informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Pintu masuk ke sistem shuffle. ShuffleManager dibuat di sparkEnv di driver dan eksekutor. Daftarkan shuffle di driver dan baca dan tulis data di eksekutor.
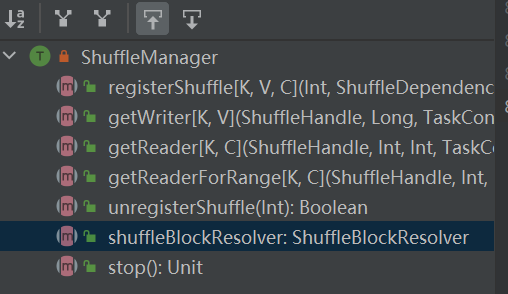
registerShuffle: daftar acak, kembalikan shuffleHandle
unregisterShuffle: menghapus shuffle
shuffleBlockResolver: Dapatkan shuffleBlockResolver, digunakan untuk menangani hubungan antara shuffle dan block
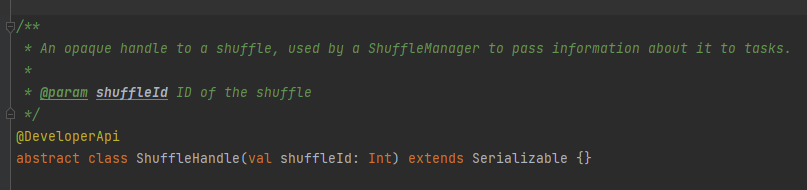
getWriter: Dapatkan penulis yang sesuai dengan partisi dan panggil dalam tugas peta pelaksana
getReader, getReaderForRange: Dapatkan pembaca partisi rentang dan panggil dalam tugas pengurangan pelaksana
Apakah satu-satunya implementasi shuffleManager.
Dalam pengacakan berbasis pengurutan, pesan masuk diurutkan berdasarkan partisi, dan akhirnya file terpisah dikeluarkan.
Peredam akan membaca wilayah data dari file ini.
Ketika file keluaran terlalu besar untuk muat dalam memori, file hasil antara yang diurutkan akan tumpah ke disk, dan file perantara ini akan digabungkan menjadi file akhir untuk keluaran.
Pengacakan berbasis pengurutan memiliki dua metode:
Keuntungan dari pengurutan serial
