minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
A entrada para o sistema aleatório. ShuffleManager é criado em sparkEnv no driver e no executor. Registre o shuffle no driver e leia e grave os dados no executor.
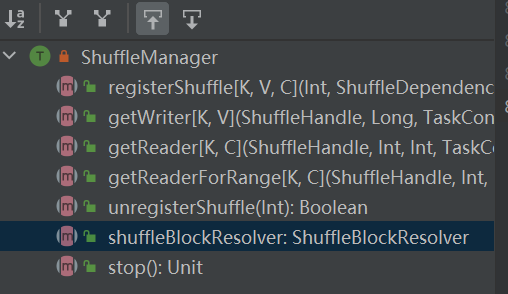
RegisterShuffle: registra shuffle, retorna shuffleHandle
cancelar registroShuffle: remover embaralhamento
shuffleBlockResolver: Obtenha shuffleBlockResolver, usado para lidar com o relacionamento entre embaralhar e bloquear
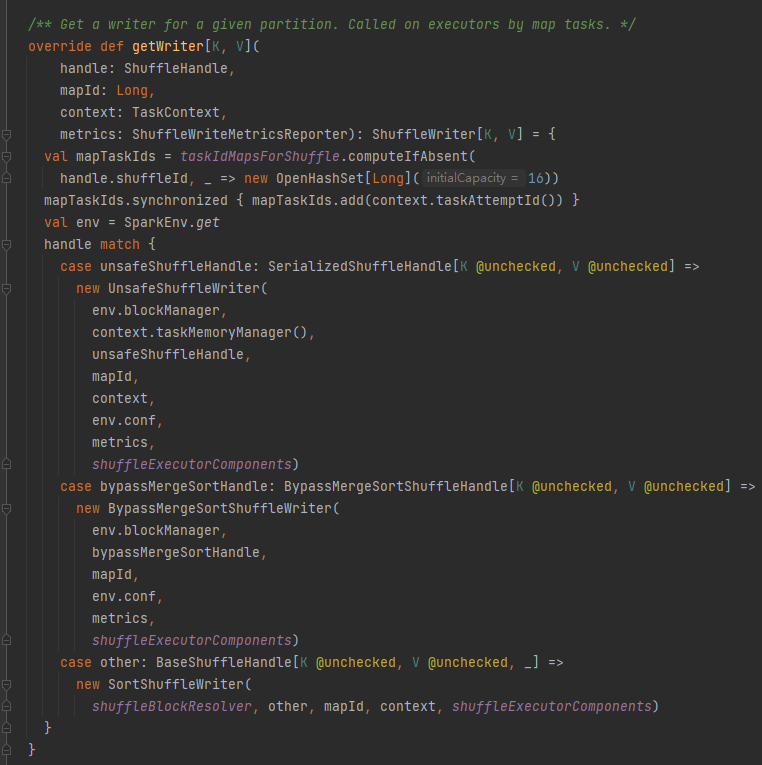
getWriter: Obtenha o gravador correspondente à partição e chame-o na tarefa de mapa do executor
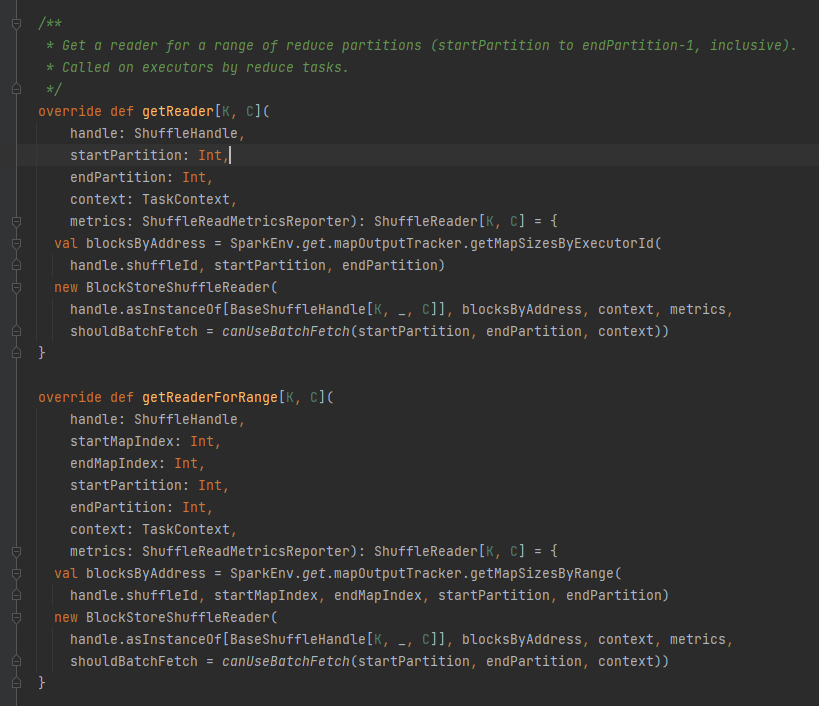
getReader, getReaderForRange: obtém o leitor de uma partição de intervalo e chama-o na tarefa de redução do executor
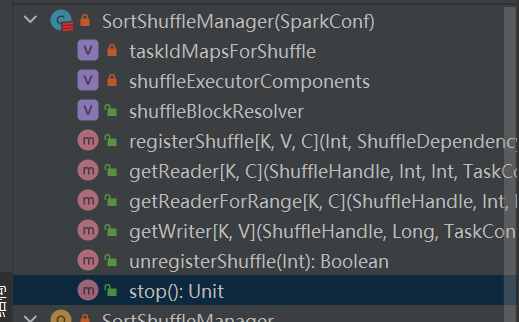
É a única implementação do shuffleManager.
Em uma ordem aleatória baseada em classificação, as mensagens recebidas são classificadas de acordo com as partições e, finalmente, um arquivo separado é gerado.
