2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Der Eingang zum Shuffle-System. ShuffleManager wird in sparkEnv im Treiber und Executor erstellt. Registrieren Sie Shuffle im Treiber und lesen und schreiben Sie Daten im Executor.
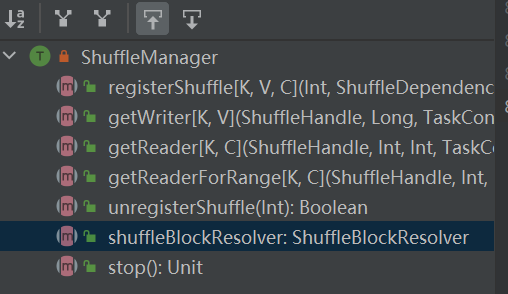
registerShuffle: Shuffle registrieren, shuffleHandle zurückgeben
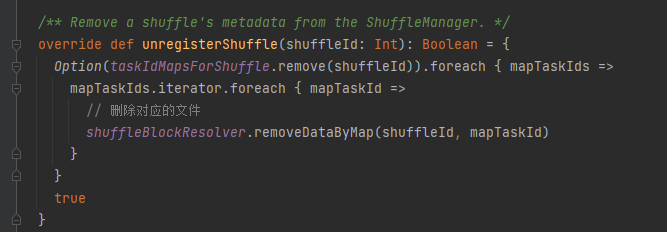
unregisterShuffle: Shuffle entfernen
shuffleBlockResolver: Ruft shuffleBlockResolver ab, mit dem die Beziehung zwischen Shuffle und Block verwaltet wird
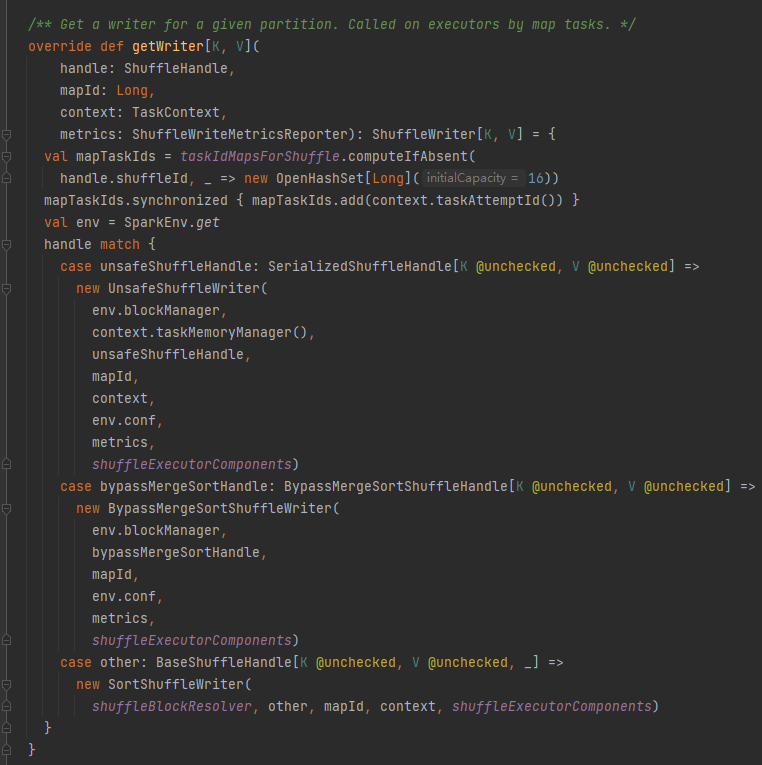
getWriter: Rufen Sie den der Partition entsprechenden Writer ab und rufen Sie ihn in der Map-Aufgabe des Executors auf
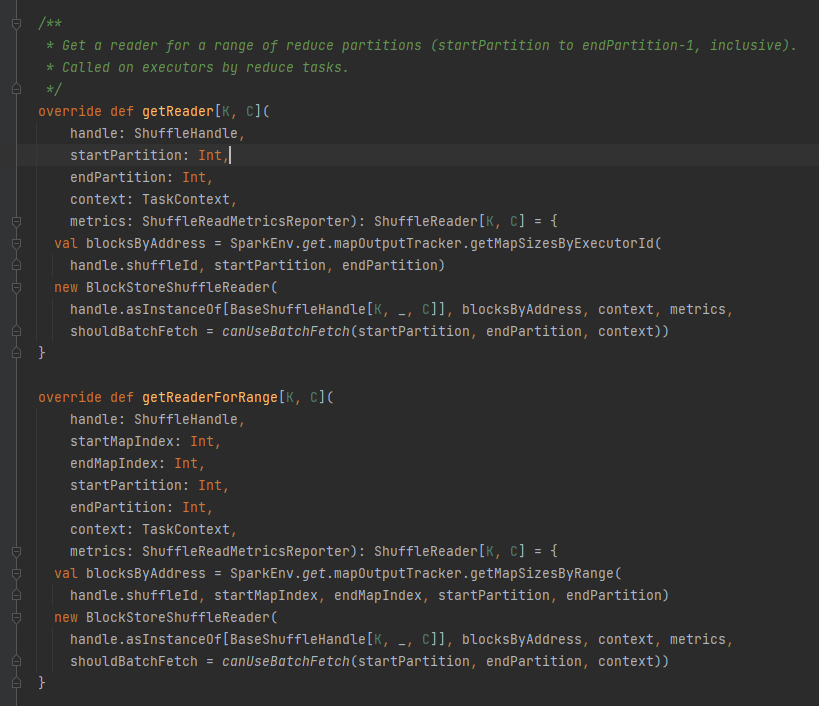
getReader, getReaderForRange: Holen Sie sich den Reader einer Bereichspartition und rufen Sie ihn in der Reduzierungsaufgabe des Executors auf
