
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP はクライアント/サーバー プロトコルであり、通信の 2 つの当事者はクライアントとサーバーです。クライアントは HTTP リクエストを送信し、サーバーはそのリクエストを受信して処理し、HTTP 応答を返します。
HTTP リクエストは、リクエスト行、リクエスト ヘッダー、空行、およびリクエスト データ (POST リクエストのフォーム データなど) で構成されます。
リクエスト例:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
リクエストライン:POST /api/users HTTP/1.1
リクエストヘッダー: Host、User-Agent、Accept、Content-Type、Content-Length などが含まれます。
空行: リクエストヘッダーとリクエストボディの間の空行
リクエストボディ:JSONデータ
HTTP 応答は、ステータス行、応答ヘッダー、空行、応答データで構成されます。
サーバーが単純な HTML ページを返すと仮定すると、応答は次のようになります。
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
ステータスライン:HTTP/1.1 200 OK
応答ヘッダー: 日付、サーバー、コンテンツ タイプ、コンテンツの長さ、接続などが含まれます。
空行: レスポンスヘッダーとレスポンスボディの間の空行
レスポンスボディ: HTMLコードが含まれています
HTTP ステータス コードは、サーバーによるリクエストの処理結果を示します。一般的なステータス コードは次のとおりです。

Python の Requests ライブラリは、非常に強力で使いやすい HTTP ライブラリです。
使用する前に、Requests ライブラリをインストールする必要があります。pip install requests
GET リクエストは、サーバーにデータをリクエストするために使用されます。 Requests ライブラリを使用して GET リクエストを作成するのは非常に簡単です。
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
POST リクエストは、サーバーにデータを送信するために使用されます。たとえば、ログインが必要な Web サイトでは、多くの場合、POST リクエストを使用してユーザー名とパスワードを送信します。 Requests ライブラリを使用して POST リクエストを開始する方法は次のとおりです。
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
一部の Web サイト (Douban など) では、クローラーに対してクロール防止メカニズムが許可されていないため、ブラウザーのふりをして認証を通過するには、HTTP 要求ヘッダーとパラメーターを設定する必要があります。
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
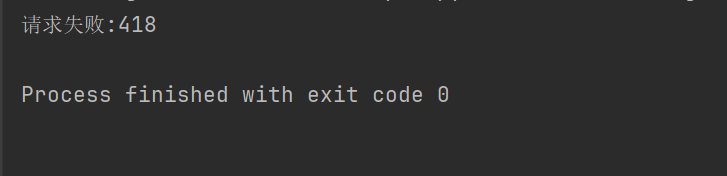
たとえば、上記のコードでリクエスト ヘッダーが設定されていない場合、Douban はアクセスを拒否します。
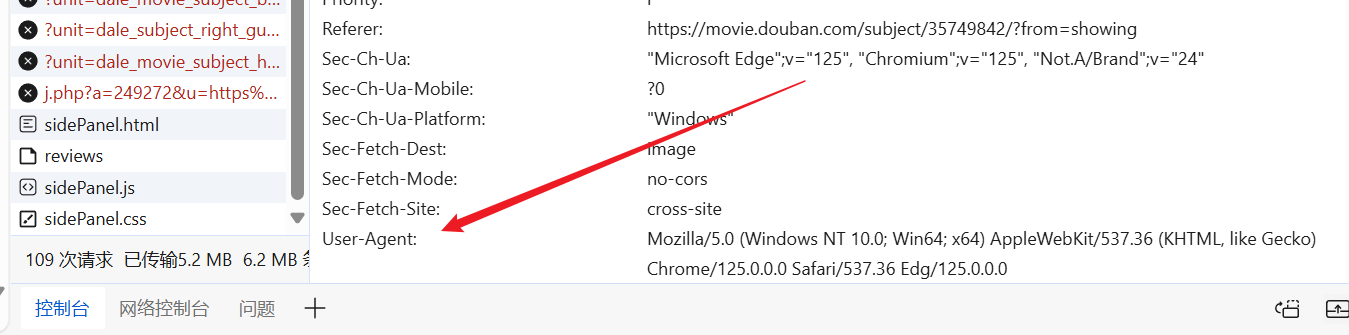
自由に Web サイトに入り、既製のユーザー エージェントを見つけて、それをリクエスト ヘッダーに含めることができます。
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
このようにして、Douban にアクセスし、Web ページのコンテンツを取得できます。
BeautifulSoup は、HTML および XML ドキュメントを解析するため、特に Web ページからデータを抽出するための Python ライブラリです。
使用する前に、BeautifulSoup ライブラリをインストールする必要があります。pip install beautifulsoup4
html.parserこれは Python の組み込みパーサーであり、ほとんどのシナリオに適しています。上記の Douban を例に挙げます。
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup は、HTML ドキュメントからデータを検索して抽出するための複数の方法を提供します。
BeautifulSoup の一般的なメソッド:
find(tag, attributes): 条件に一致する最初のタグを検索します。find_all(tag, attributes): 一致するタグをすべて検索します。select(css_selector): CSS セレクターを使用して、条件に一致するタグを検索します。get_text(): ラベル内のテキスト コンテンツを取得します。attrs: タグの属性辞書を取得します。findメソッドは、基準を満たす最初の要素を見つけるために使用されます。たとえば、ページ内の最初のタイトルを検索するには、次のようにします。
title = soup.find("span", class_="title")
print(title.string)
findAllメソッドは、基準を満たすすべての要素を検索するために使用されます。たとえば、ページ内のすべてのタイトルを検索するには:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
selectこのメソッドでは、CSS セレクターを使用して要素を検索できます。たとえば、すべてのタイトルを検索するには:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
使えるattrsプロパティ 要素の属性辞書を取得します。たとえば、すべての画像の URL を取得します。
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
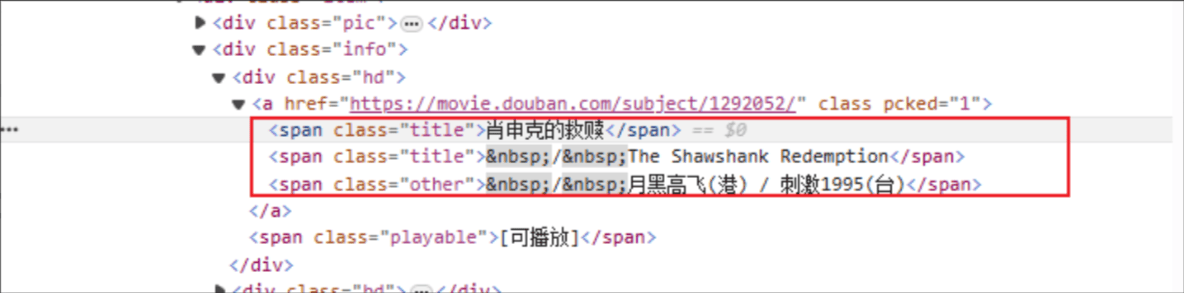
映画のタイトル: HTML タグ名は「span」、指定された要素の class 属性は「title」です。

Rating: HTML タグはspan、指定された要素の class 属性は Rating_num です。
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
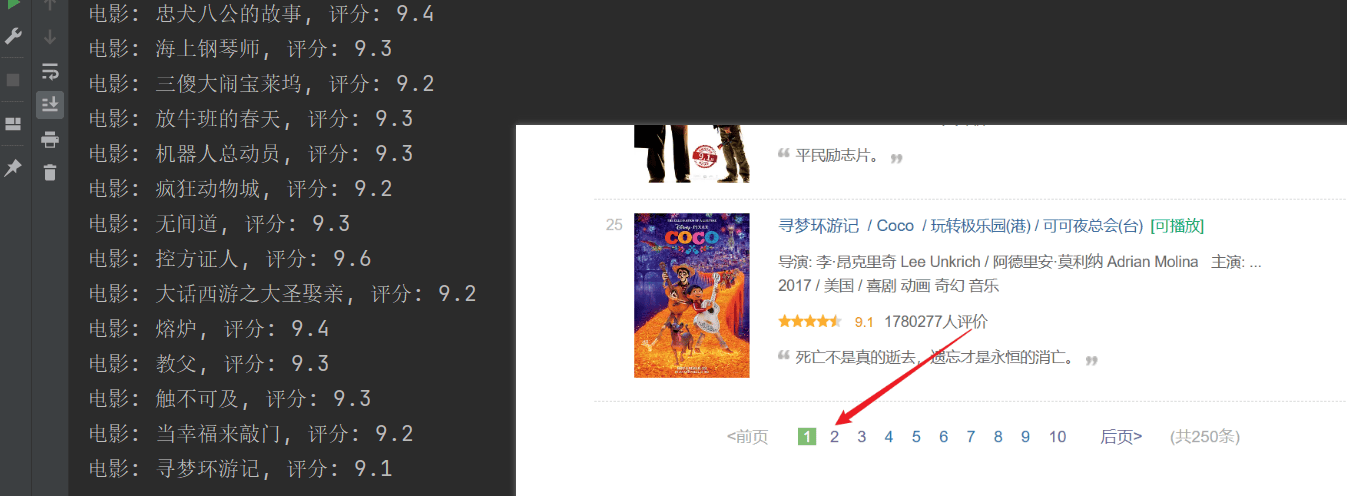
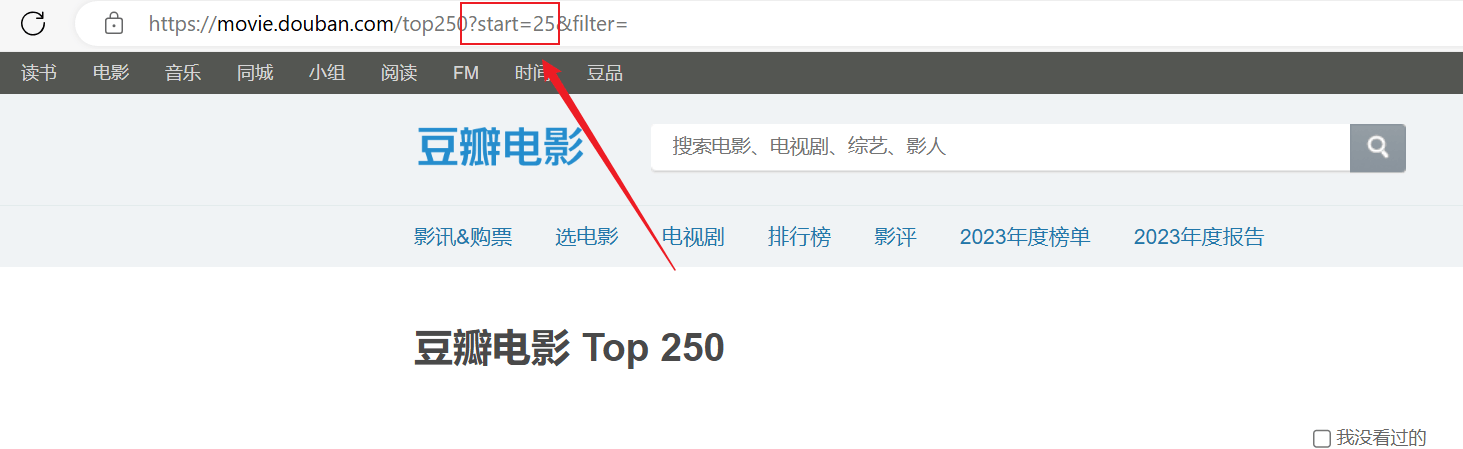
クロールは成功しましたが、最初のページのみがクロールされ、それ以降のコンテンツは正常にクロールされませんでした。上記の URL 接続を分析し、各ページは URL をstartパラメータはページングされます。
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: