
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
ご存知のとおり、MySQL のプライマリ データベースとセカンダリ データベース (2 つのノード) は、通常、非同期レプリケーションと半同期レプリケーション (Semi-Sync) を通じて高いデータ可用性を実現します。ただし、コンピュータ ルームのネットワーク障害やホストのハングアップなどの異常なシナリオでは、プライマリ アーキテクチャとセカンダリ アーキテクチャでは、HA 切り替え後に重大な問題が発生する可能性があります (RPO!=0 と呼ばれます)。したがって、ビジネス データがある程度重要な場合は、MySQL プライマリ アーキテクチャとセカンダリ アーキテクチャ (2 ノード) のデータベース製品を選択すべきではありません。RPO=0 のマルチコピー アーキテクチャを選択することをお勧めします。
RPO=0 でのマルチコピー テクノロジーの進化に関する MySQL コミュニティ:
ポーラーDB-X集中型および分散型統合の概念: データ ノード DN は、スタンドアロン データベース フォームと完全に互換性のある集中型 (標準バージョン) フォームとして独立して使用できます。ビジネスが分散拡張が必要になるまで成長すると、アーキテクチャは適切な分散形式にアップグレードされ、分散コンポーネントは元のデータ ノードにシームレスに接続されます。アプリケーション側でのデータの移行や変更は必要ありません。この式、アーキテクチャの説明によってもたらされる使いやすさと拡張性を楽しむことができます。「集中分散統合」
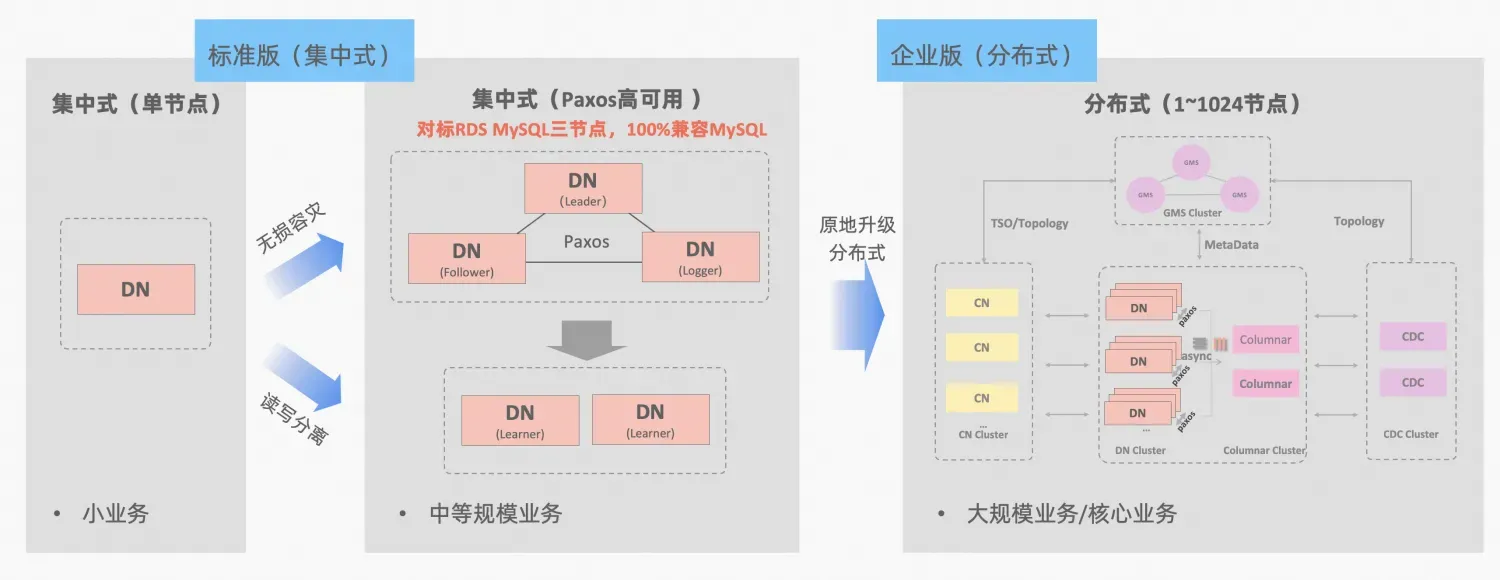
MySQL の MGR と PolarDB-X の標準バージョン DN はどちらも最下層の原理から Paxos プロトコルを使用しています。では、実際の使用における具体的なパフォーマンスと違いは何でしょうか。この記事では、アーキテクチャの比較、主な違い、テストの比較について詳しく説明します。
MGR/DN 略語の説明: MGR は MySQL MGR の技術形式を表し、DN は PolarDB-X 単一 DN 集中型 (標準バージョン) の技術形式を表します。
詳細な比較分析は比較的長いため、興味があれば最初に概要と結論を読んで、その後の記事でヒントを探すことができます。
MySQL MGR を使いこなすには専門的な技術知識と運用保守チームが必要なため、一般の企業や企業には推奨されません。この記事では、業界で長年出回っている MySQL MGR の 3 つの「隠れた落とし穴」も再現しています。 :
MySQL MGR と比較すると、PolarDB-X Paxos には、データの一貫性、コンピュータ ルーム間の災害復旧、ノードの運用とメンテナンスの点で MGR のような落とし穴はありませんが、災害復旧においてはいくつかの小さな欠点と利点もあります。
MGR/DN 略語の説明:
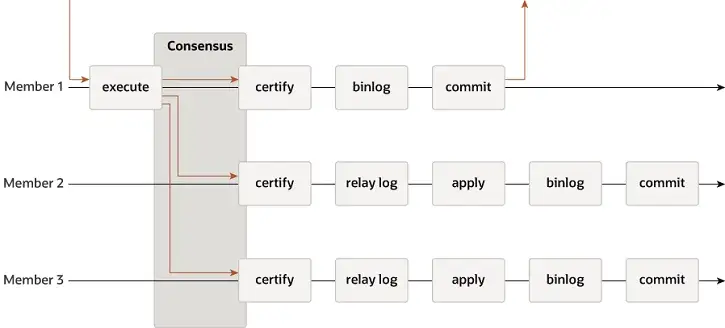
MGR はシングルマスター モードとマルチマスター モードをサポートし、イベント、Binlog & Relaylog、Apply、Binlog apply Recovery、GTID などの MySQL のレプリケーション システムを完全に再利用します。 DN との主な違いは、MGR トランザクション ログの多数派がコンセンサスに達するためのエントリ ポイントが、メインのデータベース トランザクションがコミットされる前であることです。
MGR が上記のプロセスを採用する理由は、MGR がデフォルトでマルチマスター モードになっており、各ノードが書き込みできるため、単一の Paxos グループ内のフォロワー ノードは、まず受信したログを RelayLog に変換してから結合する必要があるためです。送信するリーダーとして受信した書き込みトランザクションを使用して、2 段階のグループ送信プロセスで最後のトランザクションを送信するために Binlog ファイルが作成されます。
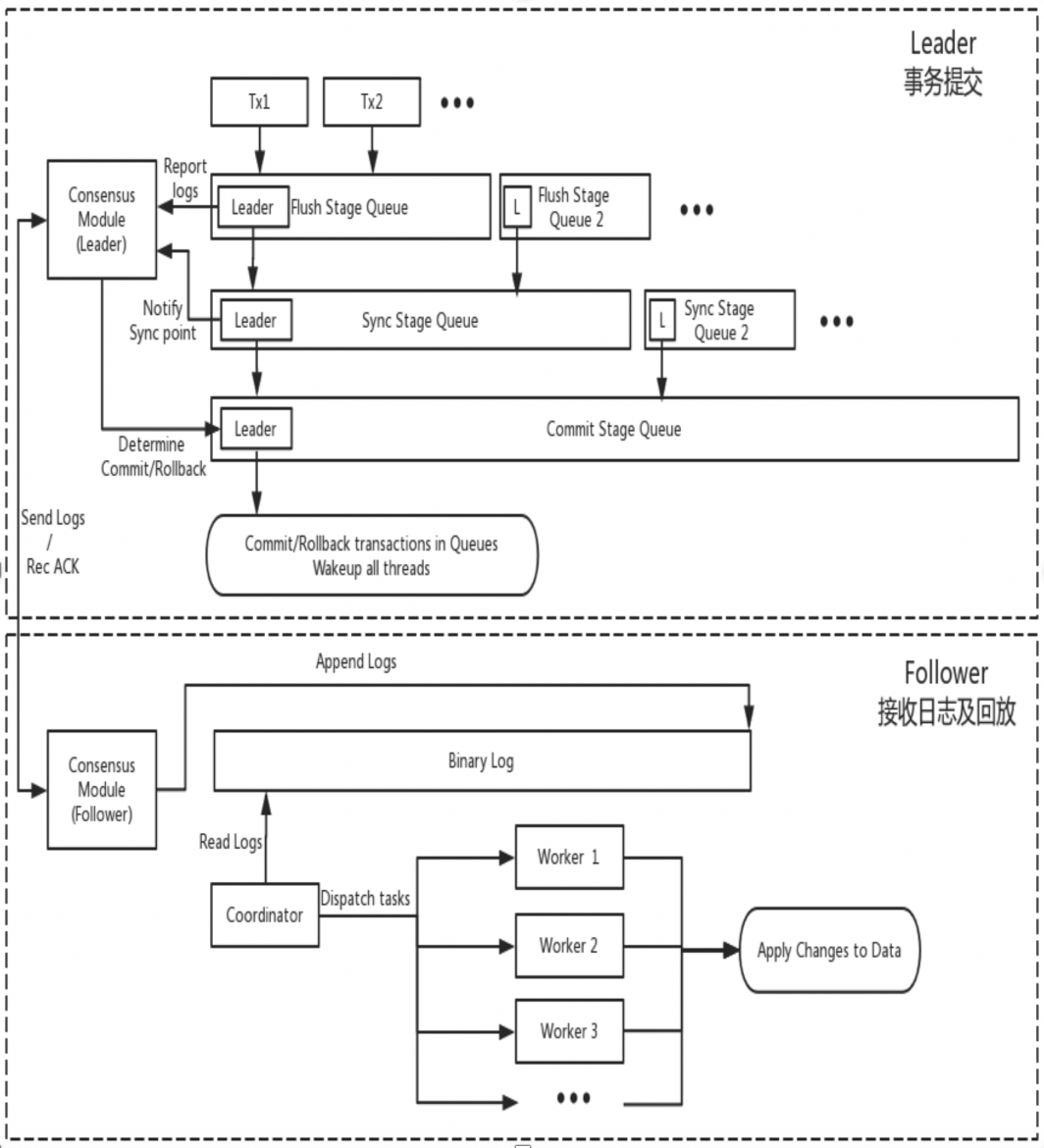