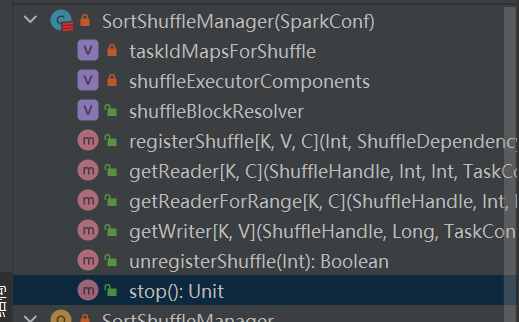
Ist die einzige Implementierung von shuffleManager.
Bei einem sortbasierten Shuffle werden eingehende Nachrichten nach Partitionen sortiert und schließlich in einer separaten Datei ausgegeben.
Der Reduzierer liest einen Datenbereich aus dieser Datei.
Wenn die Ausgabedatei zu groß ist, um in den Speicher zu passen, wird eine sortierte Zwischenergebnisdatei auf der Festplatte abgelegt und diese Zwischendateien werden für die Ausgabe zu einer endgültigen Datei zusammengeführt.
Sortierbasiertes Mischen verfügt über zwei Methoden:
Vorteile der serialisierten Sortierung
Im serialisierten Sortiermodus serialisiert der Shuffle-Writer eingehende Nachrichten, speichert sie in einer Datenstruktur und sortiert sie.
Wählen Sie den entsprechenden Griff je nach Szenario. Die Prioritätsreihenfolge ist BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
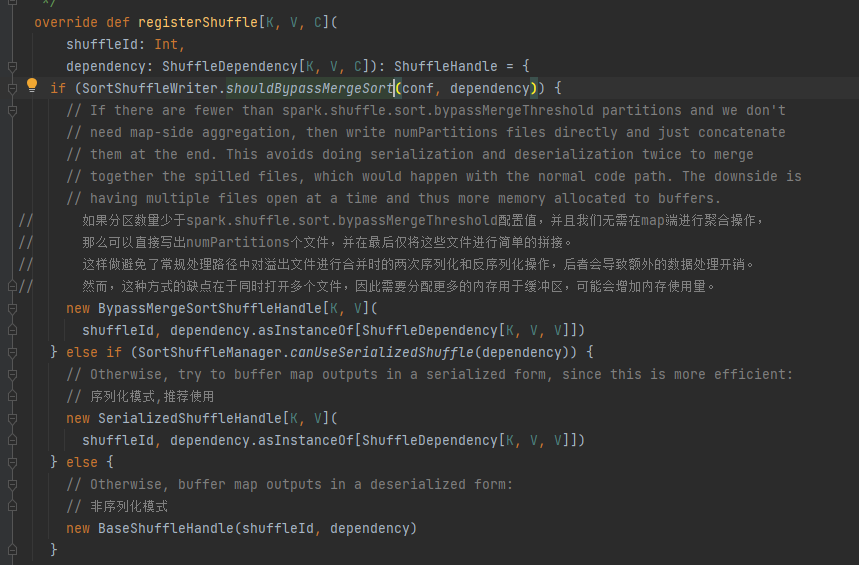
Umgehungsbedingung: Keine Kartenseite, die Anzahl der Partitionen ist kleiner oder gleich _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

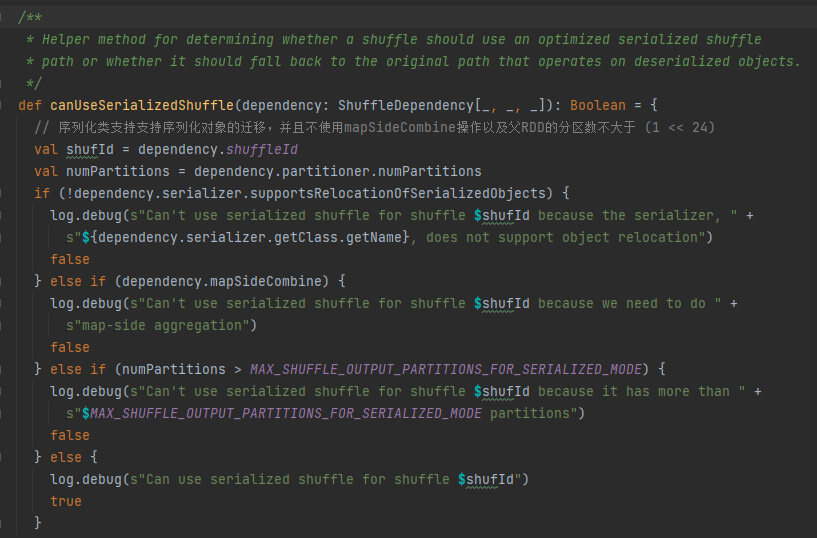
Bedingungen für Serialisierungshandles: Die Serialisierungsklasse unterstützt die Migration serialisierter Objekte, verwendet nicht die MapSideCombine-Operation und die Anzahl der Partitionen des übergeordneten RDD ist nicht größer als (1 << 24).
Cachen Sie zunächst diese Shuffle- und Map-Informationen in taskIdMapsForShuffle_
Wählen Sie den entsprechenden Autor basierend auf dem Handle aus, das dem Shuffle entspricht.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle entfernt die entsprechende Shuffle-Karte und die durch die Shuffle-Karte generierten Dateien
Rufen Sie alle Blockadressen ab, die der Shuffle-Datei entsprechen, also BlocksByAddress.
Erstellt ein BlockStoreShuffleReader-Objekt und gibt es zurück.
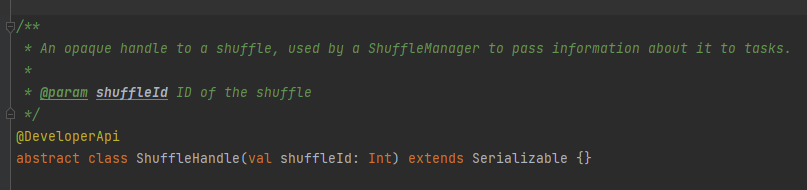
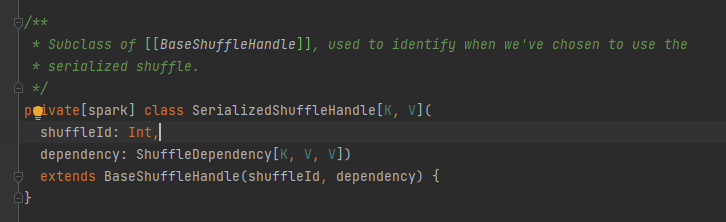
Es wird hauptsächlich zum Übergeben der Shuffle-Parameter verwendet und ist auch eine Markierung, um zu markieren, welcher Autor ausgewählt werden soll.


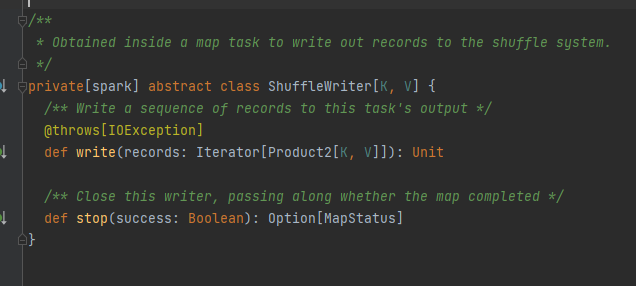
Abstrakte Klasse, verantwortlich für die Ausgabe von Kartenaufgaben. Die Hauptmethode ist Schreiben, und es gibt drei Implementierungsklassen
Wird später separat analysiert.
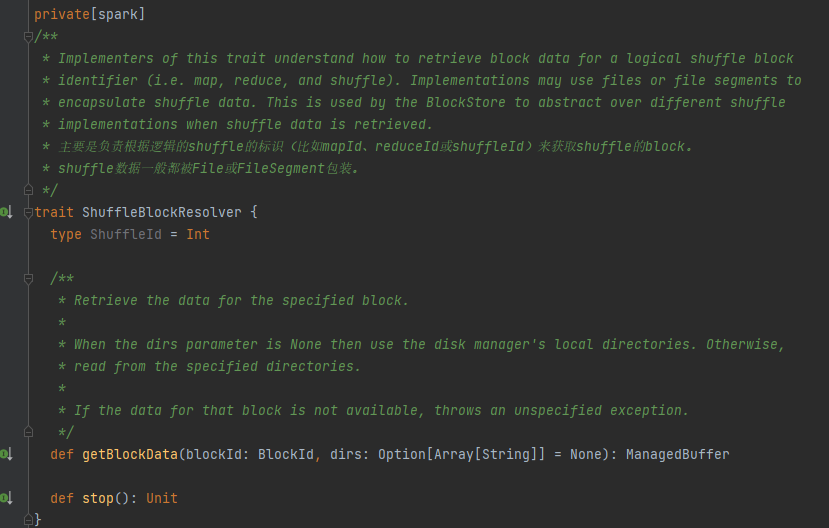
Merkmal: Die Implementierungsklasse kann die entsprechenden Blockdaten basierend auf MapId, ReduceId und ShuffleId abrufen.
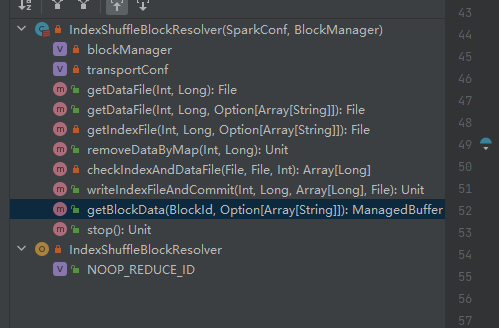
Die einzige Implementierungsklasse von ShuffleBlockResolver.
Erstellen und pflegen Sie Zuordnungen zwischen logischen Blöcken und physischen Dateispeicherorten für Shuffle-Blockdaten aus derselben Zuordnungsaufgabe.
Mischblockdaten, die zur gleichen Kartenaufgabe gehören, werden in einer konsolidierten Datendatei gespeichert.
Die Offsets dieser Datenblöcke in der Datendatei werden separat in einer Indexdatei gespeichert.
.data ist das Datendateisuffix
.index ist das Indexdateisuffix
Holen Sie sich die Datendatei.
Generieren Sie ShuffleDataBlockId und rufen Sie die Methode blockManager.diskBlockManager.getFile auf, um die Datei abzurufen
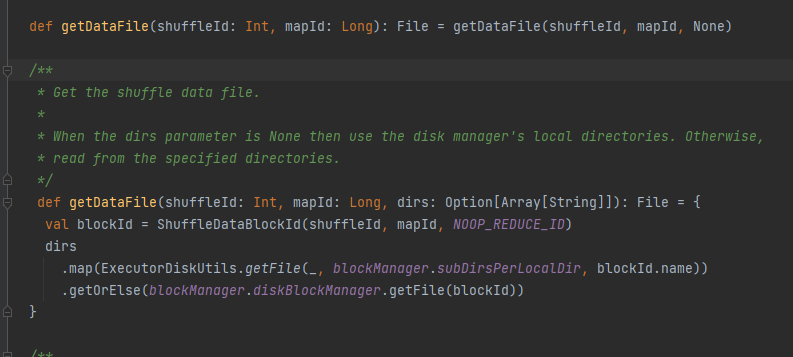
Ähnlich wie getDataFile
Generieren Sie ShuffleIndexBlockId und rufen Sie die Methode blockManager.diskBlockManager.getFile auf, um die Datei abzurufen

Rufen Sie die Datendatei und die Indexdatei basierend auf ShuffleId und MapId ab und löschen Sie sie dann
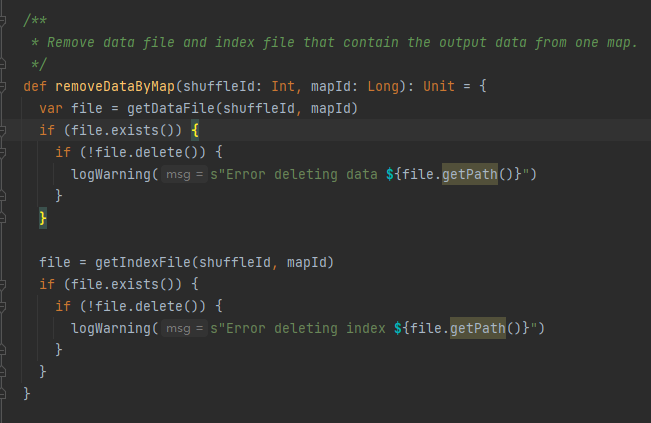
Rufen Sie die entsprechende Datendatei und Indexdatei gemäß MapId und ShuffleId ab.
Überprüfen Sie, ob die Datendatei und die Indexdatei vorhanden sind und übereinstimmen, und kehren Sie direkt zurück.
Wenn dies nicht der Fall ist, wird eine neue temporäre Indexdatei generiert. Benennen Sie dann die generierte Indexdatei und Datendatei um und kehren Sie zurück.
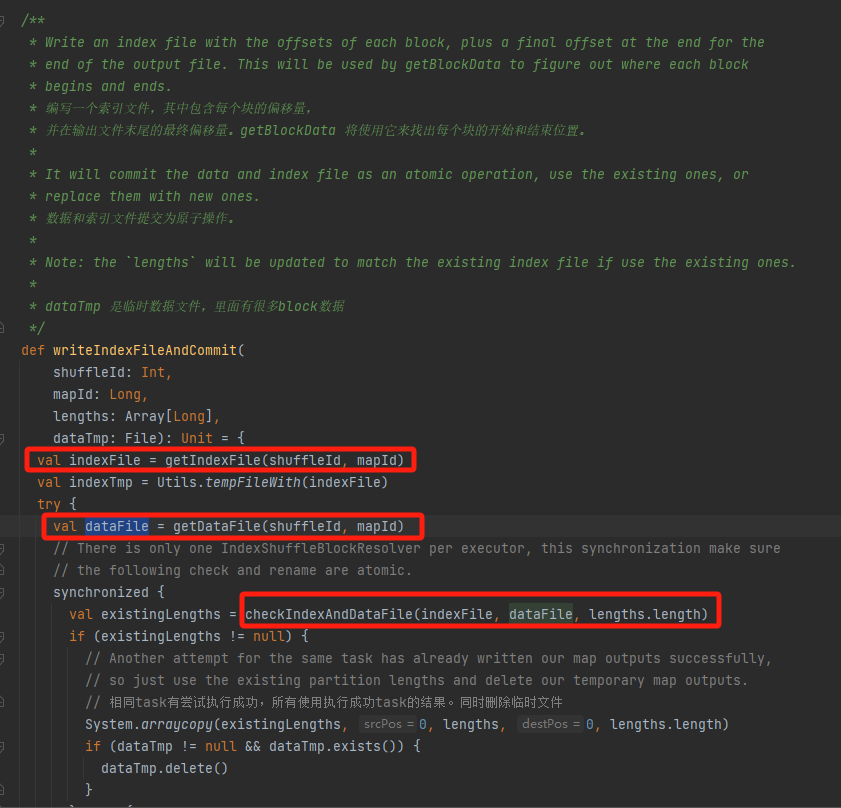

Angenommen, Shuffle hat drei Partitionen und die entsprechenden Datengrößen betragen 1000, 1500 bzw. 2500.
In der Indexdatei ist die erste Zeile 0, gefolgt vom kumulativen Wert der Partitionsdaten. Die zweite Zeile ist 1000, die dritte Zeile ist 1000+1500=2500 und die dritte Zeile ist 2500+2500=5000.
Datendateien werden nach Partitionsgröße sortiert gespeichert.

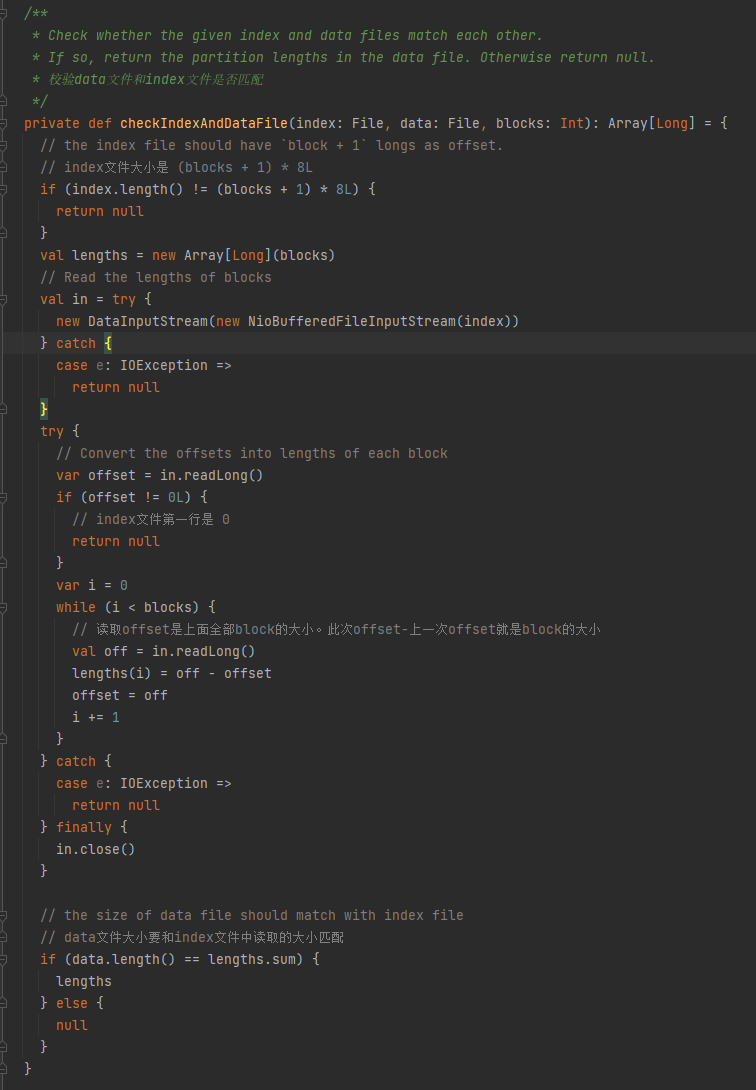
Überprüfen Sie, ob die Datendatei und die Indexdatei übereinstimmen. Wenn sie nicht übereinstimmen, wird null zurückgegeben. Wenn sie übereinstimmen, wird ein Array mit der Partitionsgröße zurückgegeben.
1. Die Größe der Indexdatei beträgt (Blöcke + 1) * 8L
2. Die erste Zeile der Indexdatei ist 0
3. Ermitteln Sie die Größe der Partition und schreiben Sie sie in Längen. Der Gesamtwert der Längen entspricht der Größe der Datendatei.
Wenn die oben genannten drei Bedingungen erfüllt sind, werden Längen zurückgegeben, andernfalls wird Null zurückgegeben.
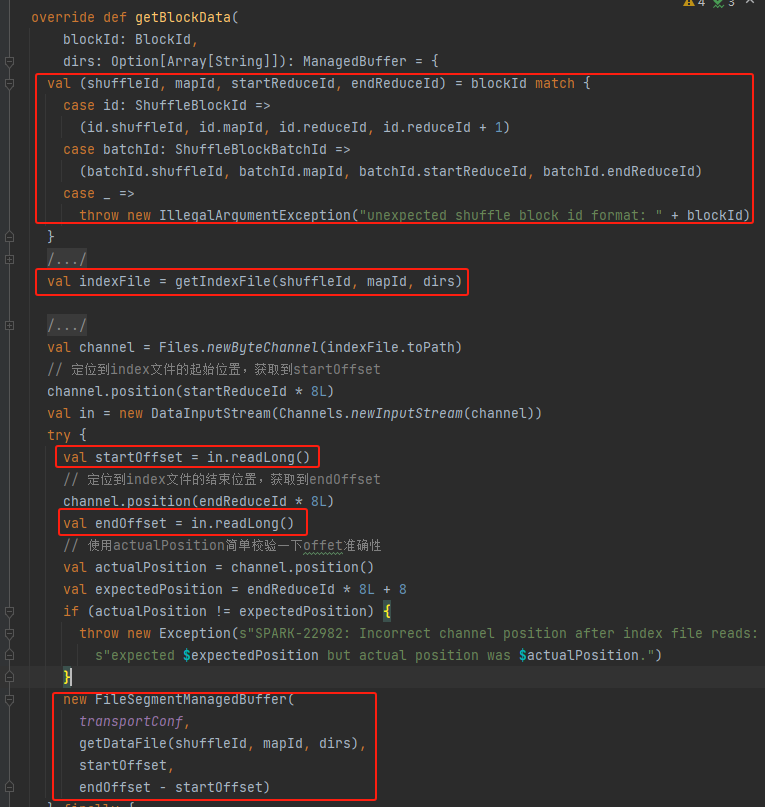
Rufen Sie ShuffleId, MapId, StartReduceId und EndReduceId ab
Holen Sie sich die Indexdatei
Lesen Sie den entsprechenden startOffset und endOffset
Verwenden Sie die Datendatei startOffset und endOffset, um FileSegmentManagedBuffer zu generieren und zurückzugeben

Er widmet sich seit mehr als dreißig Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. und hat viele Beiträge im Open-Source-Bereich geleistet eine Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
