2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Sisäänkäynti sekoitusjärjestelmään. ShuffleManager luodaan sparkEnv:ssä ajurissa ja executorissa. Rekisteröi satunnaistoisto ajurissa ja lue ja kirjoita tietoja executorissa.
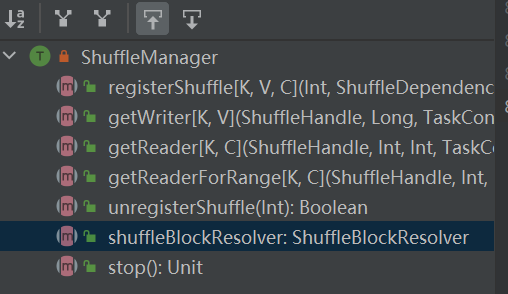
registerShuffle: rekisteröi sekoitus, return shuffleHandle
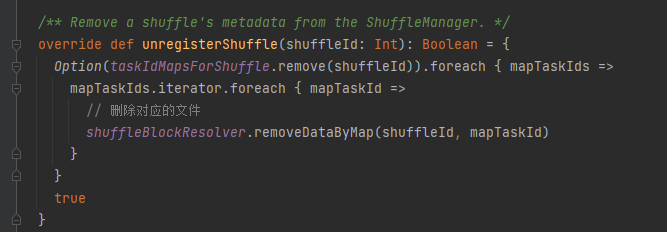
unregisterShuffle: poista sekoitus
shuffleBlockResolver: Hanki shuffleBlockResolver, jota käytetään käsittelemään sekoituksen ja lohkon välistä suhdetta
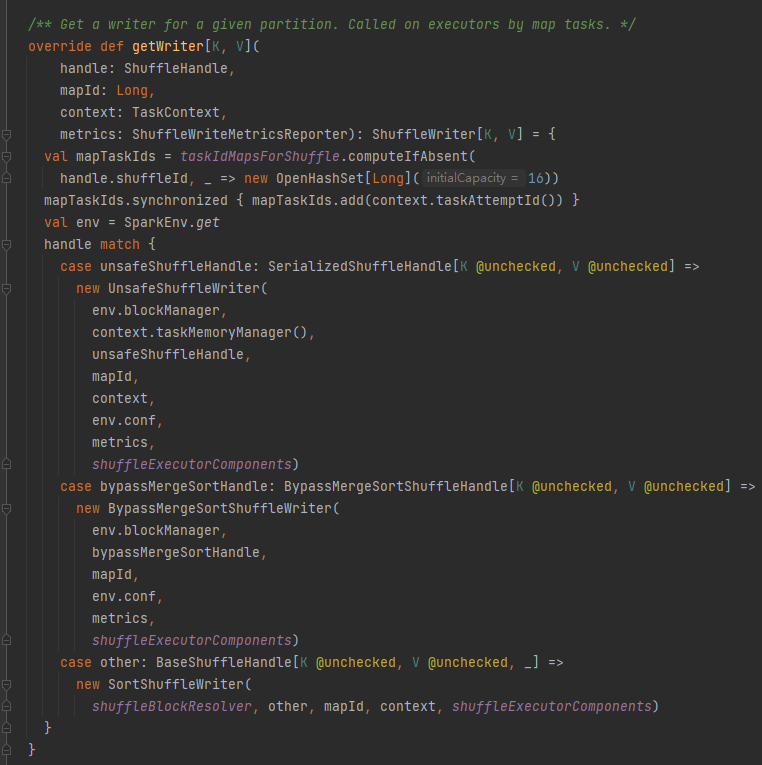
getWriter: Hanki osiota vastaava kirjoittaja ja kutsu se suorittajan karttatehtävässä
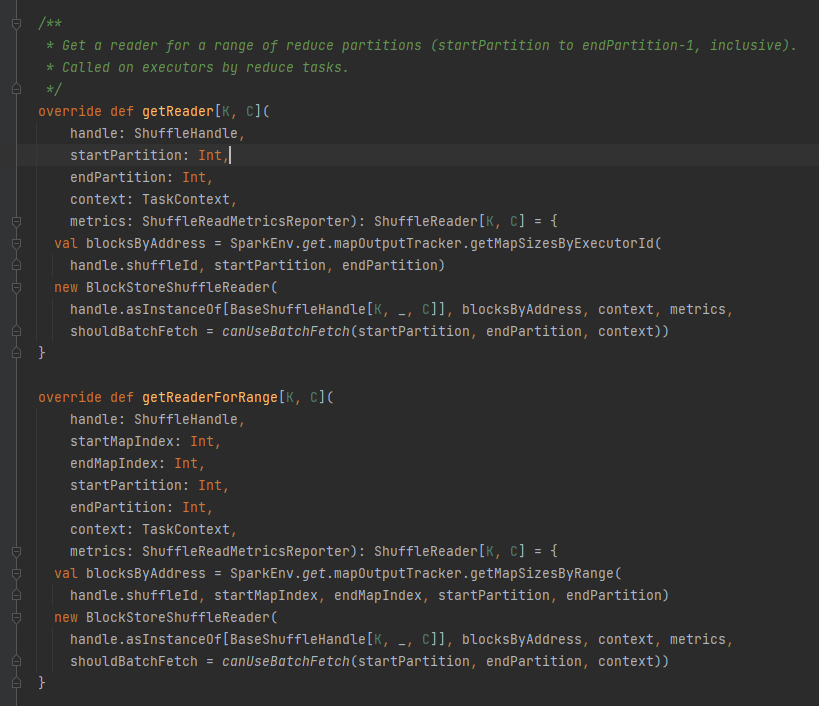
getReader, getReaderForRange: Hanki alueosion lukija ja kutsu se suorittajan redusointitehtävässä
Onko shuffleManagerin ainoa toteutus.
Lajitteluperusteisessa sekoitustilassa saapuvat viestit lajitellaan osioiden mukaan ja lopuksi tulostetaan erillinen tiedosto.
Vähentäjä lukee data-alueen tästä tiedostosta.
Kun tulostiedosto on liian suuri mahtumaan muistiin, lajiteltu välitulostiedosto valuu levylle, ja nämä välitiedostot yhdistetään lopulliseksi tiedostoksi tulostusta varten.
Lajitteluperusteisessa satunnaistoistossa on kaksi tapaa:
Sarjalajittelun edut
Sarjamuotoisessa lajittelutilassa satunnaiskirjoittaja sarjoittaa saapuvat viestit, tallentaa ne tietorakenteeseen ja lajittelee ne.
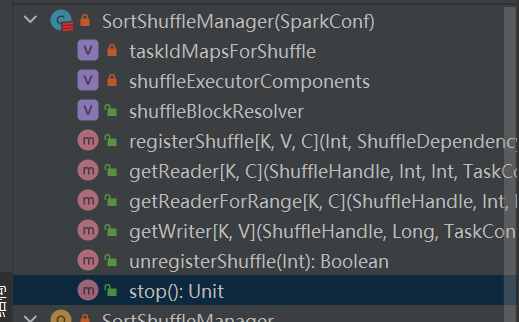
Valitse vastaava kahva eri skenaarioiden mukaan. Prioriteettijärjestys on BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
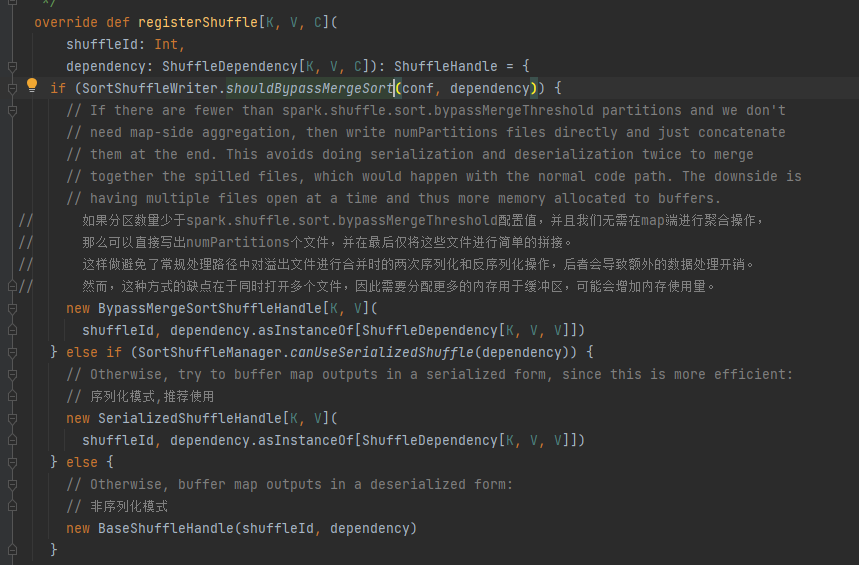
Ohitusehto: ei karttasivua, osioiden määrä on pienempi tai yhtä suuri kuin _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

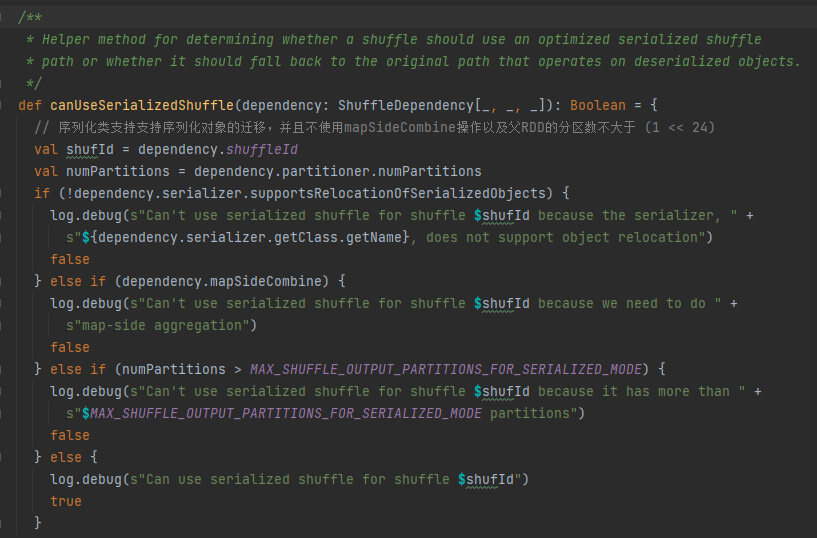
Sarjastamiskahvan ehdot: Serialisointiluokka tukee sarjoitettujen objektien siirtoa, ei käytä mapSideCombine-toimintoa, ja emo-RDD:n osioiden määrä ei ole suurempi kuin (1 << 24)
Tallenna tämä sekoitus ensin välimuistiin ja yhdistä tiedot kohteeseen taskIdMapsForShuffle_
Valitse vastaava kirjoittaja sekoitusta vastaavan kahvan perusteella.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle-> UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle poistaa vastaavan sekoituksen ja sekoituksen luomat tiedostot vastaavan kartan
Hanki kaikki lohkoosoitteet, jotka vastaavat sekoitustiedostoa, eli blocksByAddress.
Luo BlockStoreShuffleReader-objektin ja palauttaa sen.
Sitä käytetään pääasiassa sekoitusparametrien välittämiseen, ja se on myös merkki valitsemaan kirjoittaja.
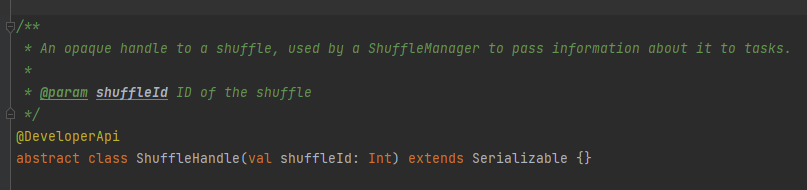


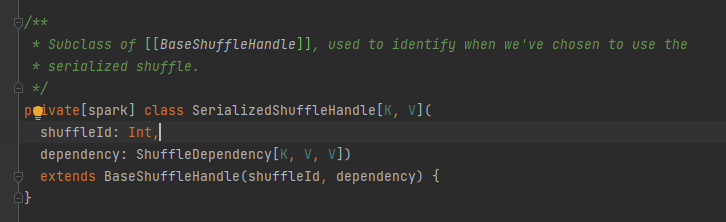
Abstrakti luokka, joka vastaa karttatehtävän lähtösanomista Päämenetelmä on kirjoitus, ja toteutusluokkaa on kolme
Analysoidaan myöhemmin erikseen.
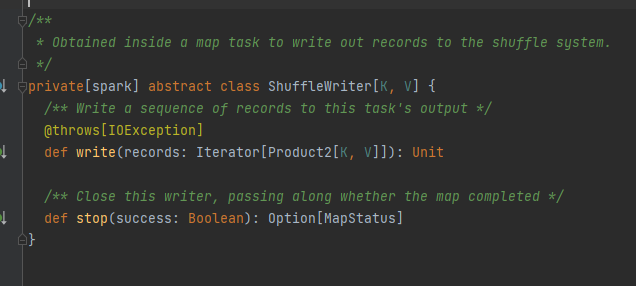
Ominaisuus, toteutusluokka voi saada vastaavat lohkotiedot mapId:n, reductionId:n, shuffleId:n perusteella.
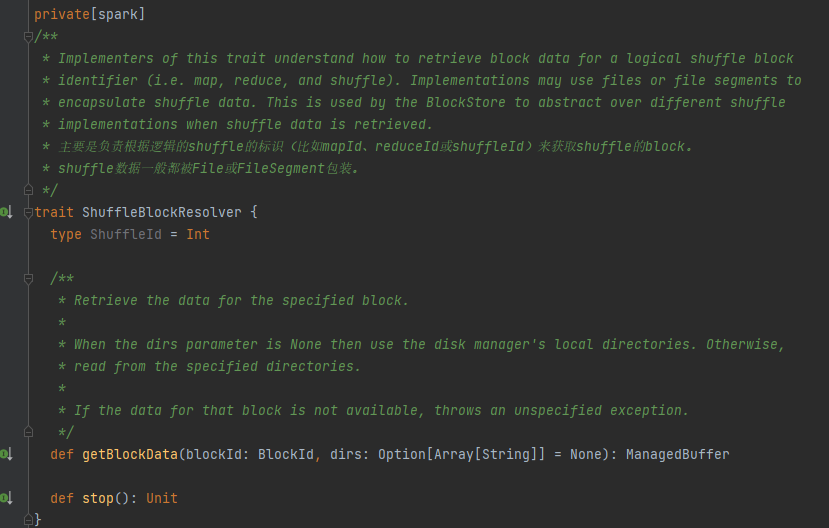
ShuffleBlockResolverin ainoa toteutusluokka.
Luo ja ylläpidä kartoituksia loogisten lohkojen ja fyysisten tiedostojen välillä samasta karttatehtävästä peräisin olevalle sekoituslohkodatalle.
Samaan karttatehtävään kuuluvat sekoituslohkotiedot tallennetaan yhdistettyyn tietotiedostoon.
Näiden datalohkojen siirtymät datatiedostossa tallennetaan erikseen indeksitiedostoon.
.data on datatiedoston pääte
.index on hakemistotiedoston pääte
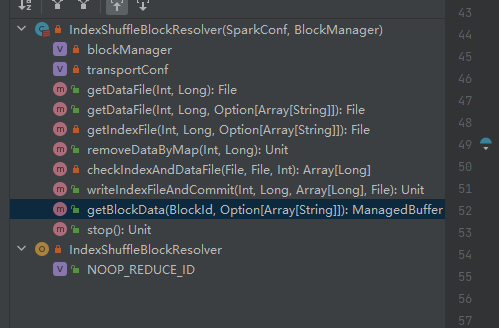
Hanki datatiedosto.
Luo ShuffleDataBlockId ja kutsu menetelmä blockManager.diskBlockManager.getFile saadaksesi tiedoston
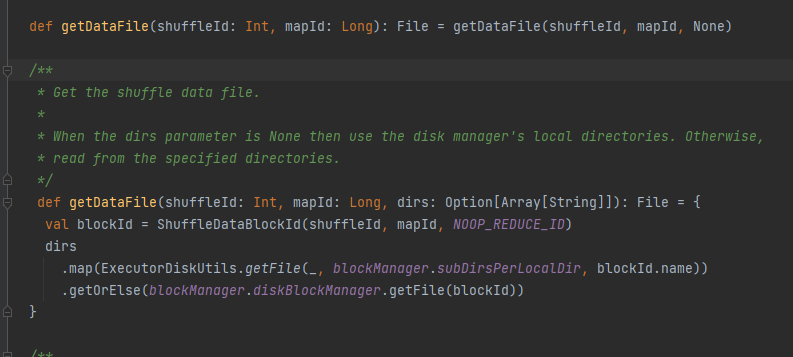
Samanlainen kuin getDataFile
Luo ShuffleIndexBlockId ja kutsu menetelmä blockManager.diskBlockManager.getFile saadaksesi tiedoston

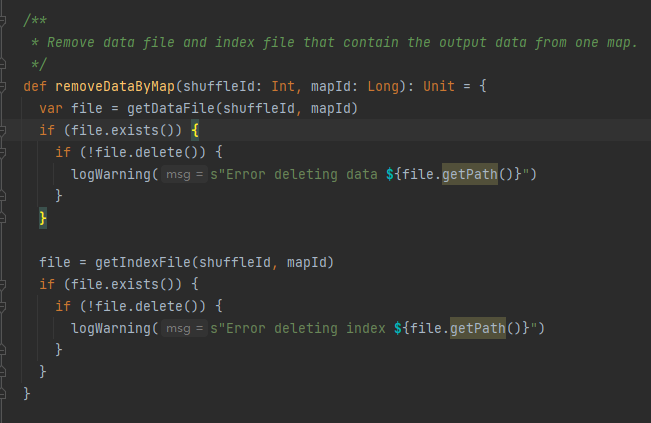
Hanki datatiedosto ja hakemistotiedosto shuffleId- ja mapId-tunnisteisiin ja poista ne sitten
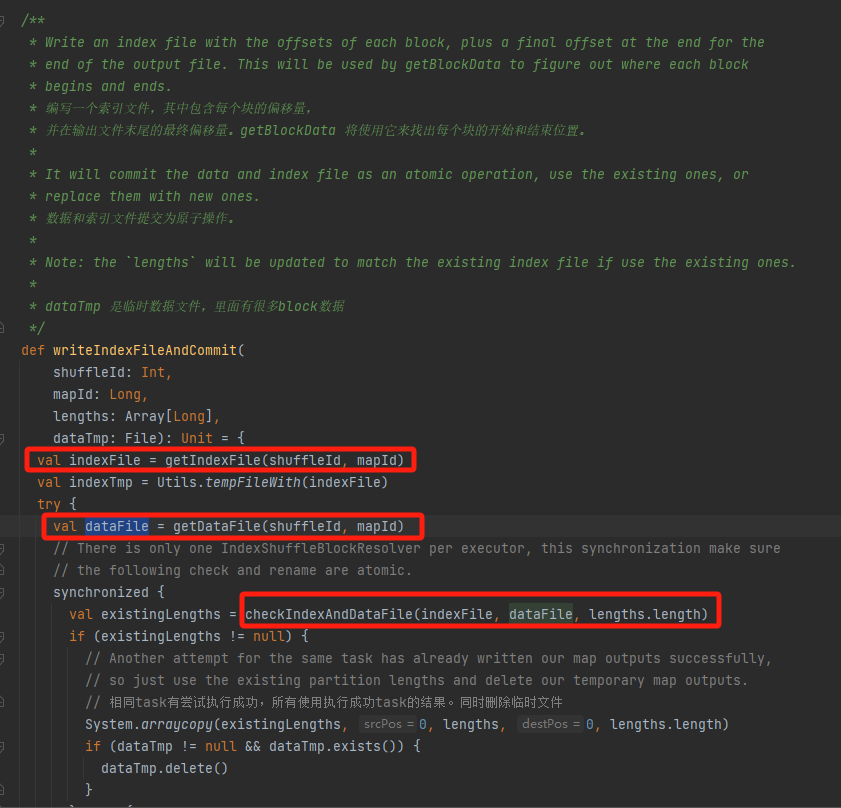
Hanki vastaava datatiedosto ja indeksitiedosto mapId:n ja shuffleId:n mukaan.
Tarkista, ovatko datatiedosto ja hakemistotiedosto olemassa ja täsmäävät, ja palaa suoraan.
Jos se ei täsmää, uusi väliaikainen hakemistotiedosto luodaan. Nimeä sitten luotu hakemistotiedosto ja datatiedosto uudelleen ja palauta.

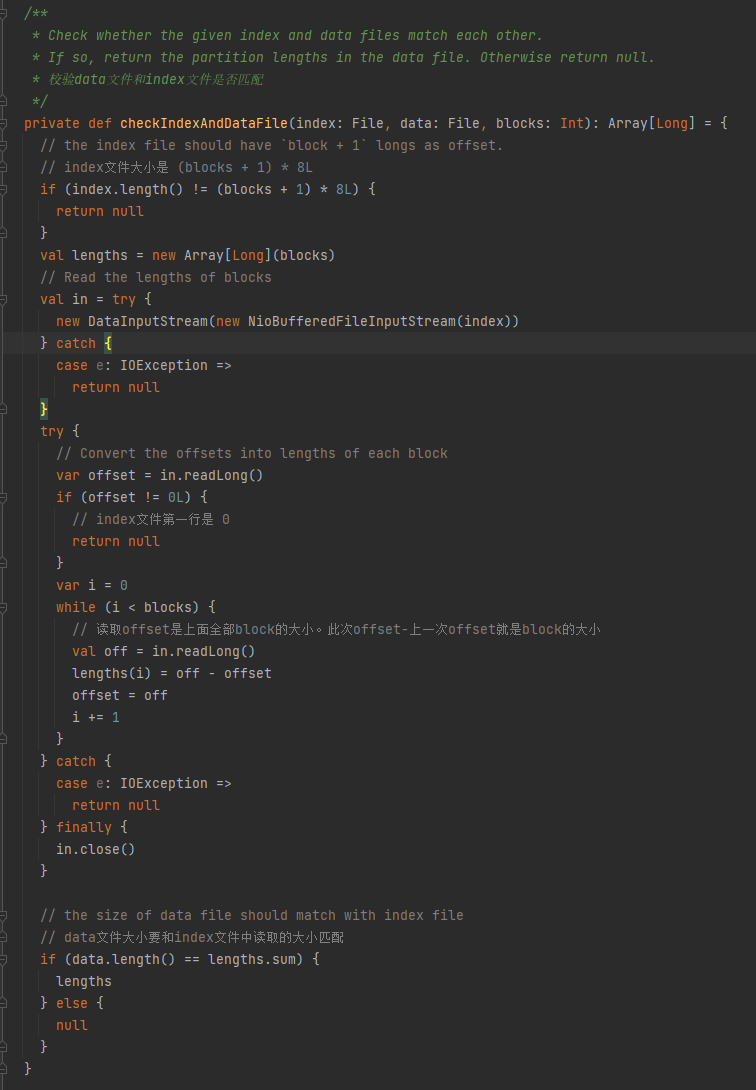
Oletetaan, että sekoitustilassa on kolme osiota ja vastaavat tietokoot ovat 1000, 1500 ja 2500.
Indeksitiedoston ensimmäinen rivi on 0, jota seuraa osion datan kumulatiivinen arvo. Toinen rivi on 1000, kolmas rivi on 1000+1500=2500 ja kolmas rivi on 2500+2500=5000.
Datatiedostot tallennetaan osion koon mukaan lajiteltuina.

Tarkista, vastaavatko datatiedosto ja hakemistotiedosto, jos ne eivät täsmää, palautetaan osion koko.
1. Hakemistotiedoston koko on (lohkoja + 1) * 8L
2. Hakemistotiedoston ensimmäinen rivi on 0
3. Selvitä osion koko ja kirjoita se pituuksiin. Pituuksien yhteenvetoarvo on yhtä suuri kuin datatiedoston koko.
Jos yllä olevat kolme ehtoa täyttyvät, pituus palautetaan, muussa tapauksessa null.
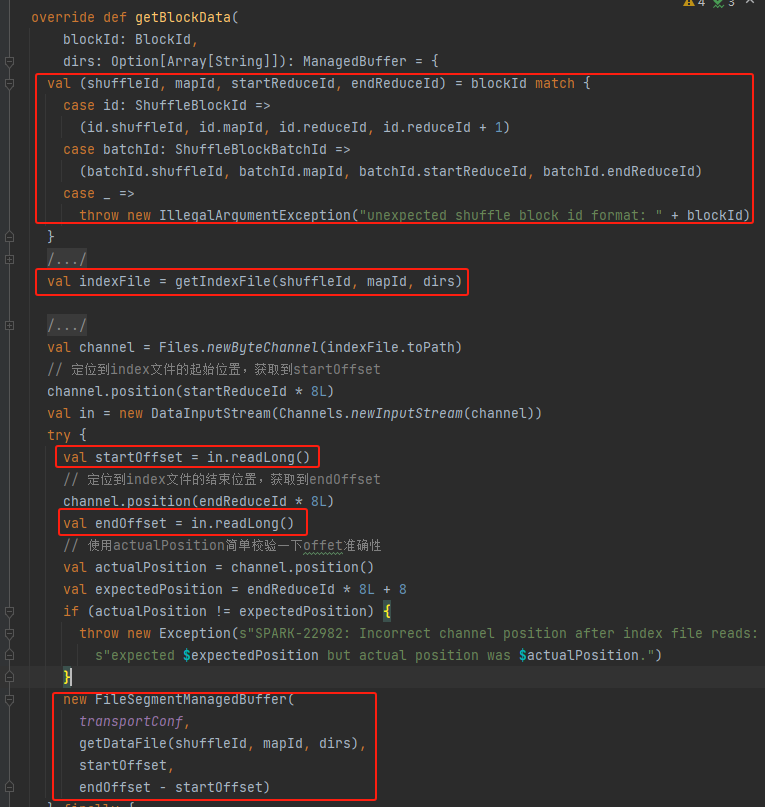
Hanki shuffleId, mapId, startReduceId, endReduceId
Hanki hakemistotiedosto
Lue vastaava startOffset ja endOffset
Käytä tiedostoa, startOffset, endOffset FileSegmentManagedBufferin luomiseen ja palautukseen

Hän on omistautunut teknologian tutkimukselle yli kolmenkymmenen vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne., ja hän on tehnyt monia panoksia avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehityksen ongelmia tulevaa käyttöä varten
