私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
シャッフルシステムへの入り口。 ShuffleManagerはドライバーとエグゼキューターのsparkEnv内に作成されます。ドライバにシャッフルを登録し、エグゼキュータでデータの読み書きを行います。
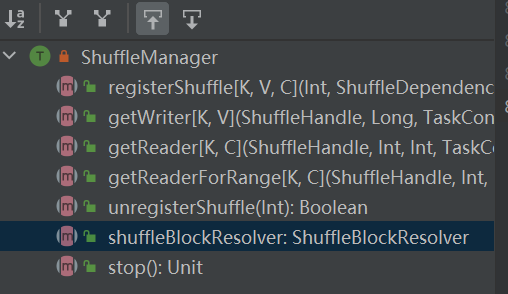
registerShuffle: シャッフルを登録し、shuffleHandle を返します。
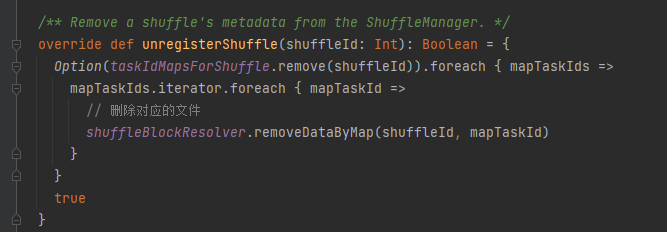
unregisterShuffle: シャッフルを削除します
shuffleBlockResolver: シャッフルとブロックの間の関係を処理するために使用される shuffleBlockResolver を取得します。
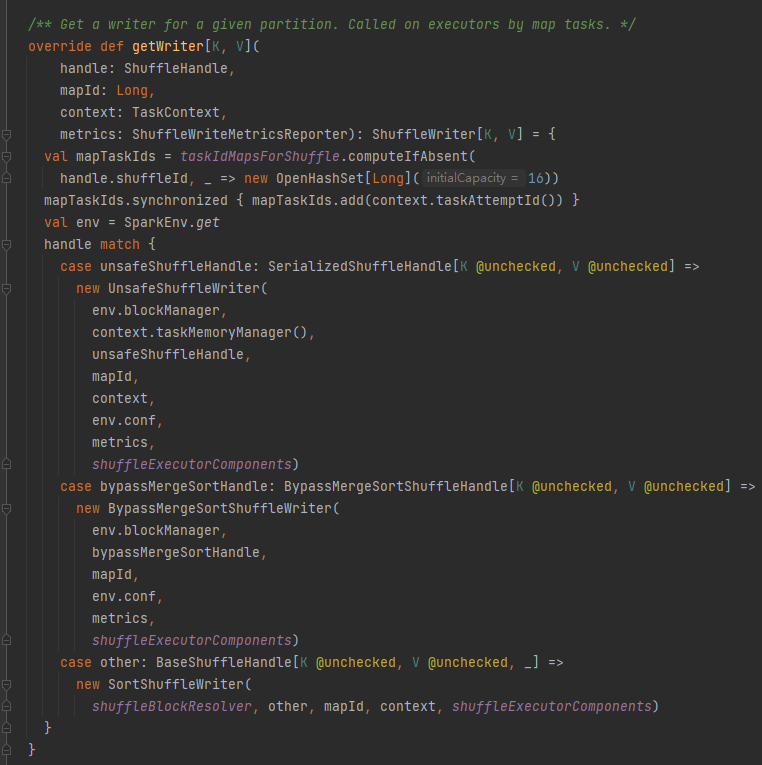
getWriter: パーティションに対応するライターを取得し、エグゼキューターのマップタスクで呼び出します。
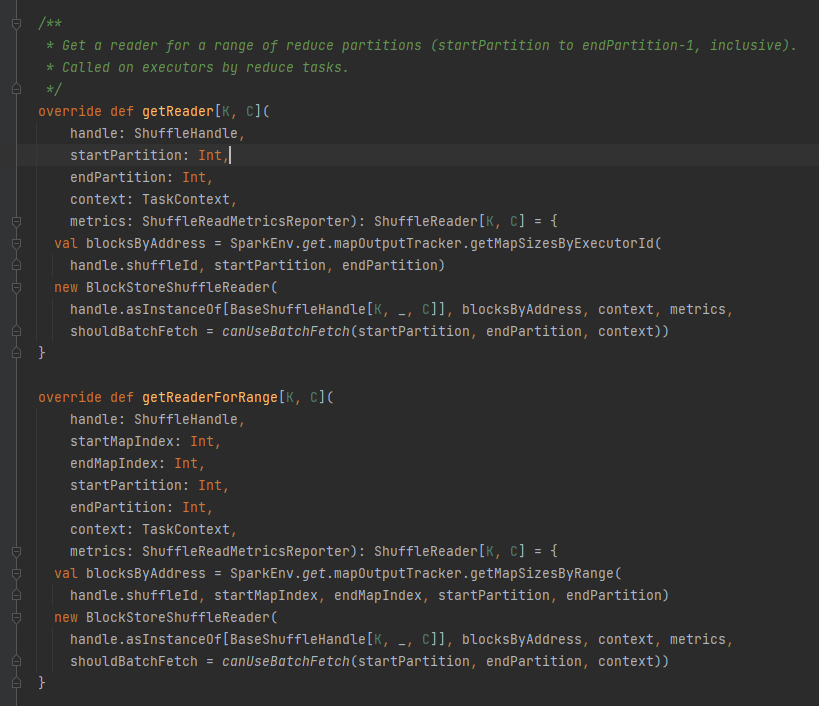
getReader、getReaderForRange: 範囲パーティションのリーダーを取得し、エグゼキューターの Reduce タスクで呼び出します。
