Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La entrada al sistema aleatorio. ShuffleManager se crea en sparkEnv en el controlador y el ejecutor. Registre la reproducción aleatoria en el controlador y lea y escriba datos en el ejecutor.
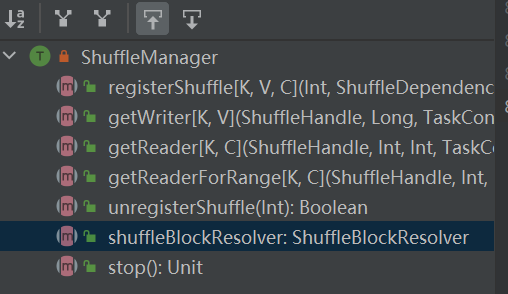
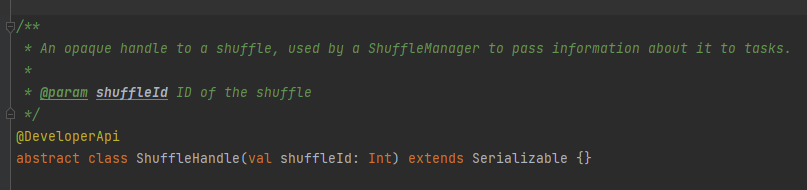
RegisterShuffle: registra la reproducción aleatoria, devuelve shuffleHandle
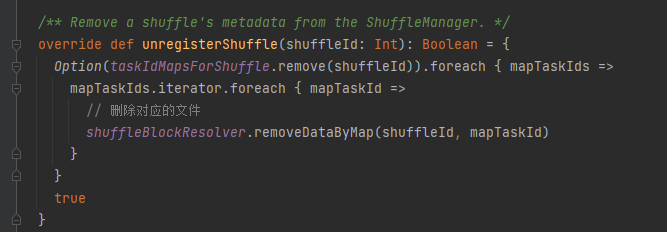
unregisterShuffle: eliminar la reproducción aleatoria
shuffleBlockResolver: obtiene shuffleBlockResolver, utilizado para manejar la relación entre reproducción aleatoria y bloque
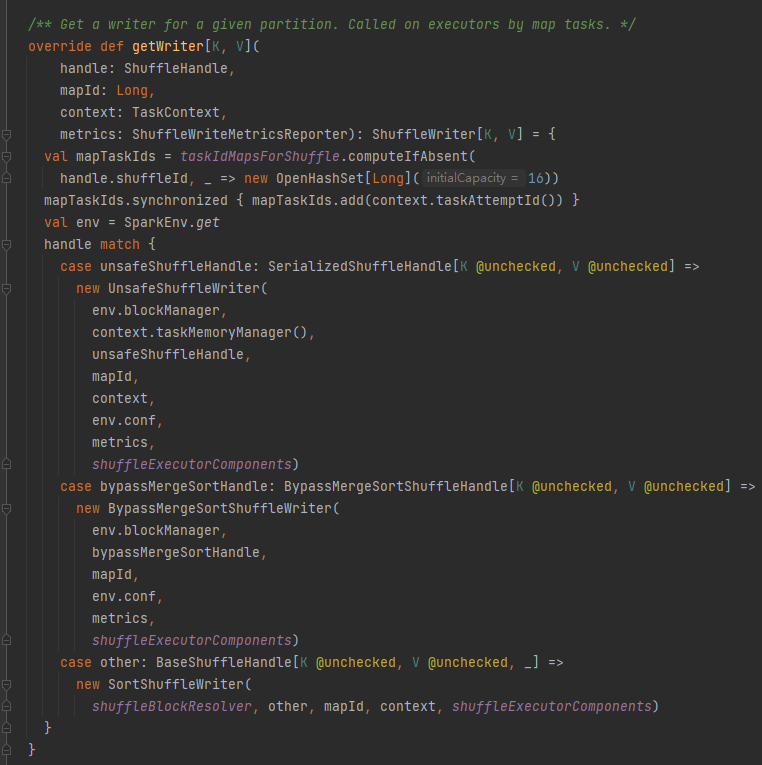
getWriter: obtiene el escritor correspondiente a la partición y lo llama en la tarea de mapa del ejecutor
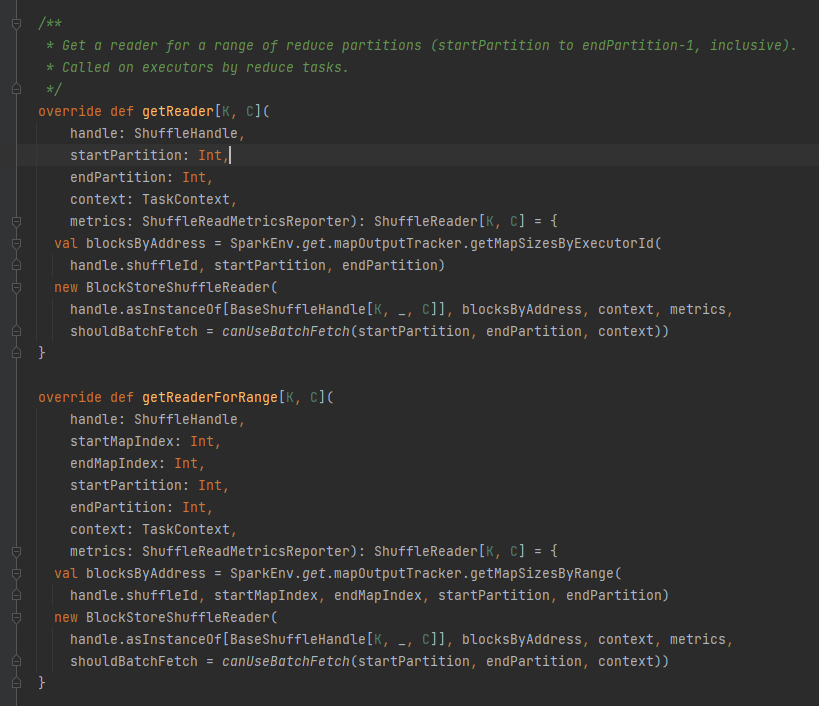
getReader, getReaderForRange: obtiene el lector de una partición de rango y lo llama en la tarea de reducción del ejecutor.
Es la única implementación de shuffleManager.
En una reproducción aleatoria basada en clasificación, los mensajes entrantes se clasifican según particiones y, finalmente, se genera un archivo separado.
