2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP on asiakas-palvelin-protokolla, ja viestinnän osapuolet ovat asiakas ja palvelin. Asiakas lähettää HTTP-pyynnön, ja palvelin vastaanottaa ja käsittelee pyynnön ja palauttaa HTTP-vastauksen.
HTTP-pyynnöt koostuvat pyyntöriveistä, pyyntöjen otsikoista, tyhjistä riveistä ja pyyntötiedoista (kuten POST-pyyntöjen lomaketiedoista).
Pyyntöesimerkki:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
pyyntörivi:POST /api/users HTTP/1.1
Pyynnön otsikko: Sisältää isännän, käyttäjäagentin, hyväksynnän, sisältötyypin, sisällön pituuden jne.
tyhjä rivi: Tyhjä rivi pyynnön otsikon ja pyynnön tekstin välillä
Pyynnön runko:JSON-tiedot
HTTP-vastaus koostuu tilariviltä, vastausotsikoista, tyhjistä riveistä ja vastaustiedoista.
Olettaen, että palvelin palauttaa yksinkertaisen HTML-sivun, vastaus voi olla seuraava:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
tilarivi:HTTP/1.1 200 OK
vastauksen otsikko: Sisältää päivämäärän, palvelimen, sisältötyypin, sisällön pituuden, yhteyden jne.
tyhjä rivi: Tyhjä viiva vastauksen otsikoiden ja vastauksen rungon välillä
vastausrunko: Sisältää HTML-koodin
HTTP-tilakoodit osoittavat palvelimen pyynnön käsittelytulokset. Yleisiä tilakoodeja ovat:

Pythonin Requests-kirjasto on erittäin tehokas ja helppokäyttöinen HTTP-kirjasto.
Ennen kuin käytät sitä, sinun on asennettava Requests-kirjasto:pip install requests
GET-pyyntöä käytetään tietojen pyytämiseen palvelimelta. GET-pyynnön tekeminen Requests-kirjaston avulla on hyvin yksinkertaista:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
POST-pyyntöä käytetään tietojen lähettämiseen palvelimelle. Esimerkiksi sivustot, jotka vaativat kirjautumisen, käyttävät usein POST-pyyntöjä käyttäjänimen ja salasanan lähettämiseen. Pyyntökirjaston käyttäminen POST-pyynnön käynnistämiseen on seuraava:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Joillakin verkkosivustoilla (kuten Douban) indeksoinnin estomekanismi ei ole sallittu indeksointiroboteille, ja HTTP-pyyntöjen otsikot ja parametrit on asetettava niin, että ne teeskentelevät selaimia ja läpäisevät todennuksen.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
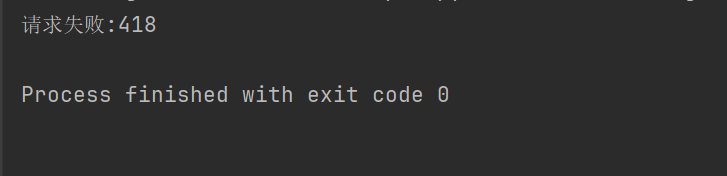
Jos yllä oleva koodi ei esimerkiksi aseta pyynnön otsikkoa, Douban estää meiltä pääsyn.
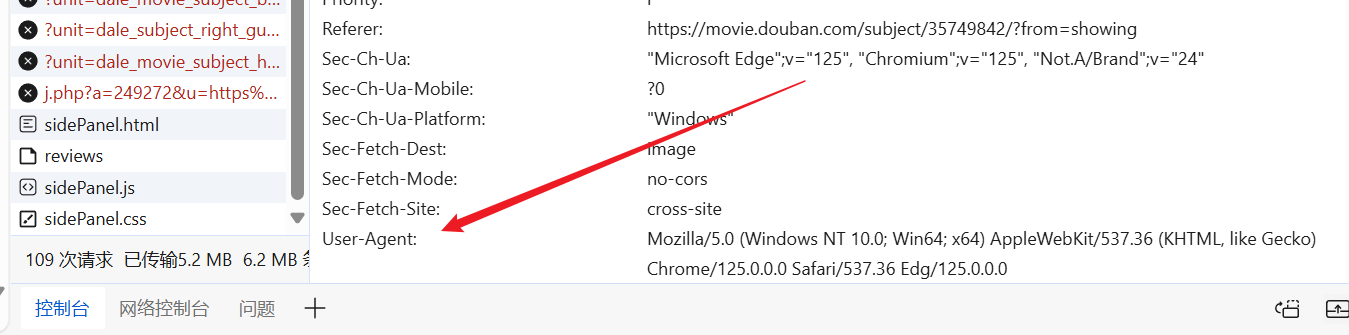
Voimme siirtyä verkkosivustolle halutessasi, löytää valmiin User-Agentin ja laittaa sen pyyntömme otsikkoon.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
Tällä tavalla voit käyttää Doubania ja saada verkkosivun sisällön.
