
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Как мы все знаем, первичная и вторичная базы данных MySQL (два узла) обычно обеспечивают высокую доступность данных за счет асинхронной и полусинхронной репликации (полусинхронная репликация). Однако в аномальных сценариях, таких как сбои сети компьютерного зала и зависания хоста, Первичная и вторичная архитектуры столкнутся с серьезными проблемами после переключения высокой доступности. Существует вероятность несогласованности данных (называемая RPO!=0).Поэтому, если бизнес-данные имеют определенную важность, не следует выбирать базу данных с первичной и вторичной архитектурой MySQL (два узла). Рекомендуется выбирать архитектуру с несколькими копиями с RPO=0.
Сообщество MySQL об эволюции технологии множественного копирования с RPO=0:
PolarDB-X Концепция централизованной и распределенной интеграции: DN узла данных может использоваться независимо как централизованная (стандартная версия) форма, которая полностью совместима с автономной формой базы данных. Когда бизнес достигает точки, когда требуется распределенное расширение, архитектура обновляется до распределенной формы, и распределенные компоненты легко подключаются к исходным узлам данных. Нет необходимости в миграции или модификации данных на стороне приложения. , и вы сможете наслаждаться удобством использования и масштабируемостью, обеспечиваемыми этой формулой, описанием архитектуры:«Централизованная распределенная интеграция»
MySQL MGR и стандартная версия DN PolarDB-X используют протокол Paxos по низшему принципу. Так каковы конкретные характеристики и различия в реальном использовании? В этой статье подробно рассматриваются аспекты сравнения архитектур, ключевые различия и сравнение тестов.
Описание аббревиатуры MGR/DN: MGR представляет собой техническую форму MySQL MGR, а DN представляет собой техническую форму централизованного единого DN PolarDB-X (стандартная версия).
Подробный сравнительный анализ относительно длинный, поэтому вы можете сначала прочитать краткое содержание и заключение. Если вам интересно, вы можете следить за кратким изложением и искать подсказки в последующих статьях.
MySQL MGR не рекомендуется для обычных предприятий и компаний, поскольку для его правильного использования требуются профессиональные технические знания, а также команда по эксплуатации и обслуживанию. В этой статье также воспроизводятся три «скрытые ловушки» MySQL MGR, которые уже давно циркулируют в отрасли. :
По сравнению с MySQL MGR, PolarDB-X Paxos не имеет недостатков, подобных MGR, с точки зрения согласованности данных, аварийного восстановления между компьютерами, а также работы и обслуживания узлов. Однако у него также есть некоторые незначительные недостатки и преимущества в аварийном восстановлении:
Описание аббревиатуры MGR/DN:
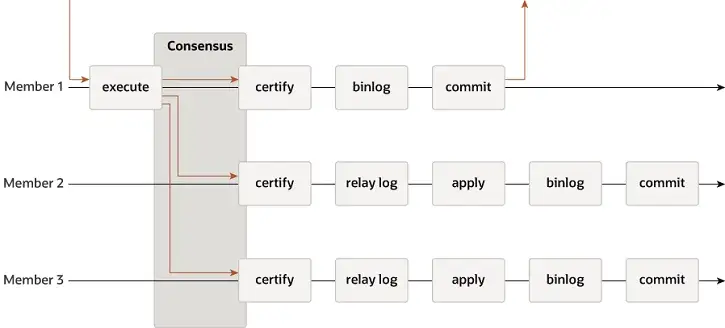
MGR поддерживает режимы с одним главным и несколькими главными устройствами и полностью повторно использует систему репликации MySQL, включая Event, Binlog & Relaylog, Apply, Binlog Apply Recovery и GTID. Ключевое отличие от DN заключается в том, что точка входа для большинства журналов транзакций MGR для достижения консенсуса находится до фиксации основной транзакции базы данных.
Причина, по которой MGR использует описанный выше процесс, заключается в том, что MGR по умолчанию находится в режиме с несколькими главными устройствами, и каждый узел может писать. Поэтому ведомому узлу в одной группе Paxos необходимо сначала преобразовать полученный журнал в RelayLog, а затем объединить его. с транзакцией записи, которую он получает в качестве лидера для отправки, создается файл Binlog для отправки последней транзакции в двухэтапном групповом процессе отправки.
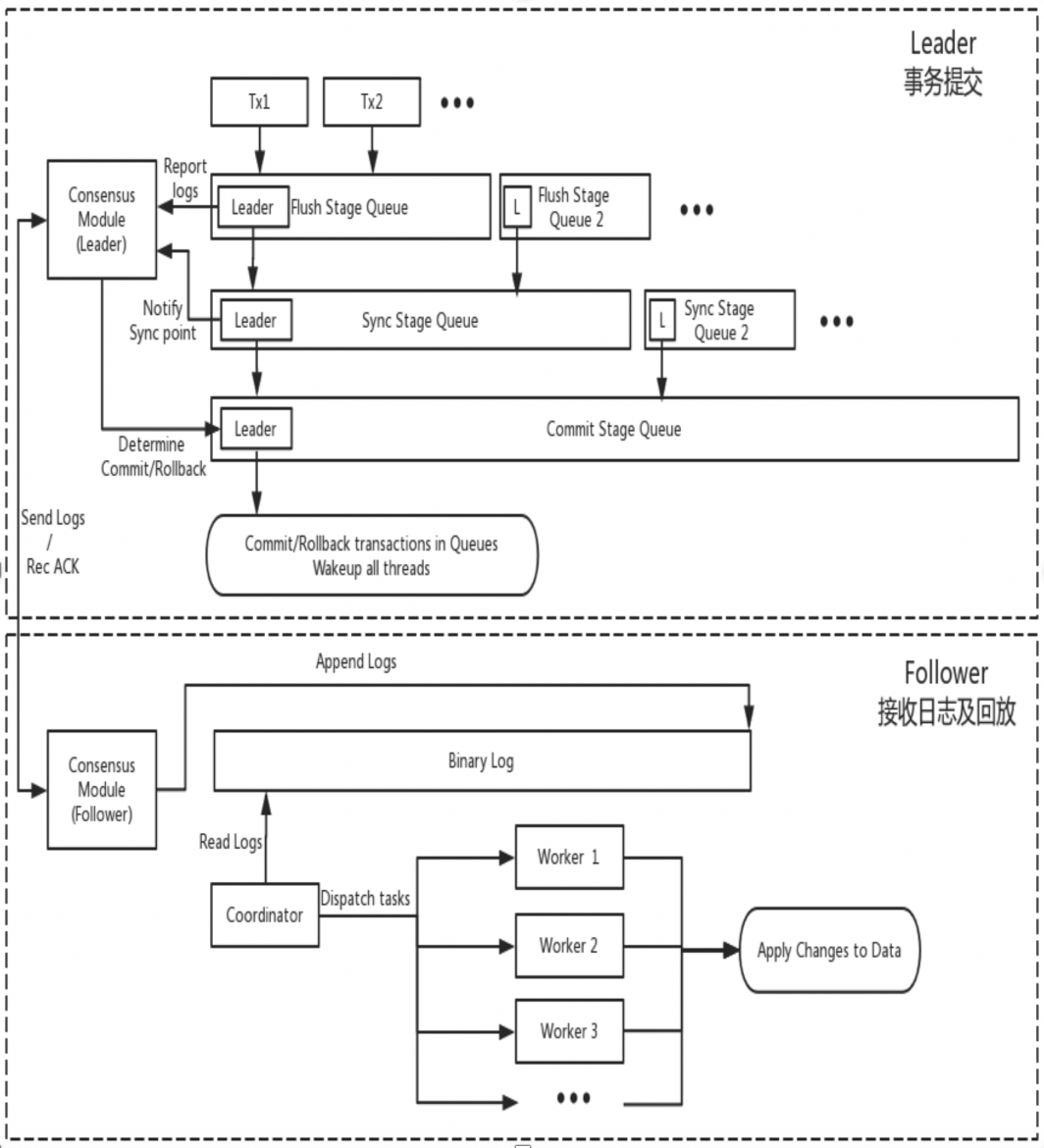
DN повторно использует базовую структуру данных MySQL и код функционального уровня, но тесно интегрирует репликацию журналов, управление журналами, воспроизведение журналов и восстановление после сбоев с протоколом X-Paxos, чтобы сформировать собственный набор механизмов репликации большинства и машины состояния. Ключевое отличие от MGR заключается в том, что точка входа для большинства журналов транзакций DN для достижения консенсуса находится во время процесса отправки транзакции основной базы данных.
