le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'ingresso al sistema shuffle. ShuffleManager viene creato in sparkEnv nel driver e nell'esecutore. Registra lo shuffle nel driver e leggi e scrivi i dati nell'esecutore.
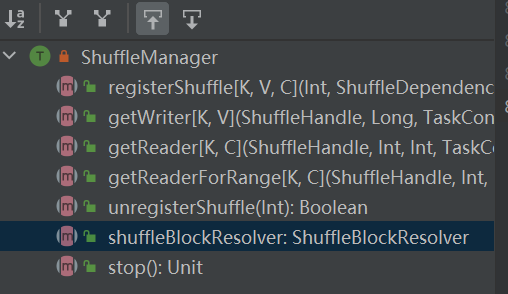
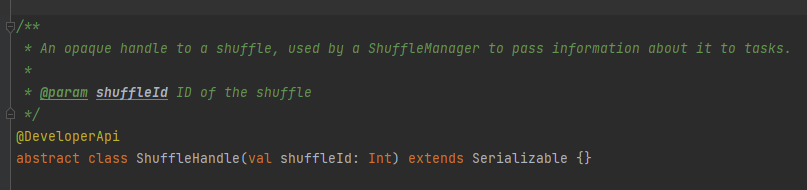
RegisterShuffle: registra lo shuffle, restituisce shuffleHandle
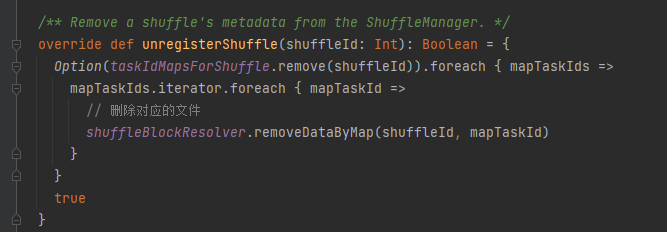
unregisterShuffle: rimuove la riproduzione casuale
shuffleBlockResolver: ottieni shuffleBlockResolver, utilizzato per gestire la relazione tra shuffle e blocco
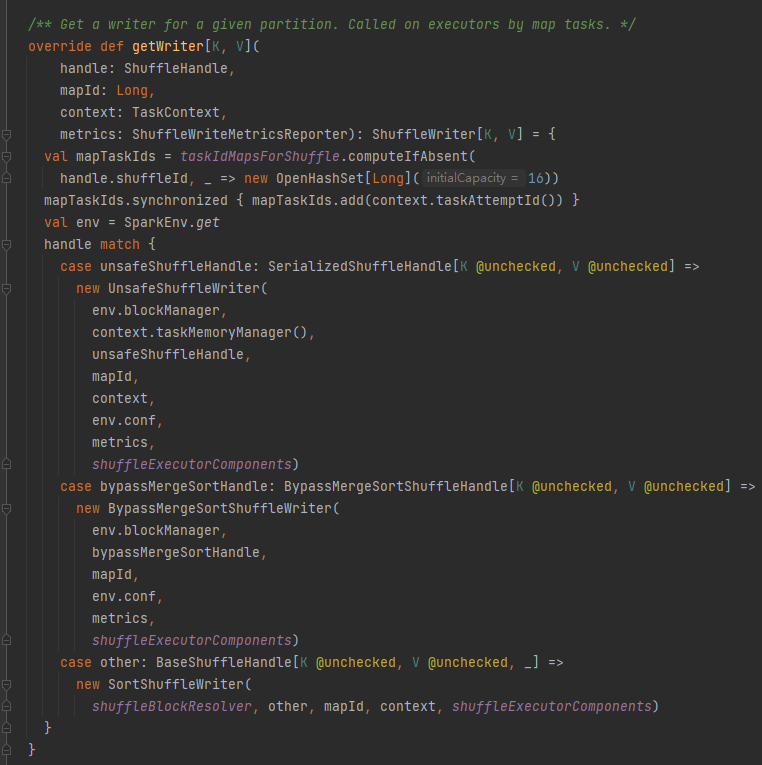
getWriter: ottiene lo scrittore corrispondente alla partizione e lo chiama nell'attività di mappa dell'esecutore
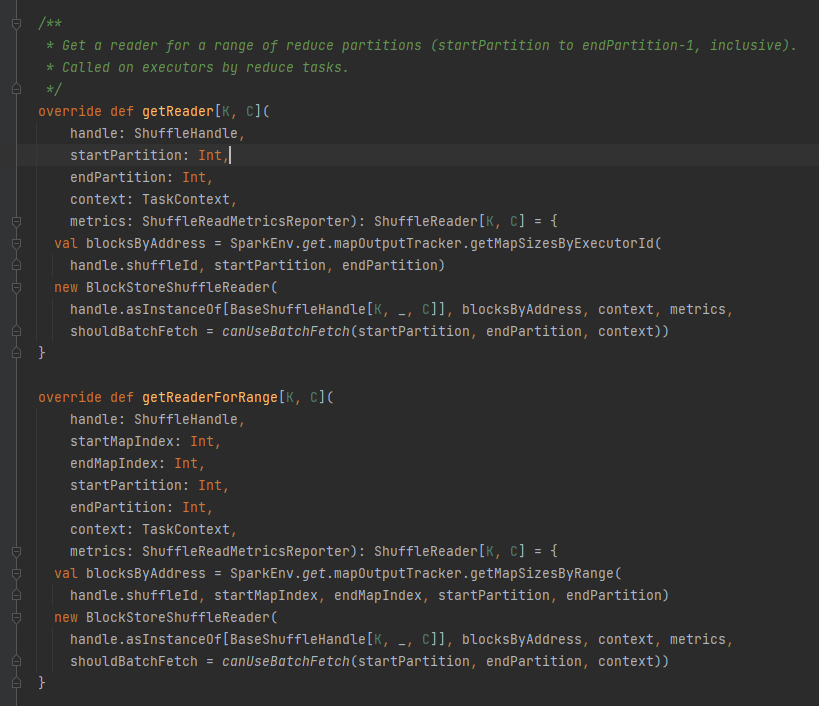