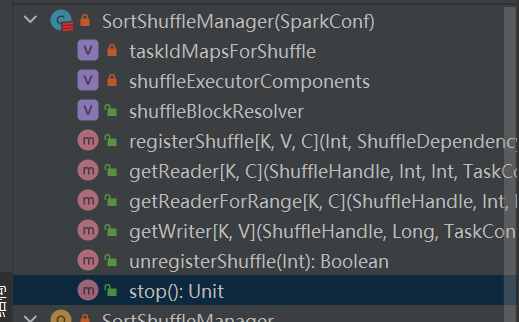
shuffleManager の唯一の実装です。
ソートベースのシャッフルでは、受信メッセージがパーティションに従ってソートされ、最終的に別のファイルが出力されます。
リデューサーは、このファイルからデータの領域を読み取ります。
出力ファイルが大きすぎてメモリに収まらない場合、ソートされた中間結果ファイルがディスク上にあふれ、これらの中間ファイルは出力用の最終ファイルにマージされます。
ソートベースのシャッフルには 2 つの方法があります。
シリアル化ソートの利点
シリアル化並べ替えモードでは、シャッフル ライターは受信メッセージをシリアル化してデータ構造に保存し、並べ替えます。
さまざまなシナリオに応じて、対応するハンドルを選択してください。優先順位は BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle です。
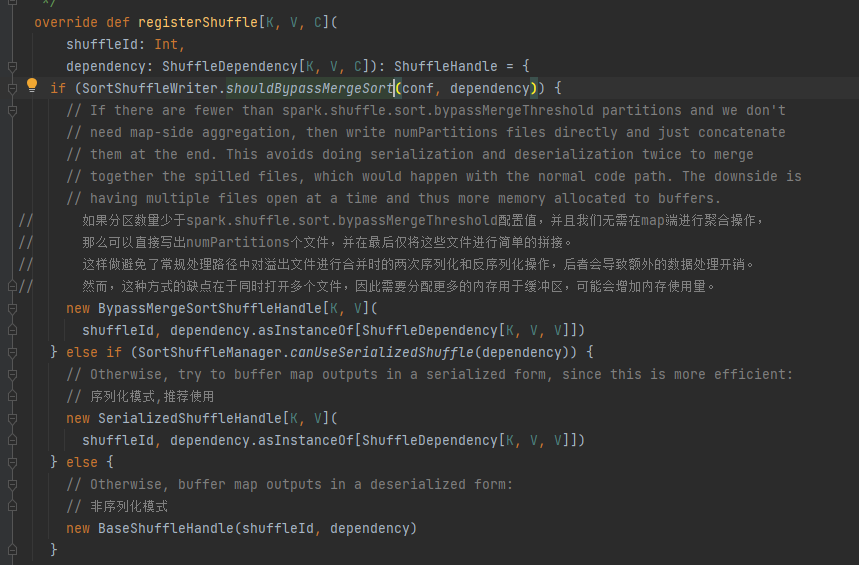
バイパス条件: マップサイドなし、パーティションの数が _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_ 以下である

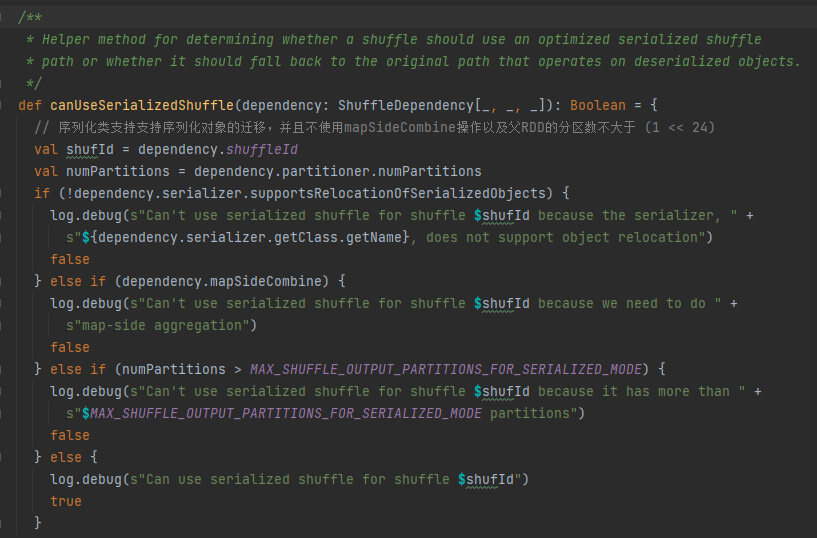