Причина такой конструкции заключается в том, что DN в настоящее время поддерживает только режим с одним главным устройством, поэтому журнал на уровне протокола X-Paxos представляет собой сам Binlog, а также опускает журнал ретрансляции и содержимое его постоянного журнала и журнала ведущего. равны той же цене.

МГР

ДН
Теоретически и Paxos, и Raft могут обеспечить согласованность данных и логи, достигшие большинства после Crash Recovery, не будут потеряны, но различия в конкретных проектах все же есть.
МГР
XCOM полностью инкапсулирует протокол Paxos, и все данные протокола сначала кэшируются в памяти. По умолчанию для большинства транзакций не требуется сохранение журнала. В случае, когда большая часть пирогов не работает и Лидер терпит неудачу, возникает серьезная проблема с RPO != 0.Предположим крайний сценарий:
Согласно параметрам сообщества по умолчанию, большинство транзакций не требуют сохранения журнала и не гарантируют RPO=0. Это можно считать компромиссом для производительности при реализации проекта XCOM. Чтобы обеспечить абсолютное значение RPO=0, необходимо настроить параметр group_replication_consistency, который контролирует согласованность чтения и записи, на значение AFTER. Однако в этом случае, в дополнение к сетевым издержкам 1,5 RTT, для достижения большинства транзакция потребует служебных данных ввода-вывода журнала. и разница будет очень плохой.
ДН
PolarDB-X DN использует X-Paxos для реализации распределенного протокола и тесно связан с процессом групповой фиксации MySQL. Когда транзакция отправляется, большинство должно подтвердить размещение и постоянство, прежде чем фактическая отправка будет разрешена. Большая часть размещения на диске здесь относится к размещению Binlog основной библиотеки. Поток ввода-вывода резервной библиотеки получает журнал основной библиотеки и записывает его в свой собственный Binlog для сохранения. Таким образом, даже если все узлы выйдут из строя в экстремальных сценариях, данные не будут потеряны и можно гарантировать RPO=0.
Время RTO тесно связано с затратами времени на холодный перезапуск самой системы, что отражается на конкретных базовых функциях:Механизм обнаружения ошибок->механизм восстановления после сбоя->механизм выбора мастера->балансировка журналов
МГР
ДН
МГР
ДН
В режиме с одним главным устройством XCOM и DN X-Paxos MGR, режим сильного лидера, следуют одному и тому же основному принципу выбора лидера — журналы, согласованные с кластером, не могут быть отменены. Но когда дело доходит до журнала несогласованности, есть различия.
МГР
ДН
Выравнивание журналов означает, что существует задержка репликации журналов между первичной и вторичной базами данных, и базе данных-получателю необходимо выровнять журналы. Для узлов, которые перезапускаются и восстанавливаются, восстановление обычно начинается с резервной базы данных, и уже произошла задержка репликации журналов по сравнению с основной базой данных, и логи нужно догонять с основной базой данных. Для тех нод, которые физически удалены от Лидера, достижение большинства обычно не имеет к ним никакого отношения. У них всегда задержка журнала репликации и он постоянно догоняет журнал. В таких ситуациях требуется специальная инженерная реализация, обеспечивающая своевременное устранение задержек репликации журналов.
МГР
ДН
Задержка воспроизведения резервной базы данных — это задержка между моментом завершения той же транзакции в основной базе данных и моментом применения транзакции в резервной базе данных. Здесь проверяется производительность журнала приложения Apply резервной базы данных. Это влияет на то, сколько времени потребуется резервной базе данных для завершения приложения данных и предоставления услуг чтения и записи при возникновении исключения.
МГР
ДН
Крупные транзакции не только влияют на отправку обычных транзакций, но также влияют на стабильность всего распределенного протокола в распределенной системе. В тяжелых случаях крупная транзакция приведет к тому, что весь кластер будет недоступен в течение длительного времени.
МГР
ДН
МГР
ДН

| МГР | ДН | ||
| Эффективность протокола | Время отправки транзакции | 1,5~2,5 РРТ | 1 РТТ |
| Настойчивость большинства | сохранение памяти XCOM | Постоянство бинлога | |
| надежность | РПО=0 | Не гарантируется по умолчанию | Полная гарантия |
| Обнаружение неисправностей | Все узлы проверяют друг друга, нагрузка на сеть высокая Цикл сердцебиения не может быть отрегулирован | Главный узел периодически проверяет другие узлы Параметры цикла сердцебиения регулируются. | |
| Восстановление после коллапса большинства | ручное вмешательство | Автоматическое восстановление | |
| Восстановление после сбоев меньшинства | Автоматическое восстановление в большинстве случаев, ручное вмешательство в особых обстоятельствах. | Автоматическое восстановление | |
| Выберите мастера | Свободно указывайте порядок отбора | Свободно указывайте порядок отбора | |
| Бревенчатый галстук | Отстающие журналы не могут превышать кэш XCOM 1 ГБ. | Файлы BInlog не удаляются | |
| Задержка воспроизведения резервной базы данных | Две ступени + двойная, очень медленно | Один этап + двойной ноль, быстрее | |
| Большой бизнес | Ограничение по умолчанию — не более 143 МБ. | Нет ограничений по размеру | |
| форма | Высокая стоимость доступности | Полнофункциональные три копии, 3 копии накладных расходов на хранение данных | Копия журнала регистратора, 2 копии хранилища данных |
| узел только для чтения | Реализовано с помощью репликации master-slave. | Протокол поставляется с реализацией копирования Leaner только для чтения. |
MGR был представлен в MySQL 5.7.17, но дополнительные функции, связанные с MGR, доступны только в MySQL 8.0, а в MySQL 8.0.22 и более поздних версиях общая производительность будет более стабильной и надежной. Поэтому для сравнительного тестирования мы выбрали последнюю версию 8.0.32 обеих сторон.
