minhas informações de contato
Correspondência[email protected]
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Destaques: reclassificação

Destaques: índice de processamento de dados

Os destaques incluem análise de documentos, fatiamento, reescrita de consultas e ajuste fino do modelo de recuperação.

Vantagens: Mais flexibilidade
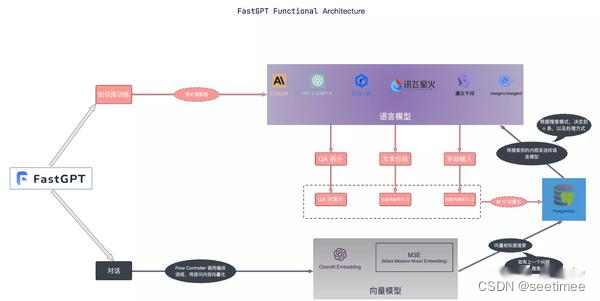
A seguir comparamos as diferenças de cada framework de acordo com os módulos.
| módulo funcional | QQualquer coisa | Fluxo de trapos | FastGPT | Espectro de sabedoria AI |
|---|---|---|---|---|
| Módulo de processamento de conhecimento | A análise de arquivos PDF é implementada pelo PyMUPDF, que é atualmente o mais eficiente. O get_text do PyMuPDF é usado para analisar o texto do documento. Ele não distingue entre documentos de texto e documentos de imagem (se não houver texto no documento de imagem, um erro). será relatado) | OCR, Análise de layout de documento, etc., eles podem ser incluídos como um carregador não estruturado discreto no RAG normal. Você pode adivinhar que um dos principais recursos do RagFlow está no processo de análise de arquivos. | ||
| módulo de recall | A biblioteca de vetores usa recuperação híbrida de milvus (recuperação de vetor BM25), não define um limite e retorna topk (100) | O banco de dados vetorial usa ElasticSearch.A recuperação híbrida implementa a recuperação de vetor de recuperação de texto. Nenhum modelo de vetor específico é especificado, mas huqie é usado como segmentador de palavras para recuperação de texto. | Recuperação semântica O modo de recuperação semântica utiliza tecnologia avançada de modelo vetorial para converter conjuntos de dados na base de conhecimento em pontos no espaço vetorial de alta dimensão. Neste espaço, cada documento ou item de dado é representado como um vetor que captura a informação semântica dos dados. Quando um usuário faz uma consulta, o sistema também converte a pergunta em um vetor e realiza cálculos de similaridade no espaço vetorial com os vetores da base de conhecimento para encontrar os resultados mais relevantes. Vantagens: Capacidade de compreender e capturar o significado mais profundo das consultas e fornecer resultados de pesquisa mais precisos. Cenários de aplicação: Adequado para situações que exigem compreensão semântica profunda e processamento de consultas complexas, como pesquisas acadêmicas, resolução de problemas técnicos, etc. Implementação técnica: Use modelos como text-embedding-ada-002 para incorporar dados de texto para obter correspondência semântica eficiente. Pesquisa de texto completo O modo de pesquisa de texto completo concentra-se na indexação do conteúdo de texto completo dos documentos, permitindo que os usuários pesquisem documentos inserindo palavras-chave. Este modo analisa cada termo do documento e cria um banco de dados de índice contendo todos os documentos, permitindo aos usuários encontrar rapidamente documentos relevantes através de qualquer palavra ou frase. Vantagens: A velocidade de recuperação é rápida e pode realizar pesquisas extensas em um grande número de documentos, tornando conveniente para os usuários localizar rapidamente documentos que contenham palavras específicas. Cenários de aplicação: Adequado para cenários que exigem pesquisas abrangentes em bibliotecas de documentos, como reportagens, bibliotecas online, etc. Implementação técnica: Use tecnologia de índice invertido para localizar documentos rapidamente por meio de palavras-chave e combine-a com algoritmos como TF-IDF para otimizar a relevância dos resultados da pesquisa. Recuperação híbrida O modo de recuperação híbrida combina a compreensão profunda da recuperação semântica com a resposta rápida da recuperação de texto completo, com o objetivo de fornecer uma experiência de pesquisa precisa e abrangente. Neste modo, o sistema não apenas realiza a correspondência de palavras-chave, mas também combina cálculos de similaridade semântica para garantir a relevância e precisão dos resultados da pesquisa. Vantagens: Levando em consideração a velocidade de recuperação do texto completo e a profundidade da recuperação semântica, fornece uma solução de pesquisa equilibrada e melhora a satisfação do usuário. Cenários de aplicação: Adequado para cenários onde a velocidade de recuperação e a qualidade dos resultados precisam ser consideradas de forma abrangente, como atendimento ao cliente online, sistemas de recomendação de conteúdo, etc. Implementação técnica: Ao combinar o índice invertido e o modelo de espaço vetorial, é alcançada uma compreensão abrangente e uma resposta rápida às consultas dos usuários. Por exemplo, você pode filtrar rapidamente o conjunto de candidatos por meio de pesquisa de texto completo e, em seguida, encontrar os resultados mais relevantes do conjunto de candidatos por meio de pesquisa semântica. O modelo vetorial usa: BGE-M3 recupera dados por meio de recuperação vetorial e recuperação de texto e usa o algoritmo RFF para classificar; | Adotar o fatiamento da estrutura do artigo e uma estratégia de indexação de pequeno a grande porte pode ser uma boa solução. Para este último, o modelo de incorporação precisa ser ajustado. Temos quatro esquemas diferentes para construção de dados, todos com bom desempenho na prática: Consulta vs Original: simples e eficiente, a estrutura de dados utiliza diretamente a consulta do usuário para recuperar fragmentos da base de conhecimento: fácil de manter, ou seja, usar a consulta do usuário recupera a consulta. Durante a inicialização a frio, a automação do modelo pode ser usada para extrair a consulta do fragmento de conhecimento correspondente. Consulta vs Resumo: Use a consulta para recuperar o resumo do fragmento de conhecimento e construir um relacionamento de mapeamento entre o resumo e o resumo. o fragmento de conhecimento; Resposta F vs Original: Gere respostas falsas com base em consultas de usuários para recuperar fragmentos de conhecimento.Ajustando o modelo de incorporação |
| reorganizar módulo | A classificação de precisão usa seu próprio modelo de reclassificação, mas o limite é definido em 0,35 | O rearranjo é baseado em uma mistura de pontuações de correspondência de texto e pontuações de correspondência de vetor. O peso padrão da correspondência de texto é 0,3 e o peso da correspondência de vetor é 0,7. | Suporta reordenação, define dinamicamente os resultados da fusão de incorporação e texto completo e remove a duplicação com base no ID; é reordenado e a pontuação de reclassificação é adicionada à pontuação; caso contrário, a pontuação de reclassificação não será adicionada; | |
| Manuseio de modelos grandes | Solicitação para organizar todos os dados juntos (otimizado para token máximo) | Filtre pelo número de tokens disponíveis para modelos grandes | Para o ajuste fino do modelo, é adotado o ajuste fino em etapas, ou seja, primeiro o ajuste fino é realizado usando dados gerais de perguntas e respostas de código aberto, depois o ajuste fino é realizado usando dados de perguntas e respostas de domínio vertical e, finalmente, o ajuste fino é realizada usando dados de perguntas e respostas de alta qualidade anotados manualmente. | |
| serviço de internet | Usando sanic para implementar serviços web | Frasco | Fastapi | |
| Processamento de segmentação de palavras | ChineseTextSplitter personalizado concluído | huqie | ||
| Armazenamento de arquivo | O armazenamento de arquivos usa MinIO | |||
| Destaques | Em comparação com o RAG convencional, foram feitos ajustes finos no processo de reclassificação. | O processo de análise também é muito complicado de escrever, então não é de admirar que a velocidade de processamento seja um pouco lenta. No entanto, espera-se que o efeito de processamento seja melhor do que outros projetos RAG. A julgar pela demonstração exibida no front end real, o RAGFlow pode associar o bloco de texto analisado à posição original no documento original. Atualmente, parece que apenas o RagFlow alcançou um efeito semelhante. | FastGPT fornece três modos de recuperação, cobrindo implementações convencionais em RAG. Desduplicar dados e usar a pontuação mais alta calcular rrfScore e classificar com base nele; |
Resumir:
1. O módulo de reclassificação Qanything é o mais bem projetado
2. O processamento de documentos RAGFlow é o melhor
3. O módulo FastGPT tem muitas configurações dinâmicas
4. Wisdom Spectrum RAG é o melhor para treinamento de ajuste fino em dados de domínio
dimensão completa. Não existe o melhor em termos de dados do seu próprio negócio, o melhor é poder implementá-lo ~

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]