getReader, getReaderForRange: ottiene il lettore di una partizione di intervallo e lo chiama nell'attività di riduzione dell'esecutore
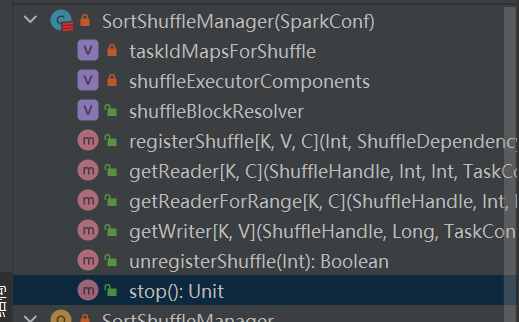
È l'unica implementazione di shuffleManager.
In uno shuffle basato sull'ordinamento, i messaggi in arrivo vengono ordinati in base alle partizioni e infine viene generato un file separato.
Il riduttore leggerà una regione di dati da questo file.
Quando il file di output è troppo grande per essere contenuto in memoria, sul disco verrà distribuito un file di risultati intermedio ordinato e questi file intermedi verranno uniti in un file finale per l'output.
La riproduzione casuale basata sull'ordinamento prevede due metodi:
Vantaggi dell'ordinamento serializzato
Nella modalità di ordinamento serializzato, lo scrittore casuale serializza i messaggi in arrivo, li salva in una struttura dati e li ordina.
