τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Η είσοδος στο σύστημα ανακατέματος. Το ShuffleManager δημιουργείται στο sparkEnv στο πρόγραμμα οδήγησης και στον εκτελεστή. Καταχωρίστε το shuffle στο πρόγραμμα οδήγησης και διαβάστε και γράψτε δεδομένα στον εκτελεστή.
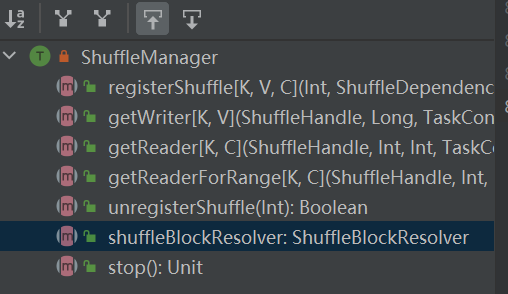
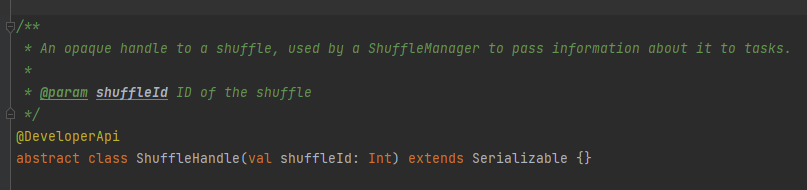
registerShuffle: καταχώριση shuffle, επιστροφή shuffleHandle
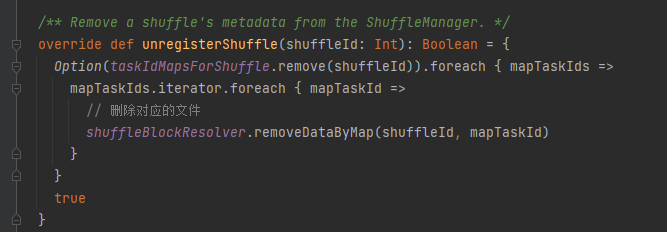
unregisterShuffle: κατάργηση της τυχαίας αναπαραγωγής
shuffleBlockResolver: Λήψη shuffleBlockResolver, που χρησιμοποιείται για τη διαχείριση της σχέσης μεταξύ shuffle και block
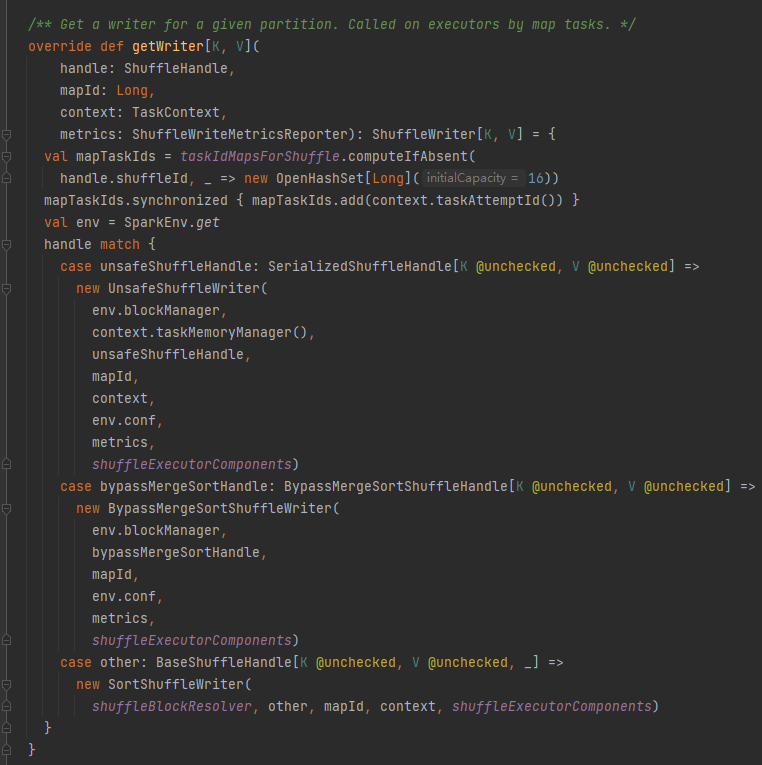
getWriter: Λάβετε το πρόγραμμα εγγραφής που αντιστοιχεί στο διαμέρισμα και καλέστε το στην εργασία χάρτη του εκτελεστή
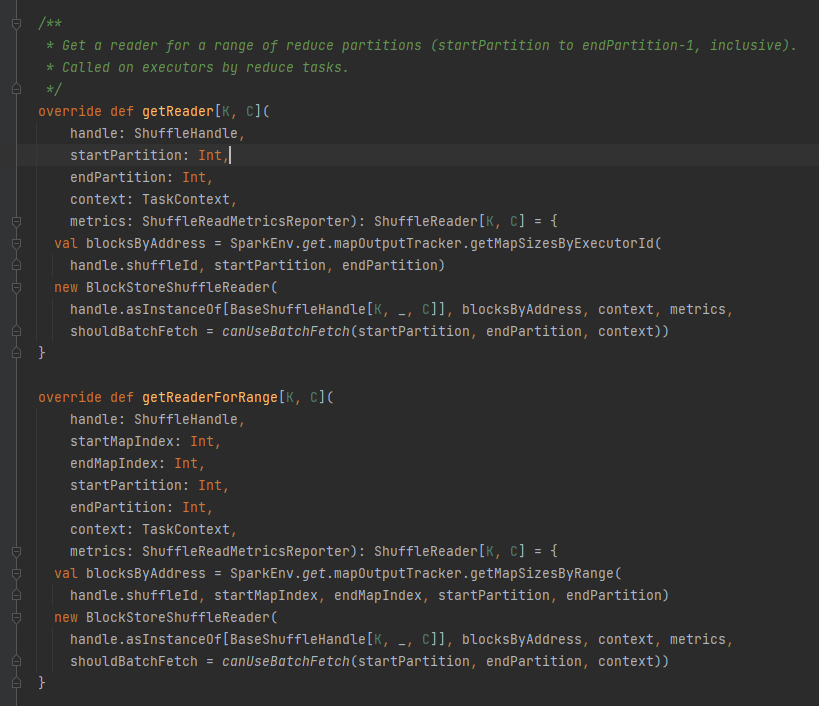
