2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Highlights: rerank

Highlights: Data processing index

Highlights include document parsing, slicing, query rewriting, and fine-tuning of recall models.

Advantages: Greater flexibility
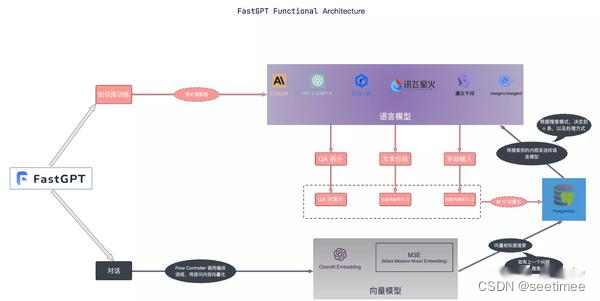
The following is a comparison of the differences between the frameworks according to the module
| functional module | QAnything | RAGFLow | FastGPT | Zhipu AI |
|---|---|---|---|---|
| Knowledge Processing Module | The pdf file parsing is implemented by PyMUPDF, which is currently the most efficient. The text of the document is parsed using PyMuPDF's get_text. It does not distinguish between text documents and image documents (image documents will report an error if there is no text) | OCR, Document Layout Analyze, etc. These may be included as an inconspicuous Unstructured Loader in regular RAG. It can be guessed that one of the core capabilities of RagFlow lies in the file parsing link. | ||
| Recall Module | The vector library uses milvus's hybrid search (BM25 vector search), does not set a threshold, and returns topk (100) | The vector database uses ElasticSearch. Hybrid search implements text search and vector search. No specific vector model is specified, but huqie is used as the word segmenter for text search. | Semantic retrieval The semantic retrieval mode converts the data set in the knowledge base into points in a high-dimensional vector space through advanced vector model technology. In this space, each document or data item is represented as a vector that can capture the semantic information of the data. When a user asks a query, the system also converts the question into a vector and calculates the similarity with the vector in the knowledge base in the vector space to find the most relevant results. Advantages: It can understand and capture the deep meaning of the query and provide more accurate search results. Application scenarios: It is suitable for situations that require deep semantic understanding and complex query processing, such as academic research and technical problem solving. Technical implementation: Use models such as text-embedding-ada-002 to embed text data and achieve efficient semantic matching. Full-text retrieval The full-text retrieval mode focuses on indexing the full-text content of the document, allowing users to search for documents by entering keywords. This mode analyzes each word in the document and establishes an index database containing all documents, allowing users to quickly find relevant documents through any word or phrase. Advantages: Fast retrieval speed, the ability to conduct extensive searches on a large number of documents, and convenient for users to quickly locate documents containing specific vocabulary. Application scenarios: Suitable for scenarios where a comprehensive search of the document library is required, such as news reports, online libraries, etc. Technical implementation: Inverted index technology is used to quickly locate documents through keywords, and algorithms such as TF-IDF are combined to optimize the relevance of search results. Hybrid retrieval The hybrid retrieval mode combines the deep understanding of semantic retrieval with the fast response of full-text retrieval, aiming to provide a search experience that is both accurate and comprehensive. In this mode, the system not only performs keyword matching, but also combines semantic similarity calculations to ensure the relevance and accuracy of search results. Advantages: It takes into account the speed of full-text retrieval and the depth of semantic retrieval, providing a balanced search solution and improving user satisfaction. Application scenarios: Suitable for scenarios where retrieval speed and result quality need to be comprehensively considered, such as online customer service, content recommendation systems, etc. Technical implementation: By combining inverted index and vector space model, a comprehensive understanding and rapid response to user queries can be achieved. For example, a candidate set can be quickly screened out through full-text retrieval, and then the most relevant results can be found from the candidate set through semantic retrieval. Vector model used: BGE-M3 Recall data through vector retrieval and text retrieval, and sort it using the RFF algorithm; | This problem can be solved well by adopting article structure slicing and small to big indexing strategies. For the latter, the Embedding model needs to be fine-tuned. We have four different solutions for constructing data, all of which have performed well in practice: Query vs Original: simple and efficient, the data structure is to directly use the user query to recall the knowledge base fragment; Query vs Query: easy to maintain, that is, use the user's query to recall the query, and during cold start, the model can be used to automatically extract the query from the corresponding knowledge fragment; Query vs Summary: use the query to recall the summary of the knowledge fragment, and build a mapping relationship between the summary and the knowledge fragment; F-Answer vs Original: generate a fake answer based on the user query to recall the knowledge fragment. Fine-tune the Embedding model |
| Rearrange Modules | The precise sorting uses its own rerank model, but the threshold is set at 0.35 | The re-ranking is based on a mixture of text matching scores and vector matching scores. The default weight of text matching is 0.3 and the weight of vector matching is 0.7. | Support re-ranking, dynamically set the result of merging embedding and fulltext, and remove duplicates based on id; concatenate qa strings, delete spaces and punctuation marks, perform hash encoding on strings and remove duplicates; if a rerank model is configured, call the model for re-ranking and add the rerank score to the score; if not, the rerank score will not be increased; | |
| Handling of large models | Prompt with all data organized together (optimized for the largest token) | Filter by the number of tokens available for large models | For model fine-tuning, we adopt a staged fine-tuning approach, that is, first fine-tuning with open source general question-answering data, then fine-tuning with vertical domain question-answering data, and finally fine-tuning with manually annotated high-quality question-answering data. | |
| Web Services | Implementing web services using sanic | Flask | Fastapi | |
| Word segmentation | Custom ChineseTextSplitter completed | huqie | ||
| File Storage | MinIO is used for file storage | |||
| Highlights | Compared with the conventional RAG, fine-tuning has been done in the rerank phase | The parsing process is also very complicated, so it is no wonder that the processing speed is a bit slow. However, the expected processing effect is better than other RAG projects. From the actual front-end demo, RAGFlow can associate the parsed text block with the original position in the original document. This effect is quite amazing. At present, it seems that only RagFlow has achieved a similar effect. | FastGPT provides three search modes, covering the mainstream implementations in RAG: remove duplicate data and use the highest score; calculate rrfScore and sort based on it; |
Summarize:
1. Qanything rerank module is the best designed
2. RAGFlow is the best for document processing
3. FastGPT module dynamically configures multiple
4. Zhipu RAG, best for fine-tuning training on domain data
All dimensions. There is no best. The best is to implement the data of your own business.

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.
