2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'entrée du système de lecture aléatoire. ShuffleManager est créé dans sparkEnv dans le pilote et l'exécuteur. Enregistrez le mélange dans le pilote et lisez et écrivez les données dans l'exécuteur.
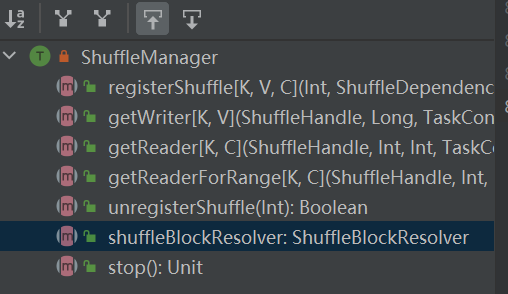
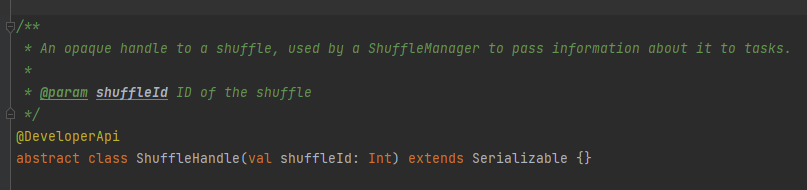
registerShuffle : enregistre le shuffle, renvoie shuffleHandle
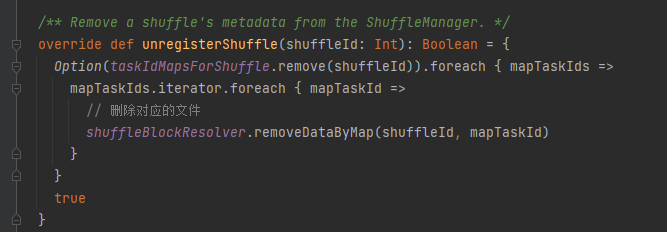
unregisterShuffle : supprimer la lecture aléatoire
shuffleBlockResolver : récupère shuffleBlockResolver, utilisé pour gérer la relation entre shuffle et block
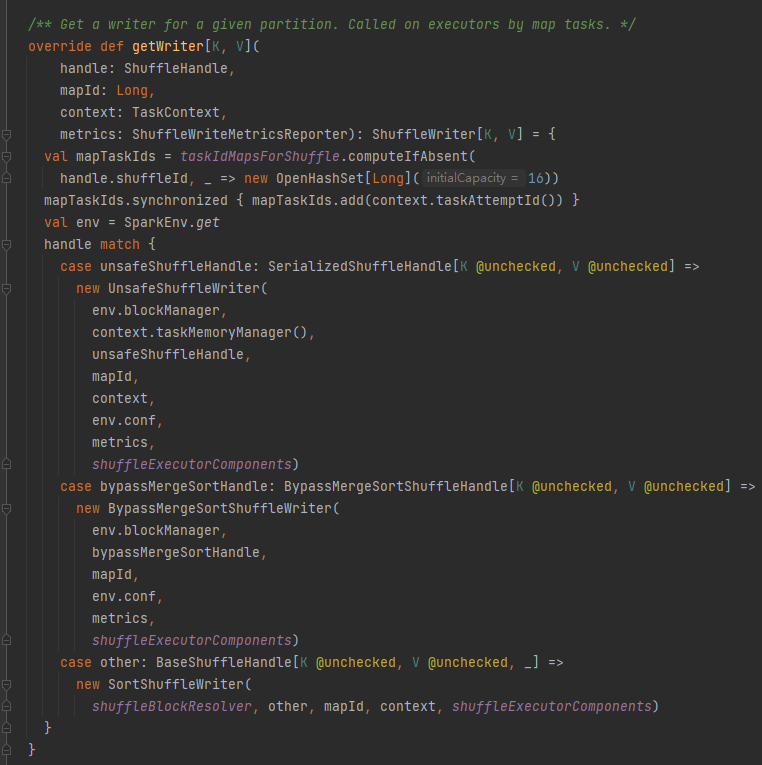
getWriter : Récupère le rédacteur correspondant à la partition et l'appelle dans la tâche map de l'exécuteur
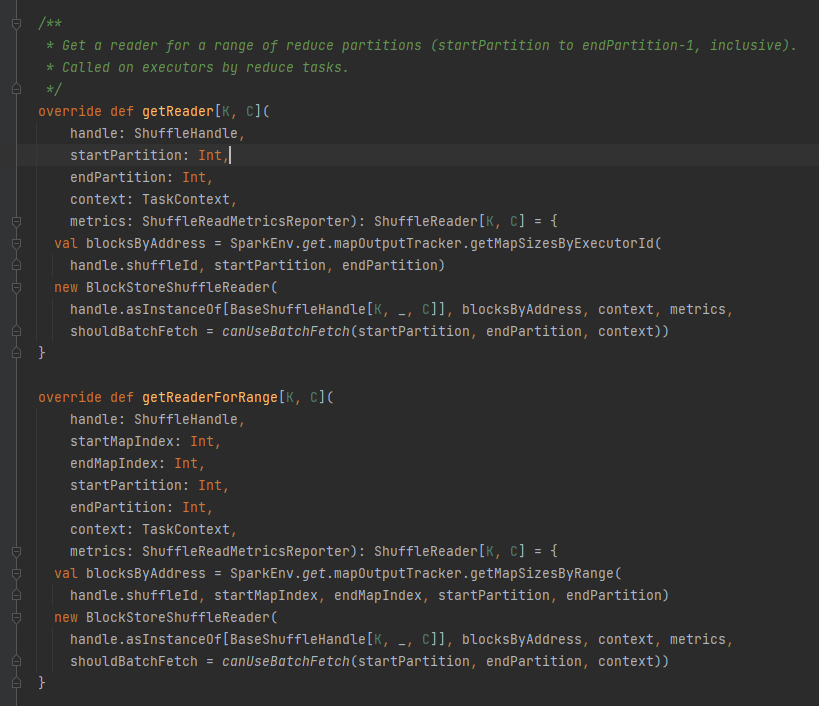
getReader, getReaderForRange : récupère le lecteur d'une partition de plage et l'appelle dans la tâche de réduction de l'exécuteur
Est la seule implémentation de shuffleManager.
Dans une lecture aléatoire basée sur le tri, les messages entrants sont triés en fonction des partitions et finalement un fichier séparé est généré.
