2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Kohokohdat: rerank

Kohokohdat: tietojenkäsittelyindeksi

Kohokohtia ovat asiakirjan jäsentäminen, viipalointi, kyselyjen uudelleenkirjoittaminen ja palautusmallin hienosäätö.

Edut: Lisää joustavuutta
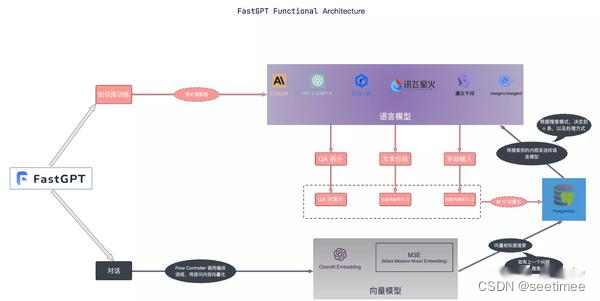
Seuraavassa verrataan kunkin kehyksen eroja moduulien mukaan.
| toiminnallinen moduuli | QMitä tahansa | RAGFLlow | FastGPT | Viisauden spektrin AI |
|---|---|---|---|---|
| Tiedonkäsittelymoduuli | PDF-tiedostojen jäsennys on toteutettu PyMUPDF:llä, joka on tällä hetkellä tehokkain PyMuPDF:n get_text, jota käytetään dokumentin tekstin jäsentämiseen. Se ei tee eroa tekstidokumenttien ja kuvadokumenttien välillä (jos kuvadokumentissa ei ole tekstiä). ilmoitetaan) | OCR, Document Layout Analyze jne., nämä voidaan sisällyttää huomaamattomana Unstructured Loaderina tavalliseen RAG:iin. Voit arvata, että yksi RagFlown ydinominaisuuksista on tiedostojen jäsennysprosessi. | ||
| palautusmoduuli | Vektorikirjasto käyttää milvuksen hybridihakua (BM25-vektorihaku), ei aseta kynnystä ja palauttaa topk (100) | Vektoritietokanta käyttää ElasticSearchia.Hybridihaku toteuttaa tekstinhaun vektorihaussa Mitään erityistä vektorimallia ei ole määritetty, mutta tekstinhaussa käytetään sanan segmentoijana huqieta. | Semanttinen haku Semanttinen hakutila käyttää kehittynyttä vektorimallitekniikkaa tietokannan tietojoukon muuntamiseen pisteiksi korkeadimensionaalisessa vektoriavaruudessa. Tässä tilassa jokainen asiakirja tai tietokohde esitetään vektorina, joka kaappaa datan semanttiset tiedot. Kun käyttäjä esittää kyselyn, järjestelmä myös muuntaa kysymyksen vektoriksi ja suorittaa samankaltaisuuslaskelmia vektoriavaruudessa tietokannan vektorien kanssa löytääkseen olennaisimmat tulokset. Edut: Kyky ymmärtää ja vangita kyselyiden syvemmät merkitykset ja tarjota tarkempia hakutuloksia. Sovellusskenaariot: Soveltuu tilanteisiin, jotka vaativat syvällistä semanttista ymmärrystä ja monimutkaista kyselyjen käsittelyä, kuten akateeminen tutkimus, tekninen ongelmanratkaisu jne. Tekninen toteutus: Käytä malleja, kuten text-embedding-ada-002, upottaaksesi tekstitietoja tehokkaan semanttisen vastaavuuden saavuttamiseksi. Kokotekstihaku Täystekstihakutila keskittyy asiakirjojen kokotekstisisällön indeksointiin, jolloin käyttäjät voivat etsiä asiakirjoja syöttämällä avainsanoja. Tämä tila analysoi asiakirjan jokaisen termin ja rakentaa hakemistotietokannan, joka sisältää kaikki asiakirjat, jolloin käyttäjät voivat löytää nopeasti asiaankuuluvat asiakirjat minkä tahansa sanan tai lauseen avulla. Edut: Hakunopeus on nopea, ja se voi tehdä laajoja hakuja suuresta määrästä asiakirjoja, mikä tekee käyttäjien helpoksi paikantaa nopeasti tiettyjä sanoja sisältävät asiakirjat. Sovellusskenaariot: Soveltuu skenaarioihin, jotka vaativat kattavia hakuja asiakirjakirjastoista, kuten uutisraporteista, online-kirjastoista jne. Tekninen toteutus: Käytä käänteistä hakemistotekniikkaa dokumenttien nopeaan paikantamiseen avainsanojen avulla ja yhdistä se algoritmeihin, kuten TF-IDF, optimoidaksesi hakutulosten osuvuuden. Hybridihaku Hybridihakutila yhdistää semanttisen haun syvän ymmärryksen ja kokotekstihaun nopean vastauksen. Tavoitteena on tarjota tarkka ja kattava hakukokemus. Tässä tilassa järjestelmä ei vain suorita avainsanahakuja, vaan myös yhdistää semanttisia samankaltaisuuslaskelmia varmistaakseen hakutulosten osuvuuden ja tarkkuuden. Edut: Ottaen huomioon koko tekstin haun nopeuden ja semanttisen haun syvyyden, se tarjoaa tasapainoisen hakuratkaisun ja parantaa käyttäjätyytyväisyyttä. Sovellusskenaariot: Soveltuu skenaarioihin, joissa hakunopeus ja tulosten laatu on harkittava kokonaisvaltaisesti, kuten online-asiakaspalvelu, sisällön suositusjärjestelmät jne. Tekninen toteutus: Yhdistämällä käänteinen indeksi- ja vektoriavaruusmalli saavutetaan kattava ymmärrys ja nopea vastaus käyttäjien kyselyihin. Voit esimerkiksi suodattaa nopeasti pois ehdokasjoukon kokotekstihaun avulla ja löytää sitten osuvimmat tulokset ehdokasjoukosta semanttisella haulla. Vektorimalli käyttää: BGE-M3 palauttaa tiedot vektorihaulla ja tekstihaulla ja käyttää RFF-algoritmia lajitteluun; | Artikkelin rakenteen viipaloinnin ja pienistä suuriin indeksointistrategian ottaminen käyttöön voi olla hyvä ratkaisu. Jälkimmäistä varten Embedding-mallia on hienosäädettävä. Meillä on neljä erilaista datan muodostamismallia, jotka kaikki toimivat hyvin käytännössä: Query vs Original: yksinkertainen ja tehokas, tietorakenne käyttää suoraan käyttäjän kyselyä tietokannan fragmenttien palauttamiseen Query vs Query: helppo ylläpitää, eli käyttäjän kyselyn käyttäminen palauttaa kyselyn kylmäkäynnistyksen aikana malliautomaatiota käyttämällä kyselyn poimimiseen vastaavasta tietofragmentista. tietofragmentti F-Answer vs Original: Luo väärennettyjä vastauksia käyttäjien kyselyjen perusteella tietofragmenttien palauttamiseksi.Upotusmallin hienosäätö |
| järjestää moduuli uudelleen | Tarkkuuslajittelu käyttää omaa uudelleensijoitusmalliaan, mutta kynnys on 0,35 | Uudelleenjärjestely perustuu tekstin täsmäytyspisteiden ja vektorisovituspisteiden sekoitukseen. Tekstin vastaavuuden oletuspaino on 0,3 ja vektorisovituksen painoarvo on 0,7. | Tukee uudelleenjärjestelyä, asettaa dynaamisesti upottamisen ja kokotekstin yhdistämisen tulokset ja poistaa tunnuksen perusteella tehdyt päällekkäisyydet, poistaa välilyönnit ja välimerkit, tiivistää merkkijonot ja poistaa päällekkäisyyden, jos malli on määritetty järjestellään uudelleen ja uudelleensijoituspisteet lisätään pistemäärään, jos ei, uudelleensijoitusta ei lisätä; | |
| Isojen mallien käsittely | Kehotus järjestää kaikki tiedot yhteen (optimoitu maksimitunnukselle) | Suodata suurille malleille saatavilla olevien merkkien määrän mukaan | Mallin hienosäätöön käytetään vaiheittaista hienosäätöä, eli ensin hienosäätö suoritetaan käyttämällä avoimen lähdekoodin yleistä kysymys- ja vastausdataa, sitten hienosäätö vertikaalisen toimialueen kysymys-vastausdatalla ja lopuksi hienosäätö suoritetaan käyttämällä manuaalisesti merkittyjä korkealaatuisia kysymys- ja vastaustietoja. | |
| verkkopalvelu | Sanicin käyttö verkkopalvelujen toteuttamiseen | Pullo | Fastapi | |
| Sanojen segmentoinnin käsittely | Mukautettu ChineseTextSplitter valmis | huqie | ||
| Tiedostojen tallennus | Tiedostojen tallennustila käyttää MinIO:ta | |||
| Kohokohdat | Verrattuna perinteiseen RAG:iin, uudelleenjärjestysprosessissa on tehty hienosäätöjä. | Jäsennysprosessi on myös erittäin monimutkainen kirjoittaa, joten ei ihme, että käsittelynopeus on hieman hidas. Käsittelyvaikutuksen odotetaan kuitenkin olevan muita RAG-hankkeita parempi. Varsinaisessa käyttöliittymässä näytetystä demosta päätellen RAGFlow voi liittää jäsennetyn tekstilohkon alkuperäisen asiakirjan alkuperäiseen sijaintiin. Tällä hetkellä näyttää siltä, että vain RagFlow on saavuttanut samanlaisen vaikutuksen. | FastGPT tarjoaa kolme hakutilaa, jotka kattavat yleiset toteutukset RAG:ssa. Poista tiedot ja käytä korkeinta pistemäärää ja laske rrfScore ja lajittele sen perusteella; |
Yhteenveto:
1. Qanything rerank -moduuli on parhaiten suunniteltu
2. RAGFlow-asiakirjojen käsittely on paras
3. FastGPT-moduulissa on monia dynaamisia konfiguraatioita
4. Wisdom Spectrum RAG on paras verkkoalueen datan koulutuksen hienosäätöön
täysi ulottuvuus. Ei ole parasta Oman yrityksen datan kannalta on parasta pystyä toteuttamaan se~

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin tässä Kehittäjän dokumentaatioasema jakaaksesi teknologian kehityksen ongelman tulevaa käyttöä varten
