τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Χαρακτηριστικά: ανακατάταξη

Χαρακτηριστικά: ευρετήριο επεξεργασίας δεδομένων

Στα κυριότερα σημεία περιλαμβάνονται η ανάλυση εγγράφων, η κοπή σε φέτες, η επανεγγραφή ερωτημάτων και η ανάκληση λεπτομέρειας μοντέλου.

Πλεονεκτήματα: Περισσότερη ευελιξία
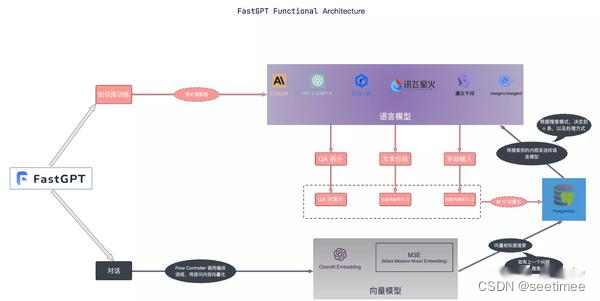
Το παρακάτω συγκρίνει τις διαφορές κάθε πλαισίου σύμφωνα με ενότητες.
| λειτουργική μονάδα | Q Οτιδήποτε | RAGFLow | FastGPT | Φάσμα σοφίας AI |
|---|---|---|---|---|
| Ενότητα επεξεργασίας γνώσης | Η ανάλυση αρχείων PDF υλοποιείται από το PyMUPDF, το οποίο αυτή τη στιγμή είναι το πιο αποτελεσματικό get_text του PyMuPDF για την ανάλυση του κειμένου του εγγράφου θα αναφερθεί) | OCR, Document Layout Analyse, κ.λπ., αυτά μπορεί να περιλαμβάνονται ως μη εμφανής μη δομημένος φορτωτής στο κανονικό RAG Μπορείτε να μαντέψετε ότι μία από τις βασικές δυνατότητες του RagFlow βρίσκεται στη διαδικασία ανάλυσης αρχείων. | ||
| μονάδα ανάκλησης | Η διανυσματική βιβλιοθήκη χρησιμοποιεί την υβριδική ανάκτηση του milvus (ανάκτηση διανύσματος BM25), δεν ορίζει όριο και επιστρέφει το topk (100) | Η διανυσματική βάση δεδομένων χρησιμοποιεί ElasticSearch.Η υβριδική ανάκτηση υλοποιεί την ανάκτηση διανυσμάτων ανάκτησης κειμένου Δεν καθορίζεται συγκεκριμένο μοντέλο διανύσματος, αλλά το huqie χρησιμοποιείται ως τμηματοποιητής λέξεων για την ανάκτηση κειμένου. | Σημασιολογική ανάκτηση Η λειτουργία σημασιολογικής ανάκτησης χρησιμοποιεί προηγμένη τεχνολογία διανυσματικών μοντέλων για τη μετατροπή συνόλων δεδομένων στη βάση γνώσεων σε σημεία σε διανυσματικό χώρο υψηλών διαστάσεων. Σε αυτόν τον χώρο, κάθε έγγραφο ή στοιχείο δεδομένων αναπαρίσταται ως διάνυσμα που συλλαμβάνει τις σημασιολογικές πληροφορίες των δεδομένων. Όταν ένας χρήστης θέτει ένα ερώτημα, το σύστημα μετατρέπει επίσης την ερώτηση σε διάνυσμα και εκτελεί υπολογισμούς ομοιότητας στο διανυσματικό χώρο με τα διανύσματα στη βάση γνώσεων για να βρει τα πιο σχετικά αποτελέσματα. Πλεονεκτήματα: Ικανότητα κατανόησης και αποτύπωσης του βαθύτερου νοήματος των ερωτημάτων και παροχή πιο ακριβών αποτελεσμάτων αναζήτησης. Σενάρια εφαρμογής: Κατάλληλο για καταστάσεις που απαιτούν βαθιά σημασιολογική κατανόηση και περίπλοκη επεξεργασία ερωτημάτων, όπως ακαδημαϊκή έρευνα, επίλυση τεχνικών προβλημάτων κ.λπ. Τεχνική υλοποίηση: Χρησιμοποιήστε μοντέλα όπως το text-embedding-ada-002 για την ενσωμάτωση δεδομένων κειμένου για να επιτύχετε αποτελεσματική σημασιολογική αντιστοίχιση. Αναζήτηση πλήρους κειμένου Η λειτουργία αναζήτησης πλήρους κειμένου εστιάζει στην ευρετηρίαση του περιεχομένου πλήρους κειμένου των εγγράφων, επιτρέποντας στους χρήστες να αναζητούν έγγραφα εισάγοντας λέξεις-κλειδιά. Αυτή η λειτουργία αναλύει κάθε όρο στο έγγραφο και δημιουργεί μια βάση δεδομένων ευρετηρίου που περιέχει όλα τα έγγραφα, επιτρέποντας στους χρήστες να βρίσκουν γρήγορα σχετικά έγγραφα μέσω οποιασδήποτε λέξης ή φράσης. Πλεονεκτήματα: Η ταχύτητα ανάκτησης είναι γρήγορη και μπορεί να πραγματοποιήσει εκτεταμένες αναζητήσεις σε μεγάλο αριθμό εγγράφων, διευκολύνοντας τους χρήστες να εντοπίζουν γρήγορα έγγραφα που περιέχουν συγκεκριμένες λέξεις. Σενάρια εφαρμογών: Κατάλληλο για σενάρια που απαιτούν ολοκληρωμένες αναζητήσεις σε βιβλιοθήκες εγγράφων, όπως ρεπορτάζ ειδήσεων, διαδικτυακές βιβλιοθήκες κ.