Учитывая, что во время сравнительного тестирования PolarDB-X DN и MySQL MGR существуют различия в тестовых средах, методах компиляции, методах развертывания, рабочих параметрах и методах тестирования, что может привести к получению неточных данных сравнения тестов, в этой статье основное внимание будет уделено различным деталям. .Действуйте следующим образом:
| подготовка к тесту | PolarDB-X DN | MySQL MGR[1] |
| Аппаратная среда | Использование той же физической машины с памятью 96C 754 ГБ и SSD-диском. | |
| Операционная система | Linux 4.9.168-019.ali3000.alios7.x86_64 | |
| Версия ядра | Использование базовой версии ядра на основе версии сообщества 8.0.32. | |
| Метод компиляции | Скомпилируйте с тем же RelWithDebInfo. | |
| Рабочие параметры | Используйте тот же официальный сайт PolarDB-X для продажи 32C128G с теми же характеристиками и параметрами. | |
| Метод развертывания | Одиночный мастер-режим | |
Примечание:
Тестирование производительности — первое, на что все обращают внимание при выборе базы данных. Здесь мы используем официальный инструмент sysbench для создания 16 таблиц, каждая из которых содержит 10 миллионов данных, для выполнения тестирования производительности в сценариях OLTP, а также тестируем и сравниваем производительность этих двух приложений в различных условиях параллелизма в разных сценариях OLTP.Учитывая различные ситуации фактического развертывания, мы моделируем следующие четыре сценария развертывания соответственно:
проиллюстрировать:
a. Рассмотрим горизонтальное сравнение производительности четырех сценариев развертывания. Три центра в двух местах и три центра в трех местах используют режим развертывания 3 копий. Реальный производственный бизнес можно расширить до режима развертывания 5 копий.
b Учитывая строгие ограничения на RPO=0 при использовании продуктов баз данных высокой доступности, MGR по умолчанию настроен с RPO<>0. Здесь мы продолжим добавлять сравнительные тесты между MGR RPO<>0 и RPO=0 в каждом из них. сценарий развертывания.
| 1 | 4 | 16 | 64 | 256 | ||
| oltp_read_only | МГР_1 | 688.42 | 2731.68 | 6920.54 | 11492.88 | 14561.71 |
| МГР_0 | 699.27 | 2778.06 | 7989.45 | 11590.28 | 15038.34 | |
| ДН | 656.69 | 2612.58 | 7657.03 | 11328.72 | 14771.12 | |
| MGR_0 против MGR_1 | 1.58% | 1.70% | 15.45% | 0.85% | 3.27% | |
| DN против MGR_1 | -4.61% | -4.36% | 10.64% | -1.43% | 1.44% | |
| DN против MGR_0 | -6.09% | -5.96% | -4.16% | -2.26% | -1.78% | |
| oltp_read_write | МГР_1 | 317.85 | 1322.89 | 3464.07 | 5052.58 | 6736.55 |
| МГР_0 | 117.91 | 425.25 | 721.45 | 217.11 | 228.24 | |
| ДН | 360.27 | 1485.99 | 3741.36 | 5460.47 | 7536.16 | |
| MGR_0 против MGR_1 | -62.90% | -67.85% | -79.17% | -95.70% | -96.61% | |
| DN против MGR_1 | 13.35% | 12.33% | 8.00% | 8.07% | 11.87% | |