Dalam mode pengurutan berseri, penulis acak membuat serial pesan masuk, menyimpannya dalam struktur data, dan mengurutkannya.
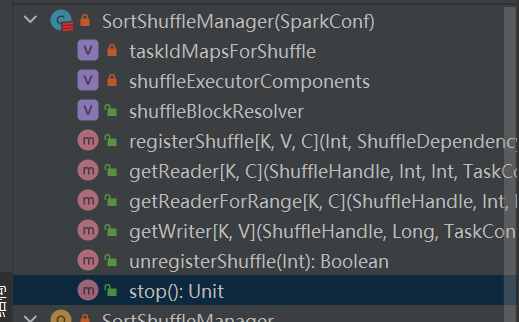
Pilih pegangan yang sesuai berdasarkan skenario yang berbeda. Urutan prioritasnya adalah BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
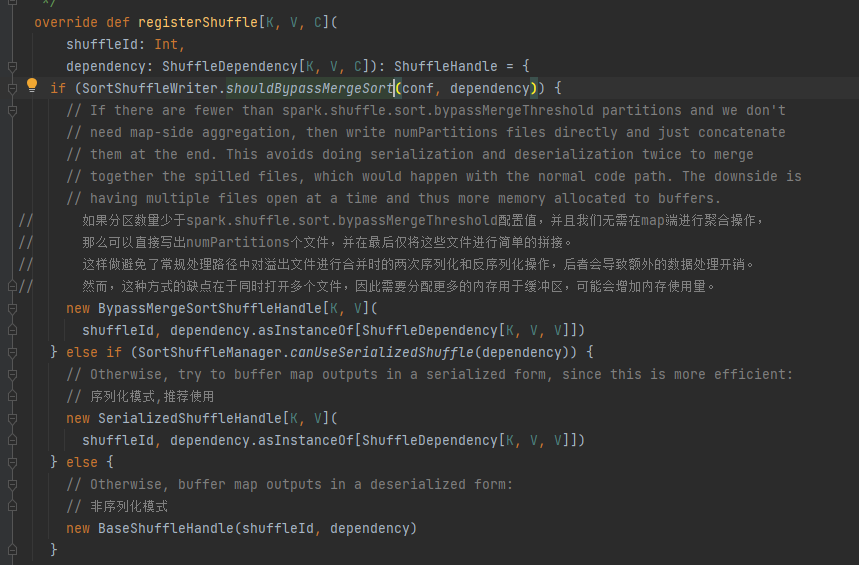
Kondisi bypass: tidak ada sisi peta, jumlah partisi kurang dari atau sama dengan _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Kondisi penanganan serialisasi: Kelas serialisasi mendukung migrasi objek serial, tidak menggunakan operasi mapSideCombine, dan jumlah partisi RDD induk tidak lebih besar dari (1 << 24)
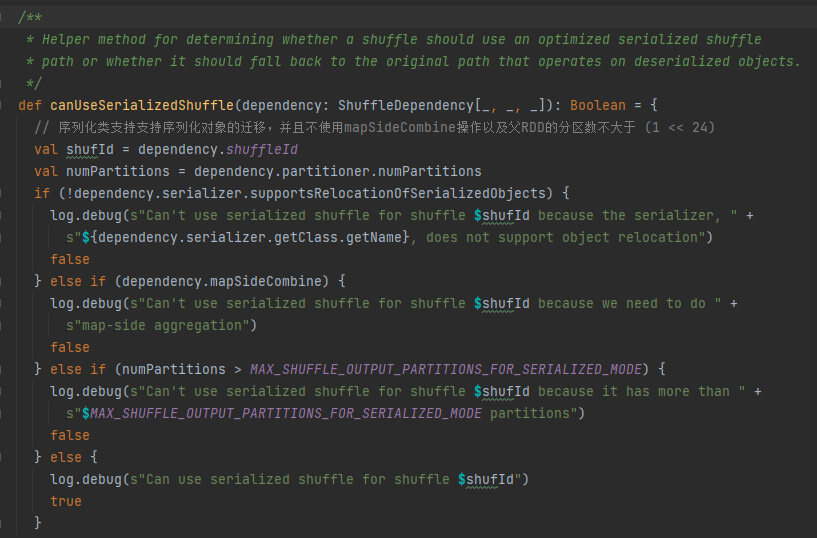
Pertama-tama cache pengacakan ini dan petakan informasi ke taskIdMapsForShuffle_
Pilih penulis yang sesuai berdasarkan pegangan yang sesuai dengan pengacakan.
LewatiGabungkanUrutkanAcakPegangan->LewatiGabungkanUrutkanAcakPenulis
Penanganan Acak Berseri->Penulis Acak Tidak Aman
Penanganan AcakBasis->Penulis AcakUrutan
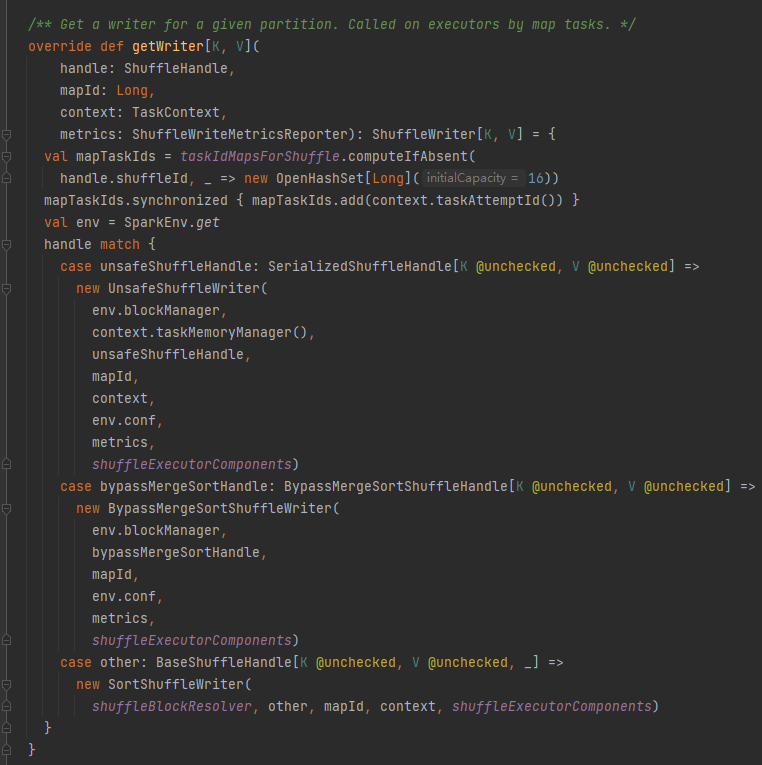
taskIdMapsForShuffle menghapus pengacakan yang sesuai dan file yang dihasilkan oleh pengacakan peta yang sesuai
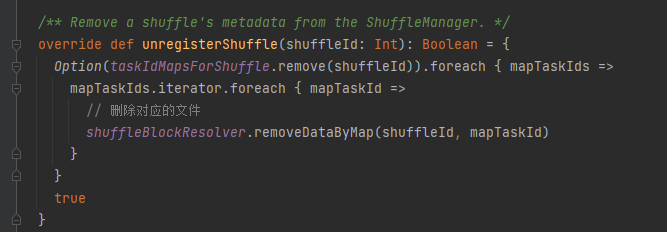
Dapatkan semua alamat blok yang sesuai dengan file shuffle, yaitu blockByAddress.
