моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Вход в систему перемешивания. ShuffleManager создается в sparkEnv в драйвере и исполнителе. Зарегистрируйте shuffle в драйвере и читайте и записывайте данные в исполнителе.
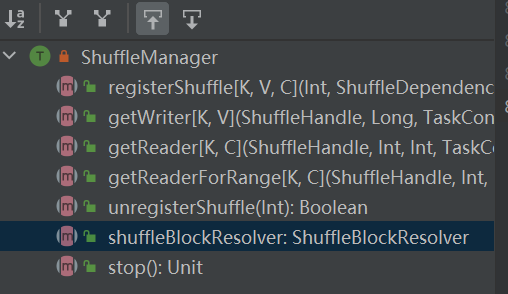
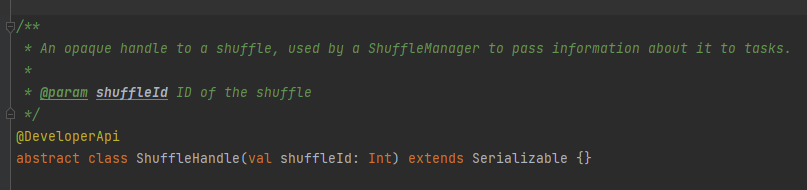
RegisterShuffle: зарегистрировать перемешивание, вернуть shuffleHandle
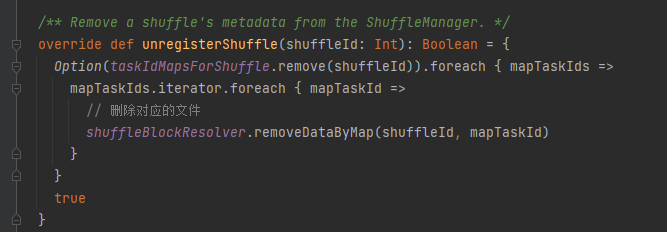
unregisterShuffle: удалить перемешивание
shuffleBlockResolver: получите shuffleBlockResolver, используемый для обработки взаимосвязи между перемешиванием и блокировкой.
getWriter: получить средство записи, соответствующее разделу, и вызвать его в задаче карты исполнителя.
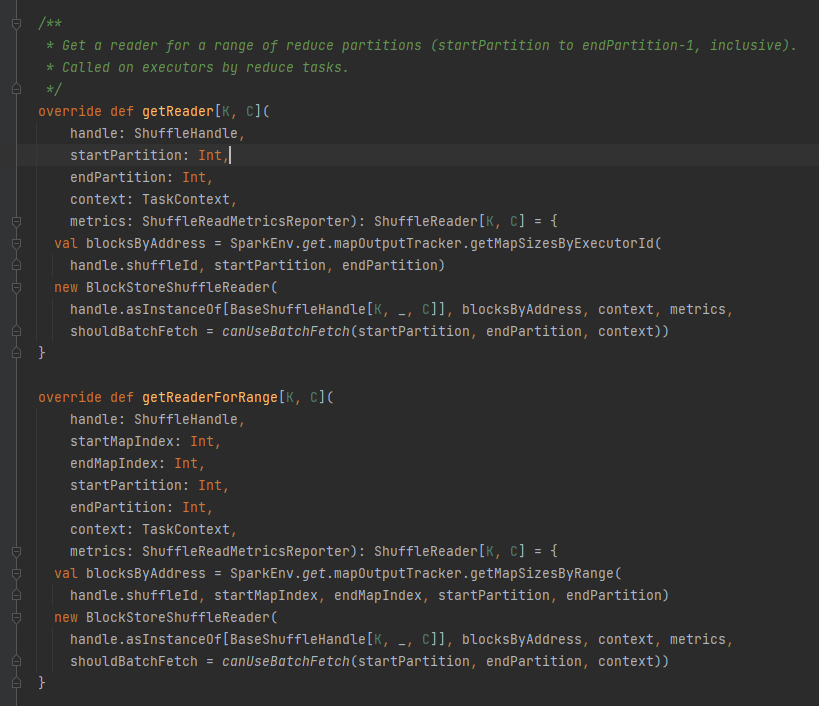
getReader, getReaderForRange: получить средство чтения раздела диапазона и вызвать его в задаче сокращения исполнителя.