シリアル化ハンドルの条件: シリアル化クラスはシリアル化オブジェクトの移行をサポートし、mapSideCombine 操作を使用せず、親 RDD のパーティション数は (1 << 24) 以下です。
まずこのシャッフルをキャッシュし、情報を taskIdMapsForShuffle_ にマップします
シャッフルに対応するハンドルに基づいて、対応するライターを選択します。
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
シリアル化されたShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
taskIdMapsForShuffle は、対応するシャッフルと、シャッフル対応マップによって生成されたファイルを削除します
シャッフル ファイルに対応するすべてのブロック アドレス (blocksByAddress) を取得します。
BlockStoreShuffleReader オブジェクトを作成して返します。
主にシャッフルのパラメータを渡すために使用され、どのライターを選択するかを示すマークでもあります。
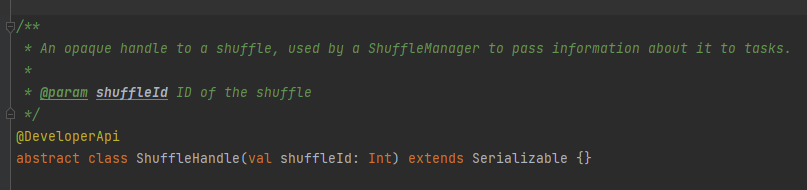


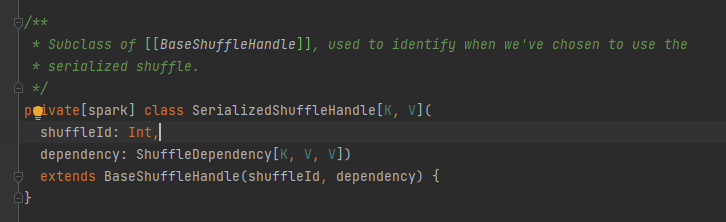