Scegli la maniglia corrispondente in base ai diversi scenari. L'ordine di priorità è BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
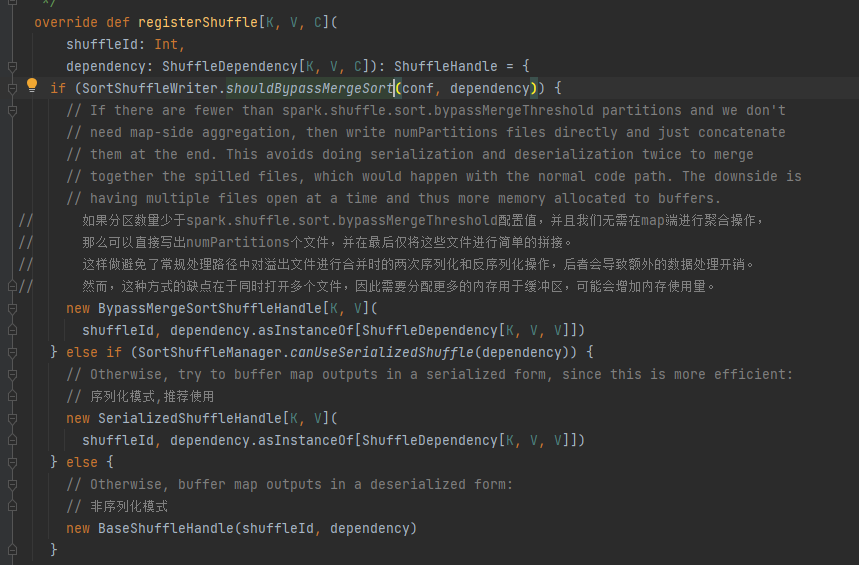
Condizione di bypass: nessun lato mappa, il numero di partizioni è inferiore o uguale a _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Condizioni di gestione della serializzazione: la classe di serializzazione supporta la migrazione di oggetti serializzati, non utilizza l'operazione mapSideCombine e il numero di partizioni dell'RDD padre non è maggiore di (1 << 24)
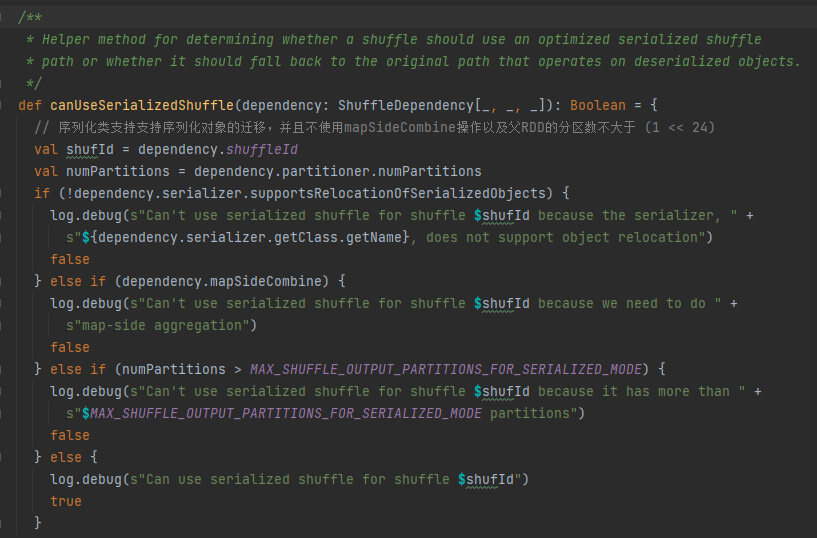
Per prima cosa memorizza nella cache questo shuffle e mappa le informazioni in taskIdMapsForShuffle_
Seleziona lo scrittore corrispondente in base alla maniglia corrispondente allo shuffle.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle rimuove lo shuffle corrispondente e i file generati dalla mappa corrispondente dello shuffle
Ottieni tutti gli indirizzi di blocco corrispondenti al file shuffle, ovvero blocchiByAddress.
Crea un oggetto BlockStoreShuffleReader e lo restituisce.
Viene utilizzato principalmente per passare i parametri di shuffle ed è anche un segno per contrassegnare quale scrittore scegliere.


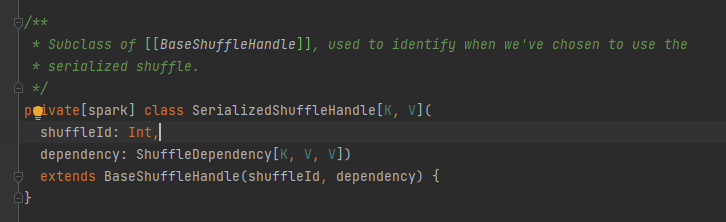
Classe astratta, responsabile dei messaggi di output dell'attività della mappa. Il metodo principale è write e sono disponibili tre classi di implementazione
Verranno analizzati separatamente in seguito.
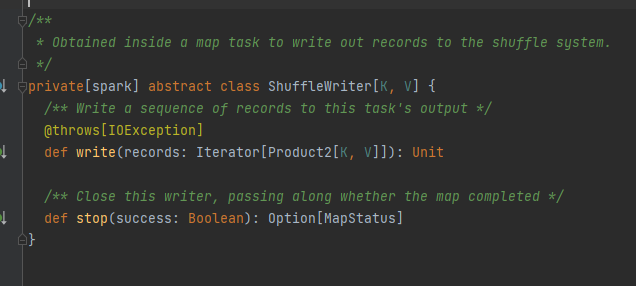
Tratto, la classe di implementazione può ottenere i dati del blocco corrispondente in base a mapId, reduceId, shuffleId.