DN は MySQL の基本的なデータ構造と関数レベルのコードを再利用しますが、ログ レプリケーション、ログ管理、ログ再生、およびクラッシュ リカバリを X-Paxos プロトコルと密接に統合して、独自の多数派レプリケーションとステータス マシン メカニズムのセットを形成します。 MGR との主な違いは、DN トランザクション ログの多数派がコンセンサスに達するためのエントリ ポイントが、メインのデータベース トランザクション送信プロセス中にあることです。
この設計の理由は、DN が現在シングルマスター モードのみをサポートしているため、X-Paxos プロトコル レベルのログは Binlog 自体であり、フォロワーもリレー ログとその永続ログとリーダーのログのデータ コンテンツを省略しているためです。は同じ価格に等しい。

MGR

DN
理論的には、Paxos と Raft はどちらもデータの一貫性を確保でき、クラッシュ リカバリ後に大部分に達したログは失われませんが、特定のプロジェクトでは依然として違いがあります。
MGR
XCOM は Paxos プロトコルを完全にカプセル化し、そのすべてのプロトコル データはデフォルトで最初にメモリにキャッシュされます。トランザクション マジョリティはログの永続性を必要としません。 パイのほとんどがダウンし、リーダーが失敗した場合、RPO != 0 という深刻な問題が発生します。極端なシナリオを想定します。
コミュニティのデフォルト パラメータでは、トランザクションの大部分はログの永続性を必要とせず、RPO=0 を保証しません。これは、XCOM プロジェクトの実装におけるパフォーマンスとのトレードオフであると考えられます。絶対 RPO=0 を保証するには、読み取りおよび書き込みの一貫性を制御するパラメータ group_replication_consistency を AFTER まで設定する必要があります。ただし、この場合、トランザクションは 1.5 RTT ネットワーク オーバーヘッドに加えて、過半数に達するためにログ IO オーバーヘッドを必要とします。パフォーマンスは非常に悪くなります。
DN
PolarDB-X DN は、X-Paxos を使用して分散プロトコルを実装し、MySQL のグループ コミット プロセスに深く結合しています。トランザクションが送信されると、実際の送信が許可される前に大部分が配置と永続性を確認する必要があります。ここでのディスク配置のほとんどは、メイン ライブラリの Binlog 配置を指します。スタンバイ ライブラリの IO スレッドは、メイン ライブラリのログを受信し、それを永続化するために独自の Binlog に書き込みます。したがって、極端なシナリオですべてのノードに障害が発生した場合でも、データは失われず、RPO=0 が保証されます。
RTO 時間は、システム自体のコールド リスタートの時間オーバーヘッドと密接に関係しており、これは特定の基本機能に反映されます。障害検出メカニズム -> クラッシュ回復メカニズム -> マスター選択メカニズム -> ログ バランシング
MGR
DN
MGR
DN
シングルマスター モードでは、MGR の XCOM と強力なリーダー モードである DN X-Paxos は、リーダーの選択に関して同じ基本原則に従います。つまり、クラスターによって合意されたログはロールバックできません。 しかし、合意されていないログに関しては違いがあります
MGR
DN
ログの等化とは、プライマリ データベースとセカンダリ データベース間のログにログ レプリケーションの遅延があり、セカンダリ データベースでログを等化する必要があることを意味します。再起動および復元されるノードの場合、通常、スタンバイ データベースからリカバリが開始されますが、メイン データベースと比較してログ レプリケーションの遅延がすでに発生しているため、ログをメイン データベースに追いつく必要があります。リーダーから物理的に遠く離れたノードの場合、通常、過半数に到達することは関係ありません。常にレプリケーション ログの遅延があり、常にログに追いついています。このような状況では、ログ レプリケーションの遅延をタイムリーに解決するには、特別なエンジニアリングの実装が必要です。
MGR
DN
スタンバイ・データベースの再生遅延は、同じトランザクションがメイン・データベースで完了した時点と、トランザクションがスタンバイ・データベースに適用された時点との間の遅延です。ここでテストされるのは、スタンバイ・データベースの適用アプリケーション・ログのパフォーマンスです。これは、例外が発生したときにスタンバイ データベースがデータ アプリケーションを完了し、読み取りおよび書き込みサービスを提供するまでにかかる時間に影響します。
