내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
셔플 시스템의 입구입니다. ShuffleManager는 드라이버 및 실행 프로그램의 SparkEnv에 생성됩니다. 드라이버에 셔플을 등록하고 실행기에서 데이터를 읽고 씁니다.
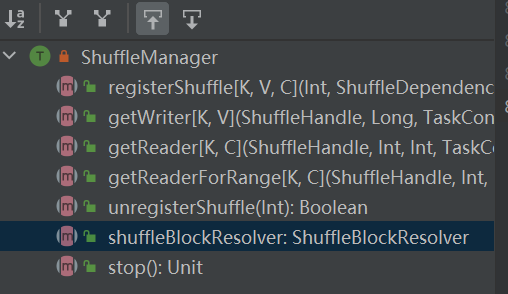
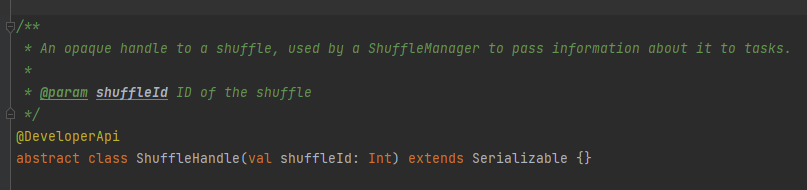
RegisterShuffle: 셔플 등록, shuffleHandle 반환
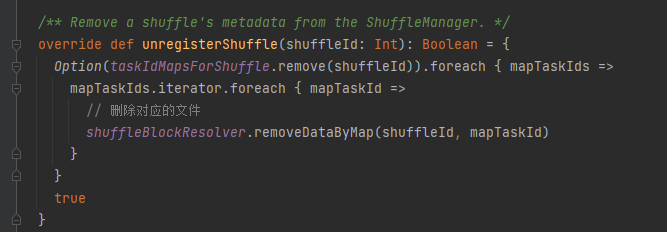
unregisterShuffle: 셔플 제거
shuffleBlockResolver: 셔플과 블록 간의 관계를 처리하는 데 사용되는 shuffleBlockResolver를 가져옵니다.
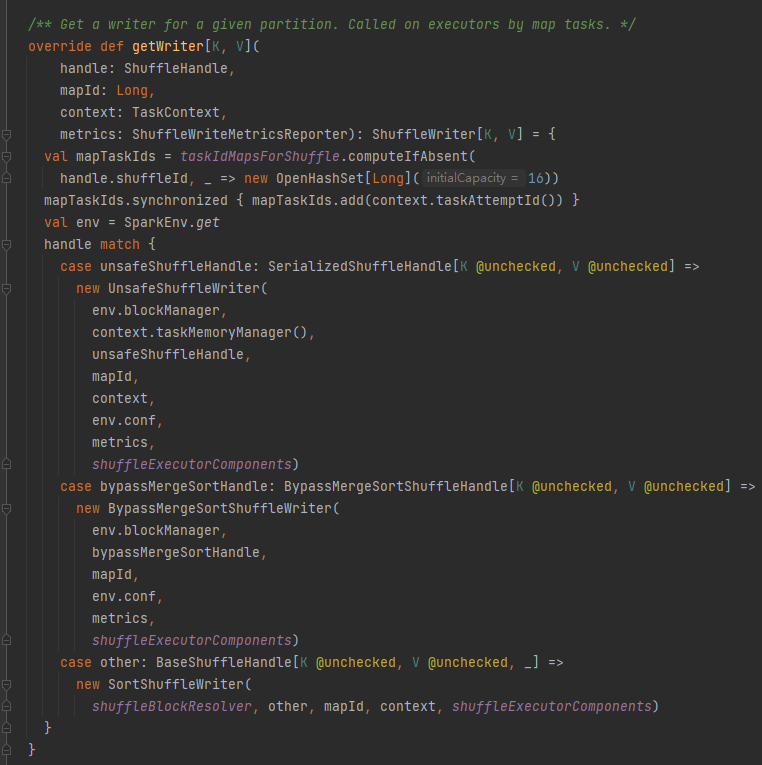
getWriter: 파티션에 해당하는 Writer를 가져와서 Executor의 맵 작업에서 호출합니다.
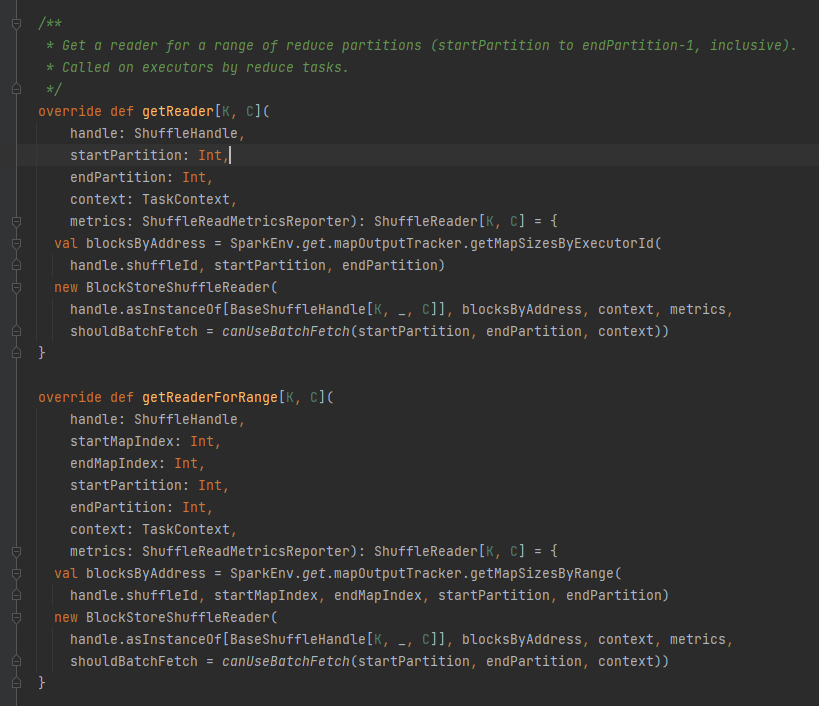
getReader, getReaderForRange: 범위 파티션의 리더를 가져와서 실행기의 축소 작업에서 호출합니다.
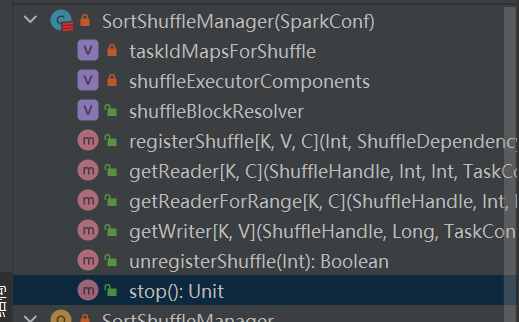
shuffleManager의 유일한 구현입니다.
정렬 기반 셔플에서는 수신 메시지가 파티션에 따라 정렬되고 최종적으로 별도의 파일이 출력됩니다.
감속기는 이 파일에서 데이터 영역을 읽습니다.
출력 파일이 너무 커서 메모리에 맞지 않는 경우 정렬된 중간 결과 파일이 디스크에 유출되고 이러한 중간 파일은 출력을 위해 최종 파일로 병합됩니다.
정렬 기반 셔플에는 두 가지 방법이 있습니다.
직렬 정렬의 장점
직렬화된 정렬 모드에서 셔플 작성기는 들어오는 메시지를 직렬화하고 이를 데이터 구조에 저장한 후 정렬합니다.
다양한 시나리오에 따라 해당 핸들을 선택하십시오. 우선순위 순서는 BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle입니다.
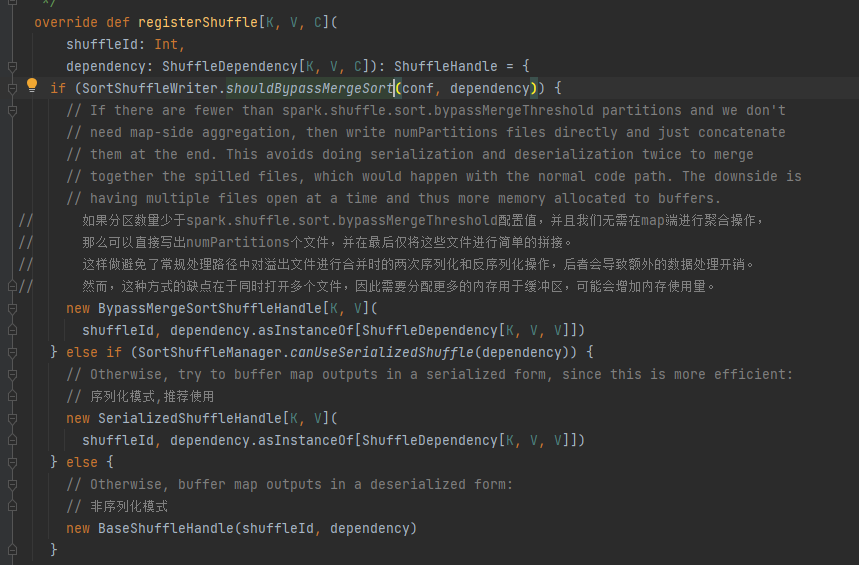
우회 조건: 맵사이드가 없으며 파티션 수가 _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_보다 작거나 같습니다.

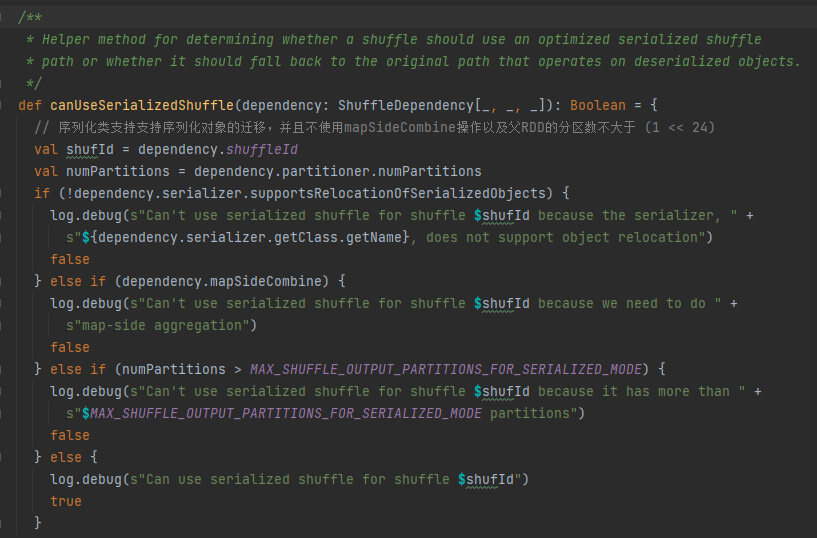
직렬화 핸들 조건: 직렬화 클래스는 직렬화된 개체의 마이그레이션을 지원하고, mapSideCombine 작업을 사용하지 않으며, 상위 RDD의 파티션 수가 (1 << 24)보다 크지 않습니다.
먼저 이 셔플을 캐시하고 정보를 taskIdMapsForShuffle_에 매핑합니다.
셔플에 해당하는 핸들을 기준으로 해당 작가를 선택합니다.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle은 해당 셔플과 셔플 해당 맵에 의해 생성된 파일을 제거합니다.
셔플 파일에 해당하는 모든 블록 주소, 즉 blockByAddress를 가져옵니다.
BlockStoreShuffleReader 객체를 생성하고 반환합니다.
주로 셔플의 매개변수를 전달하는 데 사용되며, 어떤 작가를 선택할지 표시하는 표시이기도 합니다.


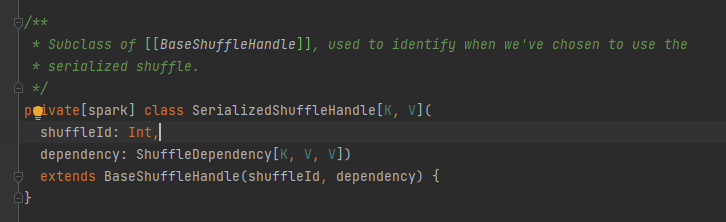
맵 작업 출력 메시지를 담당하는 추상 클래스입니다. 기본 메서드는 쓰기이며 세 가지 구현 클래스가 있습니다.
나중에 따로 분석하겠습니다.
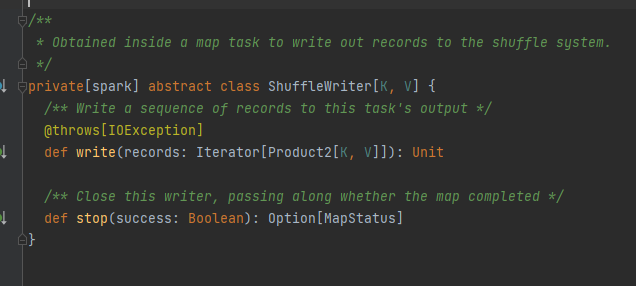
특성상, 구현 클래스는 mapId, ReduceId, shuffleId를 기반으로 해당 블록 데이터를 얻을 수 있습니다.
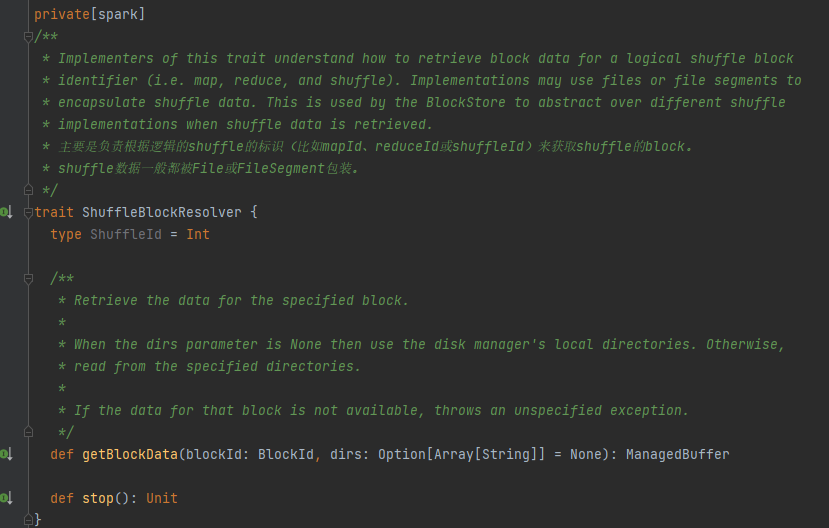
ShuffleBlockResolver의 유일한 구현 클래스입니다.
동일한 맵 작업에서 셔플 블록 데이터에 대한 논리 블록과 실제 파일 위치 간의 매핑을 생성하고 유지합니다.
동일한 맵 작업에 속하는 셔플 블록 데이터는 통합된 데이터 파일에 저장됩니다.
데이터 파일에 있는 이러한 데이터 블록의 오프셋은 인덱스 파일에 별도로 저장됩니다.
.data는 데이터 파일 접미사입니다.
.index는 인덱스 파일 접미사입니다.
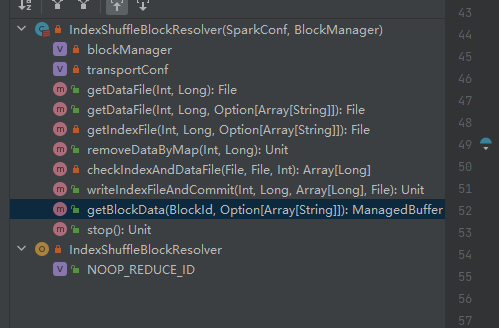
데이터 파일을 가져옵니다.
ShuffleDataBlockId를 생성하고 blockManager.diskBlockManager.getFile 메서드를 호출하여 파일을 가져옵니다.
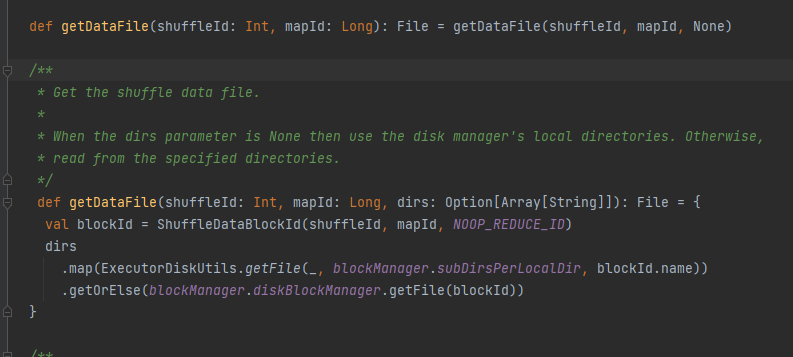
getDataFile 과 유사함
ShuffleIndexBlockId를 생성하고 blockManager.diskBlockManager.getFile 메서드를 호출하여 파일을 가져옵니다.

shuffleId 및 mapId를 기반으로 데이터 파일과 인덱스 파일을 가져온 후 삭제합니다.
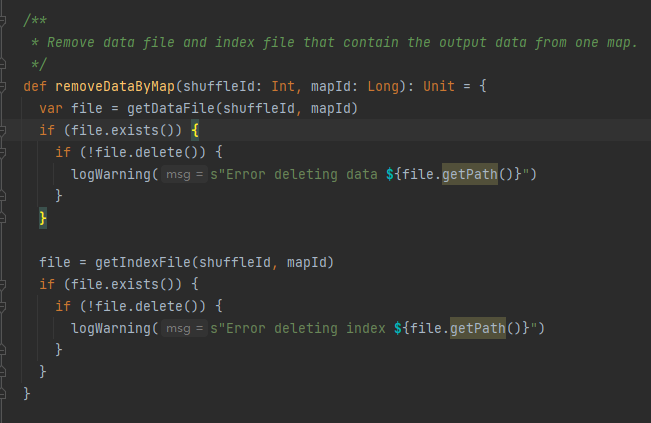
mapId 및 shuffleId에 따라 해당 데이터 파일과 인덱스 파일을 얻습니다.
데이터 파일과 인덱스 파일이 존재하는지 확인하고 일치하는지 확인하고 직접 반환합니다.
일치하지 않으면 새 인덱스 임시 파일이 생성됩니다. 그런 다음 생성된 인덱스 파일과 데이터 파일의 이름을 바꾸고 반환합니다.
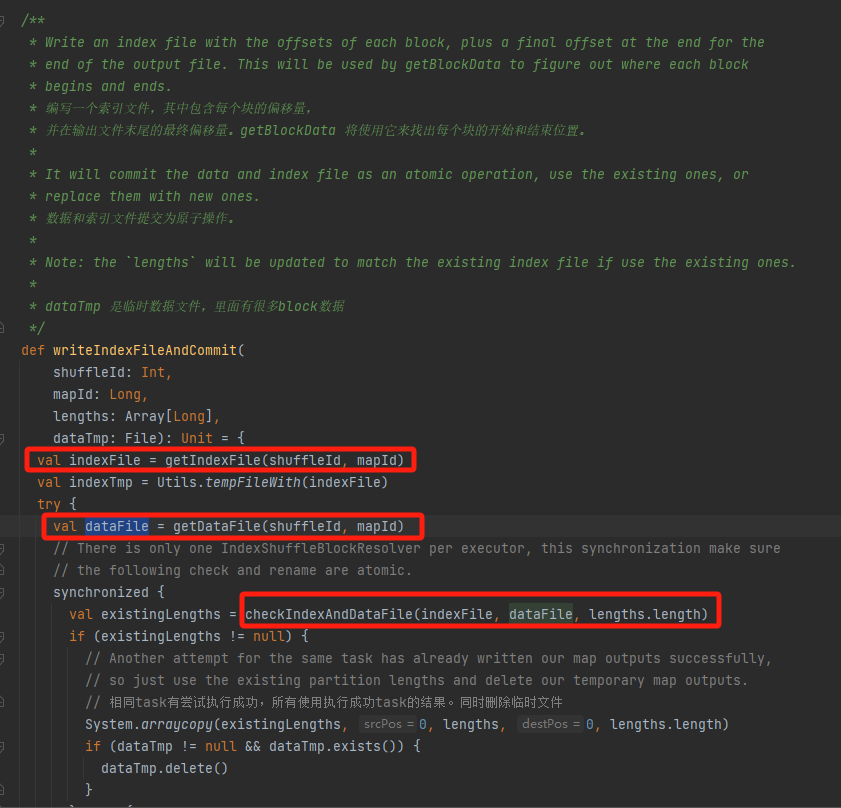

Shuffle에 세 개의 파티션이 있고 해당 데이터 크기가 각각 1000, 1500, 2500이라고 가정합니다.
인덱스 파일에서 첫 번째 줄은 0이고, 두 번째 줄은 1000, 세 번째 줄은 1000+1500=2500, 세 번째 줄은 2500+2500=5000입니다.
데이터 파일은 파티션 크기별로 정렬되어 저장됩니다.

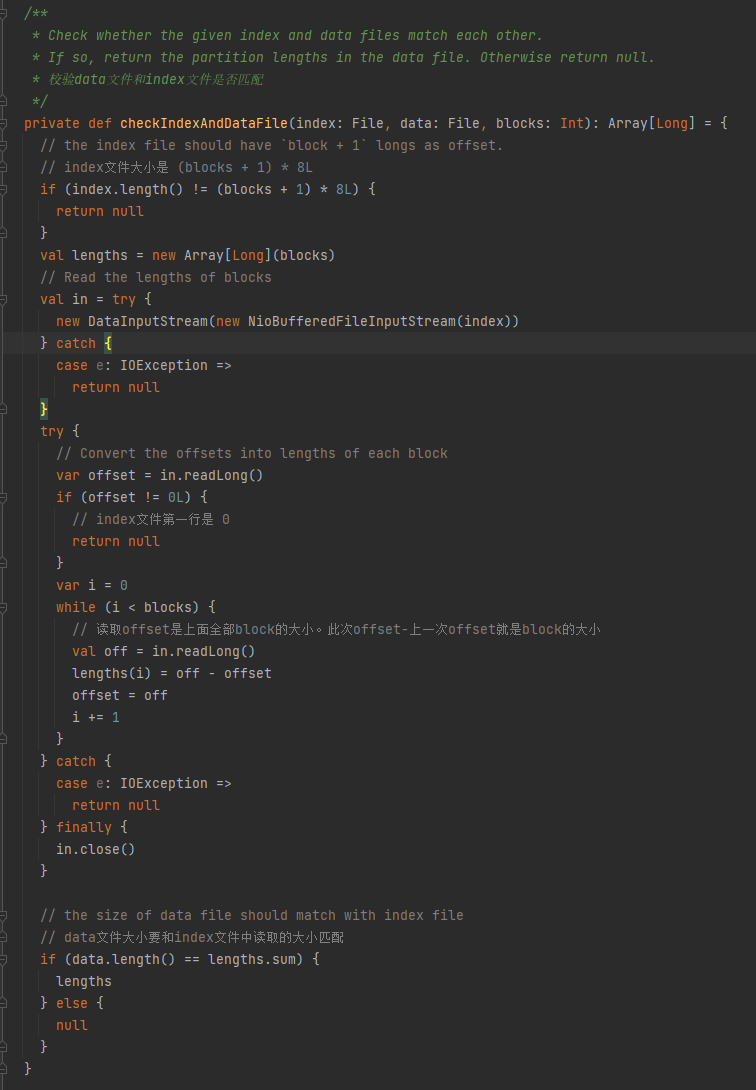
데이터 파일과 인덱스 파일이 일치하는지 확인합니다. 일치하지 않으면 null이 반환됩니다. 일치하면 파티션 크기의 배열이 반환됩니다.
1.인덱스 파일 크기는 (블록 + 1) * 8L입니다.
2.인덱스 파일의 첫 번째 줄은 0입니다.
3. 파티션의 크기를 가져와서 길이로 기록합니다. 길이의 요약 값은 데이터 파일의 크기와 같습니다.
위의 세 가지 조건이 충족되면 길이가 반환되고, 그렇지 않으면 null이 반환됩니다.
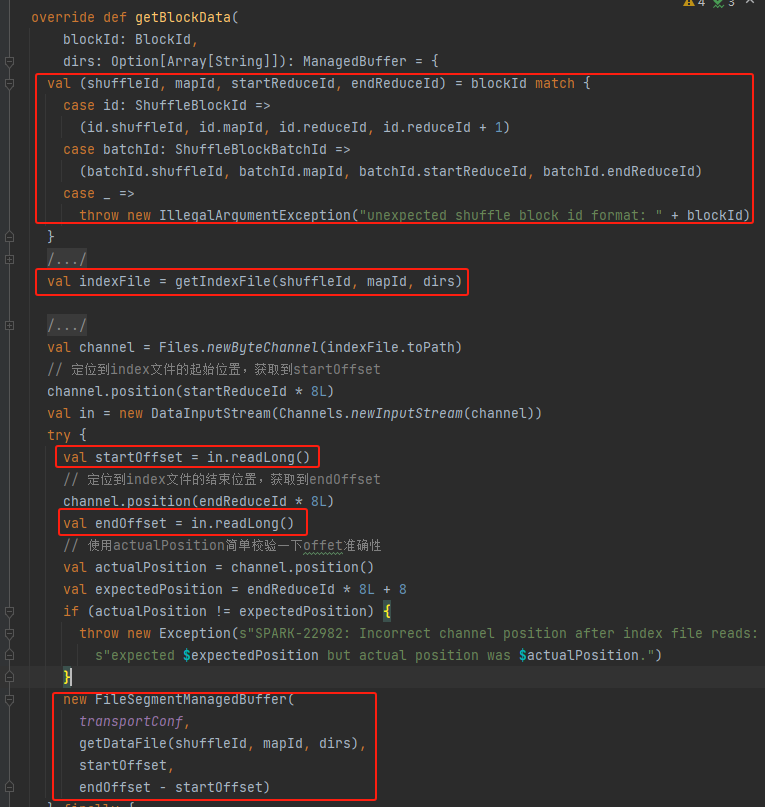
shuffleId, mapId, startReduceId, endReduceId 가져오기
인덱스 파일 가져오기
해당 startOffset 및 endOffset을 읽습니다.
데이터 파일 startOffset, endOffset을 사용하여 FileSegmentManagedBuffer를 생성하고 반환

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com