
Mi información de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP es un protocolo cliente-servidor y las dos partes de la comunicación son el cliente y el servidor. El cliente envía una solicitud HTTP y el servidor recibe y procesa la solicitud y devuelve una respuesta HTTP.
Las solicitudes HTTP constan de líneas de solicitud, encabezados de solicitud, líneas en blanco y datos de solicitud (como datos de formulario en solicitudes POST).
Ejemplo de solicitud:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
línea de solicitud:POST /api/usuarios HTTP/1.1
Encabezado de solicitud: Contiene host, agente de usuario, aceptación, tipo de contenido, longitud del contenido, etc.
linea en blanco: Línea en blanco entre el encabezado de la solicitud y el cuerpo de la solicitud
Cuerpo de la solicitud:datos JSON
La respuesta HTTP consta de una línea de estado, encabezados de respuesta, líneas en blanco y datos de respuesta.
Suponiendo que el servidor devuelve una página HTML simple, la respuesta podría ser la siguiente:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
línea de estado:HTTP/1.1 200 OK
encabezado de respuesta: Contiene fecha, servidor, tipo de contenido, longitud del contenido, conexión, etc.
linea en blanco: Línea en blanco entre los encabezados de respuesta y el cuerpo de la respuesta
cuerpo de respuesta: Contiene código HTML
Los códigos de estado HTTP indican los resultados del procesamiento de la solicitud por parte del servidor. Los códigos de estado comunes incluyen:

La biblioteca de solicitudes de Python es una biblioteca HTTP muy potente y fácil de usar.
Antes de usarlo, debe instalar la biblioteca de Solicitudes:pip install requests
La solicitud GET se utiliza para solicitar datos del servidor. Realizar una solicitud GET usando la biblioteca de Solicitudes es muy simple:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
La solicitud POST se utiliza para enviar datos al servidor. Por ejemplo, los sitios web que requieren un inicio de sesión suelen utilizar solicitudes POST para enviar un nombre de usuario y contraseña. El método para utilizar la biblioteca de Solicitudes para iniciar una solicitud POST es el siguiente:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
En algunos sitios web (como Douban), el mecanismo anti-rastreo no está permitido para los rastreadores, y los encabezados y parámetros de las solicitudes HTTP deben configurarse para simular ser un navegador y pasar la autenticación.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
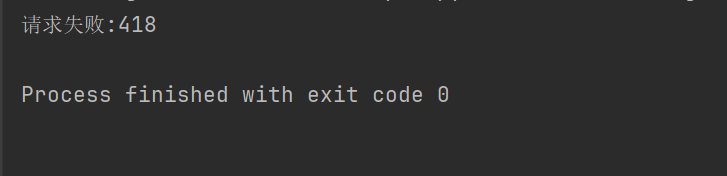
Por ejemplo, si el código anterior no establece el encabezado de la solicitud, Douban nos negará el acceso.
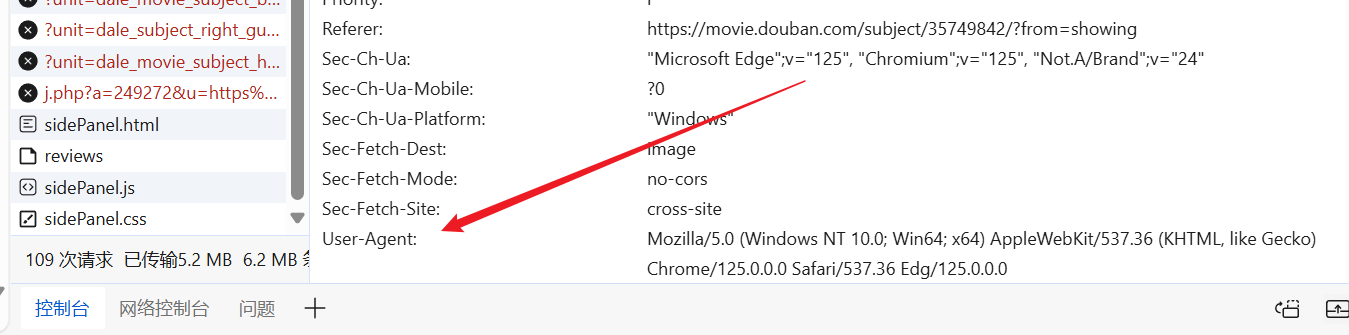
Podemos ingresar al sitio web a voluntad, encontrar un Agente de usuario ya preparado y colocarlo en el encabezado de nuestra solicitud.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
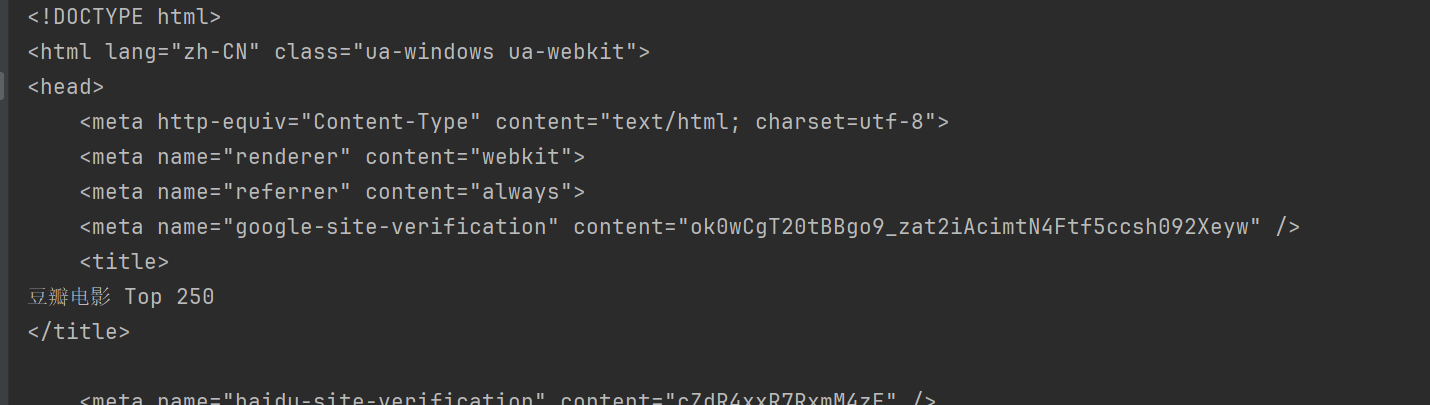
De esta forma podrás acceder a Douban y obtener el contenido de la página web.
BeautifulSoup es una biblioteca de Python para analizar documentos HTML y XML, especialmente para extraer datos de páginas web.
Antes de su uso, debe instalar la biblioteca BeautifulSoup:pip install beautifulsoup4
html.parser Es el analizador integrado de Python y es adecuado para la mayoría de escenarios. Tome Douban arriba como ejemplo.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup proporciona múltiples métodos para buscar y extraer datos de documentos HTML.
Métodos comunes de BeautifulSoup:
find(tag, attributes): busque la primera etiqueta que coincida con los criterios.find_all(tag, attributes): Encuentra todas las etiquetas coincidentes.select(css_selector): utilice selectores CSS para buscar etiquetas que coincidan con los criterios.get_text(): obtiene el contenido del texto dentro de la etiqueta.attrs: Obtiene el diccionario de atributos de la etiqueta.find El método se utiliza para encontrar el primer elemento que cumpla con los criterios. Por ejemplo, para buscar el primer título de una página:
title = soup.find("span", class_="title")
print(title.string)
findAll El método se utiliza para encontrar todos los elementos que cumplan los criterios. Por ejemplo, para buscar todos los títulos de una página:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select El método permite utilizar selectores CSS para buscar elementos. Por ejemplo, para buscar todos los títulos:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
puedo usarattrs Propiedades Obtiene el diccionario de atributos del elemento. Por ejemplo, obtenga las URL de todas las imágenes:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
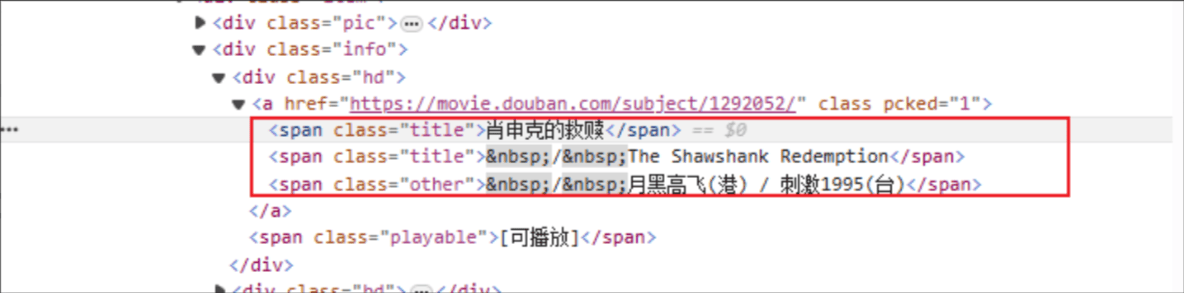
Título de la película: el nombre de la etiqueta HTML es: span y el atributo de clase del elemento especificado es el título.

