2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP इति क्लायन्ट्-सर्वर-प्रोटोकॉलः, संचारस्य पक्षद्वयं च क्लायन्ट्-सर्वर-इत्येतत् । क्लायन्ट् HTTP अनुरोधं प्रेषयति, सर्वरः च अनुरोधं प्राप्य HTTP प्रतिक्रियां प्रत्यागच्छति ।
HTTP अनुरोधाः अनुरोधपङ्क्तयः, अनुरोधशीर्षकाः, रिक्तपङ्क्तयः, अनुरोधदत्तांशः (यथा POST अनुरोधेषु प्रपत्रदत्तांशः) च भवन्ति ।
उदाहरणं अनुरोधयन्तु : १.
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
अनुरोध रेखा:POST /api/उपयोक्तारः HTTP/1.1
अनुरोध शीर्षकम्: Host, User-Agent, Accept, Content-Type, Content-Length इत्यादयः सन्ति ।
रिक्तरेखा: अनुरोधशीर्षकस्य अनुरोधशरीरस्य च मध्ये रिक्तरेखा
निवेदन शरीर:JSON डेटा
HTTP प्रतिक्रियायां स्थितिरेखा, प्रतिक्रियाशीर्षकाणि, रिक्तरेखाः, प्रतिक्रियादत्तांशः च भवति ।
सर्वरः सरलं HTML पृष्ठं प्रत्यागच्छति इति कल्पयित्वा प्रतिक्रिया निम्नलिखितरूपेण भवितुम् अर्हति ।
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
स्थितिरेखा:HTTP/1.1 200 ठीकम्
प्रतिक्रिया शीर्षकम्: तिथिः, सर्वरः, सामग्री-प्रकारः, सामग्री-दीर्घता, संयोजनम् इत्यादयः सन्ति ।
रिक्तरेखा: प्रतिक्रियाशीर्षकाणां प्रतिक्रियाशरीरस्य च मध्ये रिक्तरेखा
प्रतिक्रिया शरीर: HTML कोडः अस्ति
HTTP स्थितिसङ्केताः अनुरोधस्य सर्वरस्य संसाधनपरिणामान् सूचयन्ति । सामान्यस्थितिसङ्केतेषु अन्तर्भवन्ति : १.

Python इत्यस्य Requests पुस्तकालयः अतीव शक्तिशाली अस्ति तथा च सुलभतया उपयोक्तुं HTTP पुस्तकालयः अस्ति ।
तस्य उपयोगात् पूर्वं भवद्भिः Requests पुस्तकालयं संस्थापनीयम् :pip install requests
सर्वरतः आँकडानां अनुरोधाय GET अनुरोधस्य उपयोगः भवति । Requests पुस्तकालयस्य उपयोगेन GET अनुरोधं करणं अतीव सरलम् अस्ति:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
सर्वरे दत्तांशं प्रस्तूय POST अनुरोधस्य उपयोगः भवति । यथा, येषु जालपुटेषु प्रवेशस्य आवश्यकता भवति, तेषु प्रायः उपयोक्तृनाम गुप्तशब्दं च प्रस्तूय POST अनुरोधानाम् उपयोगः भवति । POST अनुरोधं आरभ्य Requests पुस्तकालयस्य उपयोगस्य विधिः निम्नलिखितरूपेण अस्ति ।
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
केषुचित् वेबसाइट्-स्थानेषु (यथा Douban) क्रॉल-विरोधी-तन्त्रस्य अनुमतिः नास्ति, तथा च HTTP-अनुरोध-शीर्षकाणि, मापदण्डानि च ब्राउजर्-रूपेण अभिनयं कर्तुं, प्रमाणीकरणं च पारयितुं सेट् कर्तुं आवश्यकाः सन्ति
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
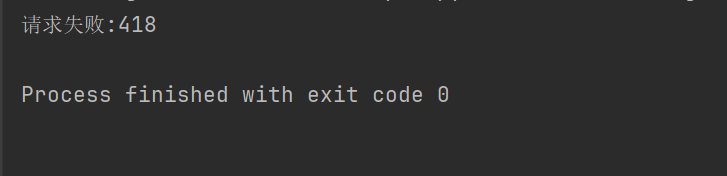
यथा, यदि उपरिष्टात् कोडः अनुरोधशीर्षकं न सेट् करोति तर्हि Douban अस्मान् प्रवेशं नकारयिष्यति ।
वयं इच्छानुसारं जालपुटे प्रविश्य, सज्जं User-Agent अन्वेष्टुं, अस्माकं अनुरोधशीर्षके स्थापयितुं च शक्नुमः ।
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
एवं प्रकारेण भवान् Douban -नगरं गत्वा जालपुटस्य सामग्रीं प्राप्तुं शक्नोति ।
BeautifulSoup HTML तथा XML दस्तावेजानां विश्लेषणार्थं विशेषतः जालपुटेभ्यः आँकडान् निष्कासयितुं Python पुस्तकालयः अस्ति ।
उपयोगात् पूर्वं भवद्भिः BeautifulSoup पुस्तकालयं संस्थापनीयम्:pip install beautifulsoup4
html.parser इदं पायथन् इत्यस्य अन्तःनिर्मितं पार्सर् अस्ति तथा च अधिकांशपरिदृश्यानां कृते उपयुक्तम् अस्ति । उपरि डौबन् उदाहरणरूपेण गृह्यताम्।
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup HTML दस्तावेजेभ्यः आँकडान् अन्वेष्टुं निष्कासयितुं च बहुविधाः पद्धतयः प्रदाति ।
BeautifulSoup सामान्यविधयः : १.
