
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP è un protocollo client-server e le due parti della comunicazione sono il client e il server. Il client invia una richiesta HTTP e il server riceve ed elabora la richiesta e restituisce una risposta HTTP.
Le richieste HTTP sono costituite da righe di richiesta, intestazioni di richiesta, righe vuote e dati di richiesta (come i dati del modulo nelle richieste POST).
Richiedi esempio:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
riga di richiesta:POST /api/utenti HTTP/1.1
Intestazione della richiesta: contiene Host, User-Agent, Accetta, Tipo di contenuto, Lunghezza del contenuto, ecc.
riga vuota: riga vuota tra l'intestazione e il corpo della richiesta
Richiedi corpo:Dati JSON
La risposta HTTP è composta da riga di stato, intestazioni di risposta, righe vuote e dati di risposta.
Supponendo che il server restituisca una semplice pagina HTML, la risposta potrebbe essere la seguente:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
linea di stato:HTTP/1.1 200 OK
intestazione della risposta: contiene data, server, tipo di contenuto, lunghezza del contenuto, connessione, ecc.
riga vuota: riga vuota tra le intestazioni e il corpo della risposta
corpo della risposta: contiene il codice HTML
I codici di stato HTTP indicano i risultati dell'elaborazione della richiesta da parte del server. I codici di stato comuni includono:

La libreria Requests di Python è una libreria HTTP molto potente e facile da usare.
Prima di utilizzarlo è necessario installare la libreria Requests:pip install requests
La richiesta GET viene utilizzata per richiedere dati dal server. Effettuare una richiesta GET utilizzando la libreria Richieste è molto semplice:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
La richiesta POST viene utilizzata per inviare dati al server. Ad esempio, i siti Web che richiedono un accesso spesso utilizzano richieste POST per inviare un nome utente e una password. Il metodo per utilizzare la libreria Requests per avviare una richiesta POST è il seguente:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Su alcuni siti web (come Douban), per impedire ai crawler di avere un meccanismo anti-crawling, è necessario impostare intestazioni e parametri della richiesta HTTP per fingere di essere un browser e passare l'autenticazione.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
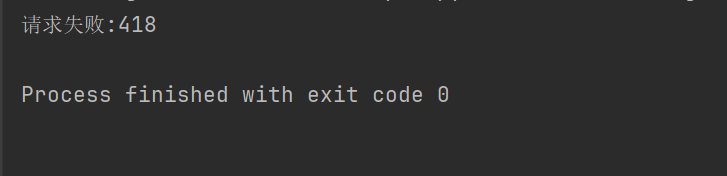
Ad esempio, se il codice sopra non imposta l'intestazione della richiesta, Douban ci negherà l'accesso.
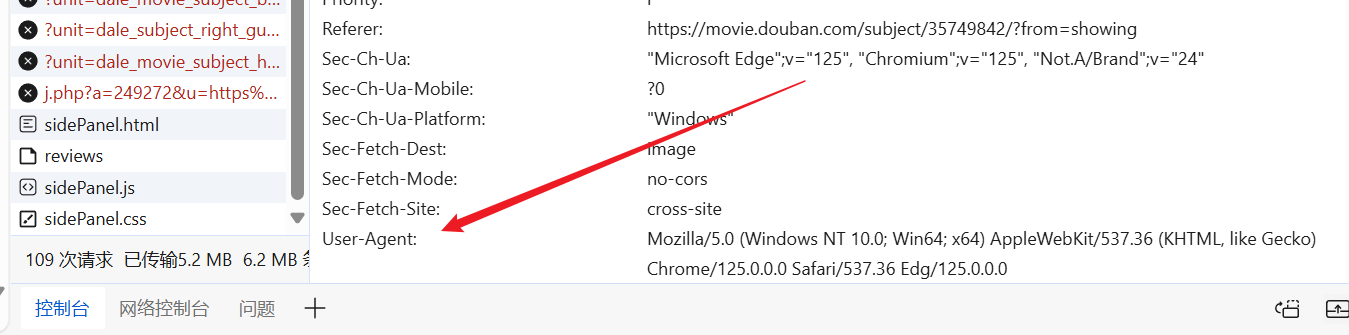
Possiamo accedere al sito Web a nostro piacimento, trovare uno User-Agent già pronto e inserirlo nell'intestazione della nostra richiesta.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
In questo modo potrai accedere a Douban e ottenere il contenuto della pagina web.