Le réducteur lira une région de données de ce fichier.
Lorsque le fichier de sortie est trop volumineux pour tenir en mémoire, un fichier de résultats intermédiaire trié sera répandu sur le disque et ces fichiers intermédiaires seront fusionnés dans un fichier final pour la sortie.
La lecture aléatoire basée sur le tri comporte deux méthodes :
Avantages du tri sérialisé
En mode de tri sérialisé, le rédacteur aléatoire sérialise les messages entrants, les enregistre dans une structure de données et les trie.
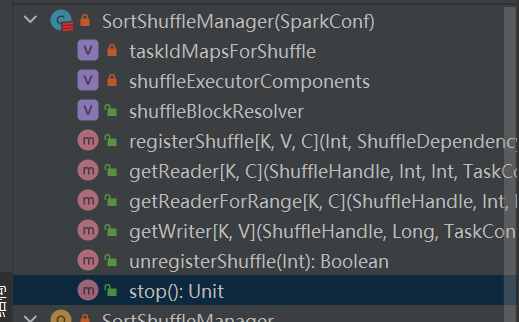
Choisissez la poignée correspondante selon différents scénarios. L'ordre de priorité est BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
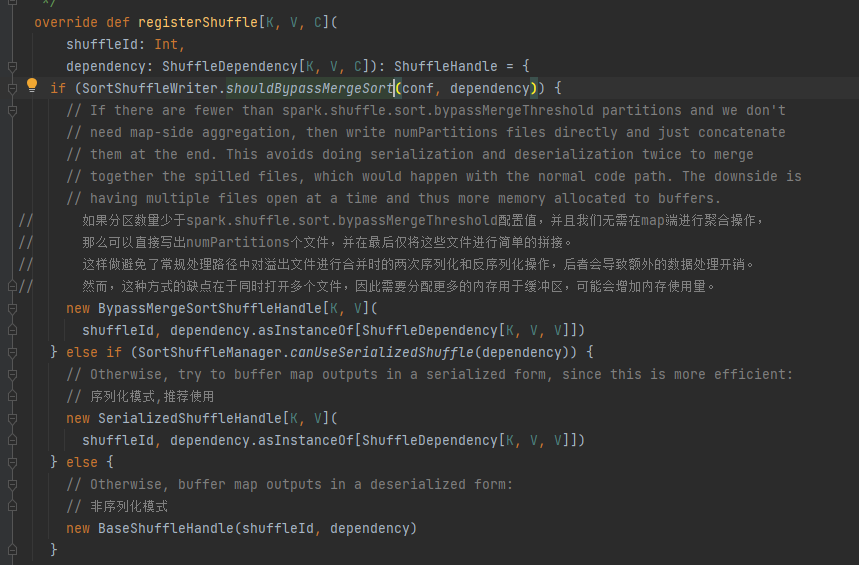
Condition de contournement : pas de mapside, le nombre de partitions est inférieur ou égal à _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Conditions de gestion de sérialisation : la classe de sérialisation prend en charge la migration d'objets sérialisés, n'utilise pas l'opération mapSideCombine et le nombre de partitions du RDD parent n'est pas supérieur à (1 << 24)
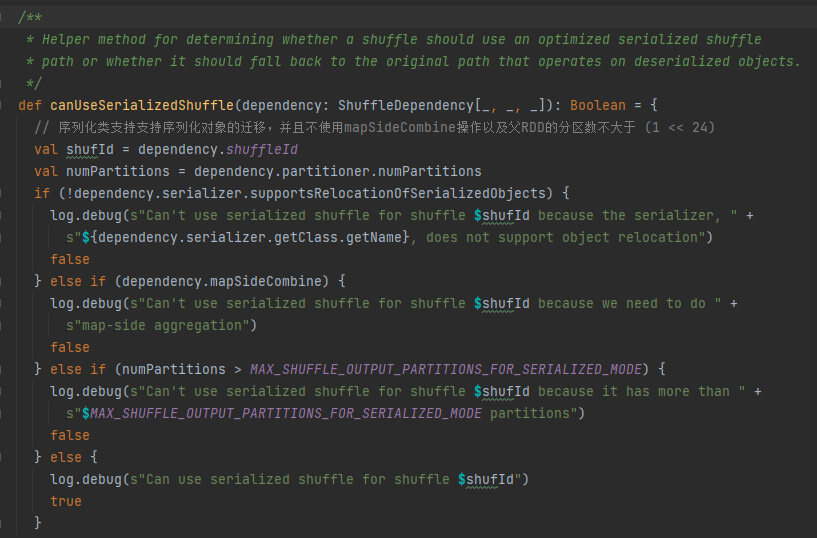
Mettez d’abord en cache ce mélange et mappez les informations dans taskIdMapsForShuffle_
Sélectionnez l'écrivain correspondant en fonction de la poignée correspondant à la lecture aléatoire.
ContournerMergeSortShuffleHandle->ContournerMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle supprime le shuffle correspondant et les fichiers générés par le shuffle correspondant
Obtenez toutes les adresses de bloc correspondant au fichier aléatoire, c'est-à-dire BlocksByAddress.
Crée un objet BlockStoreShuffleReader et le renvoie.
Il est principalement utilisé pour passer les paramètres de lecture aléatoire, et c'est aussi une marque pour marquer quel écrivain choisir.


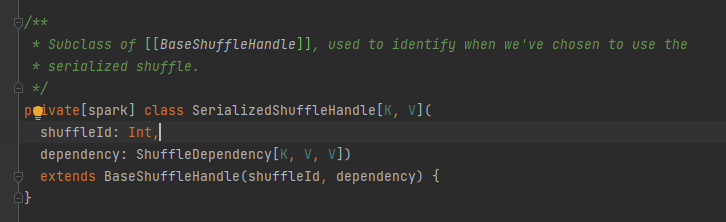
Classe abstraite, responsable des messages de sortie des tâches de cartographie. La méthode principale est l'écriture et il existe trois classes d'implémentation.
Sera analysé séparément plus tard.
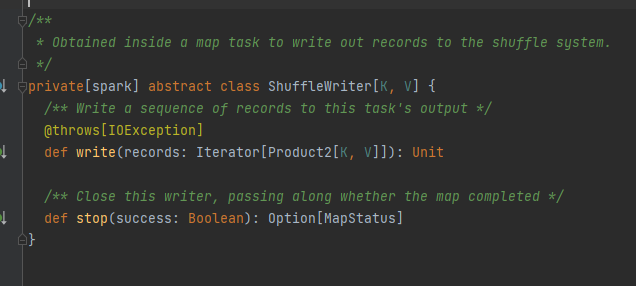
Trait, la classe d'implémentation peut obtenir les données de bloc correspondantes en fonction de mapId, réduireId, shuffleId.
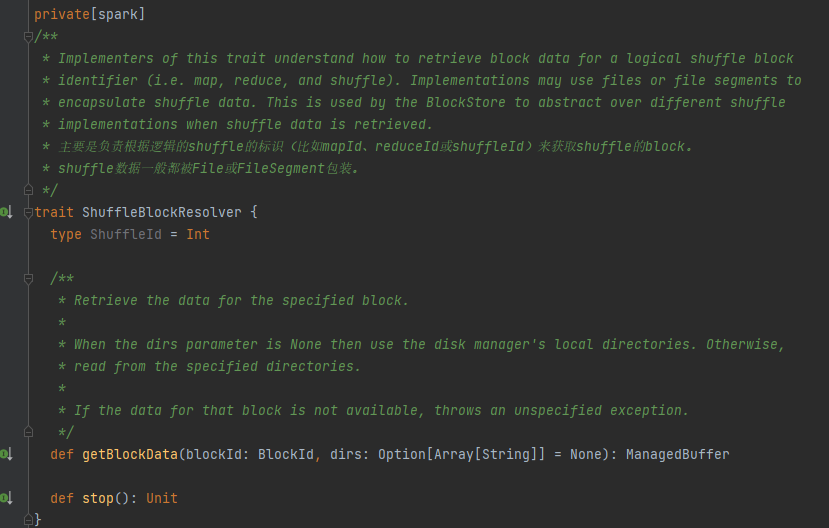
La seule classe d'implémentation de ShuffleBlockResolver.
Créez et gérez des mappages entre les blocs logiques et les emplacements de fichiers physiques pour mélanger les données de bloc de la même tâche de mappage.
Les données de blocs aléatoires appartenant à la même tâche cartographique seront stockées dans un fichier de données consolidé.
Les décalages de ces blocs de données dans le fichier de données sont stockés séparément dans un fichier d'index.
.data est le suffixe du fichier de données
.index est le suffixe du fichier d'index
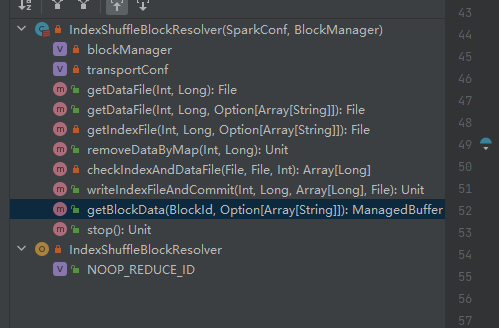
Obtenez le fichier de données.
Générez ShuffleDataBlockId et appelez la méthode blockManager.diskBlockManager.getFile pour obtenir le fichier
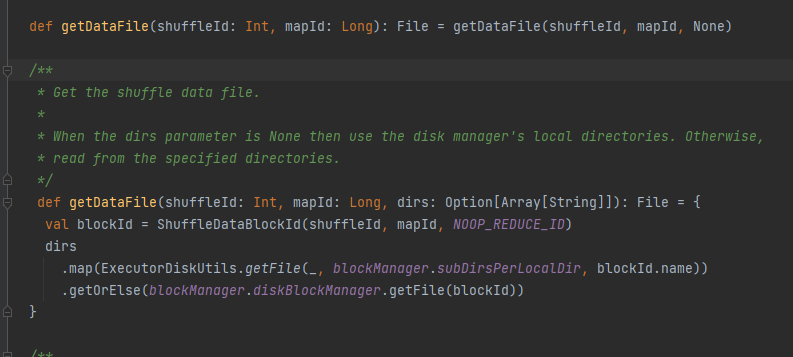
Semblable à getDataFile
Générez ShuffleIndexBlockId et appelez la méthode blockManager.diskBlockManager.getFile pour obtenir le fichier

Récupérez le fichier de données et le fichier d'index en fonction de shuffleId et mapId, puis supprimez-les
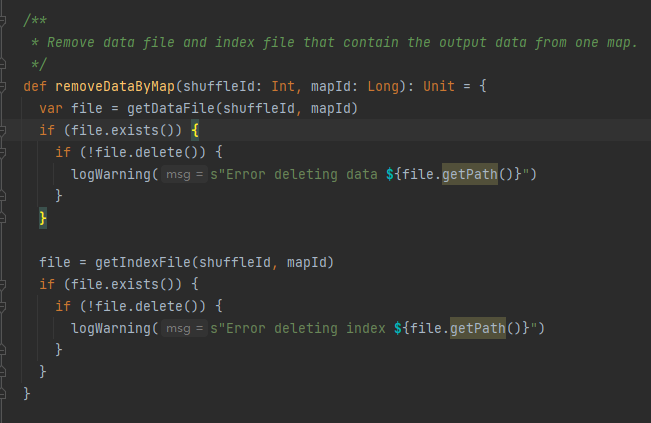
Obtenez le fichier de données et le fichier d'index correspondants selon mapId et shuffleId.
Vérifiez si le fichier de données et le fichier d'index existent et correspondent, et revenez directement.
S'il ne peut pas correspondre, un nouveau fichier temporaire d'index sera généré. Renommez ensuite le fichier d'index et le fichier de données générés et revenez.
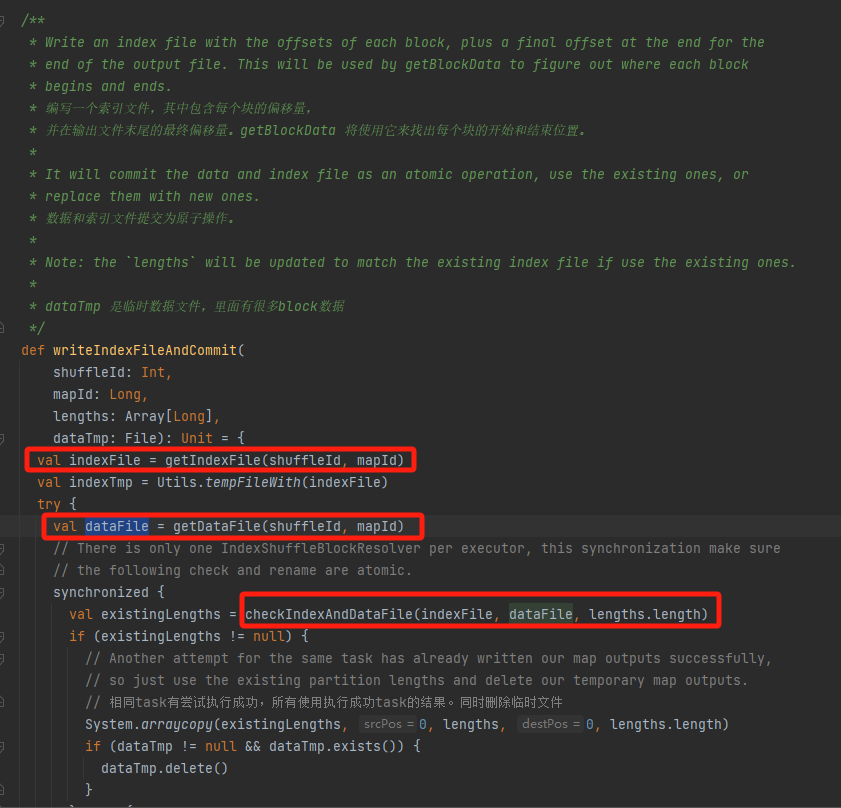

Supposons que la lecture aléatoire comporte trois partitions et que les tailles de données correspondantes sont respectivement de 1 000, 1 500 et 2 500.
Dans le fichier d'index, la première ligne est 0, suivie de la valeur cumulée des données de partition, la deuxième ligne est 1 000, la troisième ligne est 1 000+1 500=2 500 et la troisième ligne est 2 500+2 500=5 000.
Les fichiers de données sont stockés triés par taille de partition.

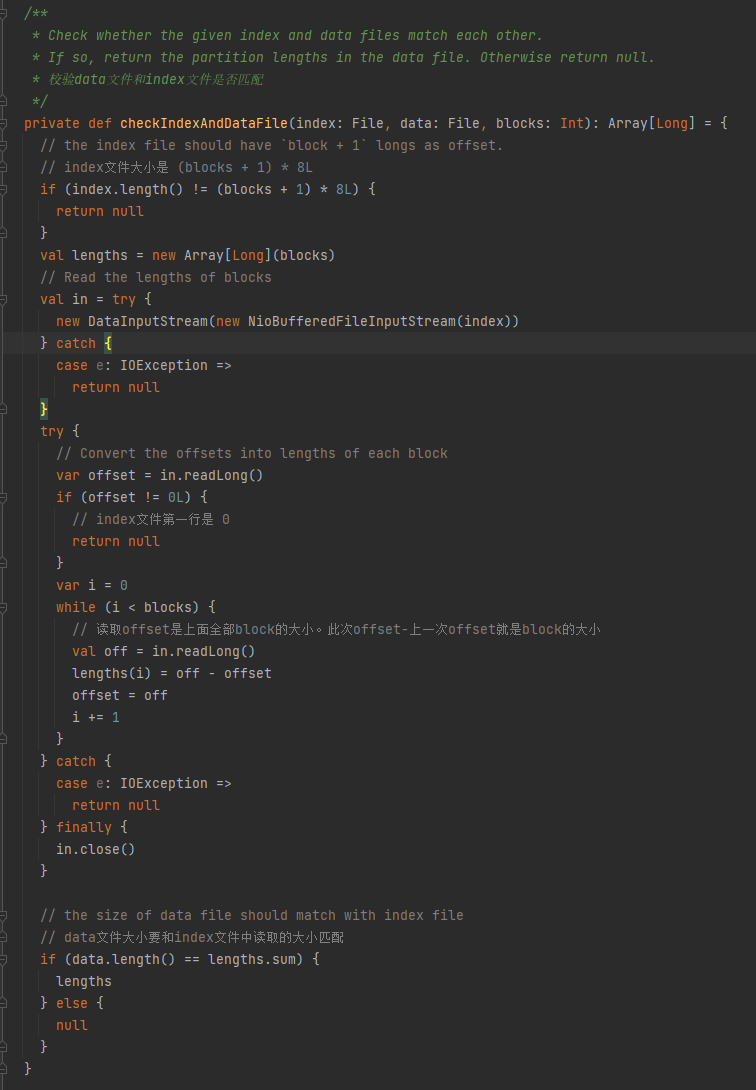
Vérifiez si le fichier de données et le fichier d'index correspondent. S'ils ne correspondent pas, null est renvoyé. S'ils correspondent, un tableau de taille de partition est renvoyé.
1.La taille du fichier d'index est de (blocs + 1) * 8L
2.La première ligne du fichier d'index est 0
3. Obtenez la taille de la partition et écrivez-la en longueurs. La valeur récapitulative des longueurs est égale à la taille du fichier de données.
Si les trois conditions ci-dessus sont remplies, lengths est renvoyé, sinon null est renvoyé.
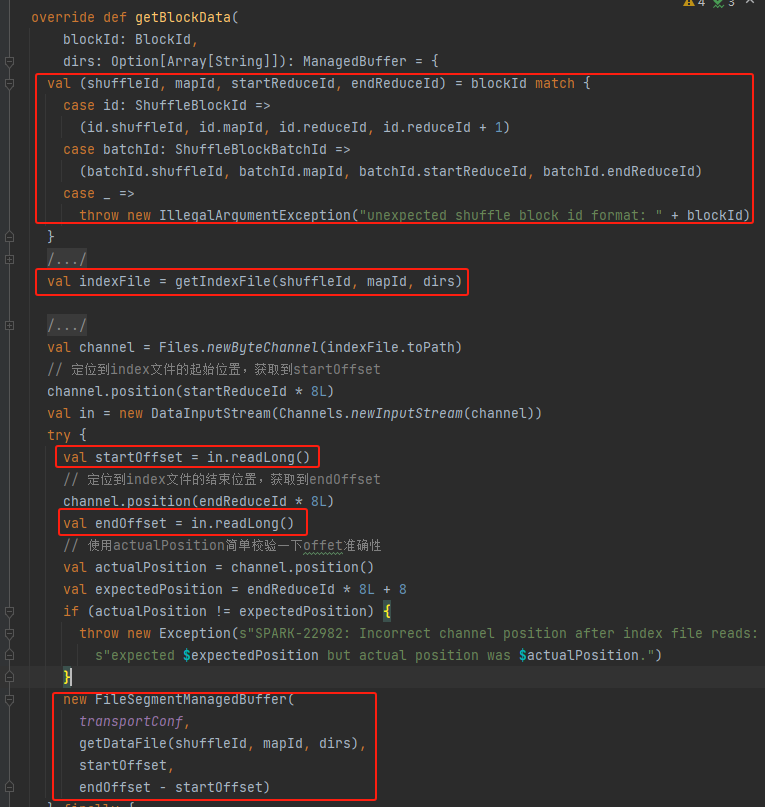
Obtenez shuffleId, mapId, startReduceId, endReduceId
Récupérer le fichier d'index
Lire les startOffset et endOffset correspondants
Utilisez le fichier de données, startOffset, endOffset pour générer FileSegmentManagedBuffer et renvoyer

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