getReader, getReaderForRange: Αποκτήστε τον αναγνώστη ενός διαμερίσματος εύρους και καλέστε το στην εργασία μείωσης του εκτελεστή
Είναι η μόνη υλοποίηση του shuffleManager.
Σε μια τυχαία σειρά που βασίζεται σε ταξινόμηση, τα εισερχόμενα μηνύματα ταξινομούνται σύμφωνα με τα διαμερίσματα και, τέλος, εξάγεται ένα ξεχωριστό αρχείο.
Ο μειωτής θα διαβάσει μια περιοχή δεδομένων από αυτό το αρχείο.
Όταν το αρχείο εξόδου είναι πολύ μεγάλο για να χωρέσει στη μνήμη, ένα ταξινομημένο ενδιάμεσο αρχείο αποτελεσμάτων θα χυθεί στο δίσκο και αυτά τα ενδιάμεσα αρχεία θα συγχωνευθούν σε ένα τελικό αρχείο για έξοδο.
Η τυχαία σειρά βάσει ταξινόμησης έχει δύο μεθόδους:
Πλεονεκτήματα του σειριακού τύπου
Στη λειτουργία σειριακής ταξινόμησης, το πρόγραμμα εγγραφής τυχαίας αναπαραγωγής σειριοποιεί τα εισερχόμενα μηνύματα, τα αποθηκεύει σε μια δομή δεδομένων και τα ταξινομεί.
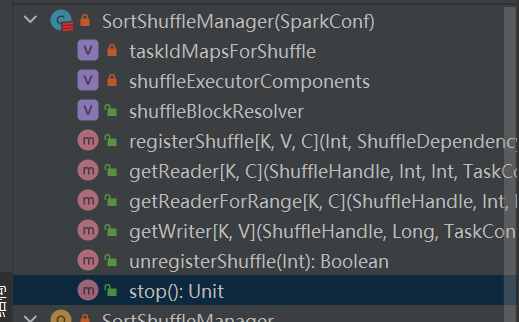
Επιλέξτε την αντίστοιχη λαβή σύμφωνα με διαφορετικά σενάρια. Η σειρά προτεραιότητας είναι BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
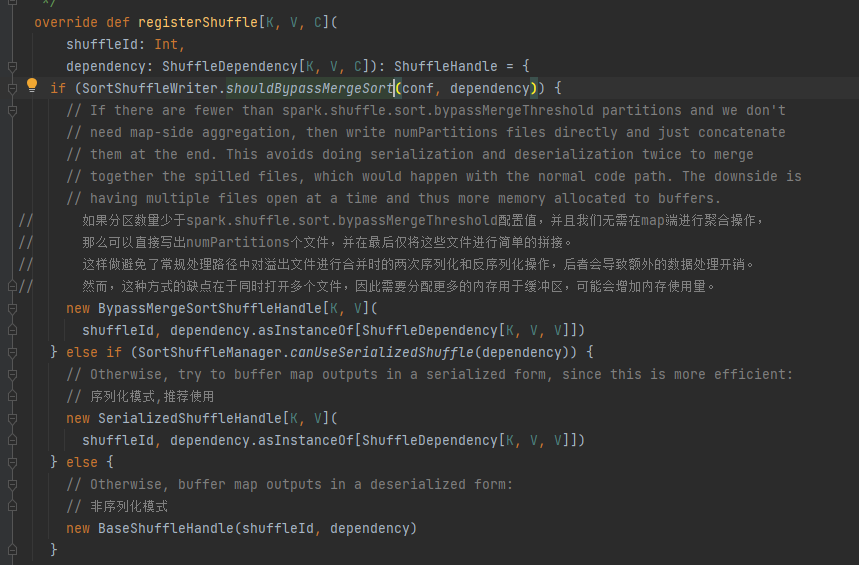
Συνθήκη παράκαμψης: δεν υπάρχει όψη, ο αριθμός των κατατμήσεων είναι μικρότερος ή ίσος με _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Συνθήκες χειρισμού σειριοποίησης: Η κλάση σειριοποίησης υποστηρίζει τη μετεγκατάσταση σειριακών αντικειμένων, δεν χρησιμοποιεί τη λειτουργία mapSideCombine και ο αριθμός των διαμερισμάτων του γονικού RDD δεν είναι μεγαλύτερος από (1 << 24)
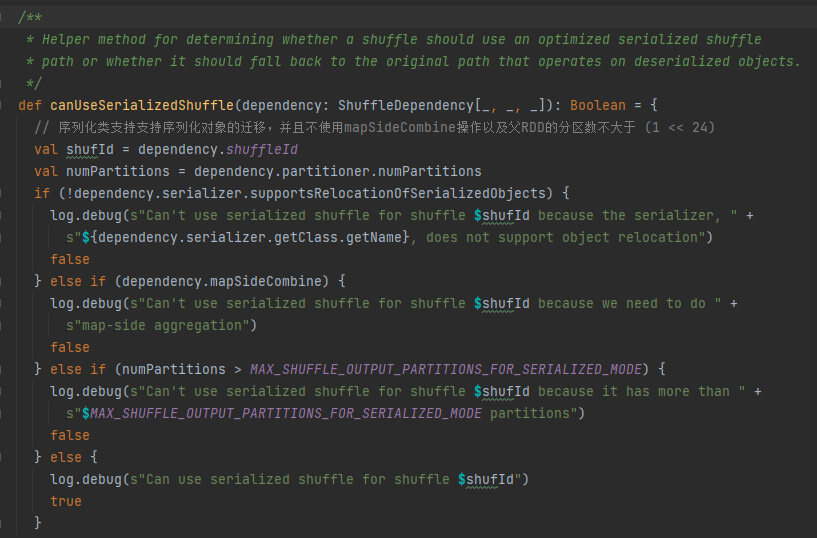
Πρώτα αποθηκεύστε προσωρινά αυτήν την τυχαία σειρά και τις πληροφορίες χάρτη στο taskIdMapsForShuffle_
Επιλέξτε το αντίστοιχο πρόγραμμα εγγραφής με βάση τη λαβή που αντιστοιχεί στο ανακάτεμα.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
Το taskIdMapsForShuffle αφαιρεί την αντίστοιχη τυχαία αναπαραγωγή και τα αρχεία που δημιουργούνται από την τυχαία αναπαραγωγή του αντίστοιχου χάρτη
Λάβετε όλες τις διευθύνσεις μπλοκ που αντιστοιχούν στο αρχείο shuffle, δηλαδή blocksByAddress.