マップ タスクの出力メッセージを担当する抽象クラス。主なメソッドは write で、3 つの実装クラスがあります。
後ほど別途分析させていただきます。
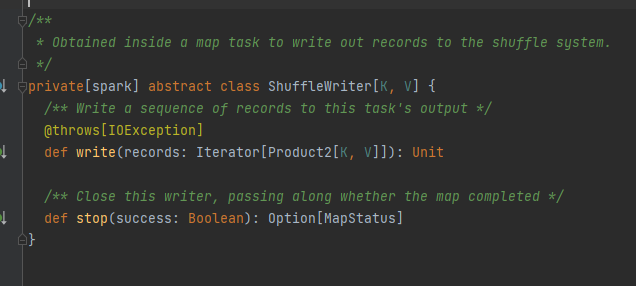
特性、実装クラスは、mapId、reduceId、shuffleId に基づいて対応するブロック データを取得できます。
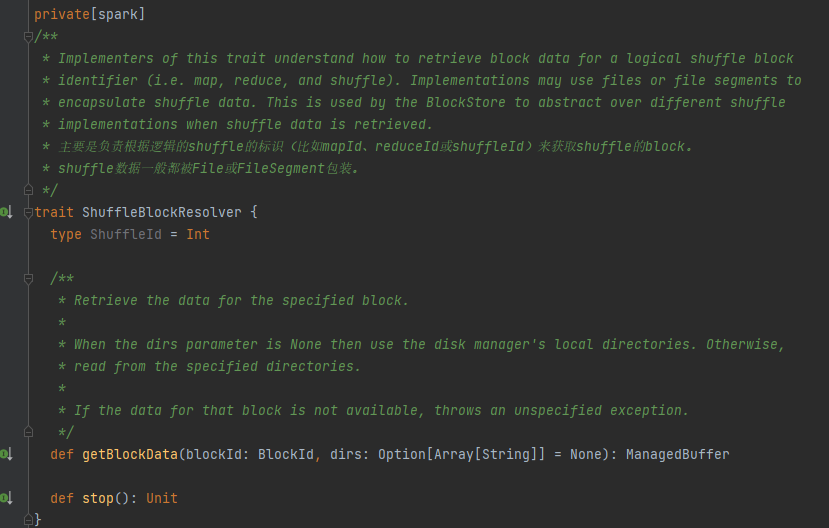
ShuffleBlockResolver の唯一の実装クラス。
同じマップ タスクからのシャッフル ブロック データの論理ブロックと物理ファイルの場所の間のマッピングを作成および維持します。
同じマップタスクに属するシャッフルブロックデータは、統合データファイルに保存されます。
データ ファイル内のこれらのデータ ブロックのオフセットは、インデックス ファイルに個別に保存されます。
.data はデータファイルの接尾辞です
.index はインデックス ファイルの接尾辞です。
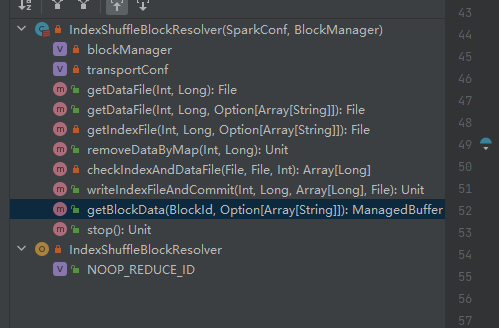
データファイルを取得します。
ShuffleDataBlockId を生成し、blockManager.diskBlockManager.getFile メソッドを呼び出してファイルを取得します