BeautifulSoup è una libreria Python per l'analisi di documenti HTML e XML, in particolare per l'estrazione di dati da pagine web.
Prima dell'uso è necessario installare la libreria BeautifulSoup:pip install beautifulsoup4
html.parser È il parser integrato di Python ed è adatto alla maggior parte degli scenari. Prendi Douban sopra come esempio.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup fornisce diversi metodi per trovare ed estrarre dati da documenti HTML.
Metodi comuni di BeautifulSoup:
find(tag, attributes): trova il primo tag che corrisponde ai criteri.find_all(tag, attributes): trova tutti i tag corrispondenti.select(css_selector): utilizza i selettori CSS per trovare i tag che corrispondono ai criteri.get_text(): ottiene il contenuto del testo all'interno dell'etichetta.attrs: ottiene il dizionario degli attributi del tag.find Il metodo viene utilizzato per trovare il primo elemento che soddisfa i criteri. Ad esempio, per trovare il primo titolo in una pagina:
title = soup.find("span", class_="title")
print(title.string)
findAll Il metodo viene utilizzato per trovare tutti gli elementi che soddisfano i criteri. Ad esempio, per trovare tutti i titoli in una pagina:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Il metodo consente di utilizzare i selettori CSS per trovare elementi. Ad esempio, per trovare tutti i titoli:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
poter usareattrs Proprietà Ottiene il dizionario degli attributi dell'elemento. Ad esempio, ottieni gli URL di tutte le immagini:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
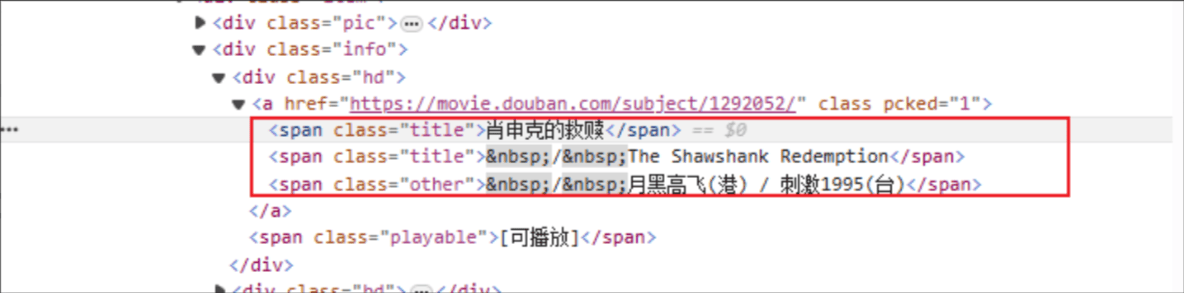
Titolo del film: il nome del tag HTML è: span e l'attributo di classe dell'elemento specificato è title.