λπ. Τεχνική υλοποίηση: Χρησιμοποιήστε την τεχνολογία ανεστραμμένου ευρετηρίου για να εντοπίσετε γρήγορα έγγραφα μέσω λέξεων-κλειδιών και συνδυάστε την με αλγόριθμους όπως το TF-IDF για να βελτιστοποιήσετε τη συνάφεια των αποτελεσμάτων αναζήτησης. Υβριδική ανάκτηση Η λειτουργία υβριδικής ανάκτησης συνδυάζει τη βαθιά κατανόηση της σημασιολογικής ανάκτησης με τη γρήγορη απόκριση της ανάκτησης πλήρους κειμένου, με στόχο να παρέχει μια εμπειρία αναζήτησης που είναι ταυτόχρονα ακριβής και περιεκτική. Σε αυτήν τη λειτουργία, το σύστημα όχι μόνο εκτελεί αντιστοίχιση λέξεων-κλειδιών, αλλά συνδυάζει επίσης υπολογισμούς σημασιολογικής ομοιότητας για να εξασφαλίσει τη συνάφεια και την ακρίβεια των αποτελεσμάτων αναζήτησης. Πλεονεκτήματα: Λαμβάνοντας υπόψη την ταχύτητα ανάκτησης πλήρους κειμένου και το βάθος της σημασιολογικής ανάκτησης, παρέχει μια ισορροπημένη λύση αναζήτησης και βελτιώνει την ικανοποίηση των χρηστών. Σενάρια εφαρμογών: Κατάλληλο για σενάρια όπου η ταχύτητα ανάκτησης και η ποιότητα των αποτελεσμάτων πρέπει να ληφθούν υπόψη πλήρως, όπως η ηλεκτρονική εξυπηρέτηση πελατών, τα συστήματα συστάσεων περιεχομένου κ.λπ. Τεχνική υλοποίηση: Συνδυάζοντας το μοντέλο ανεστραμμένου ευρετηρίου και διανυσματικού χώρου, επιτυγχάνεται μια ολοκληρωμένη κατανόηση και ταχεία απόκριση στα ερωτήματα των χρηστών. Για παράδειγμα, μπορείτε να φιλτράρετε γρήγορα το σύνολο υποψηφίων μέσω αναζήτησης πλήρους κειμένου και, στη συνέχεια, να βρείτε τα πιο σχετικά αποτελέσματα από το σύνολο υποψηφίων μέσω της σημασιολογικής αναζήτησης. Το διανυσματικό μοντέλο χρησιμοποιεί: Το BGE-M3 ανακαλεί δεδομένα μέσω ανάκτησης διανυσμάτων και ανάκτησης κειμένου και χρησιμοποιεί τον αλγόριθμο RFF για ταξινόμηση. | Η υιοθέτηση του τεμαχισμού της δομής των άρθρων και της στρατηγικής ευρετηρίασης από μικρές έως μεγάλες μπορεί να είναι μια καλή λύση. Για το τελευταίο, το μοντέλο Embedding πρέπει να βελτιωθεί. Έχουμε τέσσερα διαφορετικά σχήματα για την κατασκευή δεδομένων, τα οποία έχουν όλα καλά αποτελέσματα στην πράξη: Ερώτημα έναντι Πρωτότυπου: απλή και αποτελεσματική, η δομή δεδομένων χρησιμοποιεί απευθείας το ερώτημα χρήστη για να ανακαλέσει θραύσματα βάσης γνώσεων: εύκολο στη συντήρηση, Η χρήση του ερωτήματος του χρήστη ανακαλεί το ερώτημα Κατά τη διάρκεια της ψυχρής εκκίνησης, η αυτοματοποίηση του μοντέλου μπορεί να χρησιμοποιηθεί για την εξαγωγή του ερωτήματος από το αντίστοιχο τμήμα γνώσης: Χρησιμοποιήστε το ερώτημα για να ανακαλέσετε τη σύνοψη του τμήματος γνώσης και να δημιουργήσετε μια σχέση αντιστοίχισης μεταξύ της περίληψης και της σύνοψης. το τμήμα γνώσης F-Answer vs Original: Δημιουργήστε ψεύτικες απαντήσεις με βάση τα ερωτήματα των χρηστών για να ανακαλέσετε θραύσματα γνώσης.Βελτιστοποίηση του μοντέλου Embedding |
| αναδιάταξη της μονάδας | Η ταξινόμηση ακριβείας χρησιμοποιεί το δικό της μοντέλο ανακατάταξης, αλλά το όριο ορίζεται στο 0,35 | Η αναδιάταξη βασίζεται σε ένα μείγμα βαθμολογιών αντιστοίχισης κειμένου και βαθμών αντιστοίχισης διανυσμάτων Το προεπιλεγμένο βάρος της αντιστοίχισης κειμένου είναι 0,3 και το βάρος της αντιστοίχισης διανυσμάτων είναι 0,7. | Υποστηρίζει την αναδιάταξη, ορίζει δυναμικά τα αποτελέσματα της συγχώνευσης ενσωμάτωσης και πλήρους κειμένου και καταργεί την αντιγραφή με βάση το αναγνωριστικό συνενώνει τις συμβολοσειρές qa, αφαιρεί κενά και σημεία στίξης, κατακερματίζει τις συμβολοσειρές και αφαιρεί την αντιγραφή, εάν το μοντέλο ανακατάταξης έχει ρυθμιστεί αναδιατάσσεται και η βαθμολογία ανακατάταξης προστίθεται στη βαθμολογία, εάν όχι, η βαθμολογία ανακατάταξης δεν θα προστεθεί. | |
| Χειρισμός μεγάλων μοντέλων | Προτροπή για οργάνωση όλων των δεδομένων μαζί (βελτιστοποιημένο για μέγιστο διακριτικό) | Φιλτράρισμα με βάση τον αριθμό των κουπονιών που είναι διαθέσιμα για μεγάλα μοντέλα | Για τη λεπτομέρεια μοντέλων, υιοθετείται η σταδιακή λεπτομέρεια, δηλαδή, πρώτα η λεπτομέρεια πραγματοποιείται χρησιμοποιώντας δεδομένα γενικών ερωτήσεων και απαντήσεων ανοιχτού κώδικα, στη συνέχεια η λεπτομέρεια πραγματοποιείται χρησιμοποιώντας δεδομένα ερωτήσεων και απαντήσεων κάθετου τομέα και, τέλος, η μικρορύθμιση εκτελείται χρησιμοποιώντας μη αυτόματα σχολιασμένα δεδομένα ερωτήσεων και απαντήσεων υψηλής ποιότητας. | |
| υπηρεσία Ιστού | Χρήση του sanic για την υλοποίηση υπηρεσιών web | Φλάσκα | Fastapi | |
| Επεξεργασία κατάτμησης λέξεων | Ολοκληρώθηκε το προσαρμοσμένο ChineseTextSplitter | huqie | ||
| Αποθήκευση αρχείων | Η αποθήκευση αρχείων χρησιμοποιεί MinIO | |||
| Καλύτερες στιγμές | Σε σύγκριση με τα συμβατικά RAG, έχουν γίνει λεπτές προσαρμογές στη διαδικασία ανακατάταξης. | Η διαδικασία ανάλυσης είναι επίσης πολύ περίπλοκη στη γραφή, επομένως δεν είναι περίεργο ότι η ταχύτητα επεξεργασίας είναι λίγο αργή. Ωστόσο, το αποτέλεσμα επεξεργασίας αναμένεται να είναι καλύτερο από άλλα έργα RAG. Κρίνοντας από την επίδειξη που εμφανίζεται στο πραγματικό μπροστινό μέρος, το RAGFlow μπορεί να συσχετίσει το αναλυμένο μπλοκ κειμένου με την αρχική θέση στο αρχικό έγγραφο. | Το FastGPT παρέχει τρεις τρόπους ανάκτησης, καλύπτοντας κύριες εφαρμογές στο RAG. Αφαιρέστε τα δεδομένα και χρησιμοποιήστε την υψηλότερη βαθμολογία υπολογίστε το rrfScore και ταξινομήστε με βάση αυτό. |
Συνοψίζω:
1. Η ενότητα επανακατάταξης Qanything είναι η καλύτερα σχεδιασμένη
2. Η επεξεργασία εγγράφων RAGFlow είναι η καλύτερη
3. Η μονάδα FastGPT έχει πολλές δυναμικές διαμορφώσεις
4. Το Wisdom Spectrum RAG είναι το καλύτερο για την τελειοποίηση της εκπαίδευσης σε δεδομένα τομέα
πλήρης διάσταση. Δεν υπάρχει καλύτερο από την άποψη των δεδομένων της δικής σας επιχείρησης, είναι το καλύτερο να μπορείτε να το εφαρμόσετε

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]