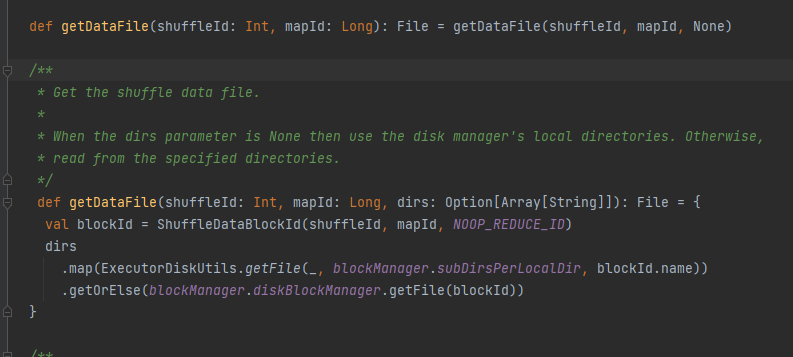
getDataFileに似ている
ShuffleIndexBlockId を生成し、blockManager.diskBlockManager.getFile メソッドを呼び出してファイルを取得します

shuffleIdとmapIdに基づいてデータファイルとインデックスファイルを取得し、削除します
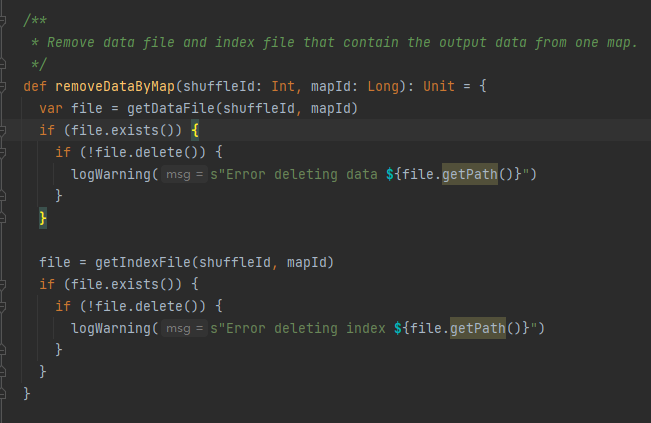
mapIdとshuffleIdに従って、対応するデータファイルとインデックスファイルを取得します。
データファイルとインデックスファイルが存在し、一致するかどうかを確認し、直接リターンします。
一致しない場合は、新しいインデックス一時ファイルが生成されます。次に、生成されたインデックス ファイルとデータ ファイルの名前を変更して戻ります。
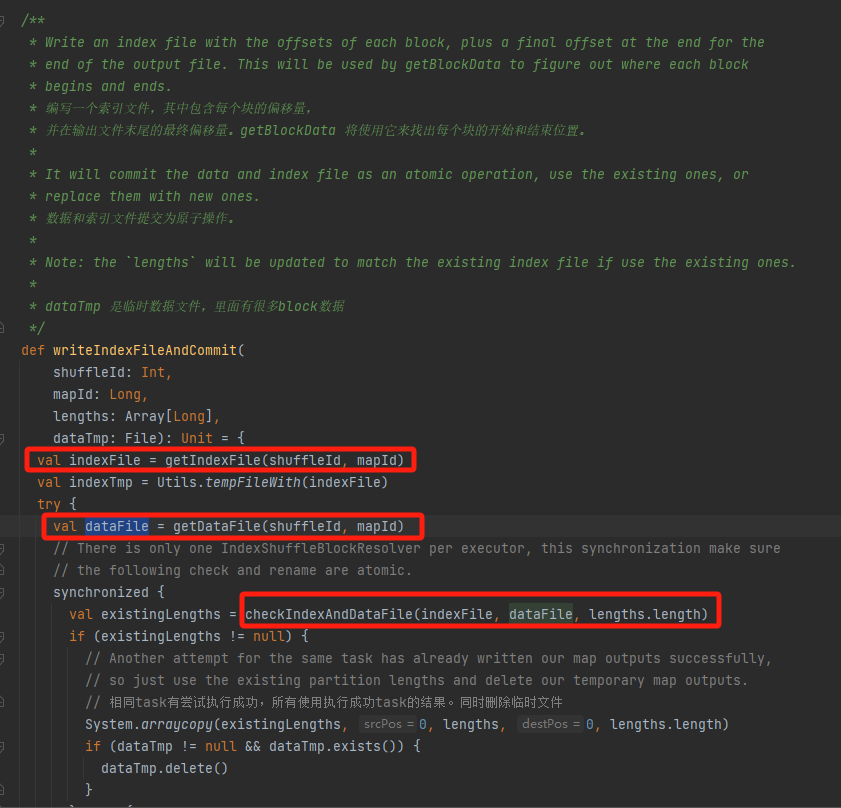

シャッフルに 3 つのパーティションがあり、対応するデータ サイズがそれぞれ 1000、1500、2500 であるとします。
インデックスファイルの1行目は0、2行目は1000、3行目は1000+1500=2500、3行目は2500+2500=5000となります。
データ ファイルはパーティション サイズごとにソートされて保存されます。

