informasi kontak saya
Surat[email protected]
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Sorotan: peringkat ulang

Sorotan: indeks pemrosesan data

Sorotan mencakup penguraian dokumen, pemotongan, penulisan ulang kueri, dan penyempurnaan model penarikan.

Keuntungan: Lebih banyak fleksibilitas
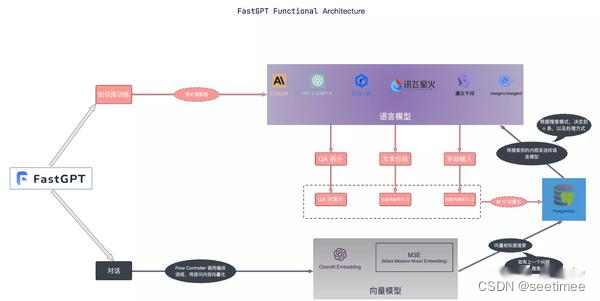
Berikut perbandingan perbedaan masing-masing framework menurut modulnya.
| modul fungsional | QApa saja | Aliran RAG | GPT cepat | AI spektrum kebijaksanaan |
|---|---|---|---|---|
| Modul pemrosesan pengetahuan | Penguraian file PDF diimplementasikan oleh PyMUPDF, yang saat ini paling efisien. Get_text PyMuPDF digunakan untuk mengurai teks dokumen. Tidak membedakan antara dokumen teks dan dokumen gambar (jika tidak ada teks dalam dokumen gambar, terjadi kesalahan akan dilaporkan) | OCR, Analisis Tata Letak Dokumen, dll., ini mungkin dimasukkan sebagai Pemuat Tidak Terstruktur yang tidak mencolok dalam RAG biasa. | ||
| modul penarikan | Pustaka vektor menggunakan pengambilan hibrid milvus (pengambilan vektor BM25), tidak menetapkan ambang batas, dan mengembalikan topk (100) | Basis data vektor menggunakan ElasticSearch.Pengambilan hibrid mengimplementasikan pengambilan vektor pengambilan teks. Tidak ada model vektor spesifik yang ditentukan, tetapi huqie digunakan sebagai segmenter kata untuk pengambilan teks. | Pengambilan semantik Mode pengambilan semantik menggunakan teknologi model vektor canggih untuk mengubah kumpulan data dalam basis pengetahuan menjadi titik-titik dalam ruang vektor berdimensi tinggi. Dalam ruang ini, setiap dokumen atau item data direpresentasikan sebagai vektor yang menangkap informasi semantik data. Saat pengguna mengajukan kueri, sistem juga mengubah pertanyaan tersebut menjadi vektor dan melakukan penghitungan kemiripan di ruang vektor dengan vektor di basis pengetahuan untuk menemukan hasil yang paling relevan. Keuntungan: Kemampuan untuk memahami dan menangkap makna kueri yang lebih dalam dan memberikan hasil pencarian yang lebih akurat. Skenario aplikasi: Cocok untuk situasi yang memerlukan pemahaman semantik yang mendalam dan pemrosesan kueri yang kompleks, seperti penelitian akademis, pemecahan masalah teknis, dll. Implementasi teknis: Gunakan model seperti text-embedding-ada-002 untuk menyematkan data teks guna mencapai pencocokan semantik yang efisien. Pencarian teks lengkap Mode pencarian teks lengkap berfokus pada pengindeksan konten teks lengkap dokumen, memungkinkan pengguna mencari dokumen dengan memasukkan kata kunci. Mode ini menganalisis setiap istilah dalam dokumen dan membangun basis data indeks yang berisi semua dokumen, memungkinkan pengguna dengan cepat menemukan dokumen yang relevan melalui kata atau frasa apa pun. Keuntungan: Kecepatan pengambilannya cepat, dan dapat melakukan pencarian ekstensif pada sejumlah besar dokumen, sehingga memudahkan pengguna untuk menemukan dokumen yang berisi kata-kata tertentu dengan cepat. Skenario aplikasi: Cocok untuk skenario yang memerlukan pencarian komprehensif pustaka dokumen, seperti laporan berita, perpustakaan online, dll. Implementasi teknis: Gunakan teknologi indeks terbalik untuk menemukan dokumen dengan cepat melalui kata kunci, dan menggabungkannya dengan algoritma seperti TF-IDF untuk mengoptimalkan relevansi hasil pencarian. Pengambilan hibrid Mode pengambilan hibrid menggabungkan pemahaman mendalam tentang pengambilan semantik dengan respons cepat pengambilan teks lengkap, yang bertujuan untuk memberikan pengalaman pencarian yang akurat dan komprehensif. Dalam mode ini, sistem tidak hanya melakukan pencocokan kata kunci, tetapi juga menggabungkan penghitungan kesamaan semantik untuk memastikan relevansi dan keakuratan hasil pencarian. Keuntungan: Dengan mempertimbangkan kecepatan pengambilan teks lengkap dan kedalaman pengambilan semantik, ini memberikan solusi pencarian yang seimbang dan meningkatkan kepuasan pengguna. Skenario aplikasi: Cocok untuk skenario di mana kecepatan pengambilan dan kualitas hasil perlu dipertimbangkan secara komprehensif, seperti layanan pelanggan online, sistem rekomendasi konten, dll. Implementasi teknis: Dengan menggabungkan model indeks terbalik dan ruang vektor, pemahaman komprehensif dan respons cepat terhadap pertanyaan pengguna dapat dicapai. Misalnya, Anda dapat dengan cepat memfilter kumpulan kandidat melalui pencarian teks lengkap, lalu menemukan hasil paling relevan dari kumpulan kandidat melalui pencarian semantik. Model vektor menggunakan: BGE-M3 mengingat data melalui pengambilan vektor dan pengambilan teks, dan menggunakan algoritma RFF untuk mengurutkannya; | Mengadopsi pemotongan struktur artikel dan strategi pengindeksan kecil hingga besar dapat menjadi solusi yang baik. Untuk yang terakhir, model Penyematan perlu disesuaikan. Kami memiliki empat skema berbeda untuk menyusun data, yang semuanya berkinerja baik dalam praktiknya: Query vs Original: sederhana dan efisien, struktur data secara langsung menggunakan kueri pengguna untuk memanggil kembali fragmen basis pengetahuan; Query vs Query: mudah dipelihara, yaitu, menggunakan kueri pengguna untuk mengingat kueri. Selama cold start, otomatisasi model dapat digunakan untuk mengekstrak kueri dari fragmen pengetahuan yang sesuai; Kueri vs Ringkasan: Gunakan kueri untuk mengingat ringkasan fragmen pengetahuan dan membangun hubungan pemetaan antara ringkasan dan fragmen pengetahuan; F-Answer vs Asli: Menghasilkan jawaban palsu berdasarkan pertanyaan pengguna untuk mengingat fragmen pengetahuan.Menyempurnakan model Penyematan |
| mengatur ulang modul | Penyortiran presisi menggunakan model pemeringkatan ulangnya sendiri, tetapi ambang batasnya ditetapkan pada 0,35 | Penataan ulang didasarkan pada campuran skor pencocokan teks dan skor pencocokan vektor. Bobot default pencocokan teks adalah 0,3 dan bobot pencocokan vektor adalah 0,7. | Mendukung pengurutan ulang, secara dinamis mengatur hasil penggabungan penyematan dan teks lengkap, dan menghapus duplikasi berdasarkan ID; menggabungkan string qa, menghilangkan spasi dan tanda baca, mengkodekan string secara hash, dan menghapus duplikasi; jika model pemeringkatan ulang dikonfigurasi, panggil Model diurutkan ulang dan skor rerank ditambahkan pada skor; jika tidak, skor rerank tidak akan ditambahkan; | |
| Penanganan model besar | Perintah untuk mengatur semua data bersama-sama (dioptimalkan untuk token maksimum) | Filter berdasarkan jumlah token yang tersedia untuk model besar | Untuk penyempurnaan model, dilakukan penyempurnaan bertahap, yaitu penyempurnaan pertama dilakukan menggunakan data tanya jawab umum open source, kemudian penyempurnaan dilakukan menggunakan data tanya jawab domain vertikal, dan terakhir penyempurnaan dilakukan dengan menggunakan data tanya jawab berkualitas tinggi yang dianotasi secara manual. | |
| layanan web | Menggunakan sanic untuk mengimplementasikan layanan web | Labu | Fastapi | |
| Pemrosesan segmentasi kata | ChineseTextSplitter kustom selesai | huqie | ||
| Penyimpanan berkas | Penyimpanan file menggunakan MinIO | |||
| Highlight | Dibandingkan dengan RAG konvensional, penyesuaian halus telah dilakukan dalam proses rerank. | Proses parsingnya juga sangat rumit untuk ditulis, sehingga tidak heran kecepatan prosesnya agak lambat. Namun, efek pemrosesannya diharapkan lebih baik dibandingkan proyek RAG lainnya. Dilihat dari demo yang ditampilkan di front end sebenarnya, RAGFlow dapat mengaitkan blok teks yang diurai dengan posisi asli di dokumen asli. Efek ini cukup menakjubkan. | FastGPT menyediakan tiga mode pengambilan, yang mencakup implementasi umum di RAG. Hapus duplikat data dan gunakan skor tertinggi; hitung rrfScore dan urutkan berdasarkan itu; |
Meringkaskan:
1. Modul rerank Qanything adalah yang dirancang terbaik
2. Pemrosesan dokumen RAGFlow adalah yang terbaik
3. Modul FastGPT memiliki banyak konfigurasi dinamis
4. Wisdom Spectrum RAG adalah yang terbaik untuk menyempurnakan pelatihan data domain
dimensi penuh. Tidak ada yang terbaik. Dalam hal data bisnis Anda sendiri, yang terbaik adalah bisa mengimplementasikannya~

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang

Surat[email protected]