Δημιουργεί ένα αντικείμενο BlockStoreShuffleReader και το επιστρέφει.
Χρησιμοποιείται κυρίως για τη μετάδοση των παραμέτρων της τυχαίας αναπαραγωγής και είναι επίσης ένα σημάδι για να επισημάνετε ποιον συγγραφέα να επιλέξετε.


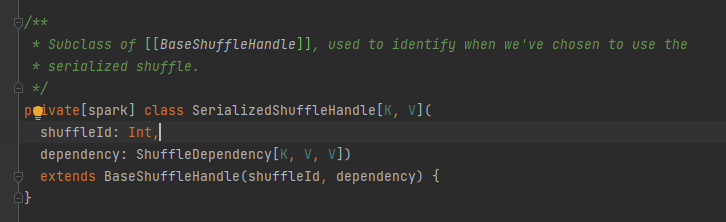
Abstract class, υπεύθυνη για τα μηνύματα εξόδου των εργασιών χάρτη Η κύρια μέθοδος είναι η εγγραφή και υπάρχουν τρεις κλάσεις υλοποίησης
Θα αναλυθεί ξεχωριστά αργότερα.
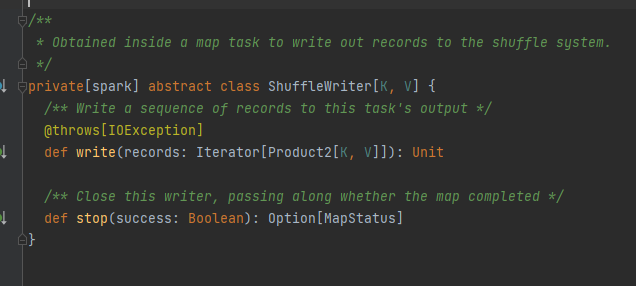
Χαρακτηριστικό, η κλάση υλοποίησης μπορεί να λάβει τα αντίστοιχα δεδομένα μπλοκ με βάση τα mapId, reduceId, shuffleId.
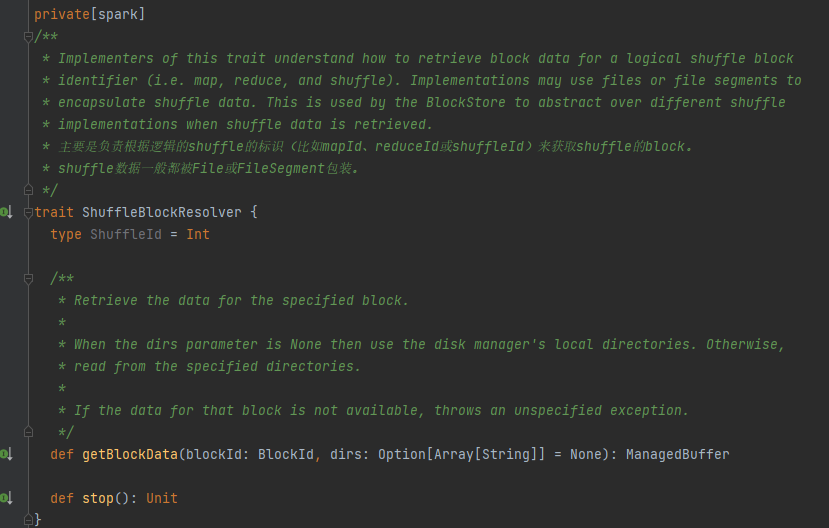
Η μόνη κλάση υλοποίησης του ShuffleBlockResolver.
Δημιουργήστε και διατηρήστε αντιστοιχίσεις μεταξύ λογικών μπλοκ και φυσικών τοποθεσιών αρχείων για τυχαία αναπαραγωγή δεδομένων μπλοκ από την ίδια εργασία χάρτη.
Τα δεδομένα μπλοκ τυχαίας αναπαραγωγής που ανήκουν στην ίδια εργασία χάρτη θα αποθηκευτούν σε ένα ενοποιημένο αρχείο δεδομένων.
Οι μετατοπίσεις αυτών των μπλοκ δεδομένων στο αρχείο δεδομένων αποθηκεύονται χωριστά σε ένα αρχείο ευρετηρίου.