Membuat objek BlockStoreShuffleReader dan mengembalikannya.
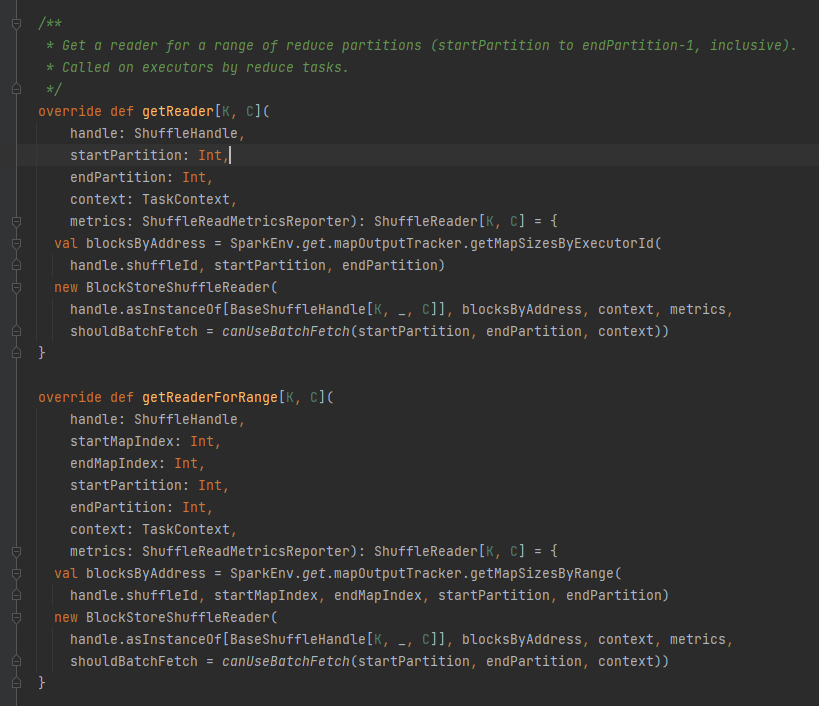
Ini terutama digunakan untuk meneruskan parameter pengacakan, dan juga merupakan tanda untuk menandai penulis mana yang harus dipilih.


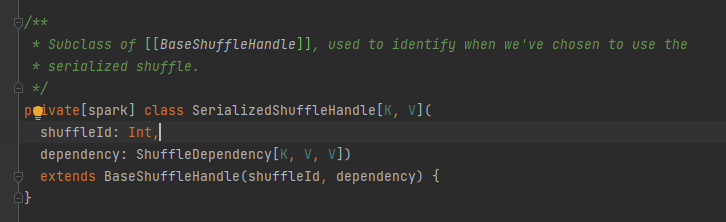
Kelas abstrak, bertanggung jawab atas pesan keluaran tugas peta. Metode utamanya adalah menulis, dan ada tiga kelas implementasi
Nanti akan dianalisis secara terpisah.
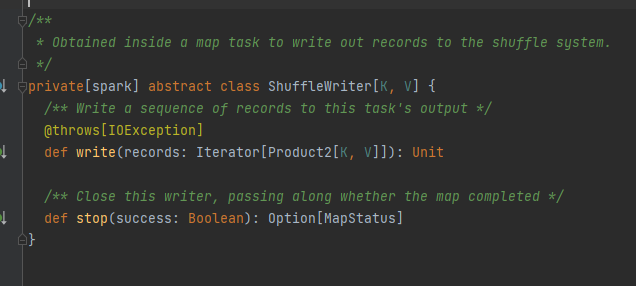
Sifatnya, kelas implementasi dapat memperoleh data blok yang sesuai berdasarkan mapId, penguranganId, shuffleId.
