2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Points forts : reclassement

Faits saillants : indice informatique

Les points forts incluent l'analyse de documents, le découpage, la réécriture de requêtes et l'ajustement précis du modèle de rappel.

Avantages : Plus de flexibilité
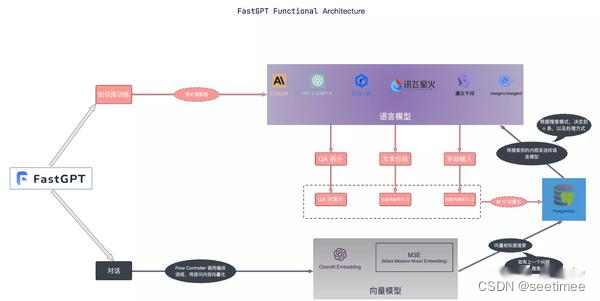
Ce qui suit compare les différences de chaque framework selon les modules.
| module fonctionnel | QQuoi que ce soit | RAGFLow | GPT rapide | IA du spectre de la sagesse |
|---|---|---|---|---|
| Module de traitement des connaissances | L'analyse des fichiers PDF est implémentée par PyMUPDF, qui est actuellement le plus efficace. Le get_text de PyMuPDF est utilisé pour analyser le texte du document. Il ne fait pas la distinction entre les documents texte et les documents image (s'il n'y a pas de texte dans le document image, une erreur. sera signalé) | OCR, Document Layout Analysis, etc., ceux-ci peuvent être inclus en tant que chargeur non structuré discret dans le RAG standard. Vous pouvez deviner que l'une des fonctionnalités principales de RagFlow réside dans le processus d'analyse des fichiers. | ||
| module de rappel | La bibliothèque de vecteurs utilise la récupération hybride de Milvus (récupération de vecteur BM25), ne définit pas de seuil et renvoie topk (100) | La base de données vectorielles utilise ElasticSearch.La récupération hybride implémente la récupération vectorielle de texte. Aucun modèle vectoriel spécifique n'est spécifié, mais huqie est utilisé comme segmenteur de mots pour la récupération de texte. | Récupération sémantique Le mode de récupération sémantique utilise une technologie avancée de modèle vectoriel pour convertir les ensembles de données de la base de connaissances en points dans un espace vectoriel de grande dimension. Dans cet espace, chaque document ou élément de données est représenté comme un vecteur qui capture les informations sémantiques des données. Lorsqu'un utilisateur pose une requête, le système convertit également la question en vecteur et effectue des calculs de similarité dans l'espace vectoriel avec les vecteurs de la base de connaissances pour trouver les résultats les plus pertinents. Avantages : Capacité à comprendre et à capturer le sens profond des requêtes et à fournir des résultats de recherche plus précis. Scénarios d'application : conviennent aux situations qui nécessitent une compréhension sémantique approfondie et un traitement de requêtes complexes, telles que la recherche universitaire, la résolution de problèmes techniques, etc. Implémentation technique : utilisez des modèles tels que text-embedding-ada-002 pour intégrer des données textuelles afin d'obtenir une correspondance sémantique efficace. Recherche en texte intégral Le mode de recherche en texte intégral se concentre sur l'indexation du contenu en texte intégral des documents, permettant aux utilisateurs de rechercher des documents en saisissant des mots-clés. Ce mode analyse chaque terme du document et crée une base de données d'index contenant tous les documents, permettant aux utilisateurs de trouver rapidement des documents pertinents à travers n'importe quel mot ou expression. Avantages : La vitesse de récupération est rapide et il peut effectuer des recherches approfondies sur un grand nombre de documents, ce qui permet aux utilisateurs de localiser rapidement des documents contenant des mots spécifiques. Scénarios d'application : convient aux scénarios nécessitant des recherches complètes dans des bibliothèques de documents, telles que des reportages, des bibliothèques en ligne, etc. Implémentation technique : utilisez la technologie d'index inversé pour localiser rapidement les documents grâce à des mots-clés, et combinez-la avec des algorithmes tels que TF-IDF pour optimiser la pertinence des résultats de recherche. Récupération hybride Le mode de récupération hybride combine la compréhension approfondie de la récupération sémantique avec la réponse rapide de la récupération de texte intégral, dans le but de fournir une expérience de recherche à la fois précise et complète. Dans ce mode, le système effectue non seulement la correspondance des mots clés, mais combine également des calculs de similarité sémantique pour garantir la pertinence et l'exactitude des résultats de recherche. Avantages : Compte tenu de la rapidité de récupération du texte intégral et de la profondeur de la récupération sémantique, il offre une solution de recherche équilibrée et améliore la satisfaction des utilisateurs. Scénarios d'application : convient aux scénarios dans lesquels la vitesse de récupération et la qualité des résultats doivent être pris en compte de manière globale, tels que le service client en ligne, les systèmes de recommandation de contenu, etc. Implémentation technique : en combinant l'index inversé et le modèle d'espace vectoriel, une compréhension globale et une réponse rapide aux requêtes des utilisateurs sont obtenues. Par exemple, vous pouvez filtrer rapidement l'ensemble de candidats via une recherche en texte intégral, puis trouver les résultats les plus pertinents de l'ensemble de candidats via une recherche sémantique. Le modèle vectoriel utilise : BGE-M3 rappelle les données via la récupération vectorielle et la récupération de texte, et utilise l'algorithme RFF pour trier ; | L'adoption d'un découpage de la structure des articles et d'une stratégie d'indexation petite à grande peut être une bonne solution. Pour ces derniers, le modèle d’intégration doit être affiné. Nous disposons de quatre schémas différents pour construire des données, qui fonctionnent tous bien en pratique : Query vs Original : simple et efficace, la structure des données utilise directement la requête de l'utilisateur pour rappeler des fragments de la base de connaissances ; l'utilisation de la requête de l'utilisateur rappelle la requête. Lors du démarrage à froid, l'automatisation du modèle peut être utilisée pour extraire la requête du fragment de connaissances correspondant ; le fragment de connaissances ; F-Answer vs Original : génère de fausses réponses basées sur les requêtes des utilisateurs pour rappeler des fragments de connaissances.Affiner le modèle d'intégration |
| réorganiser le module | Le tri de précision utilise son propre modèle de reclassement, mais le seuil est fixé à 0,35 | Le réarrangement est basé sur un mélange de scores de correspondance de texte et de scores de correspondance de vecteurs. Le poids par défaut de la correspondance de texte est de 0,3 et le poids de la correspondance de vecteurs est de 0,7. | Prend en charge la réorganisation, définit dynamiquement les résultats de la fusion de l'intégration et du texte intégral et supprime la duplication en fonction de l'ID ; concatène les chaînes qa, supprime les espaces et les signes de ponctuation, code par hachage les chaînes et supprime la duplication si le modèle de reclassement est configuré, appelez le modèle ; est réorganisé et le score de reclassement est ajouté au score ; sinon, le score de reclassement ne sera pas ajouté ; | |
| Manipulation de grands modèles | Invite à organiser toutes les données ensemble (optimisé pour un maximum de jetons) | Filtrer par le nombre de tokens disponibles pour les grands modèles | Pour le réglage fin du modèle, un réglage fin par étapes est adopté, c'est-à-dire qu'un réglage fin est d'abord effectué à l'aide de données de questions et réponses générales open source, puis un réglage fin est effectué à l'aide de données de questions et réponses du domaine vertical, et enfin un réglage fin est effectuée à l’aide de données de questions et réponses de haute qualité annotées manuellement. | |
| service Web | Utiliser Sanic pour implémenter des services Web | Ballon | Fastapi | |
| Traitement de segmentation de mots | ChineseTextSplitter personnalisé terminé | Huqie | ||
| Stockage de fichiers | Le stockage de fichiers utilise MinIO | |||
| Points forts | Par rapport au RAG conventionnel, des ajustements précis ont été apportés au processus de reclassement. | Le processus d'analyse est également très compliqué à écrire, il n'est donc pas étonnant que la vitesse de traitement soit un peu lente. Cependant, l'effet de traitement devrait être meilleur que celui des autres projets RAG. À en juger par la démo affichée sur le front-end réel, RAGFlow peut associer le bloc de texte analysé à la position d'origine dans le document original. Actuellement, il semble que seul RagFlow ait obtenu un effet similaire. | FastGPT propose trois modes de récupération, couvrant les implémentations courantes dans RAG. Dédupliquez les données et utilisez le score le plus élevé ; calculez rrfScore et triez en fonction de celui-ci ; |
Résumer:
1. Le module de reclassement Qanything est le mieux conçu
2. Le traitement des documents RAGFlow est le meilleur
3. Le module FastGPT a de nombreuses configurations dynamiques
4. Wisdom Spectrum RAG est le meilleur pour affiner la formation sur les données de domaine
pleine dimension. Il n'y a pas de meilleur en termes de données de votre propre entreprise, c'est le mieux de pouvoir les mettre en œuvre~.

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
