2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP est clientis protocollum, et duae communicationis partes client et ministra sunt. Cliens petitionem HTTP mittit et minister accipit et roganti processit et responsionem HTTP reddit.
HTTP petitiones sunt lineae petitionis, petendi capitis, lineae vestis et data petitio (ut forma data in POST petitionibus).
Exemplum peto:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
petentibus lineamPOST /api/users HTTP/1.1
Request header: Hostiam continet, User-Agent, Accipe, Content-Typus, Content-Longitudo, etc.
blank linea: Blank line between petere header and request body
Request corpus: JSON data
Responsio HTTP consistit in linea status, responsio capitis, lineae blank et notitia responsionis.
Posito server paginam HTML simplicem reddit, responsio sic sequitur:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
status lineaHTTP/1.1 200 OK
responsio header: Continet Date, Servo, Content-Type, Content-Longitudo, Connection, etc.
blank linea: Blank line between responsio capitis et responsio corporis
responsio corpus: Continet HTML
HTTP status codes indicant eventus processus petitionis ministri. Communis status codes includit:

Bibliotheca libellis Pythonis valde potens et facilis ad usum bibliothecae HTTP est.
Priusquam utatur, necesse est ut supplicum libellis instituas;pip install requests
Petitio GET adhibetur a servo peto data. Petitionem GET utens in bibliotheca supplicum libellis est valde simplex:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Post petitionem adhibetur submittere data in calculonis servi. Exempli gratia, paginae quae login postulant saepe utuntur Post petitiones usoris tesseraeque subiciendae. Modus petendi bibliothecam utendi utendi Post petitionem petitio haec est:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
In nonnullis locis (ut Douban), mechanismus anti reptans pro reptilia non permittitur, et HTTP petitio capitis ac parametri opus est ut constituatur ut navigatrum sit et authenticas transeat.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
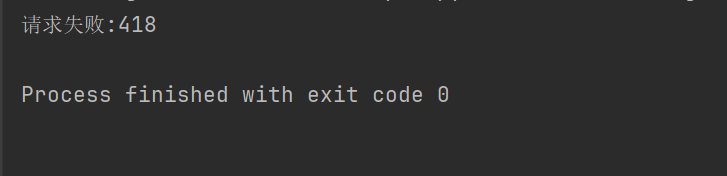
Exempli gratia, si superius codicem petitio capitis non posuerit, Douban nos accessum negabit.
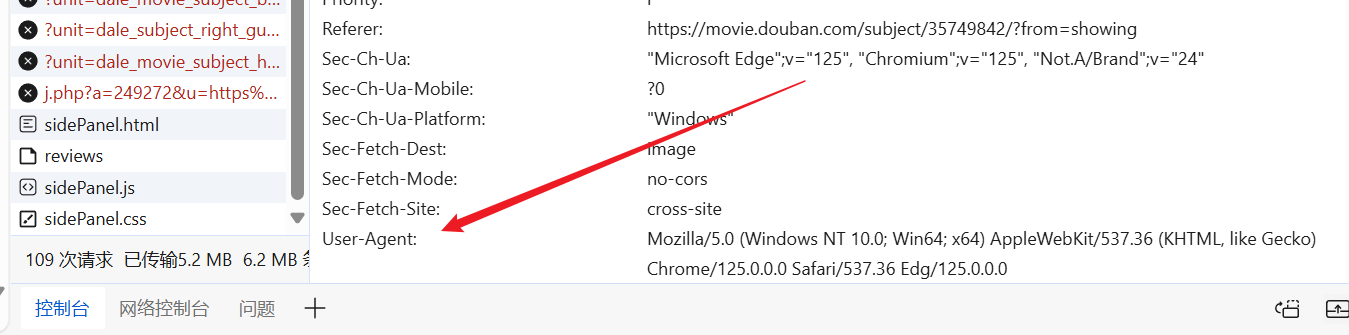
Paginam ad libitum ingredi possumus, paratum User-Agentum factum invenire et in petitione nostra caput imponere.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
Hoc modo, Douban accedere potes et paginae telae contentum obtinere.
Pulchra Soup bibliotheca Python est ad parsingendas HTML et XML documenta, praesertim ad notitias e paginis extrahendis.
Ante usum, debes bibliothecam BeautifulSoup instituere:pip install beautifulsoup4
html.parser In parser Pythonis aedificatur et missionibus maxime convenit. Douban supra in exemplum sume.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
Pulchra Soup plures modos praebet ut notitias ex HTML documentis inveniendi et extrahendi.
BeautifulSoup communes modos:
find(tag, attributes): Reperio primum tag quod criteriis aequet.find_all(tag, attributes): Find omnes tags matching.select(css_selector): Utere CSS selectoribus ad inveniendas tags quae criteriis congruit.get_text()Accipe textum contentum intra pittacium.attrs: Dictionarium tag attributum posside.find Methodus adhibetur ut primum elementum re- gulae occurrat. Exempli gratia primum titulum in pagina invenire:
title = soup.find("span", class_="title")
print(title.string)
findAll Methodus adhibetur ad inveniendum omnia elementa quae criteriis occurrentia. Exempli gratia, omnes titulos in pagina invenire:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Ratio permittit utens CSS selectores elementa invenire. Exempli gratia omnes titulos invenimus:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
potestattrs Dictionarium proprietatum Getae elementi attributum. Exempli gratia URL omnium imaginum:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
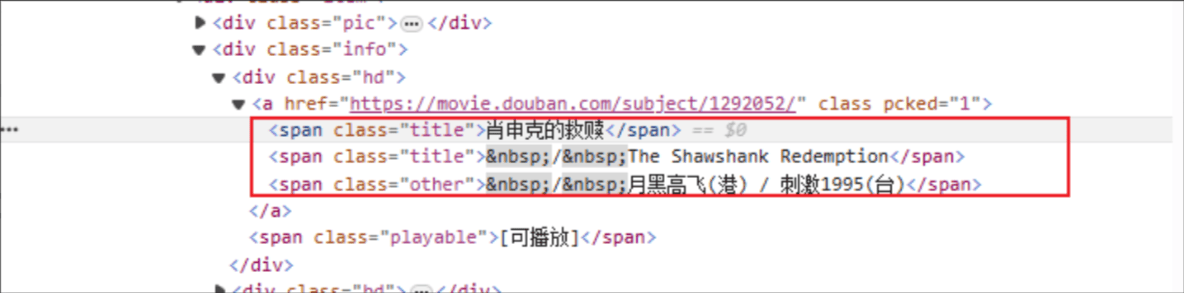
Titulus cinematicus: Nomen tag HTML est: span, et genus attributum elementi determinati titulus est.