MGR
DN
大規模なトランザクションは、通常のトランザクションの送信に影響を与えるだけでなく、分散システム内の分散プロトコル全体の安定性に影響を与えます。深刻な場合、大規模なトランザクションにより、クラスター全体が長時間使用できなくなります。
MGR
DN
MGR
DN

| MGR | DN | ||
| プロトコルの効率 | トランザクションの送信時間 | 1.5〜2.5RTT | 1RTT |
| 大多数の永続性 | XCOMメモリの保存 | バイナリログの永続性 | |
| 信頼性 | 目標到達度=0 | デフォルトでは保証されません | 完全保証 |
| 故障検出 | すべてのノードが相互にチェックしており、ネットワーク負荷が高い 心拍周期が調整できない | マスターノードは定期的に他のノードをチェックします 心拍周期パラメータは調整可能 | |
| 大多数崩壊の回復 | 手動介入 | 自動回復 | |
| マイノリティクラッシュからの回復 | ほとんどの場合は自動回復、特殊な状況では手動介入 | 自動回復 | |
| マスターを選択してください | 選択順序を自由に指定 | 選択順序を自由に指定 | |
| 丸太ネクタイ | 遅延ログは XCOM 1GB キャッシュを超えることはできません | BInlog ファイルは削除されません | |
| スタンバイデータベースの再生遅延 | 2 段階 + 2 段階、非常に遅い | 1 ステージ + ダブルゼロ、より高速 | |
| 大企業 | デフォルトの制限は 143MB 以下です | サイズ制限なし | |
| 形状 | 高可用性のコスト | 完全に機能する 3 つのコピー、データ ストレージのオーバーヘッドの 3 つのコピー | ロガーログのコピー、データストレージのコピー 2 つ |
| 読み取り専用ノード | マスター/スレーブ レプリケーションで実装 | このプロトコルには、より効率的な読み取り専用コピーの実装が付属しています。 |
MGR は MySQL 5.7.17 で導入されましたが、その他の MGR 関連機能は MySQL 8.0 でのみ利用可能であり、MySQL 8.0.22 以降のバージョンでは全体的なパフォーマンスがより安定し、信頼性が高くなります。したがって、比較テストには、両者の最新バージョン 8.0.32 を選択しました。
PolarDB-X DN と MySQL MGR の比較テストでは、テスト環境、コンパイル方法、展開方法、操作パラメータ、およびテスト方法に違いがあり、それが不正確なテスト比較データにつながる可能性があることを考慮して、この記事ではさまざまな詳細に焦点を当てます。次のように進めます。
| 試験の準備 | PolarDB-X DN | MySQLマネージャー[1] |
| ハードウェア環境 | 96C 754GB メモリと SSD ディスクを搭載した同じ物理マシンを使用する | |
| オペレーティング·システム | Linux 4.9.168-019.ali3000.alios7.x86_64 | |
| カーネルのバージョン | コミュニティ バージョン 8.0.32 に基づくカーネル ベースラインの使用 | |
| コンパイル方法 | 同じ RelWithDebInfo でコンパイルする | |
| 動作パラメータ | 同じPolarDB-X公式Webサイトを使用して、同じ仕様とパラメータの32C128Gを販売します | |
| 導入方法 | シングルマスターモード | |
注記:
データベースを選択するときに誰もが最初に注目するのはパフォーマンス テストです。ここでは、公式の sysbench ツールを使用して、それぞれ 1,000 万のデータを含む 16 のテーブルを構築し、OLTP シナリオでパフォーマンス テストを実行し、異なる OLTP シナリオの異なる同時実行条件下で 2 つのパフォーマンスをテストして比較します。実際の展開のさまざまな状況を考慮して、次の 4 つの展開シナリオをそれぞれシミュレートします。
例証します:
a. 4 つの展開シナリオのパフォーマンスを水平に比較してみます。2 か所の 3 センターと 3 か所の 3 つのセンターはすべて 3 コピーの展開モードを採用しており、実際の運用ビジネスは 5 コピーの展開モードに拡張できます。