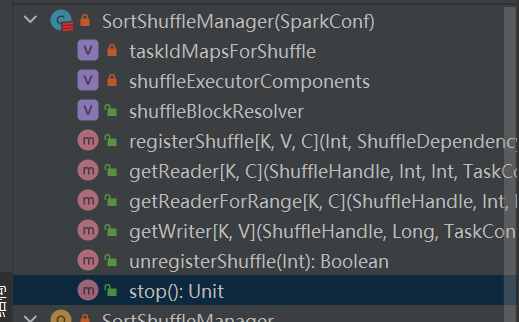
Это единственная реализация shuffleManager.
При перемешивании на основе сортировки входящие сообщения сортируются по разделам и, наконец, выводятся в отдельный файл.
Редюсер прочитает область данных из этого файла.
Если выходной файл слишком велик и не помещается в памяти, отсортированный файл промежуточных результатов будет перенесен на диск, и эти промежуточные файлы будут объединены в окончательный файл для вывода.
Перетасовка на основе сортировки имеет два метода:
Преимущества сериализованной сортировки
В режиме сериализованной сортировки модуль записи в случайном порядке сериализует входящие сообщения, сохраняет их в структуре данных и сортирует.
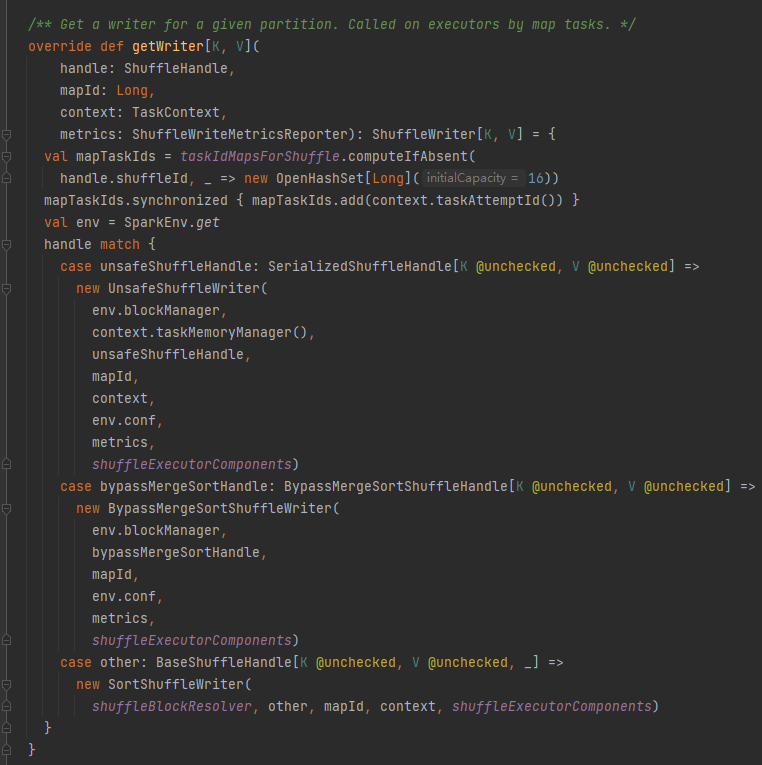
Выберите соответствующий дескриптор в соответствии с различными сценариями. Порядок приоритетов: BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle.
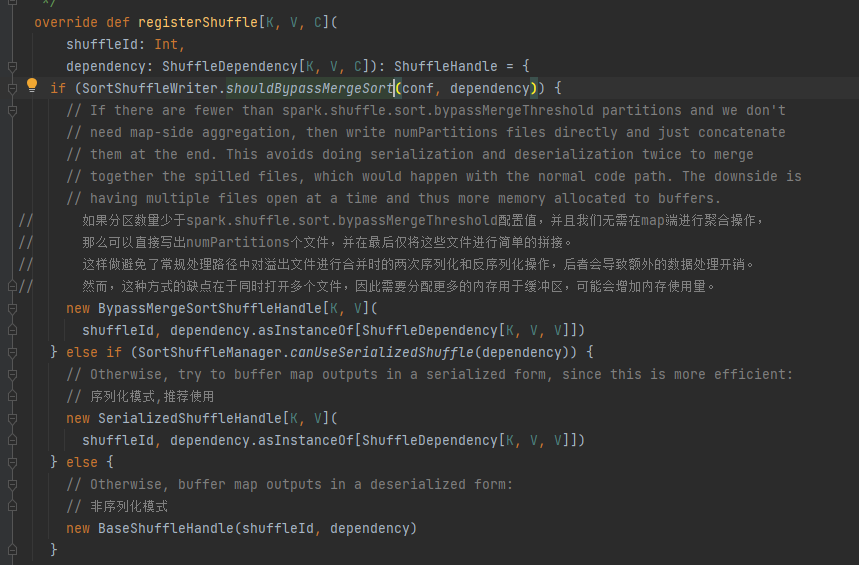
Условие обхода: нет карты, количество разделов меньше или равно _SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

Условия дескриптора сериализации: класс сериализации поддерживает миграцию сериализованных объектов, не использует операцию mapSideCombine, а количество разделов родительского RDD не превышает (1 << 24).
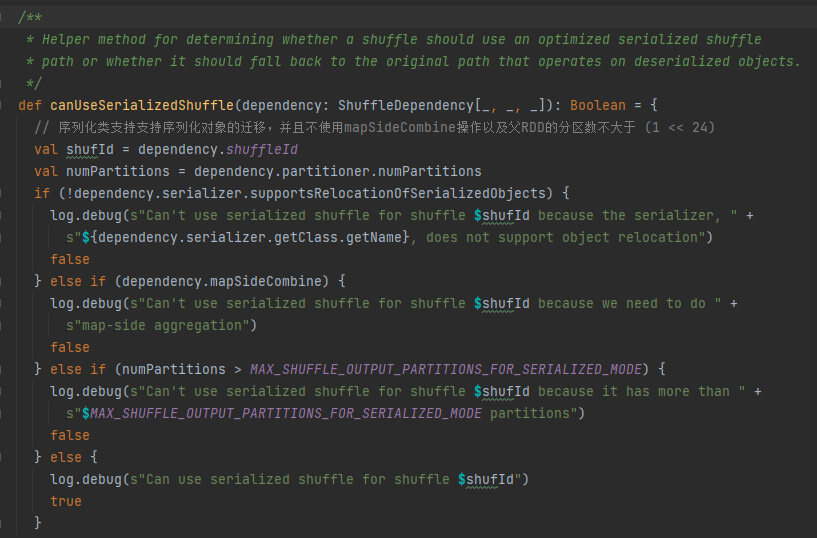
Сначала кэшируйте это перемешивание и сопоставьте информацию с TaskIdMapsForShuffle_.
Выберите соответствующего писателя на основе дескриптора, соответствующего перетасовке.
ОбходMergeSortShuffleHandle->ОбходMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
TaskIdMapsForShuffle удаляет соответствующее перемешивание и файлы, созданные в результате перемешивания соответствующей карты.
Получите все адреса блоков, соответствующие файлу перемешивания, то естьblocksByAddress.
Создает объект BlockStoreShuffleReader и возвращает его.
В основном он используется для передачи параметров перемешивания, а также является меткой, указывающей, какой писатель выбрать.


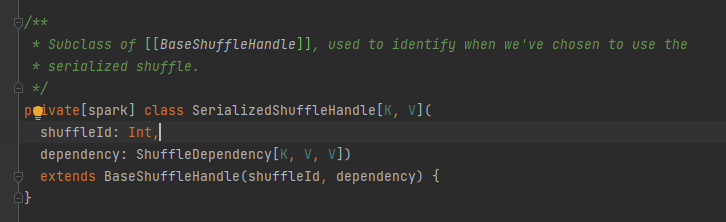
Абстрактный класс, отвечающий за выходные сообщения задачи карты. Основной метод — write, и существует три класса реализации.
Позже будет проанализировано отдельно.
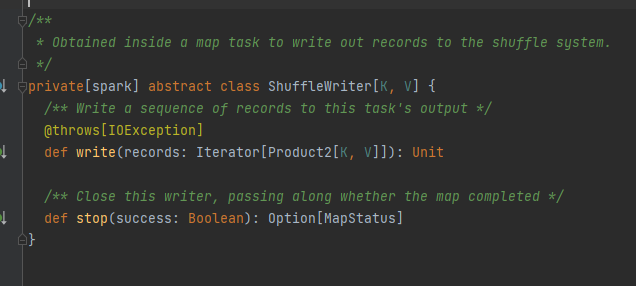
Особенность: класс реализации может получить соответствующие данные блока на основе MapId, ReducId, ShuffleId.
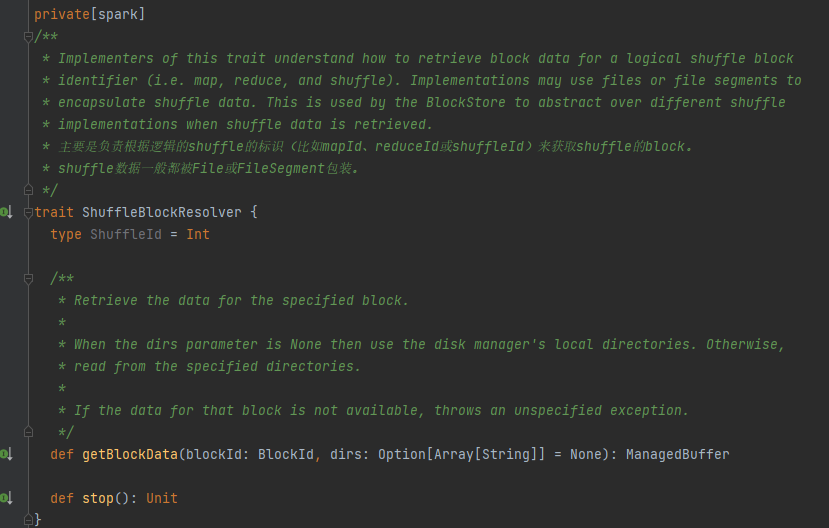
Единственный класс реализации ShuffleBlockResolver.
Создавайте и обслуживайте сопоставления между логическими блоками и физическими расположениями файлов для перемешивания данных блоков из одной и той же задачи сопоставления.
Данные блока перемешивания, принадлежащие одной и той же задаче карты, будут храниться в консолидированном файле данных.
Смещения этих блоков данных в файле данных сохраняются отдельно в индексном файле.
.data — это суффикс файла данных.
.index — это суффикс индексного файла.
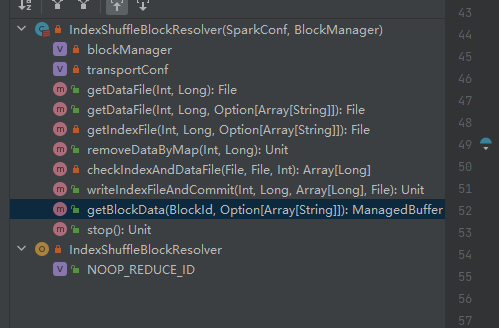
Получите файл данных.
Создайте ShuffleDataBlockId и вызовите метод blockManager.diskBlockManager.getFile, чтобы получить файл.
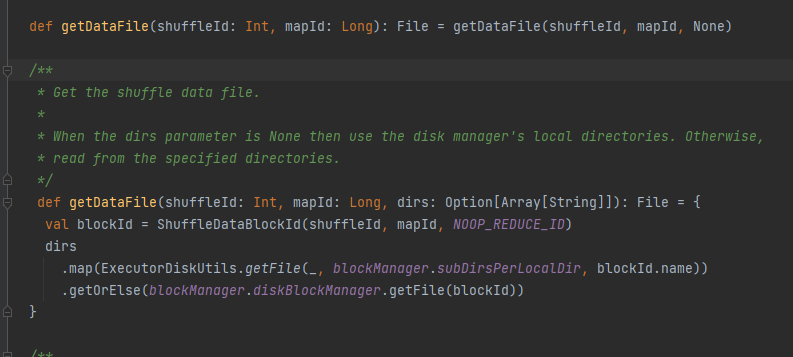
Похоже на: getDataFile
Создайте ShuffleIndexBlockId и вызовите метод blockManager.diskBlockManager.getFile, чтобы получить файл.

Получите файл данных и индексный файл на основе shuffleId и MapId, а затем удалите их.
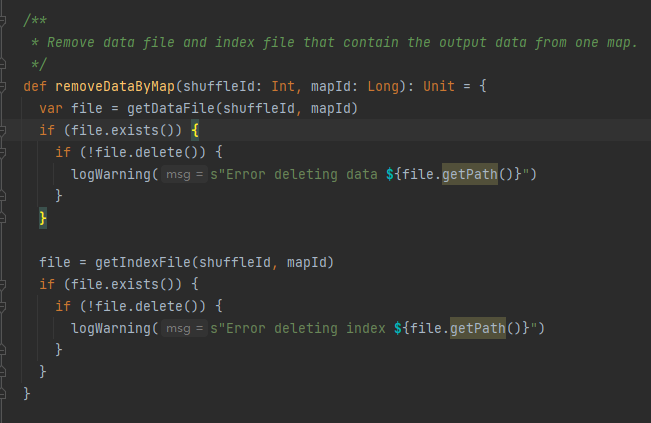
Получите соответствующий файл данных и файл индекса в соответствии с идентификаторами карты и shuffleId.
Проверьте, существуют ли и совпадают ли файл данных и индексный файл, и верните их напрямую.
Если он не может совпасть, будет создан новый временный файл индекса. Затем переименуйте сгенерированный индексный файл и файл данных и вернитесь.
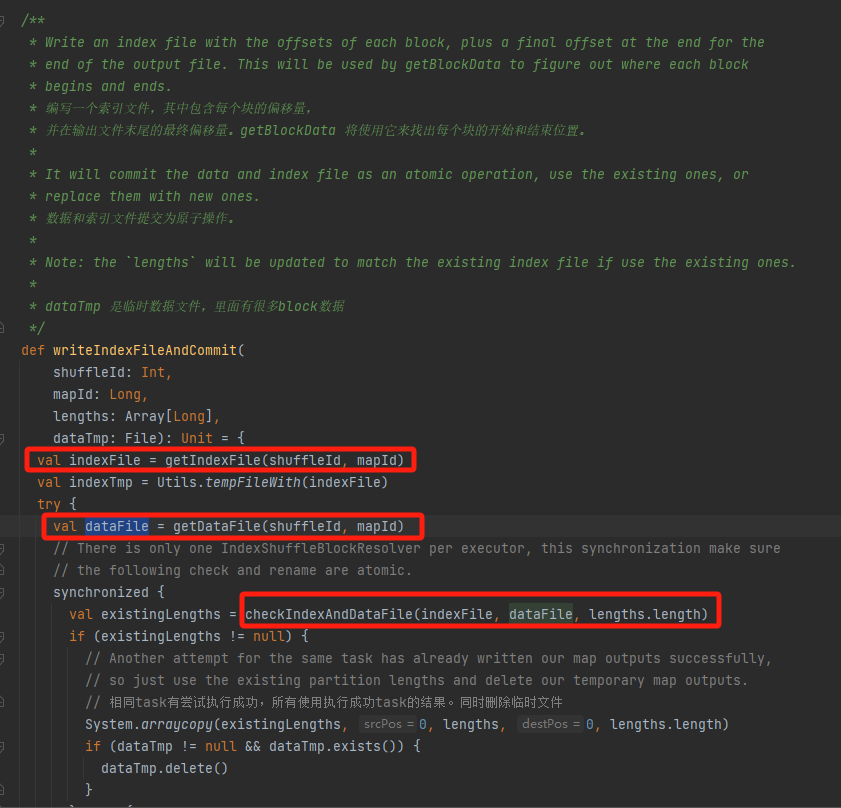

Предположим, что shuffle имеет три раздела, а соответствующие размеры данных равны 1000, 1500 и 2500 соответственно.
В индексном файле первая строка равна 0, за ней следует совокупное значение данных раздела. Вторая строка — 1000, третья строка — 1000+1500=2500, а третья строка — 2500+2500=5000.
Файлы данных хранятся отсортированные по размеру раздела.

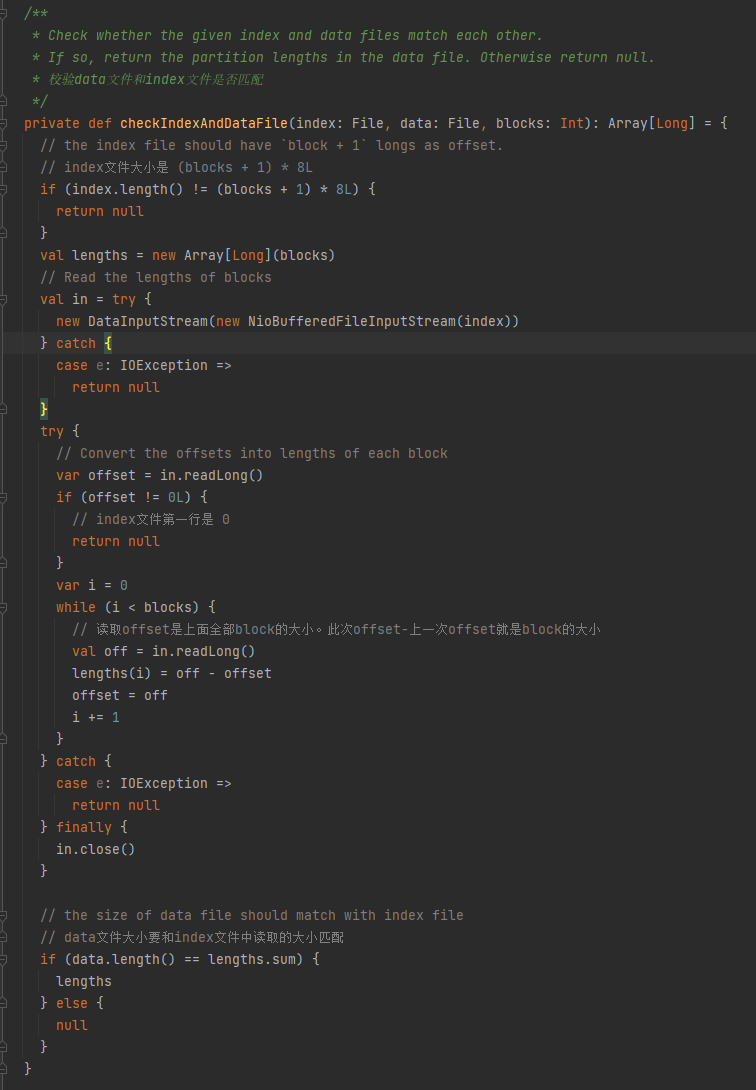
Проверьте, совпадают ли файл данных и индексный файл. Если они не совпадают, возвращается значение null. Если они совпадают, возвращается массив размеров раздела.
1. Размер индексного файла составляет (блоки + 1) * 8L.
2. Первая строка индексного файла равна 0.
3. Получите размер раздела и запишите его в длины. Суммарное значение длин равно размеру файла данных.
Если три вышеуказанных условия соблюдены, возвращается длина, в противном случае возвращается ноль.
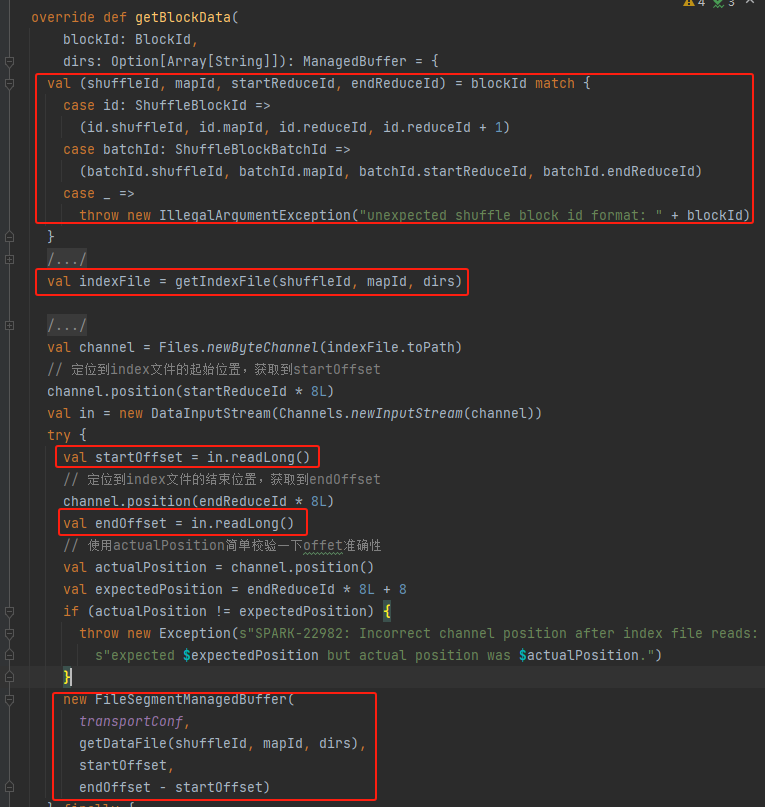
Получить shuffleId, MapId, startReduceId, endReduceId
Получить индексный файл
Прочитайте соответствующие startOffset и endOffset.
Используйте файл данных startOffset, endOffset для создания FileSegmentManagedBuffer и возврата.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com