| DN против MGR_0 | 205.55% | 249.44% | 418.59% | 2415.07% | 3201.86% | |
| oltp_write_only | МГР_1 | 761.87 | 2924.1 | 7211.97 | 10374.15 | 16092.02 |
| МГР_0 | 309.83 | 465.44 | 748.68 | 245.75 | 318.48 | |
| ДН | 1121.07 | 3787.64 | 7627.26 | 11684.37 | 15137.23 | |
| MGR_0 против MGR_1 | -59.33% | -84.08% | -89.62% | -97.63% | -98.02% | |
| DN против MGR_1 | 47.15% | 29.53% | 5.76% | 12.63% | -5.93% | |
| DN против MGR_0 | 261.83% | 713.78% | 918.76% | 4654.58% | 4652.96% |
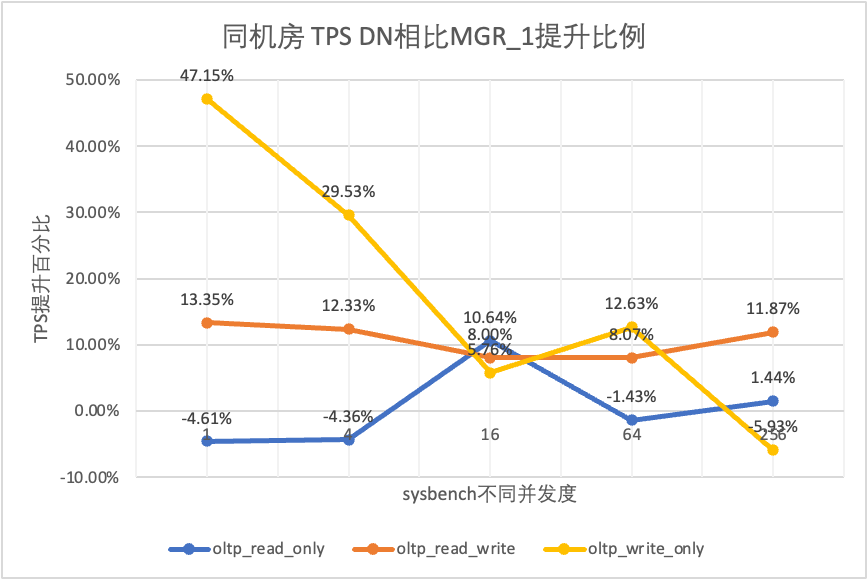
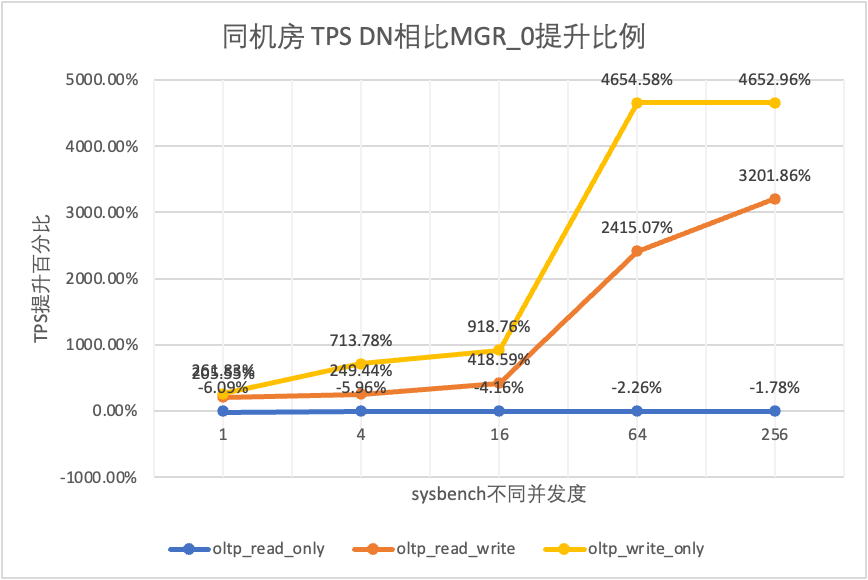
Это видно по результатам испытаний:
| Сравнение TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | МГР_1 | 695.69 | 2697.91 | 7223.43 | 11699.29 | 14542.4 |
| МГР_0 | 691.17 | 2708.6 | 7849.98 | 11636.94 | 14670.99 | |
| ДН | 645.11 | 2611.15 | 7628.39 | 11294.36 | 14647.22 | |
| MGR_0 против MGR_1 | -0.65% | 0.40% | 8.67% | -0.53% | 0.88% | |
| DN против MGR_1 | -7.27% | -3.22% | 5.61% | -3.46% | 0.72% | |
| DN против MGR_0 | -6.66% | -3.60% | -2.82% | -2.94% | -0.16% | |
| oltp_read_write | МГР_1 | 171.37 | 677.77 | 2230 | 3872.87 | 6096.62 |
| МГР_0 | 117.11 | 469.17 | 765.64 | 813.85 | 812.46 | |
| ДН | 257.35 | 1126.07 | 3296.49 | 5135.18 | 7010.37 | |
| MGR_0 против MGR_1 | -31.66% | -30.78% | -65.67% | -78.99% | -86.67% | |
| DN против MGR_1 | 50.17% | 66.14% | 47.82% | 32.59% | 14.99% | |
| DN против MGR_0 | 119.75% | 140.01% | 330.55% | 530.97% | 762.86% | |
| oltp_write_only | МГР_1 | 248.37 | 951.88 | 2791.07 | 5989.57 | 11666.16 |
| МГР_0 | 162.92 | 603.72 | 791.27 | 828.16 | 866.65 | |
| ДН | 553.69 | 2173.18 | 5836.64 | 10588.9 | 13241.74 | |
| MGR_0 против MGR_1 | -34.40% | -36.58% | -71.65% | -86.17% | -92.57% | |
| DN против MGR_1 | 122.93% | 128.30% | 109.12% | 76.79% | 13.51% | |
| DN против MGR_0 | 239.85% | 259.96% | 637.63% | 1178.61% | 1427.92% |


Это видно по результатам испытаний:
| Сравнение TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | МГР_1 | 687.76 | 2703.5 | 7030.37 | 11580.36 | 14674.7 |
| МГР_0 | 687.17 | 2744.41 | 7908.44 | 11535.35 | 14656 | |
| ДН | 657.06 | 2610.58 | 7591.21 | 11174.94 | 14545.45 | |
| MGR_0 против MGR_1 | -0.09% | 1.51% | 12.49% | -0.39% | -0.13% | |
| DN против MGR_1 | -4.46% | -3.44% | 7.98% | -3.50% | -0.88% | |
| DN против MGR_0 | -4.38% | -4.88% | -4.01% | -3.12% | -0.75% | |
| oltp_read_write | МГР_1 | 29.13 | 118.64 | 572.25 | 997.92 | 2253.19 |
| МГР_0 | 26.94 | 90.8 | 313.64 | 419.17 | 426.7 | |
| ДН | 254.87 | 1146.57 | 3339.83 | 5307.85 | 7171.95 | |
| MGR_0 против MGR_1 | -7.52% | -23.47% | -45.19% | -58.00% | -81.06% | |
| DN против MGR_1 | 774.94% | 866.43% | 483.63% | 431.89% | 218.30% | |
| DN против MGR_0 | 846.07% | 1162.74% | 964.86% | 1166.28% | 1580.79% | |
| oltp_write_only | МГР_1 | 30.81 | 145.54 | 576.61 | 1387.64 | 3705.51 |
| МГР_0 | 28.68 | 108.86 | 387.48 | 470.5 | 476.4 | |
| ДН | 550.11 | 2171.64 | 5866.41 | 10381.72 | 14478.38 | |
| MGR_0 против MGR_1 | -6.91% | -25.20% | -32.80% | -66.09% | -87.14% | |
| DN против MGR_1 | 1685.49% | 1392.13% | 917.40% | 648.16% | 290.73% | |
| DN против MGR_0 | 1818.10% | 1894.89% | 1413.99% | 2106.53% | 2939.12% |
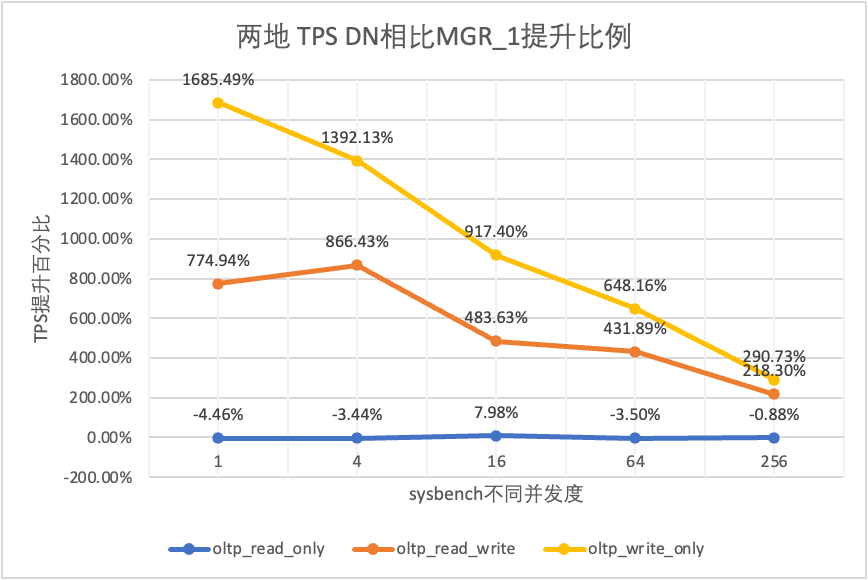
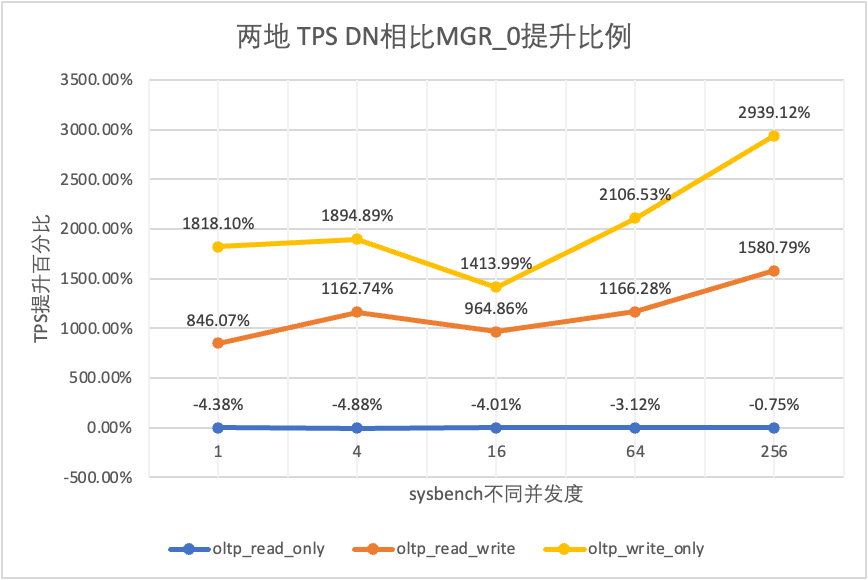
Это видно по результатам испытаний:
| Сравнение TPS | 1 | 4 | 16 | 64 | 256 | |
| oltp_read_only | МГР_1 | 688.49 | 2747.69 | 7853.91 | 11722.71 | 15292.73 |
| МГР_0 | 687.66 | 2756.3 | 8005.11 | 11567.89 | 15055.69 | |
| ДН | 656.06 | 2600.35 | 7657.85 | 11227.56 | 14562.86 | |
| MGR_0 против MGR_1 | -0.12% | 0.31% | 1.93% | -1.32% | -1.55% | |
| DN против MGR_1 | -4.71% | -5.36% | -2.50% | -4.22% | -4.77% | |
| DN против MGR_0 | -4.60% | -5.66% | -4.34% | -2.94% | -3.27% | |
| oltp_read_write | МГР_1 | 26.01 | 113.98 | 334.95 | 693.34 | 2030.6 |
| МГР_0 | 23.93 | 110.17 | 475.68 | 497.92 | 511.99 | |
| ДН | 122.06 | 525.88 | 1885.7 | 3314.9 | 5889.79 | |
| MGR_0 против MGR_1 | -8.00% | -3.34% | 42.02% | -28.19% | -74.79% | |
| DN против MGR_1 | 369.28% | 361.38% | 462.98% | 378.11% | 190.05% | |
| DN против MGR_0 | 410.07% | 377.34% | 296.42% | 565.75% | 1050.37% | |
| oltp_write_only | МГР_1 | 27.5 | 141.64 | 344.05 | 982.47 | 2889.85 |
| МГР_0 | 25.52 | 155.43 | 393.35 | 470.92 | 504.68 | |
| ДН | 171.74 | 535.83 | 1774.58 | 4328.44 | 9429.24 | |
| MGR_0 против MGR_1 | -7.20% | 9.74% | 14.33% | -52.07% | -82.54% | |
| DN против MGR_1 | 524.51% | 278.30% | 415.79% | 340.57% | 226.29% | |
| DN против MGR_0 | 572.96% | 244.74% | 351.15% | 819.15% | 1768.36% |
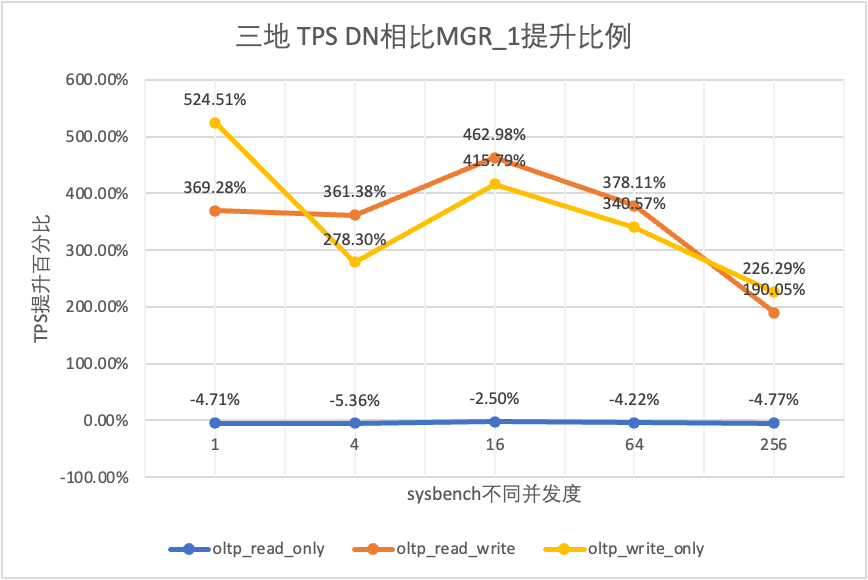
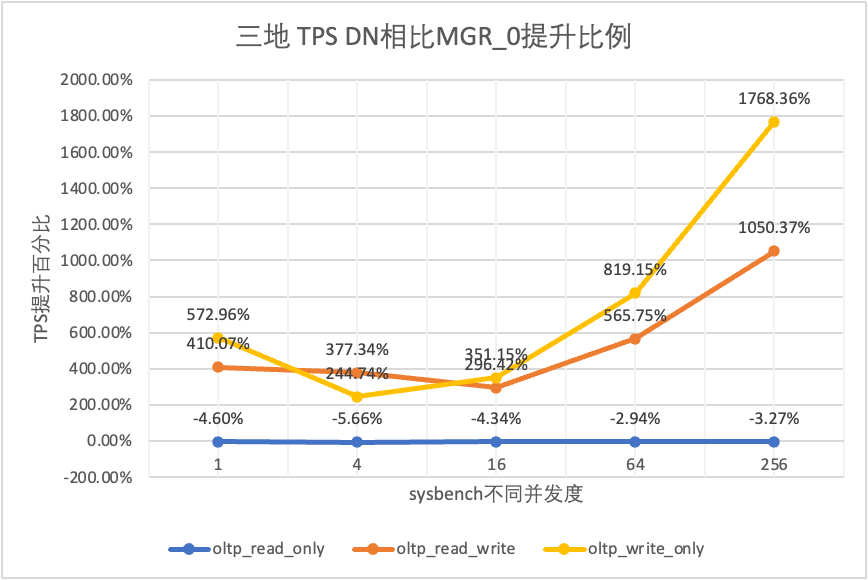
Это видно по результатам испытаний:
Чтобы наглядно сравнить изменения производительности при различных методах развертывания, мы выбрали данные TPS для MGR и DN при разных методах развертывания в рамках сценария oltp_write_only 256 в приведенном выше тесте. Используя данные испытаний в компьютерном зале в качестве базовых, мы рассчитали и сравнили данные TPS различных методов развертывания по сравнению с базовым уровнем, чтобы оценить разницу в изменениях производительности при развертывании в пределах города.
| MGR_1 (256 одновременно) | DN (256 одновременно) | Преимущества производительности DN по сравнению с MGR | |
| Тот же компьютерный зал | 16092.02 | 15137.23 | -5.93% |
| Три центра в одном городе | 11666.16 (72.50%) | 13241.74 (87.48%) | +13.50% |
| Два места и три центра | 3705.51 (23.03%) | 14478.38 (95.64%) | +290.72% |
| Три места и три центра | 2889.85 (17.96%) | 9429.24 (62.29%) | +226.28% |