b. 高可用性データベース製品を使用する場合の RPO=0 に対する厳しい制限を考慮して、MGR はデフォルトで RPO<>0 で構成されます。ここでは、それぞれの MGR RPO<>0 と RPO=0 の間の比較テストを追加していきます。導入シナリオ。
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_読み取り専用 | MGR_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| 翻訳元 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| DN | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 対 MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN vs MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN vs MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_read_write | MGR_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| 翻訳元 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| DN | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 対 MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN vs MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN vs MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_書き込みのみ | MGR_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| 翻訳元 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| DN | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 対 MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN vs MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN vs MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
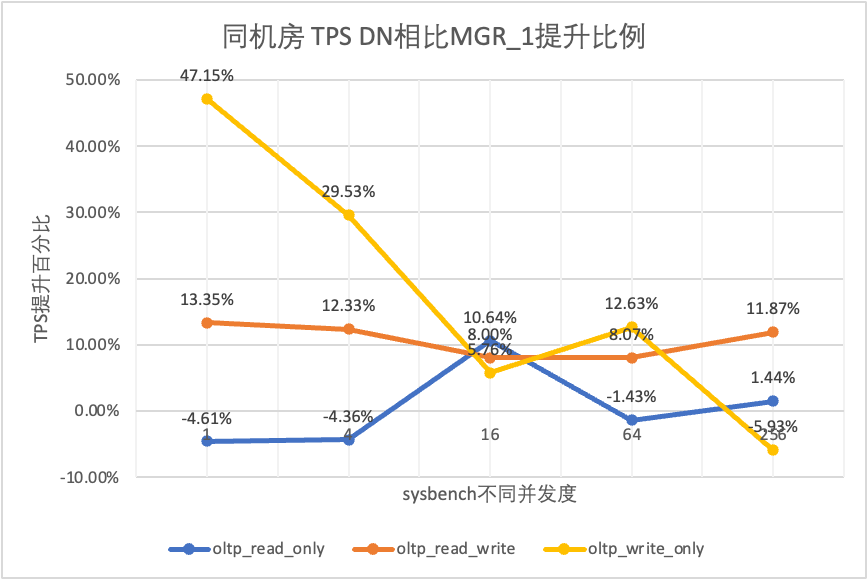
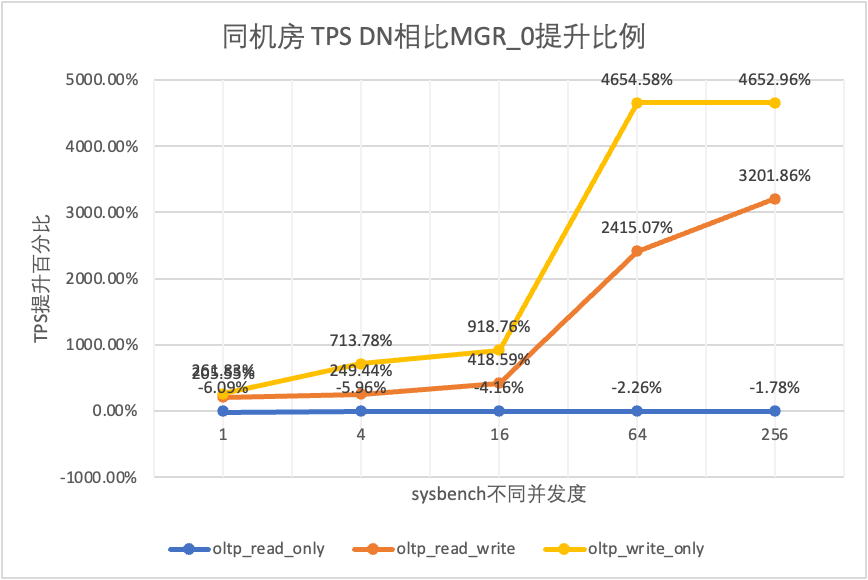
それはテスト結果からわかります。
| TPSの比較 | 1 | 4 | 16 | 64 | 256 | |
| oltp_読み取り専用 | MGR_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| 翻訳元 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| DN | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 対 MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN vs MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN vs MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_read_write | MGR_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| 翻訳元 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| DN | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 対 MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN vs MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN vs MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_書き込みのみ | MGR_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| 翻訳元 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| DN | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 対 MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN vs MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN vs MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


それはテスト結果からわかります。
| TPSの比較 | 1 | 4 | 16 | 64 | 256 | |
| oltp_読み取り専用 | MGR_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| 翻訳元 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| DN | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 対 MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN vs MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN vs MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_read_write | MGR_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| 翻訳元 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| DN | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 対 MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN vs MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN vs MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_書き込みのみ | MGR_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| 翻訳元 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| DN | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 対 MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN vs MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN vs MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
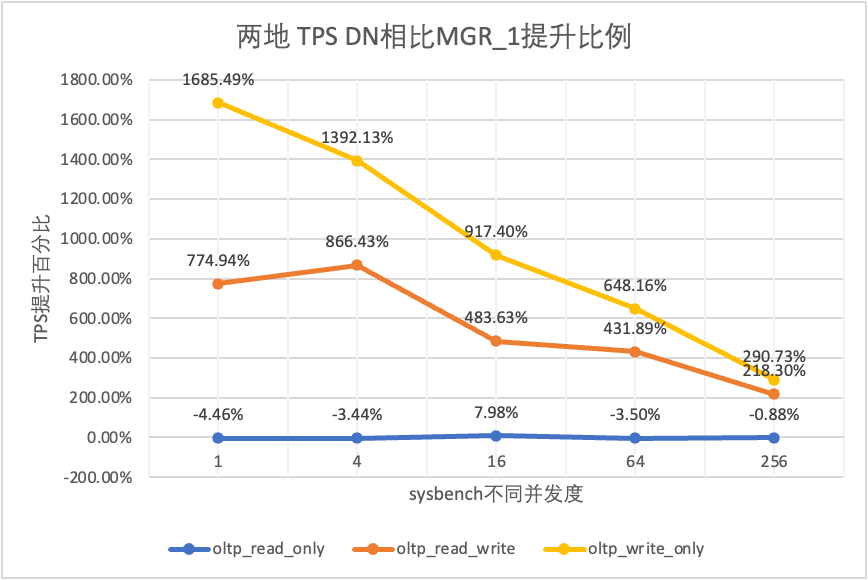
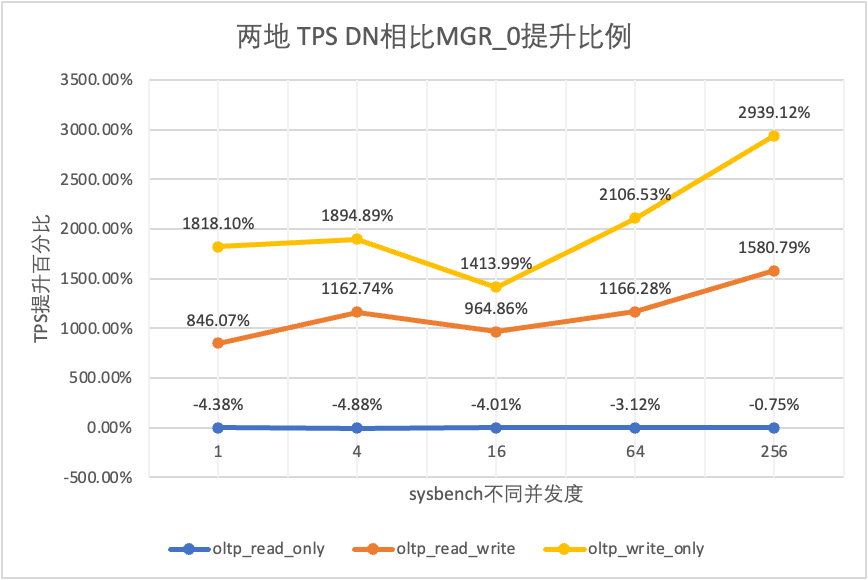
それはテスト結果からわかります。
| TPSの比較 | 1 | 4 | 16 | 64 | 256 | |