Clasificación: la etiqueta HTML es: span y el atributo de clase del elemento especificado es rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
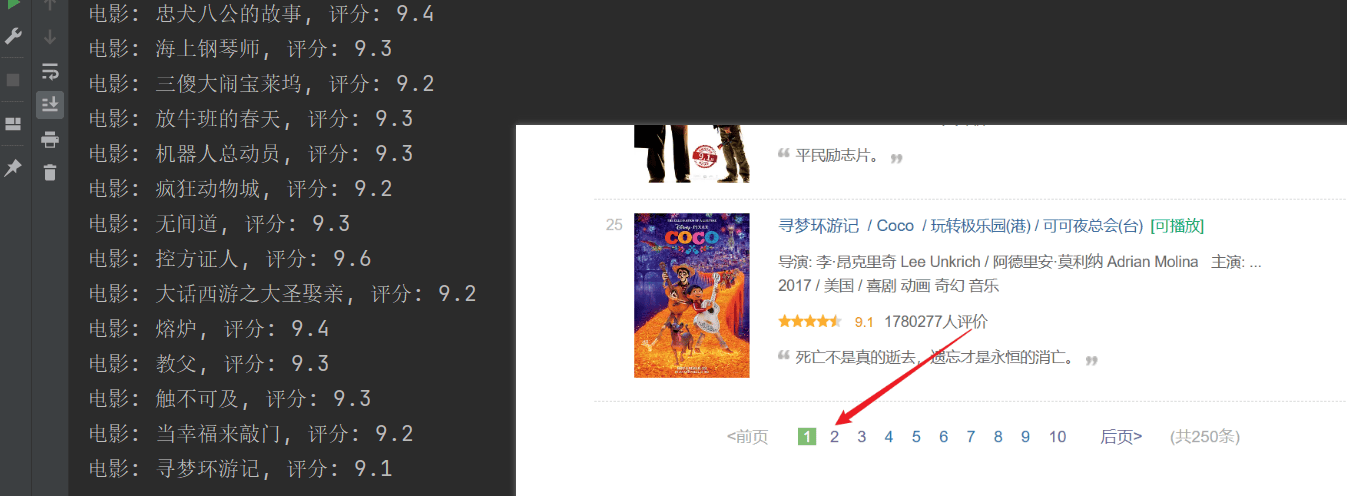
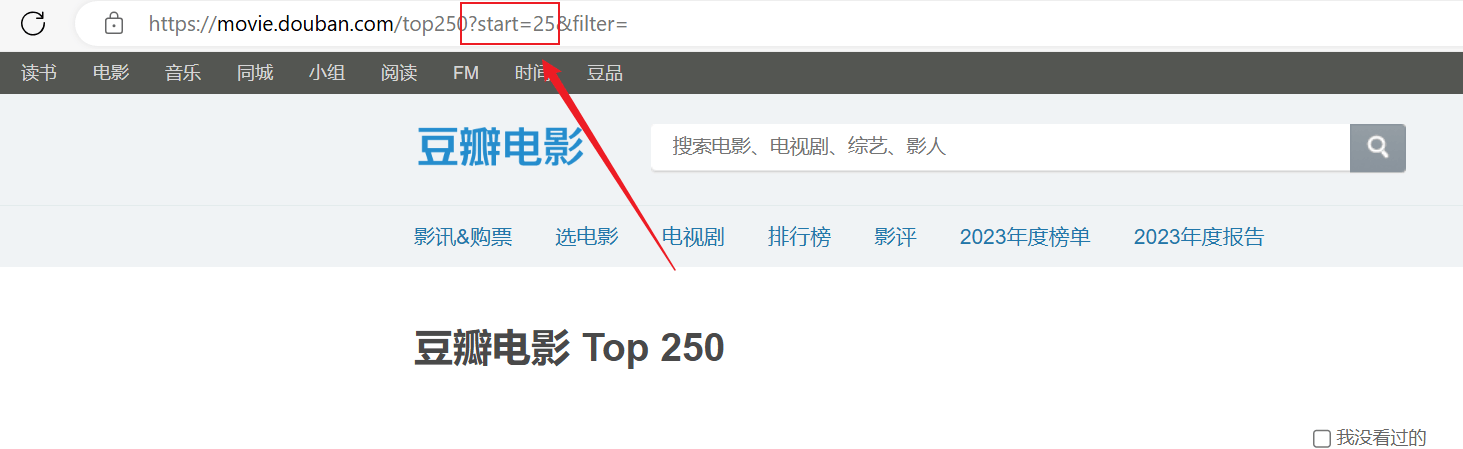
El rastreo se realizó correctamente, pero solo se rastreó la primera página y el contenido posterior no se rastreó correctamente.Analice la conexión de URL anterior, cada página pasa la URL en elstartLos parámetros están paginados.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]