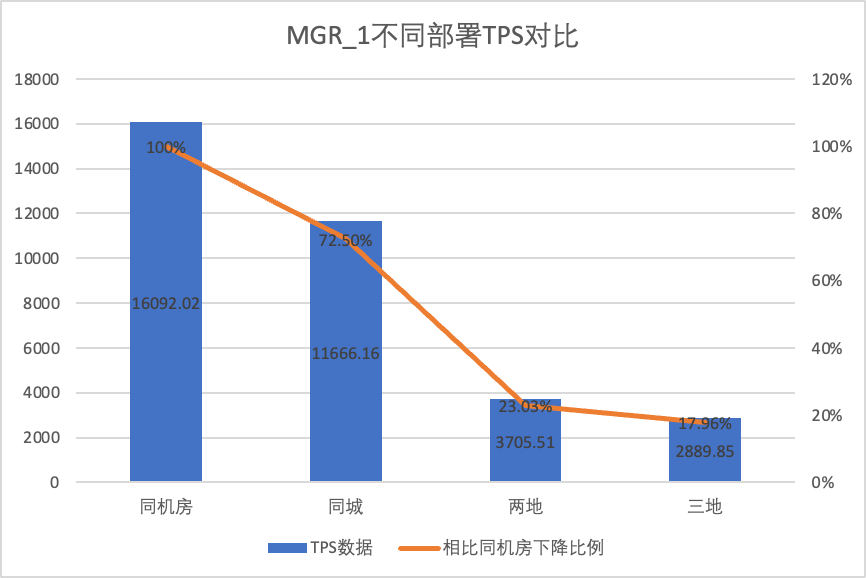
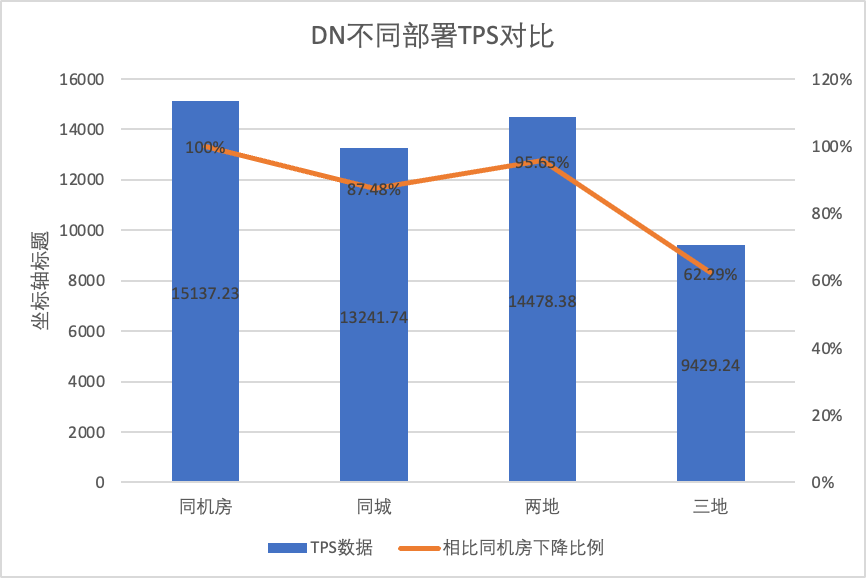
Это видно по результатам испытаний:
При фактическом использовании мы обращаем внимание не только на данные о производительности, но также должны обращать внимание на дрожание производительности. В конце концов, если дрожание похоже на американские горки, реальный пользовательский опыт будет очень плохим. Мы отслеживаем и отображаем выходные данные TPS в реальном времени. Учитывая, что сам инструмент sysbenc не поддерживает выходные данные мониторинга джиттера производительности, в качестве показателя сравнения мы используем математический коэффициент вариации:
На примере сценария oltp_read_write с 256 параллельными операциями мы статистически анализируем TPS MGR_1 (RPO<>0) и DN (RPO=0) в одном компьютерном зале, трех центрах в одном городе, трех центрах в двух местах и три центра в трех местах. Фактический график джиттера выглядит следующим образом, а фактические данные индикатора джиттера для каждого сценария следующие:
| резюме | Тот же компьютерный зал | Три центра в одном городе | Два места и три центра | Три места и три центра |
| МГР_1 | 10.04% | 8.96% | 6.02% | 8.63% |
| ДН | 3.68% | 3.78% | 2.55% | 4.05% |
| MGR_1/DN | 272.83% | 237.04% | 236.08% | 213.09% |
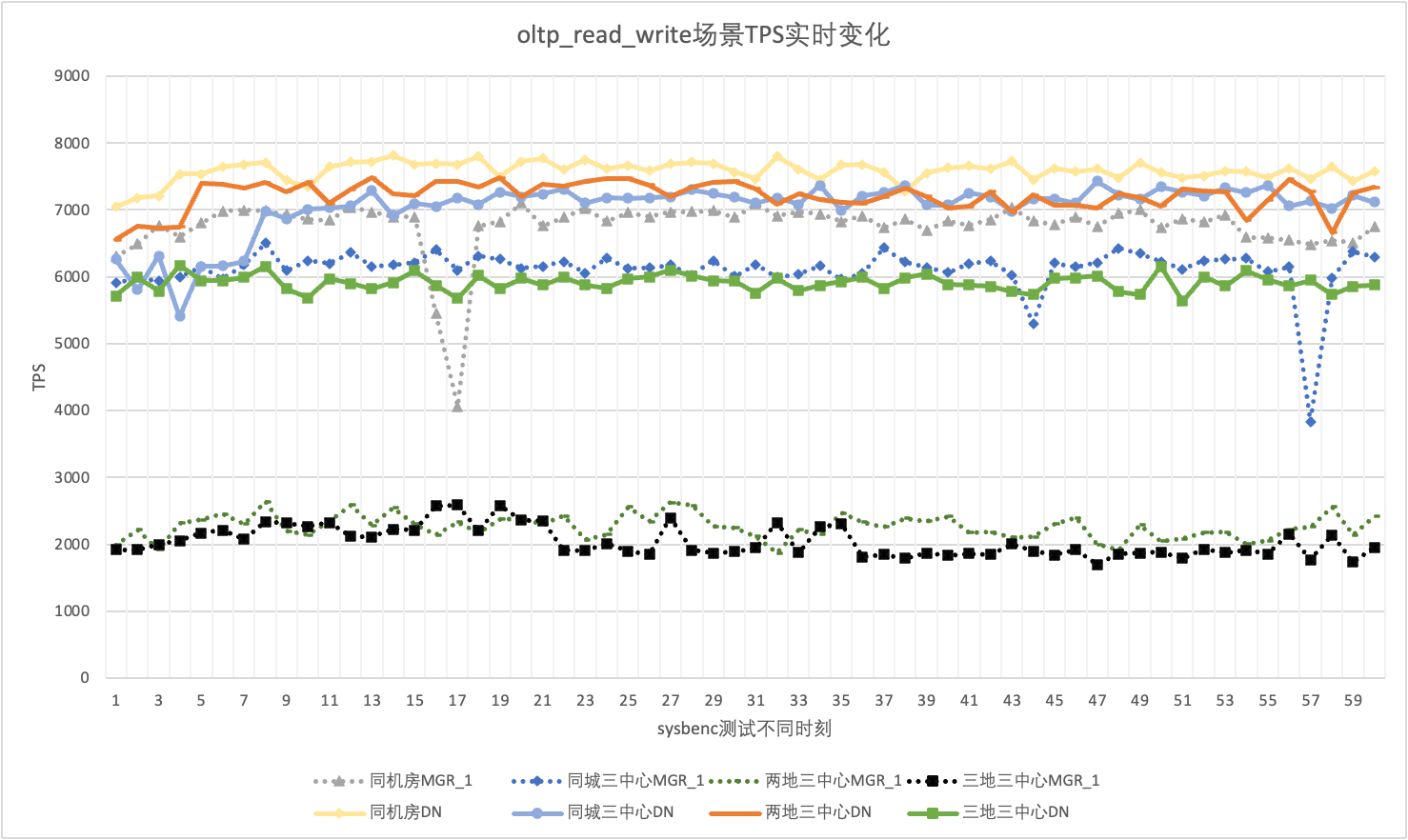
Это видно по результатам испытаний:
Основной особенностью распределенной базы данных является высокая доступность. Отказ любого узла в кластере не повлияет на общую доступность. Для типичной формы развертывания трех узлов с одним главным и двумя резервными узлами, развернутыми в одном компьютерном зале, мы попытались провести тесты удобства использования в следующих трех сценариях:
Когда нагрузки нет, убейте лидера и следите за изменением статуса каждого узла в кластере и за тем, доступен ли он для записи.
| МГР | ДН | |
| Запускаем нормально | 0 | 0 |
| убить лидера | 0 | 0 |
| Обнаружено аномальное время узла | 5 | 5 |
| Время сократить 3 узла до 2 узлов | 23 | 8 |
| МГР | ДН | |
| Запускаем нормально | 0 | 0 |
| убить лидера, автоматически подтянуться | 0 | 0 |
| Обнаружено аномальное время узла | 5 | 5 |
| Время сократить 3 узла до 2 узлов | 23 | 8 |
| 2 узла восстанавливают 3 узла времени | 37 | 15 |

Из результатов испытаний видно, что в условиях отсутствия давления:
Используйте sysbench для проведения одновременного стресс-теста из 16 потоков в сценарии oltp_read_write. На 10-й секунде на рисунке вручную завершите резервный узел и наблюдайте за выходными данными TPS sysbench в реальном времени.
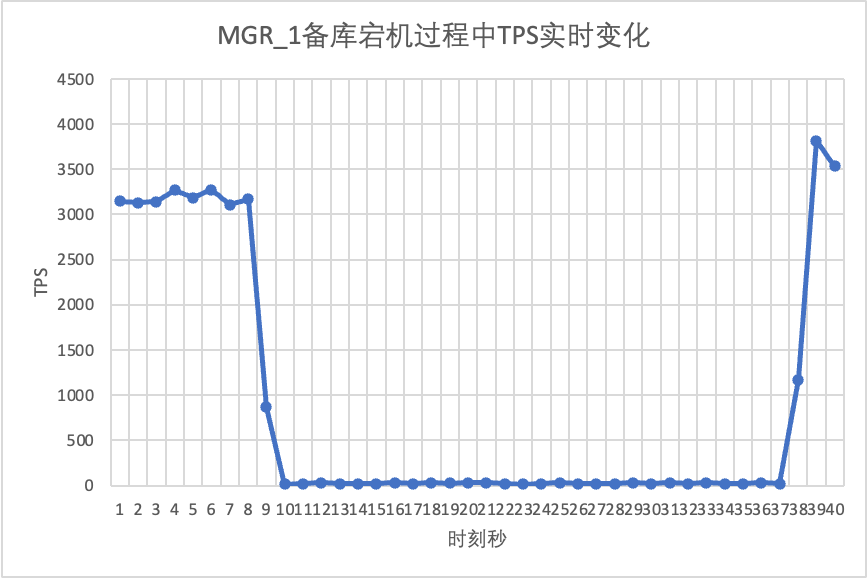


Это видно из таблицы результатов теста:
Продолжая тест, перезапускаем и восстанавливаем резервную базу данных и наблюдаем за изменением данных TPS основной базы данных.
