내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
하이라이트: 순위 재지정

하이라이트: 데이터 처리 지수

주요 내용에는 문서 구문 분석, 슬라이싱, 쿼리 재작성 및 리콜 모델 미세 조정이 포함됩니다.

장점: 더 많은 유연성
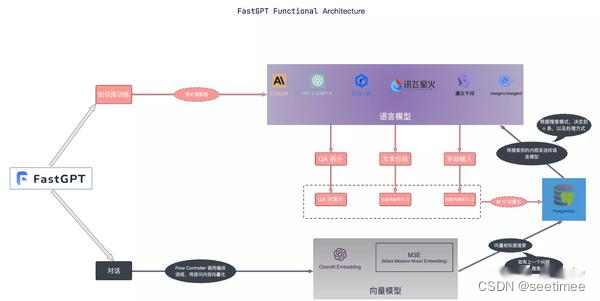
다음은 모듈에 따른 각 프레임워크의 차이점을 비교한 것입니다.
| 기능 모듈 | 큐애니씽 | 래그플로우 | 빠른GPT | 지혜 스펙트럼 AI |
|---|---|---|---|---|
| 지식처리모듈 | PDF 파일 구문 분석은 현재 가장 효율적인 PyMUPDF에 의해 구현됩니다. PyMuPDF의 get_text는 문서의 텍스트를 구문 분석하는 데 사용됩니다. 텍스트 문서와 이미지 문서를 구분하지 않습니다(이미지 문서에 텍스트가 없으면 오류가 발생합니다). 신고하겠습니다) | OCR, 문서 레이아웃 분석 등은 일반 RAG에 눈에 띄지 않는 비구조적 로더로 포함될 수 있습니다. RagFlow의 핵심 기능 중 하나가 파일 구문 분석 프로세스에 있다고 짐작할 수 있습니다. | ||
| 리콜 모듈 | 벡터 라이브러리는 milvus의 하이브리드 검색(BM25 벡터 검색)을 사용하고 임계값을 설정하지 않으며 topk(100)를 반환합니다. | 벡터 데이터베이스는 ElasticSearch를 사용합니다.하이브리드 검색은 텍스트 검색 벡터 검색을 구현합니다. 특정 벡터 모델은 지정되지 않지만 huqie는 텍스트 검색을 위한 단어 분할기로 사용됩니다. | 의미 검색 의미 검색 모드는 고급 벡터 모델 기술을 사용하여 지식 기반의 데이터 세트를 고차원 벡터 공간의 포인트로 변환합니다. 이 공간에서 각 문서 또는 데이터 항목은 데이터의 의미 정보를 캡처하는 벡터로 표시됩니다. 사용자가 쿼리를 하면 시스템도 질문을 벡터로 변환하고 지식 베이스의 벡터와 벡터 공간에서 유사성 계산을 수행하여 가장 관련성이 높은 결과를 찾습니다. 장점: 쿼리의 더 깊은 의미를 이해하고 포착하며 보다 정확한 검색 결과를 제공하는 능력. 응용 시나리오: 학술 연구, 기술 문제 해결 등 깊은 의미 이해와 복잡한 쿼리 처리가 필요한 상황에 적합합니다. 기술적 구현: 효율적인 의미 체계 일치를 달성하기 위해 text-embedding-ada-002와 같은 모델을 사용하여 텍스트 데이터를 삽입합니다. 전체 텍스트 검색 전체 텍스트 검색 모드는 문서의 전체 텍스트 내용을 색인화하는 데 중점을 두므로 사용자는 키워드를 입력하여 문서를 검색할 수 있습니다. 이 모드는 문서의 각 용어를 분석하고 모든 문서를 포함하는 인덱스 데이터베이스를 구축하므로 사용자는 어떤 단어나 구문을 통해 관련 문서를 빠르게 찾을 수 있습니다. 장점: 검색 속도가 빠르고, 다수의 문서에 대한 광범위한 검색이 가능하여 사용자가 특정 단어가 포함된 문서를 빠르게 찾을 수 있어 편리합니다. 적용 시나리오: 뉴스 보도, 온라인 라이브러리 등 문서 라이브러리에 대한 포괄적인 검색이 필요한 시나리오에 적합합니다. 기술적 구현: 역색인 기술을 사용하여 키워드를 통해 문서를 빠르게 찾고, TF-IDF와 같은 알고리즘과 결합하여 검색 결과의 관련성을 최적화합니다. 하이브리드 검색 하이브리드 검색 모드는 의미 검색에 대한 깊은 이해와 전체 텍스트 검색의 빠른 응답을 결합하여 정확하고 포괄적인 검색 경험을 제공하는 것을 목표로 합니다. 이 모드에서 시스템은 키워드 일치를 수행할 뿐만 아니라 의미 유사성 계산을 결합하여 검색 결과의 관련성과 정확성을 보장합니다. 장점: 전체 텍스트 검색 속도와 의미 검색의 깊이를 고려하여 균형 잡힌 검색 솔루션을 제공하고 사용자 만족도를 향상시킵니다. 적용 시나리오: 온라인 고객 서비스, 콘텐츠 추천 시스템 등 검색 속도와 결과 품질을 종합적으로 고려해야 하는 시나리오에 적합합니다. 기술적 구현: 역색인과 벡터 공간 모델을 결합하여 사용자 쿼리에 대한 포괄적인 이해와 빠른 응답을 달성합니다. 예를 들어, 전체 텍스트 검색을 통해 후보 집합을 빠르게 필터링한 다음 의미 검색을 통해 후보 집합에서 가장 관련성이 높은 결과를 찾을 수 있습니다. 벡터 모델은 다음을 사용합니다. BGE-M3은 벡터 검색 및 텍스트 검색을 통해 데이터를 회상하고 RFF 알고리즘을 사용하여 정렬합니다. | 기사 구조 슬라이싱과 소규모에서 대규모 색인 전략을 채택하는 것이 좋은 솔루션이 될 수 있습니다. 후자의 경우 Embedding 모델을 미세 조정해야 합니다. 우리는 데이터 구성을 위한 네 가지 다른 체계를 가지고 있으며 모두 실제로 잘 수행됩니다. 쿼리 대 원본: 간단하고 효율적이며 데이터 구조는 지식 기반 조각을 호출하기 위해 사용자 쿼리를 직접 사용합니다. 쿼리 대 쿼리: 유지 관리가 쉽습니다. 사용자의 쿼리를 사용하면 쿼리가 호출됩니다. 콜드 스타트 중에 모델 자동화를 사용하여 해당 지식 조각에서 쿼리를 추출할 수 있습니다. 쿼리 대 요약: 쿼리를 사용하여 지식 조각의 요약을 호출하고 요약과 지식 조각 간의 매핑 관계를 구축합니다. 지식 조각 F-Answer vs Original: 지식 조각을 회상하기 위해 사용자 쿼리를 기반으로 가짜 답변을 생성합니다.임베딩 모델 미세 조정 |
| 모듈 재배열 | 정밀 정렬은 자체 순위 재지정 모델을 사용하지만 임계값은 0.35로 설정됩니다. | 재배열은 텍스트 일치 점수와 벡터 일치 점수의 혼합을 기반으로 합니다. 텍스트 일치의 기본 가중치는 0.3이고 벡터 일치의 가중치는 0.7입니다. | 재정렬을 지원하고, 포함 및 전체 텍스트 병합 결과를 동적으로 설정하고, ID를 기준으로 중복을 제거하고, 공백과 구두점을 제거하고, 문자열을 해시 인코딩하고, 순위 재지정 모델이 구성된 경우 중복을 제거합니다. 재정렬되고 재순위 점수가 점수에 추가됩니다. 그렇지 않으면 재순위 점수가 추가되지 않습니다. | |
| 대형 모델 취급 | 모든 데이터를 함께 정리하라는 메시지 표시(최대 토큰에 최적화됨) | 대형 모델에 사용할 수 있는 토큰 수를 기준으로 필터링 | 모델 미세 조정에는 단계적 미세 조정이 채택됩니다. 즉, 오픈 소스 일반 질문 및 답변 데이터를 사용하여 먼저 미세 조정을 수행한 다음 수직 도메인 질문 및 답변 데이터를 사용하여 미세 조정을 수행하고 마지막으로 미세 조정을 수행합니다. 수동으로 주석이 달린 고품질 질문 및 답변 데이터를 사용하여 수행됩니다. | |
| 웹 서비스 | sanic을 사용하여 웹 서비스 구현 | 플라스크 | 패스트파이 | |
| 단어 분할 처리 | 사용자 정의 ChineseTextSplitter 완료 | 후키 | ||
| 파일 저장 | 파일 저장소는 MinIO를 사용합니다. | |||
| 하이라이트 | 기존 RAG와 비교하여 순위 재지정 과정에서 세밀한 조정이 이루어졌습니다. | 파싱 과정도 작성하기가 매우 복잡하기 때문에 처리 속도가 조금 느린 것은 당연합니다. 하지만 처리 효과는 다른 RAG 프로젝트보다 좋을 것으로 예상된다. 실제 프런트 엔드에 표시된 데모를 보면 RAGFlow는 구문 분석된 텍스트 블록을 원본 문서의 원래 위치와 연결할 수 있습니다. 이 효과는 현재 RagFlow만이 비슷한 효과를 얻은 것으로 보입니다. | FastGPT는 RAG의 주류 구현을 다루는 세 가지 검색 모드를 제공합니다. 데이터를 중복 제거하고 가장 높은 점수를 사용합니다. rrfScore를 계산하고 이를 기준으로 정렬합니다. |
요약하다:
1. Qanything rerank 모듈이 가장 잘 설계되었습니다.
2. RAGFlow 문서처리가 최고입니다
3. FastGPT 모듈에는 다양한 동적 구성이 있습니다.
4. Wisdom Spectrum RAG는 도메인 데이터에 대한 미세 조정 교육에 가장 적합합니다.
전체 차원. 자신의 사업 데이터에 있어서는 최고는 없습니다~ 구현이 가능한게 최고죠~

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com