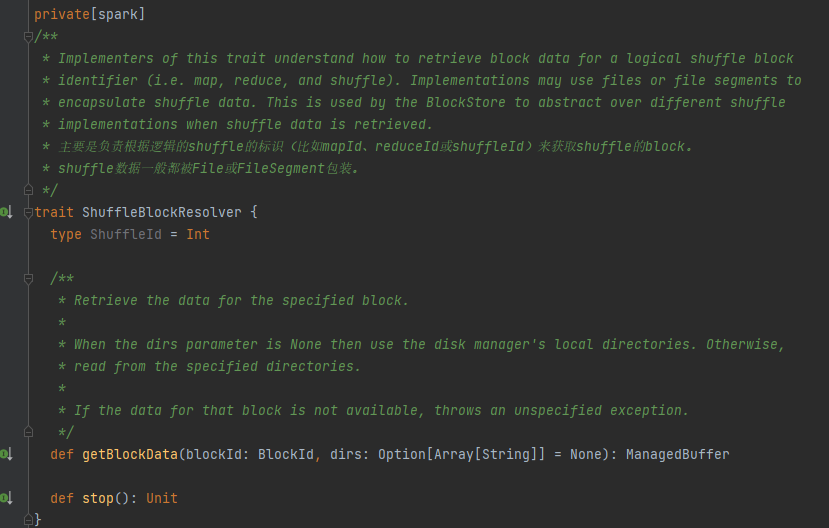
L'unica classe di implementazione di ShuffleBlockResolver.
Crea e mantieni mappature tra blocchi logici e posizioni di file fisici per i dati dei blocchi mescolati dalla stessa attività di mappa.
I dati dei blocchi casuali appartenenti alla stessa attività della mappa verranno archiviati in un file di dati consolidato.
Gli offset di questi blocchi di dati nel file di dati vengono memorizzati separatamente in un file di indice.
.data è il suffisso del file di dati
.index è il suffisso del file indice
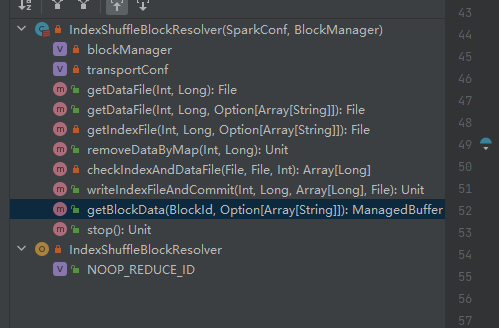
Ottieni il file di dati.
Genera ShuffleDataBlockId e chiama il metodo blockManager.diskBlockManager.getFile per ottenere il file
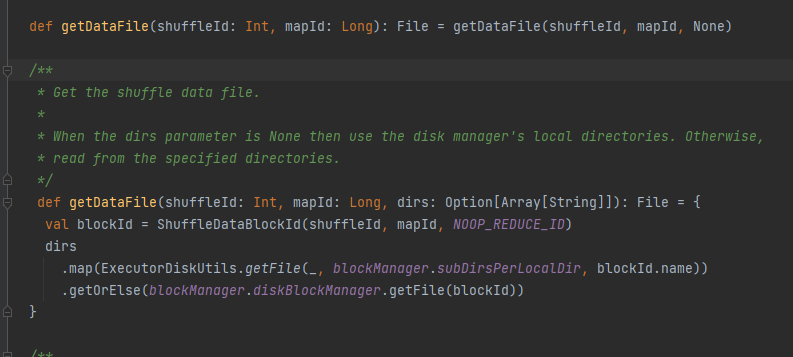
Simile a getDataFile
Genera ShuffleIndexBlockId e chiama il metodo blockManager.diskBlockManager.getFile per ottenere il file

Ottieni il file di dati e il file di indice in base a shuffleId e mapId, quindi eliminali
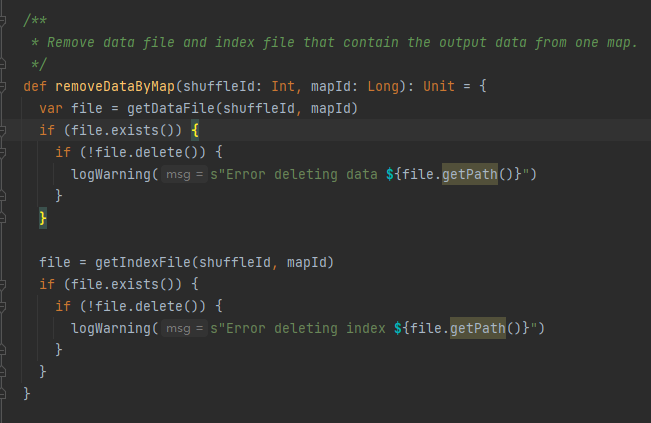
Ottieni il file di dati e il file di indice corrispondenti in base a mapId e shuffleId.