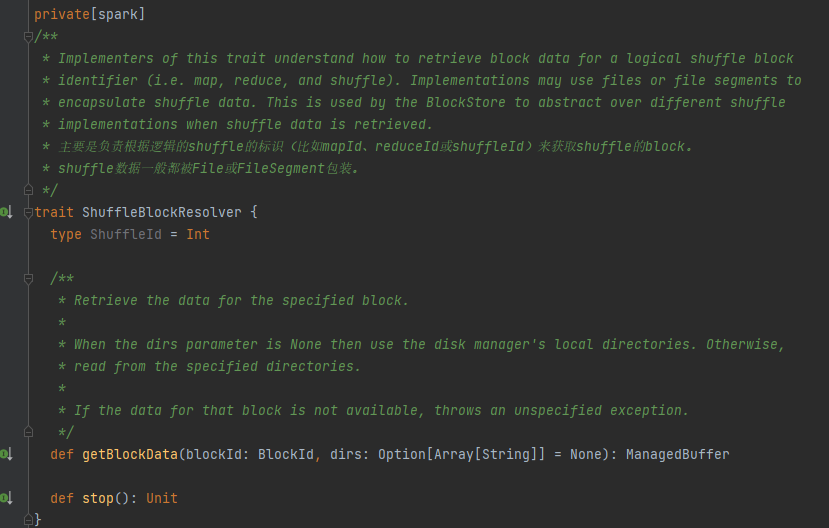
Satu-satunya kelas implementasi ShuffleBlockResolver.
Membuat dan memelihara pemetaan antara blok logis dan lokasi file fisik untuk mengacak data blok dari tugas peta yang sama.
Data blok acak milik tugas peta yang sama akan disimpan dalam file data gabungan.
Offset blok data ini dalam file data disimpan secara terpisah dalam file indeks.
.data adalah akhiran file data
.index adalah akhiran file indeks
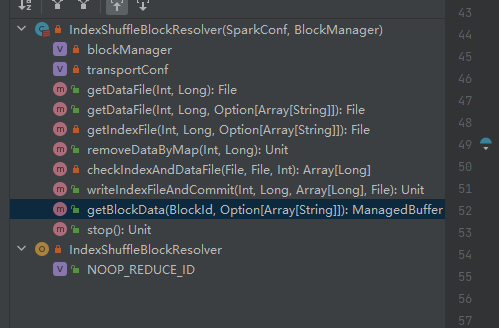
Dapatkan file datanya.
Hasilkan ShuffleDataBlockId dan panggil metode blockManager.diskBlockManager.getFile untuk mendapatkan file
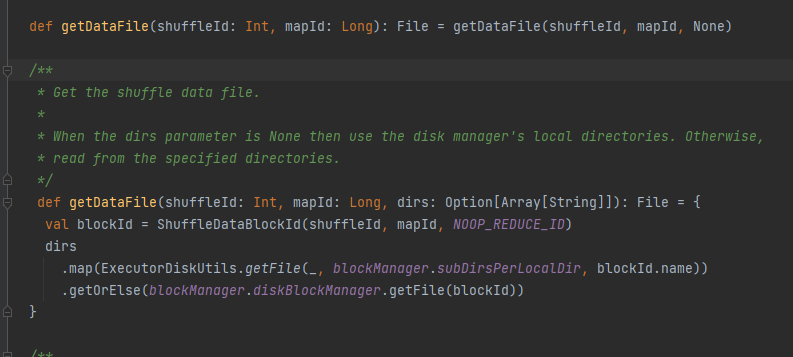
Mirip dengan getDataFile
Hasilkan ShuffleIndexBlockId dan panggil metode blockManager.diskBlockManager.getFile untuk mendapatkan file

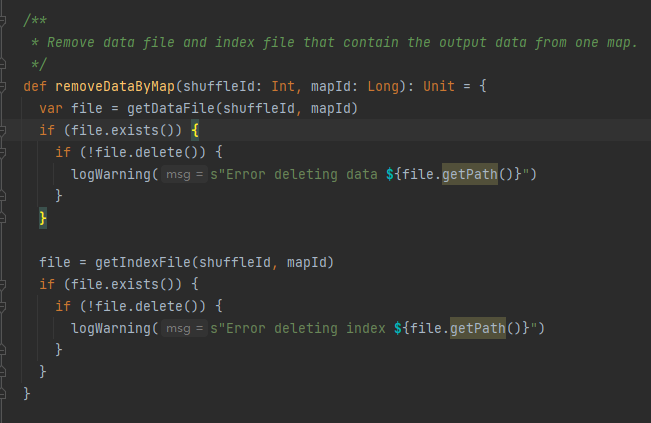
Dapatkan file data dan file indeks berdasarkan shuffleId dan mapId, lalu hapus
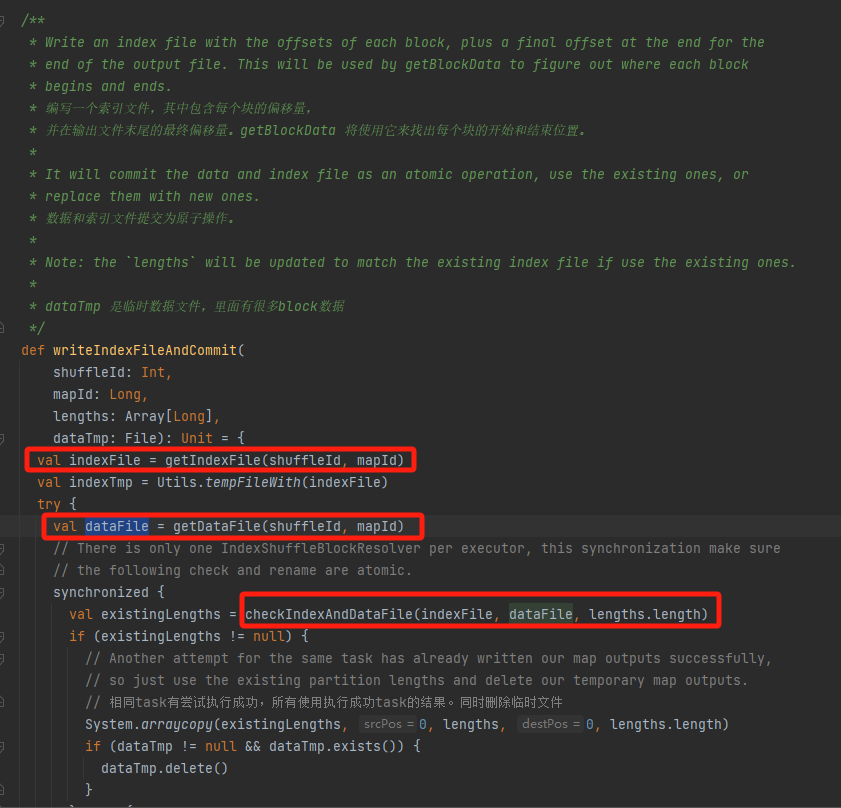
Dapatkan file data dan file indeks yang sesuai menurut mapId dan shuffleId.
Periksa apakah file data dan file indeks ada dan cocok, dan langsung kembali.
Jika tidak cocok, file sementara indeks baru akan dibuat. Kemudian ganti nama file indeks dan file data yang dihasilkan dan kembalikan.

Asumsikan shuffle memiliki tiga partisi, dan ukuran data terkait masing-masing adalah 1000, 1500, dan 2500.
Dalam file indeks, baris pertama adalah 0, diikuti dengan nilai kumulatif data partisi. Baris kedua adalah 1000, baris ketiga adalah 1000+1500=2500, dan baris ketiga adalah 2500+2500=5000.
File data disimpan diurutkan berdasarkan ukuran partisi.

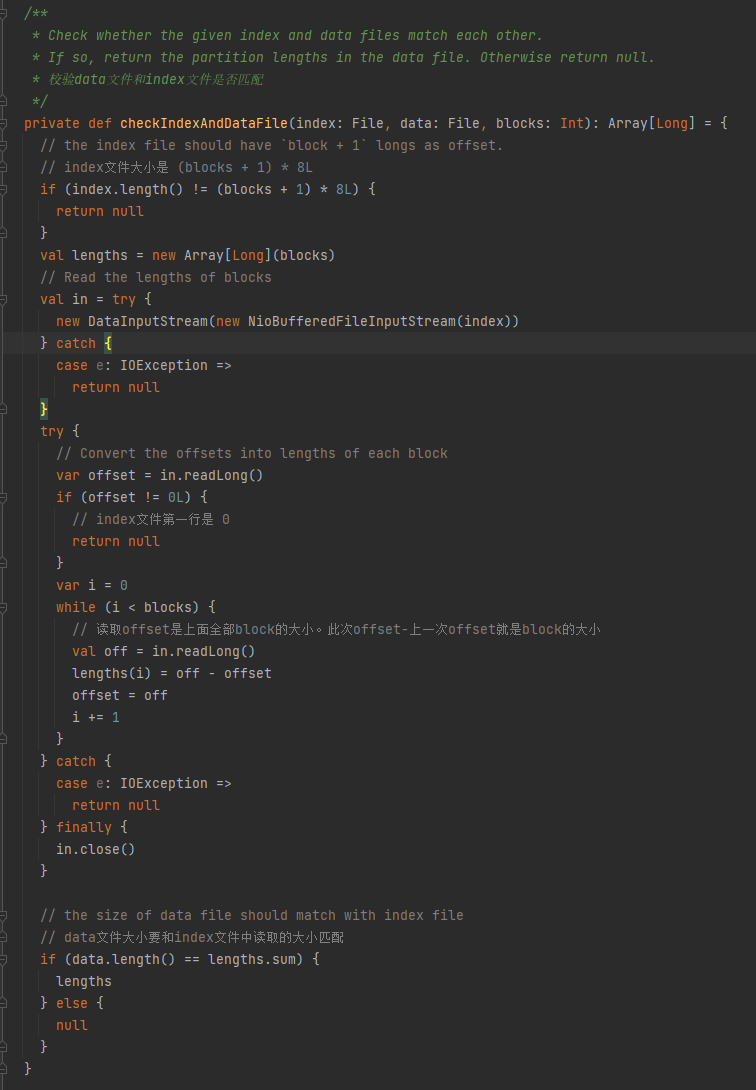
Verifikasi apakah file data dan file indeks cocok. Jika tidak cocok, null dikembalikan.
1.Ukuran file indeks adalah (blok + 1) * 8L
2.Baris pertama file indeks adalah 0
3. Dapatkan ukuran partisi dan tuliskan ke dalam panjangnya. Nilai ringkasan panjangnya sama dengan ukuran file data.
Jika ketiga kondisi di atas terpenuhi, panjang dikembalikan, jika tidak maka null dikembalikan.
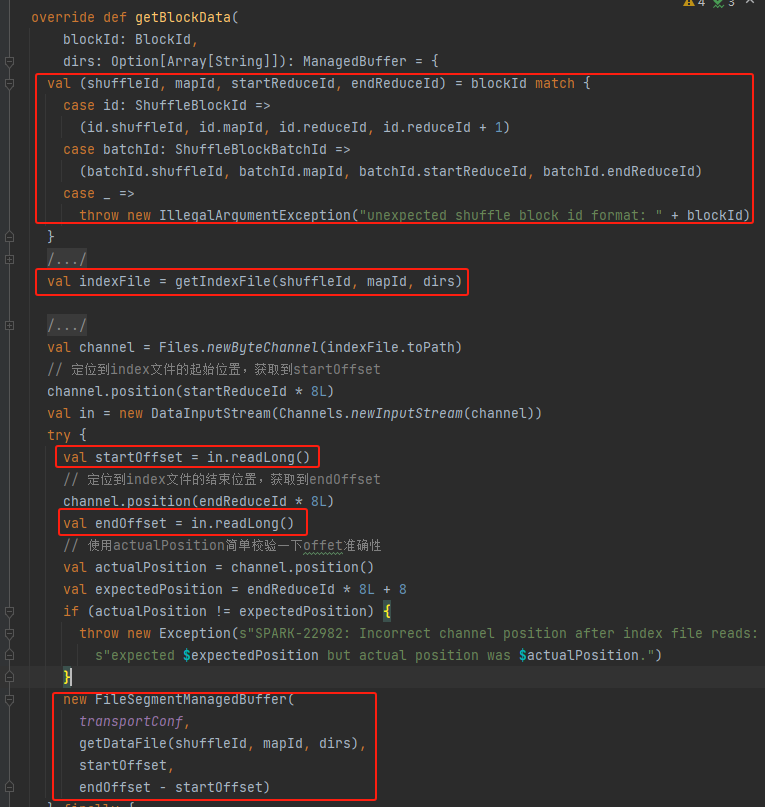
Dapatkan shuffleId, mapId, startReduceId, endReduceId
Dapatkan file indeks
Baca startOffset dan endOffset yang sesuai
Gunakan file data, startOffset, endOffset untuk menghasilkan FileSegmentManagedBuffer dan kembali

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]