| oltp_読み取り専用 | MGR_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| 翻訳元 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| DN | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 対 MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN vs MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN vs MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_read_write | MGR_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| 翻訳元 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| DN | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 対 MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN vs MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN vs MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_書き込みのみ | MGR_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| 翻訳元 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| DN | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 対 MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN vs MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN vs MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
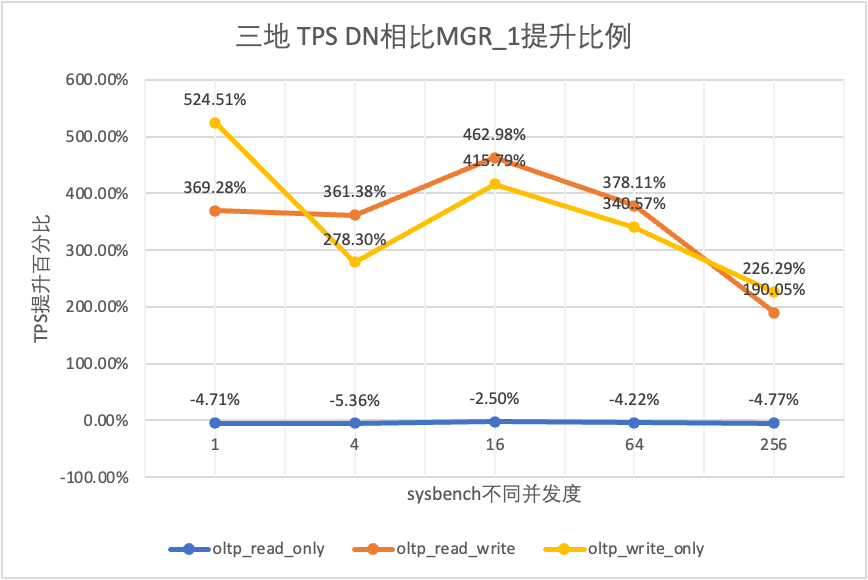
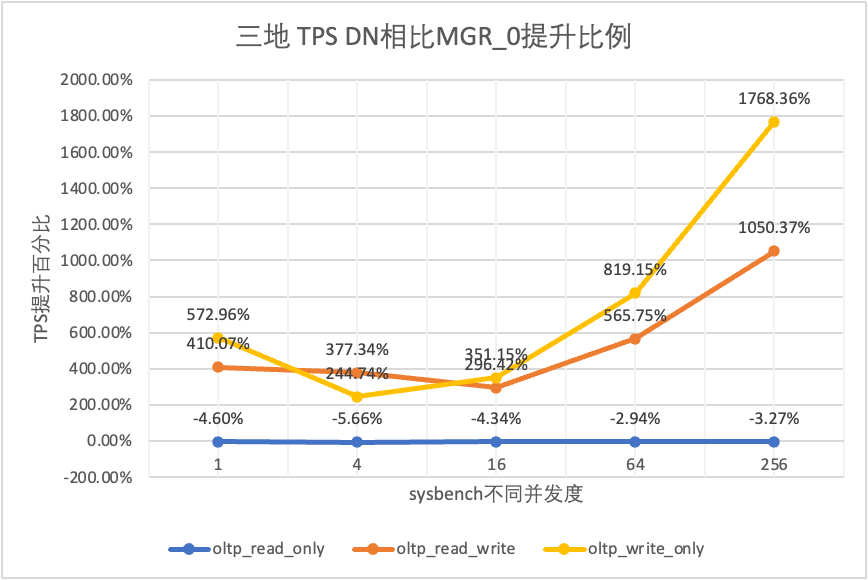
それはテスト結果からわかります。
さまざまな導入方法でのパフォーマンスの変化を明確に比較するために、上記のテストでは、oltp_write_only シナリオ 256 同時実行でのさまざまな導入方法での MGR と DN の TPS データを選択し、ベースラインとしてコンピューター ルームのテスト データを使用して計算しました。異なる導入方法の TPS データをベースラインと比較して、都市間導入時のパフォーマンス変化の違いを認識します。
| MGR_1 (同時 256) | DN (同時256) | MGRと比較したDNのパフォーマンス上の利点 | |
| 同じコンピューター室 | 16092.02 | 15137.23 | -5.93% |
| 同じ市内に 3 つのセンター | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| 2 つの場所と 3 つのセンター | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| 3 つの場所と 3 つのセンター | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
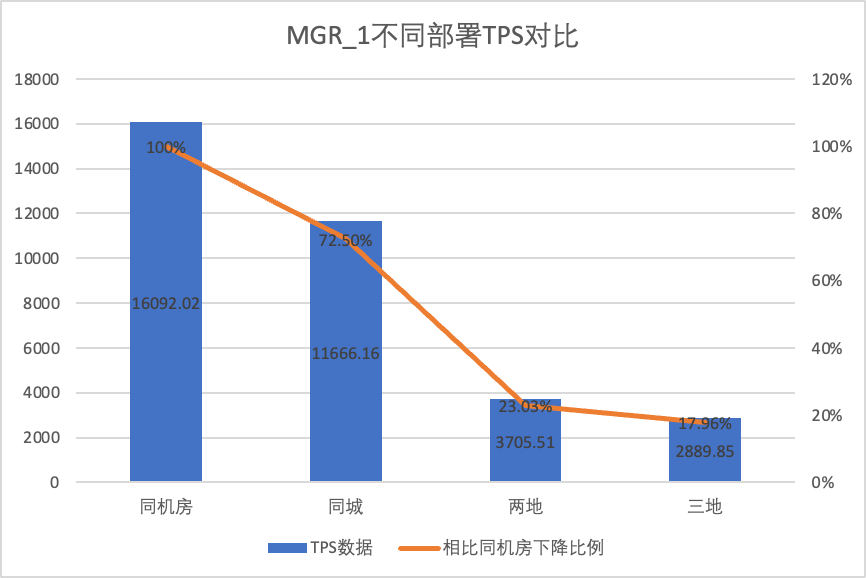
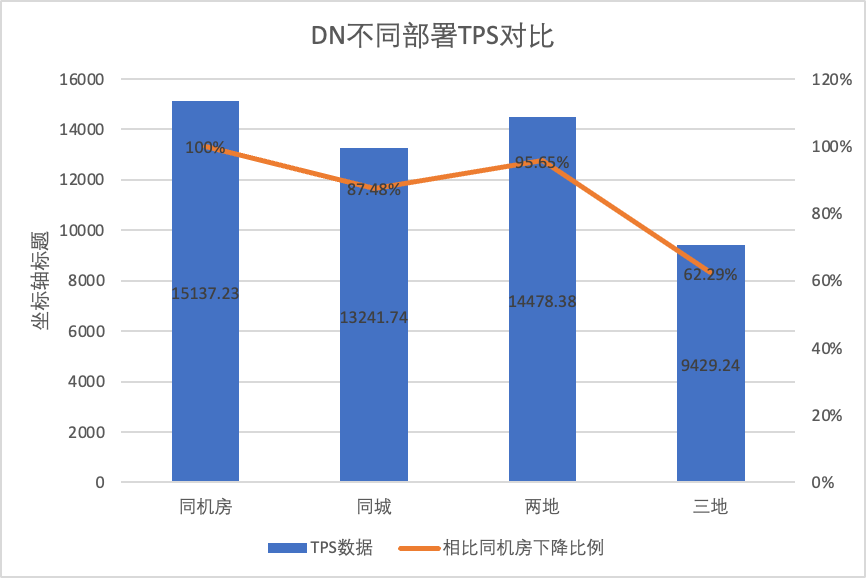
それはテスト結果からわかります。
実際の使用では、パフォーマンスデータに注意を払うだけでなく、パフォーマンスジッターにも注意する必要があります。結局のところ、ジッターがジェット コースターのような場合、実際のユーザー エクスペリエンスは非常に悪くなります。 TPS リアルタイム出力データを監視および表示します。sysbenc ツール自体がパフォーマンス ジッターの出力監視データをサポートしていないことを考慮して、比較指標として数学的な変動係数を使用します。
256 の同時 oltp_read_write シナリオを例として、同じコンピュータ ルーム、同じ都市の 3 つのセンター、2 か所の 3 つのセンターにある MGR_1 (RPO<>0) と DN (RPO=0) の TPS を統計的に分析します。 3 つのセンターに 3 つのジッター状況。 実際のジッター グラフは次のとおりです。各シナリオの実際のジッター インジケーター データは次のとおりです。
| 履歴書 | 同じコンピューター室 | 同じ市内に 3 つのセンター | 2 つの場所と 3 つのセンター | 3 つの場所と 3 つのセンター |
| MGR_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| DN | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
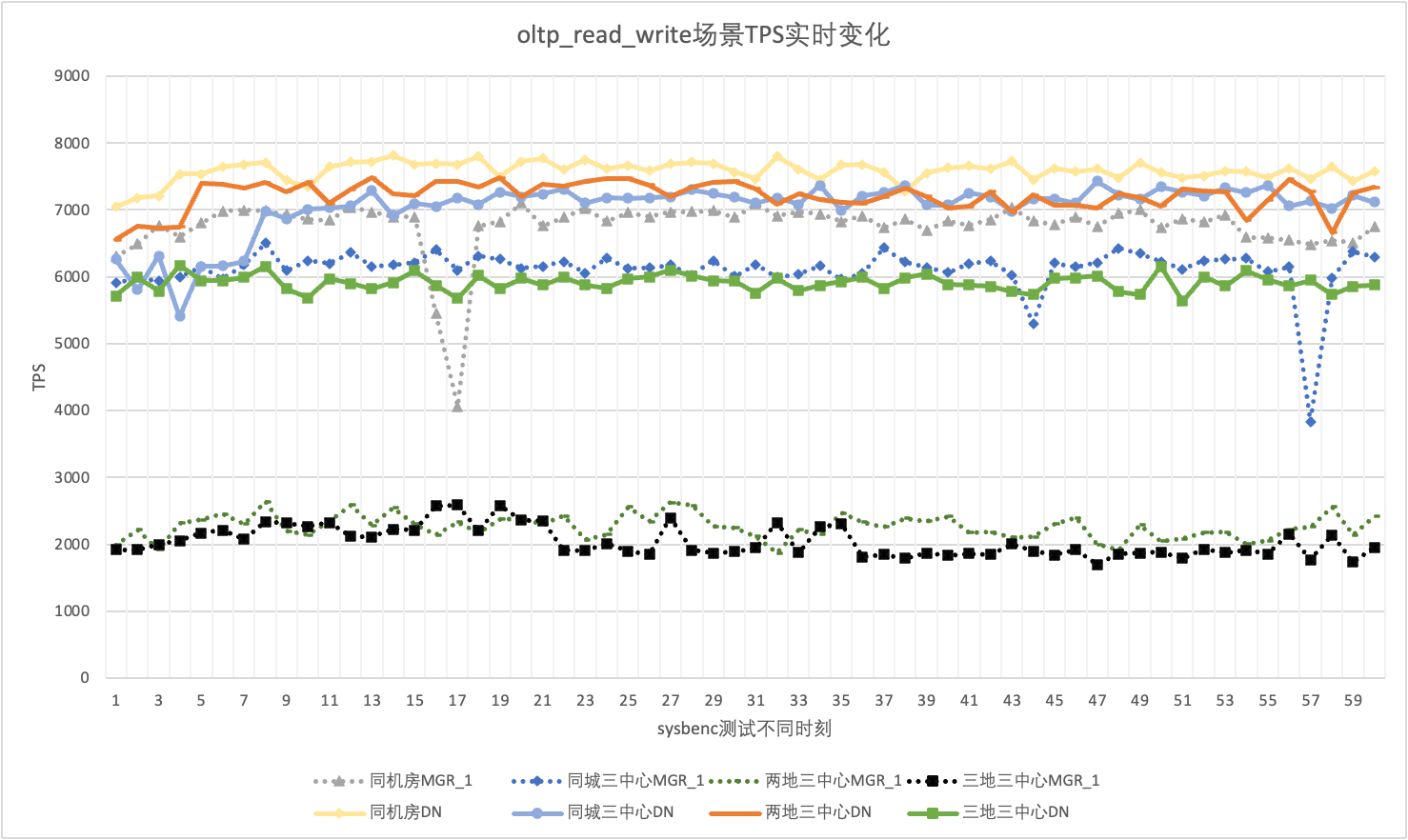
それはテスト結果からわかります。
分散データベースの中核となる機能は、高可用性です。クラスター内のどのノードに障害が発生しても、全体の可用性には影響しません。同じコンピュータ ルームに 1 つのマスターと 2 つのバックアップを備えた 3 ノードの典型的な導入形態について、次の 3 つのシナリオでユーザビリティ テストを実施しようとしました。
負荷がない場合は、リーダーを強制終了し、クラスター内の各ノードのステータスの変化と書き込み可能かどうかを監視します。
| MGR | DN | |
| 正常に起動します | 0 | 0 |
| リーダーを殺す | 0 | 0 |
| 異常なノード時間が見つかりました | 5 | 5 |
| 3 ノードを 2 ノードに減らすのにかかる時間 | 23 | 8 |
| MGR | DN | |
| 正常に起動します | 0 | 0 |
| リーダーをキルし、自動的に引き上げます | 0 | 0 |
| 異常なノード時間が見つかりました | 5 | 5 |
| 3 ノードを 2 ノードに減らすのにかかる時間 | 23 | 8 |
| 2 ノードの復元時間 3 ノードの時間 | 37 | 15 |

テスト結果から、無圧力条件下では次のことがわかります。
sysbench を使用して、oltp_read_write シナリオで 16 スレッドの同時ストレス テストを実行します。図の 10 秒目で、スタンバイ ノードを手動で強制終了し、sysbench のリアルタイム出力 TPS データを観察します。
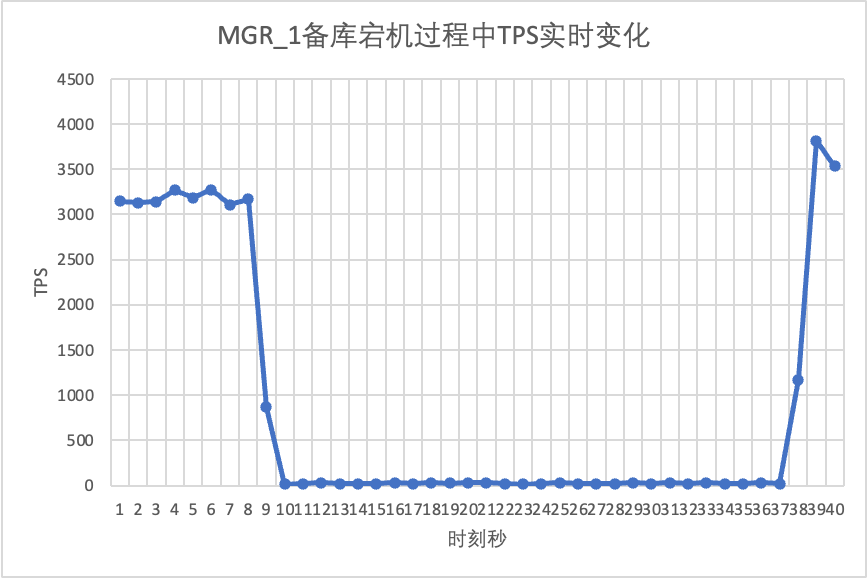


それはテスト結果のグラフからわかります。
テストを継続して、スタンバイ データベースを再起動して復元し、メイン データベースの TPS データの変化を観察します。
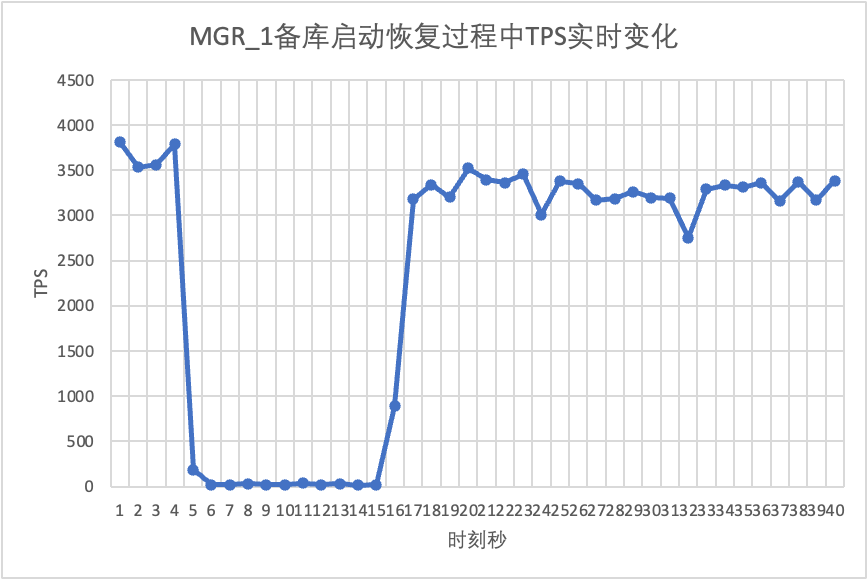
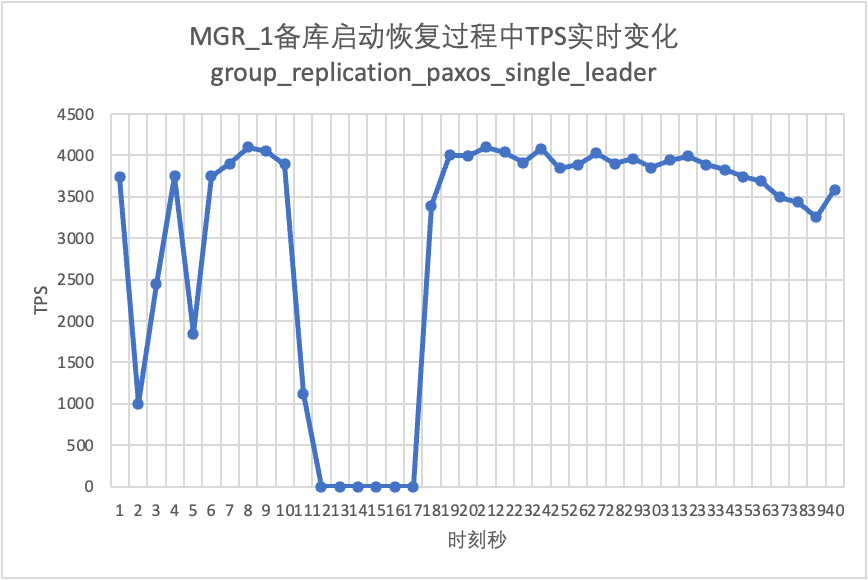
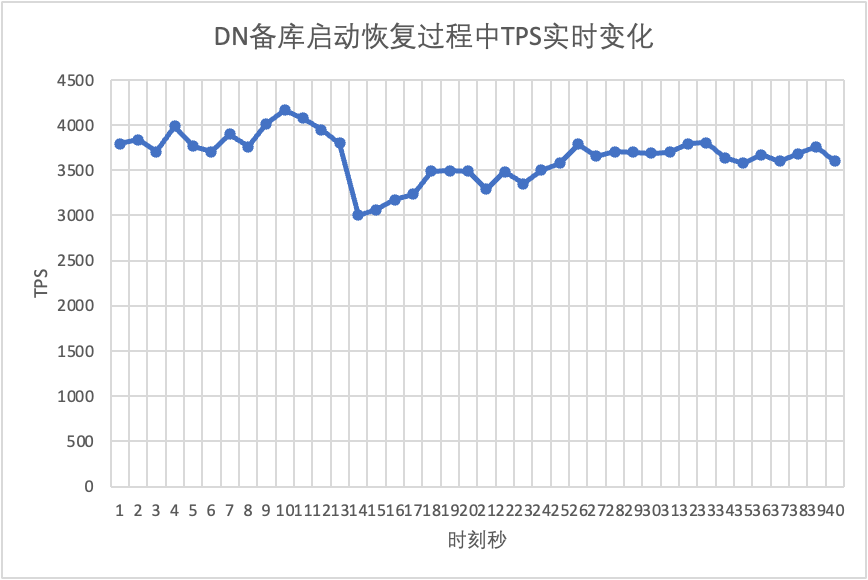
それはテスト結果のグラフからわかります。
MGR 過半数障害 RPO<>0 シナリオを構築するために、コミュニティ独自の MTR ケース メソッドを使用して、MGR で障害挿入テストを実行します。設計されたケースは次のとおりです。
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
ケースの実行結果は次のとおりです。
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
欠損番号を再現する場合のおおよそのロジックは次のとおりです。
上記のケースによると、MGR の場合、サーバーの大部分がダウンしてメイン データベースが使用できなくなり、スタンバイ データベースが復元された後、RPO<>0 のデータ損失が発生し、成功したコミットのレコードは次のようになります。元々クライアントに返却されたものは紛失しています。
DN の場合、マジョリティを達成するにはマジョリティでログが保持される必要があるため、上記のシナリオでもデータは失われず、RPO=0 が保証されます。
MySQL の従来のアクティブ/スタンバイ モードでは、通常、スタンバイ データベースには IO スレッドと適用スレッドが含まれます。Paxos プロトコルの導入後、IO スレッドは主にスタンバイ データベースのレプリケーション遅延を同期します。スタンバイ データベースの再生の適用のオーバーヘッドに依存します。ここではスタンバイ データベースの再生遅延になります。
