2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP ist ein Client-Server-Protokoll und die beiden Kommunikationsparteien sind der Client und der Server. Der Client sendet eine HTTP-Anfrage, und der Server empfängt und verarbeitet die Anfrage und gibt eine HTTP-Antwort zurück.
HTTP-Anfragen bestehen aus Anfragezeilen, Anfrageheadern, Leerzeilen und Anfragedaten (z. B. Formulardaten in POST-Anfragen).
Anfragebeispiel:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
Anforderungszeile:POST /api/users HTTP/1.1
Anforderungsheader: Enthält Host, User-Agent, Accept, Content-Type, Content-Length usw.
Leerzeile: Leere Zeile zwischen Anforderungsheader und Anforderungstext
Anforderungstext:JSON-Daten
Die HTTP-Antwort besteht aus einer Statuszeile, Antwortheadern, Leerzeilen und Antwortdaten.
Angenommen, der Server gibt eine einfache HTML-Seite zurück, könnte die Antwort wie folgt aussehen:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
Statuszeile:HTTP/1.1 200 OK
Antwortheader: Enthält Datum, Server, Inhaltstyp, Inhaltslänge, Verbindung usw.
Leerzeile: Leerzeile zwischen Antwortheadern und Antworttext
Antwortkörper: Enthält HTML-Code
HTTP-Statuscodes geben die Verarbeitungsergebnisse der Anfrage durch den Server an. Zu den gängigen Statuscodes gehören:

Die Requests-Bibliothek von Python ist eine sehr leistungsstarke und benutzerfreundliche HTTP-Bibliothek.
Bevor Sie es verwenden können, müssen Sie die Requests-Bibliothek installieren:pip install requests
Mit der GET-Anfrage werden Daten vom Server angefordert. Das Erstellen einer GET-Anfrage mithilfe der Requests-Bibliothek ist sehr einfach:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Mit der POST-Anfrage werden Daten an den Server übermittelt. Beispielsweise verwenden Websites, die eine Anmeldung erfordern, häufig POST-Anfragen, um einen Benutzernamen und ein Passwort zu übermitteln. Die Methode zur Verwendung der Requests-Bibliothek zum Initiieren einer POST-Anfrage ist wie folgt:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Um zu verhindern, dass Crawler auf einigen Websites (z. B. Douban) über einen Anti-Crawling-Mechanismus verfügen, müssen Sie HTTP-Anforderungsheader und -Parameter so festlegen, dass sie sich als Browser ausgeben und die Authentifizierung bestehen.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
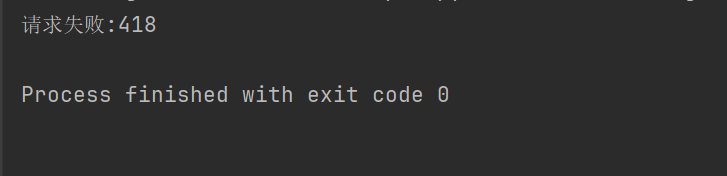
Wenn der obige Code beispielsweise den Anforderungsheader nicht festlegt, verweigert Douban uns den Zugriff.
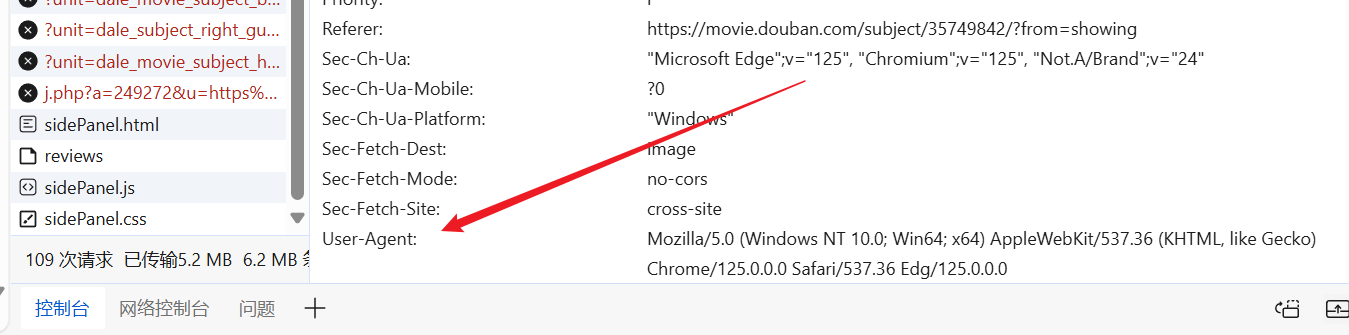
Wir können die Website nach Belieben betreten, einen vorgefertigten User-Agent finden und ihn in unseren Anfrage-Header einfügen.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
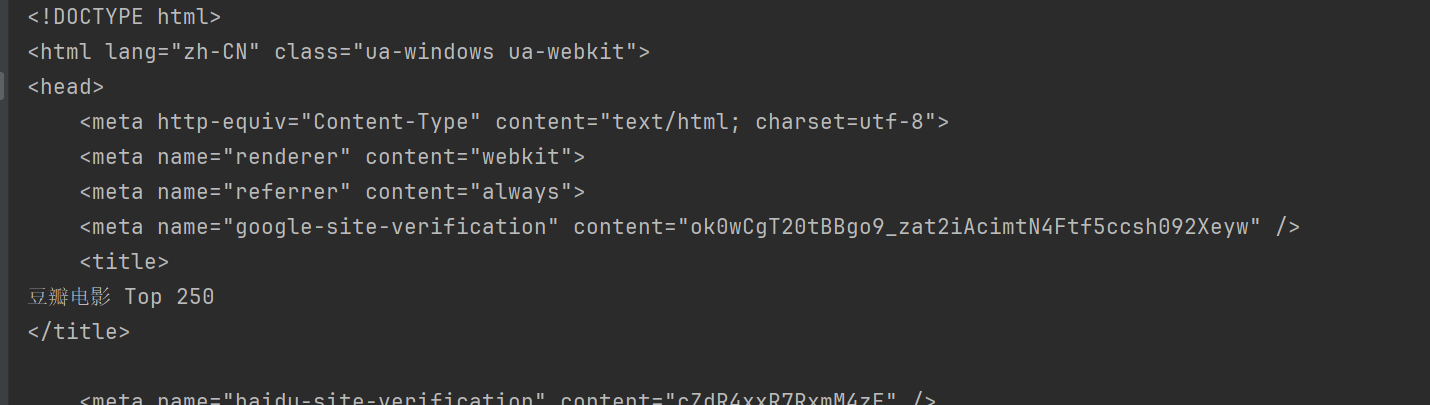
Auf diese Weise können Sie auf Douban zugreifen und den Inhalt der Webseite abrufen.
BeautifulSoup ist eine Python-Bibliothek zum Parsen von HTML- und XML-Dokumenten, insbesondere zum Extrahieren von Daten aus Webseiten.
Vor der Verwendung müssen Sie die BeautifulSoup-Bibliothek installieren:pip install beautifulsoup4
html.parser Es handelt sich um den in Python integrierten Parser, der für die meisten Szenarien geeignet ist. Nehmen Sie als Beispiel Douban oben.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup bietet mehrere Methoden zum Suchen und Extrahieren von Daten aus HTML-Dokumenten.
Gemeinsame Methoden von BeautifulSoup:
find(tag, attributes): Finden Sie das erste Tag, das den Kriterien entspricht.find_all(tag, attributes): Alle passenden Tags finden.select(css_selector): Verwenden Sie CSS-Selektoren, um Tags zu finden, die den Kriterien entsprechen.get_text(): Holen Sie sich den Textinhalt innerhalb des Etiketts.attrs: Rufen Sie das Attributwörterbuch des Tags ab.find Die Methode wird verwendet, um das erste Element zu finden, das die Kriterien erfüllt. So finden Sie beispielsweise den ersten Titel auf einer Seite:
title = soup.find("span", class_="title")
print(title.string)
findAll Die Methode wird verwendet, um alle Elemente zu finden, die die Kriterien erfüllen. So finden Sie beispielsweise alle Titel auf einer Seite:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Die Methode ermöglicht die Verwendung von CSS-Selektoren zum Suchen von Elementen. Um beispielsweise alle Titel zu finden:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
Kann benutzenattrs Eigenschaften Ruft das Attributwörterbuch des Elements ab. Rufen Sie beispielsweise die URLs aller Bilder ab:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
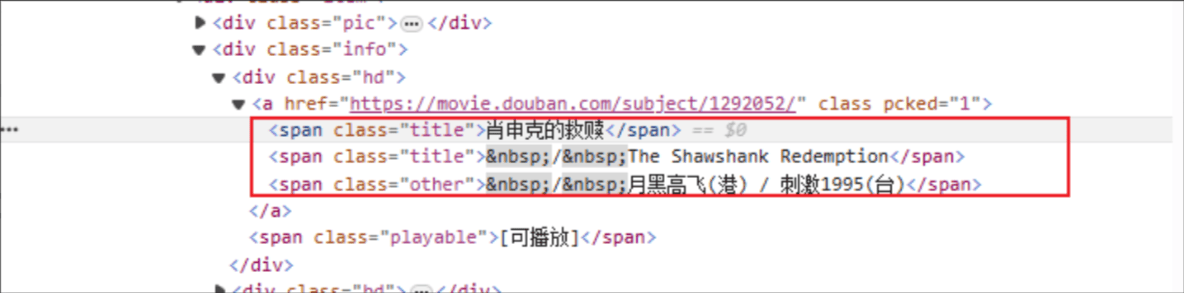
Filmtitel: Der HTML-Tag-Name lautet: span und das Klassenattribut des angegebenen Elements ist title.

Bewertung: Das HTML-Tag lautet: span und das Klassenattribut des angegebenen Elements ist Rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
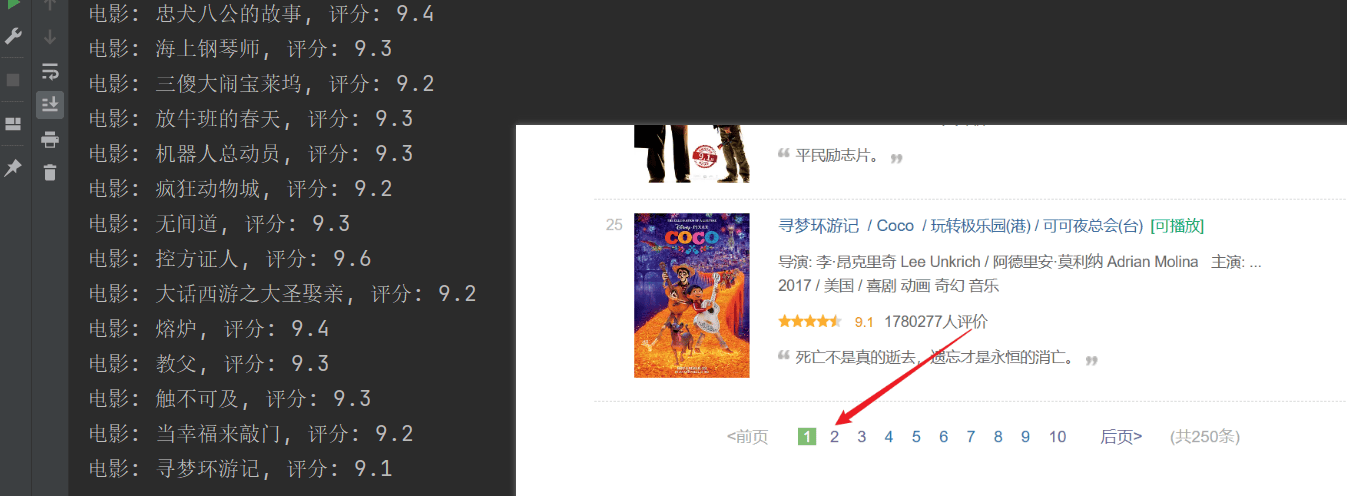
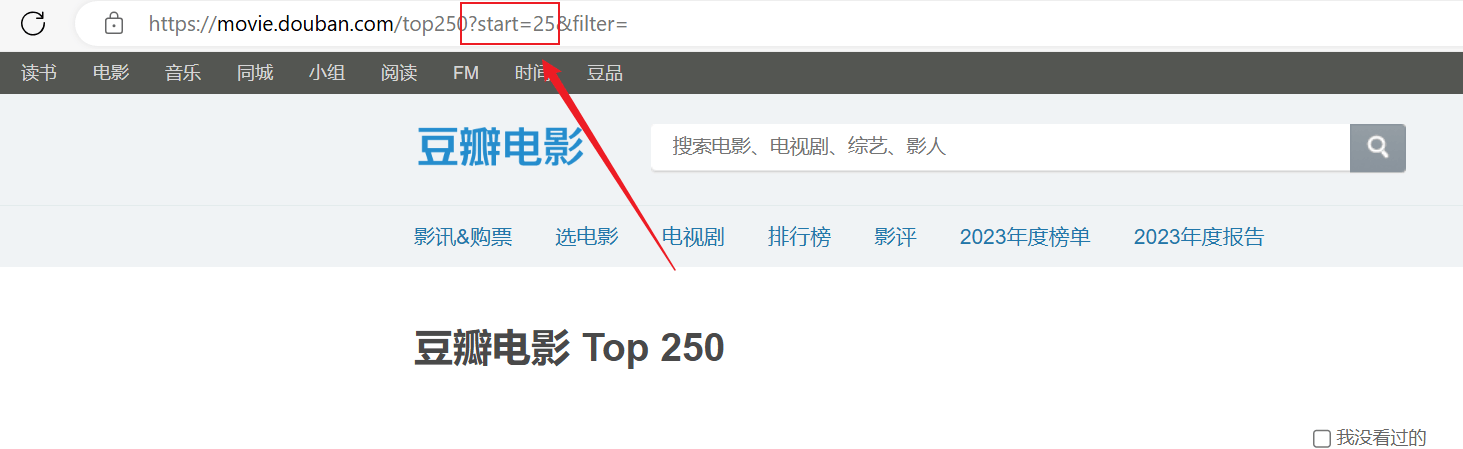
Das Crawling war erfolgreich, aber nur die erste Seite wurde gecrawlt und nachfolgende Inhalte wurden nicht erfolgreich gecrawlt.Analysieren Sie die obige URL-Verbindung. Jede Seite übergibt siestartParameter werden ausgelagert.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet, Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