Controlla se il file di dati e il file di indice esistono e corrispondono e restituiscono direttamente.
Se non può corrispondere, verrà generato un nuovo file temporaneo di indice. Quindi rinominare il file di indice e il file di dati generati e restituire.
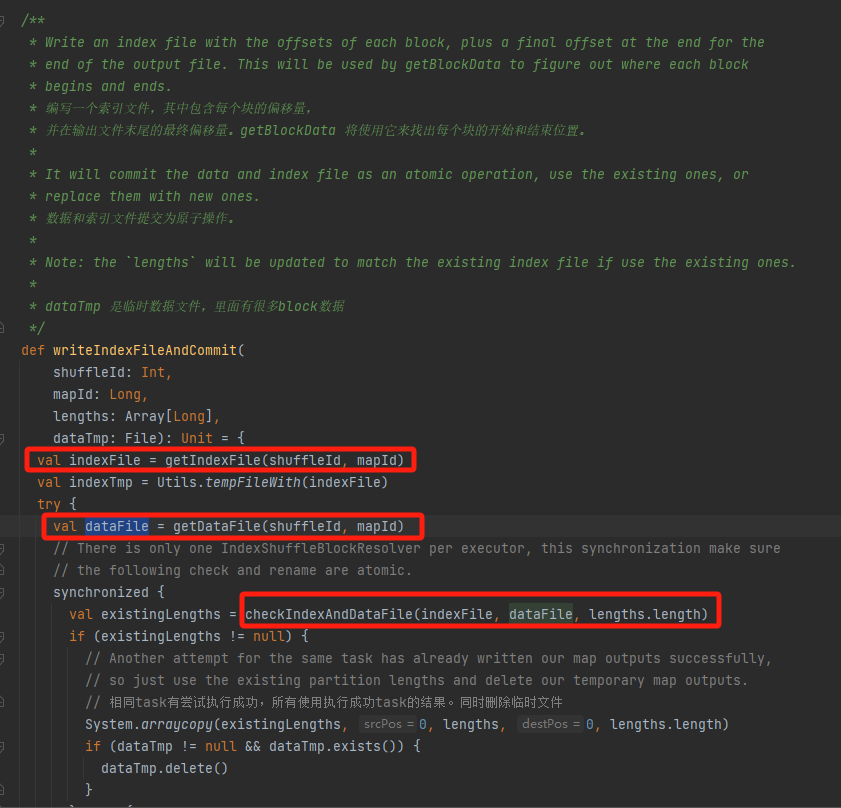

Supponiamo che la riproduzione casuale abbia tre partizioni e che le dimensioni dei dati corrispondenti siano rispettivamente 1000, 1500 e 2500.
Nel file di indice, la prima riga è 0, seguita dal valore cumulativo dei dati della partizione. La seconda riga è 1000, la terza riga è 1000+1500=2500 e la terza riga è 2500+2500=5000.
I file di dati vengono archiviati ordinati in base alla dimensione della partizione.