Rating: The HTML tag is: span, and class attributum elementi determinati est rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
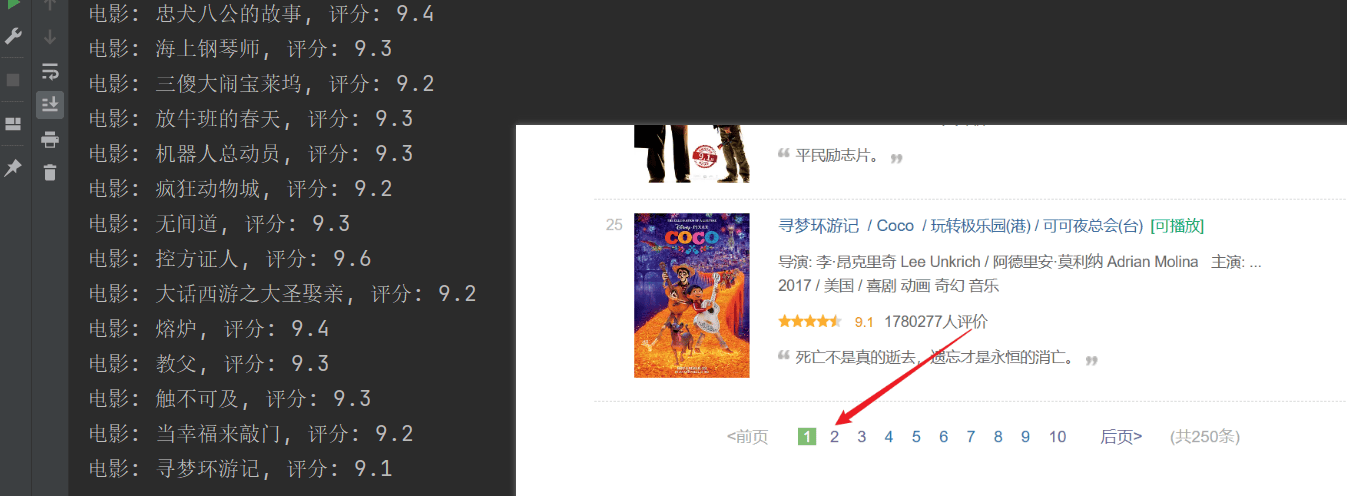
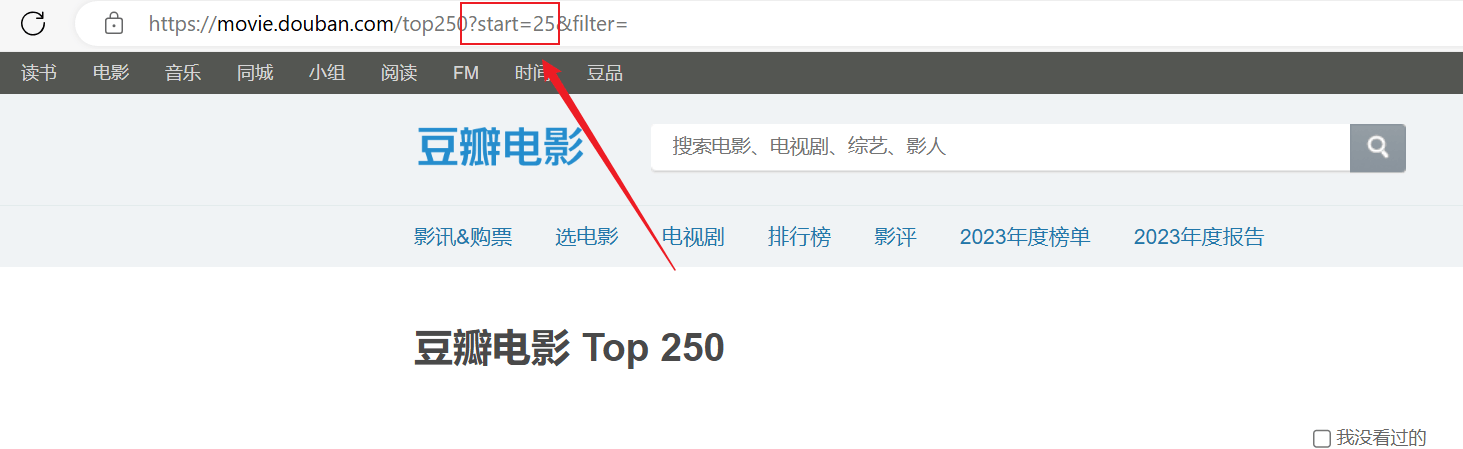
Reptans valuit, sed prima pagina tantum repit, et contentum sequens non feliciter reptavit.Connexionem URL superius examinare, singula pagina domicilium in the transitstartAliquam eget laoreet libero.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones technologiarum progressus ad futuram referentiam