O redutor lerá uma região de dados deste arquivo.
Quando o arquivo de saída for muito grande para caber na memória, um arquivo de resultado intermediário classificado será espalhado no disco e esses arquivos intermediários serão mesclados em um arquivo final para saída.
O shuffle baseado em classificação tem dois métodos:
Vantagens da classificação serializada
No modo de classificação serializada, o gravador aleatório serializa as mensagens recebidas, salva-as em uma estrutura de dados e as classifica.
Escolha a alça correspondente de acordo com diferentes cenários. A ordem de prioridade é BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
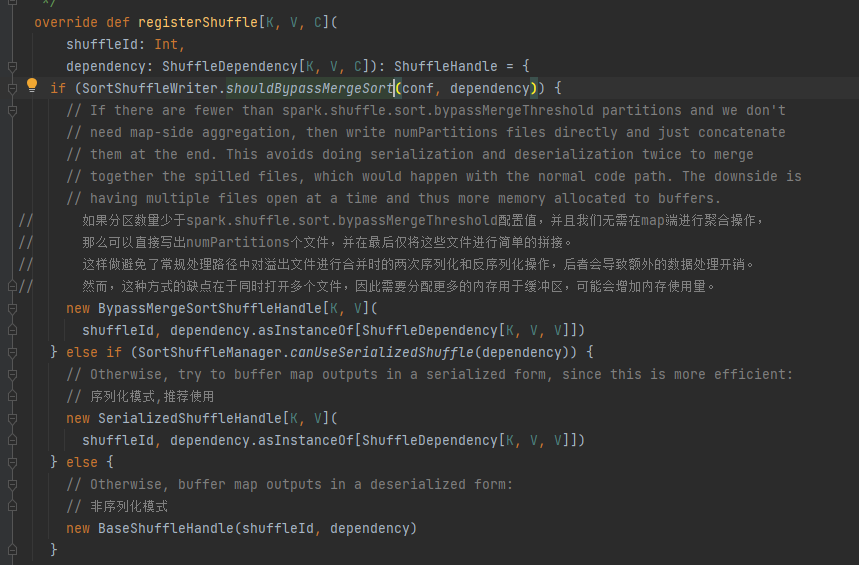
Condição de desvio: sem mapa, o número de partições é menor ou igual a _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

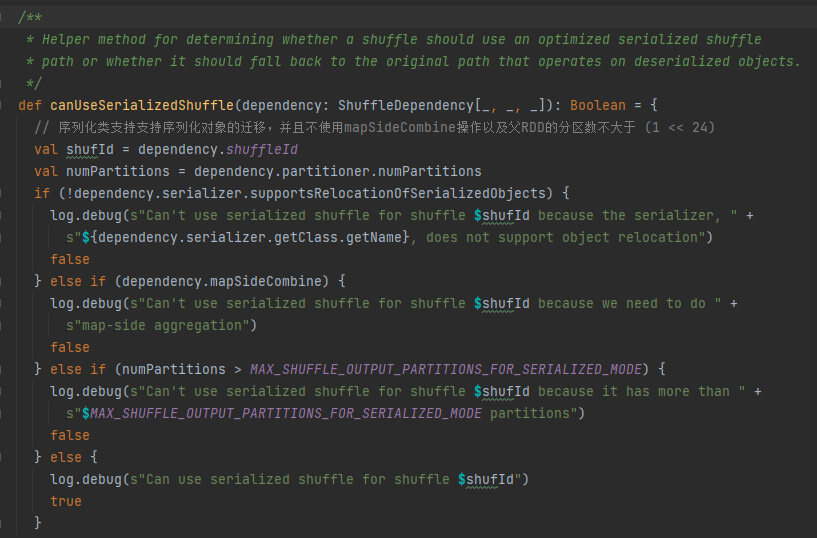
Condições de manipulação de serialização: a classe de serialização suporta a migração de objetos serializados, não usa a operação mapSideCombine e o número de partições do RDD pai não é maior que (1 << 24)
Primeiro armazene em cache esse embaralhamento e mapeie as informações em taskIdMapsForShuffle_
Selecione o escritor correspondente com base no identificador correspondente ao embaralhamento.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
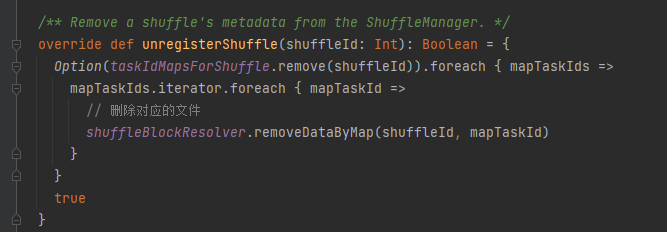
taskIdMapsForShuffle remove o embaralhamento correspondente e os arquivos gerados pelo mapa correspondente do embaralhamento
Obtenha todos os endereços de bloco correspondentes ao arquivo aleatório, ou seja, blocksByAddress.
Cria um objeto BlockStoreShuffleReader e o retorna.
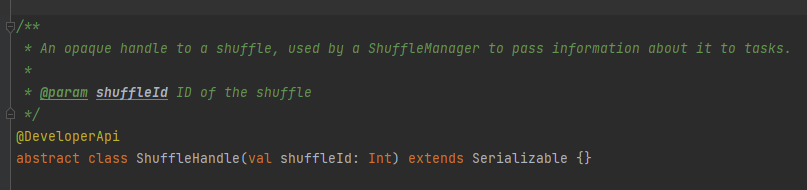
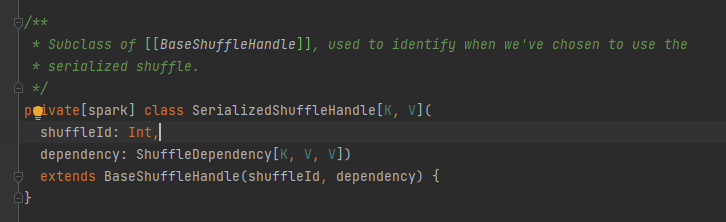
É usado principalmente para passar os parâmetros do shuffle, e também é uma marca para marcar qual escritor escolher.


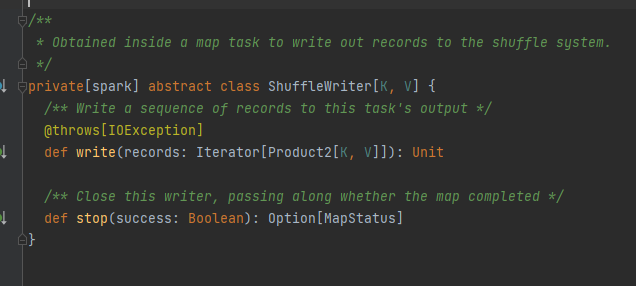
Classe abstrata, responsável pelas mensagens de saída da tarefa de mapeamento. O método principal é write e existem três classes de implementação.
Será analisado separadamente posteriormente.
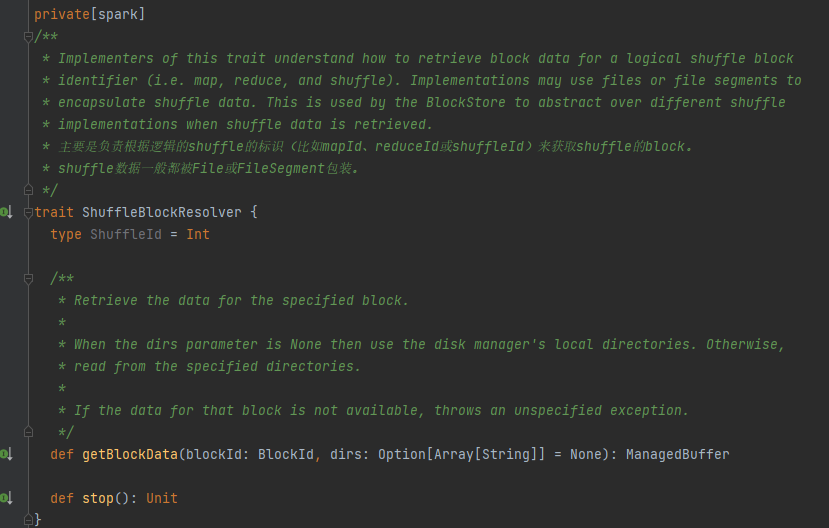
Trait, a classe de implementação pode obter os dados do bloco correspondente com base em mapId, reduzId, shuffleId.
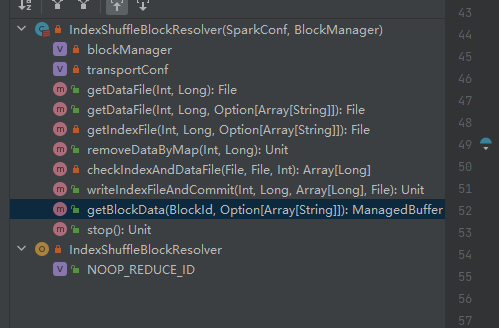
A única classe de implementação de ShuffleBlockResolver.
Crie e mantenha mapeamentos entre blocos lógicos e locais de arquivos físicos para embaralhar dados de bloco da mesma tarefa de mapa.
Os dados do bloco aleatório pertencentes à mesma tarefa de mapa serão armazenados em um arquivo de dados consolidados.
Os deslocamentos desses blocos de dados no arquivo de dados são armazenados separadamente em um arquivo de índice.
.data é o sufixo do arquivo de dados
.index é o sufixo do arquivo de índice
Obtenha o arquivo de dados.
Gere ShuffleDataBlockId e chame o método blockManager.diskBlockManager.getFile para obter o arquivo
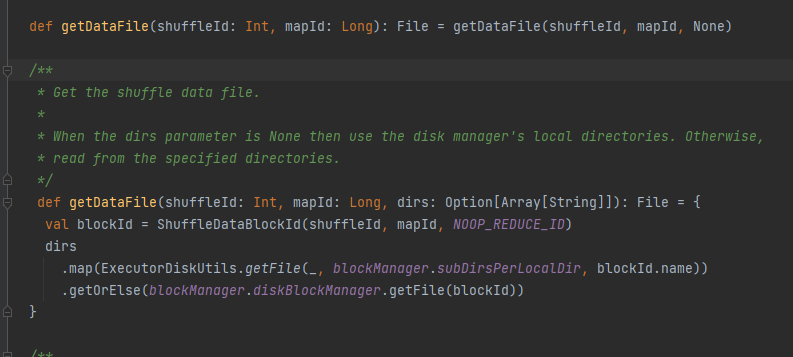
Semelhante a getDataFile
Gere ShuffleIndexBlockId e chame o método blockManager.diskBlockManager.getFile para obter o arquivo

Obtenha o arquivo de dados e o arquivo de índice com base em shuffleId e mapId e exclua-os
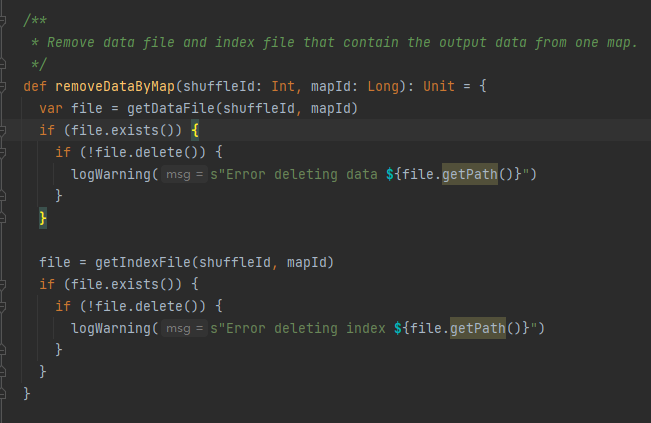
Obtenha o arquivo de dados e o arquivo de índice correspondentes de acordo com mapId e shuffleId.
Verifique se o arquivo de dados e o arquivo de índice existem e correspondem e retorne diretamente.
Se não corresponder, um novo arquivo temporário de índice será gerado. Em seguida, renomeie o arquivo de índice gerado e o arquivo de dados e retorne.
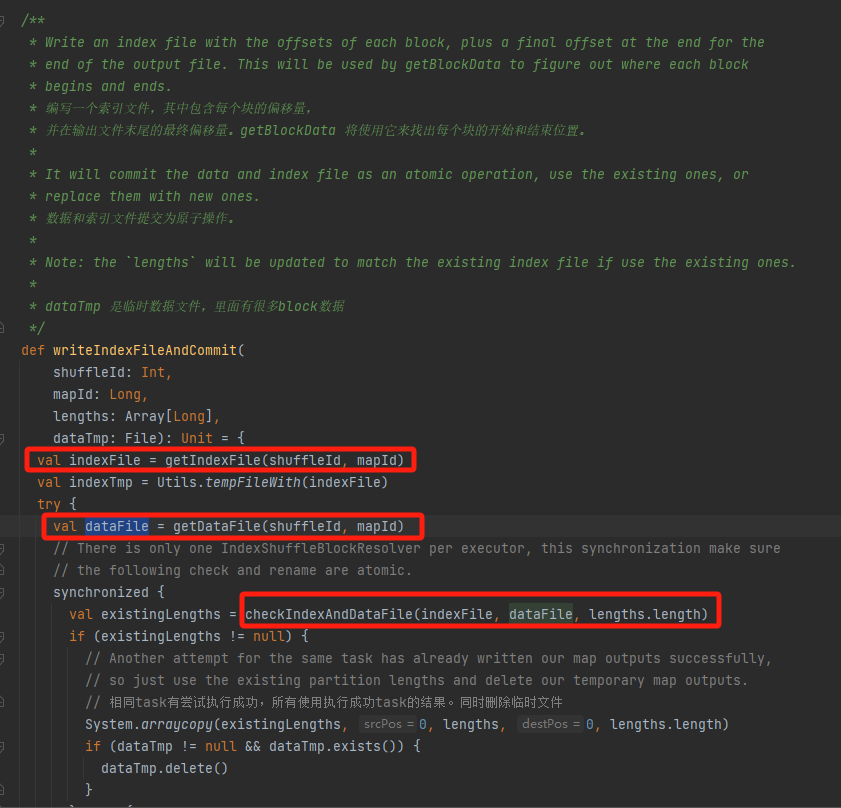

Suponha que o shuffle tenha três partições e os tamanhos de dados correspondentes sejam 1.000, 1.500 e 2.500, respectivamente.
No arquivo de índice, a primeira linha é 0, seguida pelo valor cumulativo dos dados da partição. A segunda linha é 1000, a terceira linha é 1000+1500=2500 e a terceira linha é 2500+2500=5000.
Os arquivos de dados são armazenados classificados por tamanho de partição.

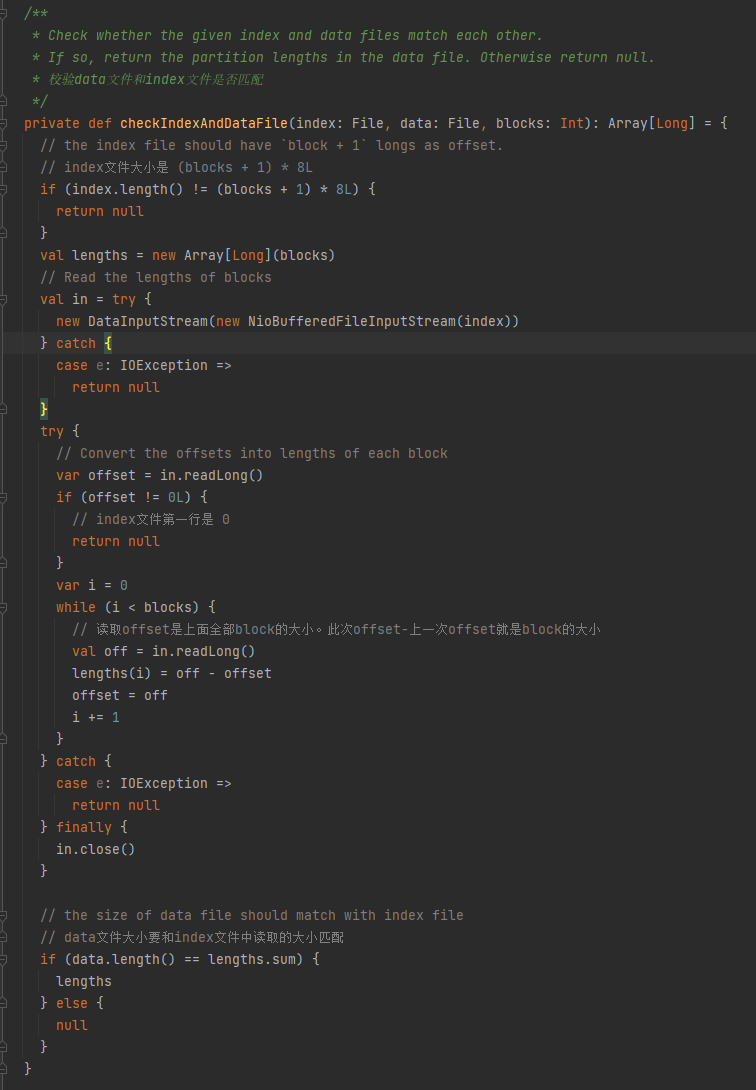
Verifique se o arquivo de dados e o arquivo de índice correspondem. Se não corresponderem, será retornado nulo. Se corresponderem, uma matriz de tamanho de partição será retornada.
1. O tamanho do arquivo de índice é (blocos + 1) * 8L
2.A primeira linha do arquivo de índice é 0
3. Obtenha o tamanho da partição e escreva-o em comprimentos. O valor resumido dos comprimentos é igual ao tamanho do arquivo de dados.
Se as três condições acima forem atendidas, os comprimentos serão retornados, caso contrário, será retornado nulo.
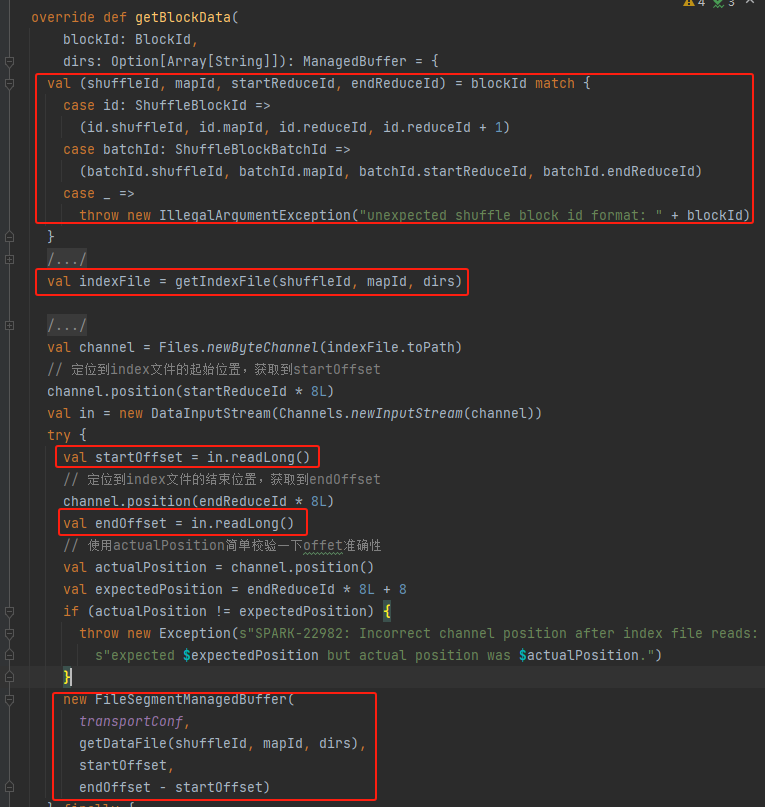
Obtenha shuffleId, mapId, startReduceId, endReduceId
Obtenha o arquivo de índice
Leia o startOffset e endOffset correspondentes
Use arquivo de dados, startOffset, endOffset para gerar FileSegmentManagedBuffer e retornar

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]