El reductor leerá una región de datos de este archivo.
Cuando el archivo de salida es demasiado grande para caber en la memoria, un archivo de resultados intermedio ordenado se derramará en el disco y estos archivos intermedios se fusionarán en un archivo final para la salida.
La reproducción aleatoria basada en clasificación tiene dos métodos:
Ventajas de la clasificación serializada
En el modo de clasificación serializada, el escritor aleatorio serializa los mensajes entrantes, los guarda en una estructura de datos y los clasifica.
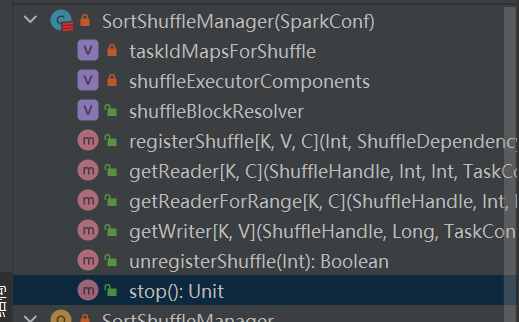
Elija el mango correspondiente según los diferentes escenarios. El orden de prioridad es BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
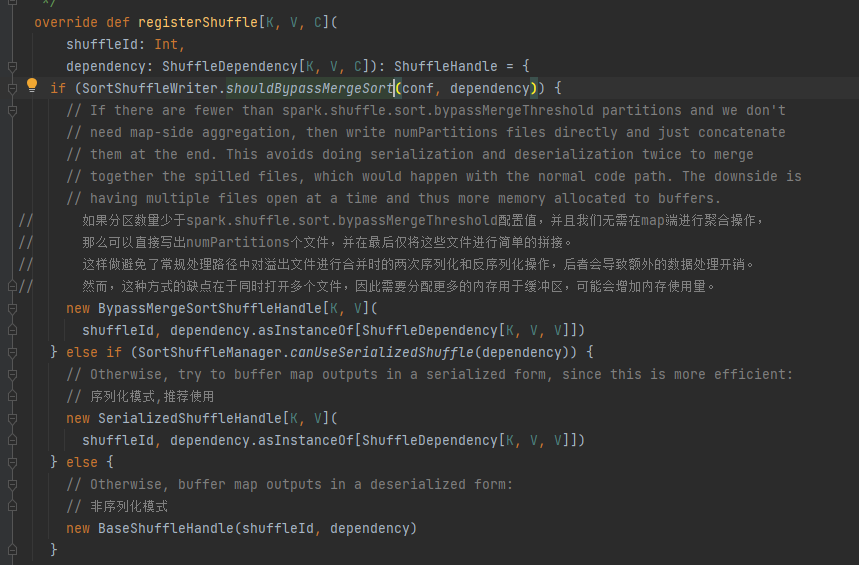
Condición de omisión: sin lado del mapa, el número de particiones es menor o igual a _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Condiciones de manejo de serialización: la clase de serialización admite la migración de objetos serializados, no utiliza la operación mapSideCombine y el número de particiones del RDD principal no es mayor que (1 << 24)
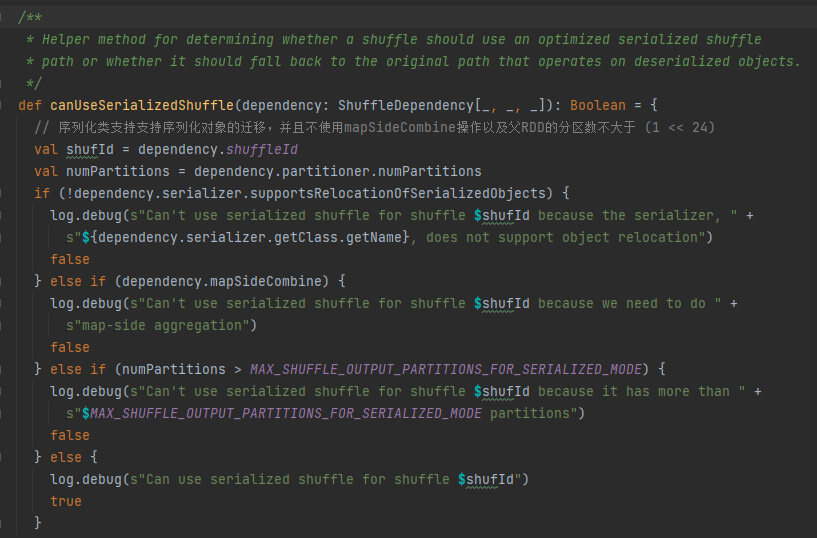
Primero guarde en caché esta información aleatoria y de mapa en taskIdMapsForShuffle_
Seleccione el escritor correspondiente según el identificador correspondiente a la reproducción aleatoria.
OmitirMergeSortShuffleHandle->OmitirMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle elimina el mapa aleatorio correspondiente y los archivos generados por el mapa correspondiente al aleatorio
Obtenga todas las direcciones de bloque correspondientes al archivo aleatorio, es decir, blocksByAddress.
Crea un objeto BlockStoreShuffleReader y lo devuelve.
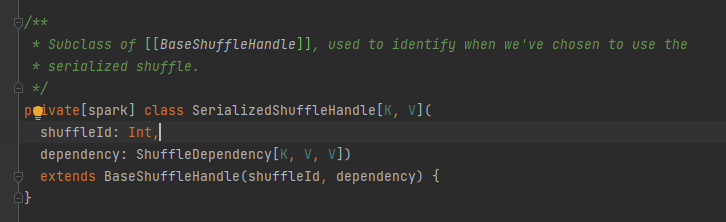
Se utiliza principalmente para pasar parámetros de reproducción aleatoria y también es una marca para marcar qué escritor elegir.


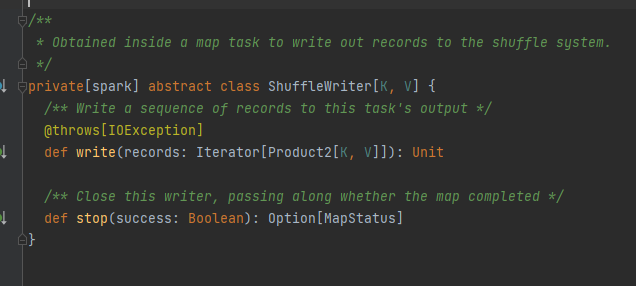
Clase abstracta, responsable de los mensajes de salida de la tarea de mapa. El método principal es la escritura y hay tres clases de implementación.
Se analizará por separado más adelante.
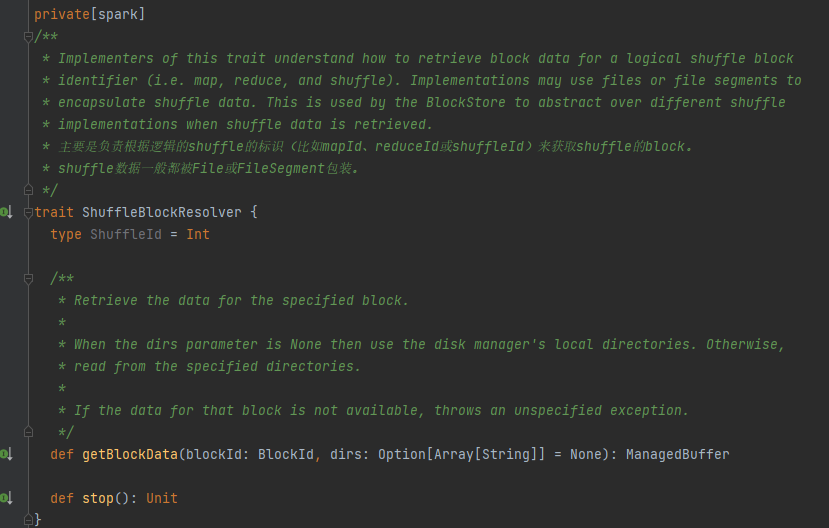
Característica, la clase de implementación puede obtener los datos del bloque correspondiente según mapId, reduceId, shuffleId.
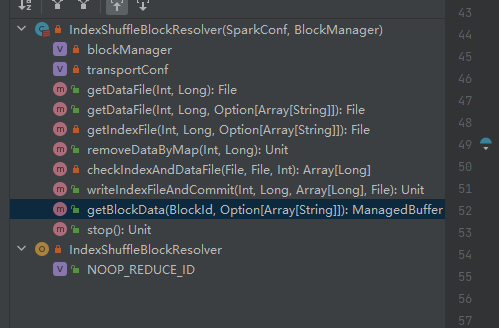
La única clase de implementación de ShuffleBlockResolver.
Cree y mantenga asignaciones entre bloques lógicos y ubicaciones de archivos físicos para mezclar datos de bloques desde la misma tarea de mapa.
Los datos del bloque aleatorio que pertenecen a la misma tarea de mapa se almacenarán en un archivo de datos consolidado.
Los desplazamientos de estos bloques de datos en el archivo de datos se almacenan por separado en un archivo de índice.
.data es el sufijo del archivo de datos
.index es el sufijo del archivo índice
Obtenga el archivo de datos.
Genere ShuffleDataBlockId y llame al método blockManager.diskBlockManager.getFile para obtener el archivo
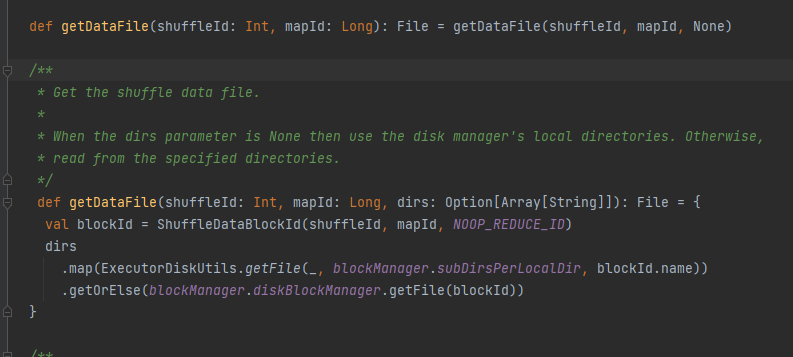
Similar a obtener archivo de datos
Genere ShuffleIndexBlockId y llame al método blockManager.diskBlockManager.getFile para obtener el archivo

Obtenga el archivo de datos y el archivo de índice según shuffleId y mapId, y luego elimínelos
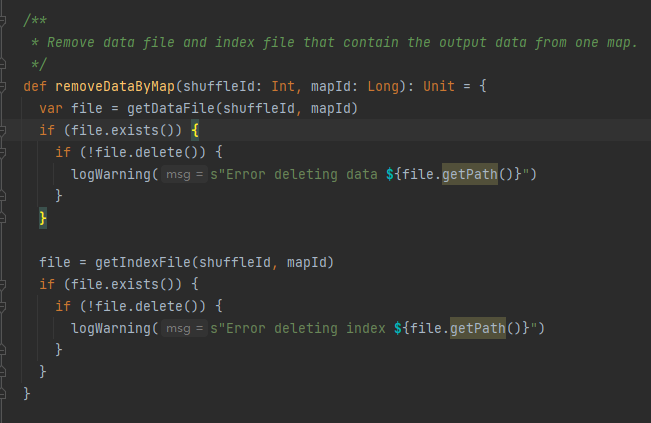
Obtenga el archivo de datos y el archivo de índice correspondientes según mapId y shuffleId.
Compruebe si el archivo de datos y el archivo de índice existen y coinciden, y regrese directamente.
Si no puede coincidir, se generará un nuevo archivo temporal de índice. Luego cambie el nombre del archivo de índice y el archivo de datos generados y regrese.
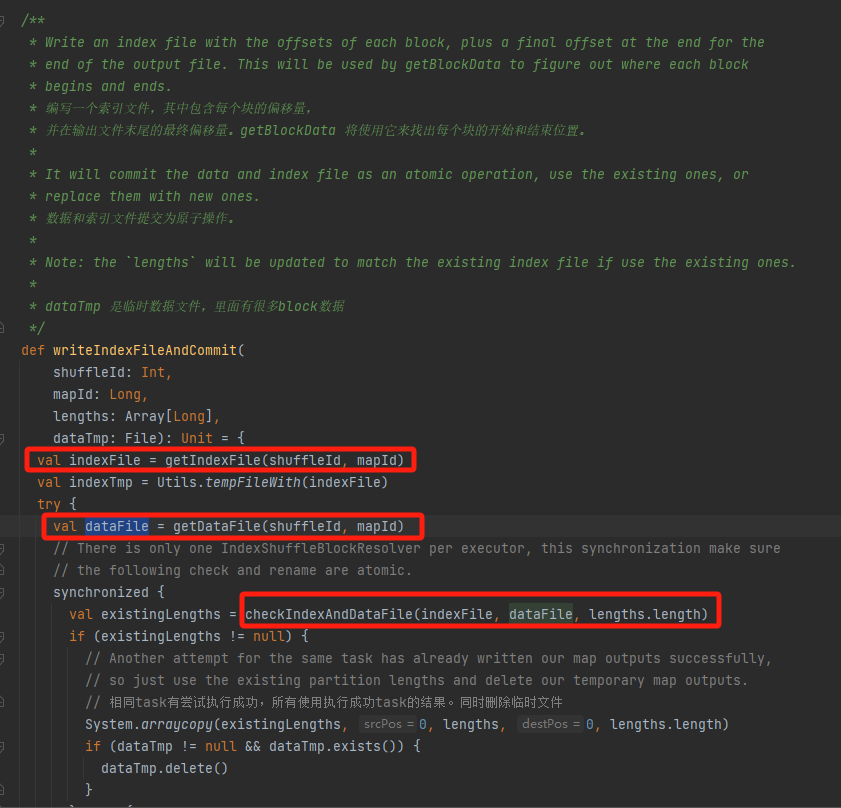

Supongamos que la reproducción aleatoria tiene tres particiones y que los tamaños de datos correspondientes son 1000, 1500 y 2500 respectivamente.
En el archivo de índice, la primera línea es 0, seguida del valor acumulado de los datos de la partición. La segunda línea es 1000, la tercera línea es 1000+1500=2500 y la tercera línea es 2500+2500=5000.
Los archivos de datos se almacenan ordenados por tamaño de partición.

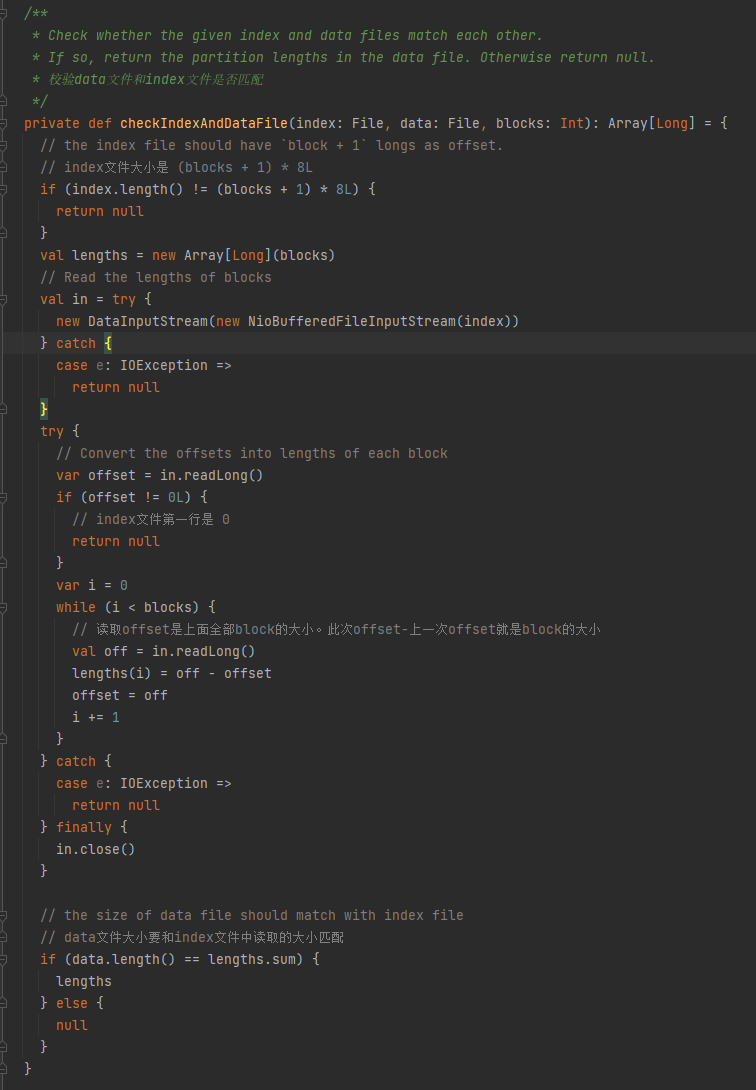
Verifique si el archivo de datos y el archivo de índice coinciden. Si no coinciden, se devuelve nulo. Si coinciden, se devuelve una matriz del tamaño de la partición.
1.El tamaño del archivo de índice es (bloques + 1) * 8L
2.La primera línea del archivo de índice es 0.
3. Obtenga el tamaño de la partición y escríbalo en longitudes. El valor resumido de las longitudes es igual al tamaño del archivo de datos.
Si se cumplen las tres condiciones anteriores, se devuelven longitudes; de lo contrario, se devuelve nulo.
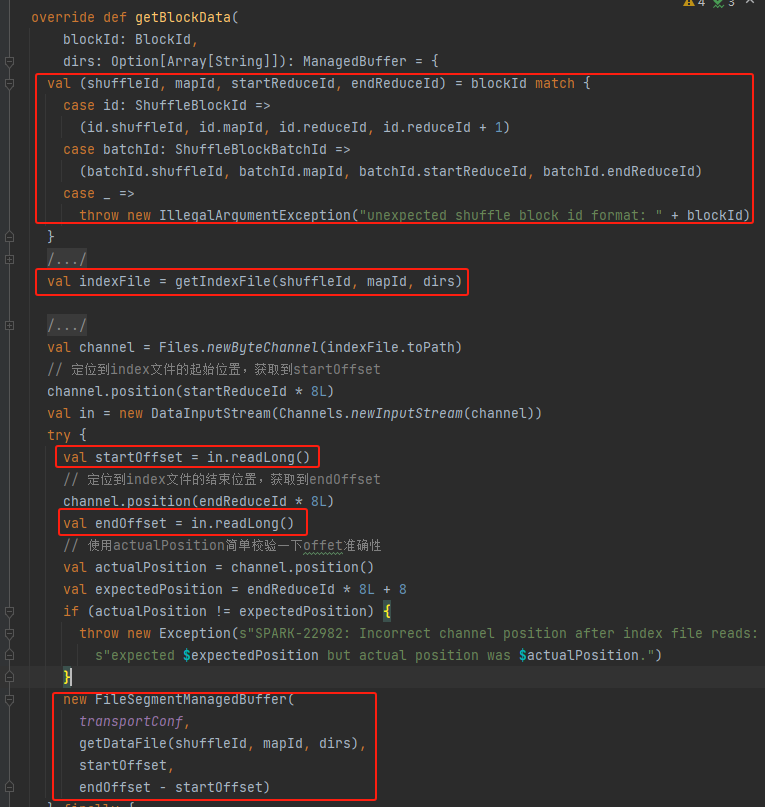
Obtener shuffleId, mapId, startReduceId, endReduceId
Obtener el archivo de índice
Lea el startOffset y endOffset correspondientes
Utilice el archivo de datos, startOffset, endOffset para generar FileSegmentManagedBuffer y devolver

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]