Rating: il tag HTML è: span e l'attributo class dell'elemento specificato è rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
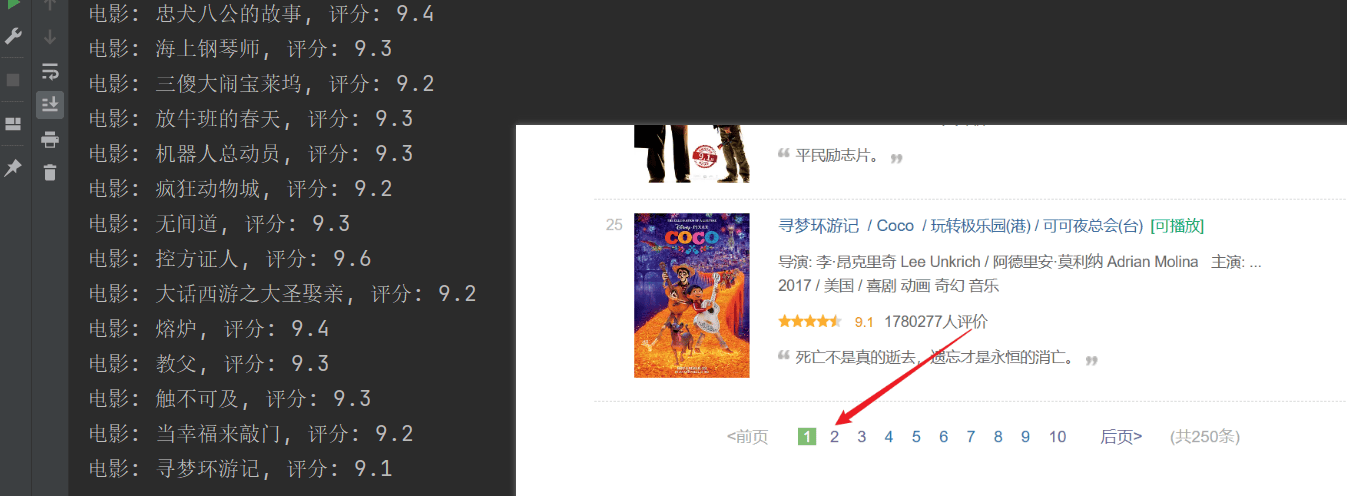
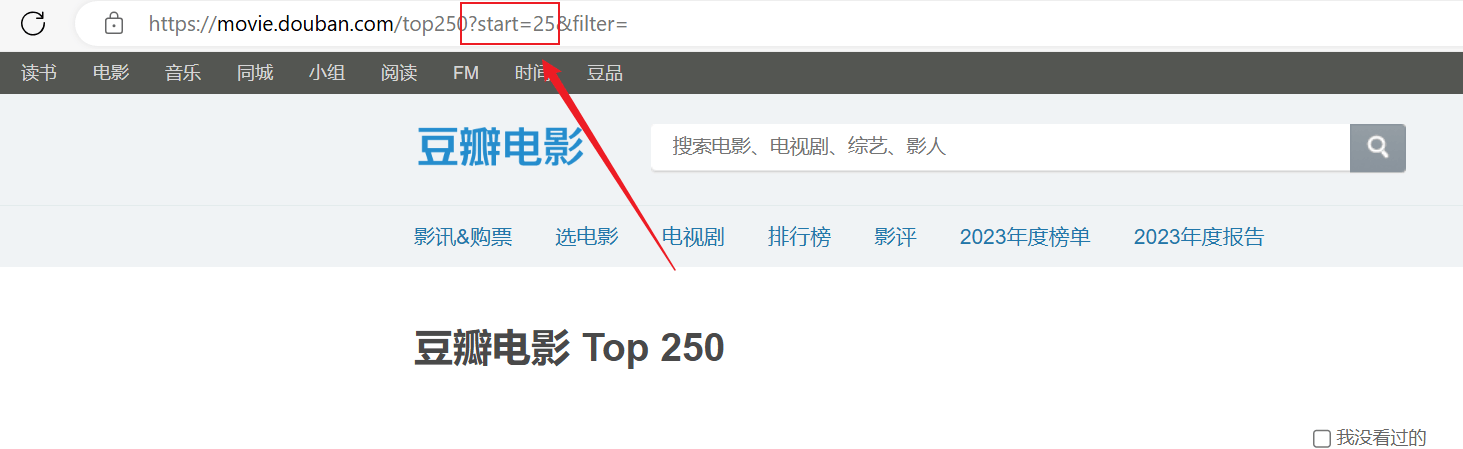
La scansione ha avuto esito positivo, ma è stata sottoposta a scansione solo la prima pagina e il contenuto successivo non è stato scansionato correttamente.Analizza la connessione URL sopra, ogni pagina passastartI parametri sono paginati.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]