene il nodo in standby si sia finalmente unito al cluster, lo stato MEMBER_STATE è sempre stato RECOVERING, indicando che in questo momento è in corso la ricerca dei dati.
- Nello scenario successivo all'abilitazione di group_replication_paxos_single_leader, viene verificato anche il riavvio del database in standby. Di conseguenza, MGR ripristina da 2 a 3 nodi in 10 secondi.Ma c'era ancora un tempo non disponibile della durata di circa 7 secondi.Sembra che questo parametro non possa risolvere completamente il problema dell'MGR a master singolo che presenta un guasto a un singolo nodo e l'intera istanza non è disponibile.
- Per DN, il database in standby viene ripristinato da 2 a 3 nodi in 10 secondi e il database principale rimane disponibile. In questo caso si verificheranno fluttuazioni a breve termine nel TPS. Ciò è dovuto al ritardo nella replica dei registri dovuto al riavvio del database in standby. È necessario estrarre i registri in ritardo dal database principale, quindi avrà un impatto minimo sul database principale dopo la revisione del registro, le prestazioni generali saranno stabili.
3.3. L'RPO
Per costruire lo scenario RPO<>0 di errore della maggioranza di MGR, utilizziamo il metodo MTR Case della comunità per eseguire test di iniezione di guasti su MGR. Il caso progettato è il seguente:
--echo ############################################################
--echo # 1. Deploy a 3 members group in single primary mode.
--source include/have_debug.inc
--source include/have_group_replication_plugin.inc
--let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
--let $rpl_group_replication_single_primary_mode=1
--let $rpl_skip_group_replication_start= 1
--let $rpl_server_count= 3
--source include/group_replication.inc
--let $rpl_connection_name= server1
--source include/rpl_connection.inc
--let $server1_uuid= `SELECT @@server_uuid`
--source include/start_and_bootstrap_group_replication.inc
--let $rpl_connection_name= server2
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
--source include/start_group_replication.inc
--echo ############################################################
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
--source include/rpl_sync.inc
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
--echo ############################################################
--echo # 3. Mock crash majority members
--echo # server 2 wait before write relay log
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 3 wait before write relay log
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
--echo # server 1 commit new transaction
--let $rpl_connection_name = server1
--source include/rpl_connection.inc
INSERT INTO t1 VALUES(2);
# server 1 commit t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--source include/kill_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 crash and restart
--source include/kill_and_restart_mysqld.inc
--echo # sleep enough time for electing new leader
--echo ############################################################
--echo # 4. Check alive members, lost t1(c1=2) record
--let $rpl_connection_name= server3
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 3 lost t1(c1=2) record
--let $rpl_connection_name = server2
--source include/rpl_connection.inc
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
--echo # server 2 lost t1(c1=2) record

loose-group_replication_member_weight=100
loose-group_replication_member_weight=90
loose-group_replication_member_weight=80
SERVER_MYPORT_3= @mysqld.3.port
SERVER_MYSOCK_3= @mysqld.3.socket
I risultati dell'esecuzione del caso sono i seguenti:
############################################################
# 1. Deploy a 3 members group in single primary mode.
include/group_replication.inc [rpl_server_count=3]
Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
include/start_and_bootstrap_group_replication.inc
include/start_group_replication.inc
include/start_group_replication.inc
############################################################
CREATE TABLE t1 (c1 INT PRIMARY KEY);
INSERT INTO t1 VALUES(1);
############################################################
# 3. Mock crash majority members
# server 2 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 3 wait before write relay log
SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
# server 1 commit new transaction
INSERT INTO t1 VALUES(2);
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
# server 3 crash and restart
# sleep enough time for electing new leader
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
# server 2 crash and restart
# sleep enough time for electing new leader
############################################################
# 4. Check alive members, lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 3 lost t1(c1=2) record
select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
group_replication_applier NULL OFFLINE
# server 2 lost t1(c1=2) record
La logica approssimativa di un caso che riproduce numeri mancanti è la seguente:
- MGR è composto da 3 nodi in modalità single-master, Server 1/2/3, dove Server 1 è il database principale e inizializza 1 record c1=1
- Il server Fault injection 2/3 si bloccherà durante la scrittura del registro di inoltro
- Connesso al nodo Server 1, ha scritto il record di c1=2 e anche il commit della transazione ha restituito successo.
- Quindi il server Mock1 si blocca in modo anomalo (guasto della macchina, non può essere ripristinato e non è possibile accedervi). In questo momento, il Server 2/3 è lasciato a formare la maggioranza.
- Riavviare il Server 2/3 normalmente (ripristino rapido), ma il Server 2/3 non può ripristinare il cluster a uno stato utilizzabile.
- Connettersi al nodo Server 2/3 ed interrogare i record del database Viene visualizzato solo il record di c1=1 (il Server 2/3 ha perso c1=2).
In base al caso precedente, per MGR, quando la maggior parte dei server è inattiva e il database principale non è disponibile, e dopo che il database di standby viene ripristinato, si verificherà una perdita di dati di RPO<>0 e il record di commit riuscito che originariamente restituito al cliente è andato perduto.
Per DN, il raggiungimento della maggioranza richiede che i log siano persistenti nella maggioranza, quindi anche nello scenario precedente i dati non andranno persi e può essere garantito RPO=0.
3.4. Ritardo di riproduzione del database in standby
Nella tradizionale modalità active-standby di MySQL, il database in standby contiene generalmente thread IO e thread Apply. Dopo l'introduzione del protocollo Paxos, il thread IO sincronizza principalmente il binlog dei database attivo e in standby dipende dal sovraccarico della riproduzione applicata del database in standby, qui diventiamo il ritardo della riproduzione del database in standby.
Utilizziamo sysbench per testare lo scenario oltp_write_only e testare la durata del ritardo nella riproduzione del database in standby con 100 simultaneità e un numero diverso di eventi.Il tempo di ritardo della riproduzione del database in standby può essere determinato monitorando la colonna APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP della tabella performance_schema.replication_applier_status_by_worker per verificare se ogni lavoratore sta lavorando in tempo reale per determinare se la replica è terminata.

Si può vedere dalla tabella dei risultati del test:
- Con la stessa quantità di dati scritti, il tempo di completamento della riproduzione del database in standby di DN di tutti i registri è di gran lunga migliore di quello del consumo di tempo di MGR, pari solo al 3%-4% di quello di MGR. Questo è fondamentale per la tempestività della commutazione attivo/standby.
- Con l'aumento del numero di scritture, il vantaggio di latenza di riproduzione del database in standby di DN rispetto a MGR continua a essere mantenuto ed è molto stabile.
- Analizzando le ragioni del ritardo nella riproduzione del database in standby, la strategia di riproduzione del database in standby di MGR adotta group_replication_consistency con il valore predefinito di EVENTUAL, ovvero le transazioni RO e RW non attendono l'applicazione delle transazioni precedenti prima dell'esecuzione. Ciò può garantire le massime prestazioni di scrittura del database principale, ma il ritardo del database in standby sarà relativamente elevato (sacrificando il ritardo del database in standby e RPO=0 in cambio di una scrittura ad alte prestazioni del database principale, attivando la funzione di limitazione corrente di MGR può bilanciare le prestazioni e il database in standby subisce ritardi, ma le prestazioni del database principale verranno compromesse)
3.5. Riepilogo della prova
| | Direttore Generale | D.N. |
| prestazione | Leggi la transazione | Piatto | Piatto |
| scrivere transazione | Le prestazioni non sono buone quanto quelle DN quando RPO<>0 Quando RPO=0, le prestazioni sono di gran lunga inferiori a DN Le prestazioni di implementazione in città sono diminuite notevolmente del 27% ~ 82% | Le prestazioni delle transazioni di scrittura sono molto più elevate di quelle di MGR Le prestazioni di implementazione in città diminuiscono dal 4% al 37%. |
| Jitter | Il jitter delle prestazioni è grave, l'intervallo del jitter è del 6~10% | Relativamente stabile al 3%, solo la metà di MGR |
| RTO | Il database principale è inattivo | L'anomalia è stata scoperta in 5 secondi e ridotta a due nodi in 23 secondi. | L'anomalia è stata scoperta in 5 secondi e ridotta a due nodi in 8 secondi. |
| Riavviare la libreria principale | È stata scoperta un'anomalia in 5 secondi e tre nodi sono stati ripristinati in 37 secondi. | Viene rilevata un'anomalia in 5 secondi e tre nodi vengono ripristinati in 15 secondi. |
| Tempo di inattività del database di backup | Il traffico del database principale è sceso a 0 per 20 secondi. Può essere alleviato attivando esplicitamente group_replication_paxos_single_leader. | Alta disponibilità continua del database principale |
| Riavvio del database in standby | Il traffico del database principale è sceso a 0 per 10 secondi. Anche l'attivazione esplicita di group_replication_paxos_single_leader non ha alcun effetto. | Alta disponibilità continua del database principale |
| RPO | Ricorrenza del caso | RPO<>0 quando cade il partito di maggioranza Prestazioni e RPO=0 non possono avere entrambi. | RPO = 0 |
| Ritardo del database in standby | Tempo di riproduzione del database di backup | Il ritardo tra attivo e standby è molto ampio. Non è possibile ottenere contemporaneamente le prestazioni e la latenza del backup primario. | Il tempo totale impiegato nella riproduzione complessiva del database in standby è pari al 4% di MGR, ovvero 25 volte quello di MGR. |
| parametro | parametro chiave |
- Il controllo di flusso group_replication_flow_control_mode è abilitato per impostazione predefinita e deve essere configurato per disattivarlo per migliorare le prestazioni.
- replication_optimize_for_static_plugin_config l'ottimizzazione del plug-in statico è disattivata per impostazione predefinita e deve essere attivata per migliorare le prestazioni
- group_replication_paxos_single_leader è disattivato per impostazione predefinita e deve essere attivato per migliorare la stabilità del database principale quando il database di standby è inattivo.
- group_replication_consistency è disattivato per impostazione predefinita e non garantisce RPO=0 Se è richiesto RPO=0, è necessario configurare AFTER.
- Il valore predefinito group_replication_transaction_size_limit è 143 milioni, che deve essere aumentato quando si riscontrano transazioni di grandi dimensioni.
- binlog_transaction_dependency_tracking predefinito su COMMIT_ORDER deve essere modificato su WRITESET per migliorare le prestazioni di riproduzione del database in standby.
| Configurazione predefinita, non è necessario che i professionisti personalizzino la configurazione |
4. Riepilogo
Dopo un'analisi tecnica approfondita e un confronto delle prestazioni,PolarDB-X Con il suo protocollo X-Paxos sviluppato autonomamente e una serie di design ottimizzati, DN ha dimostrato molti vantaggi rispetto a MySQL MGR in termini di prestazioni, correttezza, disponibilità e sovraccarico delle risorse. Tuttavia, MGR occupa anche una posizione importante nell'ecosistema MySQL , è necessario considerare varie situazioni come il jitter di interruzione del database in standby, le fluttuazioni delle prestazioni di ripristino di emergenza tra sale macchine e la stabilità. Pertanto, se si desidera fare buon uso di MGR, è necessario disporre di un team tecnico professionale, operativo e di manutenzione supporto.
Di fronte a requisiti su larga scala, elevata concorrenza e alta disponibilità, il motore di archiviazione PolarDB-X presenta vantaggi tecnici unici e prestazioni eccellenti rispetto a MGR in scenari pronti all'uso.PolarDB-XLa versione centralizzata su base DN (versione standard) presenta un buon equilibrio tra funzioni e prestazioni, rendendola una soluzione di database altamente competitiva.