find(tag, attributes): प्रथमं टैग् अन्वेष्टुम् यत् मापदण्डेन सह मेलति।find_all(tag, attributes): सर्वाणि मेलयुक्तानि टैग्स् अन्वेष्टुम्।select(css_selector): मापदण्डेन सह मेलनं कुर्वन्ति टैग् अन्वेष्टुं CSS चयनकर्तानां उपयोगं कुर्वन्तु ।get_text(): लेबलस्य अन्तः पाठसामग्री प्राप्नुवन्तु।attrs: टैगस्य विशेषताकोशं प्राप्नुवन्तु।find प्रथमं तत्त्वं अन्वेष्टुं विधिः उपयुज्यते यत् मापदण्डं पूरयति । यथा पृष्ठे प्रथमं शीर्षकं अन्वेष्टुं :
title = soup.find("span", class_="title")
print(title.string)
findAll मापदण्डं पूरयन्तः सर्वे तत्त्वानि अन्वेष्टुं विधिः उपयुज्यते । यथा, पृष्ठे सर्वाणि शीर्षकाणि अन्वेष्टुं :
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select विधिः तत्त्वान् अन्वेष्टुं CSS चयनकर्तानां उपयोगं कर्तुं शक्नोति । यथा सर्वाणि शीर्षकाणि अन्वेष्टुं : १.
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
उपयोक्तुं शक्नोतिattrs गुणाः तत्त्वस्य विशेषताकोशं प्राप्नोति । यथा, सर्वेषां चित्राणां URLs प्राप्नुवन्तु :
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
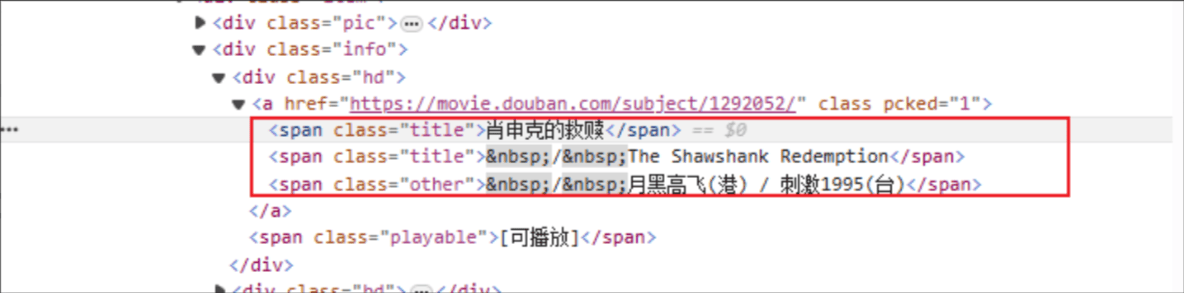
चलचित्रस्य शीर्षकम्: HTML टैग् नाम: span, निर्दिष्टस्य तत्त्वस्य वर्गविशेषणं च शीर्षकम् अस्ति ।

रेटिंग्: HTML टैग् अस्ति: span, तथा च निर्दिष्टस्य तत्त्वस्य क्लास् एट्रिब्यूट् rating_num अस्ति
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
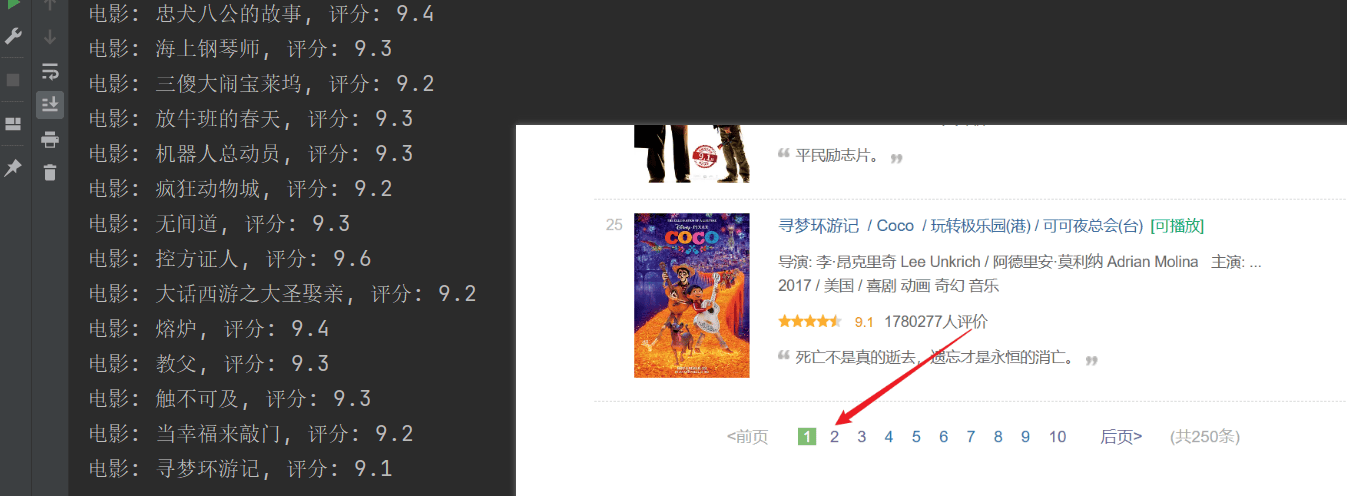
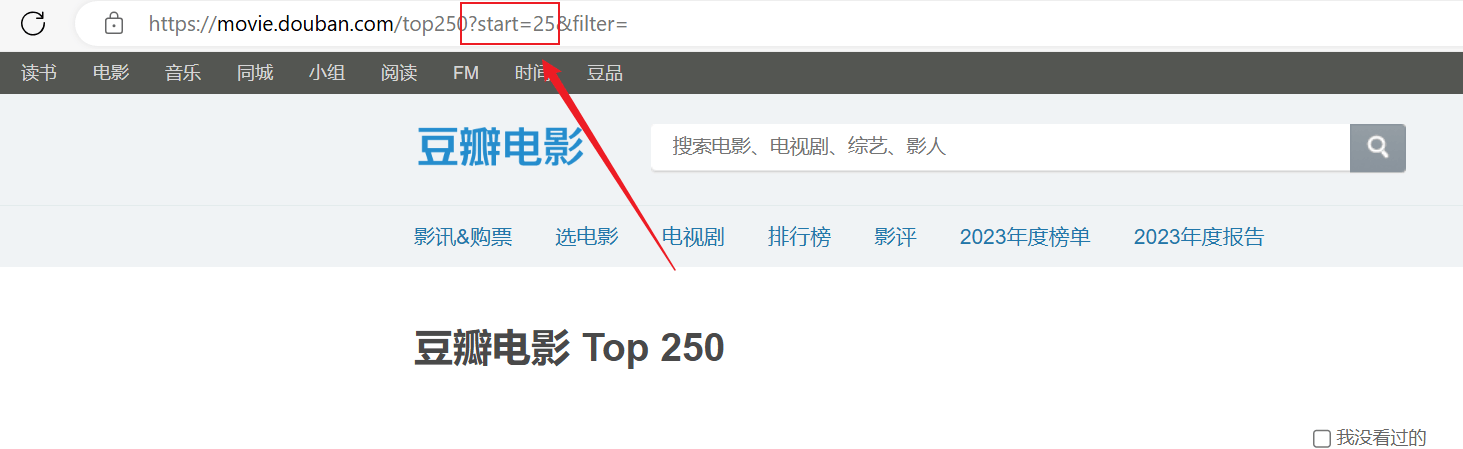
क्रॉलिंग् सफलम् अभवत्, परन्तु केवलं प्रथमं पृष्ठं क्रौल् कृतम्, तदनन्तरं सामग्री सफलतया क्रॉल न अभवत् ।उपरिष्टाद् url संयोजनं विश्लेषयन्तु, प्रत्येकं पृष्ठं URL मध्ये पारयतिstartमापदण्डाः पृष्ठीकृताः सन्ति ।
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

सः ३० वर्षाणाम् अनुसरणं प्रौयोगिक क्रमबद्धता युक्तं, आलंकार, जावा, जावास्विस्च, ph, css, सद्भावना संस्कृती, ph, css निर्वहनशील भाषा सुनावंश, ससरोत विद्वान विपक्षी विद्वान विनियोग विनियोग विनियोग विनियोग्य विवेचन विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग विनियोग