sysbench を使用して oltp_write_only シナリオをテストし、同時実行数 100 およびさまざまなイベント数でのスタンバイ データベース再生の遅延時間をテストします。スタンバイ データベースの再生遅延時間は、performance_schema.replication_applier_status_by_worker テーブルの APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP 列を監視して各ワーカーがリアルタイムで動作しているかどうかを確認し、レプリケーションが終了したかどうかを判断することで判断できます。

それはテスト結果のグラフからわかります。
| MGR | DN | ||
| パフォーマンス | トランザクションの読み取り | フラット | フラット |
| 書き込みトランザクション | RPO<>0 の場合、パフォーマンスは DN ほど良くありません。 RPO=0 の場合、パフォーマンスは DN に比べて大幅に劣ります。 都市間展開のパフォーマンスが 27% ~ 82% 大幅に低下 | 書き込みトランザクションのパフォーマンスはMGRよりもはるかに高い 都市間展開のパフォーマンスは 4% から 37% 低下します。 | |
| ジッター | パフォーマンスのジッターが激しく、ジッター範囲は 6 ~ 10% | 3% で比較的安定しており、MGR の半分にすぎません | |
| 料金 | メインデータベースがダウンしています | 異常は 5 秒で発見され、23 秒でノード 2 つに減りました。 | 異常は 5 秒で発見され、8 秒でノード 2 つに減りました。 |
| メインライブラリを再起動します | 5秒で異常を発見し、37秒で3ノードを復旧した。 | 5秒で異常を検知し、15秒で3ノードを復旧します。 | |
| バックアップデータベースのダウンタイム | メイン データベースのトラフィックは 20 秒間 0 になりました。 これは、group_replication_paxos_single_leader を明示的にオンにすることで軽減できます。 | メインデータベースの継続的な高可用性 | |
| スタンバイデータベースの再起動 | メイン データベースのトラフィックは 10 秒間 0 になりました。 group_replication_paxos_single_leader を明示的にオンにしても効果はありません。 | メインデータベースの継続的な高可用性 | |
| RPO | 症例再発 | 多数党が倒れるとRPO<>0 パフォーマンスと RPO=0 を両方持つことはできません。 | 目標達成率 = 0 |
| スタンバイデータベースの遅延 | バックアップデータベースの再生時間 | アクティブとスタンバイの間の遅延は非常に大きくなります。 パフォーマンスとプライマリ バックアップの遅延を同時に達成することはできません。 | スタンバイ データベース全体の再生に費やされる合計時間は MGR の 4% で、これは MGR の 25 倍です。 |
| パラメータ | キーパラメータ |
| デフォルト構成。専門家が構成をカスタマイズする必要はありません。 |
綿密な技術分析とパフォーマンス比較を経て、ポーラーDB-X DN は、自社開発の X-Paxos プロトコルと一連の最適化された設計により、パフォーマンス、正確性、可用性、リソース オーバーヘッドの点で MySQL MGR に比べて多くの利点を示しています。ただし、MGR は MySQL エコシステムでも重要な位置を占めています。 、スタンバイ データベースの停止のジッター、マシン ルーム間の災害復旧パフォーマンスの変動、安定性などのさまざまな状況を考慮する必要があるため、MGR を有効に活用したい場合は、専門の技術チームと運用保守チームを備えている必要があります。サポート。
大規模、高同時実行性、高可用性の要件に直面した場合、PolarDB-X ストレージ エンジンは、すぐに使用できるシナリオで MGR と比較して、独自の技術的利点と優れたパフォーマンスを備えています。ポーラーDB-XDN ベースの集中型 (標準バージョン) は、機能とパフォーマンスのバランスが良く、競争力の高いデータベース ソリューションです。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: