2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Highlights: Neu einstufen

Highlights: Datenverarbeitungsindex

Zu den Highlights gehören das Parsen, Slicing, Abfrage-Umschreiben und die Feinabstimmung des Recall-Modells von Dokumenten.

Vorteile: Mehr Flexibilität
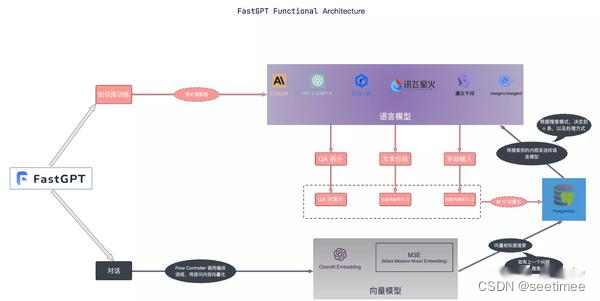
Im Folgenden werden die Unterschiede der einzelnen Frameworks je nach Modul verglichen.
| Funktionsmodul | QAlles | RAGFLow | FastGPT | Weisheitsspektrum KI |
|---|---|---|---|---|
| Modul zur Wissensverarbeitung | Das Parsen von PDF-Dateien wird von PyMUPDF implementiert. Get_text von PyMuPDF wird zum Parsen des Texts des Dokuments verwendet. Es wird nicht zwischen Textdokumenten und Bilddokumenten unterschieden (wenn das Bilddokument keinen Text enthält). wird berichtet) | OCR, Dokumentlayoutanalyse usw. können als unauffälliger unstrukturierter Loader in regulären RAG enthalten sein. Sie können sich vorstellen, dass eine der Kernfunktionen von RagFlow im Dateianalyseprozess liegt. | ||
| Rückrufmodul | Die Vektorbibliothek verwendet den Hybridabruf von Milvus (BM25-Vektorabruf), legt keinen Schwellenwert fest und gibt topk (100) zurück. | Die Vektordatenbank verwendet ElasticSearch.Der Hybridabruf implementiert den Textabruf-Vektorabruf. Es ist kein spezifisches Vektormodell angegeben, aber Huqie wird als Wortsegmentierer für den Textabruf verwendet. | Semantischer Abruf Der semantische Abrufmodus nutzt fortschrittliche Vektormodelltechnologie, um Datensätze in der Wissensdatenbank in Punkte im hochdimensionalen Vektorraum umzuwandeln. In diesem Bereich wird jedes Dokument oder Datenelement als Vektor dargestellt, der die semantischen Informationen der Daten erfasst. Wenn ein Benutzer eine Anfrage stellt, wandelt das System die Frage auch in einen Vektor um und führt Ähnlichkeitsberechnungen im Vektorraum mit den Vektoren in der Wissensdatenbank durch, um die relevantesten Ergebnisse zu finden. Vorteile: Fähigkeit, die tiefere Bedeutung von Suchanfragen zu verstehen und zu erfassen und genauere Suchergebnisse bereitzustellen. Anwendungsszenarien: Geeignet für Situationen, die ein tiefes semantisches Verständnis und eine komplexe Abfrageverarbeitung erfordern, wie z. B. akademische Forschung, technische Problemlösung usw. Technische Umsetzung: Verwenden Sie Modelle wie text-embedding-ada-002 zum Einbetten von Textdaten, um eine effiziente semantische Übereinstimmung zu erreichen. Volltextsuche Der Volltextsuchmodus konzentriert sich auf die Indizierung des Volltextinhalts von Dokumenten und ermöglicht Benutzern die Suche nach Dokumenten durch Eingabe von Schlüsselwörtern. Dieser Modus analysiert jeden Begriff im Dokument und erstellt eine Indexdatenbank mit allen Dokumenten, sodass Benutzer relevante Dokumente anhand jedes Wortes oder Satzes schnell finden können. Vorteile: Die Abrufgeschwindigkeit ist hoch und es können umfangreiche Suchvorgänge in einer großen Anzahl von Dokumenten durchgeführt werden, sodass Benutzer Dokumente mit bestimmten Wörtern schnell finden können. Anwendungsszenarien: Geeignet für Szenarien, die eine umfassende Suche in Dokumentbibliotheken erfordern, z. B. Nachrichtenberichte, Online-Bibliotheken usw. Technische Umsetzung: Nutzen Sie die Inverted-Index-Technologie, um Dokumente anhand von Schlüsselwörtern schnell zu finden, und kombinieren Sie sie mit Algorithmen wie TF-IDF, um die Relevanz der Suchergebnisse zu optimieren. Hybrider Abruf Der Hybrid-Abrufmodus kombiniert das tiefe Verständnis des semantischen Abrufs mit der schnellen Reaktion des Volltextabrufs und zielt darauf ab, ein Sucherlebnis zu bieten, das sowohl genau als auch umfassend ist. In diesem Modus führt das System nicht nur einen Schlüsselwortabgleich durch, sondern kombiniert auch semantische Ähnlichkeitsberechnungen, um die Relevanz und Genauigkeit der Suchergebnisse sicherzustellen. Vorteile: Unter Berücksichtigung der Geschwindigkeit des Volltextabrufs und der Tiefe des semantischen Abrufs bietet es eine ausgewogene Suchlösung und verbessert die Benutzerzufriedenheit. Anwendungsszenarien: Geeignet für Szenarien, in denen Abrufgeschwindigkeit und Ergebnisqualität umfassend berücksichtigt werden müssen, z. B. Online-Kundenservice, Inhaltsempfehlungssysteme usw. Technische Umsetzung: Durch die Kombination des invertierten Index- und Vektorraummodells werden ein umfassendes Verständnis und eine schnelle Reaktion auf Benutzeranfragen erreicht. Beispielsweise können Sie die Kandidatenmenge mithilfe der Volltextsuche schnell herausfiltern und dann mithilfe der semantischen Suche die relevantesten Ergebnisse aus der Kandidatenmenge finden. Das Vektormodell verwendet: BGE-M3 ruft Daten durch Vektorabruf und Textabruf ab und verwendet zum Sortieren den RFF-Algorithmus. | Die Einführung einer Artikelstrukturaufteilung und einer kleinen bis großen Indexierungsstrategie kann eine gute Lösung sein. Für Letzteres muss das Einbettungsmodell verfeinert werden. Wir haben vier verschiedene Schemata zum Erstellen von Daten, die alle in der Praxis gut funktionieren: Abfrage vs. Original: einfach und effizient, die Datenstruktur nutzt direkt die Benutzerabfrage, um Fragmente der Wissensdatenbank abzurufen. Abfrage vs. Abfrage: einfach zu warten, d. h. Mithilfe der Abfrage des Benutzers kann die Abfrage beim Kaltstart mithilfe der Modellautomatisierung aus dem entsprechenden Wissensfragment extrahiert werden. Abfrage vs. Zusammenfassung: Verwenden Sie die Abfrage, um die Zusammenfassung des Wissensfragments abzurufen und eine Zuordnungsbeziehung zwischen der Zusammenfassung und dem Wissensfragment herzustellen das Wissensfragment; F-Antwort vs. Original: Generieren Sie gefälschte Antworten basierend auf Benutzeranfragen, um Wissensfragmente abzurufen.Feinabstimmung des Einbettungsmodells |
| Modul neu anordnen | Die Präzisionssortierung verwendet ein eigenes Reranking-Modell, der Schwellenwert ist jedoch auf 0,35 festgelegt | Die Neuordnung basiert auf einer Mischung aus Text-Matching-Scores und Vektor-Matching-Scores. Die Standardgewichtung des Text-Matchings beträgt 0,3 und die Gewichtung des Vektor-Matchings beträgt 0,7. | Unterstützt die Neuordnung, legt die Ergebnisse der Zusammenführung von Einbettung und Volltext dynamisch fest und entfernt Duplikate basierend auf der ID; wird neu geordnet und die Neubewertungspunktzahl wird zur Bewertung hinzugefügt; andernfalls wird die Neubewertungspunktzahl nicht hinzugefügt; | |
| Umgang mit großen Modellen | Aufforderung, alle Daten zusammen zu organisieren (optimiert für maximales Token) | Filtern Sie nach der Anzahl der für große Modelle verfügbaren Token | Für die Feinabstimmung des Modells wird eine abgestufte Feinabstimmung angewendet, d. h. zunächst wird die Feinabstimmung unter Verwendung allgemeiner Open-Source-Frage- und Antwortdaten durchgeführt, dann wird die Feinabstimmung unter Verwendung von Frage- und Antwortdaten aus vertikalen Domänen durchgeführt und schließlich erfolgt die Feinabstimmung wird unter Verwendung manuell kommentierter, qualitativ hochwertiger Frage- und Antwortdaten durchgeführt. | |
| Internetservice | Verwendung von Sanic zur Implementierung von Webdiensten | Flasche | Fastapi | |
| Wortsegmentierungsverarbeitung | Benutzerdefinierter ChineseTextSplitter abgeschlossen | huqie | ||
| Dateispeicher | Die Dateispeicherung verwendet MinIO | |||
| Höhepunkte | Im Vergleich zum herkömmlichen RAG wurden beim Reranking-Prozess Feinanpassungen vorgenommen. | Der Parsing-Prozess ist auch sehr kompliziert zu schreiben, daher ist es kein Wunder, dass die Verarbeitungsgeschwindigkeit etwas langsam ist. Es wird jedoch erwartet, dass der Verarbeitungseffekt besser ist als bei anderen RAG-Projekten. Der im tatsächlichen Frontend angezeigten Demo nach zu urteilen, kann RAGFlow den analysierten Textblock mit der ursprünglichen Position im Originaldokument verknüpfen. Dieser Effekt ist derzeit ziemlich erstaunlich. | FastGPT bietet drei Abrufmodi, die gängige Implementierungen in RAG abdecken. Daten deduplizieren und den höchsten Score verwenden; rrfScore berechnen und darauf basierend sortieren; |
Zusammenfassen:
1. Das Qanything-Reranking-Modul ist das am besten konzipierte
2. Die RAGFlow-Dokumentenverarbeitung ist die beste
3. Das FastGPT-Modul verfügt über viele dynamische Konfigurationen
4. Wisdom Spectrum RAG eignet sich am besten für die Feinabstimmung des Trainings auf Domänendaten
volle Dimension. Es gibt kein Bestes, was die Daten Ihres eigenen Unternehmens betrifft, es ist das Beste, es umsetzen zu können

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