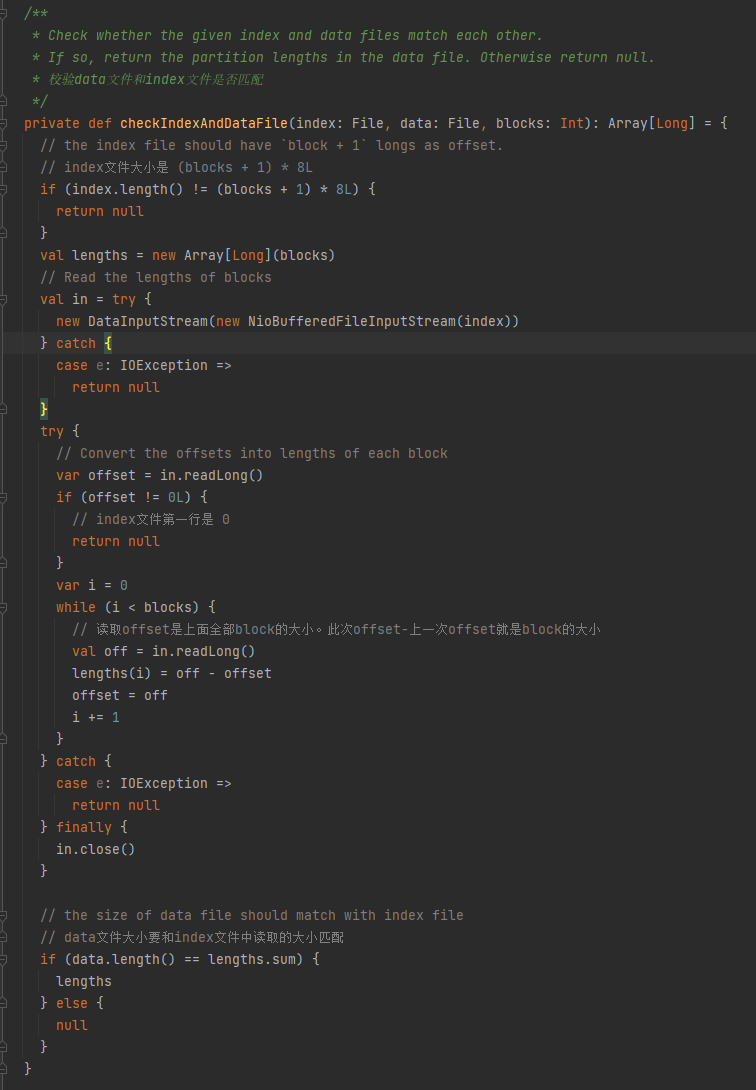
データファイルとインデックスファイルが一致するかどうかを確認し、一致しない場合は null を返し、一致する場合はパーティション サイズの配列を返します。
1.インデックスファイルのサイズは(ブロック+1)*8Lです。
2.インデックスファイルの1行目は0です
3. パーティションのサイズを取得し、長さに書き込みます。長さの合計値はデータ ファイルのサイズと等しくなります。
上記 3 つの条件が満たされる場合は長さが返され、そうでない場合は null が返されます。
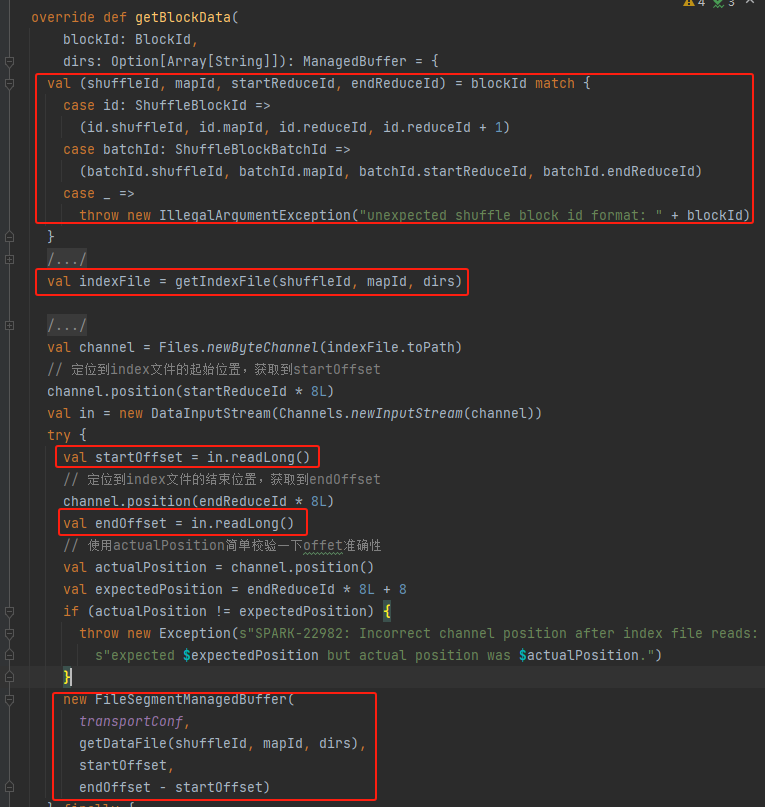
shuffleId、mapId、startReduceId、endReduceId を取得します
インデックスファイルを取得する
対応する startOffset と endOffset を読み取ります。
データ ファイル、startOffset、endOffset を使用して FileSegmentManagedBuffer を生成し、返します

彼は 30 年以上テクノロジーの研究に専念しており、Java、Linux、JavaScript、PHP、CSS などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: