2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP est un protocole client-serveur et les deux parties de communication sont le client et le serveur. Le client envoie une requête HTTP, le serveur reçoit et traite la requête et renvoie une réponse HTTP.
Les requêtes HTTP se composent de lignes de requête, d'en-têtes de requête, de lignes vides et de données de requête (telles que les données de formulaire dans les requêtes POST).
Exemple de demande :
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
ligne de demande:POST /api/utilisateurs HTTP/1.1
En-tête de requête: Contient l'hôte, l'agent utilisateur, l'acceptation, le type de contenu, la longueur du contenu, etc.
ligne blanche: Ligne vide entre l'en-tête de la requête et le corps de la requête
Corps de la demande:Données JSON
La réponse HTTP comprend une ligne d'état, des en-têtes de réponse, des lignes vides et des données de réponse.
En supposant que le serveur renvoie une simple page HTML, la réponse pourrait être la suivante :
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
ligne d'état:HTTP/1.1 200 OK
en-tête de réponse: Contient la date, le serveur, le type de contenu, la longueur du contenu, la connexion, etc.
ligne blanche: Ligne vide entre les en-têtes de réponse et le corps de la réponse
corps de réponse: Contient du code HTML
Les codes d'état HTTP indiquent les résultats du traitement de la demande par le serveur. Les codes d'état courants incluent :

La bibliothèque Requests de Python est une bibliothèque HTTP très puissante et facile à utiliser.
Avant de l'utiliser, vous devez installer la bibliothèque Requests :pip install requests
La requête GET est utilisée pour demander des données au serveur. Faire une requête GET à l’aide de la bibliothèque Requests est très simple :
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
La requête POST est utilisée pour soumettre des données au serveur. Par exemple, les sites Web qui nécessitent une connexion utilisent souvent des requêtes POST pour soumettre un nom d'utilisateur et un mot de passe. La méthode d'utilisation de la bibliothèque Requests pour lancer une requête POST est la suivante :
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Sur certains sites Web (tels que Douban), le mécanisme anti-exploration n'est pas autorisé pour les robots d'exploration, et les en-têtes et paramètres de requête HTTP doivent être définis pour prétendre être un navigateur et réussir l'authentification.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
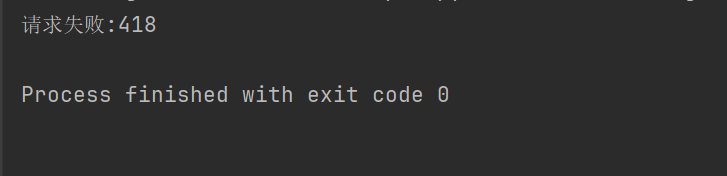
Par exemple, si le code ci-dessus ne définit pas l'en-tête de la requête, Douban nous refusera l'accès.
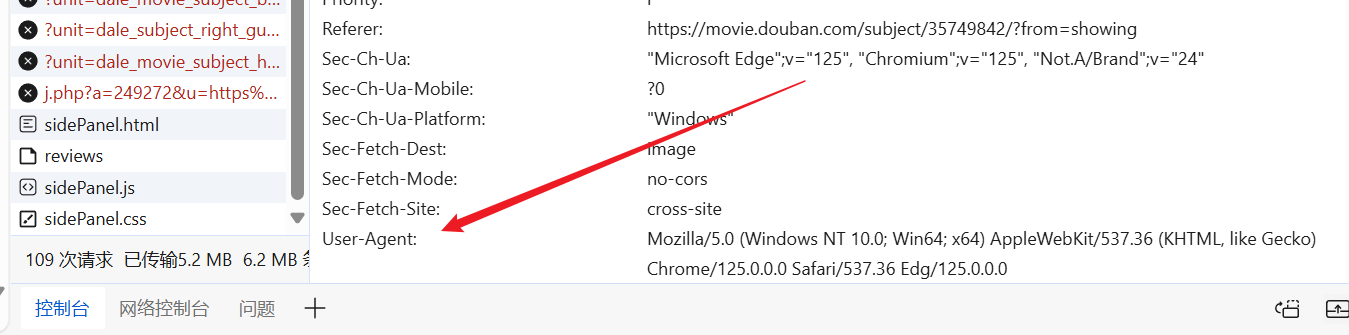
Nous pouvons accéder au site Web à volonté, trouver un agent utilisateur prêt à l'emploi et le mettre dans l'en-tête de notre demande.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
De cette façon, vous pouvez accéder à Douban et obtenir le contenu de la page Web.
