
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP는 클라이언트-서버 프로토콜이며 통신의 두 당사자는 클라이언트와 서버입니다. 클라이언트는 HTTP 요청을 보내고, 서버는 요청을 수신 및 처리하고 HTTP 응답을 반환합니다.
HTTP 요청은 요청 라인, 요청 헤더, 빈 라인, 요청 데이터(예: POST 요청의 양식 데이터)로 구성됩니다.
요청 예시:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
요청 라인:POST /api/users HTTP/1.1
요청 헤더: Host, User-Agent, Accept, Content-Type, Content-Length 등을 포함합니다.
빈 줄: 요청 헤더와 요청 본문 사이에 빈 줄이 있습니다.
요청 본문:JSON 데이터
HTTP 응답은 상태 줄, 응답 헤더, 빈 줄 및 응답 데이터로 구성됩니다.
서버가 간단한 HTML 페이지를 반환한다고 가정하면 응답은 다음과 같을 수 있습니다.
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
상태 표시줄:HTTP/1.1 200 확인
응답 헤더: 날짜, 서버, 콘텐츠 유형, 콘텐츠 길이, 연결 등이 포함됩니다.
빈 줄: 응답 헤더와 응답 본문 사이에 빈 줄이 있습니다.
응답 본문: HTML 코드가 포함되어 있습니다.
HTTP 상태 코드는 서버의 요청 처리 결과를 나타냅니다. 일반적인 상태 코드는 다음과 같습니다.

Python의 요청 라이브러리는 매우 강력하고 사용하기 쉬운 HTTP 라이브러리입니다.
사용하기 전에 Requests 라이브러리를 설치해야 합니다.pip install requests
GET 요청은 서버에 데이터를 요청하는 데 사용됩니다. Requests 라이브러리를 사용하여 GET 요청을 하는 것은 매우 간단합니다.
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
POST 요청은 서버에 데이터를 제출하는 데 사용됩니다. 예를 들어 로그인이 필요한 웹사이트에서는 POST 요청을 사용하여 사용자 이름과 비밀번호를 제출하는 경우가 많습니다. 요청 라이브러리를 사용하여 POST 요청을 시작하는 방법은 다음과 같습니다.
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
일부 웹사이트(예: Douban)에서는 크롤러에 대한 크롤링 방지 메커니즘이 허용되지 않으며 HTTP 요청 헤더와 매개변수는 브라우저인 것처럼 가장하고 인증을 통과하도록 설정되어야 합니다.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
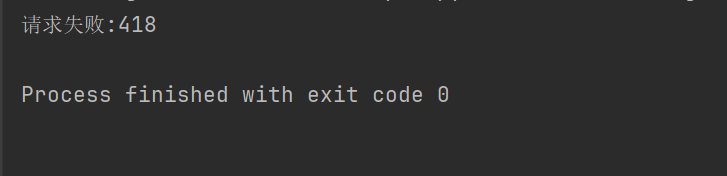
예를 들어 위 코드가 요청 헤더를 설정하지 않으면 Douban은 우리의 액세스를 거부합니다.
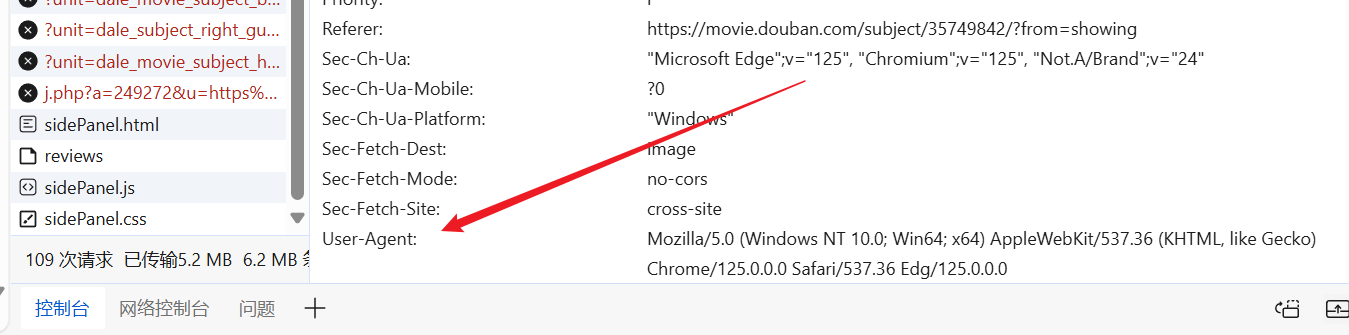
우리는 마음대로 웹사이트에 들어갈 수 있고, 미리 만들어진 User-Agent를 찾아 요청 헤더에 넣을 수 있습니다.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
이러한 방식으로 Douban에 액세스하고 웹페이지의 콘텐츠를 얻을 수 있습니다.
BeautifulSoup은 특히 웹 페이지에서 데이터를 추출하기 위해 HTML 및 XML 문서를 구문 분석하기 위한 Python 라이브러리입니다.
사용하기 전에 BeautifulSoup 라이브러리를 설치해야 합니다.pip install beautifulsoup4
html.parser Python의 내장 파서이며 대부분의 시나리오에 적합합니다. 위의 Douban을 예로 들어 보겠습니다.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup은 HTML 문서에서 데이터를 찾고 추출하는 다양한 방법을 제공합니다.
BeautifulSoup 일반적인 방법:
find(tag, attributes): 기준에 맞는 첫 번째 태그를 찾습니다.find_all(tag, attributes): 일치하는 태그를 모두 찾습니다.select(css_selector): CSS 선택기를 사용하여 기준과 일치하는 태그를 찾습니다.get_text(): 라벨 내의 텍스트 내용을 가져옵니다.attrs: 태그의 속성 사전을 가져옵니다.find 방법은 기준을 충족하는 첫 번째 요소를 찾는 데 사용됩니다. 예를 들어 페이지에서 첫 번째 제목을 찾으려면 다음을 수행하세요.
title = soup.find("span", class_="title")
print(title.string)
findAll 방법은 기준을 충족하는 모든 요소를 찾는 데 사용됩니다. 예를 들어 페이지의 모든 제목을 찾으려면 다음을 수행하세요.
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select 메서드를 사용하면 CSS 선택기를 사용하여 요소를 찾을 수 있습니다. 예를 들어 모든 제목을 찾으려면 다음을 수행하세요.
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
사용할 수 있다attrs 속성 요소의 속성 사전을 가져옵니다. 예를 들어 모든 이미지의 URL을 가져옵니다.
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
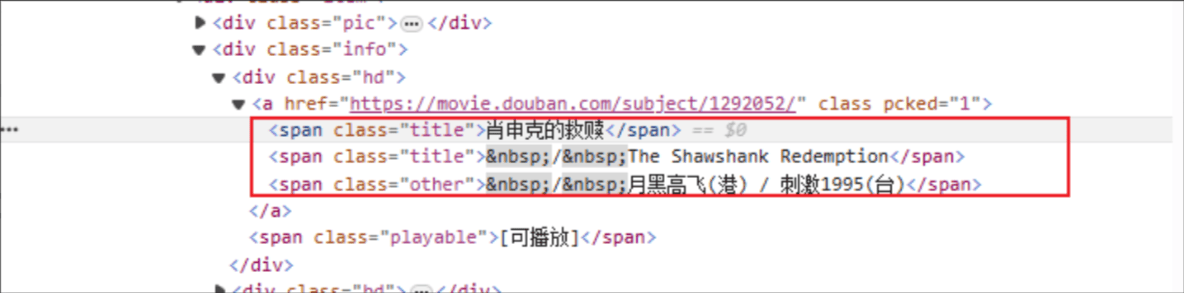
영화 제목: HTML 태그 이름은 범위이며, 지정된 요소의 클래스 속성은 제목입니다.

등급: HTML 태그는 범위이며, 지정된 요소의 클래스 속성은 rating_num입니다.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
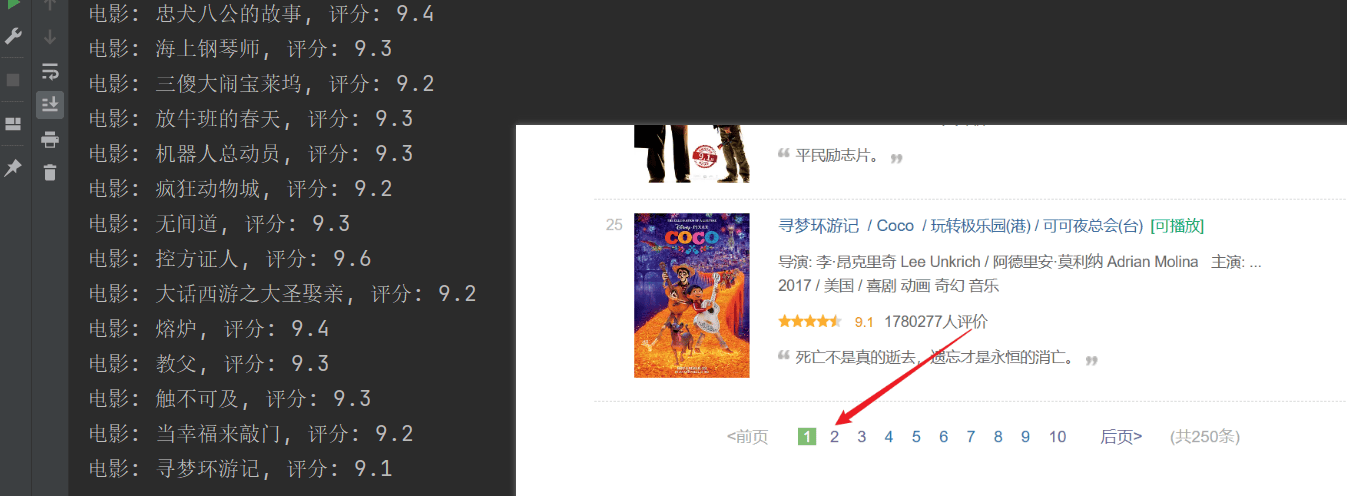
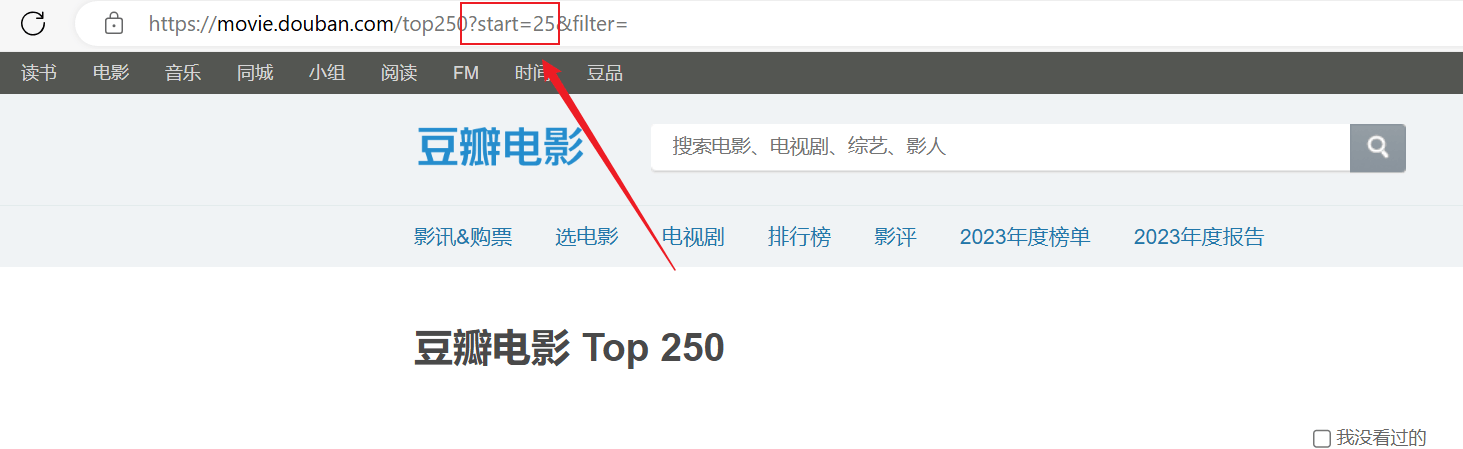
크롤링에 성공했지만 첫 번째 페이지만 크롤링되었으며 이후 콘텐츠는 성공적으로 크롤링되지 않았습니다.위의 URL 연결을 분석하면 각 페이지는start매개변수가 페이징됩니다.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com