Mi informacion de contacto
Correo[email protected]
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Aspectos destacados: reclasificar

Aspectos destacados: índice de procesamiento de datos

Los aspectos más destacados incluyen análisis, división, reescritura de consultas y ajuste del modelo de recuperación de documentos.

Ventajas: Más flexibilidad
A continuación se comparan las diferencias de cada framework según módulos.
| módulo funcional | QCualquier cosa | RAGFlow | GPT rápido | Espectro de sabiduría IA |
|---|---|---|---|---|
| Módulo de procesamiento de conocimientos | El análisis de archivos PDF lo implementa PyMUPDF, que actualmente es el más eficiente. Get_text de PyMuPDF se utiliza para analizar el texto del documento. No distingue entre documentos de texto y documentos de imagen (si no hay texto en el documento de imagen, se produce un error). será reportado) | OCR, análisis de diseño de documentos, etc., estos pueden incluirse como un cargador no estructurado discreto en RAG normal. Puede adivinar que una de las capacidades principales de RagFlow radica en el proceso de análisis de archivos. | ||
| módulo de recuperación | La biblioteca de vectores utiliza la recuperación híbrida de milvus (recuperación de vectores BM25), no establece un umbral y devuelve topk (100). | La base de datos de vectores utiliza ElasticSearch.La recuperación híbrida implementa la recuperación de vectores de recuperación de texto. No se especifica ningún modelo de vector específico, pero huqie se utiliza como segmentador de palabras para la recuperación de texto. | Recuperación semántica El modo de recuperación semántica utiliza tecnología avanzada de modelos vectoriales para convertir conjuntos de datos de la base de conocimientos en puntos en un espacio vectorial de alta dimensión. En este espacio, cada documento o dato se representa como un vector que captura la información semántica de los datos. Cuando un usuario plantea una consulta, el sistema también convierte la pregunta en un vector y realiza cálculos de similitud en el espacio vectorial con los vectores en la base de conocimientos para encontrar los resultados más relevantes. Ventajas: Capacidad para comprender y capturar el significado más profundo de las consultas y proporcionar resultados de búsqueda más precisos. Escenarios de aplicación: adecuado para situaciones que requieren una comprensión semántica profunda y un procesamiento de consultas complejas, como investigación académica, resolución de problemas técnicos, etc. Implementación técnica: utilice modelos como text-embedding-ada-002 para incrustar datos de texto y lograr una coincidencia semántica eficiente. Búsqueda de texto completo El modo de búsqueda de texto completo se centra en indexar el contenido de texto completo de los documentos, lo que permite a los usuarios buscar documentos ingresando palabras clave. Este modo analiza cada término del documento y crea una base de datos de índice que contiene todos los documentos, lo que permite a los usuarios encontrar rápidamente documentos relevantes a través de cualquier palabra o frase. Ventajas: la velocidad de recuperación es rápida y puede realizar búsquedas exhaustivas en una gran cantidad de documentos, lo que hace que sea conveniente para los usuarios localizar rápidamente documentos que contienen palabras específicas. Escenarios de aplicación: adecuado para escenarios que requieren búsquedas exhaustivas en bibliotecas de documentos, como informes de noticias, bibliotecas en línea, etc. Implementación técnica: utilice tecnología de índice invertido para localizar rápidamente documentos mediante palabras clave y combínela con algoritmos como TF-IDF para optimizar la relevancia de los resultados de búsqueda. Recuperación híbrida El modo de recuperación híbrida combina la comprensión profunda de la recuperación semántica con la respuesta rápida de la recuperación de texto completo, con el objetivo de proporcionar una experiencia de búsqueda precisa y completa. En este modo, el sistema no sólo realiza coincidencias de palabras clave, sino que también combina cálculos de similitud semántica para garantizar la relevancia y precisión de los resultados de búsqueda. Ventajas: teniendo en cuenta la velocidad de recuperación de texto completo y la profundidad de la recuperación semántica, proporciona una solución de búsqueda equilibrada y mejora la satisfacción del usuario. Escenarios de aplicación: adecuado para escenarios donde la velocidad de recuperación y la calidad de los resultados deben considerarse de manera integral, como servicio al cliente en línea, sistemas de recomendación de contenido, etc. Implementación técnica: al combinar el índice invertido y el modelo de espacio vectorial, se logra una comprensión integral y una respuesta rápida a las consultas de los usuarios. Por ejemplo, puede filtrar rápidamente el conjunto de candidatos mediante la búsqueda de texto completo y luego encontrar los resultados más relevantes del conjunto de candidatos mediante la búsqueda semántica. El modelo vectorial utiliza: BGE-M3 recupera datos mediante recuperación de vectores y recuperación de texto, y utiliza el algoritmo RFF para ordenar; | Adoptar una estrategia de división de la estructura del artículo y de indexación de pequeño a grande puede ser una buena solución. Para esto último, es necesario ajustar el modelo de incrustación. Tenemos cuatro esquemas diferentes para construir datos, todos los cuales funcionan bien en la práctica: Consulta versus Original: simple y eficiente, la estructura de datos utiliza directamente la consulta del usuario para recuperar fragmentos de la base de conocimientos; Consulta versus Consulta: fácil de mantener, es decir, el uso de la consulta del usuario recuerda la consulta Durante el inicio en frío, la automatización del modelo se puede utilizar para extraer la consulta del fragmento de conocimiento correspondiente. Consulta versus resumen: use la consulta para recuperar el resumen del fragmento de conocimiento y construir una relación de mapeo entre el resumen y el fragmento de conocimiento; F-Answer vs Original: genera respuestas falsas basadas en consultas de los usuarios para recordar fragmentos de conocimiento.Ajuste fino del modelo de incrustación |
| reorganizar el módulo | La clasificación de precisión utiliza su propio modelo de reclasificación, pero el umbral se establece en 0,35 | La reorganización se basa en una combinación de puntuaciones de coincidencia de texto y puntuaciones de coincidencia de vectores. El peso predeterminado de la coincidencia de texto es 0,3 y el peso de la coincidencia de vectores es 0,7. | Admite reordenamiento, establece dinámicamente los resultados de la fusión de incrustación y texto completo, y elimina la duplicación según la ID; concatena cadenas qa, elimina espacios y signos de puntuación, codifica las cadenas con hash y elimina la duplicación si el modelo de reordenación está configurado, llame al modelo; se reordena y la puntuación de reclasificación se suma a la puntuación; de lo contrario, la puntuación de reclasificación no se agregará; | |
| Manejo de modelos grandes. | Solicitud para organizar todos los datos juntos (optimizado para token máximo) | Filtrar por la cantidad de tokens disponibles para modelos grandes | Para el ajuste fino del modelo, se adopta el ajuste fino por etapas, es decir, el primer ajuste se realiza utilizando datos generales de preguntas y respuestas de código abierto, luego el ajuste fino se realiza utilizando datos de preguntas y respuestas de dominio vertical y, finalmente, el ajuste fino. se realiza utilizando datos de preguntas y respuestas de alta calidad anotados manualmente. | |
| servicio web | Usando sanic para implementar servicios web | Matraz | Fastapi | |
| Procesamiento de segmentación de palabras | Divisor de texto chino personalizado completado | Huqie | ||
| Almacenamiento de archivos | El almacenamiento de archivos utiliza MinIO | |||
| Reflejos | En comparación con el RAG convencional, se han realizado ajustes finos en el proceso de cambio de rango. | El proceso de análisis también es muy complicado de escribir, por lo que no es de extrañar que la velocidad de procesamiento sea un poco lenta. Sin embargo, se espera que el efecto de procesamiento sea mejor que el de otros proyectos RAG. A juzgar por la demostración mostrada en la interfaz real, RAGFlow puede asociar el bloque de texto analizado con la posición original en el documento original. Este efecto es bastante sorprendente. Actualmente, parece que solo RagFlow ha logrado un efecto similar. | FastGPT proporciona tres modos de recuperación, que cubren implementaciones convencionales en RAG. Deduplicar datos y utilizar la puntuación más alta; calcular rrfScore y ordenar en función de ella; |
Resumir:
1. El módulo de reordenación de Qanything es el mejor diseñado
2. El procesamiento de documentos RAGFlow es el mejor
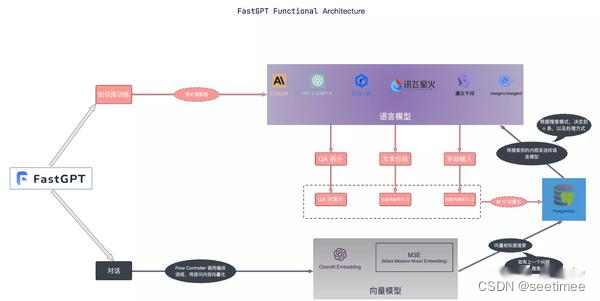
3. El módulo FastGPT tiene muchas configuraciones dinámicas
4. Wisdom Spectrum RAG es el mejor para perfeccionar la capacitación sobre datos de dominio
dimensión completa. No existe lo mejor en términos de los datos de su propio negocio, lo mejor es poder implementarlo ~

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]