BeautifulSoup est une bibliothèque Python permettant d'analyser des documents HTML et XML, notamment pour extraire des données de pages Web.
Avant utilisation, vous devez installer la bibliothèque BeautifulSoup :pip install beautifulsoup4
html.parser Il s'agit de l'analyseur intégré de Python et convient à la plupart des scénarios. Prenons Douban ci-dessus comme exemple.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup propose plusieurs méthodes pour rechercher et extraire des données à partir de documents HTML.
Méthodes courantes de BeautifulSoup :
find(tag, attributes): Recherchez la première balise qui correspond aux critères.find_all(tag, attributes) : Trouver toutes les balises correspondantes.select(css_selector): utilisez les sélecteurs CSS pour trouver les balises qui correspondent aux critères.get_text(): Obtenez le contenu du texte dans l'étiquette.attrs: Récupère le dictionnaire d'attributs de la balise.find La méthode est utilisée pour trouver le premier élément qui répond aux critères. Par exemple, pour rechercher le premier titre d'une page :
title = soup.find("span", class_="title")
print(title.string)
findAll La méthode est utilisée pour trouver tous les éléments qui répondent aux critères. Par exemple, pour rechercher tous les titres d'une page :
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select La méthode permet d'utiliser des sélecteurs CSS pour rechercher des éléments. Par exemple, pour rechercher tous les titres :
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
peut utiliserattrs Propriétés Obtient le dictionnaire d'attributs de l'élément. Par exemple, obtenez les URL de toutes les images :
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
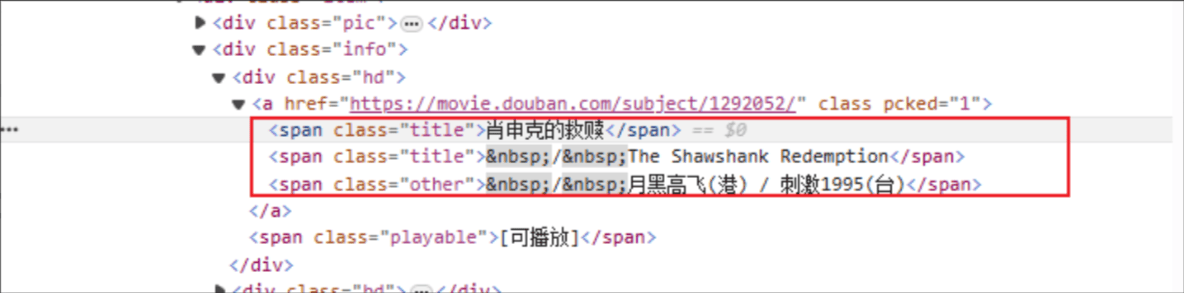
Titre du film : le nom de la balise HTML est : span et l'attribut de classe de l'élément spécifié est title.

Évaluation : la balise HTML est : span et l'attribut de classe de l'élément spécifié est rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
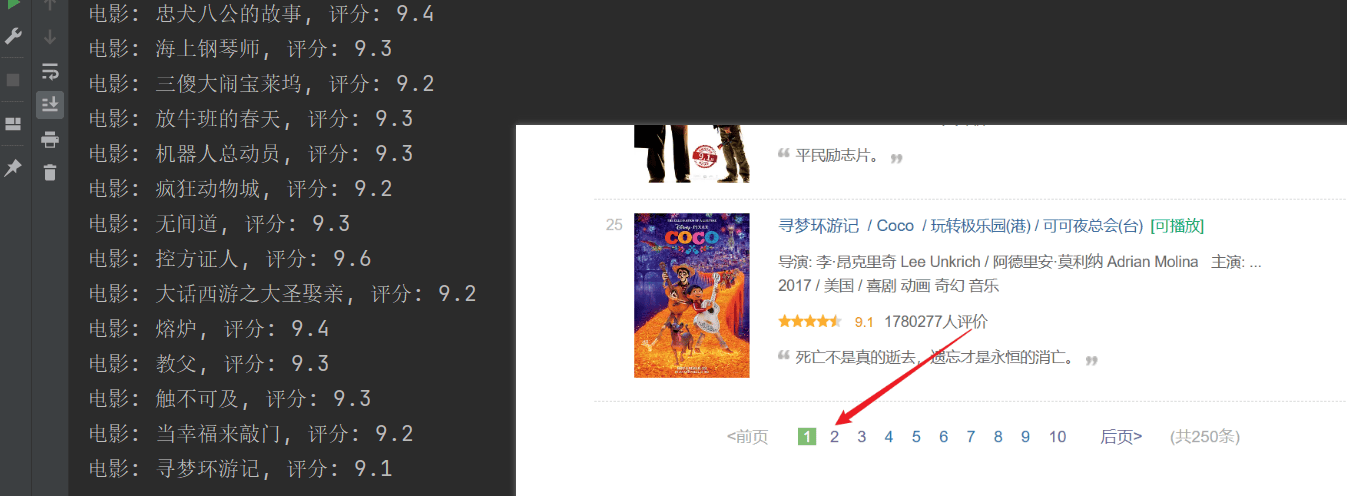
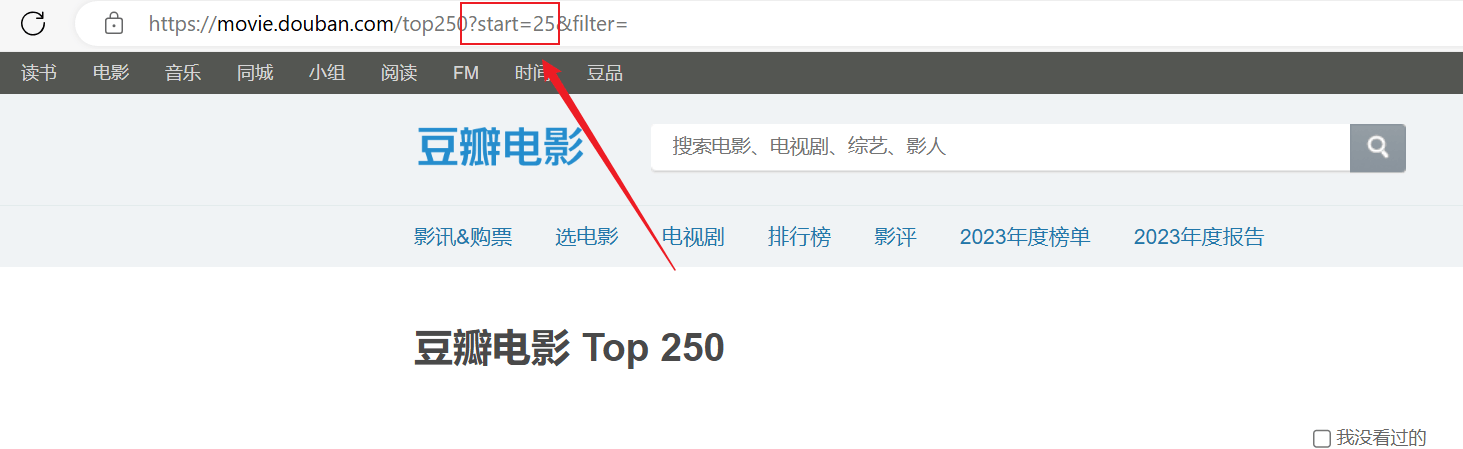
L'analyse a réussi, mais seule la première page a été analysée et le contenu suivant n'a pas été analysé correctement.Analysez la connexion URL ci-dessus, chaque page transmet l'URL dans lestartLes paramètres sont paginés.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