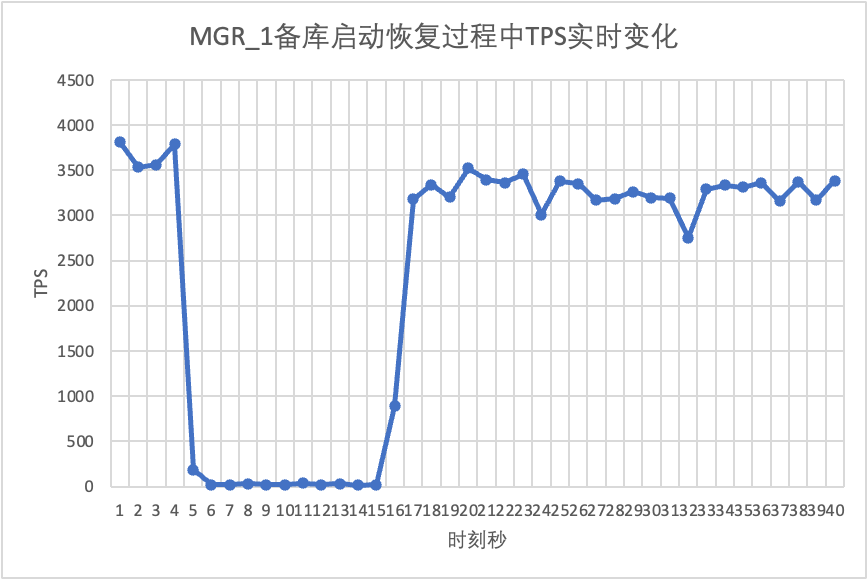
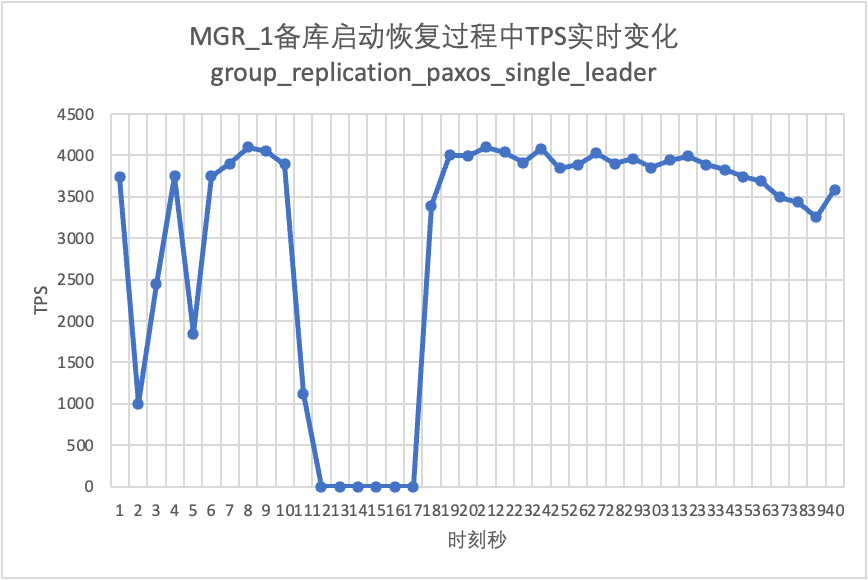
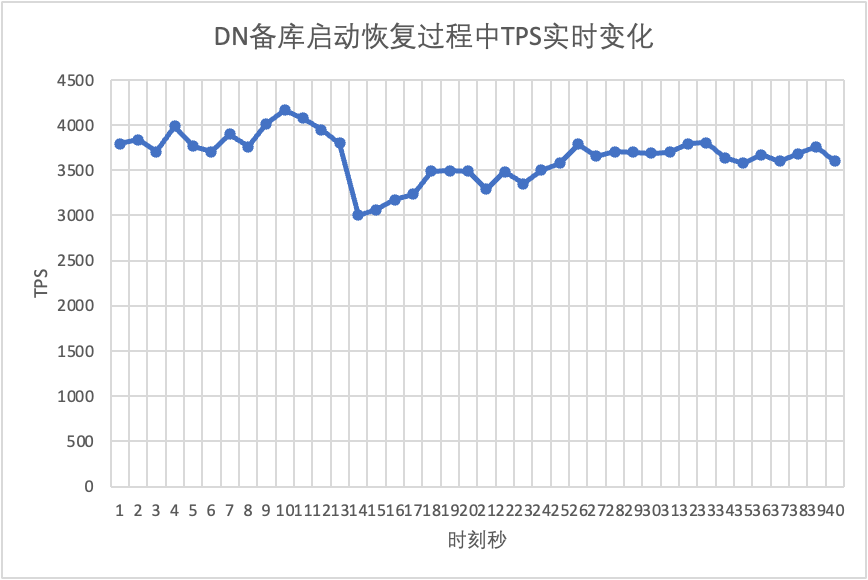
Это видно из таблицы результатов теста:
Чтобы построить сценарий RPO<>0 сбоев MGR, мы используем собственный метод MTR Case для выполнения тестирования с внесением ошибок в MGR. Разработанный случай выглядит следующим образом:
- --echo
- --echo ############################################################
- --echo # 1. Deploy a 3 members group in single primary mode.
- --source include/have_debug.inc
- --source include/have_group_replication_plugin.inc
- --let $group_replication_group_name= aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
- --let $rpl_group_replication_single_primary_mode=1
- --let $rpl_skip_group_replication_start= 1
- --let $rpl_server_count= 3
- --source include/group_replication.inc
-
- --let $rpl_connection_name= server1
- --source include/rpl_connection.inc
- --let $server1_uuid= `SELECT @@server_uuid`
- --source include/start_and_bootstrap_group_replication.inc
-
- --let $rpl_connection_name= server2
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- --source include/start_group_replication.inc
-
- --echo
- --echo ############################################################
- --echo # 2. Init data
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
-
- --source include/rpl_sync.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
-
- --echo
- --echo ############################################################
- --echo # 3. Mock crash majority members
-
- --echo # server 2 wait before write relay log
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
- --echo # server 3 wait before write relay log
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
-
-
- --echo # server 1 commit new transaction
- --let $rpl_connection_name = server1
- --source include/rpl_connection.inc
- INSERT INTO t1 VALUES(2);
- # server 1 commit t1(c1=2) record
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 1 crash
- --source include/kill_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 3 check
- --let $rpl_connection_name = server3
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- SELECT * FROM t1;
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 crash and restart
- --source include/kill_and_restart_mysqld.inc
-
- --echo # sleep enough time for electing new leader
- sleep 60;
-
- --echo
- --echo ############################################################
- --echo # 4. Check alive members, lost t1(c1=2) record
-
- --echo # server 3 check
- --let $rpl_connection_name= server3
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
-
- --echo
- --echo # server 2 check
- --let $rpl_connection_name = server2
- --source include/rpl_connection.inc
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- --echo # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- !include ../my.cnf
-
- [mysqld.1]
- loose-group_replication_member_weight=100
-
- [mysqld.2]
- loose-group_replication_member_weight=90
-
- [mysqld.3]
- loose-group_replication_member_weight=80
-
- [ENV]
- SERVER_MYPORT_3= @mysqld.3.port
- SERVER_MYSOCK_3= @mysqld.3.socket
Результаты рассмотрения дела следующие:
-
- ############################################################
- # 1. Deploy a 3 members group in single primary mode.
