
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP — это протокол клиент-сервер, и двумя сторонами связи являются клиент и сервер. Клиент отправляет HTTP-запрос, а сервер получает и обрабатывает запрос и возвращает HTTP-ответ.
HTTP-запросы состоят из строк запроса, заголовков запросов, пустых строк и данных запроса (например, данных формы в запросах POST).
Пример запроса:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
строка запроса:POST /api/users HTTP/1.1
Заголовок запроса: содержит Host, User-Agent, Accept, Content-Type, Content-Length и т. д.
пустая строка: Пустая строка между заголовком запроса и телом запроса.
Тело запроса:данные JSON
Ответ HTTP состоит из строки состояния, заголовков ответа, пустых строк и данных ответа.
Предполагая, что сервер возвращает простую HTML-страницу, ответ может быть следующим:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
строка состояния:HTTP/1.1 200 ОК
заголовок ответа: содержит дату, сервер, тип контента, длину контента, соединение и т. д.
пустая строка: Пустая строка между заголовками ответа и телом ответа.
тело ответа: Содержит HTML-код.
Коды состояния HTTP указывают на результаты обработки запроса сервером. Общие коды состояния включают в себя:

Библиотека запросов Python — очень мощная и простая в использовании HTTP-библиотека.
Перед использованием вам необходимо установить библиотеку Requests:pip install requests
GET-запрос используется для запроса данных с сервера. Сделать GET-запрос с помощью библиотеки Requests очень просто:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
POST-запрос используется для отправки данных на сервер. Например, веб-сайты, требующие входа в систему, часто используют запросы POST для отправки имени пользователя и пароля. Метод использования библиотеки Requests для инициации запроса POST следующий:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
На некоторых веб-сайтах (например, Douban) механизм защиты от сканирования не разрешен для сканеров, а заголовки и параметры HTTP-запросов необходимо настроить так, чтобы они выдавали себя за браузер и проходили аутентификацию.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
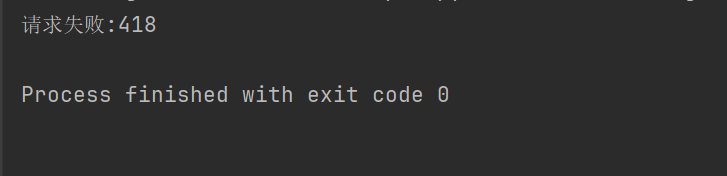
Например, если приведенный выше код не установит заголовок запроса, Дубан откажет нам в доступе.
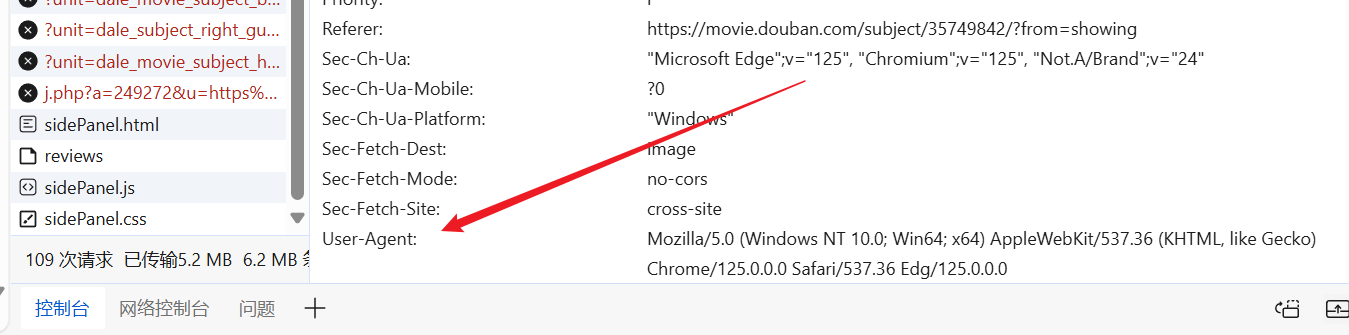
Мы можем по желанию зайти на сайт, найти готовый User-Agent и поместить его в заголовок нашего запроса.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
Таким образом, вы можете получить доступ к Douban и получить содержимое веб-страницы.
BeautifulSoup — это библиотека Python для анализа документов HTML и XML, особенно для извлечения данных с веб-страниц.
Перед использованием необходимо установить библиотеку BeautifulSoup:pip install beautifulsoup4
html.parser Это встроенный парсер Python, подходящий для большинства сценариев. Возьмите Дубана выше в качестве примера.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup предоставляет несколько методов для поиска и извлечения данных из HTML-документов.
Общие методы BeautifulSoup:
find(tag, attributes): найти первый тег, соответствующий критериям.find_all(tag, attributes): найти все совпадающие теги.select(css_selector): используйте селекторы CSS для поиска тегов, соответствующих критериям.get_text(): получить текстовое содержимое метки.attrs: Получить словарь атрибутов тега.find Метод используется для поиска первого элемента, соответствующего критериям. Например, чтобы найти первый заголовок на странице:
title = soup.find("span", class_="title")
print(title.string)
findAll Метод используется для поиска всех элементов, соответствующих критериям. Например, чтобы найти все заголовки на странице:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Метод позволяет использовать селекторы CSS для поиска элементов. Например, чтобы найти все заголовки:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
можешь использоватьattrs Свойства Получает словарь атрибутов элемента. Например, получите URL-адреса всех изображений:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
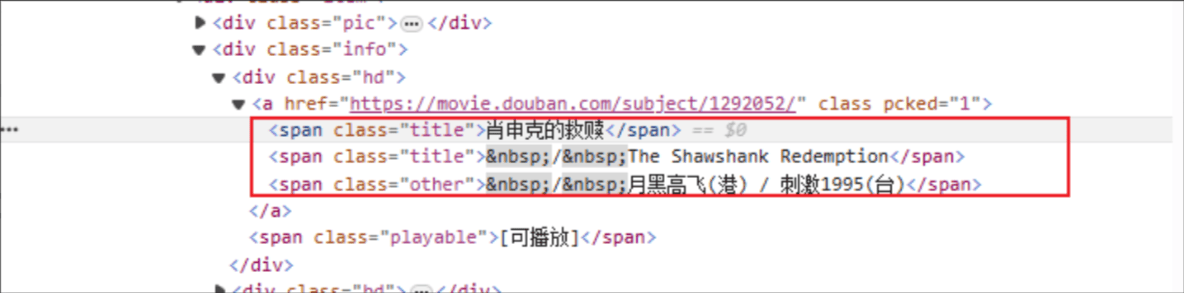
Название фильма: имя HTML-тега: span, а атрибут класса указанного элемента — title.

Рейтинг: HTML-тег: span, а атрибут класса указанного элемента — рейтинг_номер.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
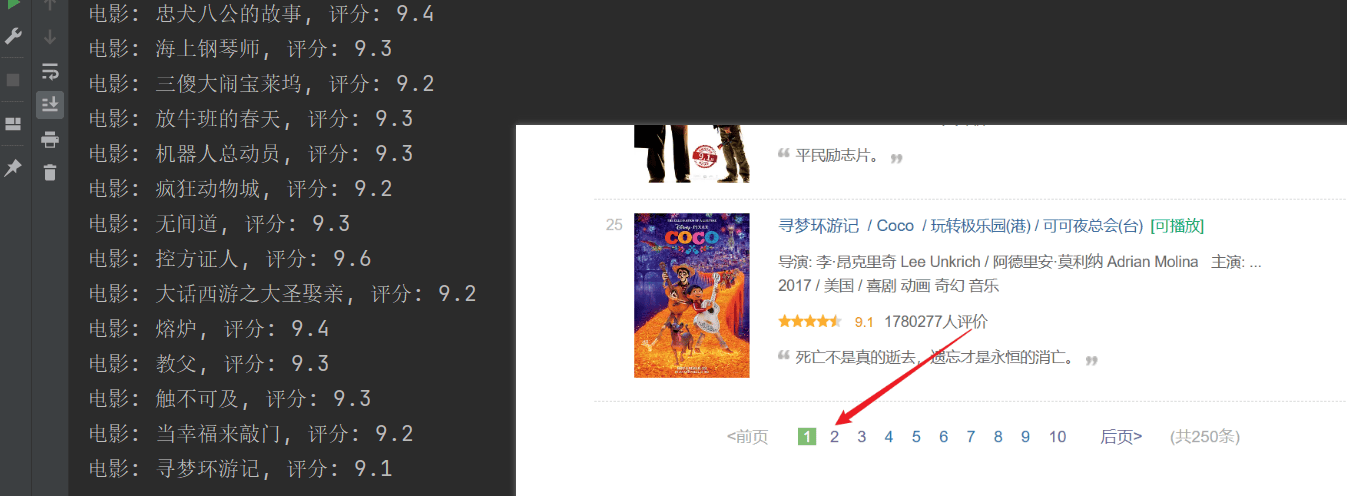
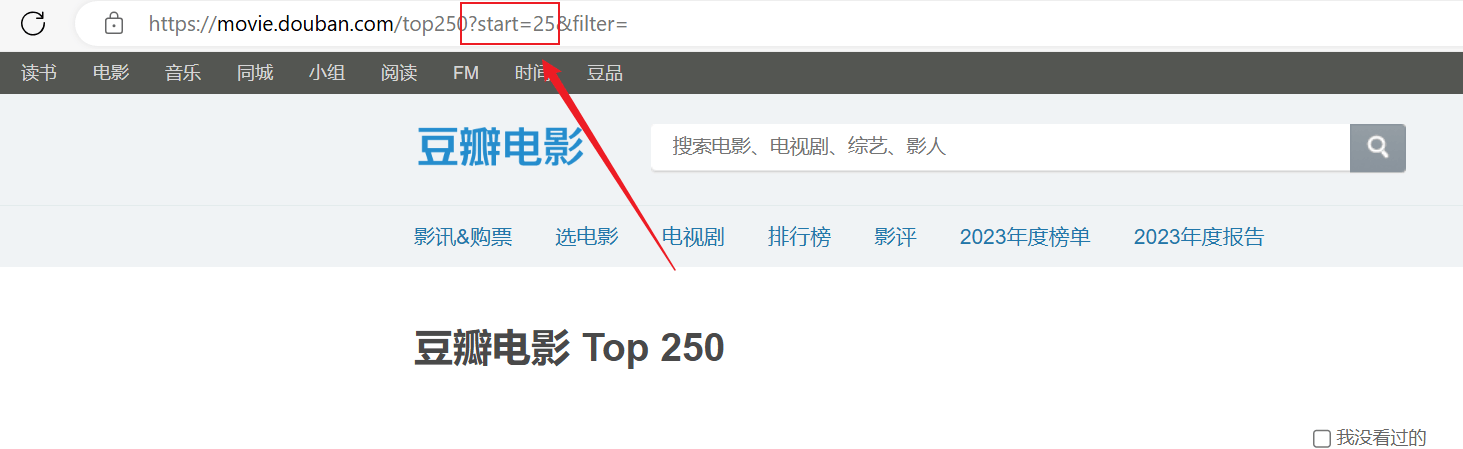
Сканирование прошло успешно, но была просканирована только первая страница, а последующий контент не был просканирован успешно.Проанализируйте указанное выше URL-соединение: каждая страница передает URL-адрес вstartПараметры выводятся на страницы.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com