моя контактная информация
Почтамезофия@protonmail.com
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Основные моменты: изменение рейтинга

Основные моменты: индекс обработки данных

Основные моменты включают анализ документов, нарезку на фрагменты, переписывание запросов и точную настройку модели отзыва.

Преимущества: Больше гибкости.
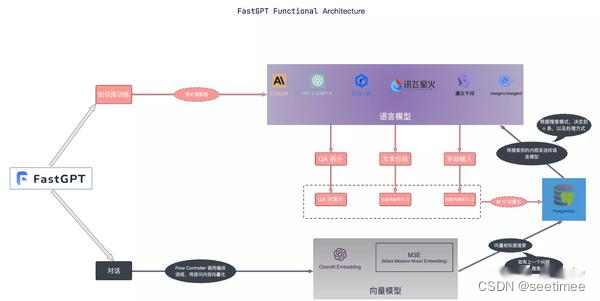
Ниже сравниваются различия каждой платформы в зависимости от модулей.
| функциональный модуль | QЧто угодно | RAGFlow | FastGPT | Спектр мудрости ИИ |
|---|---|---|---|---|
| Модуль обработки знаний | Анализ PDF-файла реализуется PyMUPDF, который на данный момент является наиболее эффективным. Для анализа текста документа используется метод get_text PyMuPDF. Он не различает текстовые документы и документы-изображения (если в документе-изображении нет текста, возникает ошибка). будет сообщено) | OCR, анализ макета документа и т. д., их можно включить в качестве незаметного неструктурированного загрузчика в обычный RAG. Вы можете догадаться, что одна из основных возможностей RagFlow заключается в процессе анализа файлов. | ||
| модуль отзыва | Библиотека векторов использует гибридный поиск Milvus (поиск векторов BM25), не устанавливает порог и возвращает topk (100). | База данных векторов использует ElasticSearch.Гибридный поиск реализует векторный поиск текста. Конкретная векторная модель не указана, но в качестве сегментатора слов для поиска текста используется huqie. | Семантический поиск В режиме семантического поиска используется передовая технология векторных моделей для преобразования наборов данных в базе знаний в точки в многомерном векторном пространстве. В этом пространстве каждый документ или элемент данных представлен как вектор, который фиксирует семантическую информацию данных. Когда пользователь задает запрос, система также преобразует вопрос в вектор и выполняет вычисления сходства в векторном пространстве с векторами в базе знаний, чтобы найти наиболее релевантные результаты. Преимущества: способность понимать и улавливать более глубокий смысл запросов и предоставлять более точные результаты поиска. Сценарии применения: подходят для ситуаций, требующих глубокого семантического понимания и сложной обработки запросов, таких как академические исследования, решение технических проблем и т. д. Техническая реализация: используйте такие модели, как text-embedding-ada-002, для внедрения текстовых данных для достижения эффективного семантического сопоставления. Полнотекстовый поиск Режим полнотекстового поиска ориентирован на индексирование полнотекстового содержимого документов, что позволяет пользователям осуществлять поиск документов путем ввода ключевых слов. В этом режиме анализируется каждый термин в документе и создается индексная база данных, содержащая все документы, что позволяет пользователям быстро находить соответствующие документы по любому слову или фразе. Преимущества: высокая скорость поиска, возможность проведения обширного поиска по большому количеству документов, что позволяет пользователям быстро находить документы, содержащие определенные слова. Сценарии применения: подходят для сценариев, требующих комплексного поиска в библиотеках документов, таких как новостные репортажи, онлайн-библиотеки и т. д. Техническая реализация: используйте технологию инвертированного индекса для быстрого поиска документов по ключевым словам и комбинируйте ее с такими алгоритмами, как TF-IDF, для оптимизации релевантности результатов поиска. Гибридный поиск. Режим гибридного поиска сочетает в себе глубокое понимание семантического поиска с быстрым откликом полнотекстового поиска, стремясь обеспечить одновременно точный и всеобъемлющий поиск. В этом режиме система не только выполняет сопоставление ключевых слов, но и объединяет расчеты семантического сходства для обеспечения релевантности и точности результатов поиска. Преимущества: Учитывая скорость полнотекстового поиска и глубину семантического поиска, он обеспечивает сбалансированное поисковое решение и повышает удовлетворенность пользователей. Сценарии применения: подходят для сценариев, в которых необходимо всесторонне учитывать скорость поиска и качество результатов, например, онлайн-обслуживание клиентов, системы рекомендаций по контенту и т. д. Техническая реализация: за счет объединения модели инвертированного индекса и векторного пространства достигается всестороннее понимание и быстрый ответ на запросы пользователей. Например, вы можете быстро отфильтровать набор кандидатов с помощью полнотекстового поиска, а затем найти наиболее релевантные результаты из набора кандидатов с помощью семантического поиска. В векторной модели используются: BGE-M3 вызывает данные посредством векторного поиска и поиска текста, а также использует алгоритм RFF для сортировки; | Принятие разделения структуры статей и стратегии индексации от малого к большому может быть хорошим решением. Для последнего необходимо доработать модель внедрения. У нас есть четыре различные схемы построения данных, каждая из которых хорошо работает на практике: Query vs Original: простая и эффективная, структура данных напрямую использует пользовательский запрос для вызова фрагментов базы знаний Query vs Query: проста в обслуживании, т. е. проста в обслуживании; использование запроса пользователя вызывает вызов запроса. Во время холодного запуска можно использовать автоматизацию модели для извлечения запроса из соответствующего фрагмента знаний; Запрос и сводка: используйте запрос для вызова сводки фрагмента знаний и построения связи между сводкой и сводкой. фрагмент знаний; F-ответ против оригинала: генерация поддельных ответов на основе запросов пользователей для вызова фрагментов знаний.Точная настройка модели внедрения |
| переставить модуль | При прецизионной сортировке используется собственная модель переранжирования, но порог установлен на уровне 0,35. | Перестановка основана на сочетании оценок соответствия текста и оценок соответствия векторам. Вес соответствия текста по умолчанию равен 0,3, а вес соответствия векторам — 0,7. | Поддерживает переупорядочение, динамически устанавливает результаты слияния встраивания и полнотекстового текста, а также удаляет дублирование на основе идентификатора, объединяет строки qa, удаляет пробелы и знаки препинания, хэш-кодирует строки и удаляет дублирование, если настроена модель переранжирования, вызов модели; переупорядочивается, и оценка повторного ранжирования добавляется к баллу; в противном случае оценка повторного ранжирования не будет добавлена; | |
| Работа с большими моделями. | Подсказка организовать все данные вместе (оптимизировано для максимального количества токенов) | Фильтровать по количеству токенов, доступных для больших моделей. | Для точной настройки модели применяется поэтапная точная настройка, то есть сначала точная настройка выполняется с использованием общих данных вопросов и ответов из открытого источника, затем точная настройка выполняется с использованием данных вопросов и ответов вертикальной области и, наконец, точная настройка. выполняется с использованием вручную аннотированных высококачественных данных вопросов и ответов. | |
| веб-сервис | Использование sanic для реализации веб-сервисов | Фляга | Фастапи | |
| Обработка сегментации слов | Пользовательский ChineseTextSplitter завершен | хуцие | ||
| Файловое хранилище | Хранилище файлов использует MinIO | |||
| Основные моменты | По сравнению с обычным RAG, в процесс изменения ранга были внесены точные корректировки. | Процесс синтаксического анализа также очень сложен в написании, поэтому неудивительно, что скорость обработки немного медленная. Однако ожидается, что эффект обработки будет лучше, чем в других проектах RAG. Судя по демонстрации, отображаемой на реальном интерфейсе, RAGFlow может связать проанализированный текстовый блок с исходной позицией в исходном документе. Этот эффект просто потрясающий. В настоящее время кажется, что только RagFlow достиг подобного эффекта. | FastGPT предоставляет три режима извлечения, охватывающие основные реализации в RAG. Дедублировать данные и использовать наивысший балл, вычислять rrfScore и сортировать на его основе; |
Подведем итог:
1. Модуль реранга Qanything разработан лучше всего.
2. Обработка документов RGFlow — лучшая
3. Модуль FastGPT имеет множество динамических конфигураций.
4. Wisdom Spectrum RAG лучше всего подходит для точной настройки обучения на предметных данных.
полный размер. Лучшего не существует. С точки зрения данных вашего собственного бизнеса, лучше всего уметь это реализовать~

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com