Το .data είναι το επίθημα αρχείου δεδομένων
Το .index είναι το επίθημα αρχείου ευρετηρίου
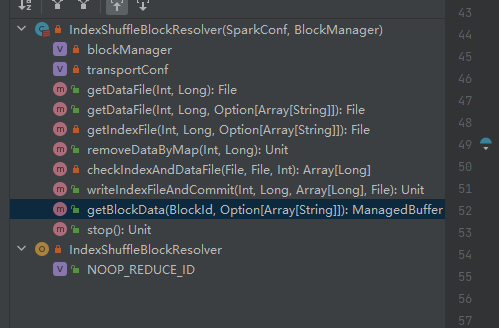
Λάβετε το αρχείο δεδομένων.
Δημιουργήστε ShuffleDataBlockId και καλέστε τη μέθοδο blockManager.diskBlockManager.getFile για να αποκτήσετε το αρχείο
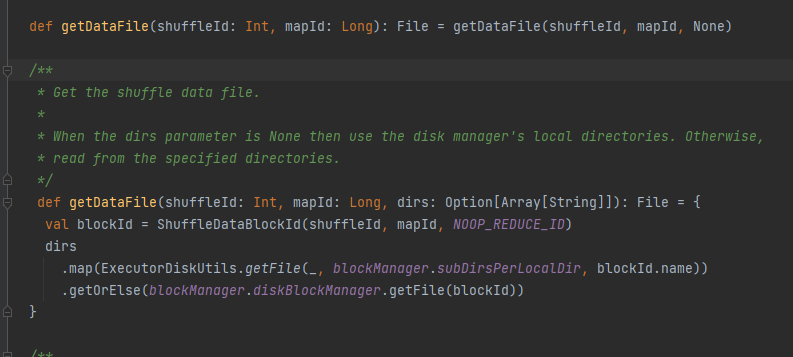
Παρόμοιο με το getDataFile
Δημιουργήστε ShuffleIndexBlockId και καλέστε τη μέθοδο blockManager.diskBlockManager.getFile για να αποκτήσετε το αρχείο

Λάβετε το αρχείο δεδομένων και το αρχείο ευρετηρίου με βάση το shuffleId και το mapId και, στη συνέχεια, διαγράψτε τα
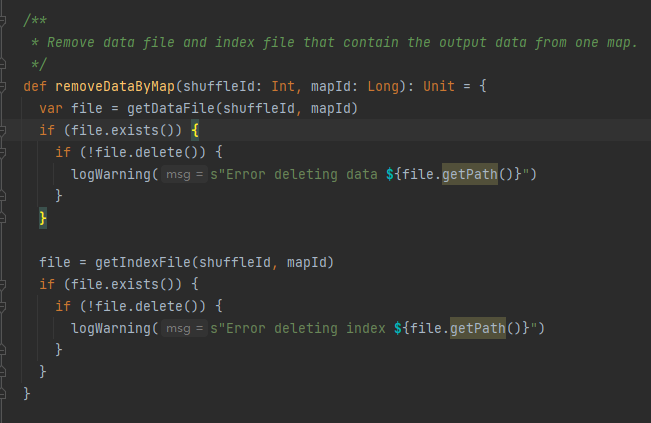
Αποκτήστε το αντίστοιχο αρχείο δεδομένων και αρχείο ευρετηρίου σύμφωνα με το mapId και το shuffleId.
Ελέγξτε εάν το αρχείο δεδομένων και το αρχείο ευρετηρίου υπάρχουν και ταιριάζουν και επιστρέψτε απευθείας.
Εάν δεν μπορεί να ταιριάζει, θα δημιουργηθεί ένα νέο προσωρινό αρχείο ευρετηρίου. Στη συνέχεια μετονομάστε το αρχείο ευρετηρίου και το αρχείο δεδομένων που δημιουργήθηκε και επιστρέψτε.
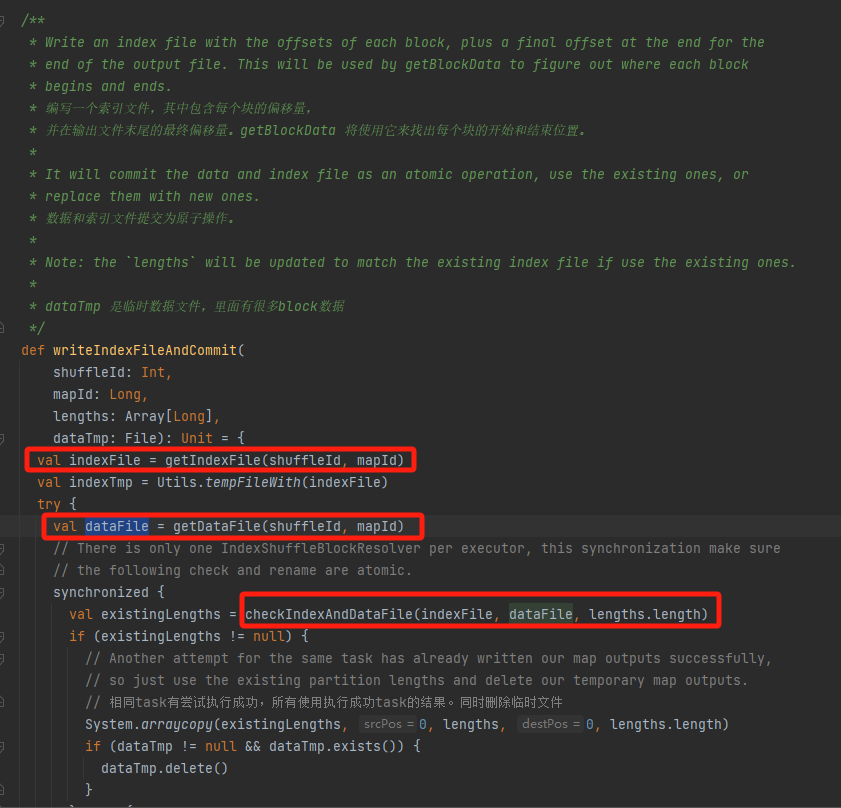

Ας υποθέσουμε ότι το shuffle έχει τρία διαμερίσματα και τα αντίστοιχα μεγέθη δεδομένων είναι 1000, 1500 και 2500 αντίστοιχα.
Στο αρχείο ευρετηρίου, η πρώτη γραμμή είναι 0, ακολουθούμενη από τη αθροιστική τιμή των δεδομένων διαμερίσματος Η δεύτερη γραμμή είναι 1000, η τρίτη γραμμή είναι 1000+1500=2500 και η τρίτη γραμμή είναι 2500+2500=5000.
Τα αρχεία δεδομένων αποθηκεύονται ταξινομημένα κατά μέγεθος διαμερίσματος.

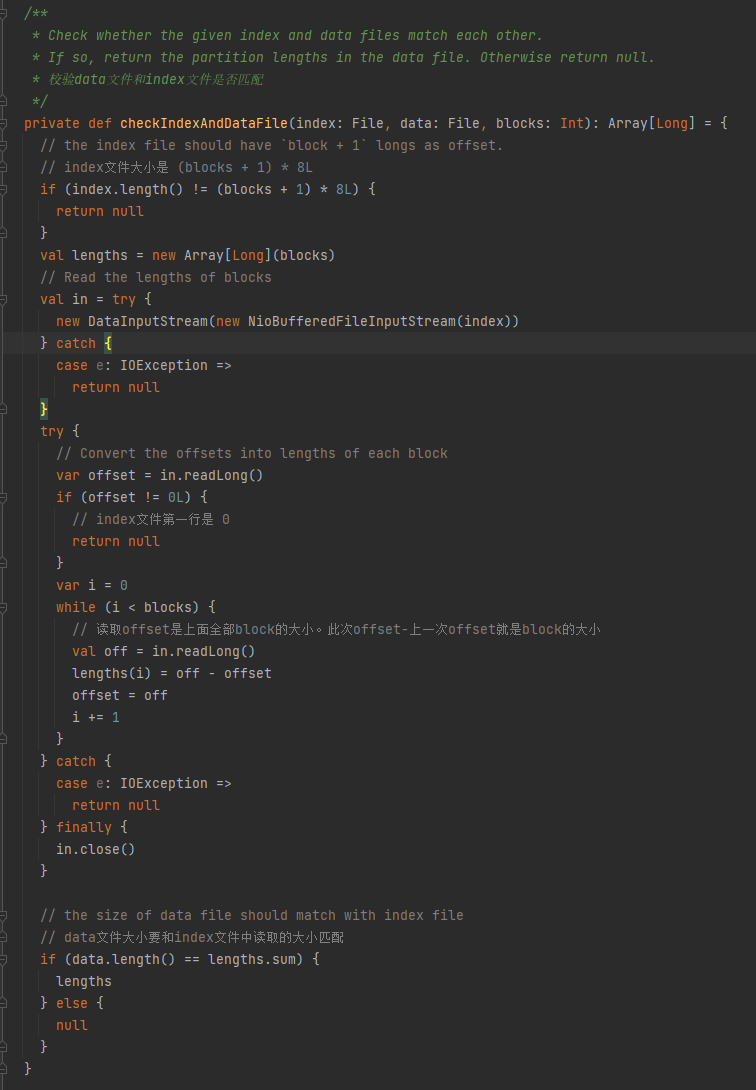
Επαληθεύστε εάν το αρχείο δεδομένων και το αρχείο ευρετηρίου ταιριάζουν, επιστρέφεται το null, εάν ταιριάζουν, επιστρέφεται ένας πίνακας μεγέθους διαμερίσματος.
1.Το μέγεθος αρχείου ευρετηρίου είναι (μπλοκ + 1) * 8L
2. Η πρώτη γραμμή του αρχείου ευρετηρίου είναι 0
3. Λάβετε το μέγεθος του διαμερίσματος και γράψτε το σε μήκη Η συνοπτική τιμή των μηκών είναι ίση με το μέγεθος του αρχείου δεδομένων.
Εάν πληρούνται οι τρεις παραπάνω προϋποθέσεις, επιστρέφονται τα μήκη, διαφορετικά επιστρέφεται το null.
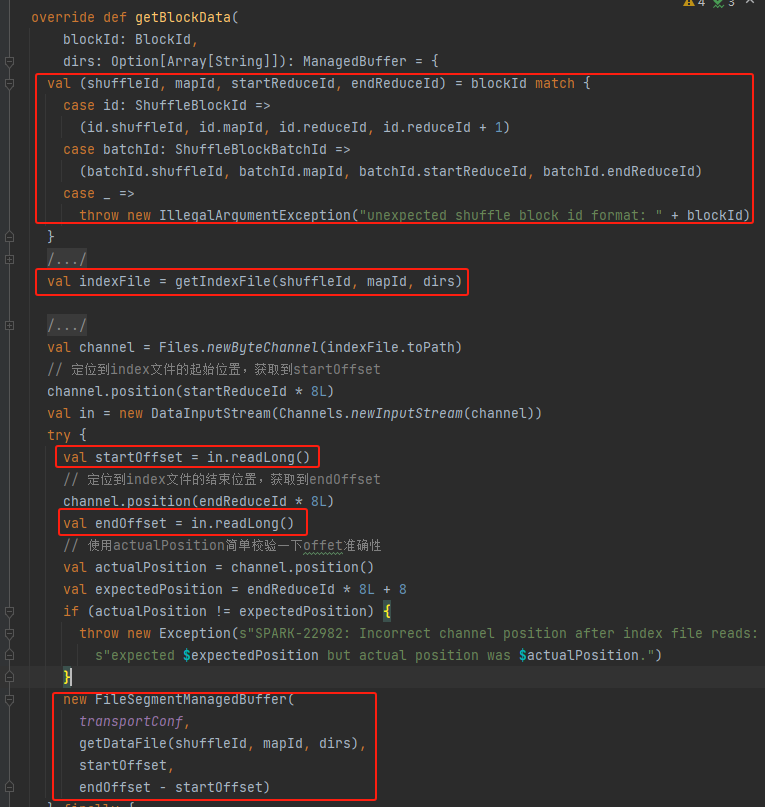
Λάβετε shuffleId, mapId, startReduceId, endReduceId
Αποκτήστε το αρχείο ευρετηρίου
Διαβάστε τα αντίστοιχα startOffset και endOffset
Χρησιμοποιήστε το αρχείο δεδομένων, το startOffset, το endOffset για να δημιουργήσετε FileSegmentManagedBuffer και να επιστρέψετε

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]