BeautifulSoup on Python-kirjasto HTML- ja XML-dokumenttien jäsentämiseen, erityisesti tietojen poimimiseen verkkosivuilta.
Ennen käyttöä sinun on asennettava BeautifulSoup-kirjasto:pip install beautifulsoup4
html.parser Se on Pythonin sisäänrakennettu jäsentäjä ja sopii useimpiin skenaarioihin. Otetaan esimerkkinä yllä oleva Douban.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup tarjoaa useita tapoja löytää ja poimia tietoja HTML-asiakirjoista.
BeautifulSoupin yleiset menetelmät:
find(tag, attributes): Etsi ensimmäinen ehtoja vastaava tunniste.find_all(tag, attributes): Etsi kaikki vastaavat tunnisteet.select(css_selector): Käytä CSS-valitsimia löytääksesi ehtoja vastaavat tunnisteet.get_text(): Hae tekstisisältö tarran sisällä.attrs: Hanki tunnisteen attribuuttisanakirja.find Menetelmää käytetään etsimään ensimmäinen kriteerit täyttävä elementti. Esimerkiksi sivun ensimmäisen otsikon etsiminen:
title = soup.find("span", class_="title")
print(title.string)
findAll Menetelmällä etsitään kaikki kriteerit täyttävät elementit. Voit esimerkiksi etsiä sivun kaikki otsikot seuraavasti:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Menetelmä mahdollistaa CSS-valitsimien käytön elementtien etsimiseen. Voit esimerkiksi etsiä kaikki otsikot seuraavasti:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
voi käyttääattrs Ominaisuudet Hakee elementin attribuuttisanakirjan. Hanki esimerkiksi kaikkien kuvien URL-osoitteet:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
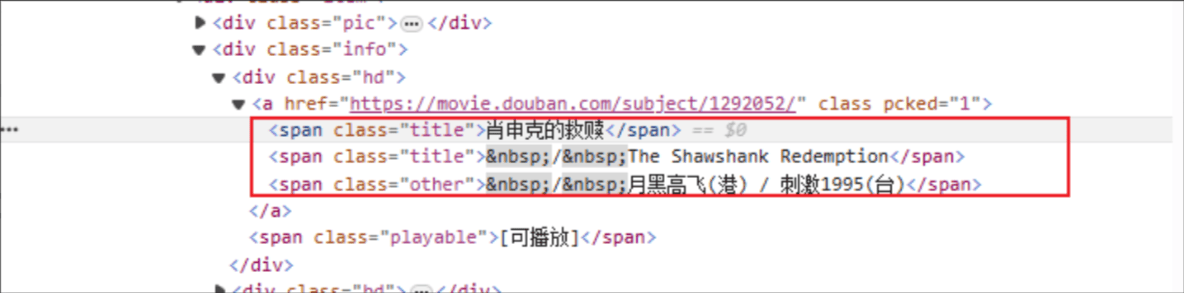
Elokuvan nimi: HTML-tunnisteen nimi on: span ja määritetyn elementin class-attribuutti on title.