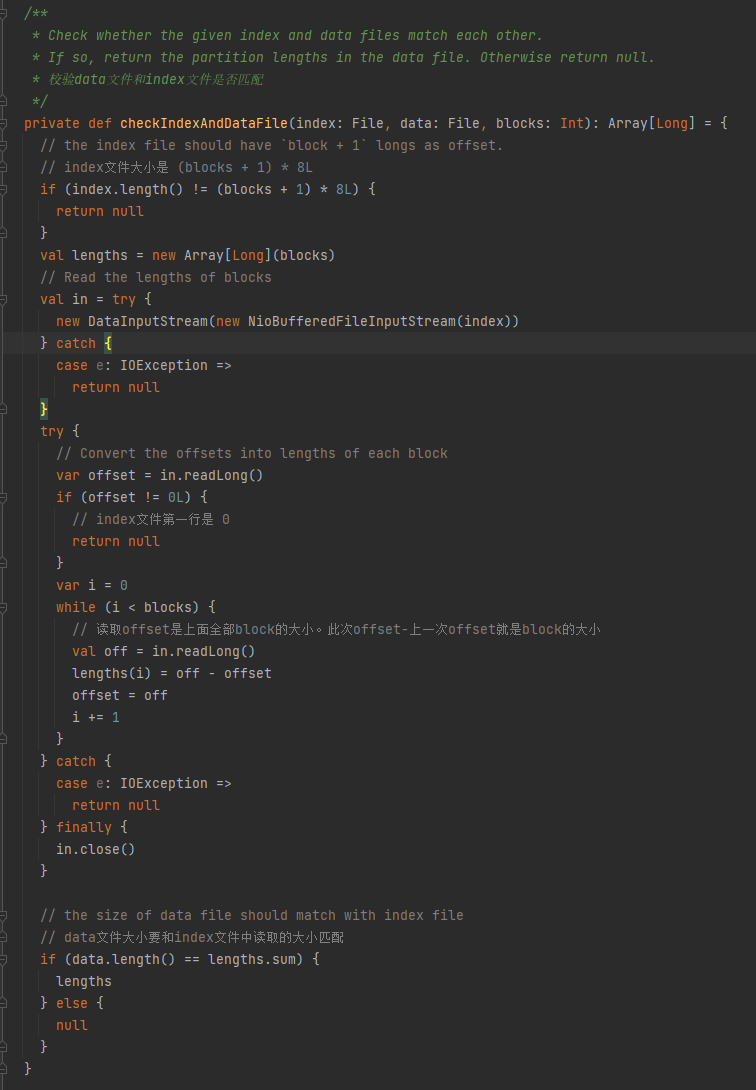
Verificare se il file di dati e il file di indice corrispondono. Se non corrispondono, viene restituito null. Se corrispondono, viene restituito un array di dimensioni della partizione.
1.La dimensione del file indice è (blocchi + 1) * 8L
2.La prima riga del file indice è 0
3. Ottieni la dimensione della partizione e scrivila in lunghezze. Il valore di riepilogo delle lunghezze è uguale alla dimensione del file di dati.
Se le tre condizioni precedenti sono soddisfatte, viene restituito lengths, altrimenti viene restituito null.
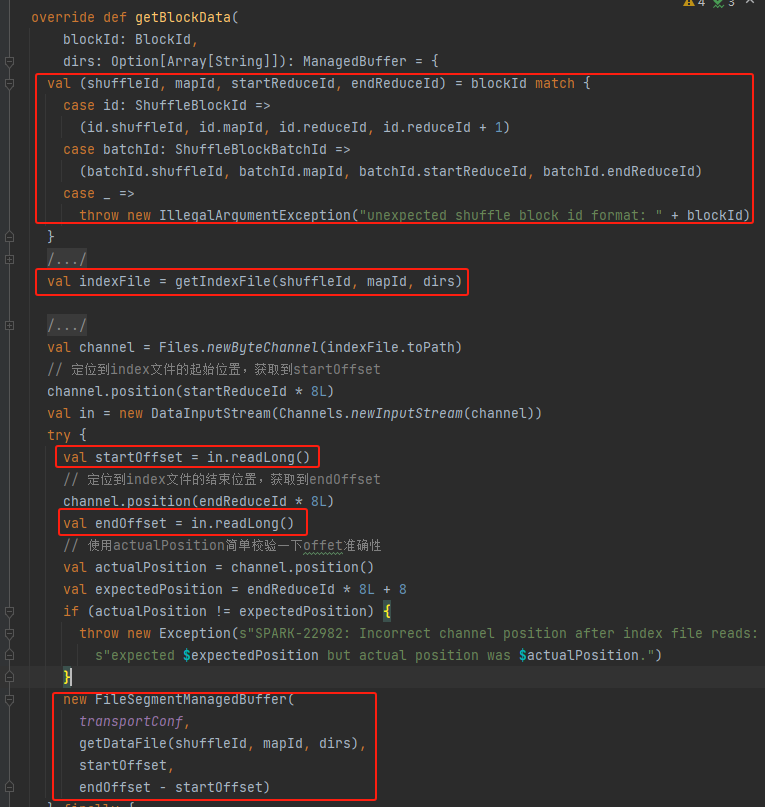
Ottieni shuffleId, mapId, startReduceId, endReduceId
Ottieni il file indice
Leggere i corrispondenti startOffset e endOffset
Utilizza il file di dati, startOffset, endOffset per generare FileSegmentManagedBuffer e restituire

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]