- include/group_replication.inc [rpl_server_count=3]
- Warnings:
- Note #### Sending passwords in plain text without SSL/TLS is extremely insecure.
- Note #### Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
- [connection server1]
- [connection server1]
- include/start_and_bootstrap_group_replication.inc
- [connection server2]
- include/start_group_replication.inc
- [connection server3]
- include/start_group_replication.inc
-
- ############################################################
- # 2. Init data
- [connection server1]
- CREATE TABLE t1 (c1 INT PRIMARY KEY);
- INSERT INTO t1 VALUES(1);
- include/rpl_sync.inc
- SELECT * FROM t1;
- c1
- 1
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
-
- ############################################################
- # 3. Mock crash majority members
- # server 2 wait before write relay log
- [connection server2]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 3 wait before write relay log
- [connection server3]
- SET GLOBAL debug = '+d,wait_in_the_middle_of_trx';
- # server 1 commit new transaction
- [connection server1]
- INSERT INTO t1 VALUES(2);
- SELECT * FROM t1;
- c1
- 1
- 2
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13000 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13002 ONLINE SECONDARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 1 crash
- # Kill the server
- # sleep enough time for electing new leader
-
- # server 3 check
- [connection server3]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 ONLINE SECONDARY 8.0.32 XCom
- # server 3 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- # server 2 check
- [connection server2]
- SELECT * FROM t1;
- c1
- 1
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier 127.0.0.1 13002 ONLINE PRIMARY 8.0.32 XCom
- group_replication_applier 127.0.0.1 13004 UNREACHABLE SECONDARY 8.0.32 XCom
- # server 2 crash and restart
- # Kill and restart
- # sleep enough time for electing new leader
-
- ############################################################
- # 4. Check alive members, lost t1(c1=2) record
- # server 3 check
- [connection server3]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 3 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
-
- # server 2 check
- [connection server2]
- select CHANNEL_NAME,MEMBER_HOST,MEMBER_PORT,MEMBER_STATE,MEMBER_ROLE,MEMBER_VERSION,MEMBER_COMMUNICATION_STACK from performance_schema.replication_group_members order by MEMBER_PORT;
- CHANNEL_NAME MEMBER_HOST MEMBER_PORT MEMBER_STATE MEMBER_ROLE MEMBER_VERSION MEMBER_COMMUNICATION_STACK
- group_replication_applier NULL OFFLINE
- # server 2 lost t1(c1=2) record
- SELECT * FROM t1;
- c1
- 1
Примерная логика кейса, воспроизводящего пропущенные числа, следующая:
В соответствии с приведенным выше случаем для MGR, когда большинство серверов не работает и основная база данных недоступна, а после восстановления резервной базы данных произойдет потеря данных RPO<>0 и запись об успешной фиксации, которая изначально был возвращен клиенту, утерян.
Для DN достижение большинства требует, чтобы журналы сохранялись в большинстве, поэтому даже в приведенном выше сценарии данные не будут потеряны и можно гарантировать RPO=0.
В традиционном активно-резервном режиме MySQL резервная база данных обычно содержит потоки ввода-вывода и потоки применения. После введения протокола Paxos поток ввода-вывода синхронизирует binlog активной и резервной баз данных. В основном задержка репликации резервной базы данных. зависит от накладных расходов на воспроизведение резервной базы данных, здесь мы становимся задержкой воспроизведения резервной базы данных.
Мы используем sysbench для тестирования сценария oltp_write_only и проверяем продолжительность задержки воспроизведения резервной базы данных при 100 параллелизмах и различном количестве событий.Время задержки воспроизведения резервной базы данных можно определить, отслеживая столбец APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP таблицы Performance_schema.replication_applier_status_by_worker, чтобы увидеть, работает ли каждый исполнитель в режиме реального времени, чтобы определить, закончилась ли репликация.

Это видно из таблицы результатов теста:
| МГР | ДН | ||
| производительность | Чтение транзакции | плоский | плоский |
| запись транзакции | Производительность не так хороша, как у DN, когда RPO<>0 Когда RPO=0, производительность намного хуже, чем у DN. Производительность развертывания между городами серьезно упала на 27–82 %. | Производительность транзакций записи намного выше, чем MGR Производительность развертывания между городами снижается на 4–37 %. | |
| Джиттер | Дрожание производительности серьезное, диапазон джиттера составляет 6–10 %. | Относительно стабильно на уровне 3%, что составляет лишь половину MGR. | |
| РТО | Основная база данных не работает | Аномалия была обнаружена через 5 с и уменьшена до двух узлов за 23 с. | Аномалия была обнаружена за 5 секунд и уменьшена до двух узлов за 8 секунд. |
| Перезапустите основную библиотеку | Аномалия была обнаружена за 5 секунд, а три узла были восстановлены за 37 секунд. | Аномалия обнаруживается за 5 секунд, а три узла восстанавливаются за 15 секунд. | |
| Время простоя резервной базы данных | Трафик основной базы данных упал до 0 на 20 секунд. Эту проблему можно облегчить, явно включив group_replication_paxos_single_leader. | Непрерывная высокая доступность основной базы данных | |
| Перезапуск резервной базы данных | Трафик основной базы данных упал до 0 на 10 секунд. Явное включение group_replication_paxos_single_leader также не дает никакого эффекта. | Непрерывная высокая доступность основной базы данных | |
| РПО | Повторение случая | RPO<>0, когда партия большинства выходит из строя Производительность и RPO=0 не могут иметь оба значения. | РПО = 0 |
| Задержка резервной базы данных | Время воспроизведения резервной базы данных | Задержка между активным и резервным режимами очень велика. Производительность и задержка основного резервного копирования не могут быть достигнуты одновременно. | Общее время, затрачиваемое на воспроизведение резервной базы данных, составляет 4% от MGR, что в 25 раз больше, чем у MGR. |
| параметр | ключевой параметр |
| Конфигурация по умолчанию, профессионалам не нужно настраивать конфигурацию |
После углубленного технического анализа и сравнения производительности,PolarDB-X Благодаря собственному протоколу X-Paxos и ряду оптимизированных конструкций DN продемонстрировал множество преимуществ по сравнению с MySQL MGR с точки зрения производительности, корректности, доступности и затрат ресурсов. Однако MGR также занимает важную позицию в экосистеме MySQL. Необходимо учитывать различные ситуации, такие как дрожание резервной базы данных, колебания производительности аварийного восстановления в разных машинных залах и стабильность. Поэтому, если вы хотите эффективно использовать MGR, у вас должна быть профессиональная команда технических специалистов, а также специалистов по эксплуатации и обслуживанию. поддерживать.
Когда речь идет о крупномасштабных требованиях к высокому параллелизму и высокой доступности, механизм хранения данных PolarDB-X обладает уникальными техническими преимуществами и превосходной производительностью по сравнению с MGR в готовых сценариях.PolarDB-XЦентрализованная версия на основе DN (стандартная версия) имеет хороший баланс между функциями и производительностью, что делает ее высококонкурентным решением для баз данных.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования.

Почтамезофия@protonmail.com