
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
HTTP adalah protokol klien-server, dan dua pihak yang berkomunikasi adalah klien dan server. Klien mengirimkan permintaan HTTP, dan server menerima dan memproses permintaan tersebut dan mengembalikan respons HTTP.
Permintaan HTTP terdiri dari baris permintaan, header permintaan, baris kosong, dan data permintaan (seperti data formulir dalam permintaan POST).
Contoh permintaan:
POST /api/users HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: application/json
Content-Type: application/json
Content-Length: 27
{
"name": "John",
"age": 30
}
baris permintaan:POST /api/pengguna HTTP/1.1
Judul permintaan: Berisi Host, Agen Pengguna, Terima, Tipe Konten, Panjang Konten, dll.
garis kosong: Baris kosong antara header permintaan dan isi permintaan
Permintaan tubuh:Data JSON
Respons HTTP terdiri dari baris status, header respons, baris kosong, dan data respons.
Dengan asumsi server mengembalikan halaman HTML sederhana, responsnya mungkin sebagai berikut:
HTTP/1.1 200 OK
Date: Sun, 02 Jun 2024 10:20:30 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 137
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is a sample HTML page.</p>
</body>
</html>
garis status:HTTP/1.1 200 Oke
tajuk respons: Berisi Tanggal, Server, Tipe Konten, Panjang Konten, Koneksi, dll.
garis kosong: Baris kosong antara header respons dan isi respons
badan respons: Berisi kode HTML
Kode status HTTP menunjukkan hasil pemrosesan permintaan oleh server. Kode status umum meliputi:

Pustaka Permintaan Python adalah pustaka HTTP yang sangat kuat dan mudah digunakan.
Sebelum menggunakannya, Anda perlu menginstal perpustakaan Permintaan:pip install requests
Permintaan GET digunakan untuk meminta data dari server. Membuat permintaan GET menggunakan perpustakaan Permintaan sangat sederhana:
import requests
# 发起GET请求
response = requests.get('https://news.baidu.com')
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Permintaan POST digunakan untuk mengirimkan data ke server. Misalnya, situs web yang memerlukan login sering kali menggunakan permintaan POST untuk mengirimkan nama pengguna dan kata sandi. Metode penggunaan perpustakaan Permintaan untuk memulai permintaan POST adalah sebagai berikut:
import requests
# 定义要发送的数据
data = {
'username': '123123123',
'password': '1231231312'
}
# 发起POST请求
response = requests.post('https://passport.bilibili.com/x/passport-login/web/login', data=data)
# 检查响应状态码
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
Di beberapa situs web (seperti Douban), mekanisme anti-perayapan tidak diperbolehkan untuk perayap, dan header serta parameter permintaan HTTP perlu disetel agar berpura-pura menjadi browser dan lolos autentikasi.
import requests
response = requests.get("https://movie.douban.com/top250")
if response.ok:
print(response.text)
else:
print("请求失败:" + str(response.status_code))
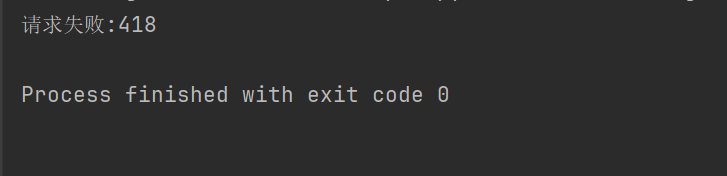
Misalnya, jika kode di atas tidak menyetel header permintaan, Douban akan menolak akses kami.
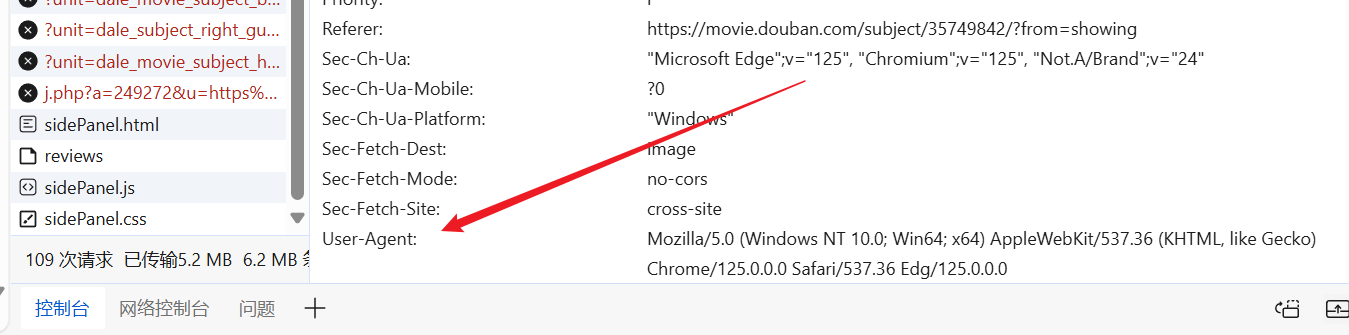
Kita bisa masuk ke website sesuka hati, mencari User-Agent yang sudah jadi, dan menaruhnya di header permintaan kita.
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
Dengan cara ini, Anda dapat mengakses Douban dan mendapatkan konten halaman web.
BeautifulSoup adalah perpustakaan Python untuk mengurai dokumen HTML dan XML, terutama untuk mengekstraksi data dari halaman web.
Sebelum digunakan, Anda perlu menginstal perpustakaan BeautifulSoup:pip install beautifulsoup4
html.parser Ini adalah parser bawaan Python dan cocok untuk sebagian besar skenario. Ambil Douban di atas sebagai contoh.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
# 使用html.parser来解析HTML内容
soup = BeautifulSoup(html, "html.parser")
BeautifulSoup menyediakan berbagai metode untuk menemukan dan mengekstrak data dari dokumen HTML.
Metode umum BeautifulSoup:
find(tag, attributes): Temukan tag pertama yang sesuai dengan kriteria.find_all(tag, attributes): Temukan semua tag yang cocok.select(css_selector): Gunakan pemilih CSS untuk menemukan tag yang sesuai dengan kriteria.get_text(): Mendapatkan konten teks di dalam label.attrs: Dapatkan kamus atribut dari tag.find Metode digunakan untuk mencari elemen pertama yang memenuhi kriteria. Misalnya, untuk menemukan judul pertama dalam sebuah halaman:
title = soup.find("span", class_="title")
print(title.string)
findAll Metode digunakan untuk mencari seluruh elemen yang memenuhi kriteria. Misalnya, untuk menemukan semua judul dalam satu halaman:
all_titles = soup.findAll("span", class_="title")
for title in all_titles:
print(title.string)
select Metode memungkinkan penggunaan pemilih CSS untuk menemukan elemen. Misalnya, untuk menemukan semua judul:
all_titles = soup.select("span.title")
for title in all_titles:
print(title.get_text())
bisa menggunakanattrs Properti Mendapatkan kamus atribut elemen. Misalnya, dapatkan URL semua gambar:
all_images = soup.findAll("img")
for img in all_images:
print(img['src'])
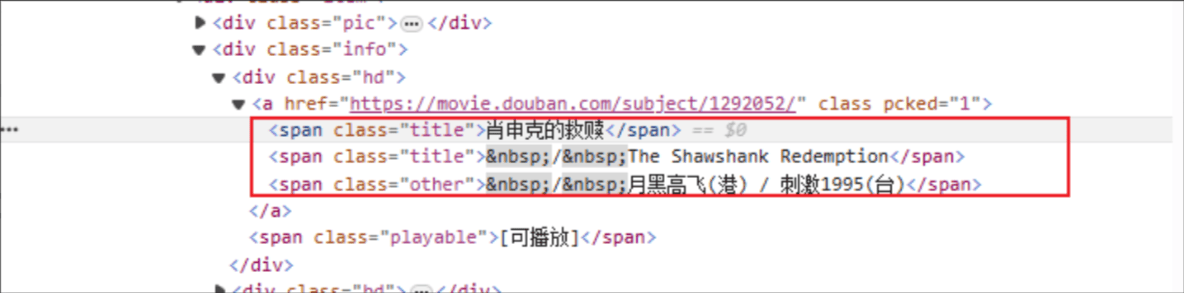
Judul film: Nama tag HTML adalah: span, dan atribut kelas dari elemen yang ditentukan adalah judul.

Peringkat: Tag HTMLnya adalah: span, dan atribut kelas dari elemen yang ditentukan adalah rating_num
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
response = requests.get(f"https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")
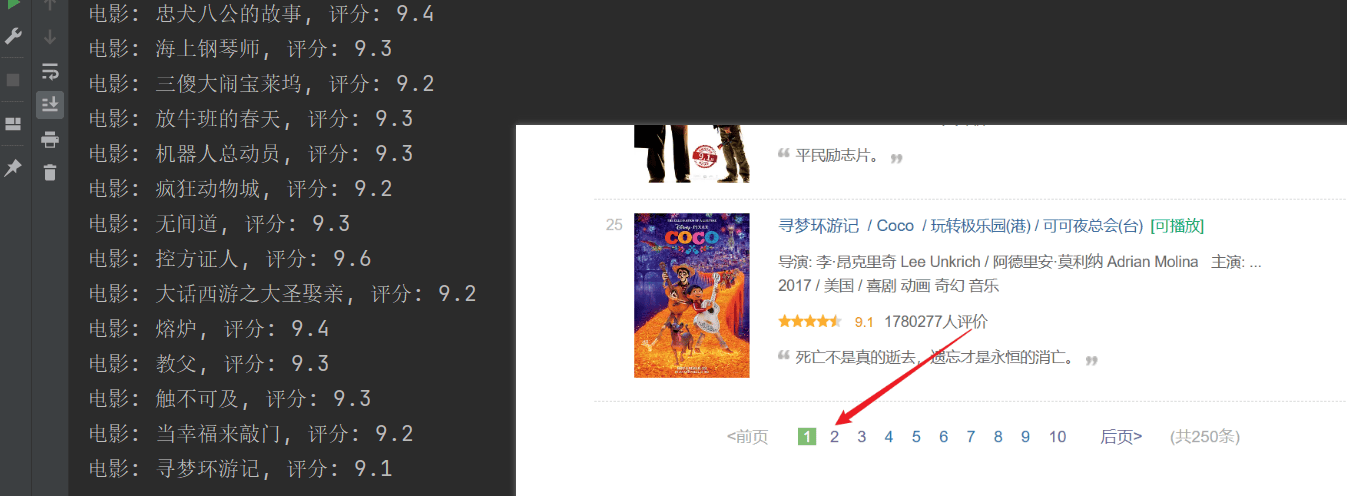
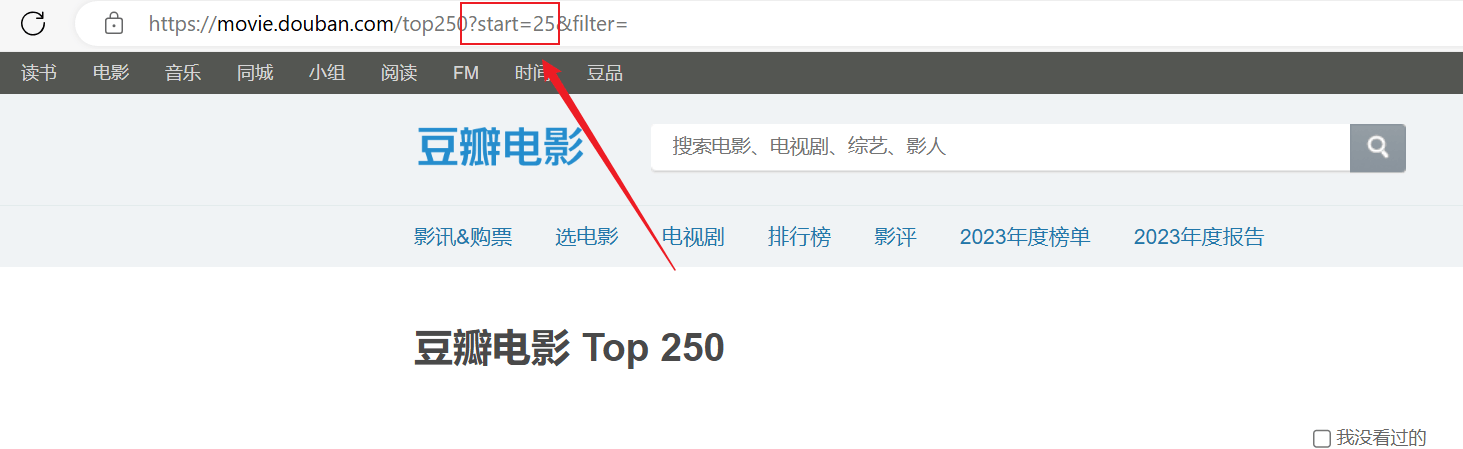
Perayapan berhasil, tetapi hanya halaman pertama yang dirayapi, dan konten berikutnya tidak berhasil dirayapi.Analisis koneksi url di atas, setiap halaman melewati URL distartParameter diberi halaman.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 获取所有电影条目
all_movies = soup.find_all("div", class_="item")
for movie in all_movies:
# 获取电影标题
titles = movie.find_all("span", class_="title")
for title in titles:
title_string = title.get_text()
if "/" not in title_string:
movie_title = title_string
# 获取电影评分
rating_num = movie.find("span", class_="rating_num").get_text()
# 输出电影标题和评分
print(f"电影: {movie_title}, 评分: {rating_num}")

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]