Rating: HTML-tunniste on: span ja määritetyn elementin class-attribuutti on rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
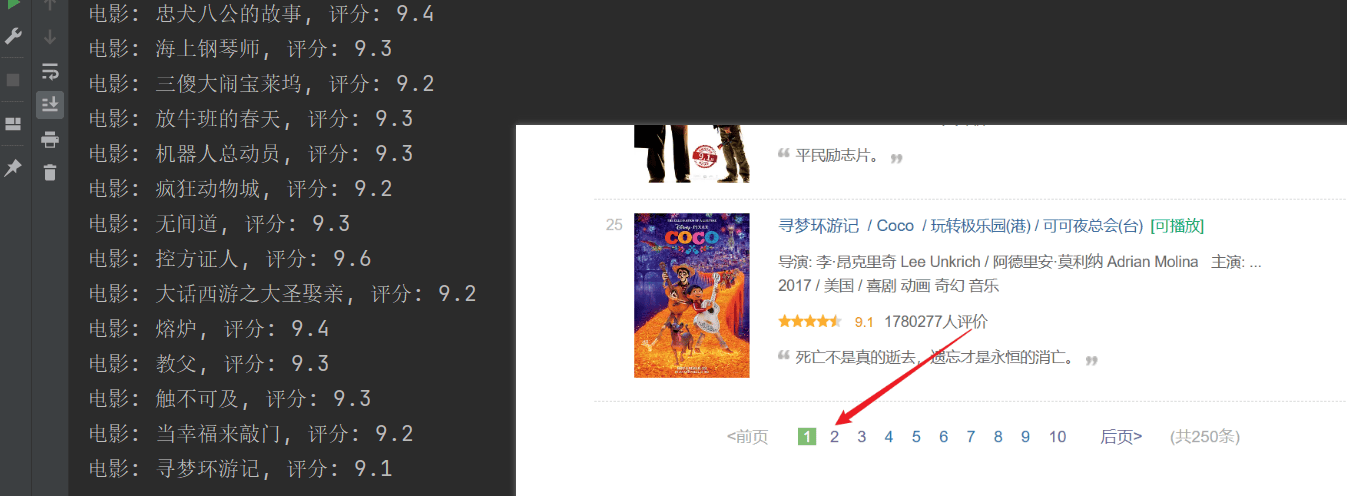
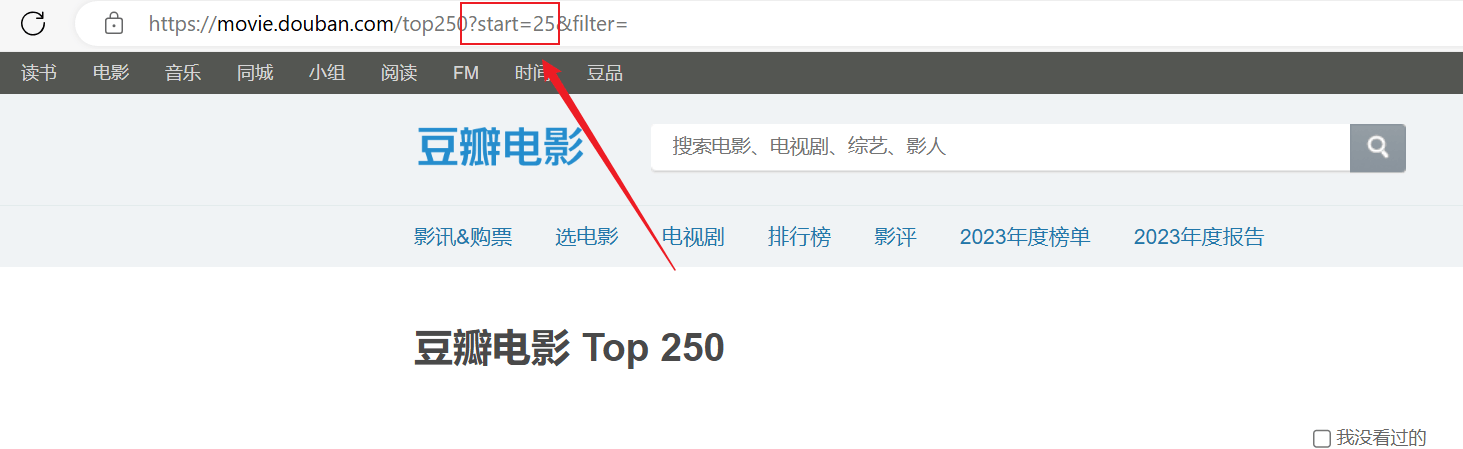
Indeksointi onnistui, mutta vain ensimmäinen sivu indeksoitiin, eikä myöhemmän sisällön indeksointi onnistunut.Analysoi yllä oleva URL-yhteys, jokainen sivu välittää URL-osoitteenstartParametrit on sivuttu.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten

