
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Το HTTP είναι ένα πρωτόκολλο πελάτη-διακομιστή και τα δύο μέρη επικοινωνίας είναι ο πελάτης και ο διακομιστής. Ο πελάτης στέλνει ένα αίτημα HTTP και ο διακομιστής λαμβάνει και επεξεργάζεται το αίτημα και επιστρέφει μια απάντηση HTTP.
Τα αιτήματα HTTP αποτελούνται από γραμμές αιτημάτων, κεφαλίδες αιτημάτων, κενές γραμμές και δεδομένα αιτημάτων (όπως δεδομένα φόρμας σε αιτήματα POST).
Παράδειγμα αιτήματος:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
γραμμή αιτήματος:POST /api/χρήστες HTTP/1.1
Κεφαλίδα αιτήματος: Περιέχει Host, User-Agent, Accept, Content-Type, Content-Length, κ.λπ.
κενή γραμμή: Κενή γραμμή μεταξύ της κεφαλίδας αιτήματος και του σώματος αιτήματος
Σώμα αιτήματος:Δεδομένα JSON
Η απόκριση HTTP αποτελείται από γραμμή κατάστασης, κεφαλίδες απόκρισης, κενές γραμμές και δεδομένα απόκρισης.
Υποθέτοντας ότι ο διακομιστής επιστρέφει μια απλή σελίδα HTML, η απάντηση μπορεί να είναι η εξής:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
γραμμή κατάστασης:HTTP/1.1 200 OK
κεφαλίδα απάντησης: Περιέχει ημερομηνία, διακομιστή, τύπο περιεχομένου, μήκος περιεχομένου, σύνδεση κ.λπ.
κενή γραμμή: Κενή γραμμή μεταξύ των κεφαλίδων απόκρισης και του σώματος απόκρισης
σώμα απάντησης: Περιέχει κώδικα HTML
Οι κωδικοί κατάστασης HTTP υποδεικνύουν τα αποτελέσματα επεξεργασίας του αιτήματος από τον διακομιστή. Οι κοινοί κωδικοί κατάστασης περιλαμβάνουν:

Η βιβλιοθήκη αιτημάτων της Python είναι μια πολύ ισχυρή και εύχρηστη βιβλιοθήκη HTTP.
Πριν το χρησιμοποιήσετε, πρέπει να εγκαταστήσετε τη βιβλιοθήκη αιτημάτων:pip install requests
Το αίτημα GET χρησιμοποιείται για να ζητήσει δεδομένα από τον διακομιστή. Η υποβολή αιτήματος GET χρησιμοποιώντας τη βιβλιοθήκη αιτημάτων είναι πολύ απλή:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Το αίτημα POST χρησιμοποιείται για την υποβολή δεδομένων στον διακομιστή. Για παράδειγμα, οι ιστότοποι που απαιτούν σύνδεση χρησιμοποιούν συχνά αιτήματα POST για να υποβάλουν ένα όνομα χρήστη και έναν κωδικό πρόσβασης. Η μέθοδος χρήσης της βιβλιοθήκης αιτημάτων για την εκκίνηση ενός αιτήματος POST είναι η εξής:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Σε ορισμένους ιστότοπους (όπως το Douban), για να αποτρέψετε τα προγράμματα ανίχνευσης να έχουν μηχανισμό κατά της ανίχνευσης, πρέπει να ορίσετε κεφαλίδες και παραμέτρους αιτημάτων HTTP ώστε να προσποιούνται ότι είναι πρόγραμμα περιήγησης και να περάσετε τον έλεγχο ταυτότητας.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
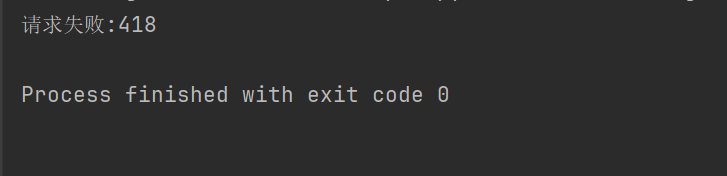
Για παράδειγμα, εάν ο παραπάνω κωδικός δεν ορίζει την κεφαλίδα του αιτήματος, το Douban θα μας αρνηθεί την πρόσβαση.
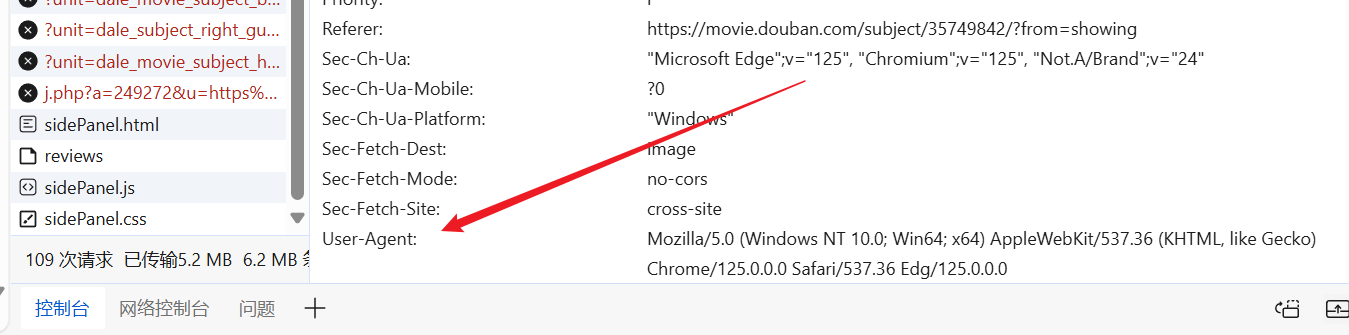
Μπορούμε να μπούμε στον ιστότοπο κατά βούληση, να βρούμε έναν έτοιμο παράγοντα χρήστη και να τον βάλουμε στην κεφαλίδα του αιτήματός μας.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
Με αυτόν τον τρόπο, μπορείτε να αποκτήσετε πρόσβαση στο Douban και να αποκτήσετε το περιεχόμενο της ιστοσελίδας.
Το BeautifulSoup είναι μια βιβλιοθήκη Python για την ανάλυση εγγράφων HTML και XML, ειδικά για την εξαγωγή δεδομένων από ιστοσελίδες.
Πριν από τη χρήση, πρέπει να εγκαταστήσετε τη βιβλιοθήκη BeautifulSoup:pip install beautifulsoup4
html.parser Είναι ο ενσωματωμένος αναλυτής της Python και είναι κατάλληλος για τα περισσότερα σενάρια. Πάρτε το Douban παραπάνω ως παράδειγμα.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
Το BeautifulSoup παρέχει πολλαπλές μεθόδους εύρεσης και εξαγωγής δεδομένων από έγγραφα HTML.
Κοινή μέθοδοι BeautifulSoup:
find(tag, attributes): Βρείτε την πρώτη ετικέτα που ταιριάζει με τα κριτήρια.find_all(tag, attributes): Βρείτε όλες τις ετικέτες που ταιριάζουν.select(css_selector): Χρησιμοποιήστε επιλογείς CSS για να βρείτε ετικέτες που ταιριάζουν με τα κριτήρια.get_text(): Λάβετε το περιεχόμενο κειμένου μέσα στην ετικέτα.attrs: Λάβετε το λεξικό χαρακτηριστικών της ετικέτας.find Η μέθοδος χρησιμοποιείται για την εύρεση του πρώτου στοιχείου που πληροί τα κριτήρια. Για παράδειγμα, για να βρείτε τον πρώτο τίτλο σε μια σελίδα:
title = soup.find("span", class_="title")
print(title.string)
findAll Η μέθοδος χρησιμοποιείται για την εύρεση όλων των στοιχείων που πληρούν τα κριτήρια. Για παράδειγμα, για να βρείτε όλους τους τίτλους σε μια σελίδα:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Η μέθοδος επιτρέπει τη χρήση επιλογέων CSS για την εύρεση στοιχείων. Για παράδειγμα, για να βρείτε όλους τους τίτλους:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
μπορεί να χρησιμοποιηθείattrs Ιδιότητες Λαμβάνει το λεξικό χαρακτηριστικών του στοιχείου. Για παράδειγμα, λάβετε τις διευθύνσεις URL όλων των εικόνων:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
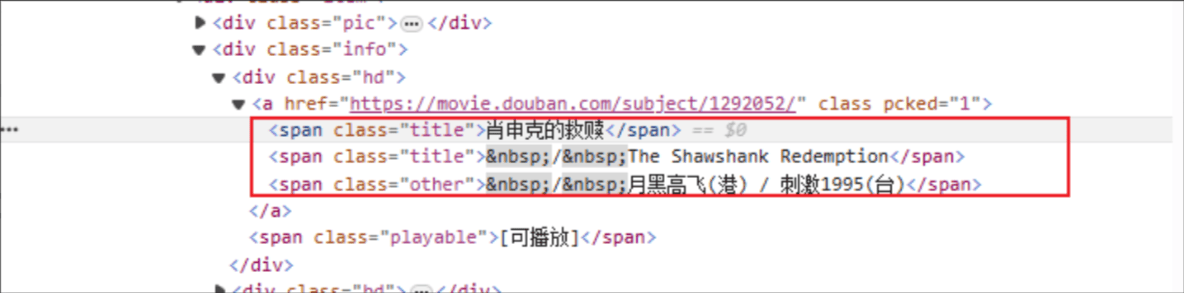
Τίτλος ταινίας: Το όνομα της ετικέτας HTML είναι: span και το χαρακτηριστικό class του καθορισμένου στοιχείου είναι τίτλος.

Βαθμολογία: Η ετικέτα HTML είναι: span και το χαρακτηριστικό class του καθορισμένου στοιχείου είναι rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
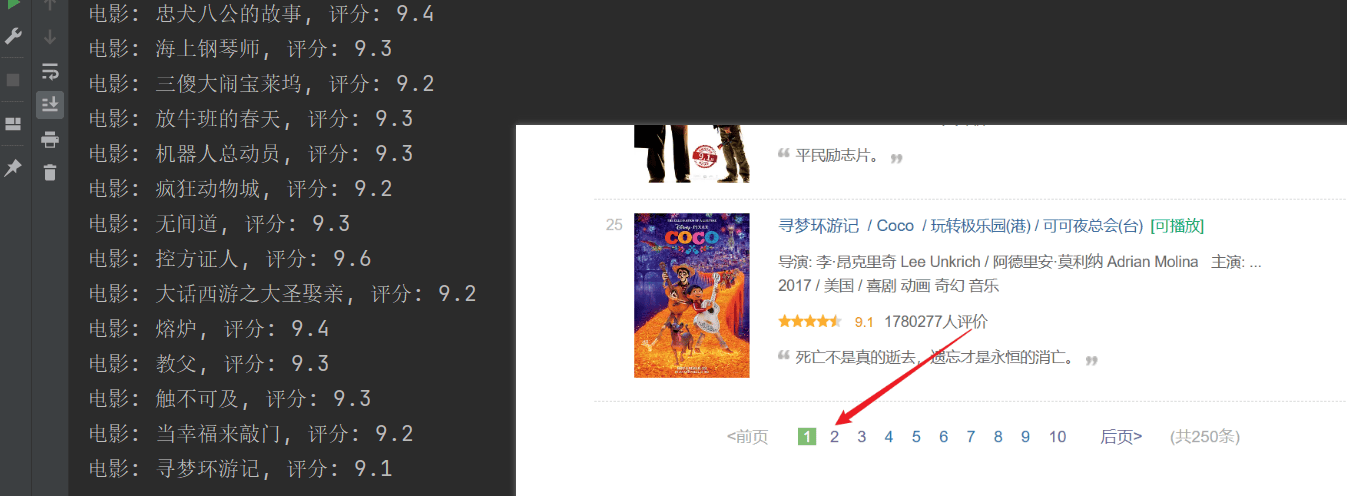
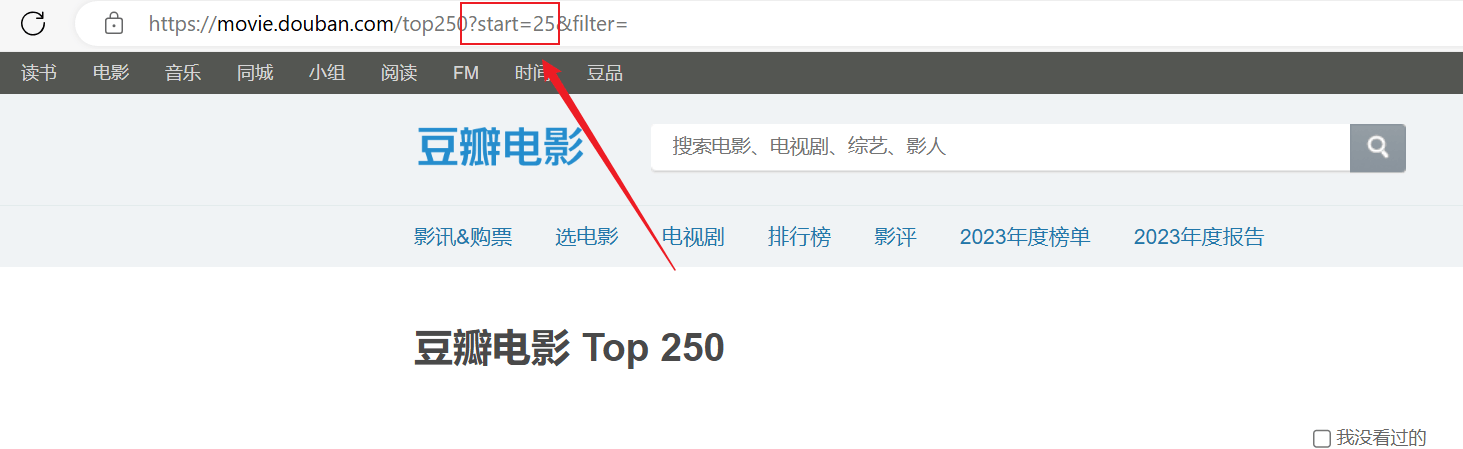
Η ανίχνευση ήταν επιτυχής, αλλά μόνο η πρώτη σελίδα ανιχνεύτηκε και το επόμενο περιεχόμενο δεν ανιχνεύτηκε με επιτυχία.Αναλύστε την παραπάνω σύνδεση url, κάθε σελίδα περνάει τοstartΟι παράμετροι σελιδοποιούνται.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]